从马尔可夫链到代码实现:彻底搞懂 DDPM 的前向扩散与反向采样(含完整公式推导)
前言
作为生成式 AI 的基石之一,扩散模型(Diffusion Model)早已不是什么新鲜概念。但相信很多人和我一样,第一次接触 DDPM(Denoising Diffusion Probabilistic Models)论文时,都会被一堆看似复杂的公式和跳步的推导劝退:

本文将严格遵循 DDPM 原文的逻辑,从人为定义的马尔可夫链出发,完整推导所有关键公式,重点解决上述所有困惑。我会尽量避免不必要的数学炫技,用最直白的语言讲透每一个设计背后的动机和原理,确保你看完不仅能懂 "是什么",更能懂 "为什么"。
DDPM论文:https://arxiv.org/pdf/2006.11239

一、前向扩散:我们人为定义的 "涂鸦过程"
DDPM 的核心思想非常朴素:先教 AI"擦涂鸦",再让 AI 从一张全灰的纸开始,一步步擦出一张全新的画。而前向扩散过程,就是我们作为 "老师",给图片 "涂鸦" 的过程 ——所有规则都是我们提前写死的,没有任何 AI 参与。
1. 第一步:定义前向扩散是马尔可夫链
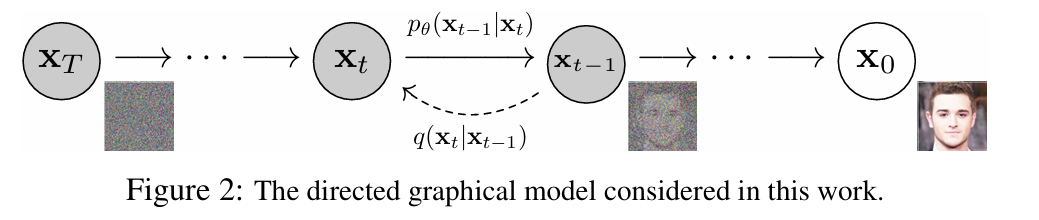
论文第 2 章开篇就明确了前向扩散的本质:
The approximate posterior q(x1:T∣x0), called the forward process or diffusion process, is fixed to a Markov chain that gradually adds Gaussian noise to the data according to a variance schedule β1,...,βT.
翻译成人话:前向扩散是一个固定的、无学习参数的马尔可夫链,它会按照我们提前定好的噪声强度表,逐步向图片中添加高斯噪声。
为什么是马尔可夫链?因为它有一个最适合我们的性质:下一步只和当前步有关,和更早的步无关。这让整个过程的数学表达变得极其简单,整个前向过程的联合分布可以直接写成每一步条件分布的乘积:q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)(1)
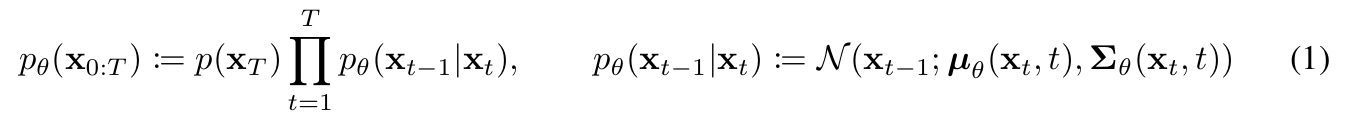
2. 第二步:人为设定单步加噪规则
这是整个 DDPM 中唯一的人为设定,所有后续的推导都建立在这个规则之上。论文公式 (2) 给出了单步加噪的定义:q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)(2)
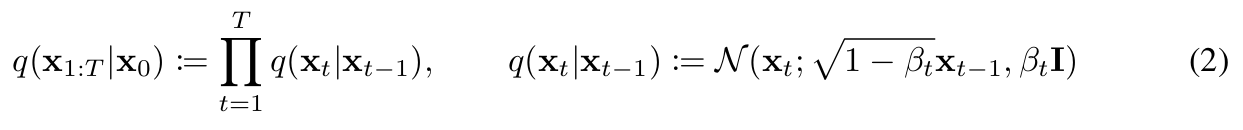
我来逐句拆解这个规则:
- 我们规定:第 t 步的图 xt 只由第 t-1 步的图 xt−1 决定
- 我们规定:xt 服从一个高斯分布(也就是我们常说的 "颗粒感" 噪声)
- 这个高斯分布的均值是
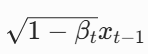 :把上一步的图稍微变暗一点
:把上一步的图稍微变暗一点 - 这个高斯分布的方差是
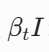 :给每个像素加独立的、强度为 βt 的高斯噪声
:给每个像素加独立的、强度为 βt 的高斯噪声
为什么要这么设计? 这里有两个极其巧妙的考量:
- 乘以
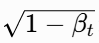 :抵消噪声带来的方差增加,让每一步的图的方差都保持在 1 左右,数值范围稳定,模型训练更稳定
:抵消噪声带来的方差增加,让每一步的图的方差都保持在 1 左右,数值范围稳定,模型训练更稳定 - 加高斯噪声:利用高斯分布独一无二的性质 ——多个独立高斯噪声加在一起,结果还是高斯噪声。这是我们能推导出任意步加噪公式的根本前提
3. 第三步:完整推导任意步加噪公式(代码中真正用的)
如果真的要给每张图跑 1000 步加噪,训练速度会慢到无法接受。但多亏了高斯分布的可加性,我们可以直接算出任意第 t 步的加噪结果,不用从 x₀一步步算到 xₜ。
推导过程(从 t=2 推广到任意 t)
我们先从最简单的 t=2 开始推导,看懂了两步,任意 t 步就都懂了。
根据单步加噪规则 (2),我们可以把高斯分布写成 "均值 + 噪声" 的形式:

把 x₁代入 x₂的表达式:
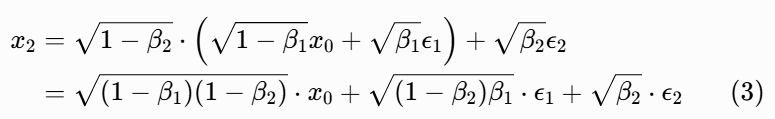
现在,我们需要合并后面两个独立的高斯噪声项。这里用到了高斯分布的可加性(整个 DDPM 唯一用到的概率论知识):
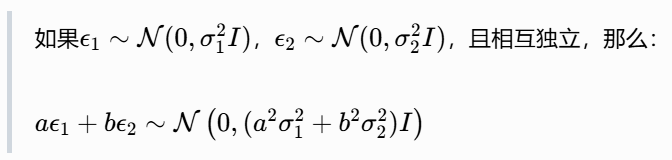
在我们的例子里,![]() ,所以:
,所以:
![]()
我们来化简括号里的方差:
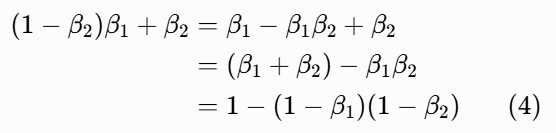
为了简化公式,论文定义了两个辅助符号(论文第 2 页):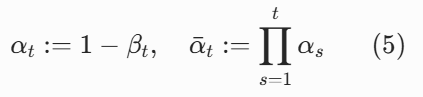 (αˉt 就是 α₁到 αₜ的累积乘积)
(αˉt 就是 α₁到 αₜ的累积乘积)
把 (4) 和 (5) 代入 (3),我们得到:
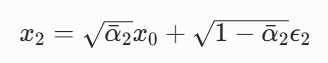
其中![]() (合并后的总噪声)
(合并后的总噪声)
用数学归纳法可以很容易地证明,对于任意 t≥1,这个结论都成立。因此,我们得到了任意步加噪的闭式解(论文公式 4):
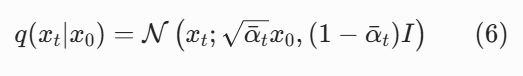
把高斯分布写成 "均值 + 噪声" 的形式,就得到了代码中 100% 会用到的加噪公式: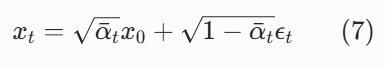
其中 ![]() 是前 t 步加的总噪声。
是前 t 步加的总噪声。
这里澄清一个最常见的概念混淆:q(xt∣x0) 不是一个概率值,而是一个条件分布。它描述的是:给定同一张原图 x₀,每次加 t 步噪声得到的 xₜ的取值规律。因为我们加的是高斯噪声,所以这个规律自然也是高斯分布。
二、训练过程:教 AI"预测我涂了多少灰色"
有了任意步的加噪公式,训练过程就变得异常简单了。我们不需要让 AI 直接 "画一张图",只需要让它完成一个最简单的回归任务:给定一张加了 t 步噪声的图 xₜ,预测我在这 t 步里总共加了多少噪声 εₜ。
1. 为什么不直接预测原图 x₀?
如果我们让 AI 直接从 xₜ预测 x₀,这是一个非常难的任务 —— 就像给你一张被涂了一半的画,让你猜原来画的是什么。而预测噪声则简单得多:噪声是随机的、无结构的,模型只需要学习 "哪些像素是我加的灰色" 就行。
2. 训练的完整流程
论文 Algorithm 1 给出了训练算法,我把它翻译成大白话:
- 随机拿一张干净的原图 x₀
- 随机选一个步数 t(1 到 T 之间随便挑)
- 随机生成一个总噪声 εₜ
- 用公式 (7),直接算出 xₜ
- 把 xₜ和 t 输入模型,让模型预测噪声
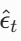
- 用 MSE 损失计算
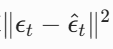 ,更新模型参数
,更新模型参数
重复几百万次,AI 就学会了:不管给我一张被涂了多少步的图,我都能准确说出这一步加了多少噪声。
三、反向采样:AI 自己 "擦涂鸦" 的过程(含完整推导)
训练完成后,AI 已经是一个顶级的 "擦涂鸦大师" 了。现在我们让它反过来,从一张全灰的噪声图开始,一步步擦出一张新画。这部分是 DDPM 最核心、也是最容易被误解的部分,我会把所有推导过程完整写出来。
1. 最致命的误区:为什么不能一步还原 x₀?
很多人都会问:既然 ![]() ,那我直接变形得到
,那我直接变形得到 ![]() ,一步就能还原原图,为什么还要走 1000 步?
,一步就能还原原图,为什么还要走 1000 步?
答案非常简单:模型预测的噪声不是 100% 准确的,有误差。如果一步还原,这个误差会被放大 ![]() 倍。当 t=1000 时,
倍。当 t=1000 时,![]() ,误差会被放大无穷大,得到的 x₀会完全是噪声。
,误差会被放大无穷大,得到的 x₀会完全是噪声。
我们来做一个简单的误差分析:假设模型预测的噪声有一个小误差δ,也就是![]() ,其中
,其中![]() 。代入一步还原的公式:
。代入一步还原的公式:
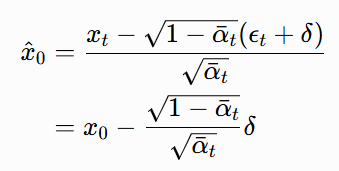
所以,x^0的误差是:
![]()
当 t=1000 时,![]() ,这个误差会趋近于无穷大。
,这个误差会趋近于无穷大。
2. 完整推导:上帝视角的完美去噪分布
那我们应该怎么去噪呢?论文告诉我们:如果我们知道真实的 x₀,那么从 xₜ还原到 xₜ₋₁的分布是可以用贝叶斯公式精确计算出来的。
贝叶斯公式的应用
对于任意两个随机变量 A 和 B,贝叶斯公式为:
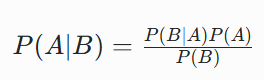
我们要求的是q(xt−1∣xt,x0),把 A 换成xt−1,B 换成xt,条件是x0,得到: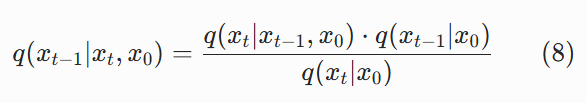
为什么能用贝叶斯公式直接算出来? 因为前向扩散的所有规则都是我们人为定死的,没有任何未知参数。右边的每一项,都是我们已经知道的:

代入计算,得到结果
把这三个高斯分布代入 (8),经过合并指数项、配方等代数运算,就会发现结果还是一个高斯分布(论文公式 6):
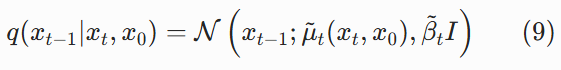
其中:
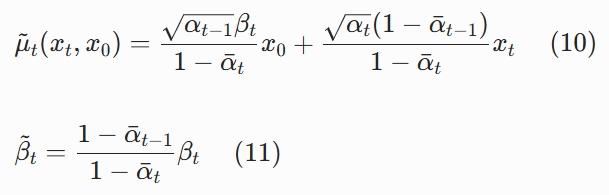
整个过程没有任何近似,是精确的数学推导。这个分布就是 "上帝视角" 的完美去噪分布 —— 如果我们知道真实的 x₀,就能用它 100% 准确地从 xₜ还原出 xₜ₋₁。
3. 完整推导:实际能用的采样公式
当然,采样的时候我们不知道真实的 x₀。但我们可以用模型预测的噪声ϵ^t来估计 x₀。
从公式 (7) 变形,我们可以得到 x₀的估计值:
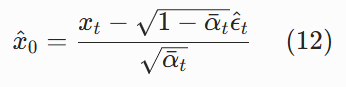
现在,我们把这个估计的x^0代入上帝视角的均值公式 (10),就得到了我们实际能用的反向过程均值μθ(xt,t):
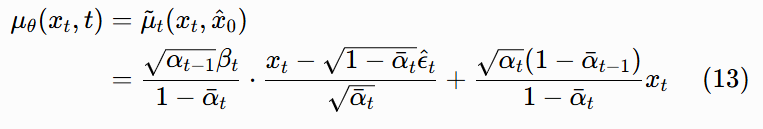
这个公式看起来很复杂,但我们可以把它化简成一个非常简洁的形式。注意到αˉt=αtαˉt−1,我们来一步步化简:
首先,把 (13) 拆成两项:
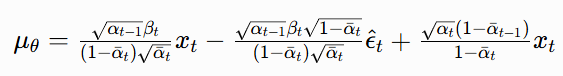
合并 x_t 的系数:
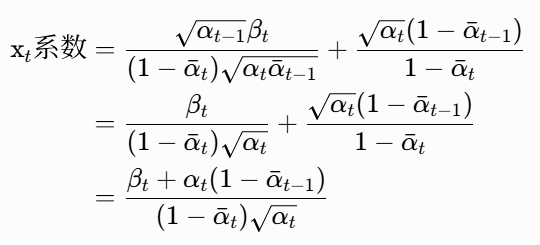
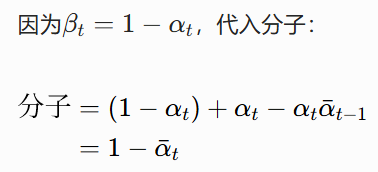
所以 x_t 的系数化简为:
![]()

把两个系数代入 (13),我们就得到了论文公式 (11),也就是最终的采样均值公式: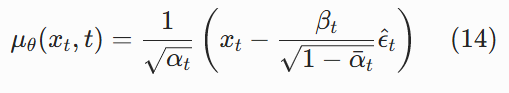
太神奇了! 这么复杂的公式,化简后居然这么简单。这就是 DDPM 采样过程的核心公式。
4. 最终的采样公式
论文里说,反向过程的方差σt2I可以固定为常数,![]() 或
或![]() 都可以,效果差不多。
都可以,效果差不多。
所以,从 xₜ采样得到 xₜ₋₁的最终公式就是:
![]()
其中:
- z∼N(0,I) 是一个随机的高斯噪声
- 当 t=1 时,z=0(最后一步不加噪声,得到确定的原图)
5. 为什么采样的时候还要加随机噪声 z?
这是另一个常见的困惑:我们好不容易把噪声擦掉了,为什么还要再加回去一点?
答案是:为了生成的多样性。反向过程是一个高斯分布,不是一个确定的点。如果我们只取均值,那么每次用同一个 x_T 生成的图都是一模一样的。加一点点随机噪声 z,就是让我们从这个高斯分布里随机采样一个点,这样每次生成的图都会有细微的差别,更自然。
6. 为什么分步去噪的误差很小?
我们之前说过,直接一步还原 x₀的误差会被指数级放大,但用误差大的![]() 估计 xₜ₋₁,误差却很小。我们来证明这一点:
估计 xₜ₋₁,误差却很小。我们来证明这一点:
假设模型预测的噪声有误差δ,即![]() ,那么x^0的误差是:
,那么x^0的误差是: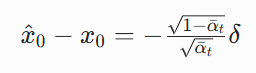
代入μθ的误差:
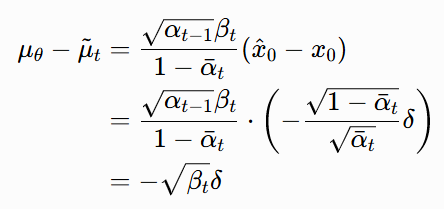
所以,μθ的误差是:
![]()
当 t=1000 时,β1000=0.02,所以误差只被放大了0.02≈0.14倍!哪怕x^0的误差是无穷大,μθ的误差也只有原来噪声误差的 0.14 倍。
这就是 DDPM 最核心的设计智慧:它没有让模型直接预测难的 x₀,而是让模型预测一个简单的 ε,然后用这个 ε 去修正 x_t,得到 xₜ₋₁。每一步只修正一点点,误差就不会被放大。
7. 完整的采样算法
论文 Algorithm 2 给出了完整的采样算法,我逐行翻译:
- 生成一张完全随机的纯噪声图 x_T(生成的起点)
- 从 t=T 倒着循环到 t=1
- 生成随机噪声 z,如果是最后一步 t=1,z=0
- 用公式 (14) 计算均值μθ
- 用公式 (15) 得到 xₜ₋₁
- 循环结束,返回 x₀
四、代码实现:极简 DDPM 的核心逻辑
下面我用 PyTorch 写出 DDPM 最核心的加噪和采样函数,你会发现理论和代码是完全一一对应的。
1. 初始化 β 和 α
import torch
import torch.nn as nn
# DDPM超参数(和论文完全一致)
T = 1000
beta_start = 1e-4
beta_end = 0.02
# 线性β调度(论文默认)
beta = torch.linspace(beta_start, beta_end, T)
alpha = 1. - beta
alpha_bar = torch.cumprod(alpha, dim=0) # 累积乘积,就是ᾱ_t
2. 加噪函数(训练时用)
def add_noise(x0, t):
"""
给干净图x0加t步噪声,返回加噪后的xt和真实噪声epsilon
对应论文公式(7)
"""
noise = torch.randn_like(x0)
# 把t对应的alpha_bar广播到和x0相同的形状
sqrt_alpha_bar = torch.sqrt(alpha_bar[t]).view(-1, 1, 1, 1)
sqrt_one_minus_alpha_bar = torch.sqrt(1 - alpha_bar[t]).view(-1, 1, 1, 1)
xt = sqrt_alpha_bar * x0 + sqrt_one_minus_alpha_bar * noise
return xt, noise
3. 采样函数(生成时用)
def sample(model, batch_size=1, image_size=32):
"""
从纯噪声开始,采样生成batch_size张图片
对应论文Algorithm 2
"""
x = torch.randn(batch_size, 3, image_size, image_size)
for t in reversed(range(T)):
t_tensor = torch.tensor([t] * batch_size)
z = torch.randn_like(x) if t > 0 else torch.zeros_like(x)
# 模型预测噪声
epsilon_hat = model(x, t_tensor)
# 计算均值(对应论文公式14)
sqrt_alpha = torch.sqrt(alpha[t]).view(-1, 1, 1, 1)
beta_t = beta[t].view(-1, 1, 1, 1)
sqrt_one_minus_alpha_bar = torch.sqrt(1 - alpha_bar[t]).view(-1, 1, 1, 1)
mu = (x - beta_t / sqrt_one_minus_alpha_bar * epsilon_hat) / sqrt_alpha
# 计算方差(论文说固定为sqrt(beta_t)即可)
sigma_t = torch.sqrt(beta[t]).view(-1, 1, 1, 1)
# 得到x_{t-1}(对应论文公式15)
x = mu + sigma_t * z
return x
五、总结:DDPM 的核心设计智慧
最后,我们用一句话总结 DDPM 的整个逻辑链:
我们人为定义了一个逐步加高斯噪声的马尔可夫链,利用高斯分布的可加性推导出任意步加噪公式,把生成任务转化为最简单的噪声预测回归任务;采样时利用贝叶斯公式推导出分步去噪公式,每一步只去掉一点点噪声,避免误差被放大,最终生成高质量的图片。
DDPM 看起来很 "笨",要走 1000 步才能生成一张图,但正是这种 "笨办法",解决了 GAN 长期存在的模式崩溃问题,也让生成模型的训练变得前所未有的稳定。这也正是它能成为现在所有主流生成模型(Stable Diffusion、Sora 等)基础的原因。
希望这篇文章能帮你彻底搞懂 DDPM 的核心原理。如果还有什么疑问,欢迎在评论区留言交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)