数据孤岛怎么破?JVS-BI 教你 5 分钟打通多源数据(附实操图解)
一、一个真实到扎心的场景
某电商公司,订单存在 MySQL,客户信息存在 SQL Server,推广成本每月由运营整理成 Excel。老板想看“不同渠道带来的客户复购率”,IT 部怎么做?
-
方案 A:写跨库 SQL?MySQL 和 SQL Server 不在同一个实例,需要开启 DBLink 或联邦查询,配置复杂且有性能风险。
-
方案 B:写 Python 脚本导出再合并?每次需求变化都要改代码,且业务人员无法自助。
-
方案 C:手工导出 Excel 再用 VLOOKUP?每次耗时 3 小时,还经常因为格式不对报错。
这就是典型的 数据孤岛——数据散落在不同系统、不同格式、不同位置,无法高效关联分析。
今天,我们使用 JVS-BI 这款开源、可私有化部署的自助式 BI 工具,全程不写一行 SQL,不迁移原始数据,5 分钟打通三个数据源,输出一张可用于图表的“宽表”。
二、为什么传统方式很难打通多源数据?
| 传统方式 | 痛点 |
|---|---|
| SQL 跨库查询 | 需要开启 DBLink / Federated 引擎,性能差,且不支持 NoSQL 或 Excel |
| ETL 工具(如 Kettle、DataX) | 需要写作业、配置复杂,业务人员无法独立完成 |
| 手工导出再关联 | 效率低、易出错、无法定时刷新 |
| 数据中台 | 建设周期长、成本高,中小企业负担不起 |
理想的方案应该是:
✅ 任意数据源(数据库、文件、API)都能接入
✅ 不需要编写复杂的 SQL 或脚本
✅ 支持跨源关联(MySQL 左连 Excel)
✅ 关联结果可保存为数据集,供图表/大屏直接使用
✅ 支持定时刷新,自动化
下面我们看 JVS-BI 如何做到。
三、JVS-BI 多源接入能力概览
JVS-BI 的数据源模块支持:
-
关系型数据库:MySQL、Oracle、PostgreSQL、SQL Server、MariaDB、DB2、达梦、人大金仓等
-
NoSQL 数据库:MongoDB
-
分析型数据库:ClickHouse、Doris、StarRocks、Presto
-
数据湖/仓:Apache Hive
-
文件:Excel(支持追加/覆盖上传)
-
接口:API、MQTT(实时)
-
低代码数据模型:JVS 自身的数据模型
最关键的能力:可以在同一个数据集加工流程中,混合使用不同类型的数据源,系统自动处理底层协议差异。

四、实操:5 分钟打通 MySQL + SQL Server + Excel
4.1 准备三个数据源(模拟真实环境)
-
MySQL(订单表):order_id, user_id, amount, order_date
-
SQL Server(客户表):user_id, user_name, register_date, city
-
Excel(渠道成本表):channel, cost, month
需求:生成一张分析表,包含 订单金额、客户城市、渠道成本,以便分析不同城市、不同渠道的 ROI。
4.2 步骤一:添加数据源
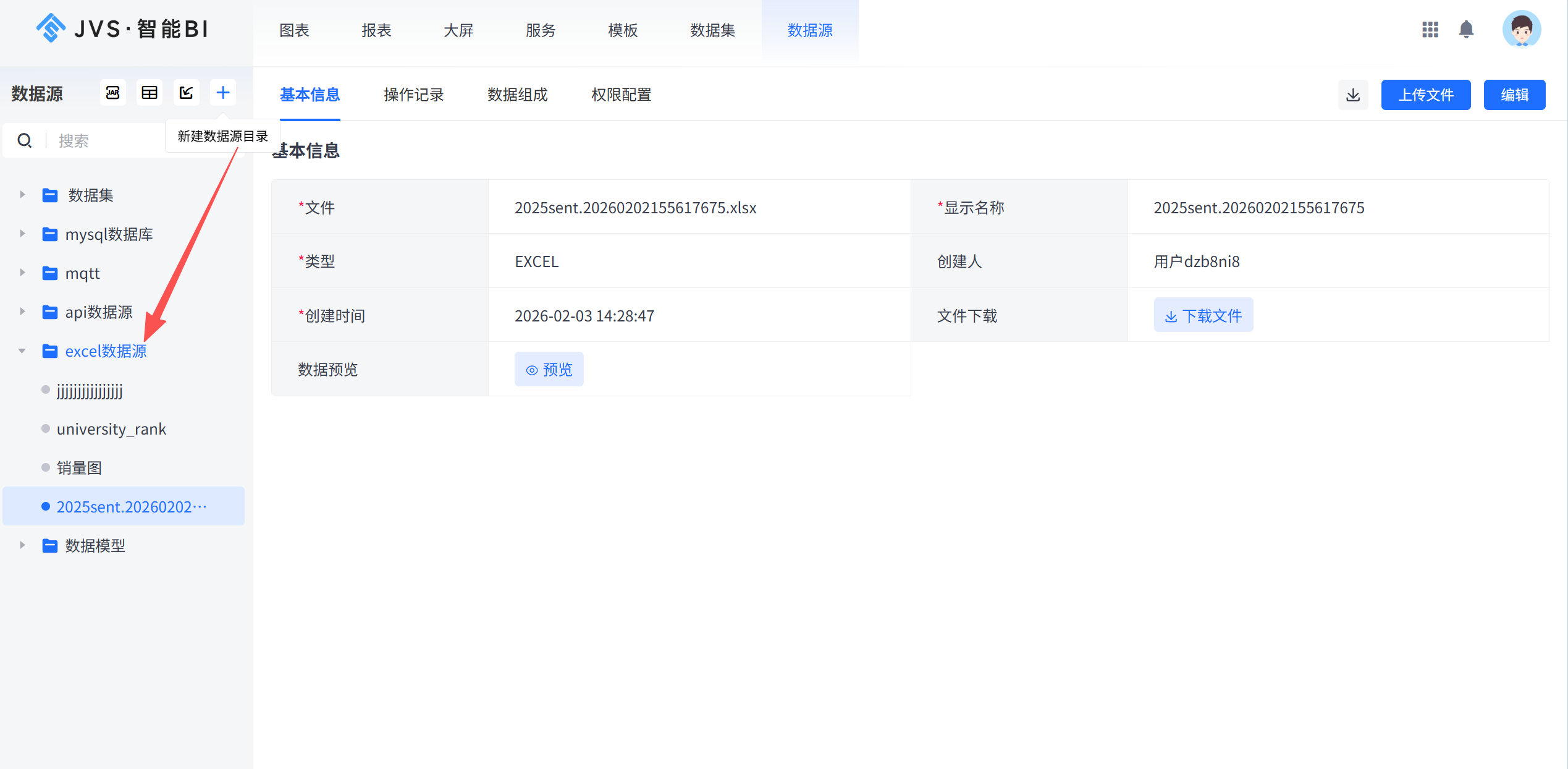
-
登录 JVS-BI,进入「数据源」模块。
-
点击「+」→ 选择 MySQL,填写 IP、端口、数据库名、账号密码,点击「校验」,通过后保存。
-
同样方式添加 SQL Server 数据源。
-
对于 Excel:点击「+」→ 选择 Excel,上传文件,系统自动读取表头(第一行为字段名),保存即完成。
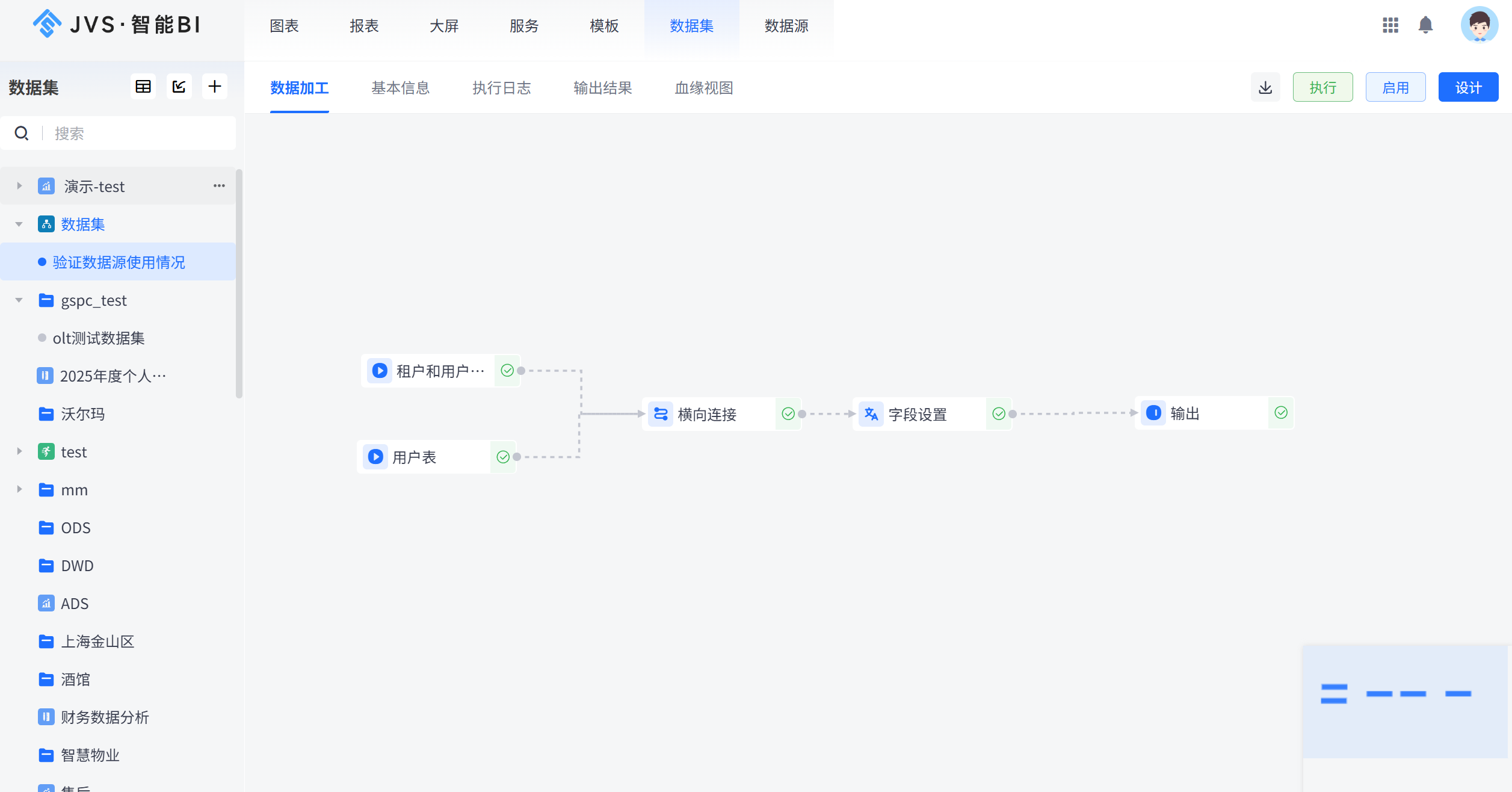
4.3 步骤二:新建数据集,拖拽式构建关联流程
-
进入「数据集」→ 新建数据集,命名“订单客户成本分析”。
-
进入数据设计器(可视化 ELT 画布)。
开始搭建节点:
-
拖入第一个「输入」节点:选择 MySQL 数据源中的「订单表」,勾选所有字段。
-
拖入第二个「输入」节点:选择 SQL Server 数据源中的「客户表」,勾选 user_id, user_name, city。
-
拖入「横向连接」节点:将两个输入节点连接到该节点。
-
连接类型:左连接(保留所有订单)
-
关联字段:左表
user_id= 右表user_id
-
-
再拖入第三个「输入」节点:选择 Excel 数据源中的「渠道成本表」。
-
再次拖入「横向连接」节点:将第一次连接的结果与 Excel 表连接。
-
由于订单表和成本表没有直接关联字段,这里通过「月份」关联(需要先提取订单表的月份)。
-
处理月份字段:
在第一次横向连接之后,拖入一个「数据拓展」节点,添加计算字段 order_month,公式为 DATE_FORMAT(order_date, '%Y-%m')。
然后在第二次横向连接中,左表用 order_month,右表用 month 字段关联。
-
最后拖入「输出」节点:保存最终结果。
4.4 步骤三:模拟建模,预览结果
点击画布上的任意节点,下方会实时展示该节点的数据预览。
点击最后的「输出」节点,可以看到已经合并好的宽表:包含订单金额、客户城市、渠道成本等字段。
整个过程不需要写一行 SQL,全部通过拖拽和点选完成。
4.5 步骤四:保存并用于图表
保存数据集后,进入「图表」模块,新建一个柱状图,选择该数据集,即可拖拽字段生成“各城市销售额与渠道成本对比”图表。
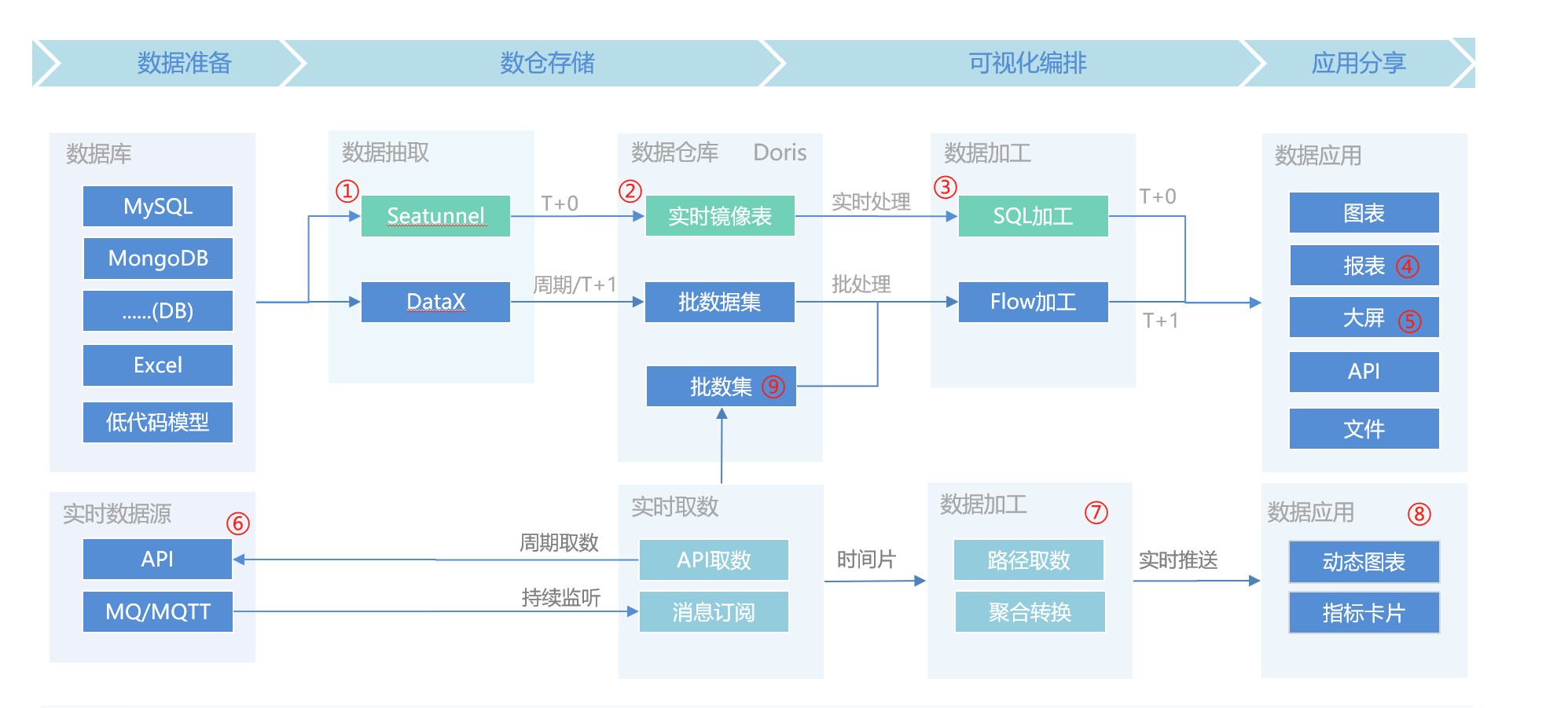
五、进阶:集中式数仓存储(不影响业务库性能)
上述示例是 直连查询模式,每次打开图表都会实时去源库查询。如果源库是生产库,频繁的大数据量关联查询可能影响业务。
JVS-BI 提供了第二种模式:集中式数仓存储。
工作原理:
-
通过 DataX 将各数据源的数据定时(如每天凌晨)抽取到内置的 Doris 数仓中。
-
数据集加工在 Doris 内部完成,完全不触碰业务库。
-
图表/报表查询 Doris,性能高且隔离。
配置方式:在数据集中,将「输入」节点的数据来源从「数据源」改为「数仓表」,并设置定时抽取任务即可。
六、常见问题与避坑指南(来自真实用户反馈)
Q1:Excel 上传后字段都是字符串,怎么计算数值?
A:在数据集中使用「字段设置」节点,将字段类型转换为数值(整数或浮点)。
Q2:跨源关联时,左右两边的字段类型不一致怎么办?
A:使用「数据拓展」节点,用公式将两边转为相同类型,例如 CAST(字段 AS STRING)。
Q3:数据量很大(千万级),直连查询很慢怎么办?
A:使用集中式数仓模式,或者在前置节点中加入「数据筛选」减少数据量。
Q4:Excel 每周更新,如何自动追加新数据?
A:在 Excel 数据源中,使用「上传文件」→ 选择「追加」模式,系统会自动将新数据添加到原表,且记录批次号。
Q5:能否让非技术人员自己配置关联?
A:可以。JVS-BI 的 ELT 画布完全可视化,业务人员经过 30 分钟培训即可独立完成简单关联。
七、总结与互动
数据孤岛的破局关键在于 工具要足够易用。JVS-BI 通过以下能力降低了跨源分析的门槛:
-
多源统一接入:数据库、文件、API 全支持
-
可视化 ELT:拖拽节点完成关联、筛选、计算
-
模拟建模:每一步都能预览,所见即所得
-
集中式数仓:可选,隔离业务系统压力
-
全源码开放:企业可二次开发,满足特殊需求
如果你也在被数据孤岛困扰,不妨下载 JVS-BI 社区版亲身体验。5 分钟,也许就能解决你一周的工作量。
📌 资源链接
Gitee 仓库(示例):https://gitee.com/software-minister/jvs-bi
欢迎在评论区分享你遇到过的数据孤岛场景,以及你是如何解决的。点赞、收藏、转发支持原创!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)