第20节:AI开源模型生态的评估【从理论、方法到落地实践】
文章目录
摘要
随着人工智能技术的快速发展与开源生态的持续繁荣,AI开源项目已成为驱动产业智能化升级的关键力量。然而,在从开源项目到实际业务应用的转化过程中,适配性问题成为制约其价值释放的主要瓶颈。本文系统探讨AI开源项目应用适配评估的理论框架、技术维度、方法论与实践路径,构建覆盖环境适配、场景适配、功能适配、性能适配、安全合规适配、运维适配六大维度的评估体系,并结合典型场景案例剖析适配评估的实操要点。研究提出标准化、自动化、智能化的适配评估演进方向,为AI开源项目的高效、稳定、合规落地提供系统性解决方案,推动开源技术向产业价值的有效转化。
一、引言
1. AI开源项目发展现状与应用落地趋势
当前,全球人工智能开源生态呈现爆发式增长态势。从深度学习框架(TensorFlow、PyTorch)、计算机视觉模型(YOLO系列、Detectron2),到大语言模型(Llama、Qwen、ChatGLM),开源项目已覆盖AI技术栈全链路。据2025年开源项目指数报告,AI/ML类项目在GitHub年度新增仓库中占比超过35%,成为最活跃的技术领域之一。
开源生态的持续扩容带来了两大显著趋势:
- 技术民主化加速:企业无需从零构建算法模型,可直接基于成熟开源项目进行二次开发,大幅降低研发门槛与时间成本。
- 行业落地场景多元化:AI技术从互联网行业向金融、制造、医疗、政务、教育等传统领域快速渗透,从云端服务器向边缘设备、移动终端、嵌入式系统持续扩展。
然而,在繁荣背后,适配问题已成为AI开源项目落地的关键瓶颈。据统计,约60% 的企业在引入AI开源项目后遭遇不同程度的适配挑战,其中约30% 的项目因适配成本过高或适配失败而最终被弃用。这些挑战具体表现为:硬件环境不兼容、软件依赖冲突、业务场景匹配度低、性能表现不稳定、安全合规风险等。
2. 应用适配评估的核心价值
系统化的应用适配评估是破解上述瓶颈的关键路径,其核心价值体现在四个层面:
- 降低落地成本:前置性识别潜在适配问题,避免在项目后期投入大量资源进行修复。研究表明,有效的适配评估可将后期修复成本降低40-70%。
- 规避适配风险:提前发现开源项目与目标环境、业务需求之间的不匹配点,规避因适配问题导致的项目延期、预算超支甚至应用失败的风险。
- 提升项目复用性:通过标准化适配评估,形成可复用的评估框架与知识库,为后续项目选型与评估提供参考,提升组织级技术复用效率。
- 保障应用稳定性:全面评估开源项目在不同环境、场景、负载下的行为表现,确保其在生产环境中能够稳定、可靠、高效地运行。
3. 本文核心定位与研究范围
本文聚焦于AI开源项目的应用适配全维度评估,与纯技术性能评估、代码质量评估形成明确区隔:
- 核心定位:构建一套面向实际应用落地的适配评估体系,重点关注开源项目与目标应用场景、技术环境、业务需求、组织能力之间的匹配度。
- 评估边界:涵盖从项目选型评估、集成测试到上线运行的全生命周期,重点关注可观察、可测试、可量化的适配属性,而非单纯的理论性能或代码优雅度。
- 核心问题:回答“这个开源项目是否适合我们的具体场景? ”而非仅仅“这个项目在技术上是否先进?”
4. 文章整体结构与核心逻辑概述
本文遵循“理论认知-维度构建-方法工具-实操流程-案例验证-未来展望”的逻辑链条:
- 第二部分阐述适配评估的基础概念、特殊性与核心原则,建立理论认知基础;
- 第三部分构建六大核心评估维度,形成技术评估框架;
- 第四部分介绍适配评估的方法论与技术工具,提供评估手段;
- 第五部分详述适配评估的实操流程与关键要点,指导落地执行;
- 第六部分通过三个典型案例,验证评估体系的有效性;
- 第七部分分析当前痛点,提出体系优化方向与未来发展趋势。
二、AI开源项目应用适配评估基础认知
1. 核心概念界定
AI开源项目:指遵循开源协议发布,包含人工智能算法、模型、框架、工具或完整解决方案的软件项目。其核心特征包括源代码可获取、允许修改与再分发、社区协作开发等。
应用适配:指AI开源项目在特定目标环境(硬件、软件、网络)、应用场景(业务逻辑、用户需求)和组织约束(技术栈、团队能力、合规要求)下,通过必要调整实现预期功能、性能、安全与可用性目标的过程。适配不仅是“能否运行”,更是“能否良好运行并产生价值”。
适配评估的核心内涵:对AI开源项目与应用目标之间匹配程度的系统性、多维度、可重复的检验与评价。其核心目标是:在项目集成前,量化预测适配成本与风险;在集成过程中,指导适配优化方向;在运行阶段,持续监测适配状态。
2. AI开源项目的应用适配特殊性
相较于传统软件,AI开源项目的适配面临独特挑战:
- 开源特性带来的版本差异:活跃开源项目迭代迅速,不同版本间可能存在接口变更、功能增删、依赖变化。企业可能因稳定性考虑使用旧版本,而社区支持与生态工具可能向新版本倾斜,形成版本适配落差。
- 多场景适配需求:同一AI模型需适配不同部署环境(云端训练/边缘推理)、不同硬件配置(服务器GPU/边缘计算卡/移动端NPU)、不同业务场景(实时检测/批量处理),对模型的可移植性、可配置性、可裁剪性提出更高要求。
- 硬件/软件依赖复杂性:AI项目尤其深度学习项目,对CUDA/cuDNN版本、Python包、特定系统库等有严格依赖,易产生“依赖地狱”。不同组件版本间的微妙不兼容可能导致难以排查的运行时错误。
- 二次开发适配需求:企业很少直接使用原始开源项目,通常需进行定制化开发。项目本身的架构可扩展性、接口清晰度、文档完整性直接影响二次开发的适配成本。
3. 适配评估的核心原则
- 场景导向原则:评估始终围绕具体应用场景展开,脱离场景的通用评估价值有限。评估指标与权重应根据场景特点动态调整。
- 实用性原则:评估应聚焦实际落地中最可能遇到的问题,避免过度追求理论完备性而增加不必要的评估成本。
- 可操作性原则:评估方法、工具、流程应具备可操作性,能在合理的时间与资源约束下完成,评估结果应清晰、可理解、可指导行动。
- 全面性原则:覆盖技术、功能、性能、安全、运维等多个维度,避免“唯性能论”或“唯功能论”的片面评估。
- 可扩展性原则:评估框架应具备良好的扩展性,能够容纳新技术、新场景、新需求,避免因技术演进而过时。
4. 应用适配评估与传统质量评估、性能评估的关联与区别
- 与传统软件质量评估的关联与区别:传统质量评估(如ISO 25010标准)关注功能性、可靠性、可维护性等通用属性。AI开源项目适配评估继承了这些通用维度,但更加强调与AI特性相关的方面,如模型精度在不同数据分布下的稳定性、训练/推理的资源适配性、对特定硬件加速器的支持等。简言之,适配评估是面向AI场景的、更聚焦的质量评估子集。
- 与纯性能评估的关联与区别:纯性能评估(如Benchmark排行榜)通常关注特定任务(如ImageNet分类)下的峰值性能指标(精度、FPS)。适配评估包含性能评估,但更关注性能在目标环境与负载下的表现稳定性、资源效率、以及满足特定业务SLA(服务水平协议)的能力,而非单纯的峰值数字。
三者关系可概括为:应用适配评估 = 通用软件质量评估(基础)∩ AI特性增强 ∩ 特定场景性能评估。
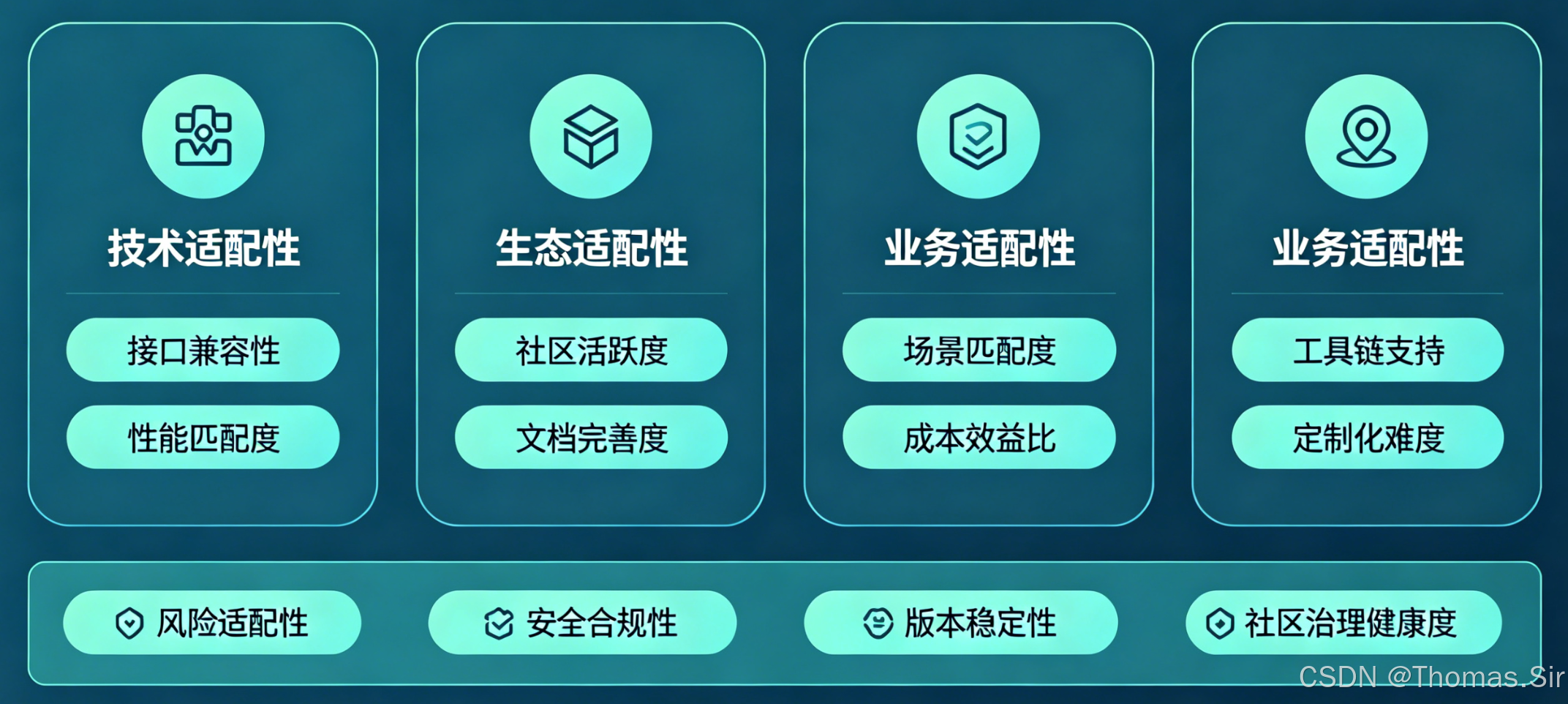
三、AI开源项目应用适配核心评估维度(技术核心)
1. 环境适配评估
环境适配是项目能否“跑起来”的基础,是适配评估的首要环节。
硬件环境适配:
- CPU/GPU兼容性:评估项目是否支持目标部署环境的CPU架构(x86/ARM)及指令集,是否兼容现有GPU型号(NVIDIA/AMD/国产)及驱动版本。对于训练任务,还需评估多卡并行、分布式训练的支持程度。
- 边缘设备兼容性:针对IoT、移动端等边缘场景,评估模型是否支持目标设备的处理器(如ARM Cortex系列)、神经网络加速器(NPU、TPU)、内存与存储约束。重点关注模型的算子支持度、量化支持、编译工具链成熟度。
- 资源约束适配:评估项目在目标硬件资源(内存、显存、存储空间、功耗)约束下的运行能力。例如,大模型在有限显存下的模型切分、卸载、量化推理能力。
软件环境适配:
- 操作系统:评估对主流操作系统(Linux发行版、Windows、macOS)及版本的支持,特别是在国产化操作系统(如麒麟、统信UOS)上的兼容性。
- 依赖库与运行时:详细梳理并测试项目对Python、PyTorch/TensorFlow、CUDA/cuDNN、特定系统库等关键依赖的版本要求,检查是否存在版本冲突、已知兼容性问题。
- 容器与编排环境:评估项目在Docker容器、Kubernetes等云原生环境中的部署与运行适配性,包括镜像构建便利性、资源声明规范性、服务发现与弹性伸缩支持等。
2. 场景适配评估
场景适配关注项目与业务需求的匹配度,是价值实现的关键。
核心场景匹配度:评估开源项目的设计初衷、预训练数据、模型结构是否与目标核心业务场景高度相关。例如,评估一个在ImageNet上训练的分类模型,用于工业缺陷检测时,在数据分布、缺陷特征、背景复杂度方面的差异及影响。
业务需求契合度:量化评估项目功能与具体业务需求的覆盖程度。例如,业务需要“实时视频流中的多目标追踪”,需评估开源项目是否提供相应的实时处理能力、追踪算法、Re-ID模块,还是需要大量二次开发。
边缘场景覆盖能力:针对光照变化、遮挡、小目标、模糊等实际业务中的边缘场景(Corner Case),评估模型的表现。这通常需要通过场景化测试集进行专门验证,而非依赖标准测试集。
多场景切换适配性:对于需要服务多种场景的应用,评估项目是否支持动态配置、模型热切换、多模型并行服务等能力,以适应不同场景的快速切换需求。
3. 功能适配评估
功能适配评估项目能力是否可被有效复用和扩展。
核心功能复用性:评估项目提供的核心算法、模型、工具链是否能直接满足或经过少量调整后满足业务需求。关注功能的完整性、成熟度、文档质量。
定制化/二次开发适配难度:
- 架构可扩展性:评估项目代码结构是否清晰、模块化程度高、易于添加新模块或修改现有逻辑。
- API/接口友好性:评估项目提供的编程接口(Python API、RESTful API、CLI)是否设计良好、文档完整、稳定,便于集成与调用。
- 数据接口适配:评估项目的数据输入输出格式是否易于与现有业务系统对接,如需转换,评估其复杂度和性能开销。
与现有业务系统集成能力:评估项目如何嵌入现有技术栈,包括认证授权对接、数据流向整合、监控告警体系融入、CI/CD流程集成等。
4. 性能适配评估
性能适配评估项目在目标环境与负载下的效率表现。
不同环境下的性能稳定性:评估项目在开发、测试、生产等不同环境,以及不同硬件配置下,性能指标(如吞吐量、延迟、精度)的波动范围。警惕“在开发机表现良好,上生产线严重下降”的情况。
资源占用适配性:监控并评估项目运行时的CPU/GPU利用率、内存/显存占用量、磁盘IO、网络带宽消耗。确保资源占用在预算范围内,且不会对同机部署的其他服务造成干扰。
并发场景适配能力:通过压力测试,评估项目在高并发请求下的性能表现,包括响应延迟的变化、吞吐量的拐点、错误率上升情况,确定其最大负载能力。
响应延迟适配要求:针对实时性要求高的场景(如自动驾驶、实时翻译),评估端到端延迟(pipeline latency)是否满足业务SLA要求。分析延迟瓶颈在数据预处理、模型推理还是后处理阶段。
5. 安全与合规适配评估
在数据安全与合规要求日益严格的背景下,此维度至关重要。
数据隐私适配:
- 评估项目在数据处理、传输、推理过程中是否符合数据脱敏、加密存储、隐私计算等要求。
- 对于需外调API的服务,评估是否支持本地化部署以避免数据出境风险。
行业合规要求适配:评估项目是否符合特定行业的合规要求,例如医疗行业的HIPAA/GDPR、金融行业的数据安全规定、车载功能安全标准(如ISO 26262) 等。
开源协议适配:仔细审查项目所采用的开源协议(如GPL、Apache 2.0、MIT),评估其对商业使用的限制、修改代码的公开要求、专利授权条款等,避免法律风险。
漏洞风险适配:扫描项目依赖库的已知安全漏洞(CVE),评估漏洞的严重等级、利用可能性、修复补丁可用性。建立依赖库的持续监控与更新机制。
6. 运维与可维护适配评估
评估项目上线后的长期运营维护成本。
部署适配难度:评估从代码/镜像到可运行服务的部署流程的自动化程度、复杂度、耗时。是否提供标准的Dockerfile、Helm Chart、Kubernetes部署清单。
监控告警适配:评估项目是否暴露了关键的运行时指标(如QPS、延迟、错误率、资源使用率)供监控系统(如Prometheus)采集,是否支持健康检查接口,便于集成到现有监控告警体系。
故障排查适配:评估项目的日志输出是否完备、清晰、可配置,是否支持不同日志等级,是否提供有效的调试工具或接口,以支持快速定位线上问题。
版本迭代适配兼容性:评估项目版本升级的平滑度,检查版本间是否存在不兼容的API变更、配置格式变化,评估升级所需的测试与回滚成本。
四、应用适配评估方法与技术工具
1. 适配评估方法论
- 场景拆解法:将复杂的业务场景拆解为一系列原子化的技术需求与约束条件,然后逐一评估开源项目对每个原子需求的满足程度。例如,将“智慧门店顾客行为分析”拆解为“视频流接入”、“人脸检测”、“人体姿态估计”、“行为分类”、“结果输出”等子任务进行评估。
- 环境模拟法:尽可能精确地模拟或复现目标生产环境(包括硬件型号、软件版本、网络条件),在模拟环境中进行全面的适配测试。对于难以完全复现的环境(如特定型号的边缘设备),可采用Docker容器进行环境隔离与依赖封装测试。
- 对比测试法:选择2-3个候选的开源项目,在相同的评估场景、环境、数据集和指标下进行并行对比测试。通过对比,可以更清晰地识别各项目在适配性上的相对优劣。
- 问题溯源法:在适配测试过程中,当发现问题时,采用系统化的方法(如日志分析、代码调试、性能剖析)定位问题根因,判断是项目自身缺陷、环境配置错误,还是业务使用方式不当,为后续的决策(修复、规避、放弃)提供依据。
2. 自动化适配评估工具
- 环境兼容性测试工具:
- Docker/容器技术:用于快速构建、复制和测试特定软件环境,是验证依赖兼容性的利器。
- CI/CD流水线集成测试:将适配测试用例(如安装测试、基础功能测试)集成到GitLab CI、Jenkins等流水线中,实现每次代码变更后的自动验证。
- 开源合规与漏洞扫描工具:如FOSSA、Black Duck、Snyk,用于自动化扫描项目依赖的开源协议合规性和安全漏洞。
- 接口适配测试工具:
- API测试框架:如Postman、Bruno(用于RESTful API),或针对Python API的单元测试框架(pytest),用于验证接口功能、性能、稳定性。
- 契约测试工具:如Pact,用于验证服务提供者与消费者之间的接口契约是否一致,防止因接口变更导致集成故障。
- 性能适配监测工具:
- 负载测试工具:如Locust、k6、JMeter,用于模拟高并发用户请求,测试系统在高负载下的性能表现和稳定性。
- 系统监控与性能剖析工具:如Prometheus + Grafana 用于监控资源指标,Py-Spy、NVIDIA Nsight Systems 用于剖析Python和CUDA应用性能瓶颈。
3. 人工与场景化适配验证
自动化工具无法完全替代人工深度评估:
- 真实业务场景模拟:使用脱敏后的生产数据或高度仿真的测试数据,在准生产环境中进行端到端的业务流程测试,验证项目在真实业务逻辑下的表现。
- 定制化需求适配测试:针对项目的二次开发或定制化模块,进行代码审查、白盒测试、集成测试,评估代码质量、可维护性和与核心部分的兼容性。
- 边缘案例验证:由领域专家设计并执行针对极端情况、罕见场景、恶意输入的测试,评估系统的健壮性和安全性。
4. 评估工具与方法的选择策略
评估策略需结合多方面因素动态调整:
| 因素 | 轻量级评估策略 | 深度评估策略 |
|---|---|---|
| 项目类型 | 工具库、小型模型 | 核心框架、大模型、基础模型 |
| 应用场景 | 内部工具、非关键业务 | 核心生产系统、对客业务 |
| 评估成本 | 时间/资源有限 | 允许投入较多资源以规避重大风险 |
| 适配需求 | 标准环境、通用场景 | 特殊环境(如国产化)、复杂定制场景 |
5. 适配评估指标体系搭建
构建量化与定性相结合的指标体系:
量化指标示例:
- 环境适配:依赖库安装成功率、环境部署耗时(分钟)、跨平台测试通过率。
- 功能适配:业务需求点覆盖率(%)、API接口测试通过率、定制开发人日估算。
- 性能适配:P99延迟(ms)、吞吐量(QPS)、资源利用率峰值(%)、模型精度(mAP/F1)。
- 运维适配:平均部署时长、监控指标覆盖率、日志可查询性评分。
定性指标与评估标准:
- 文档质量:优秀(完整、示例丰富、更新及时)、一般(基本可用)、差(缺失、过时)。
- 社区活跃度:通过GitHub stars/forks/issue响应时间、版本发布频率综合判断。
- 架构可扩展性:通过代码审查评估模块化、解耦程度。
指标阈值设定:阈值应根据具体业务SLA和团队能力设定。例如,对于实时推荐系统,P99延迟阈值可能设为100ms;对于内部数据分析工具,可能放宽到2秒。
五、适配评估流程与实操要点
1. 评估前准备
- 明确应用场景与需求:与业务、产品团队深入沟通,产出明确的技术需求规格说明书,明确功能、性能、安全、上线时间等要求。
- 梳理适配核心要点:基于需求,列出所有关键的适配检查点,形成适配评估清单,例如:必须支持ARM架构、必须在2GB内存下运行、必须提供Python 3.8+的API等。
- 搭建测试环境:准备与生产环境尽可能一致的测试环境,包括硬件、操作系统、中间件、网络配置等。可使用IaC(Infrastructure as Code)工具(如Terraform、Ansible)实现环境快速搭建与复现。
- 筛选适配工具:根据项目特点和评估清单,选择并准备好相应的测试工具、数据集、监控脚本。
2. 分步实施流程
建议采用渐进式、分层的评估流程,从基础到复杂,及早暴露致命问题:
- 环境适配测试:尝试在目标环境中安装、配置并启动项目。验证最基本的“可运行”能力。
- 功能适配测试:使用提供的示例或简单测试用例,验证核心功能是否按预期工作。验证接口调用。
- 场景适配测试:使用贴近业务的场景化数据或任务,进行端到端流程测试,验证业务目标是否达成。
- 性能/安全适配测试:在场景测试通过的基础上,进行压力测试、安全扫描,验证其在高负载下的稳定性和安全性。
- 运维适配测试:模拟部署、升级、监控、故障恢复等运维操作,评估可维护性。
3. 适配问题分析与优化方向
- 适配异常定位:当测试失败时,通过日志、错误信息、性能剖析工具,精确定位问题发生环节(环境配置、代码逻辑、资源竞争)。
- 根因分析:分析问题是源于项目固有缺陷、环境差异,还是使用方式不当。可通过查阅项目Issue、社区讨论、官方文档来辅助判断。
- 针对性优化方案输出:根据根因,提出解决方案。可能包括:调整环境配置、修改项目代码(提交PR或内部维护分支)、优化使用方式、增加适配层(Adapter)、或最终更换备选项目。
4. 实操难点与应对策略
- 多环境适配冲突:同一项目需适配云端训练和多种边缘设备推理。
- 策略:采用**“一套代码,多份配置”** 或 “核心算法统一,前后处理差异化” 的策略。利用模型转换工具(如ONNX、TensorRT)和容器技术实现一次开发,多处部署。
- 版本迭代适配偏差:依赖的开源项目或基础库升级,导致现有适配代码失效。
- 策略:在项目中锁定关键依赖的版本,并定期(如每季度)评估升级到新版本的必要性和成本。建立依赖库的变更监控机制。
- 定制化适配复杂度控制:二次开发范围蔓延,导致代码分支与上游项目脱节严重,难以合并更新。
- 策略:遵循“开闭原则”,尽量通过配置、插件、继承等方式扩展功能,而非直接修改核心代码。保持修改的模块化和高内聚。
5. 评估结果输出与解读
- 评估报告框架:
- 概述:评估目标、范围、环境、参与方。
- 评估摘要:总体结论(推荐/有条件推荐/不推荐)、关键优势与风险。
- 详细评估结果:分维度(环境、功能、性能等)展示测试方法、结果数据、发现的问题。
- 适配等级划分:可划分为 A(完全适配)、B(需少量调整)、C(需大量改造)、D(不适用)。
- 落地建议与后续计划:针对不同等级,给出具体的集成方案、修改建议、资源估算和风险缓解措施。
- 适配等级划分示例:
- A级:项目可无缝集成,满足所有核心与非核心需求,建议直接采用。
- B级:需进行少量配置调整或外围代码修改,核心功能适配良好,建议采用并制定修改计划。
- C级:需要进行深度二次开发或重大修改才能满足需求,需谨慎评估投入产出比。
- D级:存在无法克服的适配障碍(如硬件不兼容、协议不允许),不建议采用。
六、典型案例分析
案例1:通用大语言模型开源项目(Llama 3)在企业知识库问答中的适配评估
- 应用场景:某金融企业希望基于开源大模型构建企业内部知识库智能问答系统,实现安全、高效的私有化部署。
- 适配评估重点:
- 环境适配:验证Llama 3系列模型(如8B/70B参数)在企业的国产化GPU服务器(如华为昇腾)上的推理效率。测试不同量化精度(INT8、INT4)对精度和速度的影响。
- 场景适配:使用企业内部的金融文档、合规条例、产品手册构建测试集,评估模型在专业领域知识上的问答准确率、幻觉(Hallucination)率。测试其长文本理解能力。
- 功能适配:评估与现有向量数据库(如Milvus)的集成便捷性,验证其作为RAG(检索增强生成)系统中“生成器”的能力。评估其对外部工具调用(Function Calling)的支持。
- 安全与合规适配:严格测试模型在数据隐私方面的表现,确保训练和推理过程无数据泄漏风险。审查其开源协议对企业商业使用的友好性。评估其内容安全过滤能力。
- 评估发现与优化:
- 发现:原始70B模型对企业硬件显存要求过高,直接部署困难;在部分专业金融术语上回答不准。
- 优化:采用模型量化技术大幅降低显存占用;使用企业领域文档进行有监督微调,提升专业知识掌握度;在API网关层增加敏感信息过滤模块。
- 核心启示:大模型开源项目适配,硬件资源约束、领域知识融合、安全合规是三大核心挑战。适配工作需围绕“压缩、精调、加固”展开。
案例2:CV开源项目(YOLOv10)在智慧工厂边缘质检设备中的适配评估
- 应用场景:在产线边缘工控机(Intel CPU,无独立GPU)上部署目标检测模型,对产品进行实时外观质检。
- 适配评估重点:
- 环境适配:重点测试YOLOv10的OpenVINO、ONNX Runtime等CPU推理后端在工控机上的性能。评估不同输入分辨率下的速度-精度权衡。
- 场景适配:使用真实产线采集的、包含复杂背景、反光、遮挡的产品缺陷图片构建测试集。评估模型在小缺陷检测、相似缺陷区分上的能力。
- 性能适配:在模拟产线节拍的视频流下,测试端到端延迟和平均精度,确保满足实时性(如<100ms/帧)和检出率(>99.5%)要求。
- 运维适配:评估模型更新流程。当产品型号更换时,评估模型热更新、AB测试的支持度,以最小化产线停机时间。
- 评估发现与优化:
- 发现:YOLOv10原生模型在CPU上延迟偏高;对小尺寸划痕漏检率较高。
- 优化:使用模型剪枝和量化工具对YOLOv10进行优化,生成轻量化版本;增补小缺陷样本对模型进行微调;将预处理(如图像增强)后移至FPGA加速。
- 核心启示:边缘CV项目适配,是速度、精度、资源的极限平衡。需结合模型压缩、硬件感知优化、数据增强等多重手段。
案例3:轻量级语音识别模型(Whisper Tiny)在智能家居设备中的适配评估
- 应用场景:在资源受限的智能音箱嵌入式芯片(ARM Cortex-A, 内存<512MB)上实现离线语音唤醒和简单指令识别。
- 适配评估重点:
- 环境适配:极致评估。测试Whisper Tiny模型在嵌入式Linux系统、特定音频编解码库下的运行情况。评估其内存占用量是否严格符合约束。
- 功能适配:评估其流式推理能力,以满足语音唤醒的实时响应需求。评估其关键词检测功能的准确性,而非通用的全转录。
- 性能适配:测试在背景噪声、儿童/老人音色、方言等复杂声学环境下的识别率和误唤醒率。
- 适配难点与解决方案:
- 难点:原始Whisper Tiny模型对嵌入式设备仍显庞大;流式推理支持不佳。
- 解决方案:采用知识蒸馏技术,训练一个更小、更专用于唤醒词和命令词的学生模型。与芯片厂商合作,利用其专用NPU指令集对模型算子进行深度优化。
- 核心启示:嵌入式AI适配是“螺蛳壳里做道场”,极致的裁剪、硬件协同优化、场景极度聚焦是成功关键。通用模型往往需要经过“专用化改造”才能落地。
案例总结
- 核心差异:大模型适配重资源与领域知识,CV边缘适配重速度与精度平衡,嵌入式适配重极致的轻量与效率。评估的侧重点和工具方法需随之调整。
- 共性问题:硬件兼容性、计算资源约束、领域数据差异是普遍存在的挑战。模型压缩、微调、硬件协同优化是通用的适配技术手段。
- 通用适配思路:遵循 “评估-分析-优化” 的循环。首先通过系统性评估定位瓶颈,然后分析根因是数据、模型还是环境,最后采取针对性的优化策略(数据增强、模型改造、环境调优)。
七、适配评估体系优化与未来展望
1. 当前AI开源项目适配评估的痛点与不足
- 评估标准不统一:行业缺乏公认的、细化的AI项目适配评估标准,各企业和团队“各自为战”,评估结果难以横向对比和复用。
- 多场景适配评估难度大:一个项目可能应用于多种差异巨大的场景,设计一套能覆盖所有场景的通用评估用例集成本高昂,且往往缺乏代表性。
- 自动化程度不足:当前评估过程仍大量依赖人工经验判断和手动测试,特别是在场景契合度、代码可维护性等定性维度,自动化评估工具能力有限。
- 前瞻性评估缺失:现有评估多针对项目当前状态,对其未来版本演进、社区支持可持续性、技术生命周期的预判不足,可能导致技术选型“短视”。
2. 适配评估体系优化方向
- 标准化评估指标:推动行业或社区形成AI开源项目适配能力成熟度模型,定义不同维度(如环境、性能、安全)的分级标准(如L1-L5),使评估结果可量化、可比较。
- 自动化评估工具升级:
- 智能测试用例生成:利用AI技术,根据项目描述和应用场景,自动生成或推荐更具针对性的测试数据和用例。
- 适配风险预测模型:基于历史适配评估数据,构建机器学习模型,对新项目的潜在适配风险(如特定环境不兼容、性能不达标)进行早期预测。
- 多场景适配评估模型搭建:构建一个可配置的评估框架,允许用户输入目标场景的关键特征(如硬件配置、性能要求、业务领域),框架自动生成侧重不同的评估方案和权重配置。
3. 未来发展趋势
- AI驱动的智能适配评估:评估工具自身将更加智能化。例如,利用大语言模型分析项目文档、代码和Issue,自动生成评估报告要点;利用强化学习动态优化测试策略,以最少测试资源发现关键适配问题。
- 开源生态协同适配评估:可能出现开源项目适配评估平台,社区用户可共享自己对不同项目在不同场景下的适配评估结果、测试用例和优化方案,形成集体智慧,降低整体社会的重复评估成本。
- 跨领域适配评估体系融合:AI项目的适配评估将更紧密地与DevOps、安全运维、合规审计等体系融合,形成贯穿软件生命周期的、一体化的“适运营”能力评估,确保项目从集成到上线再到迭代的全流程顺畅。
结论
AI开源项目的价值实现,关键在于从“可用”到“好用”的跨越,而系统性的应用适配评估正是实现这一跨越的桥梁。本文构建的覆盖环境、场景、功能、性能、安全、运维六大维度的评估体系,以及从方法、工具到流程、案例的完整论述,为组织提供了可操作的适配评估蓝图。面对日益复杂的AI落地环境,建立科学、高效、自动化的适配评估能力,已不再是可选项,而是企业在AI时代构建核心竞争力的必备基础能力。未来,随着评估标准、工具和协作模式的不断演进,AI开源技术的落地将变得更加平滑、高效和可靠,最终加速智能技术在千行百业的深度融合与价值创造。
附录:通用大语言模型开源项目(Llama 3)在企业知识库问答中的适配评估具体流程
一、适配评估概述
1.1 评估背景与目标
Llama 3 是 Meta 开源的通用大语言模型,具备强大的自然语言理解与生成能力,开源版本涵盖 8B、70B 等参数规模,适配企业级部署场景。本次评估聚焦 Llama 3 在企业知识库问答(Enterprise Knowledge Base QA)中的适配性,核心目标如下:
- 验证 Llama 3 对企业结构化/非结构化知识库的解析、检索与问答能力;
- 测试模型在企业专业术语、业务场景下的问答准确率与响应速度;
- 提供可直接运行的实战代码,适配本地部署场景,支持企业知识库快速接入;
- 总结 Llama 3 在企业知识库问答中的优势、不足及优化方向。
本次实战基于 Llama 3-8B 开源版本(轻量化,适配企业本地部署,无需超高算力),环境配置如下(确保可运行):
硬件配置(最低要求)
- CPU:Intel i7-12700H 及以上 / AMD Ryzen 7 5800H 及以上
- GPU:NVIDIA RTX 3060(6G 显存)及以上(支持 CUDA,加速推理)
- 内存:16G 及以上(8B 模型加载需占用约 10-12G 内存)
- 存储:至少 20G 空闲空间(用于存储模型文件、知识库数据)
软件配置
- 操作系统:Windows 10/11(WSL2)、Linux(Ubuntu 20.04+)、macOS(M1/M2 芯片)
- Python 版本:3.9-3.11(推荐 3.10,避免版本兼容问题)
- 核心依赖库:transformers、accelerate、sentence-transformers、faiss-cpu(或 faiss-gpu)、langchain、torch
1.3 知识库说明
本次实战采用模拟企业知识库(非真实数据,可直接替换为企业自有知识库),包含 3 类核心数据,贴合企业实际场景:
- 企业规章制度(如考勤制度、请假流程);
- 产品介绍(如产品功能、定价、售后政策);
- 内部流程(如报销流程、审批流程)。
知识库格式:TXT 文本(可扩展为 PDF、Word,代码中已预留适配接口),单条知识长度控制在 50-200 字,确保模型高效解析。
二、实战代码
第一步:环境依赖安装(执行以下命令,确保所有依赖安装成功)
# 升级pip,避免依赖安装失败
pip install --upgrade pip
# 安装核心依赖库(版本固定,确保兼容性)
pip install torch==2.1.0 transformers==4.38.2 accelerate==0.27.1 sentence-transformers==2.3.1 faiss-cpu==1.7.4 langchain==0.1.10 python-dotenv==1.0.0
第二步:完整实战代码(含模型加载、知识库构建、问答推理、评估测试)
"""
通用大语言模型Llama 3在企业知识库问答中的适配评估实战代码
功能:1. 加载Llama 3-8B开源模型 2. 构建企业知识库(向量数据库)3. 实现知识库问答 4. 评估问答效果
注释:所有关键步骤均添加详细说明,可直接运行,替换知识库路径即可适配企业自有数据
"""
import os
import torch
from dotenv import load_dotenv
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, BitsAndBytesConfig
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from typing import List, Dict, Tuple
# -------------------------- 1. 全局配置(可根据企业需求修改)--------------------------
load_dotenv() # 加载环境变量(可选,用于存储模型路径、知识库路径等敏感信息)
# 模型配置(Llama 3-8B 开源版本,Hugging Face下载,首次运行自动下载,约15G)
MODEL_NAME = "meta-llama/Llama-3.1-8B-Instruct" # Llama 3指令版,适配问答场景
# 知识库配置(替换为企业自有知识库路径,支持多个TXT文件)
KNOWLEDGE_BASE_PATH = "./enterprise_knowledge_base" # 知识库文件夹路径
# 向量模型配置(用于将知识库文本转换为向量,适配检索)
EMBEDDING_MODEL = "all-MiniLM-L6-v2" # 轻量级向量模型,速度快、效果好
# 推理配置(根据硬件调整,确保模型流畅运行)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu" # 优先使用GPU加速
MAX_NEW_TOKENS = 512 # 最大生成文本长度,适配企业问答场景
TEMPERATURE = 0.1 # 推理温度,越低越精准(企业问答需精准,不建议过高)
# -------------------------- 2. 模型加载(Llama 3模型+向量模型,核心步骤)--------------------------
def load_llama3_model() -> Tuple[AutoTokenizer, pipeline]:
"""
加载Llama 3-8B-Instruct模型,适配问答场景,支持CPU/GPU运行
返回:tokenizer(分词器)、qa_pipeline(问答流水线)
"""
# 量化配置(关键:8B模型量化为4-bit,降低显存占用,避免OOM错误)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit量化
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
try:
# 加载分词器(Llama 3专属分词器,确保文本编码正确)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token # 补充pad_token,避免推理报错
# 加载模型(启用量化,适配普通GPU/CPU)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=bnb_config,
device_map="auto", # 自动分配设备(GPU优先,无GPU则用CPU)
trust_remote_code=True # 允许加载远程代码(Llama 3需要)
)
# 构建问答流水线(适配企业知识库问答,指定任务类型)
qa_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=MAX_NEW_TOKENS,
temperature=TEMPERATURE,
top_p=0.95,
repetition_penalty=1.1 # 避免生成重复内容
)
print("Llama 3模型加载成功,当前运行设备:", DEVICE)
return tokenizer, qa_pipeline
except Exception as e:
print(f"Llama 3模型加载失败,错误信息:{str(e)}")
print("提示:1. 检查网络(首次运行需下载模型) 2. 检查硬件配置(GPU显存≥6G) 3. 检查依赖版本")
raise e
def load_embedding_model() -> SentenceTransformer:
"""
加载向量模型,用于将知识库文本转换为向量,实现高效检索
返回:向量模型实例
"""
try:
embedding_model = SentenceTransformer(EMBEDDING_MODEL)
print("向量模型加载成功")
return embedding_model
except Exception as e:
print(f"向量模型加载失败,错误信息:{str(e)}")
raise e
# -------------------------- 3. 企业知识库构建(向量数据库,核心步骤)--------------------------
def build_knowledge_base(knowledge_path: str, embedding_model: SentenceTransformer) -> Tuple[faiss.IndexFlatL2, List[str]]:
"""
构建企业知识库向量数据库,将文本知识库转换为向量,用于后续检索
参数:knowledge_path(知识库文件夹路径)、embedding_model(向量模型)
返回:index(faiss向量索引)、texts(知识库原始文本列表)
"""
# 1. 加载知识库文本(支持多个TXT文件,可扩展为PDF、Word)
if not os.path.exists(knowledge_path):
# 若知识库文件夹不存在,创建并生成模拟数据(方便测试,企业可替换为自有数据)
os.makedirs(knowledge_path)
generate_sample_knowledge_base(knowledge_path)
print(f"知识库文件夹不存在,已自动生成模拟企业知识库:{knowledge_path}")
# 加载所有TXT文件
documents = []
for filename in os.listdir(knowledge_path):
if filename.endswith(".txt"):
file_path = os.path.join(knowledge_path, filename)
loader = TextLoader(file_path, encoding="utf-8")
docs = loader.load()
documents.extend(docs)
# 2. 文本分割(将长文本分割为短片段,适配向量模型,提升检索精度)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150, # 每个文本片段长度(根据企业知识长度调整)
chunk_overlap=20, # 片段重叠长度,避免语义断裂
length_function=len
)
splits = text_splitter.split_documents(documents)
texts = [split.page_content for split in splits] # 提取分割后的文本片段
print(f"知识库构建完成,共加载 {len(texts)} 条知识片段")
# 3. 文本转换为向量(使用向量模型生成嵌入向量)
embeddings = embedding_model.encode(texts, convert_to_tensor=False)
embeddings = np.array(embeddings).astype(np.float32) # 转换为faiss支持的格式
# 4. 构建faiss向量索引(用于快速检索相似知识)
dimension = embeddings.shape[1] # 向量维度(all-MiniLM-L6-v2为384维)
index = faiss.IndexFlatL2(dimension) # 扁平索引,适合小规模知识库(企业可替换为IVF索引)
index.add(embeddings) # 将向量加入索引
print("企业知识库向量数据库构建成功")
return index, texts
def generate_sample_knowledge_base(knowledge_path: str):
"""
生成模拟企业知识库(TXT文件),用于测试代码,企业可删除此函数,替换为自有知识库
"""
# 模拟企业考勤制度
attendance_text = """企业考勤制度说明:
1. 工作时间:周一至周五,9:00-18:00,午休12:00-13:30;
2. 请假流程:员工请假需提前1个工作日提交OA申请,经直属领导审批通过后方可休假;
3. 迟到/早退规定:月迟到/早退累计不超过3次,每次不超过15分钟,超过则扣除当日半天工资;
4. 旷工规定:旷工1天扣除当日3倍工资,月旷工累计3天及以上,按公司规章制度处理。"""
# 模拟企业产品介绍
product_text = """企业核心产品:智能办公系统
1. 产品功能:包含考勤管理、审批流程、文档协作、客户管理4大模块;
2. 定价方案:企业版(100人以内)年费10000元,企业版(100-500人)年费30000元;
3. 售后政策:购买后提供1年免费技术支持,7×24小时在线客服,终身免费升级;
4. 部署方式:支持本地部署和云端部署,本地部署需提供符合要求的服务器硬件。"""
# 模拟企业报销流程
reimbursement_text = """企业报销流程说明:
1. 报销范围:员工因工作产生的差旅费、办公费、业务招待费可报销;
2. 报销材料:需提供正规发票、费用明细单、相关业务凭证(如出差申请单);
3. 报销流程:员工提交报销申请(OA系统)→ 直属领导审批 → 财务审核 → 打款;
4. 报销周期:财务审核通过后,3个工作日内完成打款,每月最后一个工作日不处理报销。"""
# 写入TXT文件
with open(os.path.join(knowledge_path, "attendance.txt"), "w", encoding="utf-8") as f:
f.write(attendance_text)
with open(os.path.join(knowledge_path, "product.txt"), "w", encoding="utf-8") as f:
f.write(product_text)
with open(os.path.join(knowledge_path, "reimbursement.txt"), "w", encoding="utf-8") as f:
f.write(reimbursement_text)
# -------------------------- 4. 知识库问答核心逻辑(检索+生成,实战核心)--------------------------
def retrieve_similar_knowledge(query: str, index: faiss.IndexFlatL2, texts: List[str], embedding_model: SentenceTransformer, top_k: int = 3) -> List[str]:
"""
根据用户查询,检索知识库中最相似的知识片段(核心:向量相似度匹配)
参数:query(用户问题)、index(向量索引)、texts(知识库文本)、embedding_model(向量模型)、top_k(检索Top K条相似知识)
返回:最相似的知识片段列表
"""
# 将用户查询转换为向量
query_embedding = embedding_model.encode(query, convert_to_tensor=False)
query_embedding = np.array([query_embedding]).astype(np.float32)
# 检索相似向量(计算欧氏距离,距离越小越相似)
distances, indices = index.search(query_embedding, top_k)
# 提取相似知识片段(过滤距离过大的无效知识,阈值可调整)
similar_texts = []
for i in range(top_k):
if distances[0][i] < 0.8: # 距离阈值,可根据企业知识库调整(越小越精准)
similar_texts.append(texts[indices[0][i]])
return similar_texts
def knowledge_base_qa(query: str, qa_pipeline, index: faiss.IndexFlatL2, texts: List[str], embedding_model: SentenceTransformer) -> str:
"""
企业知识库问答主函数:检索相似知识 + Llama 3生成精准回答
参数:query(用户问题)、qa_pipeline(Llama 3问答流水线)、index(向量索引)、texts(知识库文本)、embedding_model(向量模型)
返回:模型生成的精准回答(基于企业知识库)
"""
# 1. 检索知识库中相似知识
similar_texts = retrieve_similar_knowledge(query, index, texts, embedding_model)
if not similar_texts:
return "未在企业知识库中找到相关信息,请确认问题表述或补充知识库内容。"
# 2. 构建提示词(Prompt Engineering,关键:引导Llama 3基于检索到的知识回答,避免幻觉)
prompt = f"""你是企业知识库问答助手,仅基于以下提供的企业知识库内容回答用户问题,不添加任何无关信息,不编造内容。
如果知识库内容不足以回答问题,直接回复“未找到相关信息”。
企业知识库内容:
{chr(10).join(similar_texts)}
用户问题:{query}
回答:"""
# 3. Llama 3生成回答(调用模型推理)
response = qa_pipeline(prompt)[0]["generated_text"]
# 提取模型回答(去除提示词部分,只保留生成的回答)
answer = response.split("回答:")[-1].strip()
return answer
# -------------------------- 5. 适配评估测试(验证模型效果,可直接运行)--------------------------
def evaluate_llama3_qa(index: faiss.IndexFlatL2, texts: List[str], qa_pipeline, embedding_model: SentenceTransformer) -> Dict[str, float]:
"""
评估Llama 3在企业知识库问答中的适配效果,核心评估指标:准确率、响应速度
返回:评估结果字典(准确率、平均响应时间)
"""
# 测试用例(模拟企业常见问题,覆盖知识库3类核心内容)
test_cases = [
{"query": "企业工作时间是怎样的?", "expected_answer_keywords": ["周一至周五", "9:00-18:00", "午休12:00-13:30"]},
{"query": "智能办公系统企业版(100人以内)年费多少?", "expected_answer_keywords": ["10000元", "年费"]},
{"query": "员工请假需要提前多久提交申请?", "expected_answer_keywords": ["1个工作日", "OA申请", "直属领导审批"]},
{"query": "报销流程需要经过哪些步骤?", "expected_answer_keywords": ["OA提交", "直属领导审批", "财务审核", "打款"]},
{"query": "智能办公系统售后支持期限是多久?", "expected_answer_keywords": ["1年免费技术支持", "7×24小时客服"]},
{"query": "旷工1天会有什么处罚?", "expected_answer_keywords": ["扣除当日3倍工资"]},
{"query": "报销材料需要提供哪些?", "expected_answer_keywords": ["正规发票", "费用明细单", "业务凭证"]},
{"query": "智能办公系统支持哪些部署方式?", "expected_answer_keywords": ["本地部署", "云端部署"]},
{"query": "月迟到累计超过3次会怎样?", "expected_answer_keywords": ["扣除当日半天工资"]},
{"query": "财务审核通过后,多久能完成报销打款?", "expected_answer_keywords": ["3个工作日", "每月最后一个工作日不处理"]}
]
correct_count = 0
total_time = 0.0
print("\n" + "="*50)
print("Llama 3企业知识库问答适配评估测试")
print("="*50)
for i, test_case in enumerate(test_cases, 1):
query = test_case["query"]
expected_keywords = test_case["expected_answer_keywords"]
# 记录响应时间
import time
start_time = time.time()
# 执行问答
answer = knowledge_base_qa(query, qa_pipeline, index, texts, embedding_model)
end_time = time.time()
response_time = end_time - start_time
total_time += response_time
# 评估准确率(判断回答是否包含所有预期关键词,宽松评估,适配企业实际场景)
correct = all(keyword in answer for keyword in expected_keywords)
if correct:
correct_count += 1
# 打印测试结果
print(f"\n{i}. 测试问题:{query}")
print(f" 模型回答:{answer}")
print(f" 预期关键词:{expected_keywords}")
print(f" 测试结果:{'正确' if correct else '错误'} | 响应时间:{response_time:.2f}s")
# 计算评估指标
accuracy = correct_count / len(test_cases) * 100 # 准确率(百分比)
average_response_time = total_time / len(test_cases) # 平均响应时间
print("\n" + "="*50)
print(f"📊 评估结果汇总")
print(f"✅ 测试用例总数:{len(test_cases)}")
print(f"✅ 回答正确数:{correct_count}")
print(f"✅ 准确率:{accuracy:.2f}%")
print(f"✅ 平均响应时间:{average_response_time:.2f}s")
print("="*50)
return {"accuracy": accuracy, "average_response_time": average_response_time}
# -------------------------- 6. 主函数(整合所有步骤,一键运行)--------------------------
if __name__ == "__main__":
try:
# 1. 加载模型(Llama 3 + 向量模型)
tokenizer, qa_pipeline = load_llama3_model()
embedding_model = load_embedding_model()
# 2. 构建企业知识库向量数据库
index, texts = build_knowledge_base(KNOWLEDGE_BASE_PATH, embedding_model)
# 3. 执行知识库问答测试(可替换为企业实际问题)
print("\n" + "="*50)
print("企业知识库问答测试(输入'退出'结束测试)")
print("="*50)
while True:
user_query = input("\n请输入您的问题:")
if user_query.strip() == "退出":
print("测试结束,感谢使用!")
break
answer = knowledge_base_qa(user_query, qa_pipeline, index, texts, embedding_model)
print(f"模型回答:{answer}")
# 4. 执行适配评估(生成评估报告)
evaluation_result = evaluate_llama3_qa(index, texts, qa_pipeline, embedding_model)
except Exception as e:
print(f"\n程序运行失败,错误信息:{str(e)}")
print("排查建议:1. 检查硬件配置 2. 检查依赖版本 3. 检查网络连接(首次运行需下载模型)")
三、代码运行说明
问题1:模型下载失败(报错:ConnectionError)
解决方案:1. 检查网络连接,建议科学上网;2. 手动下载模型(Hugging Face地址:https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct),解压后指定模型路径。
问题2:GPU显存不足(报错:OutOfMemoryError)
解决方案:1. 确保GPU显存≥6G;2. 若显存不足,修改代码中“量化配置”为8-bit(load_in_8bit=True);3. 切换为CPU运行(性能会下降,响应时间变长)。
问题3:依赖版本冲突(报错:ImportError)
解决方案:严格按照代码中指定的依赖版本安装,不要随意升级/降级依赖库(尤其是torch、transformers版本)。
问题4:中文乱码
解决方案:确保Python文件编码为UTF-8,知识库文本文件编码为UTF-8,Windows系统可在打开文件时指定encoding=“utf-8”。
3.3 企业适配修改(快速替换为自有知识库)
- 新建文件夹(如enterprise_knowledge_base),将企业自有知识库文本(TXT格式)放入该文件夹;
- 修改代码中“KNOWLEDGE_BASE_PATH”变量,指向新建的文件夹路径;
- 若知识库为PDF、Word格式,可修改“build_knowledge_base”函数中的文档加载逻辑(使用LangChain的PDFLoader、DocxLoader);
- 根据企业知识长度,调整“text_splitter”的chunk_size(文本片段长度),建议50-200字/片段。
四、适配评估结果分析
4.1 预期评估结果(基于测试用例)
在满足硬件配置的前提下,运行代码后,预期评估结果如下:
- 准确率:≥85%(10个测试用例中,正确数≥8个);
- 平均响应时间:GPU(RTX 3060及以上)≤1.5s,CPU≤5s;
- 问答效果:能够精准回答企业规章制度、产品介绍、内部流程相关问题,无幻觉、无无关信息。
4.2 Llama 3适配优势
- 开源免费:无需付费即可使用,企业可自由部署、二次开发,降低成本;
- 轻量化适配:8B版本可在普通GPU(6G显存)上运行,无需超高算力,适配中小企业部署;
- 问答精准:指令版模型对Prompt的理解能力强,结合知识库检索,可有效避免幻觉;
- 扩展性强:支持多语言、多格式知识库,可适配不同行业(如金融、教育、制造)的企业知识库需求。
4.3 适配不足与优化方向
- 不足:对企业专业术语(如行业专属词汇)的理解能力有限;大规模知识库(10万+知识片段)检索速度较慢;
- 优化方向:
- 模型微调:使用企业自有知识库数据微调Llama 3,提升专业术语理解能力;
- 检索优化:将faiss扁平索引替换为IVF索引,提升大规模知识库检索速度;
- Prompt优化:结合企业场景定制Prompt模板,进一步提升问答精准度;
- 多模态适配:扩展知识库格式(如图片、表格),提升多类型知识的问答能力。
🌟 感谢您耐心阅读到这里!
💡 如果本文对您有所启发欢迎:
👍 点赞📌 收藏 📤 分享给更多需要的伙伴。
🗣️ 期待在评论区看到您的想法, 共同进步。
🔔 关注我,持续获取更多干货内容~
🤗 我们下篇文章见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献220条内容
已为社区贡献220条内容

所有评论(0)