【个人CNN学习记录之AlexNet网络】
系列文章目录
个人CNN学习记录之AlexNet网络
文章目录
前言
在日常工作中,我专注于并行计算领域,主要依托GPGPU、NPU等高算力芯片进行开发。当前,高算力与AI已深度融合,计算与人工智能二者相辅相成:底层计算为实现通用算法与算子提供基础,而AI模型则能反哺并优化传统算法的决策效率与性能。为系统构建这方面的知识体系,我在公司导师的推荐下,跟随up主“霹雳吧啦Wz”的CNN系列视频进行学习,并通过博客记录学习过程,融入自己的理解与总结。
一、AlexNet网络介绍
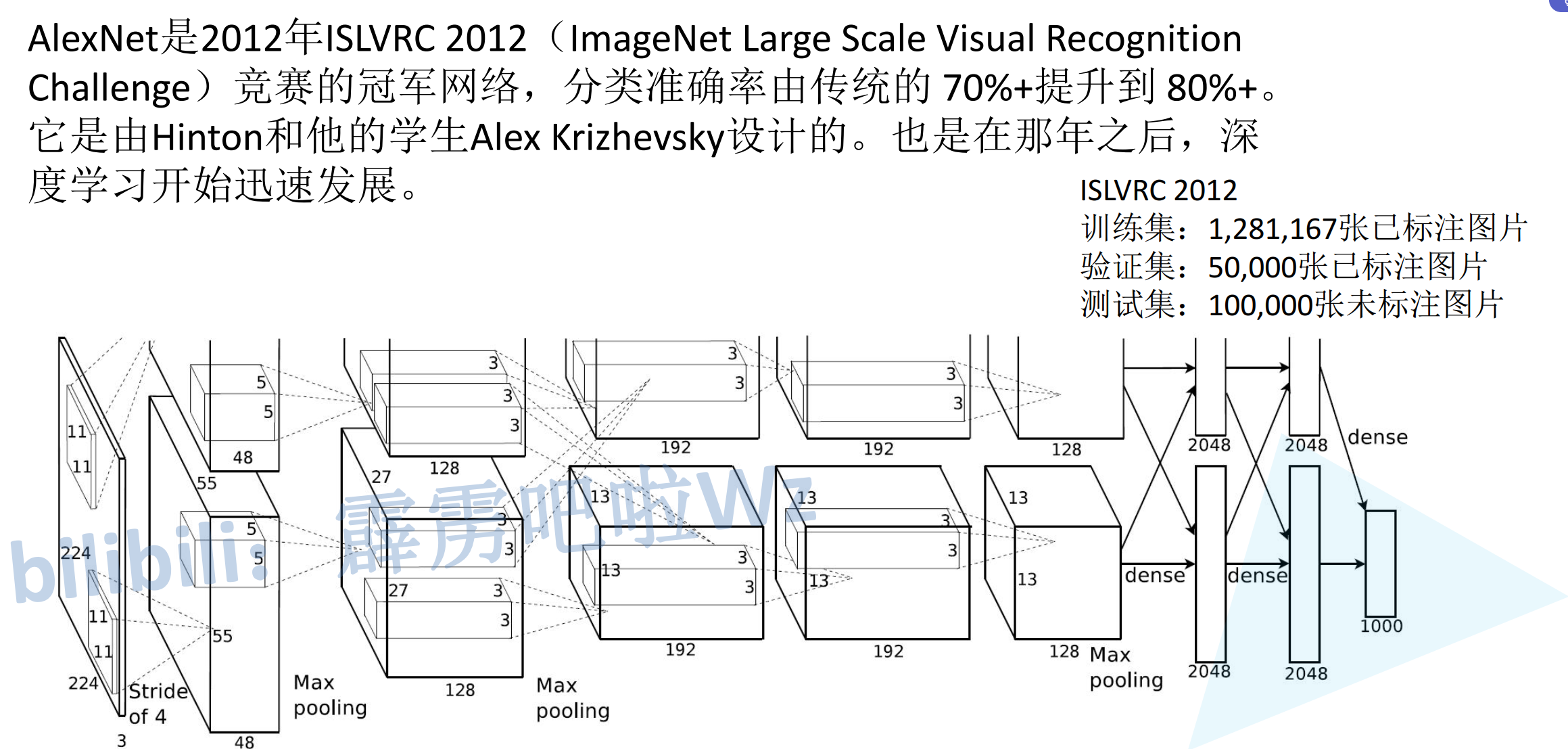
一、AlexNet的背景意义
历史地位:2012年ISLVRC竞赛冠军网络
性能突破:将ImageNet分类准确率从70%+提升到80%+
开创性:由Hinton和Alex Krizhevsky设计,开启了深度学习快速发展时代
二、ImageNet数据集规模
训练集:1,281,167张已标注图片
验证集:50,000张已标注图片
测试集:100,000张未标注图片
三、网络架构核心特征
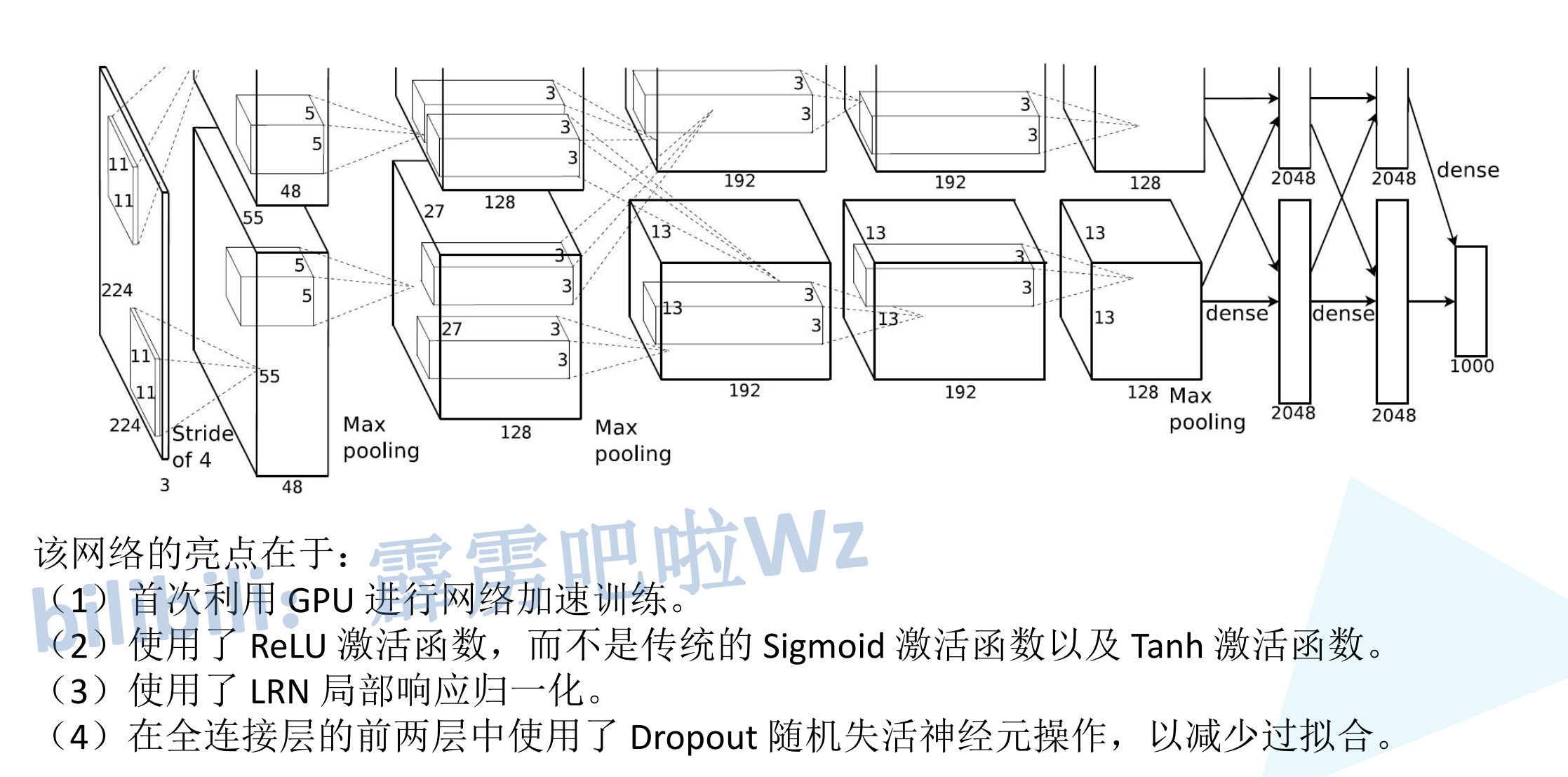
1. 基本结构
8层深度神经网络(5个卷积层 + 3个全连接层)
输入图片尺寸:224×224×3
2. 关键技术创新
ReLU激活函数:替代传统的Sigmoid,解决梯度消失问题
局部响应归一化(LRN):增强模型的泛化能力
重叠池化:步长小于池化核尺寸,提升特征丰富性
Dropout正则化:在全连接层使用,防止过拟合
数据增强:随机裁剪、翻转等增加训练数据多样性
首次利用GPU进行网络训练,双GPU并行训练:当时受限于显存,网络分两个GPU训练
四、网络各层参数详解
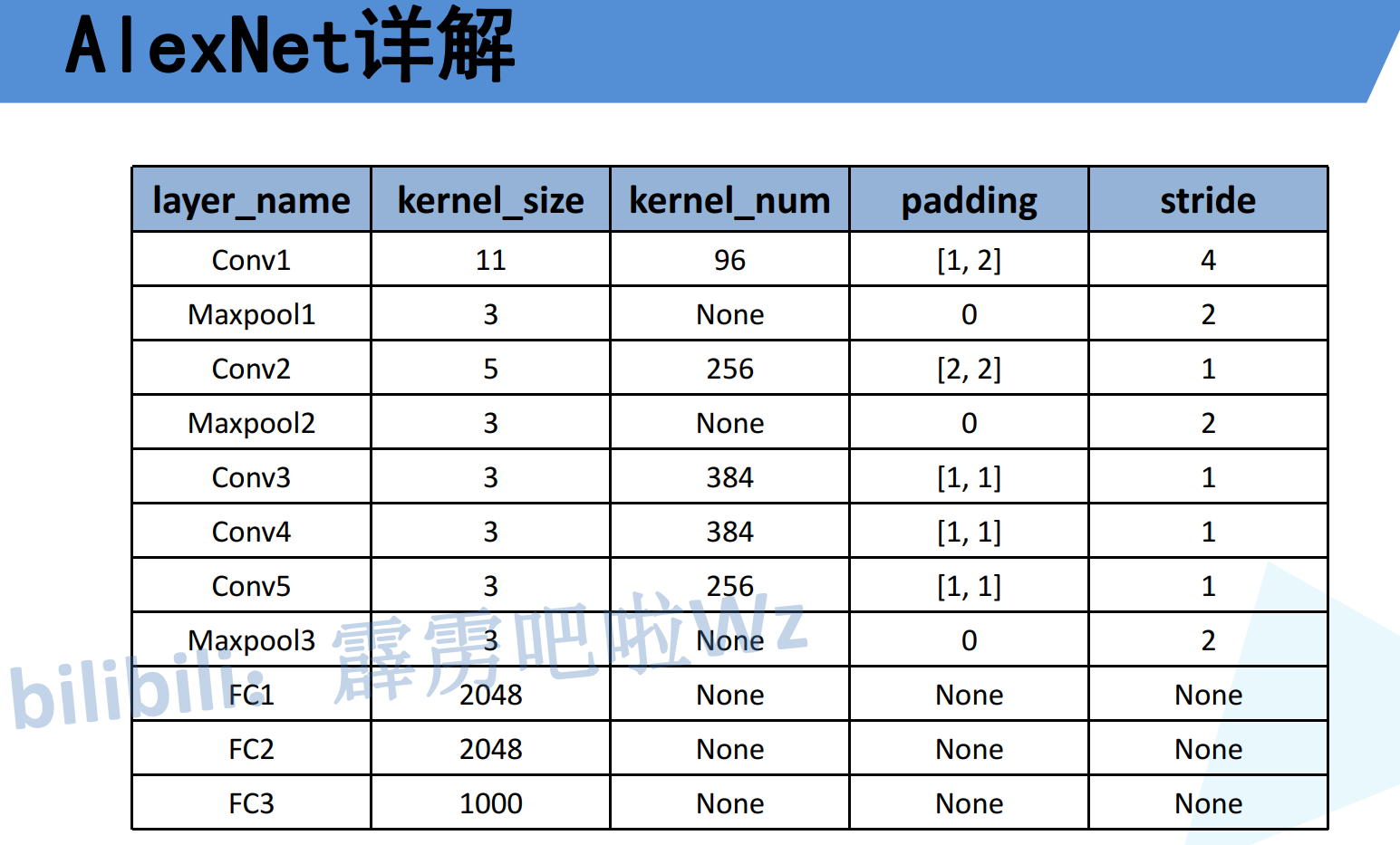
从图中可见各层尺寸变化:
尺寸计算公式参考N = (W − F + 2P ) / S + 1。注意图中的padding计算,比如conv1的padding为[1,2],则N = (W − F + 2P ) / S + 1 =[224-11+(1+2)]/4+1。
卷积层1
输入:224×224×3
96个11×11卷积核,步长4
输出:55×55×96
最大池化(3×3,步长2)
卷积层2
256个5×5卷积核
输出:27×27×256
最大池化(3×3,步长2)
卷积层3
384个3×3卷积核
输出:13×13×384
卷积层4
384个3×3卷积核
输出:13×13×384
卷积层5
256个3×3卷积核
输出:13×13×256
最大池化(3×3,步长2)
全连接层
FC1: 4096个神经元
FC2: 4096个神经元
FC3: 1000个神经元(对应1000个类别)
二、过拟合

过拟合主要由以下因素导致:
特征维度过多
模型假设过于复杂
模型参数过多
训练数据过少
数据中噪声过多
这些因素共同导致模型过度关注训练集中的细节和噪声,而忽略了数据背后的普遍规律。
模型追求泛化能力,而非对训练集的完美拟合。
为了避免过拟合,通常采用以下方法:
简化模型:减少参数、降低模型复杂度。
增加数据:获取更多训练数据。
数据增强:对现有数据进行变换以扩充数据集。
正则化(如L1、L2):在损失函数中增加对参数大小的惩罚项,限制模型复杂度。
Dropout(用于神经网络):随机丢弃一部分神经元,防止网络对特定特征过度依赖。
早停:在验证集性能不再提升时提前终止训练。
三、Dropout
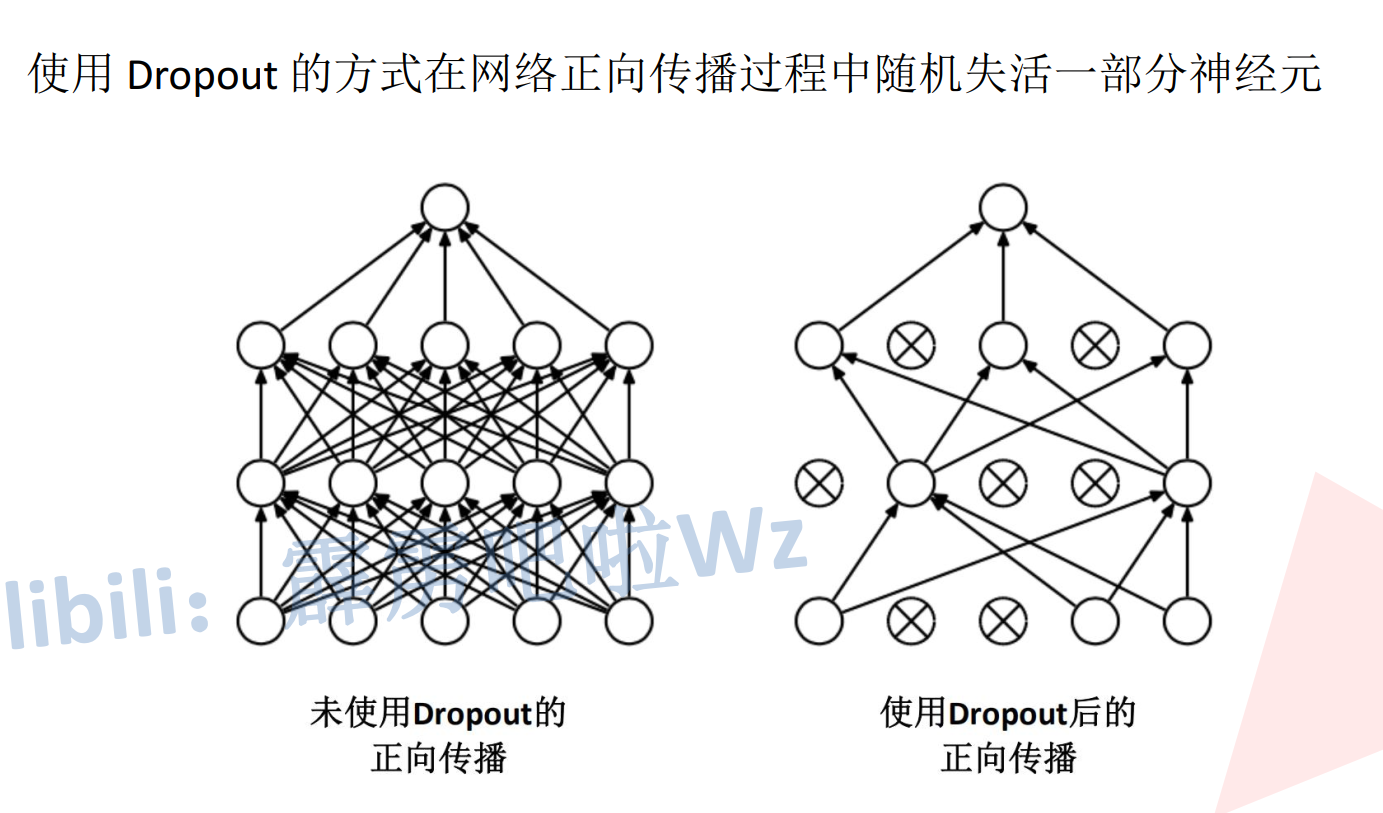
在神经网络的训练阶段,每次进行前向传播和反向传播时,随机地、临时地“关闭”(或称“失活”)网络中一部分的神经元(及其对应的连接),从而每次训练都在一个略有不同的网络结构上进行。
防止过拟合:这是最主要的目的。通过随机“失活”,Dropout相当于在每次迭代中训练一个不同的、更简单的“子网络”,并在最后对所有这些子网络的预测结果进行平均。这有效降低了神经元之间的复杂共适应性,使模型不过分依赖训练数据中的任何特定模式或噪声,从而增强了泛化能力。
Dropout只在模型训练时启用。在测试(推理)阶段,所有神经元都必须保持激活,但为了补偿所有神经元都参与计算所带来的信号强度变化,通常需要对每个神经元的输出乘以一个保留概率 p(训练时神经元被保留的概率),或者采用Inverted Dropout技巧在训练时就对激活值进行缩放。
失活率(p):p是神经元被保留的概率,那么 1−p就是被丢弃的概率。这是一个需要调整的超参数,通常隐藏层的 p默认值设为0.5。
四、代码分析
model.py
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
为了加快训练速度,代码里有些卷积核的个数不太一样,尺寸的channel有些许变化。其余和之前分析的LeNet代码对比来看卷积层多了stride, padding参数,不再用默认值。
这里说明一下nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),模型结构中这里padding应该传入一个tuple(1,2),代表上下各补一行0,左右两侧各补两列0,官方有nn.ZeroPad2d函数可以实现。这里为了方便直接写padding=2,会导致尺寸计算公式得出来的是小数,ptytorch中检测到小数会把多余的数据给舍弃掉,因此最后得到的尺寸还是一样的。
nn.ReLU(inplace=True)中inplace=True是 PyTorch 中一个重要的内存优化参数,它表示原地操作,即直接在输入张量上进行修改,而不创建新的输出张量。优点就是可以节省内存。
代码里通过self.features和self.classifier将特征提取和分类器模块分开,代码架构更清晰,分类器中通过nn.Dropout实现随机丢弃一部分神经元,p用来设置之前的失活率。
正向传播里同样是先特征提取,然后展平,再经过分类器得到输出,其中torch.flatten用来展平,和之前的view函数不同。
代码中定义了一个_initialize_weights用来初始化权重,这里通过kaiming_normal_初始化卷积层权重,通过nn.init.normal_初始化全连接层权重。其实pytorch中卷积层默认会使用这些初始化,这里给出这些接口可以让我们更底层的了解初始化动作。
train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
训练脚本和之前LeNet的脚本类似,不同的是这里使用 torch.device指定了是否使用GPU。
数据加载与预处理
然后同样使用ImageFolder进行图片加载与预处理,预处理使用了RandomResizedCrop和Resize,用于图像预处理,将输入图像的大小保持一致,满足网络输入尺寸需求。然后采用DataLoader进行数据集的批次导入。训练集和验证集分两部分完成。
模型初始化
net = AlexNet(num_classes=5, init_weights=True)初始化网络,num_classes指定类别个数
net.to(device)将网络模型放入GPU
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
定义损失函数与优化器,较小的学习率(0.0002)适合微调或小数据集
训练阶段
net.train() 设置为训练模式,默认会启用dropout方法
running_loss = 0.0初始化损失
tqdm显示实时训练进度和损失
optimizer.zero_grad()清除历史梯度
outputs = net(images.to(device)) 将训练集放入GPU并输入网络得到输出
loss = loss_function(outputs, labels.to(device)) 计算损失
loss.backward() 反向传播
optimizer.step() 优化器更新权重
running_loss += loss.item() 累计损失
验证阶段
net.eval() 设置为评估模式,默认关闭dropout方法
with torch.no_grad(): 禁用梯度计算
tqdm显示实时进度
outputs = net(val_images.to(device)) 将验证集像放入GPU并输入网络得到输出
predict_y = torch.max(outputs, dim=1)[1] 得到预测值
acc += torch.eq(predict_y, val_labels.to(device)).sum().item() 准确计数
val_accurate = acc / val_num 计算准确率
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
预测脚本基本和之前的Lenet一致
Image.open打开图像
data_transform做图像预处理,这里的预处理方法都有讲解过
unsqueeze调整维度,将batch维度压缩掉
json.load 加载类别映射
model = AlexNet(num_classes=5).to(device) 创建模型实例
model.load_state_dict(torch.load(weights_path)) 加载模型权重
model.eval()设置为评估模式
with torch.no_grad(): 禁用梯度计算
torch.squeeze(model(img_batch.to(device))).cpu() 得到模型输出
predict = torch.softmax(output, dim=0) 转换为概率
predict_cla = torch.argmax(predict).numpy() 根据概率最大值获取预测类别
总结
以上就是今天要讲的内容

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)