MySQL的执行计划详解———Explain关键字
一、什么是 EXPLAIN?
在MySQL中explain关键字是用于查询执行计划的分析工具,可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,帮助优化查询性能。它的语法就是直接在sql语句之前加explain 。
二、EXPLAIN 输出字段

第一组 快速判断好坏
1.Type
查找方式,它显示了该select SQL使用了哪一种方式进行查询,主要有七种性能,分别为
| system | 表中只有一行数据或是系统表 |
| const | 通过主键或唯一索引等值查询,最多返回一行 |
| eq_ref | 连接查询中,使用主键或唯一索引进行匹配 |
| ref | 使用普通索引或联合索引前缀进行等值查询 |
| range | 索引范围扫描 |
| Index | 全索引扫描 |
| all | 全表扫描 |
效率从优到差依次为system > const > eq_ref > ref > range > index > all
性能优化目标至少要达到range级别,要求是ref级别,最好是consts级别
2.Key
实际使用的索引,确认索引是否被使用了
使用主键索引性能最好,唯一索引、普通索引、联合索引(全部,部分也可接受)性能良好,避免索引失效,key=null的情况或没有索引key=null;
3.Rows
预计需要扫描的行数才能找到你需要的数据(不是精确值)
row越小越好, 注意rows根据索引基数,数据分布,表总行数估算的,不是结果集里的行数
优化rows的方法1.添加合适索引,使用覆盖索引,优化where条件,避免使用函数,
rows字段作用:预测性能问题,优化验证
4.Extra
执行查询的额外信息
| 现象 | 名称 | 含义 |
|
Using filesort |
文件排序 |
MySQL 需要额外的一次排序操作,无法利用索引排序 |
|
Using temporary |
使用临时表 |
MySQL 需要创建临时表来存储中间结果 |
|
Using where |
需要过滤 |
需要从存储引擎返回数据后,再进行 WHERE 条件过滤 |
|
Using index |
覆盖索引 |
查询所需的数据都在索引中,不需要回表 |
|
Using index condition |
索引下推 |
在索引层面就过滤数据(mysql5.6以上版本特性) |
|
Using where; Using index |
覆盖索引+过滤 |
查询使用覆盖索引,但 WHERE 条件需要过滤 |
|
Using join buffer |
连接缓冲区 |
JOIN 时使用了连接缓冲区 |
|
Impossible WHERE |
WHERE不可能条件 |
WHERE 条件永远为假 |
|
No tables used |
没有使用表 |
这个为正常,只是不计算不查表 |
extra可以快速发现问题,确认是否使用索引和具体执行细节
Using temporary、Using filesort必须消除,Using index努力实现,Usingwhere根据具体情况看待
第二组 理解执行逻辑
1.id
每个select对应一个id值,其值是按 select 出现的顺序增长的。 注:id 越大,越先执行,id相同则从上往下执行,id为NULL最后执行
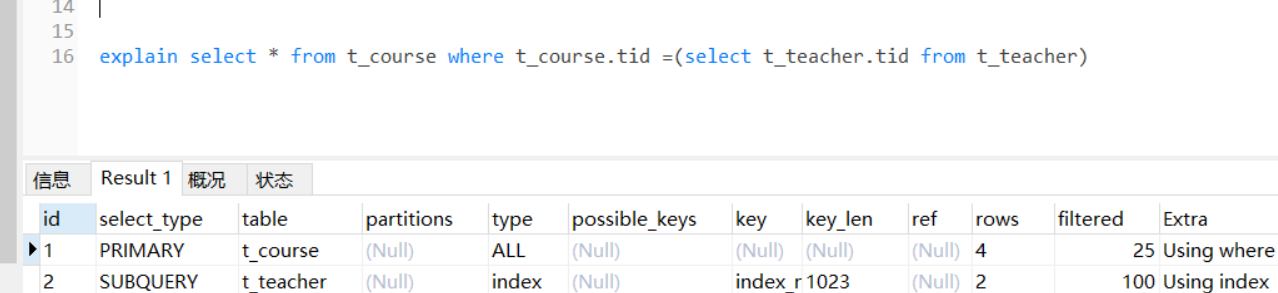
以子查询为例,先查的id在前
2.select_type
显示查询类型 区分子查询、UNION等
|
SIMPLE |
简单查询 |
没有子查询没有UNION |
|
PRIMARY |
主查询 |
包含子查询时最外层的查询 |
|
SUBQUERY |
子查询 |
select 或 where 后面的子查询 |
|
Dependent subquery |
依赖子查询 |
子查询依赖于外层查询结果 |
|
Derived |
派生表 |
from子句中的子查询 |
|
Union result |
联合结果 |
用于合并两个查询结果 |
|
Dependent union |
依赖联合 |
子查询依赖于外层查询 |
从优到劣依次为simple> primary> union\ subquery \derived >dependent subquery\ dependent union
select_type主要了解当前是简单查询还是复杂查询,发现性能问题,了解执行逻辑
出现后两种需要考虑重写了
3.possible_keys
可能使用的索引, MySQL 觉得可能用到的索引有哪些
与key的区别,key是实际用了哪个索引,它是可能用了哪些索引,显示的索引不一定都用了,但显示过多也不好,应该合并删除索引,possible_keys有值,key无值说明索引没用上。
possible_keys作用是验证索引是否存在,检查索引是否可用,发现索引冗余
4.ref
比较对象 非唯一性索引,显示索引的哪一列被使用了

常见的值为const(常量)、字段名(另一个表的列)、func(函数)、null没有使用索引进行比较
第三组 深度优化调优
1.table
表名 当前正在访问哪个表,如果起了别名显示的就是表的别名
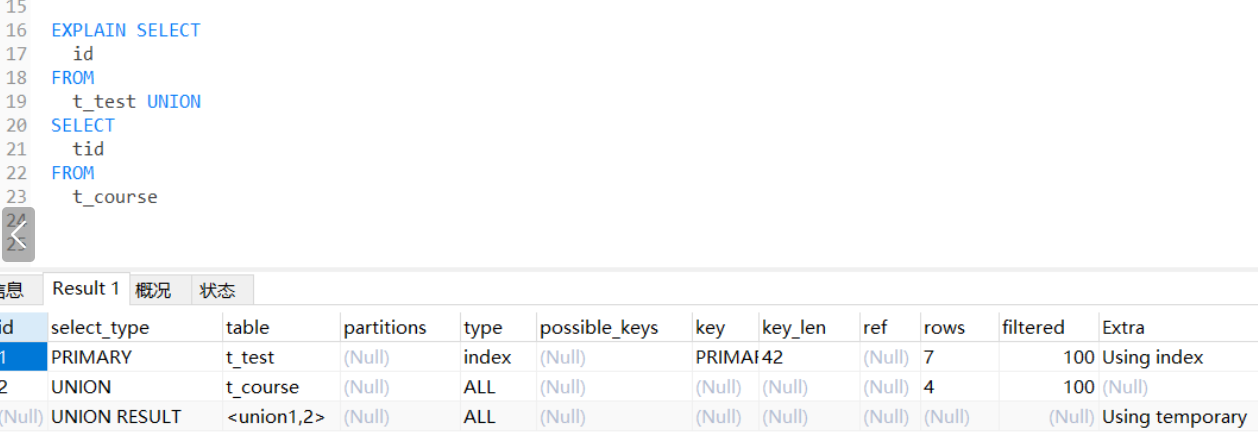
2.key_len
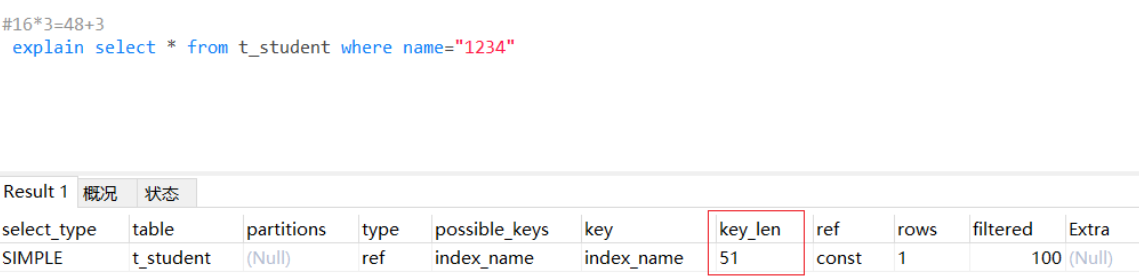
mysql实际使用的索引长度
常见的数据类型
数值类型(tinyint、smallint、int、bigint)
字符串类型(char、varchar)
日期类型(date、datetime、timestamp)
key_len =
字段本身占用的字节数
+ 是否为 NULL 的标识(1字节)
+ 是否为 VARCHAR 的长度标识(2字节)
根据字符集计算(utf8mb4=4,utf8=3,latin1=1)
key_len字段的作用:
快速判断联合索引使用了哪些列,验证是否生效,key_len在合理范围内越大用到的索引列越多越好
3.filtered
过滤比例 经过表条件过滤后剩余记录的百分比(有多少百分比的数据能满足 WHERE 条件)
作用:估算实际返回的行数 rows*filtered%,100%表示所有扫描数据都满足条件
4.Partitions
显示mysql查询时实际访问了哪些分区(比较少见)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)