[具身智能-379]:如何在仿真环境进行模型的训练?模型如何获取仿真如何的数据?模型与仿真软件交换信息的标准?
·
一、仿真环境训练模型的标准流程
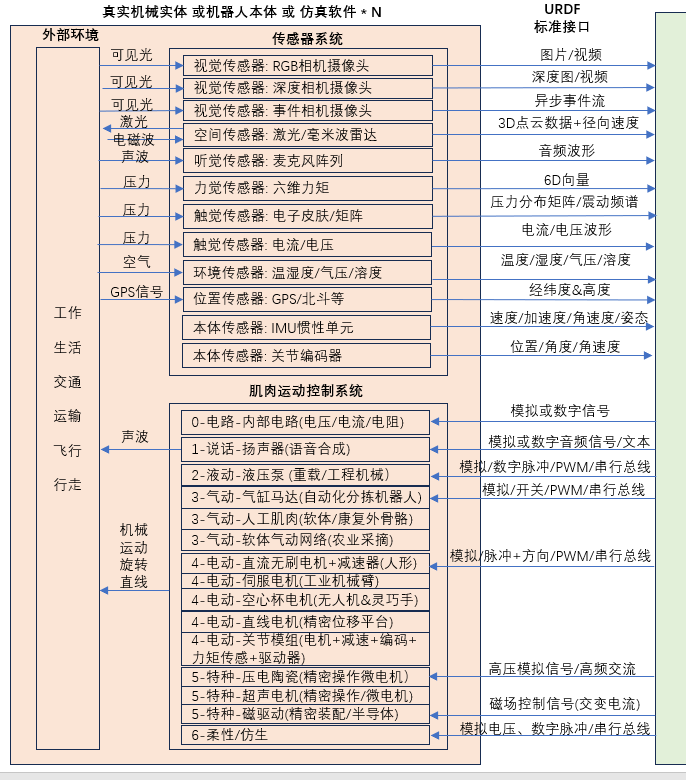
无论使用强化学习(RL)、监督学习(SL)还是模仿学习(IL),在仿真中训练都遵循以下闭环:
1. 环境配置
2. 定义交互接口
3. 构建训练循环
4. 并行加速
5. 评估与导出
| 步骤 | 关键动作 | 说明 |
|---|---|---|
| 1. 环境配置 |
导入 URDF/MJCF/USD、 配置物理参数、挂载传感器/执行器、 设置地面/障碍物 |
决定仿真的“物理上限” |
| 2. 定义接口 | 确定 observation_space、action_space、reward(RL)或 dataset(SL/IL) |
对齐模型输入输出维度 |
| 3. 训练循环 | reset() → 获取初始观测 → 模型推理输出 action → step(action) → 获取下一帧观测/奖励/done → 更新策略 |
核心是 step() 的同步交互 |
| 4. 并行加速 | 环境向量化(Vectorized Env)、GPU 物理引擎(Isaac Gym/Lab)、分布式 rollout | 将采样效率提升 100~10000 倍 |
| 5. 评估导出 | 定期冻结策略跑测试集/实机影子模式 → 保存 .pt/.onnx/.engine → 部署到推理服务 |
防止过拟合仿真分布 |
二、模型如何获取仿真环境的数据?
仿真器通过 API 暴露数据流,模型以“轮询”或“回调”方式读取。数据分为三类:
| 数据类型 | 典型内容 | 获取方式 |
|---|---|---|
| 观测(Observation) | 关节角度/速度、IMU、相机 RGB/Depth、LiDAR 点云、物体位姿、接触力、全局状态 |
/ 返回的 |
| 反馈(Feedback) | 奖励值 reward、终止标志 done、调试信息 info(如穿透深度、碰撞标志、仿真时间) |
step() 返回值 |
| 动作(Action) | 电机扭矩、目标位置/速度、末端位姿指令、高层离散动作 | 模型输出 → 传入 step(action) |
🔄 数据流底层机制
- 同步步长(Fixed Timestep):仿真器按固定物理步长(如
dt=0.005s)积分动力学,每次step()返回一帧数据。RL 最常用。 - 异步流式(Streaming/Real-time):感知模型按相机帧率(30/60Hz)或 LiDAR 频率接收数据流,不阻塞物理步进。常用于自动驾驶/CV。
- 数据后处理:模型拿到原始数据后通常需做:
- 坐标系转换(传感器 frame → base_link frame)
- 归一化/滤波(关节角度限幅、IMU 低通、深度图去噪)
- 域随机化(训练时动态加噪声/换纹理/改质量)
三、模型与仿真软件交换信息的标准/协议
不存在单一“国家标准”,而是根据任务类型形成三套主流生态:
| 生态 | 适用场景 | 核心接口/协议 | 数据格式 | 代表仿真工具 |
|---|---|---|---|---|
| 强化学习标准 | 策略训练、控制优化 | gymnasium API(reset, step, render) |
NumPy/PyTorch 张量、Dict |
Stable-Baselines3, RLlib, Isaac Lab |
| 机器人中间件 | 传统控制、多模块集成、虚实对齐 | ROS/ROS2(Topics/Services/Actions) | sensor_msgs, geometry_msgs, Protobuf, DDS |
Gazebo+ros2_control, Webots ROS2, Isaac ROS2 Bridge |
| 高性能实时通信 | 低延迟控制(<1ms)、多机协同 | gRPC, ZeroMQ, Shared Memory, TCP/UDP, Zenoh | 二进制流、FlatBuffers, MessagePack |
PyBullet 自定义桥、MuJoCo C API、 NVIDIA Omniverse Kit |
🔑 关键交互规范
| 维度 | 规范说明 |
|---|---|
| 时间同步 | 仿真使用 /clock(ROS2)或内部时钟;模型需按仿真时间而非墙钟时间步进 |
| 频率匹配 | 物理步长(如 200Hz)与策略步长(如 20Hz)可通过 action_repeat 或控制器插值解耦 |
| 线程安全 | 渲染/物理/策略通常分线程;需加锁或使用无锁队列(如 mp.Queue、ring buffer) |
| 容错机制 | 仿真崩溃需自动重启环境;网络断开需 fallback 到安全策略(如零速保持) |
四、典型交互架构与代码示例
🧩 架构对比
[策略模型 PyTorch] ←(张量/字典)→ [Gymnasium Wrapper] ←(API)→ [Isaac Lab / MuJoCo / PyBullet]
↓
[ROS2 Bridge (可选)] → 实机/可视化
💻 最小可运行示例(Gymnasium + RL)
import gymnasium as gym
import torch
# 1. 创建仿真环境(已封装为 Gym 接口)
env = gym.make("Isaac-Humanoid-v0", num_envs=1024) # GPU 并行环境
obs, info = env.reset()
policy = torch.nn.Sequential(
torch.nn.Linear(obs.shape[-1], 256),
torch.nn.ReLU(),
torch.nn.Linear(256, env.action_space.shape[-1])
)
# 2. 训练循环
for step in range(10000):
# 模型推理获取动作
with torch.no_grad():
action = policy(torch.tensor(obs, dtype=torch.float32))
# 与仿真器交互
obs, reward, terminated, truncated, info = env.step(action.numpy())
done = terminated | truncated
# 收集数据用于 PPO/SAC 等更新
buffer.store(obs, action, reward, done, info)
if step % 100 == 0:
policy.update(buffer.sample()) # 策略更新
env.reset() # 周期性重置✅ 说明:
env.step()内部完成:接收动作 → 物理积分 → 传感器渲染 → 返回观测/奖励。模型无需直接调用物理引擎。
五、工程实践关键点(避坑指南)
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 策略在 Real 上抽搐/发散 | Sim 步长与 Real 控制器频率不匹配 | 使用 action_repeat + 实机 PID 滤波;导出时冻结仿真 dt |
| 图像策略 Sim2Real 失效 | 渲染分布与真实相机差异大 | 训练时启用 Domain Randomization(光照/材质/运动模糊/噪声) |
| 通信延迟导致失稳 | 网络/序列化开销 > 控制周期 | 改用共享内存(torch.multiprocessing)、ZeroMQ 或 gRPC 流式 |
| Reward 设计导致策略取巧 | 仿真器物理漏洞(如穿模、无限能量) | 加入惩罚项(关节超限、穿透深度、能耗);用实机影子模式验证 |
| 无法调试“黑盒”交互 | 日志缺失、状态不透明 | 记录完整 rollout:obs, action, reward, sim_time, real_time;用 TensorBoard/W&B 可视化 |
📦 附:主流仿真器数据接口速查
| 仿真器 | Python API | Gym 封装 | 推荐通信方式 | 适用场景 |
|---|---|---|---|---|
| Isaac Lab / Gym | omni.isaac.core |
✅ 官方支持 | 共享内存 / ROS2 Bridge | 大规模 RL、足式/人形、灵巧手 |
| MuJoCo | mujoco / dm_control |
✅ gymnasium.envs.mujoco |
本地 C/Python API | 高精度动力学、学术基准 |
| PyBullet | pybullet |
✅ gym-pybullet-drones 等 |
TCP / 自定义队列 | 轻量级、无人机、软体 |
| Gazebo / Ignition | ign_transport / ros2 |
⚠️ 需第三方封装 | ROS2 Topics/Services | 传统机器人、多机协同 |
| CARLA | carla Python API |
❌ 无官方 Gym | gRPC / ROS2 | 自动驾驶感知/规划 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献208条内容
已为社区贡献208条内容

所有评论(0)