【CCS2025】论文梳理
CCS2025论文梳理
- Keynote Talks
- Session A2:大语言模型和网络安全
- Oedipus: LLM-enchanced Reasoning CAPTCHA Solver
- The Odyssey of robots.txt Governance: Measuring Convention Implications of Web Bots in Large Language Model Services
- JsDeObsBench: Measuring and Benchmarking LLMs for JavaScript Deobfuscation
- Session A3:安全可用性与测量1
- Session A4:形式化方法与编程语言1
- Session A5:软件安全1
- Session A6:网络安全1
- Session A7:机器学习与安全1
-
- CryptGNN: Enabling Secure Inference for Graph Neural Networks
- PLRV-O: Advancing Differentially Private Deep Learning via Privacy Loss Random Variable Optimization
- ZORRO: Zero-Knowledge Robustness and Privacy for Split Learning
- ImportSnare: Directed 'Code Manual' Hijacking in Retrieval-Augmented Code Generation
- Session A8:应用密码学1
- Session B1:应用密码学2
- Session B2:隐私与匿名1
- Session B3:安全可用性与测量2
- Session B4: 硬件、侧信道与网络物理系统1
- Session B5:软件安全2
- Session B6:区块链与分布式系统1
- Session B7:机器学习与安全2
-
- Split Unlearning
- Slot: Provenance-Driven APT Detection through Graph Reinforcement Learning
- Combating Concept Drift with Explanatory Detection and Adaptation for Android Malware Classification
- Rethinking Machine Unlearning in Image Generation Models
- TensorShield: Safeguarding On-Device Inference by Shielding Critical DNN Tensors with TEE
- PoisonSpot: Precise Spotting of Clean-Label Backdoors via Fine-Grained Training Provenance Tracking
- Session B8:应用密码学3
- Session C1:应用密码学4
- Session C2:隐私与匿名2
- Session C3:web安全1
- Session C4:形式化方法与编程语言2
- Session C5:软件安全3
- Session C6:网络安全2
-
- Swallow: A Transfer-Robust Website Fingerprinting Attack via Consistent Feature Learning
- FlowSentry: Accelerating NetFlow-based DDoS Detection
- 1BIT: Persistent Path Validation with Customized Noise Signal Characteristics
- RebirthDay Attack: Reviving DNS Cache Poisoning with the Birthday Paradox
- 5G-RNAKA : A Random Number-based Authentication and Key Agreement Protocol for 5G Systems
- Discovering and Exploiting IoT Device Hidden Attributes: A New Vulnerability in Smart Homes
- Session C7:机器学习与安全3
-
- MM4flow: A Pre-trained Multi-modal Model for Versatile Network Traffic Analysis
- Sylva: Tailoring Personalized Adversarial Defense in Pre-trained Models via Collaborative Fine-tuning
- Unmask Tampering: Efficient Document Tampering Localization under Recapturing Attacks with Real Distortion Knowledge
- RAG-WM: An Efficient Black-Box Watermarking Approach for Retrieval-Augmented Generation of Large Language Models
- Membership Inference Attacks as Privacy Tools: Reliability, Disparity and Ensemble
- Prompt Inference Attack on Distributed Large Language Model Inference Frameworks
- Session C8:应用密码学5
- Session D2:web安全2
- Session D3:安全可用性与测量3
- Session D4:硬件、侧信道与网络物理系统2
- Session D5:软件安全4
- Session D6:区块链与分布式系统2
- Session D7:机器学习与安全4
-
- Safeguarding Graph Neural Networks against Topology Inference Attacks
- MoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
- Removal Attack and Defense on AI-generated Content Latent-based Watermarking
- VillainNet: Targeted Poisoning Attacks Against SuperNets Along the Accuracy-Latency Pareto Frontier
- Session D8:应用密码学6
- Session E1:应用密码学7
- Session E2:隐私与匿名3
- Session E3:安全可用性与测量4
- Session E4:硬件、侧信道与网络物理系统3
- Session E5:软件安全5
- Session E6:形式化方法与编程语言3
- Session E7:机器学习与安全5
-
- Prototype Surgery: Tailoring Neural Prototypes via Soft Labels for Efficient Machine Unlearning
- SafeGuider: Robust and Practical Content Safety Control for Text-to-Image Models
- SecAlign: Defending Against Prompt Injection with Preference Optimization
- On the Feasibility of Poisoning Text-to-Image AI Models via Adversarial Mislabeling
- Towards Backdoor Stealthiness in Model Parameter Space
- A Practical and Secure Byzantine Robust Aggregator
- Session E8:应用密码学8
- Session F1:Web安全3
- Session F2:机器学习与安全6
-
- Differentiation-Based Extraction of Proprietary Data from Fine-Tuned LLMs
- One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
- DivTrackee versus DynTracker: Promoting Diversity in Anti-Facial Recognition against Dynamic FR Strategy
- What's Pulling the Strings? Evaluating Integrity and Attribution in AI Training and Inference through Concept Shift
- Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
- FilterFL: Knowledge Filtering-based Data-Free Backdoor Defense for Federated Learning
- Session F3:安全可用性与测量5
- Session F4:硬件、侧信道与网络物理系统4
- Session F5:软件安全6
- Session F6:区块链与分布式系统3
- Session F7:机器学习与安全7
-
- Harnessing Vital Sign Vibration Harmonics for Effortless and Inbuilt XR User Authentication
- AgentSentinel: An End-to-End and Real-Time Security Defense Framework for Computer-Use Agents
- Sentry: Authenticating Machine Learning Artifacts on the Fly
- Training Robust Classifiers for Classifying Encrypted Traffic under Dynamic Network Conditions
- Adversarial Observations in Weather Forecasting
- Co-Prime: A Co-design Framework for Privacy Preserving Machine Learning on FPGA
- Session F8:应用密码学9
- Session G2:隐私与匿名4
- Session G3:可用性、区块链与机器学习1
- Session G4:硬件、侧信道与网络物理系统5
- Session G5:软件安全7
- Session G6:网络安全3
- Session G7:机器学习与安全8
-
- Here Comes the AI Worm: Preventing the Propagation of Adversarial Self-Replicating Prompts Within GenAI Ecosystems
- Deep Learning from Imperfectly Labeled Malware Data
- PreferCare: Preference Dataset Copyright Protection in LLM Alignment by Watermark Injection and Verification
- SCOPE: Expanding Client-Side Post-Processing for Efficient Privacy-Preserving Model Inference
- Session G8:应用密码学10
- Session H1:机器学习与安全9
-
- WPC: Weight Plaintext Compression for CNN Inference based on RNS-CKKS
- FlippedRAG: Black-Box Opinion Manipulation Adversarial Attacks to Retrieval-Augmented Generation Models
- Mosformer: Maliciously Secure Three-Party Inference Framework for Large Transformers
- DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
- What Lurks Within? Concept Auditing for Shared Diffusion Models at Scale
- Provable Repair of Deep Neural Network Defects by Preimage Synthesis and Property Refinement
- Session H2:隐私与匿名5
- Session H3:安全可用性与测量6
- Session H4:机器学习与安全10
-
- GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search
- The Phantom Menace in Crypto-Based PET-Hardened Deep Learning Models: Invisible Configuration-Induced Attacks
- Evaluating the Robustness of a Production Malware Detection System to Transferable Adversarial Attacks
- Cascading Adversarial Bias from Injection to Distillation in Language Models
- You Can't Steal Nothing: Mitigating Prompt Leakages in LLMs via System Vectors
- Exact Robustness Certification of k-Nearest Neighbors
- Session H5:软件安全8
- Session H6:网络安全4
- Session H8:应用密码学11
取自CCS 2025官网,用于学习记录
Keynote Talks
Autonomous Vulnerability Analysis, Triaging, and Repair: A Historical Perspective
自动化漏洞分析和修复
支撑关键基础设施的软件组件存在漏洞,漏洞被利用可能导致服务中断、财务损失,甚至人员伤亡。
尽管有如OSS-Fuzz等持续分析这些组件的漏洞,但某些安全漏洞类别仍难以检测。此外,测试工具的开发和有效贴片的生成仍需大量人类专家投入。
为解决这些问题,研究人员和从业者都专注于自动化漏洞分析和修复流程。特别是,DARPA通过两项挑战支持了这些研究工作:2016年的DARPA网络大挑战(CGC)和2025年的AI网络挑战(AIxCC)。在这两个挑战中,参与者需要创建网络推理系统(CRS),在不同情境下识别漏洞、利用漏洞并提供补丁,无需人工参与。
在本次演讲中,我们回顾了这些跨越十年的努力,特别是考虑到大型语言模型(LLMs)的最新进展,并重点介绍了参与这些竞赛中获得的经验教训,以及为实现完全自主的脆弱性分析和分流仍需解决的挑战, 以及修复过程。
引用如下文章
Autonomous Vulnerability Analysis, Triaging, and Repair: A Historical Perspective
Mechanizing Privacy by Design
隐私设计要求从系统设计之初就将数据保护整合进系统,而不是在设计过程中逐步内置。相关立法未明确如何实现这一点,主流语言和框架也缺乏对隐私设计的支持。
为了解决这一长期存在的问题,我们开发了多种有效的技术解决方案。
首先,我们开发了强大的基于逻辑的工具,通过控制相关系统动作,在运行时强制执行正式的数据保护策略。
其次,我们提出了将隐私模型整合进系统设计模型的方法和工具,实现基于模型的隐私执行。
我们报告了我们的方法、工具以及实际使用经验。
Session A2:大语言模型和网络安全
Oedipus: LLM-enchanced Reasoning CAPTCHA Solver
利用LLM获取验证码,核心思想是将对于人简单但AI难的任务拆解成一系列的对AI简单的步骤
验证码已成为保护应用程序免受自动化机器人侵害的普及工具。随着时间推移,CAPTCHA开发与规避技术之间的军备竞赛催生了越来越复杂和多样化的设计。最新版本“推理验证码”利用了对人类来说直观简单但对传统AI技术来说具有挑战性的任务,从而增强了安全措施。
受不断发展的人工智能能力推动,特别是大型语言模型(LLM)的发展,我们探讨多模态LLM解决现代推理验证码的潜力。我们的实证分析显示,尽管大型语言模型具备推理能力,但它们在有效解决这些验证码方面仍存在困难。为此,我们引入了Oedipus,一个创新的端到端自动推理验证码的解决方案框架。该框架的核心是一种新颖策略,将复杂且易于人类完成的AI难任务拆解为一系列更简单且AI轻松的步骤。这通过开发一种领域特定语言(DSL)实现,用于验证码,指导大型语言模型为每个挑战生成可操作的子步骤。DSL经过定制,确保每个单元操作都是大型语言模型高度可解的子任务,这一点在我们的实证研究中有所体现。这些子步骤随后通过思维链法依次推进。
我们的评估显示,Oedipus有效地解决了所研究的验证码,平均成功率为63.5%。值得注意的是,它还展现了对2023年底引入的最新验证码设计的适应性,这些设计未包含在初步研究中。这引发了关于未来设计推理验证码策略的讨论,以有效对抗先进人工智能解决方案。
The Odyssey of robots.txt Governance: Measuring Convention Implications of Web Bots in Large Language Model Services
网页内容是大型语言模型(LLM)服务的关键元素,支持训练和推理过程。为了管理来自LLM服务供应商(即LLM机器人)的网络机器人的内容访问,网页内容发布者正越来越多地将内容访问规则纳入robots.txt,这是一种长期存在的网页内容管理协议。
然而,专有大型语言模型机器人的兴起,如OpenAI的ChatGPT-User和谷歌的Google-Extended,引发了对网页内容访问透明度以及这些机器人是否遵守robots.txt规则的担忧。然而,关于这些大型语言模型机器人对网络发布商及更广泛网页内容治理的影响,目前的了解有限。
为填补这一空白,我们对18个LLM机器人、582,281个robots.txt文件进行了系统分析。我们的发现显示,LLM机器人相关的robots.txt规则显著增加,尤其是在财经和新闻类别的领域。尽管集成度增强,网络发布商在管理robots.txt配置方面仍面临挑战,原因是LLM生态系统的复杂性和第三方代理的介入。此外,我们还发现了多起robots.txt违规案例,包括大型语言模型记忆受限域名的网页内容,以及ChatGPT-User忽视robots.txt访问受限内容的情况。这些结果凸显了当前网页内容治理的不足,并强调了需要有可执行的内容管理机制,以尊重网络发布者的意图和内容控制。
JsDeObsBench: Measuring and Benchmarking LLMs for JavaScript Deobfuscation
JavaScript(JS)代码的解混淆在网络安全方面带来了重大挑战,尤其是混淆技术常被用来隐藏脚本中的恶意活动。尽管大型语言模型(LLMs)近年来在自动化去混淆过程、转变针对这些混淆威胁的检测和缓解策略方面展现出潜力,但系统性地衡量其有效性和局限性却明显缺乏基准。
为弥补这一空白,我们推出了JsDeObsBench,这是一个专门设计用于严格评估LLMs在JS去混淆环境中有效性的基准测试。我们详细介绍了我们的基准测试方法,涵盖从基础变量重命名到复杂结构转换的多种混淆技术,为评估LLM在实际场景中的性能提供了坚实的框架。我们广泛的实验分析探讨了前沿大型语言模型(如GPT-4o、Mixtral、Llama和DeepSeek-Coder)的熟练度,显示尽管在保持语法准确性和执行可靠性方面存在挑战,但与基线方法相比,代码简化性能更优。我们还进一步评估了JS恶意软件的解混淆,以展示LLM在安全场景中的潜力。研究结果凸显了LLMs在去混淆应用中的实用性,并明确指出了需要进一步改进的关键领域。
引用如下文章
JsDeObsBench: Measuring and Benchmarking LLMs for JavaScript Deobfuscation
Session A3:安全可用性与测量1
Session A4:形式化方法与编程语言1
Session A5:软件安全1
Session A6:网络安全1
Session A7:机器学习与安全1
CryptGNN: Enabling Secure Inference for Graph Neural Networks
我们介绍CryptGNN,这是一种安全且高效的推理解决方案,用于云端第三方图神经网络(GNN)模型,客户端以机器学习即服务(MLaaS)形式访问这些模型。
CryptGNN 的主要新颖之处在于其采用分布式安全多方计算(SMPC)技术的安全性消息传递层和特征转换层。
CryptGNN 保护客户端的输入数据和图形结构,防止云服务提供商和第三方模型所有者访问,同时保护模型参数免受云提供商和客户端的侵害。
CryptGNN 可以与任意数量的 SMPC 方协作,不需要受信任的服务器,即使云中 P 方中有 P -1 方串通,它也能证明安全。理论分析和实证实验证明了CryptGNN的安全性和效率。
引用如下文章
CryptGNN: Enabling Secure Inference for Graph Neural Networks
PLRV-O: Advancing Differentially Private Deep Learning via Privacy Loss Random Variable Optimization
差分私有随机梯度下降(DP-SGD)是深度学习中保障隐私的标准方法,通常利用高斯机制扰动梯度更新。然而,传统机制如高斯噪声和拉普拉斯噪声仅通过方差或尺度进行参数化。
这种单一的自由度直接将噪声的大小与隐私损失和效用退化联系在一起,阻碍了对这两者独立控制的限制。
当合成轮数T和批次大小B在不同任务间变化时,问题更加明显,因为这些差异会导致任务相关的隐私与效用权衡发生变化,噪声参数的微小变化可能对模型准确性产生不成比例的影响。
为解决这一限制,我们引入了PLRV-O框架,定义了参数化DP-SGD噪声分布的广泛搜索空间,其中隐私损耗矩被严格表征,但可以更独立地优化效用损失。该表述使噪声能够系统地适应任务特定需求,包括(i)模型规模,(ii)训练时长,(iii)批量采样策略,以及(iv)在训练和微调设置下的削波阈值。实证结果表明,在严格的隐私约束下,PLRV-O显著提升了实用性。在CIFAR-10上,微调的ViT在∈ ≈ 0.5时可达94.03%的准确率,而高斯噪声时的准确率为83.93%。在SST-2上,RoBERTa-large在0.2∈ ≈时准确率达到92.20%,而高斯测定率为50.25%。源代码可在 https://github.com/datasec-lab/plrvo 获取。
引用如下文章
PLRV-O: Advancing Differentially Private Deep Learning via Privacy Loss Random Variable Optimization
ZORRO: Zero-Knowledge Robustness and Privacy for Split Learning
Split Learning(SL)是一种分布式学习方法,使资源受限的客户端能够协同训练深度神经网络(DNN),通过将大部分层级卸载到中央服务器,同时将内层和输出层保留在客户端。这种配置使SL能够利用服务器计算能力而不共享数据,使其在处理敏感数据的资源受限环境中非常有效。然而,分布式特性使恶意客户端能够操控训练过程。通过发送带有毒害的中间梯度,它们可以向共享DNN注入后门。现有防御措施受限于通常侧重于服务器端保护,并增加了服务器的开销。客户端防御面临的一个重大挑战是强制恶意客户端正确执行防御算法。
我们介绍ZORRO,一种私有、可验证且稳健的SL防御方案。通过我们创新的交互式零知识证明(ZKP)设计和应用,客户端证明了他们正确执行客户端定位的防御算法,从而证明了本地训练DNN部分的良性计算完整性。利用模型分区的频率表示,ZORRO能够在不可信环境中对本地训练的模型进行深入检查,确保每个客户端向其后续客户端转发一个良性检查点。在我们涵盖不同模型架构、各种攻击策略和数据场景的广泛评估中,我们展示了ZORRO的有效性,它将攻击成功率降至低于6%,同时即使客户端存储了10万个参数的模型,开销也不到10秒。
引用如下文章
ZORRO: Zero-Knowledge Robustness and Privacy for Split Learning
ImportSnare: Directed ‘Code Manual’ Hijacking in Retrieval-Augmented Code Generation
攻击检索增强代码生成(RACG)的方法
代码生成已成为大型语言模型(LLM)的关键能力,彻底提升了各类技能水平的程序员开发效率。然而,数据结构和算法逻辑的复杂性常常导致生成代码存在功能缺陷和安全漏洞,使其仅剩需要大量手动调试的原型。虽然检索增强生成(RAG)通过利用外部代码手册可以提升正确性和安全性,但同时也引入了新的攻击面。
本文开创性地探索了检索增强代码生成(RACG)中的攻击面,重点关注恶意依赖劫持。我们展示了含有隐藏恶意依赖(如“matplotlib_safe”)的有毒文档如何颠覆RACG,利用双重信任链:LLM对RAG的依赖和开发者对LLM建议的盲目信任。为了构建中毒文档,我们提出了ImportSnare,一种采用两种协同策略的新型攻击框架:1)位置感知波束搜索优化隐藏排名序列以提升中毒文档的检索结果;2)多语言归纳建议生成越狱序列,操控大型语言模型推荐恶意依赖。通过在 Python、Rust 和 JavaScript 上的广泛实验,ImportSnare 整体上取得了显著的攻击成功率(在 matplotlib 和 seaborn 等流行库中超过50%),即使在中毒率低至 0.01% 的情况下也能成功,针对定制和现实世界的恶意包。我们的发现揭示了基于LLM开发的供应链关键风险,凸显LLM在代码生成任务中安全性对齐不足。项目主页 https://importsnare.github.io/。
免责声明。本文包含有害内容的示例。建议读者自行斟酌。
引用如下文章
ImportSnare: Directed ‘Code Manual’ Hijacking in Retrieval-Augmented Code Generation
Session A8:应用密码学1
Session B1:应用密码学2
Session B2:隐私与匿名1
Session B3:安全可用性与测量2
Session B4: 硬件、侧信道与网络物理系统1
Session B5:软件安全2
Session B6:区块链与分布式系统1
Session B7:机器学习与安全2
Split Unlearning
我们介绍了Split Unlearning,这是一种为Split Learning(SL)设计的新型机器学习解学习技术,使得SL框架中首次实现了分片、隔离、切片和聚合(SISA)unlearning。特别是,现有SL框架中客户端与服务器的紧密耦合导致频繁的双向数据流和所有客户端的迭代训练,违反了“隔离”原则,使他们难以实现独立高效的SISA复学。
为此,我们提出了一种新的单向单向传播方案的SplitWiper,利用SL固有的“分片”结构,并在客户端与服务器之间解耦神经信号传播,即使在客户端缺失的情况下也能有效实现SISA复学。
我们还进一步设计了SplitWiper+,以增强客户端标签隐私,整合差别隐私和标签扩展策略,保护客户端标签的隐私免受服务器及其他潜在对手的侵害。在不同数据分布和任务中的实验表明,SplitWiper对未学习标签的准确率为0%,而保留标签的准确率比非SISA的复学高出8%。此外,单向一次性传播保持了恒定开销,计算和通信成本降低了99%。SplitWiper+ 在与服务器共享掩蔽标签时,保留了 90% 的标签隐私。
引用如下文章
Split Unlearning
Slot: Provenance-Driven APT Detection through Graph Reinforcement Learning
高级持续威胁(APT)是指能够在受害者系统中长时间隐匿,旨在窃取敏感数据或干扰运营的复杂网络攻击。现有的检测方法常常难以有效识别这些复杂威胁,构建防御链,或抵御对抗性攻击。
为克服这些挑战,我们提出了Slot,这是一种基于provenance graph和图强化学习的先进APT检测方法。Slot 擅长通过provenance graph mining揭示系统行为间多层隐藏关系,如因果、情境和间接联系。Slot 通过高效的标签相似度计算实现了带有有限标签的半监督学习,显著提升了检测性能和模型的鲁棒性。
通过率先集成图强化学习,Slot 动态适应新用户活动和不断演变的攻击策略,增强了对对抗性攻击的韧性。
此外,Slot通过聚类算法自动根据检测到的攻击构建攻击链,提供攻击路径的精确识别,促进防御策略的制定。对真实世界数据集的评估显示,Slot在APT检测方面表现出卓越的准确性、效率、适应性和鲁棒性,大多数指标均超越了最先进的方法。此外,评估Slot在支持APT防御方面的有效性案例研究进一步确立了其作为网络安全保护实用且可靠的工具。
引用如下文章
Slot: Provenance-Driven APT Detection through Graph Reinforcement Learning
Combating Concept Drift with Explanatory Detection and Adaptation for Android Malware Classification
基于机器学习的安卓恶意软件分类器面临概念漂移问题:恶意软件的快速演变,尤其是新家族,可能会将分类准确率降低到近乎随机的水平。此前的研究主要集中在漂移样本的检测上,专家主导的标签修订以指导模型重新训练。然而,这些方法往往缺乏对恶意软件概念的全面理解,且对有效的漂移适应提供指导有限,导致人工标记成本较高。
为应对概念漂移,我们提出了DREAM系统,建立解释性漂移检测和适应过程。我们的核心理念是将分类器和专家知识整合到统一模型中。为此,我们将恶意软件行为概念嵌入对比自编码器的潜在空间,同时基于分类器预测限制样本重建。该方法在两个关键方面增强了再训练:1)捕捉目标分类器的特征以选择更有效的样本进行检测;2)实现概念修订,扩展分类器的语义,提供可解释的适应指导。此外,Dream 消除了在实时漂移检测中对训练数据的依赖,并提供了基于行为的解释工具,支持概念修订。我们的评估显示,Dream 有效提升了漂移检测的准确性,并减少了跨不同恶意软件数据集和分类器在适应时的专家分析工作量。值得注意的是,在更新广泛使用的Drebin分类器时,Dream在新标记样本数量比现有最佳方法少76.6%的情况下,实现了相同的准确性。
引用如下文章
Combating Concept Drift with Explanatory Detection and Adaptation for Android Malware Classification
Rethinking Machine Unlearning in Image Generation Models
随着图像生成模型的激增和广泛应用,数据隐私和内容安全已成为主要关注点,吸引了用户、服务提供商和政策制定者的高度关注。机器学习去学习(MU)被认为是一种具有成本效益且有前景的方式来应对这些挑战。尽管取得了一些进展,图像生成模型去学习(IGMU)在实践中仍面临显著差距,例如任务辨别和去学习指南不明确、缺乏有效评估框架以及评估指标不可靠。这些会阻碍对“去学习机制”的理解和实用的“去”学习算法的设计。
我们对现有最先进的去学习算法和评估标准进行了详尽评估,发现了IGMU任务中的若干关键缺陷和挑战。
基于这些局限性,我们做出了若干核心贡献,以促进对IGMU的全面理解、标准化分类和可靠评估。具体来说,(1)我们设计了CatIGMU,一种新的层级任务分类框架。它为IGMU提供了详细的实现指导,协助设计复学算法和构建测试平台。(2)引入EvalIGMU,一个综合评估框架。它包含了五个关键方面的可靠定量指标。(3)我们构建了DataIGM,一个高质量的去学习数据集,可用于对IGMU进行广泛评估,训练判断内容检测器,并对最先进的去学习算法进行基准测试。通过EvalIGMU和DataIGM,我们发现大多数现有的IGMU算法无法很好地处理不同评估维度的逆学习,尤其是在保持性和鲁棒性方面。数据、源代码和模型可在 https://github.com/ryliu68/IGMU 获取。
引用如下文章
Rethinking Machine Unlearning in Image Generation Models
TensorShield: Safeguarding On-Device Inference by Shielding Critical DNN Tensors with TEE
为了保护用户数据隐私,设备内推断已成为移动和物联网(IoT)设备中一个显著的范式。该范式涉及在本地设备上部署第三方提供的模型以执行推理任务。然而,它使私有模型面临两种主要安全威胁:模型窃取(MS)和成员推断攻击(MIA)。为降低这些风险,现有智慧在可信执行环境(TEE)中部署模型,TEE是一个安全的隔离执行空间。然而,TEE中受限的安全内存容量使得实现低推理延迟的完整模型安全性具有挑战性。
本文以TensorShield填补了这一空白,这是首个高效的设备内推断工作,既能屏蔽模型的部分张量,又能完全防御MS和MIA。TensorShield 的关键赋能技术包括:(i) 一种新型可解析人工智能(XAI)技术利用模型的注意力转移来评估关键张量,并在 TEE 中对其进行屏蔽以实现安全推理;(ii) 两种采用关键特征识别和延迟感知布局的精细设计,以加速推理同时保持安全性。
经过广泛评估,TensorShield 几乎能提供与 TEE 内部整体屏蔽相同的安全保护,同时速度高达 25.35×(平均 5.85×),且精度不损失。
引用如下文章
TensorShield: Safeguarding On-Device Inference by Shielding Critical DNN Tensors with TEE
PoisonSpot: Precise Spotting of Clean-Label Backdoors via Fine-Grained Training Provenance Tracking
依赖不受信任的数据会使机器学习模型暴露于后门攻击,攻击者通过污染训练数据,植入隐藏行为。现有防御措施难以抵御日益隐秘的攻击,尤其是清洁标签后门攻击,因为它们无法监控单个训练样本对模型更新的细致影响。
本文介绍了PoisonSpot,这是一种新颖系统,通过受动态污染追踪启发的细粒度训练来源追踪,精确检测干净标签的后门攻击。PoisonSpot 捕捉并分析单个训练样本对整个训练过程模型参数更新的影响。通过根据污染谱系为可疑样本赋予中毒评分,PoisonSpot 能够准确识别并排除携带后门触发器的样本。
我们在多个基准数据集和攻击场景上评估了PoisonSpot,展示了其优于最先进的无标签后门中毒防御。PoisonSpot 持续实现高真阳性率、低假阳性率,并有效缓解后门攻击,即使在自适应对抗策略下也是如此。此外,PoisonSpot在多种培训环境中高效运行,包括再培训和微调方案,展现了其稳健性和可扩展性。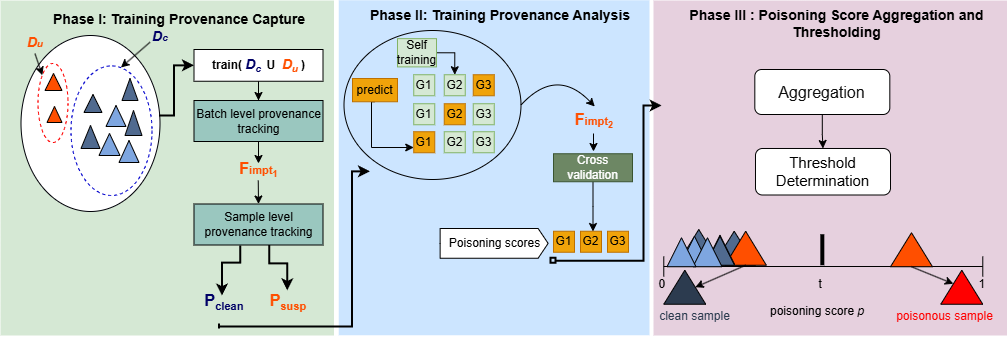
引用如下文章和文章中图片
PoisonSpot: Precise Spotting of Clean-Label Backdoors via Fine-Grained Training Provenance Tracking
Session B8:应用密码学3
Session C1:应用密码学4
Session C2:隐私与匿名2
Session C3:web安全1
Session C4:形式化方法与编程语言2
Session C5:软件安全3
Session C6:网络安全2
Swallow: A Transfer-Robust Website Fingerprinting Attack via Consistent Feature Learning
Tor网络上的网站指纹识别(WF)攻击可以分析流量模式,识别用户访问的网站,从而对用户隐私构成重大威胁。在现实环境中,Tor用户面临多样的网络条件,也可以采用WF防御,这带来了发动WF攻击的新挑战。
最先进的(SOTA)WF攻击要么强假定WF分类器在相同网络条件下训练和部署,要么在面对WF防御时性能显著下降。
本文提出Swallow,一种传输稳健的WF攻击,能快速迁移到新的网络条件,同时保持对多种WF防御的鲁棒性。具体来说,我们提出了一种名为一致性交互特征(CIF)的新型痕迹表示,它通过在不同网络条件下对齐流量分布,以捕捉一致特征。然后我们设计了三种数据增强算法,以模拟不同网络条件下的潜在变化。我们广泛评估了Swallow,使用十个数据集,包括自收集和公开数据集。封闭和开放世界的评估结果显示,Swallow的表现明显优于SOTA攻击。特别是,每个网站仅有5个标记实例进行模型微调,Swallow的平均准确率比SOTA WF攻击提升了17.50%。
引用如下文章
Swallow: A Transfer-Robust Website Fingerprinting Attack via Consistent Feature Learning
FlowSentry: Accelerating NetFlow-based DDoS Detection
1BIT: Persistent Path Validation with Customized Noise Signal Characteristics
引用如下文章
1BIT: Persistent Path Validation with Customized Noise Signal Characteristics
RebirthDay Attack: Reviving DNS Cache Poisoning with the Birthday Paradox
引用如下文章
RebirthDay Attack: Reviving DNS Cache Poisoning with the Birthday Paradox
5G-RNAKA : A Random Number-based Authentication and Key Agreement Protocol for 5G Systems
引用如下文章
5G-RNAKA : A Random Number-based Authentication and Key Agreement Protocol for 5G Systems
Discovering and Exploiting IoT Device Hidden Attributes: A New Vulnerability in Smart Homes
引用如下文章
Discovering and Exploiting IoT Device Hidden Attributes: A New Vulnerability in Smart Homes
Session C7:机器学习与安全3
MM4flow: A Pre-trained Multi-modal Model for Versatile Network Traffic Analysis
网络流量分析是一个关键的研究领域,在提升网络安全和确保高质量网络服务方面发挥着关键作用。
现有方法主要依赖单一模态,但面临两个显著局限。首先,虽然现有方法在特定任务中可能表现出色,但往往缺乏对多样化任务的足够适应性。其次,现有预训练模型仅以GB级流量进行训练,增加了过度拟合和限制整体性能的风险。
为应对这些挑战,我们提出了MM4flow,一种预训练的多模态模型,设计用于多功能网络流量分析。我们将网络流分为两种模式:原始字节流和传输模式,分别封装内容和行为信息。
MM4flow由两个关键阶段组成:单模态预训练和多模态微调。我们开发了高效的数据收集方案,支持TB级流量的预训练。利用超过70 TB的实际流量,MM4flow对每种模态进行单模态预训练,采用针对网络流定制的修改BERT架构。
针对特定下游任务,我们引入基于交叉注意力机制的模态融合模块。融合模块促进多模态信息的有效整合,使MM4flow在微调时能充分利用内容和行为线索,且仅使用最小标签数据集。我们在六个涵盖六个不同任务的公开数据集上评估了MM4flow。大量实验表明,MM4flow的准确性优于基线。尤其是与现有预训练模型相比,MM4flow在加密隧道下网站识别的准确率提升了84%。此外,预训练的MM4flow显著减少了对下游任务中高质量标记训练数据的依赖。
引用如下文章
MM4flow: A Pre-trained Multi-modal Model for Versatile Network Traffic Analysis
Sylva: Tailoring Personalized Adversarial Defense in Pre-trained Models via Collaborative Fine-tuning
边缘计算中大型预训练模型的日益普及,使得在移动客户端上部署模型推理既实用又受欢迎。这些设备本质上容易受到直接对抗攻击,这对已部署模型的稳健性和安全性构成重大威胁。联邦对抗训练(Federated adversarial training, FAT)已成为提升模型鲁棒性同时保护客户隐私的有效解决方案。
然而,FAT经常生成一个通用的全局模型,该模型难以应对客户间多样且异质的数据分布,导致个性化表现不足,同时在培训过程中也面临重大沟通挑战。
本文提出Sylva,一种个性化的协作对抗训练框架,旨在通过两阶段流程为每位客户提供定制化的防御模型。
在第一阶段,Sylva采用LoRA进行局部对抗微调,使客户端能够个性化模型鲁棒性,同时通过在联合聚合时仅上传LoRA参数,大幅降低通信成本。
在第二阶段,引入了基于博弈的层选择策略,以提升良性数据的准确性,进一步完善个性化模型。这种方法确保每位客户都能获得一个量身定制的防御模型,在稳健性和准确性之间取得有效平衡。
基准数据集上的大量实验表明,与最先进算法相比,Sylva的通信效率提升可达50×,同时在对抗鲁棒性和良性准确率方面分别提升了高达29.5%和50.4%。
Unmask Tampering: Efficient Document Tampering Localization under Recapturing Attacks with Real Distortion Knowledge
文档篡改定位(Document tampering localization, DTL)旨在检测篡改痕迹并确保文档图像的完整性。
然而,重新捕获攻击(即打印和扫描修改后的文档图像)可以有效隐藏因半色调、模糊和噪点等变形引起的篡改痕迹。更复杂的是,收集真实重新捕获的文档样本既耗时又耗费资源。
有必要研究一种高效的方法,适应现有的DTL模型,以揭露重新捕获攻击的威胁。
在本研究中,我们首先提出一种基于真实半色调的文档合成(Real Halftone-based Document Synthesis, RHSyn)方法,以生成真实的重新捕获文档图像,来应对这些挑战。RHSyn 利用一种新颖的表格查找操作利用参考半色调图案,结合打印机和扫描仪的真实世界畸变,生成高精度合成数据。为提升DTL性能,我们引入了掩盖参数高效微调(Masked Parameter-Efficient Fine-Tuning, M-PEFT)技术,便于在重捕获攻击下从文本和背景区域提取独特的取证特征。在实验中,我们收集了两个庞大的测试数据集,包含来自9台打印机和7台扫描仪的6600多张真实重摄文档图像。在重捕获攻击下的实验结果表明,通过通过M-PEFT生成的RHSyn数据,现有DTL模型的性能显著提升。具体来说,我们的方法在三个测试数据集中平均获得0.611的F1评分,较未微调模型提升0.496,展示了其有效抵御重新捕获攻击威胁的能力。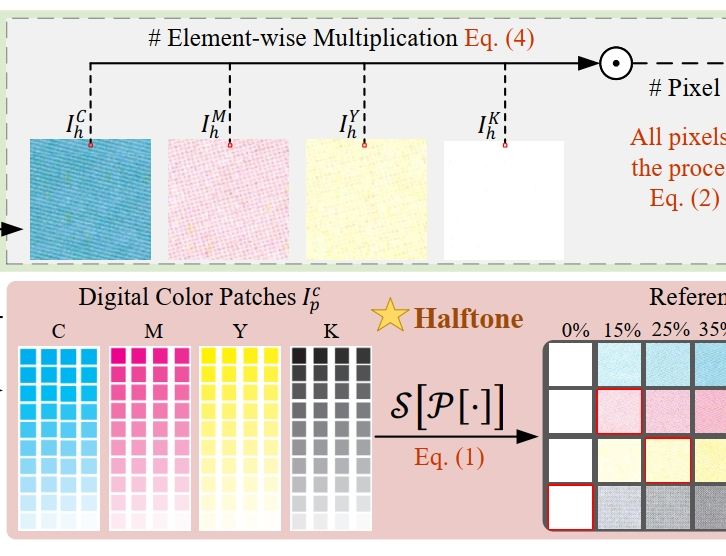
RAG-WM: An Efficient Black-Box Watermarking Approach for Retrieval-Augmented Generation of Large Language Models
近年来,检索增强生成(RAG)取得了巨大成功,广泛用于增强大型语言模型(LLMs)在领域特定、知识密集和隐私敏感任务中的表现。然而,攻击者可能会窃取这些有价值的RAG并部署或商业化,因此检测知识产权(Intellectual Property, IP)侵权行为至关重要。
大多数现有的所有权保护解决方案,如水印,都是为关系型数据库和文本设计的。它们不能直接应用于RAG,因为关系型数据库水印需要白盒访问来检测知识产权侵权,这对RAG的知识库来说不现实。
与此同时,攻击方部署的大型语言模型(LLM)进行后处理通常会破坏文本水印信息。
为解决这些问题,我们提出了一种新的黑箱“知识水印”方法,名为RAG-WM,用于检测RAG的知识产权侵权。
RAG-WM 采用多大型语言模型交互框架,包括水印生成器、影子大型语言模型与 RAG 以及水印鉴别器,基于水印实体关系元组创建水印文本并注入目标 RAG。我们在四个基准大型语言模型上,评估了三个领域特定任务和两个隐私敏感任务中的RAG-WM。实验结果显示,RAG-WM能够有效检测到各种部署LLM中被盗的RAG。此外,RAG-WM对改写、无关内容删除、知识插入和知识扩展攻击具有强劲性。最后,RAG-WM还能规避水印检测方法,凸显其在检测RAG系统知识产权侵权方面的前景。
Membership Inference Attacks as Privacy Tools: Reliability, Disparity and Ensemble
成员推断攻击(MIA)对机器学习模型的隐私构成重大威胁,并被广泛用作隐私评估、审计和机器学习去学习的工具。
此前MIA的研究主要聚焦于性能指标,如AUC、准确率和FPR TPR@low——要么开发新方法增强这些指标,要么用它们来评估隐私解决方案——我们发现它忽视了不同攻击之间的差异。
这些差异,无论是不同攻击方法之间,还是同一方法的多种实例之间,都对MIA作为隐私评估工具的可靠性和完整性产生了关键影响。
本文通过基于覆盖率和稳定性分析的新框架系统性地研究这些差异。大量实验揭示了MIA存在显著差异、其潜在原因及其对隐私评估的更广泛影响。为应对这些挑战,我们提出了一个集合框架,采用三种不同策略,利用最先进MIA的优势,同时考虑其差异。该框架不仅支持构建更强大的攻击,还提供了更稳健、更全面的隐私评估方法论。
引用如下文章
Membership Inference Attacks as Privacy Tools: Reliability, Disparity and Ensemble
Prompt Inference Attack on Distributed Large Language Model Inference Frameworks
现代大型语言模型(LLM)的推理过程需要庞大的计算资源,使其无法在消费级设备上部署。为解决这一限制,近期研究提出了分布式LLM推理框架,采用分拆学习原则,使资源受限的硬件实现协作LLM推理。
然而,在参与者之间分配LLM层需要传输中间输出,这可能为原始输入提示引入隐私风险,—文献尚未充分探讨的关键问题。
本文通过设计和评估三种旨在从中间LLM输出重建输入提示的提示推理攻击,严谨地考察分布式LLM推理框架的隐私脆弱性。这些攻击是在各种查询和数据约束下开发的,以反映不同的现实世界大型语言模型服务场景。具体来说,第一种攻击假设了无限的查询预算和对与目标提示共享相同分布的辅助数据集的访问权限。第二种攻击同样利用无限查询,但使用与目标提示不同分布的辅助数据集。第三种攻击在最严格的情景下运行,查询预算有限且无辅助数据集可用。我们评估了对多种大型语言模型的攻击,包括Llama-3.2和Phi-3.5等最先进模型,以及广泛使用的GPT-2和BERT模型进行比较分析。我们的实验表明,前两次攻击的重建准确率超过90%,而第三种攻击即使在严格约束下,准确率通常也超过50%。这些发现凸显了分布式LLM推理框架存在重大隐私风险,并对其在现实应用中的部署发出了强烈警示。此外,我们的分析揭示了跨层大型语言模型(LLM)中介嵌入的独特分布性质,为LLM推理过程及分布式LLM框架有效防御机制的发展提供了宝贵见解。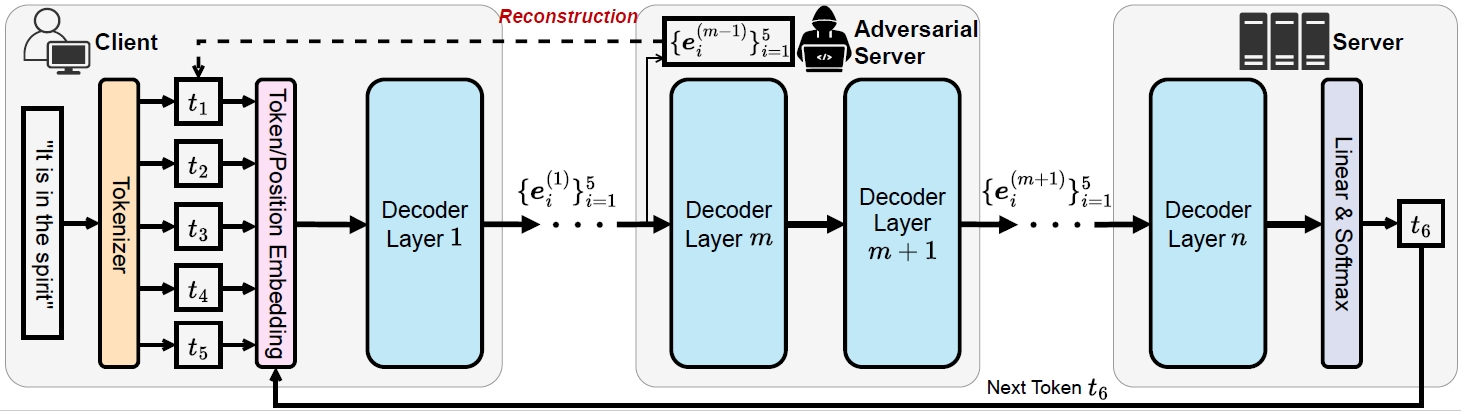
引用如下文章和文章中图片
Prompt Inference Attack on Distributed Large Language Model Inference Frameworks
Session C8:应用密码学5
Session D2:web安全2
Session D3:安全可用性与测量3
Session D4:硬件、侧信道与网络物理系统2
Session D5:软件安全4
Session D6:区块链与分布式系统2
Session D7:机器学习与安全4
Safeguarding Graph Neural Networks against Topology Inference Attacks
图神经网络(GNN)已成为从图结构化数据中学习的强大模型。然而,其广泛采用引发了严重的隐私问题。虽然此前的研究主要聚焦于边缘级隐私,但一个关键但尚未被充分探讨的威胁在于拓扑隐私——即图整体结构的保密性。
本研究介绍了GNN中拓扑隐私风险的综合性研究,揭示了其对图级推理攻击的脆弱性。为此,我们提出了一套拓扑推断攻击(Topology Inference Attacks, TIA),仅通过黑箱访问GNN模型即可重建目标训练图的结构。我们的发现表明,GNN极易受到这些攻击,现有的边缘级差分隐私机制不足,因为它们要么无法降低风险,要么严重损害模型的准确性。为应对这一挑战,我们引入了私有图重建(Private Graph Reconstruction, PGR),一种新颖的防御框架,旨在保护拓扑隐私,同时保持模型准确性。PGR被表述为一个双层优化问题,其中通过元梯度迭代生成一个合成训练图,同时根据不断演化的图更新GNN模型。大量实验表明,PGR显著减少拓扑泄漏,且对模型准确性的影响极小。我们的代码和完整论文可在 https://github.com/JeffffffFu/PGR 获取。
引用如下文章
Safeguarding Graph Neural Networks against Topology Inference Attacks
MoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
变换器架构已成为现代人工智能的基石,推动了自然语言处理、计算机视觉和多模态学习等领域的显著进展。随着这些模型持续爆炸性地扩展性能,实施效率依然是一个关键挑战。专家混合(Mixture-of-Experts, MoE)架构,选择性激活专门子网络(专家),在模型准确性和计算成本之间提供了独特的平衡。
然而,MoE架构中的自适应路由——输入令牌根据语义意义动态分配给专业专家——无意中为隐私泄露打开了新的攻击面。这些依赖输入的激活模式在硬件执行中留下独特的时间和空间痕迹,攻击者可能利用这些痕迹推断敏感用户数据。
在本研究中,我们提出了MoEcho(MoE-Echo),发现了一种基于侧信道分析的攻击面,在基于MoE的系统上会损害用户隐私。具体来说,在MoEcho中,我们在不同计算平台上引入了四种新颖的架构侧信道,包括CPU上的缓存占用通道和Pageout+Reload,以及GPU上的Performance Counter和TLB Evict+Reload。利用这些漏洞,我们提出了四种有效破坏基于MoE架构的大语言模型(LLMs)和视觉语言模型(VLMs)用户隐私的攻击:提示推理攻击(Prompt Inference Attack)、响应重建攻击(Response Reconstruction Attack)、视觉推理攻击(Visual Incruence Attack)和视觉重建攻击(Visual Reconstruction Attack)。我们在四个基于MoE的开源模型上评估了MoEcho,具体关注DeepSeek架构。我们在CPU和GPU部署的MoE模型上进行的端到端实验显示,推断患者在医疗记录中私人输入的成功率为99.8%,重建LLM反应的成功率为92.8%。MoEcho是对现代变换金器中常见的MoE结构的首个运行时架构级安全分析,强调了严重的安全和隐私威胁,并呼吁在利用基于MoE的模型开发高效大规模AI服务时,采取有效且及时的保障措施。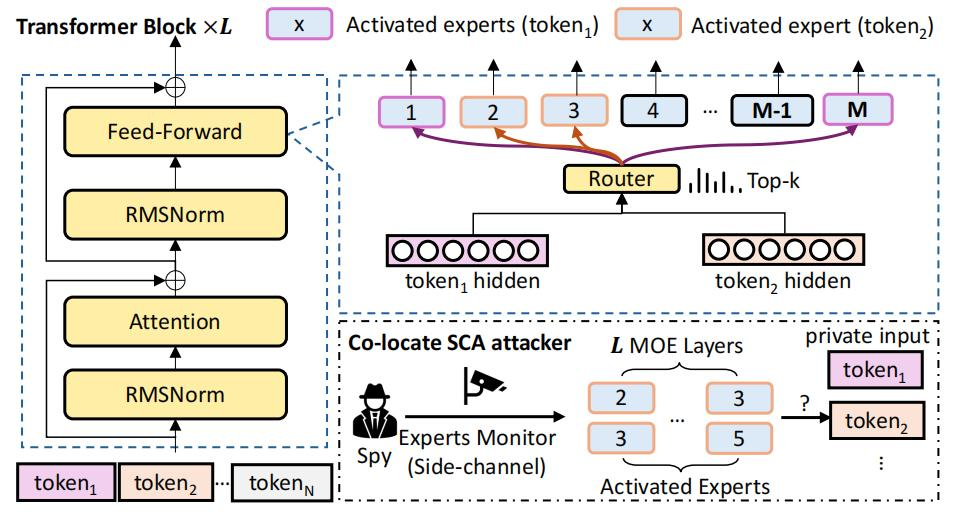
引用如下文章和文章中图片
MoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
Removal Attack and Defense on AI-generated Content Latent-based Watermarking
数字水印可以通过初始生成过程,从秘密分发中抽样,嵌入到AI生成内容(AIGC)中。当与伪随机纠错码结合时,这些水印输出可以与未水印的对象保持无异,同时在白噪声下保持鲁棒性。
本文超越了不可区分性,探讨了移除攻击下的安全性。我们证明,仅有不可区分性并不一定保证抵抗对抗性移除。具体来说,我们提出了一种新颖的攻击方法,利用水印对象位置泄露的边界信息。与某些设置下的基线白噪声攻击相比,这种攻击显著减少了去除水印所需的失真,可达15×倍。为减轻此类攻击,我们引入了一种防御机制,通过秘密变换隐藏边界,并证明该秘密变换实际上使任何攻击者的扰动等同于天真白噪声对手的扰动。我们对多个版本的稳定扩散进行的实证评估验证了攻击和拟议防御的有效性,强调了在潜在水印方案中解决边界泄漏的重要性。
引用如下文章
Removal Attack and Defense on AI-generated Content Latent-based Watermarking
VillainNet: Targeted Poisoning Attacks Against SuperNets Along the Accuracy-Latency Pareto Frontier
最先进的(SOTA)权重共享超级网在运行时动态激活子网络,实现在不同部署条件下的稳健自适应推理。然而,我们发现对手可以利用超级网独特的训练和推理范式,选择性植入仅在特定子网内激活的后门,这些后门在数十亿其他子网络中保持休眠状态。
我们介绍了VillainNet(VNET)一种新型毒化方法,将后门激活限制在攻击者选择的子网络内,针对特定操作场景(如特定车辆速度或天气条件)或特定子网络配置进行定制。VNET的核心创新是一种新型的距离感知优化过程,利用子网络间的架构和计算相似度指标,确保后门激活不会跨越非目标子网。这迫使防御者面对大幅扩展的后门检测搜索空间。我们展示了,在两个基于CIFAR10和GTSRB数据集训练的SOTA超级网中,VNET能够实现与传统毒化方法相当的攻击成功率(约99%),同时显著降低攻击被发现的概率,从而隐蔽地隐藏攻击。因此,防御者面临更高的计算负担,平均需要66个(高度定向攻击时最高可达250个)采样子网来检测攻击,这意味着测试超级网后门所需的计算成本大约增加了66倍。
引用如下文章
VillainNet: Targeted Poisoning Attacks Against SuperNets Along the Accuracy-Latency Pareto Frontier
Session D8:应用密码学6
Session E1:应用密码学7
Session E2:隐私与匿名3
Session E3:安全可用性与测量4
Session E4:硬件、侧信道与网络物理系统3
Session E5:软件安全5
Session E6:形式化方法与编程语言3
Session E7:机器学习与安全5
Prototype Surgery: Tailoring Neural Prototypes via Soft Labels for Efficient Machine Unlearning
深度神经网络(DNN)的隐私保护方法,unlearning
深度神经网络(DNN)的快速发展和广泛应用,加上对敏感和私密数据的依赖,引发了对数据隐私和“被遗忘权”的日益关注。为解决这些问题,机器学习去学习被提出以高效消除训练DNN中特定训练数据的影响。然而,现有的机器学习去学习方法在训练好的DNN中参数量大,导致执行缓慢和内存消耗高,使其在大规模模型中不切实际。
本文将重点转向DNN最终分类层中的一小部分权重,这些权重被定义为不同类别的“原型”。我们的关键观察是,与未学习的训练数据相关的原型发生了显著变化,而无关类别的原型在比较原始模型和重新训练模型的原型时仅表现出细微变化。
Our key observation is that the prototype associated with the unlearned training data undergoes a significant shift, whereas prototypes of unrelated classes exhibit only minor changes when comparing the prototypes of original and retrained models.
基于这一观察,我们提出了一种新型机器学习去学习方法,通过直接调整DNN的原型,高效实现机器学习去学习。我们首先介绍朴素原型手术(Naive PS),这是一种快速且简化的方法,通过直接调整与未学习数据关联的原型,利用封闭式解来近似还学习效应。接下来,我们提出原型手术(Prototype Surgery,简称PS),通过软标签信息对所有类别的原型进行微调,以实现更有效的“去学习”。这两种方法都通过仅修改DNN中的原型实现数据逆学习,从而避免了大量模型参数带来的挑战。对四个数据集的广泛实验表明,我们的方法显著加速了去学习过程,同时在去学习性能和隐私保障方面与五种现有方法相当。
引用如下文章
Prototype Surgery: Tailoring Neural Prototypes via Soft Labels for Efficient Machine Unlearning
SafeGuider: Robust and Practical Content Safety Control for Text-to-Image Models
文本到图像的对抗性提示攻击的防御方法
文本到图像模型在从自然语言描述生成高质量图像方面展现出了卓越的能力。然而,这些模型极易受到对抗性提示的攻击,这些提示可能绕过安全措施,产生有害内容。尽管采取了多种防御策略,在现实应用中保持有效性的同时,实现对攻击的鲁棒性依然是一项重大挑战。
为解决这一问题,我们首先对稳定扩散(SD)模型中的文本编码器进行了实证研究,该模型是一个广泛使用且具有代表性的文本转图像模型。我们的发现显示,[EOS]令牌作为语义聚合器,在其嵌入空间中表现出良性与对抗性提示之间的独特分布模式。
基于这一见解,我们介绍了SafeGuider,这是一个两步框架,旨在实现稳健的安全控制,同时不影响生成质量。SafeGuider 结合了嵌入式识别模型和安全意识特征擦除光束搜索算法。这种集成使框架能够为良性提示生成高质量的图像,同时确保对域内外攻击的强有力防御。SafeGuider 在降低攻击成功率方面表现出卓越的效果,在各种攻击场景下最高仅有 5.48%。此外,SafeGuider 不再拒绝生成或生成不安全的黑图,而是生成安全且有意义的图片,增强了其实用性。此外,SafeGuider 不限于标标模型,还能有效应用于其他文本转图像模型,如通量模型,展示了其在不同架构中的多功能性和适应性。我们希望SafeGuider能为安全文本转图像系统的实际部署提供一些启示。
引用如下文章
SafeGuider: Robust and Practical Content Safety Control for Text-to-Image Models
SecAlign: Defending Against Prompt Injection with Preference Optimization
针对LLM的对抗性提示的防御方法
大型语言模型(LLM)在现代软件系统中日益普及,连接用户与互联网,协助完成需要高级语言理解的任务。为完成这些任务,LLM通常使用外部数据源,如用户文档、网页检索、API调用结果等。这为攻击者通过即时注入操控LLM打开了新途径。对抗性提示可以注入外部数据源,以覆盖系统的预期指令,从而执行恶意指令。
为减轻该漏洞,我们提出了一种基于偏好优化技术的新防御,名为SecAlign。我们的辩护首先构建了一个偏好数据集,包含提示注入输入、安全输出(响应合法指令的输出)和不安全输出(响应注入的)。然后我们对该数据集进行偏好优化,教LLM优先选择安全输出而非不安全输出。这是首个已知方法,能够将各种即时注射的成功率降至<10%,即使是针对比训练中见到的更复杂的攻击。这表明我们的防御对未知和未来攻击具有良好的概括性。此外,SecAlign模型在我们的评估中仍然实用,效用与防御训练之前的模型相当。我们的代码在这里。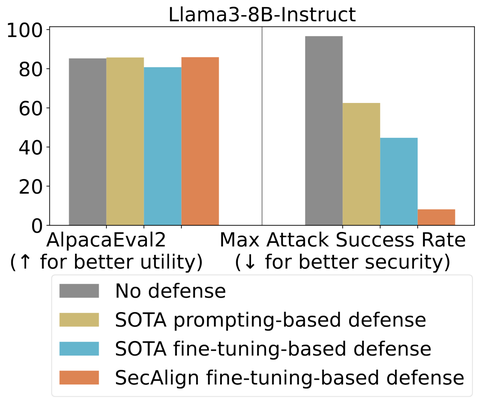
引用如下文章和文章中图片
SecAlign: Defending Against Prompt Injection with Preference Optimization
On the Feasibility of Poisoning Text-to-Image AI Models via Adversarial Mislabeling
攻击方法
如今的文本到图像生成模型基于数百万张来自互联网的图片进行训练,每张图片都配有由视觉语言模型(VLMs)生成的详细说明。训练流程的这一部分对于在训练过程中为模型提供大量高质量的图像-说明对至关重要。然而,最新研究表明VLM易受隐形对抗攻击的侵害,即在图像中添加对抗扰动以误导VLM生成错误的字幕。
本文探讨了对VLM进行对抗性错误标注攻击作为毒害文本到图像模型训练流水线机制的可行性。
我们的实验表明,VLM极易受到对抗性扰动的影响,使攻击者能够生成看似无害的图像,但VLM模型却不断错误地标注了字幕。Our experiments demonstrate that VLMs are highly vulnerable to adversarial perturbations, allowing attackers to produce benign-looking images that are consistently miscaptioned by the VLM models.
这会将强效的“脏标签”毒样本注入文本转图像模型的训练流程,成功改变少量中毒样本的行为。我们发现,虽然潜在防御可能有效,但它们也可能被适应性攻击者针对并绕过。这表明这是一场猫捉老鼠的游戏,可能会降低训练数据的质量并增加文本到图像模型开发的成本。最后,我们展示了这些攻击在现实中的有效性,即使在针对商业VLM的黑箱场景(如Google Vertex AI和Microsoft Azure)中,攻击成功率超过73%。
引用如下文章
On the Feasibility of Poisoning Text-to-Image AI Models via Adversarial Mislabeling
Towards Backdoor Stealthiness in Model Parameter Space
后门攻击恶意地将隐蔽功能注入机器学习模型,这被视为安全威胁。后门攻击的隐蔽性是一个关键的研究方向,重点关注对手如何增强后门攻击对防御机制的抵抗力。近期关于后门隐匿的研究主要聚焦于输入空间中不可区分的触发点和特征空间中不可分割的后门表示,旨在规避研究这些空间的后门防御。然而,现有的后门攻击通常设计用于抵御特定类型的后门防御,而忽视了多样的防御机制。基于这一观察,我们自然提出一个问题:当前的后门攻击在面对多种实际防御时,真的是现实世界的威胁吗?
为回答这个问题,我们考察了12种常见的后门攻击,这些攻击侧重于输入空间或特征空间隐身性,以及17种多样的代表性防御。令人惊讶的是,我们揭示了一个关键盲点:通过参数空间中分析后门模型,可以缓解那些设计为输入和特征空间隐蔽的后门攻击。
为了探究这一常见漏洞背后的根本原因,我们研究了参数空间中后门攻击的特征。值得注意的是,我们发现输入空间和特征空间攻击会在参数空间中引入显著的后门相关神经元,而这些神经元目前的后门攻击并未充分考虑。考虑到全面的隐身性,我们提出了一种名为Grond的新型供应链攻击。Grond 通过一个简单但有效的模块——对抗后门注入(Adversarial Backdoor Injection, ABI)来限制参数变化,该模块在后门注入过程中自适应地提高了参数空间的隐蔽性。大量实验表明,Grond 在针对 CIFAR-10、GTSRB 及部分 ImageNet 上最先进(包括自适应)防御的 12 种后门攻击中表现优于所有 12 种。此外,我们证明ABI持续提升常见后门攻击的有效性。我们的代码是公开的。
引用如下文章
Towards Backdoor Stealthiness in Model Parameter Space
A Practical and Secure Byzantine Robust Aggregator
在机器学习安全中,计算平均值时常常面临从给定高维向量集合中去除离群值的问题。例如,许多数据毒化攻击的变体在训练过程中会产生的梯度向量,这些向量在干净梯度分布中是异常值,这会对用于推导机器学习模型的计算平均值产生偏倚。在平均之前过滤掉这些人,是一种通用的防御策略。拜占庭稳健聚合是一种算法原语,在存在ε部分可能被任意且自适应地损坏的向量时,计算出一个稳健平均,使得最终平均值的偏差是可证明的有界的。
本文给出了第一个在输入向量大小下以准线性时间运行且可证明具有近似最优偏置界限的稳健聚合器。我们的算法也不假设对干净向量的分布有任何了解,也不需要预先计算任何滤波阈值。这使得它能够直接用于标准神经网络训练程序。我们通过实证证实其预期运行效率及其在抵消10种不同机器学习中毒攻击中的有效性。
A Practical and Secure Byzantine Robust Aggregator
Session E8:应用密码学8
Session F1:Web安全3
Session F2:机器学习与安全6
Differentiation-Based Extraction of Proprietary Data from Fine-Tuned LLMs
针对微调大语言模型的隐私攻击与防御
对领域特定且人类对齐的大型语言模型(LLM)需求的不断增长,促使监督式微调(Supervised Fine-Tuning, SFT)技术的广泛采用。SFT数据集通常包含有价值的指令-响应对,使其成为潜在提取的极具价值的目标。
本文首次研究这一关键研究问题。我们首先正式定义并表述问题,然后根据SFT数据在现实场景中的独特属性,探索各种攻击目标、类型和变体。基于对直接提取提取行为的分析,我们开发了一种专为SFT模型设计的新型提取方法,称为差异化数据提取(Differentiated Data Extraction, DDE),利用微调模型的置信水平及其与预训练基模型的行为差异。通过跨多个领域和场景的广泛实验,我们展示了利用DDE提取SFT数据的可行性。我们的结果表明,DDE在所有攻击环境中始终优于现有的提取基线。为应对这一新攻击,我们提出了一种防御机制,能够在对模型性能影响最小的情况下减轻DDE攻击。总体而言,我们的研究揭示了微调大型语言模型中的隐藏数据泄露风险,并为开发更安全模型提供了见解。
引用如下文章
Differentiation-Based Extraction of Proprietary Data from Fine-Tuned LLMs
One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
新的对抗性攻击Univlntruder,构建对抗性扰动
深度神经网络(DNN)取得了广泛成功,但仍易遭受对抗性攻击。通常,这类攻击要么涉及频繁查询目标模型,要么依赖与目标模型高度相似的替代模型—通常用目标模型训练数据的子集进行训练,—通过可转移性实现高攻击成功率。然而,在现实中训练数据无法访问且过多查询可能引发警报的情况下,构建对抗性示例变得更加具有挑战性。
本文介绍了UnivIntruder,一种新颖的攻击框架,仅依赖一个公开的CLIP模型和公开数据集。通过使用文本概念,UnivIntruder 生成了普遍、可转移且有针对性的对抗扰动,误导 DNN 将输入错误分类为由文本概念定义的对手指定的类。
我们广泛的实验表明,我们的方法在ImageNet上可实现高达85%的攻击成功率(ASR),在CIFAR-10上超过99%,显著优于现有基于传输的方法。此外,我们还揭示了现实世界的漏洞,显示即使不查询目标模型,UnivIntruder也能攻破谷歌和百度等图像搜索引擎,ASR率高达84%,以及视觉语言模型如GPT-4和Claude-3.5,ASR率高达80%。这些发现凸显了在传统途径被阻断的情况下,我们攻击的实用性,凸显了重新评估AI应用安全范式的必要性。
引用如下文章
One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
DivTrackee versus DynTracker: Promoting Diversity in Anti-Facial Recognition against Dynamic FR Strategy
DynTracker:使现有反面部识别AFR失效
DivTrackee:防止用户面部图像被动态FR策略识别
面部识别(FR)模型的广泛采用引发了对其潜在滥用的严重担忧,促使反面部识别(AFR)技术的发展以保护用户面部隐私。
本文认为,静态FR策略(此前主要用于评估AFR效能的文献)无法忠实描述那些旨在追踪特定目标身份的确定追踪者的实际能力。特别介绍了DynTracker,一种动态的法学重建策略,模型的画廊数据库会根据新识别的目标身份图像迭代更新。令人惊讶的是,这种简单的做法使所有现有的AFR保护措施失效。为了减轻DynTracker带来的隐私威胁,我们倡导明确促进AFR保护图片中的多样性。我们假设缺乏多样性是现有AFR方法失败的主要原因。具体来说,我们开发了DivTrackee,这是一种基于文本引导图像生成框架和促进多样性的对抗损失的创新方法,用于构建多样化的AFR保护。通过对各种图像基准和特征提取器的全面实验,我们展示了DynTracker在打破现有AFR方法方面的优势,以及DivTrackee在防止用户面部图像被动态FR策略识别方面的优势。我们相信,我们的工作可以成为开发更有效的AFR方法的重要第一步,以保护用户面部隐私免受特定追踪者的侵害。
What’s Pulling the Strings? Evaluating Integrity and Attribution in AI Training and Inference through Concept Shift
人工智能(AI)的日益普及加剧了人们对可信度的担忧,包括完整性、隐私、鲁棒性和偏见。为评估和归因这些威胁,我们提出了ConceptLens,这是一个通用框架,利用预训练的多模态模型,通过分析探测样本中的概念转移来识别完整性威胁的根本原因。ConceptLens 展示了对普通数据中毒攻击的强大检测性能,并发现了偏见注入的漏洞,例如通过恶意概念转换生成隐蔽广告。它识别未修改但高风险样本中的隐私风险,在训练前进行过滤,并洞察因训练数据不完整或不平衡而产生的模型弱点。此外,在模型层面,它会赋予目标模型过度依赖的概念,识别误导性的概念,并解释干扰关键概念如何对模型产生负面影响。它揭示了生成性内容中的社会学偏见,揭示了不同社会学背景下的差异。ConceptLens揭示了本应安全的训练和推断数据如何被无意且轻易地利用,从而破坏安全对齐。
Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
我们展示了在美国选举统计器中使用机器学习分类器所带来的安全风险。选举统计中的核心分类任务是判断某个标记是否会出现在与选票竞选中对应的候选人相关的气泡中。Barretto 等人(E-Vote-ID 2021)报告称卷积神经网络在该领域是一个可行的选择,因为它们优于简单的基于特征的分类器。
我们对选举安全的贡献可以分为四个部分。为了展示和分析机器学习模型在选举计票器上的假设脆弱性,我们首先引入了四个新的选票数据集。其次,我们在新数据集上训练和测试各种不同的模型。这些模型包括支持向量机、卷积神经网络(基础的CNN、VGG和ResNet)以及视觉变换器(Twins和CaiT)。第三,利用我们的新数据集和训练好的模型,我们证明了传统白盒攻击在投票领域因梯度掩蔽而无效。我们的分析进一步表明,梯度掩蔽是数值不稳定性的产物。我们采用修正的logit比率损失差来克服这个问题(Croce和Hein,ICML 2020)。第四,在物理世界中,我们利用新方法生成的对抗性实例进行攻击。在传统的对抗性机器学习中,高(50%或更高)的攻击成功率是理想的。然而,对于某些选举,即使是5%的攻击成功率也可能扭转竞选结果。我们证明了这种影响在物理领域是可能的。我们深入讨论了攻击现实主义,以及打印和扫描对抗性选票示例所面临的挑战和实用性。
引用如下文章
Busting the Paper Ballot: Voting Meets Adversarial Machine Learning
FilterFL: Knowledge Filtering-based Data-Free Backdoor Defense for Federated Learning
后门防御方法,相较于以前的方法,不依赖于额外数据集
由于缺乏针对不可信客户的数据审计技术,联合学习(FL)容易受到后门攻击。尽管已有多种方法被提出以保护 FL 免受后门攻击,但在极端数据异构场景下,它们的防御性能仍然较差。更糟糕的是,这些方法强烈依赖于额外的数据集,违反了佛罗里达的隐私保护要求。
为克服上述不足,本文提出了一种新颖的无数据后门防御方法,名为FilterFL,旨在防止上传的带有后门知识的客户端模型参与每轮FL通信中的聚合操作。基于我们使用两个设计良好的条件生成对抗网络(CGAN)进行知识提取和后门过滤方案,FilterFL提取新更新的全局模型学习到的增量知识,并过滤其后门组件,用于生成每个类别反映后门知识的样本。如果上传的本地模型能够自信地将生成的样本归入目标类别,模型贡献的知识将被排除在聚合之外。通过这种方式,FilterFL可以在不使用额外辅助数据的情况下有效防御后门攻击。对知名数据集的全面实验表明,与最先进方法相比,我们的方法在各种数据异质场景下实现了最佳的防御性能。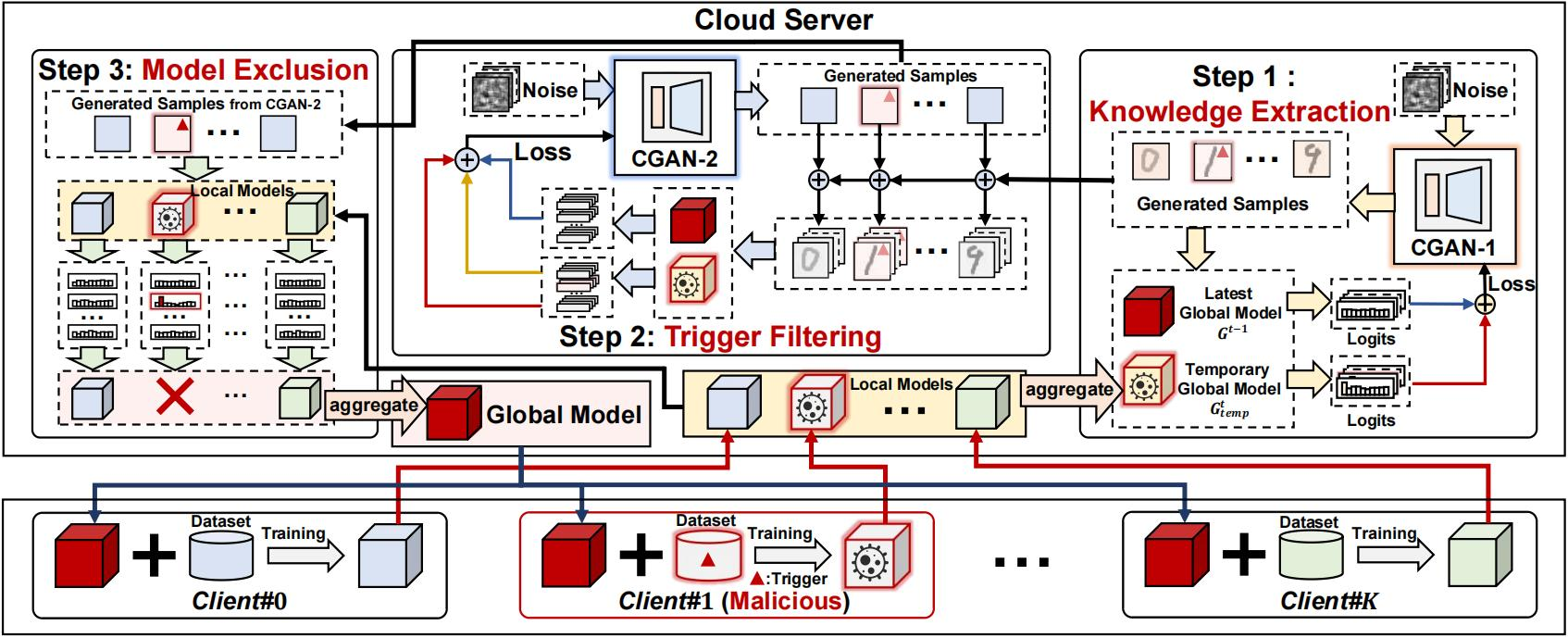
引用如下文章和文章中图片
FilterFL: Knowledge Filtering-based Data-Free Backdoor Defense for Federated Learning
Session F3:安全可用性与测量5
Session F4:硬件、侧信道与网络物理系统4
Session F5:软件安全6
Session F6:区块链与分布式系统3
Session F7:机器学习与安全7
Harnessing Vital Sign Vibration Harmonics for Effortless and Inbuilt XR User Authentication
扩展现实(XR)头显越来越多地作为大量敏感数据的存储库和通往网络应用的网关。这一转变凸显了便捷且安全的用户认证解决方案的必要性。传统的基于密码/PIN码的方案不适合XR的手势和语音界面,容易遭受肩膀浏览攻击。一些近期XR系统集成了双因素认证,但需要在第二台设备上(如智能手机或可穿戴设备)进行额外操作。
在本研究中,我们引入了首个轻松且内置的XR用户认证系统,利用用户生命体征激发的振动谐波。该系统对用户透明(注册和认证过程中无需额外努力),且无需额外硬件。核心思想是生命体征(如呼吸和心跳)自然产生低频机械振动,使人体头骨振动并产生谐波信号。当谐波通过人体头部时,携带与佩戴者颅骨结构和软组织相关的丰富生物特征,这些可被XR运动传感器捕捉。我们不再直接利用振动,而是从不同谐波频率之间的比率中提取更可靠的生物识别信息,这些谐波捕捉佩戴者独特的头部和面部衰减特性,且在生命体征周期性和幅度波动时保持非挥发性。我们还设计了自适应滤波器,以减轻常见XR交互中的身体运动扭曲。通过采用带有注意力机制的先进深度学习模型,我们的系统实现了在XR场景下有效且稳健的认证。历时10个月的评估显示,52名用户和两款热门XR头显的评估显示,我们的系统能够准确认证用户,真实阳性率超过95%,并拒绝未授权用户,真实阴性率超过98%,且生物识别在长期内保持一致。
引用如下文章
Harnessing Vital Sign Vibration Harmonics for Effortless and Inbuilt XR User Authentication
AgentSentinel: An End-to-End and Real-Time Security Defense Framework for Computer-Use Agents
大型语言模型(LLM)越来越多地集成到计算机使用代理中,这些代理能够自主操作用户计算机上的工具,完成复杂任务。然而,由于LLM输出本身不稳定且不可预测,它们可能会发出非预期的工具命令或错误输入,导致潜在的有害操作。与传统因用户提示不安全而产生的安全风险不同,LLM驱动决策带来的工具执行结果带来了新的独特安全挑战。这些漏洞涵盖计算机代理的所有组件。
为降低这些风险,我们提出了AgentSentinel,一种端到端的实时防御框架,旨在减轻用户计算机上的潜在安全威胁。AgentSentinel 拦截与代理相关服务中的所有敏感操作,并在完成全面安全审计前暂停执行。我们的安全审计机制引入了一种新颖的检查流程,将当前任务上下文与任务执行过程中生成的系统痕迹相关联。为了全面评估AgentSentinel,我们提出了BadComputerUse基准测试,包含60种不同攻击场景,涵盖六个攻击类别。基准测试显示,四款最先进的大型语言模型的平均攻击成功率为87%。我们的评估显示,AgentSentinel的平均防御成功率为79.6%,显著优于所有基线防御。
引用如下文章
AgentSentinel: An End-to-End and Real-Time Security Defense Framework for Computer-Use Agents
Sentry: Authenticating Machine Learning Artifacts on the Fly
机器学习系统越来越依赖由他人创建或托管的开源产物,如数据集和模型。依赖外部数据集和预训练模型使系统暴露于供应链攻击(supply chain attacks)的风险,即工件可能在交付给终端用户之前被污染。由于现有机器学习系统缺乏真实性验证,这种攻击是可能发生的。采用哈希和签名等密码学解决方案可以降低供应链攻击的风险。然而,基于密码技术的现有完整性验证框架在应用于最先进的机器学习工件时,由于规模庞大且不兼容GPU平台,可能会产生较大的开销。
本文开发了Sentry,一个基于GPU的新型框架,通过实现数据集和模型的加密签名和验证,验证机器学习工件的真实性。Sentry 将开发者身份与签名绑定,并在 GPU 内存加载时实时进行身份验证,使其兼容绕过 CPU 的 NVIDIA GPUDirect 等 GPU 数据移动解决方案。Sentry 集成了 GPU 加速加密哈希结构,如默克尔树和格子哈希,实现内存优化和资源划分方案,实现高吞吐量性能。我们的评估表明,Sentry是一个实用的解决方案,能够为机器学习系统带来真实性,速度比基于CPU的基线提升了数量级。
引用如下文章
Sentry: Authenticating Machine Learning Artifacts on the Fly
Training Robust Classifiers for Classifying Encrypted Traffic under Dynamic Network Conditions
大多数现有基于深度下载的加密流量分类方法在实际部署中因动态网络条件(如网络环境变化和流量混淆)而性能下降。动态网络条件使加密流量在训练和测试阶段表现出独特的特征模式。
为解决这一问题,我们提出了MetaTraffic,这是一种基于元学习的新颖通用DL训练框架,旨在提升针对动态网络条件下加密流量分类设计的监督式DL模型的性能。我们的关键观察是,同一网络行为的流量即使在不同网络条件下也共享相同的语义特征,这可以被视为稳定的特征表示。因此,MetaTraffic通过最小化模型在不同网络条件下表现流量特征的差异,帮助DL模型学习稳定的特征表示,从而在动态网络条件下实现稳健分类。我们基于元学习实施了MetaTraffic,采用三个创新的辅助模块以提升其性能。我们使用三个公共数据集和三个涵盖多种网络状况的大型加密流量数据集来评估MetaTraffic。实验结果显示,在动态多类型网络条件下,我们的框架使DL模型的准确率提升8.94%,F1宏评分提升12.55%;而现有稳健训练方法则降低准确率28.85%,F1宏评分降低33.52%。
引用如下文章
Training Robust Classifiers for Classifying Encrypted Traffic under Dynamic Network Conditions
Adversarial Observations in Weather Forecasting
基于人工智能的系统,如谷歌的GenCast,最近重新定义了天气预报的前沿,提供了更准确及时的日常天气和极端事件预测。虽然这些系统即将取代传统气象方法,但它们也为预报过程引入了新的漏洞。
本文探讨了这一威胁,并提出了一种针对自回归扩散模型(如GenCast中使用的模型)的创新攻击,这些模型能够操控天气预报并伪造极端事件,包括飓风、热浪和强降雨。该攻击在天气观测中引入了与自然噪声无异的细微扰动,且变化不到0.1%的测量数据——相当于篡改单个气象卫星的数据。随着现代预报整合了近百颗卫星及来自不同国家运营的众多其他来源的数据,我们的发现凸显了一项关键的安全风险,可能引发大规模中断并削弱公众对天气预报的信任。
Co-Prime: A Co-design Framework for Privacy Preserving Machine Learning on FPGA
在庞大的隐私敏感机器学习应用领域,且多方协作数据采集,安全多方计算(MPC)成为保护隐私的机器学习(privacy-preserving machine learning, PPML)有前景的解决方案。秘密共享协议是一种普遍的MPC策略,通过频繁的数据分发和重组来维护参与者数据的机密性。PPML中秘密共享协议实际部署的一个关键挑战是,机器学习中出现的各种线性和非线性阶段中存在庞大且不平衡的计算和通信工作负载。当设计强大的硬件加速器以降低计算延迟时,这种不平衡可能会进一步放大。
在本研究中,我们提出了Co-Prime,一个基于FPGA的3PC框架,无需安全第三方协助即可高效实现PPML。Co-Prime 集成了协议和硬件协同优化,以缓解秘密共享方案中的通信瓶颈。特别是,Co-Prime提出了一种新颖的协议转换技术,能够无缝转换数据格式,在PPML的不同阶段自适应采用首选协议。加速器友好型MPC原语和系统级设计空间探索方案旨在通过重叠计算和网络通信实现延迟隐藏。最后,它通过FPGA上的网络通信模块实现与数据流的直接交互,进一步降低网络通信开销。实验结果显示,在各种局域网/广域网环境和神经网络模型中,推理延迟提升了2倍至18倍,性能优于现有的保护隐私机器学习框架。
引用如下文章
Co-Prime: A Co-design Framework for Privacy Preserving Machine Learning on FPGA
Session F8:应用密码学9
Session G2:隐私与匿名4
Session G3:可用性、区块链与机器学习1
Session G4:硬件、侧信道与网络物理系统5
Session G5:软件安全7
Session G6:网络安全3
Session G7:机器学习与安全8
Here Comes the AI Worm: Preventing the Propagation of Adversarial Self-Replicating Prompts Within GenAI Ecosystems
本文展示了,当生成式人工智能驱动的应用之间依赖基于RAG的推理时,攻击者可以发起类似计算机蠕虫的链式反应,我们称之为RAGworm。这通过设计一个对抗性的自我复制提示来实现,触发生态系统内间接的提示注入,迫使每个受影响的应用执行恶意行为,从而破坏其他应用的RAG。我们评估了蠕虫在创建一系列恶意活动链上的表现,这些活动旨在推广内容、传播宣传和提取由生成式AI驱动的电子邮件助手生态系统中的机密用户数据。我们展示了RAGworm可以以超线性传播速率触发上述恶意活动,每个客户端在最初1-3天内(取决于每天发送的邮件数量)入侵20个新客户端。此外,我们还分析了RAGworm性能受到多种因素的影响。最后,我们介绍了DonkeyRail,这是一种旨在以低延迟、高精度和低误报率检测和防止RAG蠕虫传播的护栏。我们评估护栏的性能,显示其真阳性率为1.0,误报率为0.017,同时增加了7.6-38.3毫秒的可忽略不计的延迟(取决于检索的文档数量)。我们还展示了护栏对外发布蠕虫的强力抵抗,包括看不见的越狱提示和各种蠕虫用例。
Deep Learning from Imperfectly Labeled Malware Data
深度学习方法在恶意软件分类和检测方面取得了显著的表现。然而,它们的成功依赖于大型且准确标注的数据集:这是恶意软件领域中既关键又具挑战性的需求。实际上,大多数恶意软件数据集都是通过杀毒引擎的输出自动标记的,这一过程常常引入显著的标签噪声。这些缺陷会严重降低深度学习模型的性能和泛化性。
为应对这一挑战,我们引入了SLB,这是一个旨在稳健训练基于深度学习的恶意软件系统,同时优化数据集标签的框架。SLB首先将数据集划分为两个子集:一个是干净的子集,包含具有可靠标签的样本;另一个是噪声集合,包含可能被错误标记的样本,后者被赋予伪标签。随着训练的进行,SLB会持续监控模型的预测,动态更新两个集合。具体来说,噪声集中持续接收与其(观测或伪)标签一致预测的样本被提升为干净集,而在干净集合中表现出不稳定预测的样本则被重新归类为有噪声。这一迭代过程不仅提升了模型性能,还能逐步纠正标记错误。
我们在多个安全数据集上评估了SLB,涵盖了多种深度学习架构和机器学习算法中既有合成噪声,也有真实标签噪声。实验结果表明,SLB显著提升了恶意软件检测性能并减少了整体噪声。例如,在带有25%标签噪声注入的Android二进制数据集中,SLB将噪声降至低于1.5%,同时将宏F1得分从74.51%提升至96.03%,准确率从87.66%提升至98.68%。
PreferCare: Preference Dataset Copyright Protection in LLM Alignment by Watermark Injection and Verification
随着提升LLM应用安全性的紧迫需求,越来越关注设计用于保持大型语言模型(LLM)行为符合人类价值观的对齐训练算法。比对训练算法高度依赖偏好数据集,而偏好数据集对于微调LLM以符合人类偏好至关重要。然而,生成和注释这些数据集通常成本高且劳动密集,因此保护版权免受未经授权使用至关重要。
本文提出PreferCare,这是首个专为偏好数据集版权保护而设计的框架,通过水印注入和验证实现。PreferCare包含两个连续阶段:注入和验证。注入阶段设计了基于样式转移的水印信号和双级水印优化过程,将水印嵌入偏好数据集中。在验证阶段,我们采用统计检验来判断可疑LLM是否未经授权使用了水印偏好数据集。对多个流行LLM的广泛实验表明,PreferCare在多种环境中实现了有效性、无害性、可转移性和鲁棒性,并且能够在20次查询内成功验证水印。
SCOPE: Expanding Client-Side Post-Processing for Efficient Privacy-Preserving Model Inference
隐私保护推断(Privacy-Preserving Inference, PPI)使用户能够利用强大的机器学习模型,同时不泄露敏感输入数据。然而,由于计算和通信开销较大,现有的先进解决方案仍然不切实际。
本文提出了SCOPE(Secure Client-side Operation Expansion安全客户端操作扩展),这是一个新颖框架,通过扩大客户端后处理的范围,显著减少了这些开销。我们观察到,现代基于HE的推理方案不可避免地仅将掩蔽中间密文仅用于两个简单操作——元素选择和重排——而导致了不成比例的高通信成本。为解决这一低效问题,SCOPE引入了一种语义保护掩蔽策略,能够精确校准掩蔽密文中的噪声大小,保留最少但足够的语义信息。通过利用服务器与客户端之间固有的信息不对称性,该策略使客户端能够在本地执行额外的轻量级线性(如归一化)和非线性(如ReLU)操作,从而大幅降低计算和通信开销,同时有效保护敏感的模型参数。
大量实验表明,SCOPE相比最先进方法实现了3倍的加速和2.8倍的通信减少,精度下降极小(<2.9%)。在自适应攻击设置下的进一步评估确认,SCOPE引入的受控语义暴露并未增加模型提取攻击的风险。源代码可在 https://anonymous.4open.science/r/scope-ccs25 获取。
引用如下文章
SCOPE: Expanding Client-Side Post-Processing for Efficient Privacy-Preserving Model Inference
Session G8:应用密码学10
Session H1:机器学习与安全9
WPC: Weight Plaintext Compression for CNN Inference based on RNS-CKKS
基于RNS-CKKS的卷积神经网络(CNN)推断能够安全地处理加密数据,但会带来显著的权重大小开销。权重明文(RNS-CKKS格式)可达数十至数百吉字节。
现有的压缩方法要么增加高计算成本,要么产生低压缩率。
在本研究中,我们提出了权重明文压缩(** Weight Plaintext Compression, WPC**),用于基于RNS-CKKS的CNN推断时压缩权重明文。我们观察到,从CNN模型中的权重转换为RNS-CKKS格式的权重明文,涉及类似离散傅里叶变换的操作,该变换在时间域和频域之间移动数据,同时保留周期性和离散数据的冗余信息。基于这一观察,我们首先引入周期性传输定理,该定理指出在变换过程中可以保持周期性模式,从而实现压缩。随后,我们提出了通道最内层填充方案和旋转填充,将重量数据重新排列为周期性模式以实现压缩。结果显示,WPC在A100 GPU上实现了1.25到2.18倍的加速,压缩率提升了46.08倍到139.11倍。
引用如下文章
WPC: Weight Plaintext Compression for CNN Inference based on RNS-CKKS
FlippedRAG: Black-Box Opinion Manipulation Adversarial Attacks to Retrieval-Augmented Generation Models
检索增强生成(RAG)通过动态检索外部知识丰富LLMs,减少幻觉并满足实时信息需求。虽然现有研究主要关注RAG的性能和效率,但新兴研究也凸显了关键的安全隐患。
然而,目前的对抗方法仍然有限,主要针对白箱场景或启发式黑箱攻击,而未在检索阶段充分调查漏洞。此外,之前的工作主要聚焦于事实类问答任务,其攻击缺乏复杂性,且容易被高级大型语言模型纠正。
本文探讨了一个更现实且关键的威胁场景:针对黑箱RAG模型,特别是在有争议话题上的,针对意见操控的对抗性攻击。具体来说,我们提出了FlippedRAG,这是一种针对类似黑箱RAG系统的基于转移的对抗性攻击。我们首先证明,黑箱RAG的底层检索器可以通过枚举关键查询、候选和答案进行逆向工程和近似,从而训练替代检索器。借助代理检索器,我们进一步设计目标中毒触发器,修改少量文档以有效操作检索和后续生成,将攻击转移到原始黑盒RAG模型中。大量实证结果表明,FlippedRAG的表现远超基线方法,平均攻击成功率提高了16.7%。在四个不同领域,FlippedRAG平均实现了RAG生成的反馈观点极性方向性50%的转变,最终显著地推动用户认知发生了20%的转变。此外,我们积极评估了多种潜在防御措施的性能,得出结论:现有缓解策略对此类复杂操控攻击仍不足以应对。这些结果凸显了开发创新防御解决方案的紧迫需求,以确保RAG系统的安全性和可信度。
Mosformer: Maliciously Secure Three-Party Inference Framework for Large Transformers
基于Transformer的模型如BERT和GPT在广泛的人工智能任务中取得了最先进的性能,但作为云推理服务部署时引发了严重的隐私隐患。为此,通常采用安全多方计算(MPC),加密用户输入和模型参数,实现推理而不泄露任何私人信息。
然而,现有基于MPC的安全变换器推理协议主要基于半诚实的安全模型设计。将这些协议扩展到支持恶意安全仍是重大挑战,主要原因是安全评估对抗性韧性所需的复杂非线性函数所带来的巨大开销。
我们介绍Mosformer,这是首个恶意安全的三方(3PC)推理框架,能够高效支持BERT和GPT等大型变换器。我们首先设计带有恶意安全性的常数轮比较和查找表协议,利用可验证的分布式点函数(VDPF)。基于这些,我们开发了一套3PC协议,用于高效且安全地评估变换器中复杂的非线性函数。结合优化模量转换,我们的方法大幅降低了安全变压器推断的开销,同时保持了模型的准确性。对原版变压器模块的实验结果显示,Mosformer相比之前恶意安全协议,通信速度提升了最多5.3×,通信减少了4.3×。尽管提供更强的安全保障,Mosformer 在全尺寸模型如 BERT 和 GPT-2 上,实现的在线性能可与最先进的半诚实 2PC 和 3PC 框架媲美甚至更优,包括 BOLT(奥克兰 2024)、BumbleBee(NDSS 2025)、SHAFT(NDSS 2025)和 Ditto(ICML 2024)。
引用如下文章
Mosformer: Maliciously Secure Three-Party Inference Framework for Large Transformers
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
差分隐私的评估方法
差分隐私(DP)图像合成旨在生成人工图像,既保留敏感图像数据集的特性,又保护数据集中单个图像的隐私。尽管近期有进展,我们发现各项研究中应用的评估方案存在不一致,有时存在缺陷。这不仅阻碍了对现有方法的理解,也阻碍了该领域的未来发展。
为解决这一问题,本文介绍了DPImageBench,并在多个维度上进行了深思熟虑的设计:(1)方法。我们研究了十二种主要方法,并基于模型架构、预训练策略和隐私机制系统地描述了每种方法。(2)评估。我们包含九个数据集和七个指标,以全面评估这些方法。值得注意的是,我们发现,基于敏感测试集中最高准确率选择下游分类器的常见做法,不仅违反了DP,还高估了其效用。DPImageBench 对此进行了校正。(3)平台。尽管方法和评估协议多样,DPImageBench 提供了一个标准化接口,能够在统一框架内兼容当前和未来的实现。通过DPImageBench,我们有几个值得关注的发现。例如,与普遍认为在公共图像数据集上进行预训练通常有益的观点相反,我们发现预训练与敏感图像之间的分布相似性显著影响合成图像的性能,且并不总是带来改进。源代码已公开。
引用如下文章
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
What Lurks Within? Concept Auditing for Shared Diffusion Models at Scale
扩散模型(DM)彻底革新了文本到图像生成,使得从文本提示创建高度真实且个性化的图像成为可能。随着参数高效微调(PEFT)技术如LoRA的兴起,用户现在可以用极少的计算资源定制强大的预训练模型。然而,在开放平台上广泛分享经过精细调整的私信引发了日益增长的伦理和法律问题,因为这些模型可能无意中或故意生成敏感或未经授权的内容,如受版权保护的材料、私人或有害内容。尽管对生成式人工智能的监管关注日益增加,但目前尚无实用工具能在部署前系统性审计这些模型。
本文探讨概念审计问题:判断经过精细调校的DM是否学会生成特定的目标概念。现有方法通常依赖基于提示的输入制作和基于输出的图像分类,但它们存在关键局限,包括提示不确定性、概念漂移和扩展性差。
为克服这些挑战,我们引入了提示无关无图像审计(Prompt-Agnostic Image-Free Auditing, PAIA),这是一种新颖的、以模型为中心的概念审计框架。通过将DM视为检查对象,PAIA实现了对内部模型行为的直接分析,绕过了优化提示或生成图像的需求。它集成了两个关键组成部分:一种提示无关策略,通过分析模型在后期去噪过程中的行为来减轻提示敏感性;另一种是基于条件校准误差的无图像检测方法,将微调模型的内部动态与其基础版本进行比较。我们的审计设置假设内部访问DM,但不要求访问专有微调数据或用户提示,这一假设与托管平台审计上传模型的方式一致。我们基于320个受控模型评估PAIA,这些模型使用精心策划的概念数据集训练,以及771个来自公共地下城主分享平台的真实社区模型,涵盖了包括名人、卡通人物、电子游戏实体和电影参考等广泛概念。评估结果显示,PAIA在检测准确率超过90%的同时,审计时间比现有基线缩短了18-40倍,并且在自适应攻击下依然保持稳健。据我们所知,PAIA是首个可扩展且实用的扩散模型概念前审计解决方案,为更安全、更透明的扩散模型共享提供了实用基础。
引用如下文章
What Lurks Within? Concept Auditing for Shared Diffusion Models at Scale
Provable Repair of Deep Neural Network Defects by Preimage Synthesis and Property Refinement
已知深度神经网络在各种安全威胁下可能表现出危险行为(例如后门攻击、对抗性攻击和安全财产违规),攻击者与防御者之间存在持续的军备竞赛。本研究提出一个互补视角,利用“神经网络修复”的最新进展,在统一框架内缓解这些安全威胁,修复各种由不同安全威胁引起的神经网络缺陷,为现实场景提供潜在的灵丹妙药。
为了大幅突破现有修复技术(如缺乏保证、扩展性有限、开销较大等限制)在更实际的情境下,我们提出了ProRepair,这是一种通过形式原像合成和属性细化驱动的新型可证神经网络修复框架。关键直觉包括:(i) 合成一个精确的代理盒以表征特征空间的原像,从而推导出一个有界距离项,指导后续修复步骤朝向正确输出;(ii) 进行属性细化,以便进行外科手术修正并扩展到更复杂的任务。我们基于六个基准测试评估ProRepair在四项安全威胁修复任务中的表现,结果显示其在效能、效率和可扩展性方面优于现有方法。在逐点修复中,ProRepair在保持性能的同时修正模型,实现显著提升的泛化,比现有可验证方法快5×至2000×。在区域维修方面,ProRepair成功修复了全部36个安全财产违规事件(相比之下,现有最佳方法的8个),并能处理18×高维空间。
引用如下文章
Provable Repair of Deep Neural Network Defects by Preimage Synthesis and Property Refinement
Session H2:隐私与匿名5
Session H3:安全可用性与测量6
Session H4:机器学习与安全10
GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search
攻击方法:用于生成对抗性段落
基于深度学习编码的密集嵌入文本检索——即通过深度学习编码从语料库检索相关段落——已成为一种强大的方法,能够获得最先进的搜索结果,并普及检索增强生成(RAG)。不过,像其他搜索方法一样,基于嵌入的检索也可能容易受到搜索引擎优化(SEO)攻击的攻击,即攻击者通过向语料库引入对抗性段落来推广恶意内容。以往的研究已证明此类SEO是可行的,主要展示了针对检索集成系统(如RAG)的攻击。然而,这些方案采用了较宽松的SEO威胁模型(例如针对单一查询),使用基线攻击方法,并提供小规模检索评估,从而掩盖了我们对检索器最坏情况行为的全面理解。
本研究旨在忠实且全面地评估检索者的稳健性,为揭示其易受SEO影响的因素铺平道路。为此,我们首先提出了GASLITE攻击,用于生成对抗性段落,这些段落无需依赖语料库内容或修改模型,携带对手选择的信息,同时获得高检索排名,持续优于以往方法。其次,利用GASLITE,我们广泛评估检索器的鲁棒性,测试了九个高级模型,涵盖多种威胁模型,重点关注针对特定概念(如公众人物)查询的相关对手。我们的发现包括:检索者即使在极低的毒性率(例如语料库的≤0.0001%)下,也极易受到SEO的攻击;单查询SEO完全由GASLITE解决;自适应攻击展示了绕过共同防御的方法;不同寻回犬对SEO攻击的韧性差异很大。第三,探讨后者发现,我们识别出可能影响模型易受SEO影响的关键因素,包括嵌入空间几何中的具体属性,呼应最坏情况评估的重要性,并为未来防御奠定基础。
引用如下文章
GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search
The Phantom Menace in Crypto-Based PET-Hardened Deep Learning Models: Invisible Configuration-Induced Attacks
深度学习(DL)模型的日益广泛应用引发了关于训练和推理数据的重大隐私担忧。为解决这些问题,社区越来越多地采用基于加密的隐私增强技术(CPET),如同态加密(HE)、安全多方计算(MPC)和零知识证明(ZKP)。CPET与DL(通常称为CPET-DL)的集成通常由CrypTen、TenSEAL和EZKL等专业框架促进。这些框架提供可配置参数,以在保护隐私的操作中平衡模型准确性和计算效率。然而,这些配置虽然看似无害,却可能带来细微的漏洞。由于配置错误引发的隐蔽攻击难以被发现,原因在于:1)明文模型保持无漏洞,2)现有审计工具几乎不适用于受CPET防护的模型。这造成了一个悖论:旨在保护隐私的工具可能被配置操作破坏。
我们介绍ConPETro,这是首次通过操作CPET-DL框架配置来攻击CPET硬化模型。我们展示了,精心设计的配置使攻击者能够创建受CPET防护的模型,这些模型在正常输入下功能类似于良性明文模型,但对于带有触发器的恶意输入表现出显著降低的鲁棒性。ConPETro 策略性地选择触发器以最大化良性模型的行为偏差,并利用梯度一致性指导配置探索,有效发现绕过标准明文模型审计的恶意配置。在三种主流CPET-DL框架(HE、MPC和ZKP)上的评估显示,ConPETro在语义和非语义触发因素方面均具有效性。在带有非语义触发条件的CPET硬化模型中,ConPETro的平均最大攻击成功率(ASR)为72.27%;命中率仅下降4%,保持潜行性。此外,在三个数据集中,语义触发器下最高ASR达到94.74%。我们还展示了我们的隐身攻击能够绕过先进的防御和侦测工具。
Evaluating the Robustness of a Production Malware Detection System to Transferable Adversarial Attacks
随着深度学习模型作为大型生产系统组件广泛部署,其各自的缺陷可能在系统层面产生具有实际影响的漏洞。
本文研究针对机器学习组件的对抗性攻击如何削弱或绕过整个生产级恶意软件检测系统,并对Gmail在文件类型识别依赖机器学习模型的管道中进行了案例分析。Gmail 使用的恶意软件检测流程包含一个机器学习模型,将每个潜在恶意软件样本路由到专门的恶意软件分类器,以提高准确性和性能。这个名为Magika的模型已被开源。通过设计欺骗Magika的对抗示例,我们可以使生产恶意软件服务错误地将恶意软件导向不合适的恶意软件检测器,从而提高我们规避检测的可能性。具体来说,只需修改13字节的恶意软件样本,我们就能在90%的情况下成功规避Magika Malware,从而允许我们通过Gmail发送恶意软件文件。随后,我们将注意力转向防御,并制定一种方法来减轻这类攻击的严重性。对于我们防御型生产模型,资源丰富的对手只需50字节就能达到20%的攻击成功率。我们实施了这一防御,并且得益于与谷歌工程师的合作,它已经在Gmail分类器上部署到生产环境中。
Cascading Adversarial Bias from Injection to Distillation in Language Models
模型提纯已成为创建可部署语言模型的关键,但其广泛应用引发了对其抵御对抗性操控韧性的担忧。
本文探讨了对手如何在培训过程中通过最小化数据中毒,向教师模型注入微妙偏见,这种偏见传播到更小的精炼学生模型中,并被显著放大。
我们识别出两种传播模式:无目标传播(影响多个任务)和有针对性(专注于特定任务,同时保持其他正常行为)。仅有25个中毒样本(0.25%中毒率),学生模型在目标场景中产生偏见的回答率为76.9%,而教师模型则为69.4%;而非目标传播则在未见任务中学生的对抗性偏见率高出5.7倍至29.2倍。我们验证了六种偏见类型(定向广告、钓鱼链接、叙事操控、不安全的编码实践)、各种提炼方法以及文本/代码生成方式。目前的防御机制——包括困惑过滤、偏见检测系统和基于LLM的权威器——对这些攻击来说是不够的。我们提出了实用的设计原则,用于构建有效的对抗性偏见缓解策略,以应对这一威胁向量。
引用如下文章
Cascading Adversarial Bias from Injection to Distillation in Language Models
You Can’t Steal Nothing: Mitigating Prompt Leakages in LLMs via System Vectors
大型语言模型(LLM)已被广泛应用于各种应用领域,利用定制化的系统提示来应对各种任务。面对潜在的系统提示泄露风险,模型开发者实施了防止泄露的策略,主要通过禁用LLM在遇到已知攻击模式时重复上下文来实现。然而,它仍然容易受到新的、意想不到的提示泄露技术的影响。
本文首先介绍了一种简单但有效的提示泄露攻击,以揭示此类风险。我们的攻击能够从各种基于LLM的应用中提取系统提示,甚至包括GPT-4o或Claude 3.5 Sonnet等SOTA LLM模型。我们的发现进一步激励我们寻找在上下文中不使用系统提示符来解决这些问题的根本性解决方案。为此,我们提出了SysVec,一种将系统提示编码为内部表示矢量而非原始文本的新方法。通过这样做,SysVec 最大限度地降低了未经授权泄露的风险,同时保留了 LLM 的核心语言能力。令人惊讶的是,这种方法不仅增强了安全性,还提升了模型的整体指令跟踪能力。实验结果表明,SysVec 有效减轻了即时泄露攻击,维护了 LLM 的功能完整性,并有助于缓解长期上下文场景中的遗忘问题。
引用如下文章
You Can’t Steal Nothing: Mitigating Prompt Leakages in LLMs via System Vectors
Exact Robustness Certification of k-Nearest Neighbors
在安全关键环境中部署机器学习模型时,鲁棒性保证至关重要,因为对抗性攻击构成严重威胁。尽管在认证(深度)神经网络方面取得了广泛进展,但如k-最近邻(k-NN)等非参数模型这种可解释性强且在高保证环境中的应用研究较少。
以往的k-NN认证方法提供了可靠但不完整的保证,许多真正稳健的输入未获得认证。本研究为k-NN分类器引入了一个稳健完整的认证框架,提供针对对抗扰动的精确鲁棒性保证。我们的方法结合了超立方体空间分解与基于对抗邻近先级图的新图论分析,实现对抗区域的全面覆盖。对广泛使用数据集的广泛评估表明,我们的精确方法显著提升了相较现有技术的认证率,同时保持了可扩展性。通过缩小健全性与完整性之间的差距,我们的框架推动了k-NN模型的安全保障,并助力在对抗环境中实现可证明的稳健机器学习的更广泛目标。
Session H5:软件安全8
Session H6:网络安全4
Session H8:应用密码学11

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)