论文解读:一张RA-LLM全景图,拆透检索增强的底层逻辑
你可能遇到过这种场景:用GPT查一个去年的政策变化,它给出了一段措辞流畅、逻辑严密的回答——然后你发现,那个政策压根不存在。
这不是bug,这是LLM的原罪。
大语言模型(Large Language Model,LLM——你可以把它理解为"经过海量文本训练、能理解和生成语言的超大规模神经网络")在训练完成那一刻,就被"封印"了。它的知识库定格在某个时间节点,此后发生的一切,对它来说是真空。更要命的是,当你问它一个它不确定的问题,它不会说"我不知道",而是用极度自信的语气,生成一段看起来很有道理的胡话——这就是著名的"幻觉"(Hallucination)问题。
一项研究表明,顶级LLM在回答特定法律查询时,幻觉率高达 69% 到 88%。七八成的时间,它在撒谎,但它自己浑然不觉。
就在这种"能力惊艳、可信度危机"并存的关键节点,RAG(Retrieval-Augmented Generation,检索增强生成)成为了最被寄予厚望的解法。
而港理工联合新加坡国立大学、百度发布、在KDD '24亮相的这篇综述,第一次以"架构-训练-应用"三维框架,系统梳理了检索增强大语言模型(RA-LLMs)的全貌。
这是目前这个方向最完整的一张地图。
1. LLM的两道枷锁:知识时效与幻觉
为什么RAG这么重要?必须先说清楚LLM本质上在和什么作战。
LLM的强大来自于它的参数记忆——在预训练(Pre-training)阶段,数百亿甚至万亿参数"吸收"了互联网上的文本,把知识压缩进网络权重里。这种参数化知识让模型具备了惊人的语言理解和推理能力。
但问题也就在这里。
第一道枷锁:知识时效。 训练数据有截止日期,模型对此后发生的一切一无所知。医疗领域的新治疗方案、法律的最新修订、刚发布的产品文档——通通不在它的认知范围内。
第二道枷锁:领域幻觉。 越是需要精确、专业、可验证知识的场景,LLM的幻觉问题越严重。原因很直接:参数记忆本质上是"统计压缩",对于低频、专业、细粒度的知识,模型只能靠概率猜测,猜出来的内容往往不是事实。
图1展示了同一个问题,有无RAG的两种结果对比。左侧的纯LLM因训练数据截止于2022年1月,面对2023年的赛事结果只能给出"无法回答";右侧接入了外部数据库的RAG系统,则直接返回了"西班牙夺冠"的正确答案
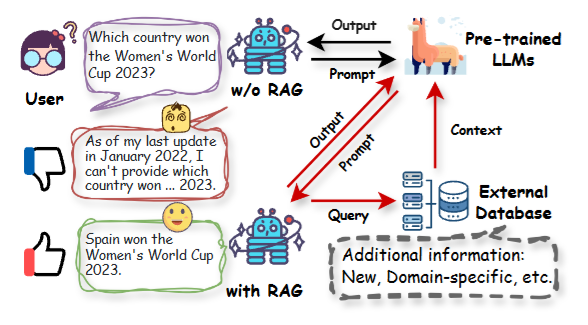
图1
注意图里的关键细节:RAG并没有改变模型本身——它只是在"提问"和"回答"之间,插入了一个"查资料"的步骤。这就是它的全部秘密,也是它能绕开参数时效限制的根本原因
更新参数能解决这两个问题吗?理论上可以,实际上行不通。
对一个千亿参数的模型做一次完整的fine-tuning(微调),所需的算力和时间成本是天文数字。你不可能为每一次知识更新都重新训练整个模型。
RAG的思路完全不同——它不改变模型的参数,而是在推理时给模型"开卷":允许它从外部知识库里查资料,再把查到的内容和问题一起送进模型,让模型基于真实的外部知识生成答案。
从"闭卷考试"变成"开卷能力",这一步转变听起来简单,背后的工程细节却相当复杂。
2. 研究团队与综述的独特视角
这篇综述由香港理工大学Wenqi Fan和通讯作者Yujuan Ding主导,联合新加坡国立大学Tat-Seng Chua(媒体与信息系统领域的顶级研究者)以及百度的Dawei Yin共同完成,核心力量横跨推荐系统、信息检索和自然语言处理三个方向。
这种跨机构、跨方向的组合,决定了这篇综述的视野——它不只是"NLP人看RAG",而是整个AI工程生态对这条技术路线的系统审视。
和同期其他RAG综述相比,这篇研究选择了"架构-训练-应用"三维框架:不是按时间线梳理发展历程,而是按技术模块的功能分工来拆解,找到每个设计选择背后的权衡逻辑。
这是一个务实的选择。
已有综述(如Zhao et al. 的多模态RAG综述、Gao et al. 的RAG全面综述)各有侧重。这篇研究的核心差异在于:它把"训练策略"单独作为一个维度,系统梳理了从完全免训练到端到端联合优化的全部路线——这是理解RA-LLMs工程落地成本的关键维度,但在其他综述里往往被简化处理。
3. 检索器的两条路:稀疏 vs 稠密
RA-LLM框架可以用一句话概括:检索器找资料,生成器写答案,融合模块负责把两者连起来。
在拆解每个模块之前,先把整体架构看清楚——每一个零件解决的是什么问题,它在整条流水线里处于什么位置
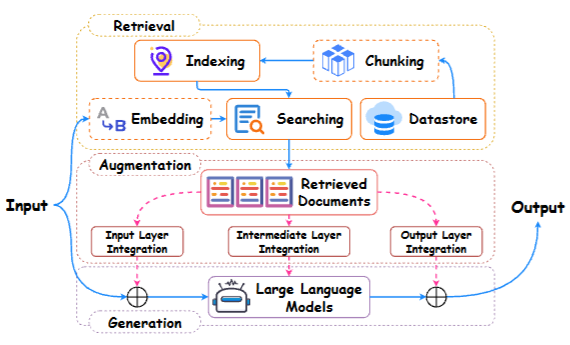
图2
图2展示了RA-LLM框架全貌。从左往右:外部Datastore先经过Chunking(分块)和Indexing(建索引),再由检索器完成Embedding(向量化)和Searching(检索匹配),最终把Retrieved Documents送入Augmentation模块——而融合可以发生在生成器的三个不同层次:Input Layer(输入层)、Intermediate Layer(中间层)和Output Layer(输出层)。
但这三句话的背后,每一步都有10种以上的技术路径,每条路径背后都是一套不同的权衡逻辑。先从检索器说起。
稀疏检索(Sparse Retrieval):代表技术是TF-IDF和BM25。它的工作方式就像图书馆的关键词索引:用词频和逆文档频率来衡量相关性,把文档表示成"词袋",通过倒排索引快速匹配。这类方法不需要训练,计算极快,在精确关键词匹配场景下表现很好。
但局限性非常明显——它只认词,不认意。
"苹果手机"和"iPhone",在稀疏检索眼里是两个完全不同的东西。语义相似但用词不同的内容,大概率检索不到。
稠密检索(Dense Retrieval):代表技术是DPR(Dense Passage Retrieval,稠密段落检索)。它把查询和文档都"压缩"成连续向量表示,通过向量空间中的距离来衡量语义相似性。
翻译成人话——它读懂了意思,而不只是认识字。
DPR用了双塔结构(bi-encoder,双编码器):一个编码器处理问题,另一个处理文档,两边的向量越接近,代表越相关。因为基于神经网络,稠密检索可以针对特定任务fine-tuning,适应性强得多。当通用预训练检索器(如Contriever、Spider)出现后,稠密检索的泛化能力大幅提升——不再只是针对某一任务的专用工具,而是可以灵活插入各种RA-LLM系统的"通用接口"。
检索粒度是另一个关键决策。检索单元可以是整篇文档、段落(Chunk/Passage)、单个Token,甚至是实体(Entity)。
主流选择是段落级别——比整篇文档更精准,比Token级别更有完整语义,在信息密度和计算效率之间取得了最好的平衡。Token级检索适合需要"罕见模式"的边缘场景;实体检索则更适合知识图谱式的精确查找任务。
检索器的选择本质上是一个工程权衡,没有万能答案。
4. 生成器:白盒与黑盒,两种完全不同的游戏规则
检索器找到了资料,生成器负责把资料和问题整合成最终答案。
在LLM时代,生成器分成了泾渭分明的两类:白盒(White-box,参数可访问)和黑盒(Black-box,参数不可访问)。
白盒生成器:参数可见、可修改。典型代表是T5和BART——Encoder-Decoder架构的代表性模型。它们允许研究者在检索-生成的全流程中进行端到端的参数优化:检索器可以根据生成器的反馈来更新,生成器也可以根据检索结果来fine-tuning。
这套玩法的上限很高,但门槛也很高——你得有足够的算力和数据,才能去调一个庞大的生成器。
黑盒生成器:GPT-4、Claude、Codex这类商业模型,只提供API接口。你能做的只有输入和输出,内部参数碰都别想碰。
这种情况下,RAG的重心完全转向检索和融合阶段:既然模型参数不能动,就把功夫花在"怎么给模型更好的上下文"上——找到更相关的文档、压缩冗余信息、设计更有效的prompt格式。
比如RECOMP提出先把检索到的文档压缩,去掉和问题无关的内容,再送给生成器——这样不但减少了推理的计算成本,也避免了超长上下文让模型"注意力分散"。
黑盒这条路线,正在成为工业界应用RAG的主流——毕竟大多数企业用的都是商业API,而不是自己训练的开源模型。
这意味着什么?意味着对工业界来说,RAG的核心战场已经从"怎么训练更好的生成器"转移到了"怎么找到更好的内容、用更好的方式喂给模型"。
5. 融合的三个层次:在哪里注入外部知识?
检索到了内容,怎么把它"灌"进生成器里?
这是Augmentation(融合)模块要解决的问题。综述把融合方式分为三个层次,从轻量到深度依次递进:
输入层融合(Input-Layer Integration):最直观的方式——把检索到的文档和原始问题拼在一起,作为新的输入送给模型。In-Context RALM就是这种做法的典型代表。
优势:简单、灵活,对任何生成器都适用,包括黑盒模型。
局限:上下文窗口有硬限制。如果检索到的文档太多太长,拼起来超过了模型的最大输入长度,就得截断——截断就意味着信息损失。FID(Fusion-in-Decoder)的做法更巧妙:把每个检索文档单独送进encoder处理,避免了"所有文档拼成一条超长序列"的问题。每个文档独立做self-attention,最后在decoder里融合,可扩展性强得多。
输出层融合(Output-Layer Integration):在生成器产生输出后,再用检索结果来"校正"。kNN-LM是这个思路的开山之作——把语言模型预测的token概率分布和k近邻检索的分布线性插值,相当于用外部知识库做了一次"实时纠偏"。
这种方式轻量、灵活,不需要重新训练,可以插入任何已有的生成模型。但也有天然的局限:输出层融合本质上是后处理,无法让模型在生成过程中"主动调用"知识,推理深度受限。
中间层融合(Intermediate-Layer Integration):把检索结果注入模型的中间层——也就是Transformer中间某个层的隐状态里。RETRO是这个方向的代表作:它引入了一个特殊的分块交叉注意力层(Chunked Cross-Attention,CCA),直接把检索到的chunk编码融入生成器的内部表示。
这是融合深度最高的方式,也是效果潜力最大的方式。
但代价是:你必须能访问模型的内部结构,黑盒模型完全不适用。实现复杂度高,不是所有人都有资源走这条路。
三种方式,三种权衡。没有绝对的优劣,只有场景匹配度。
6. 训练策略:从"零训练"到"联合调优"
架构之外,训练策略是决定RA-LLM系统上限的另一个关键维度。
综述把RA-LLM的训练方式分为四类,从复杂度来说依次递进:
免训练(Training-Free):这是目前最广泛被采用的方式。
核心逻辑很清晰:LLM已经足够强大,无需为了RAG重新训练。直接在推理时把检索到的内容插进prompt里,让模型"开卷"生成答案。IRCoT(将思维链推理和检索步骤交替进行,每步检索为下一步推理提供更相关上下文)就是这条路线的典型代表。这类方法计算效率高,部署简单,对黑盒模型友好——但检索器和生成器没有为彼此专门优化,存在"各自为战"的天然局限。
独立训练(Independent Training):检索器和生成器分别独立训练,互不干涉。DPR是独立训练的代表。好处是可以灵活替换——用最好的开源检索器搭配最好的开源生成器,像积木一样组合。但没有联合优化,两个模块的目标函数天然存在偏差,协同效果难以保证。
序列训练(Sequential Training):先训好一个,冻结,再训另一个。分为"检索器先行"和"LLM先行"两条路。
"检索器先行"的代表是RETRO——用预训练好的BERT作为固定检索器,然后在此基础上训练生成器,让生成器专注于"如何最好地利用检索到的内容"。
"LLM先行"的代表是UPRISE——先冻结LLM,用LLM产生的评分信号来训练一个轻量级的prompt检索器。检索器学会了"什么样的prompt能让这个特定的LLM表现最好",实现了零样本(zero-shot)场景下的性能提升。
联合训练(Joint Training):检索器和生成器端到端联合优化,共享梯度。RAG(Lewis et al., 2020)、REALM都走的这条路。
这是技术上最复杂的方式,也是理论上限最高的方式——两个模块互相"照顾对方的需求"。但挑战也最大:外部知识库的所有文档需要提前做embedding并建立索引,而联合训练时模型参数在更新,索引需要周期性异步刷新(每数百步一次),工程实现难度不小。
这四条训练路线,对应了从"快速原型"到"深度优化"的不同需求层次——不是哪条路更好,而是哪条路更适合你当前的资源和目标。
7. 应用版图:RAG已经渗透到哪里了?
RA-LLM不是实验室里的玩具,它正在真实落地。综述梳理了三个维度的应用版图。
NLP应用层:问答系统、对话机器人、事实核查。
QA(问答系统)是RAG最原生的应用场景——REALM可以在预训练、fine-tuning、推理三个阶段都调用知识检索,在开放域问答任务上效果显著。ChatBot结合RAG后,不再只依赖静态的Wikipedia知识库,有系统已经实现了对实时互联网搜索结果的融合,让对话内容具备了实时性。事实核查场景里,Self-RAG引入了自反思机制——检索到内容后,模型主动评估"这个内容对我的回答有帮助吗?是否可信?",大幅提升了核查精度。
下游任务层:推荐系统、软件工程。
推荐系统和RAG的结合可能是最出人意料的组合。CoRAL用强化学习从数据集中检索协作过滤信息,再和语义信息对齐,专门解决长尾推荐难题——用户互动少的冷门内容,在RAG的帮助下也能被准确推荐。代码生成方面,DocPrompting通过检索相关API文档来辅助代码生成,让模型不再"凭记忆写代码"。
领域专业层:AI4Science和金融。
分子发现领域,MolReGPT用RAG增强了ChatGPT的分子描述能力,从数据库中检索结构相似的分子来辅助生成。蛋白质表示领域,RSA通过检索结构或功能相似的蛋白质序列来增强蛋白质表示质量。金融领域,RA-LLM被用于实时融合Bloomberg、Reuters等平台的新闻数据来做情感分析;针对金融报告的PDF解析和基于文档结构的分块方法,也成为了优化金融RA-LLM输出质量的关键工程手段。
一句话概括这张版图:RAG正在成为LLM"可信落地"的标配基础设施。
8. 三条路线,各自的死角在哪里?
要理解RAG在当下AI技术栈里的定位,还要看清它和另外两条主流路线的区别。
路线一:只靠参数记忆(纯LLM)。 优势是部署简单、推理延迟低。缺陷也很明显——知识被"压缩封印"进参数,更新代价极高,幻觉问题根本无法从结构上消除。这条路适合通用能力,但在知识密集型任务上有天然的上限。
路线二:持续微调(Continuous Fine-Tuning)。 通过不断用新数据fine-tuning来更新知识。理论上能解决时效问题,但每次更新都要耗费大量算力,而且存在严重的"灾难性遗忘"(Catastrophic Forgetting)风险——学了新知识,旧能力可能退化。
路线三:RAG。 不动参数,推理时实时查外部知识库。知识更新只需要更新数据库,不需要重新训练模型;幻觉问题因为有了可溯源的外部证据,得到了结构性的缓解。
三条路线,纯LLM太封闭,持续微调太昂贵,RAG的定位正好在两者之间——在不改动模型本身的前提下,最大化知识的实时性和可信度。
这不是巧合,这是系统设计层面的必然选择。
9. 未解之题:RAG还差什么才能成为基础设施?
这篇综述没有回避挑战。在讨论未来时,研究团队列出了四个尚待突破的方向。
可信赖性(Trustworthy RA-LLMs):RAG不是万能的安全阀。已有研究表明,精心构造的恶意内容被注入外部知识库(即"知识库投毒"攻击,Knowledge Poisoning),会让RA-LLM生成有害输出——而且这种攻击比直接对模型做对抗攻击更难防御。外部知识库的隐私泄露风险也是现实存在的威胁。可信赖的RA-LLM需要同时具备鲁棒性、公平性、可解释性和隐私保护四个属性,目前任何一个都没有被很好地解决。
多语言RA-LLMs:当前大多数RAG系统默认英文或中英双语。对于低资源语言的用户,利用多语言检索来增强生成质量,是一个尚未充分开发的方向。当世界愈发互联,跨语言的知识检索能力不是锦上添花,而是普惠性的刚需。
多模态RA-LLMs:外部知识库不只有文本。图像、视频、音频作为检索对象,能给生成提供更丰富的上下文——REVEAL(视觉-语言预训练+多源多模态知识记忆)已经开始探索这条路,但离实用还有距离。多模态RAG一旦成熟,AI的"世界理解"能力将完成另一个维度的跃升。
外部知识质量:维基百科作为最常用的RAG知识库,内容质量参差不齐。低质量或含有错误信息的文档一旦被检索进来,不但帮不上忙,还可能"污染"生成结果。如何自动评估和过滤知识库质量,是一个被严重低估的工程问题——也是RAG能否真正"可信"的前提。
这四道门槛,每一道都不轻松。
10. 这张地图意味着什么?
把RA-LLMs的全貌梳理清楚,并不只是学术意义上的文献整理。
这篇综述更像是一张"当下的坐标系"——它告诉工程师们,这个方向已经有了哪些可靠的零件,哪些坑已经被人踩过,哪些方向还有真正的空白。
检索-生成的融合,本质上是在让AI从"自言自语"走向"基于证据的推理"。从只依赖参数记忆的"单机版",到可以随时查阅外部世界的"联网版"——这一步转变,不只是技术进步,是AI系统认识论意义上的一次升级。
它让知识获取从"记住"迈向"查证"。它让知识更新从"重新训练"迈向"更新数据库"。它让AI回答从"自信地猜"迈向"有据地说"。
RA-LLMs还在演化之中。可信赖性、多模态、知识质量——这三道尚未跨越的门槛,决定了RAG能否真正成为大模型落地的"基础设施级别"存在。
如果说过去几年的LLM浪潮是"让机器学会说话",那么RA-LLMs的演进,是"让机器学会查证再开口"的第一块基石。
论文地址:https://arxiv.org/abs/2405.06211

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)