AI芯片NPU子系统架构解析:从计算核心到数据流转
·
先了解缩写
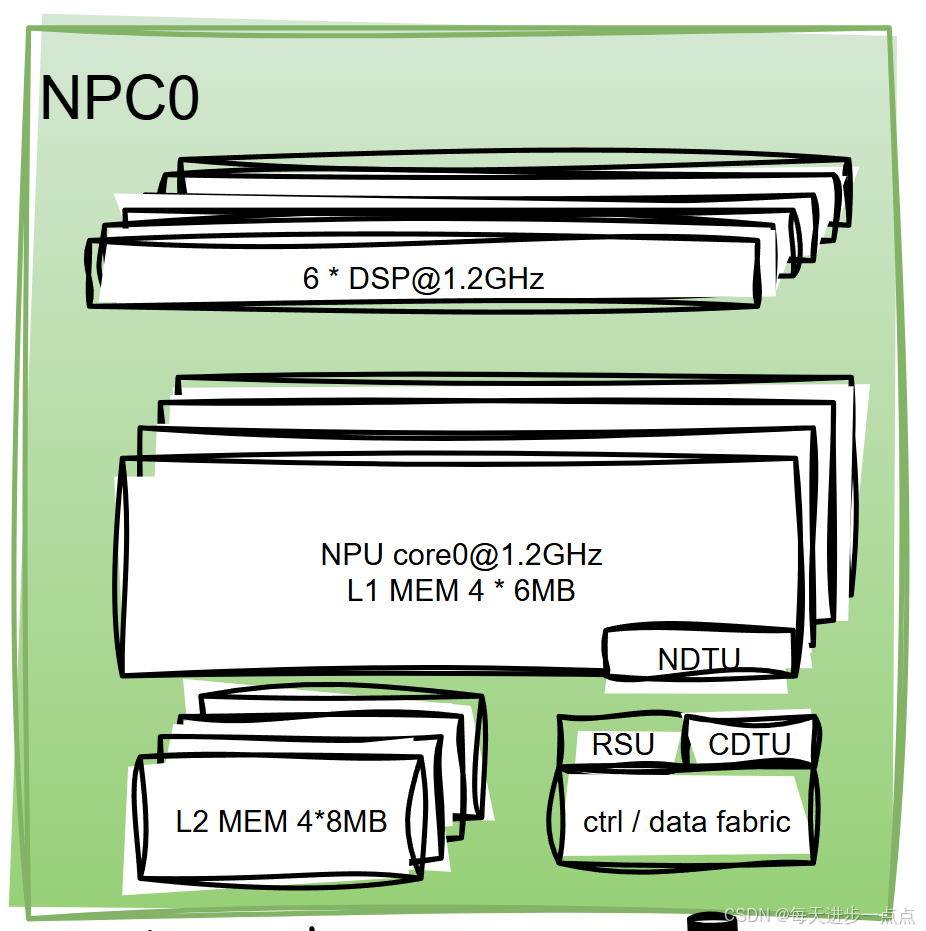
- DSP : Data Signals Process(处理部分NPU不擅长的算子,承担额外算力支持),浮点计算
- NPU:Neural/ˈnjʊərəl/ Processing Unit(神经网络处理单元)
- DLA:Deep Learning Accelerator(深度学习加速器)
- L2:Level 2 Share memory (4个NPU共享存储)
- NPC:NPU Clusters
- DLA = NPC+DSP
- RSU:Real time Scheduling Unit 调度单元
- CDTU : NPC Data Transfer Unit(理解成一个比较高档的DMA,处理L2与L3(DDR)之间数据的搬移。包含多个virtual channel,可以同时处理多个context)
- DMA: Direct Memory Access 直接内存访问(让外设直接和内存交互)
再认识缩写
NPU:神经网络处理器
- 定义:它是专门为 AI 深度学习算法(如卷积神经网络)设计的硬件加速器。
- 作用:在自动驾驶中,摄像头拍到的画面需要经过 NPU 才能识别出“这是行人”、“那是红绿灯”。NPU擅长处理大规模的矩阵乘法运算。
DSP:数据信号处理单元
- 定义:DSP设计目标是补充和增强系统的整体算力,特别是处理 NPU不擅长或不适合处理的特定类型运算,如:某些滤波算法、几何变换等
- 作用:承担额外算力支持,避免所有计算都堆积在 CPU 或 NPU 上,从而提升整个系统的处理能力和效率。
DLA:深度学习加速器
- 定义:这是一个更宏观的概念。通常,整个 NPU 子系统就被称为 DLA。
- 关系:你可以把 DLA 理解为“工厂的名字”,而 NPU 和 DSP 是工厂里的“机器”。
- 图中暗示:下图左侧有
dla2central_cfg的信号线,说明这个模块在整个芯片顶层被识别为 DLA。换句话说,整个NPC0+NPC1整个大块,对外统称为DLA
架构图梳理:数据如何流动
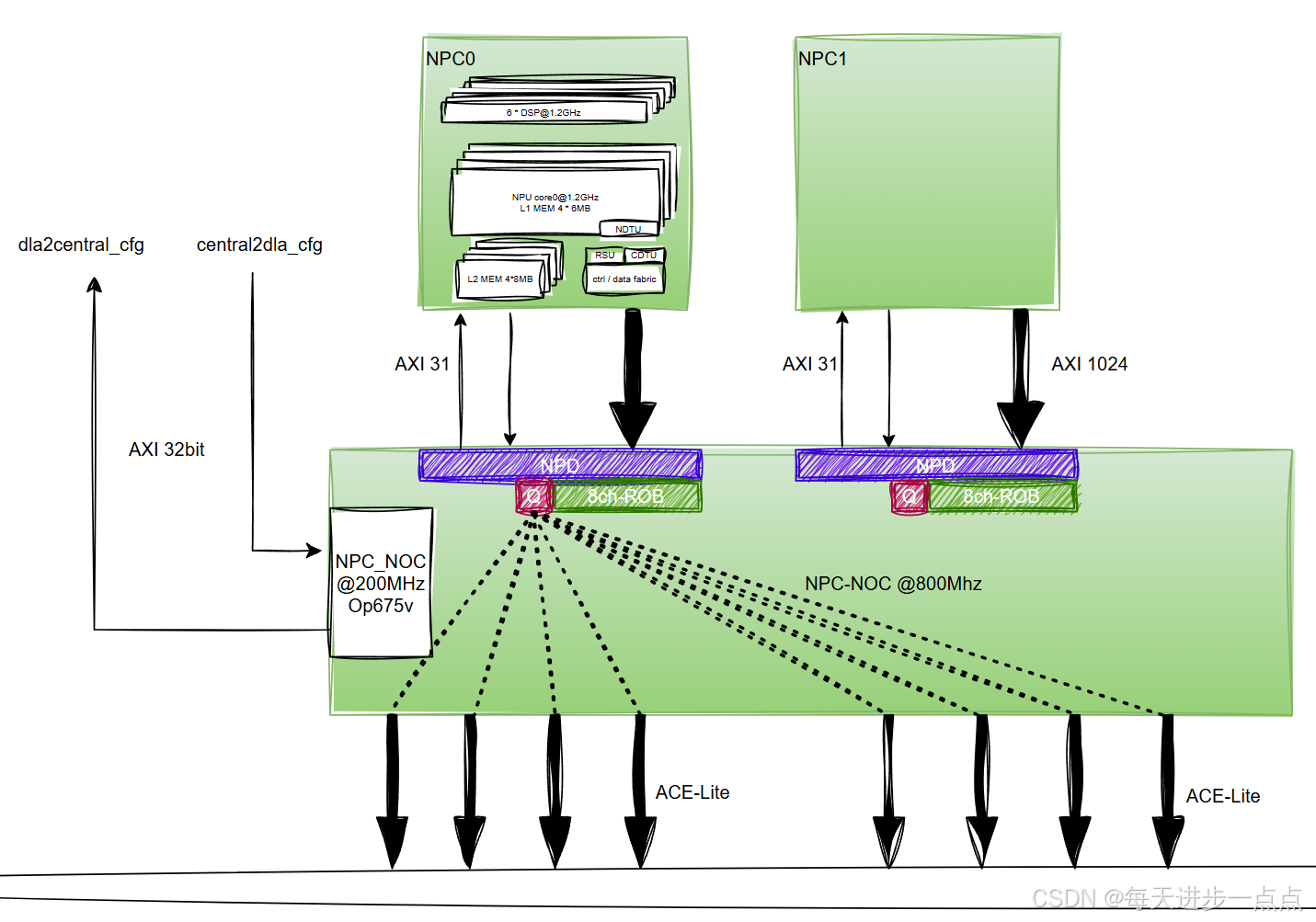
这张图其实展示了两个完全一样的“计算集群“(NPC0和NPC1),这是为了提供双核冗余或更高的算力。
以NPC0为例,来梳理架构
计算核心 NPC0:
- 这是一个独立的计算单元,内部包含了:
- 6个DSP:承担额外算力支持,处理部分NPU不擅长的算子
- NPU Core:负责核心AI计算,频率1.2GHz
- 超级超级大的缓存
- L1 MEM:4个6MB(共24MB),离核心很近,速度无敌快
- L2 MEM:4个8MB(共32MB),作为二级缓存
- 注意:这个缓存非常大!说明它为了减少去主内存拿数据的时间,自己在本地囤积了大量数据
- 数据搬运与排队(中间层NPD&NPC_NOC)
- NPD:?
- NPC_NOC@800MHz:片上网络
- 底部ACE-lite接口
- 这是标准的ARM接口协议,理解为:出口大门
- 数据流向:
- 向下:通过ACE-Lite接口,数据进入Memory noc ?
-
向左:通过
AXI 32bit接口,接收来自Central的配置信号
总结
你可以把这个架构图想象成一个“AI 计算车间”:
- 原材料进来:摄像头或激光雷达的数据通过底部的“大门”(ACE-lite)进入。
- 粗加工:数据送到 DSP 进行处理
- 精加工:数据送入 NPU 进行深度学习推理(比如识别物体)
- 临时仓库:加工过程中,大量数据暂存在 L1/L2 缓存 中,不用跑去远处的内存,所以速度极快。
- 成品运出:计算结果通过内部的 NOC 网络,再经由“大门”送回给 APU 去做决策。
为什么有两个(NFC0 NFC1)
这通常是为了算力叠加(两个一起算,速度更快)或者功能安全冗余(一个坏了,另一个还能顶上,保证车不会失控)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)