ACM MM2022 | Co-Attack | 面向视觉-语言预训练模型的对抗性攻击
·
Towards Adversarial Attack on Vision-Language Pre-training Models
该研究聚焦视觉-语言预训练(VLP)模型的对抗性攻击,首先通过分析不同攻击设置在两类 VLP 模型和三类下游任务中的表现,得出关键结论:扰动双模态输入比单模态更有效、攻击全嵌入比 [CLS] 嵌入(图像模态)或反之(文本模态)更优、ViT 作为图像编码器比 CNN 更鲁棒;随后提出协同多模态对抗攻击(Co-Attack),通过协同扰动图像与文本模态(先优化离散文本再优化连续图像),解决独立攻击的 “1+1<1” 抵消效应,实验表明其在各任务和模型上均优于基线方法,最终为 VLP 模型的攻击设计与鲁棒性提升提供指导。
引言-Introduction
- VLP 模型的重要性与研究背景
- 技术突破:视觉-语言预训练(VLP)模型近年来在各类视觉-语言(V+L)下游任务中实现革命性提升,典型任务包括图文检索、视觉定位、视觉蕴含,同时也重新激发了过去十年对多模态神经网络的研究关注。
- 研究缺口:尽管 VLP 模型在性能上取得显著进展,但针对其对抗鲁棒性的研究仍十分有限。现有少量相关研究仅针对单一模态进行扰动,采用标准单模态对抗攻击方法(如仅扰动图像或仅扰动文本),且未聚焦 VLP 模型这一特定多模态预训练架构。
- 现有研究的核心局限
- 方法适配性问题:标准对抗攻击方法最初为单模态分类任务设计,而 VLP 模型涉及图像、文本两种模态,且需处理图文检索等非分类任务,直接套用标准方法存在局限性。虽有研究尝试通过攻击嵌入表示而非下游任务标签来适配,但 VLP 嵌入表示结构复杂,尚未明确不同攻击设置对攻击效果的影响。
- 模态协同缺失:现有多模态攻击研究未考虑不同模态扰动的协同性,仅独立对图像、文本模态进行扰动。文中通过图1(视觉蕴含任务示例)指出,独立扰动双模态可能导致 “1+1<1” 的抵消效应——例如仅扰动图像可将模型预测从 “蕴含” 改为 “矛盾”,但同时独立扰动图像与文本时,两种单模态攻击可能相互冲突,反而导致攻击失败。
- 本文研究目标与核心工作
- 核心目标:针对上述局限,聚焦 VLP 模型的对抗攻击研究,填补其对抗鲁棒性分析与专用攻击方法的空白。
- 两大核心工作:
- 系统分析不同攻击设置下 VLP 模型的对抗攻击性能,明确攻击目标(如单模态嵌入、多模态嵌入)、扰动对象(如图像、文本、双模态)对攻击效果的影响,为后续攻击设计与模型鲁棒性提升提供指导。
- 提出一种专用的多模态对抗攻击方法,通过协同处理图像与文本模态的扰动,解决独立攻击的抵消效应,实现更强的 VLP 模型攻击效果。

预备知识-Preliminaries
VLP 模型与下游 V+L 任务
- VLP模型分类与结构
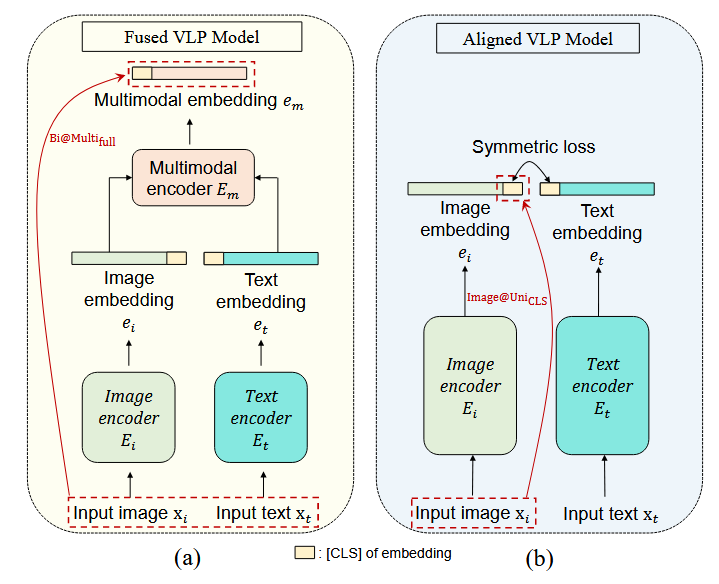
根据架构差异,VLP 模型分为两类,核心区别在于是否包含多模态编码器及输出嵌入类型:- 融合型 VLP 模型:以 ALBEF、TCL 为代表,包含三大组件——图像编码器 E i ( ⋅ ) E_i(\cdot) Ei(⋅)、文本编码器 E t ( ⋅ ) E_t(\cdot) Et(⋅)、多模态编码器 E m ( ⋅ , ⋅ ) E_m(\cdot,\cdot) Em(⋅,⋅)。输入图像 x i x_i xi 经 E i ( ⋅ ) E_i(\cdot) Ei(⋅) 编码为图像嵌入 e i e_i ei,输入文本 x t x_t xt 经 E t ( ⋅ ) E_t(\cdot) Et(⋅) 编码为文本嵌入 e t e_t et,两者再通过 E m ( ⋅ , ⋅ ) E_m(\cdot,\cdot) Em(⋅,⋅) 输出统一的多模态嵌入 e m e_m em,需依赖端到端图像编码器(如 ViT-B/16)加速推理,无需预训练目标检测器。
- 对齐型 VLP 模型:以 CLIP 为代表,仅包含图像编码器与文本编码器,无多模态编码器,仅输出独立的单模态嵌入(图像嵌入 e i e_i ei、文本嵌入 e t e_t et)。CLIP 的图像编码器可选 ViT-B/16(记为 CLIP V i T _{ViT} ViT)或 ResNet-101(记为 CLIP C N N _{CNN} CNN)。
- 下游 V+L 任务定义与实现逻辑
研究聚焦三类典型任务,各任务在不同 VLP 模型上的实现方式存在差异:- 图文检索(Image-Text Retrieval):含图像到文本(TR)、文本到图像(IR)两个子任务。 ALBEF、TCL 需先计算 e i e_i ei 与 e t e_t et 的特征相似度筛选候选,再通过 e m e_m em 的图文匹配分数排序;CLIP 直接基于 e i e_i ei 与 e t e_t et 的相似度排名。
- 视觉蕴含(Visual Entailment, VE):判断图像与文本的关系(蕴含/中性/矛盾),属三分类任务。ALBEF、TCL 通过多模态编码器输出的 [CLS] token 表示,经全连接层预测类别概率;CLIP 不支持该任务。
- 视觉定位(Visual Grounding, VG):根据文本描述定位图像区域。ALBEF 扩展 Grad-CAM 生成注意力图,对检测到的候选区域排序实现定位;TCL、CLIP 不支持该任务。
对抗攻击
- 单模态对抗攻击
- 计算机视觉(CV):对抗攻击技术成熟,以基于梯度的方法为主,如 FGSM、PGD、MIM、SI。研究中采用 ℓ ∞ \ell_\infty ℓ∞-范数约束图像扰动 δ i \delta_i δi,要求 ∥ δ i ∥ ∞ ≤ ϵ i \|\delta_i\|_\infty \leq \epsilon_i ∥δi∥∞≤ϵi( ϵ i \epsilon_i ϵi 为最大扰动幅度),可在连续像素空间高效生成对抗样本。
- 自然语言处理(NLP):因文本属离散 token 空间,对抗攻击难度更高。现有方法多通过修改/替换输入文本的部分 token(如 BERT-Attack),以最大化模型输出错误嵌入的风险,需平衡扰动幅度与语义一致性。
- 多模态神经网络对抗攻击
现有多模态攻击研究(如针对视觉问答、图文模型)与本文针对 VLP 模型的研究存在三大核心差异,凸显本文研究的必要性:- 模型架构适配性差:现有研究基于 CNN、RNN 架构设计攻击,方法与结论无法直接迁移至 Transformer-based VLP 模型(如 ALBEF、CLIP)。
- 任务覆盖范围有限:现有研究仅针对单一 V+L 分类任务(如视觉问答),攻击方法无法泛化到图文检索等非分类任务。
- 缺乏多模态协同设计:现有方法本质是 “单模态攻击的简单叠加”,仅独立扰动图像或文本模态,未考虑多模态间的交互关系,无法解决 VLP 模型多模态嵌入的攻击问题。
分析视觉语言预训练模型的对抗攻击-Analyzing Adversarial Attack In VLP Model
分析设置
- 实验对象:VLP 模型、下游任务与数据集
- VLP 模型:覆盖两类核心架构,确保分析全面性
- 融合型 VLP:ALBEF、TCL(含图像编码器 ViT-B/16、文本编码器 6 层 Transformer、多模态编码器 6 层 Transformer);
- 对齐型 VLP:CLIP(含两种图像编码器:ViT-B/16 记为 CLIP V i T _{ViT} ViT、ResNet-101 记为 CLIP C N N _{CNN} CNN,仅含单模态编码器)。
- 下游任务与数据集:匹配模型能力选择任务,保证数据有效性
- 图文检索(TR/IR):用 MSCOCO(5K 测试集)、Flickr30K(1K 测试集),CLIP、ALBEF、TCL 均支持;
- 视觉蕴含(VE):用 SNLI-VE 测试集,仅保留 “蕴含” 标签的正向样本(聚焦攻击性能),ALBEF、TCL 支持,CLIP 不支持;
- 视觉定位(VG):用 RefCOCO+ 数据集,仅 ALBEF 支持。
- 攻击参数:统一设置确保对比公平性
- 图像模态攻击:采用 PGD 方法,最大扰动 ϵ i = 2 / 255 \epsilon_i=2/255 ϵi=2/255,步长 1.25,迭代 10 次;
- 文本模态攻击:采用 BERT-Attack,最大扰动 ϵ t = 1 \epsilon_t=1 ϵt=1 个 token,候选词表长度 10.
- VLP 模型:覆盖两类核心架构,确保分析全面性
- 攻击目标与扰动对象
- 扰动对象:3 类输入扰动范围,覆盖单/双模态场景
- 单模态:仅扰动图像输入、仅扰动文本输入;
- 双模态:同时扰动图像与文本输入。
- 攻击目标:4 类嵌入攻击对象,细分嵌入类型差异
- 按模态层级:单模态嵌入(输出自图像/文本编码器)、多模态嵌入(输出自多模态编码器,仅融合型 VLP 有);
- 按嵌入范围:全嵌入(完整嵌入向量)、[CLS] 嵌入(嵌入中的 [CLS] token 表示,CLIP 仅CLIP V i T _{ViT} ViT 需讨论,CLIP C N N _{CNN} CNN 嵌入视为 [CLS] 嵌入)。

- 示例攻击设置:通过图2(VLP 模型架构与攻击设置图)直观展示,如 “Bi@Multifull”(双模态扰动+攻击多模态全嵌入)、“Image@UniCLS”(图像单模态扰动+攻击单模态[CLS]嵌入)。
- 扰动对象:3 类输入扰动范围,覆盖单/双模态场景
攻击实现
- 攻击单模态嵌入
- 图像模态:针对非分类任务(如图文检索),采用 KL 散度损失最大化嵌入差异,公式为:
δ i = ϵ i ⋅ s i g n ( ∇ x i ′ L ( E i ( x i ′ ) , E i ( x i ) ) ) \delta_{i}=\epsilon_{i} \cdot sign\left(\nabla_{x_{i}'} \mathcal{L}\left(E_{i}\left(x_{i}'\right), E_{i}\left(x_{i}\right)\right)\right) δi=ϵi⋅sign(∇xi′L(Ei(xi′),Ei(xi)))
( E i ( ⋅ ) E_i(\cdot) Ei(⋅) 为图像编码器, L \mathcal{L} L 为 KL 散度损失, x i ′ x_i' xi′ 为扰动后图像)。 - 文本模态:通过 token 修改/替换生成扰动文本 x t ′ = T ( x t ) x_t'=T(x_t) xt′=T(xt)( T ( ⋅ ) T(\cdot) T(⋅) 为 token 修改函数),扰动定义为:
δ t = a r g m a x x t ′ ( ∥ E m ( E ( x i ) , E t ( x t ′ ) ) − E m ( E ( x i ) , E t ( x t ) ) ∥ ) − x t \delta_{t}=\underset{x_{t}'}{arg max }\left(\left\| E_{m}\left(E\left(x_{i}\right), E_{t}\left(x_{t}'\right)\right)-E_{m}\left(E\left(x_{i}\right), E_{t}\left(x_{t}\right)\right)\right\| \right)-x_{t} δt=xt′argmax(∥Em(E(xi),Et(xt′))−Em(E(xi),Et(xt))∥)−xt 约束 ϵ t \epsilon_t ϵt 为 token 修改数量,确保语义一致性。
- 图像模态:针对非分类任务(如图文检索),采用 KL 散度损失最大化嵌入差异,公式为:
- 攻击多模态嵌入
基于单模态嵌入攻击方法调整,将单模态编码器输出替换为多模态编码器输出:- 攻击文本输入时,用多模态嵌入 E m ( ⋅ , ⋅ ) E_m(\cdot,\cdot) Em(⋅,⋅) 替换文本嵌入 E t ( ⋅ ) E_t(\cdot) Et(⋅);
- 攻击图像输入时,用多模态嵌入 E m ( ⋅ , ⋅ ) E_m(\cdot,\cdot) Em(⋅,⋅) 替换图像嵌入 E i ( ⋅ ) E_i(\cdot) Ei(⋅),确保攻击目标聚焦多模态交互后的统一嵌入。
核心观察
-
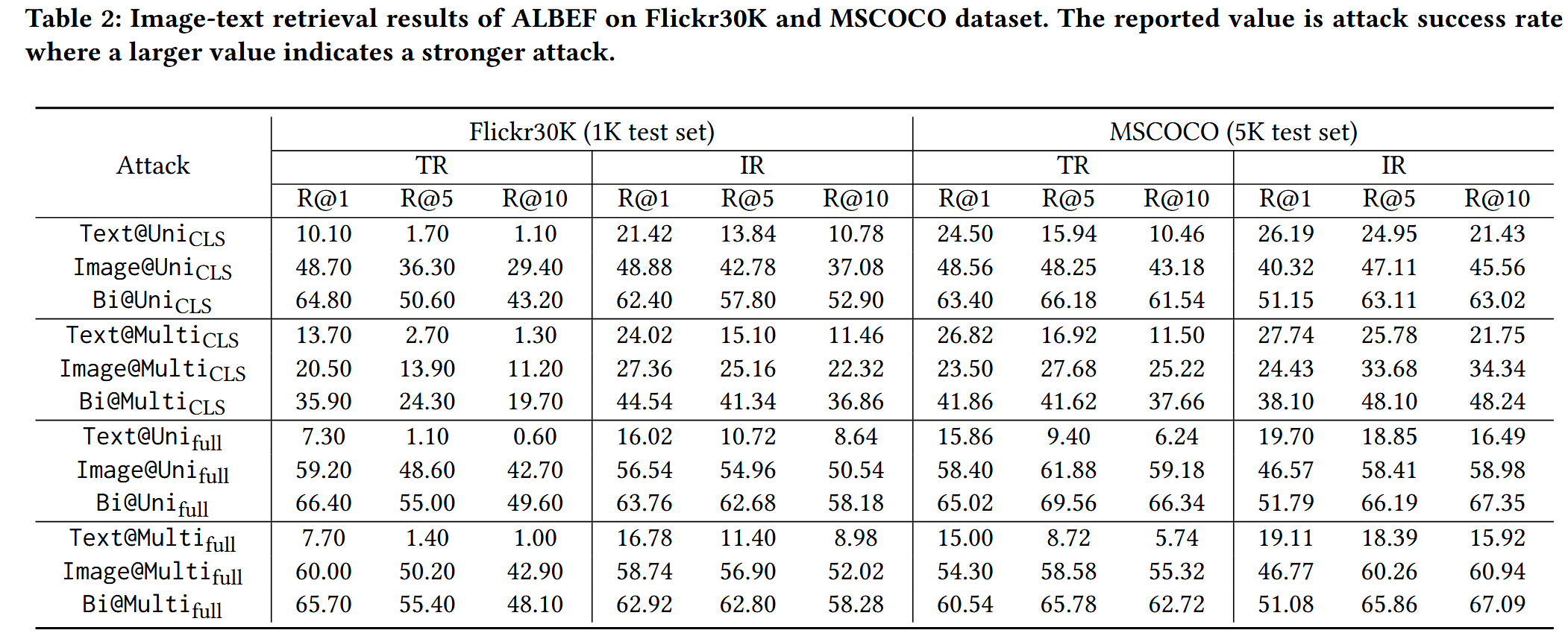
图文检索任务观察
- 扰动效果:双模态扰动(Bi@)始终强于单模态扰动(Text@/Image@),如 ALBEF 在 Flickr30K TR 任务 R@1 中,Bi@Uni full 达 66.40%,Image@Uni full 为 59.20%,Text@Uni full 仅 7.30%.
- 嵌入类型影响:
- 图像模态:攻击全嵌入比 [CLS] 嵌入更有效(ALBEF 的 Image@Uni full 在 Flickr30K IR 任务R@10 达 42.70%,Image@Uni CLS 为 29.40%);
- 文本模态:攻击 [CLS] 嵌入比全嵌入更有效(ALBEF 的 Text@Uni CLS 在 Flickr30K TR 任务R@1 达 10.10%,Text@Uni full 为 7.30%),印证 [CLS] 嵌入对文本语义的代表性。
- 模型与编码器差异:
- CLIP C N N _{CNN} CNN 的图像模态攻击成功率高于 CLIP V i T _{ViT} ViT(如 Flickr30K TR 任务 R@1,CLIP C N N _{CNN} CNN 为 63.30%,CLIP V i T _{ViT} ViT 为 64.00%),证明 ViT 比 CNN 更鲁棒;
- ALBEF(融合型)与 CLIP V i T _{ViT} ViT(对齐型)的单模态嵌入攻击效果无显著差异,说明预训练目标对对抗鲁棒性影响有限。


-
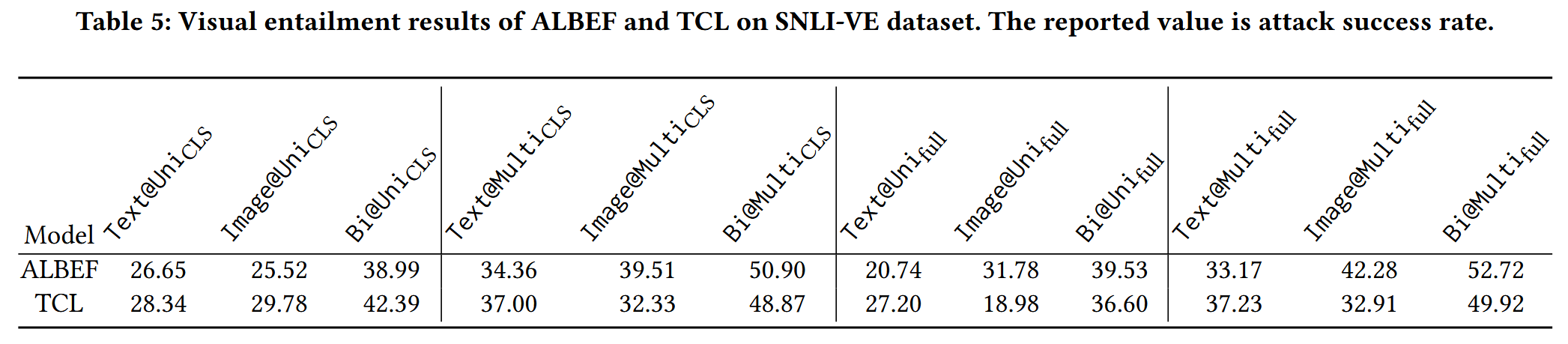
视觉蕴含任务观察
- 扰动与嵌入规律延续:双模态扰动强于单模态,图像模态攻击全嵌入更优;
- 任务特异性:
- 双模态攻击中,[CLS] 嵌入与全嵌入效果接近(如 ALBEF 的 Bi@UniCLS 与 Bi@Uni full 成功率差值 < 3%),说明 VE 任务对 [CLS] 嵌入敏感度低;
- 攻击多模态嵌入比单模态嵌入更有效(ALBEF 的 Bi@Multi full 成功率比 Bi@Uni full 高5%-8%),因 VE 任务推理依赖多模态交互结果,无需单模态嵌入参与。
-
视觉定位任务观察
- 核心结论:双模态扰动(Bi@)强于单模态,且 Bi@Multifull 在所有攻击设置中性能最优,进一步验证 “攻击多模态嵌入更适用于依赖多模态交互的任务”。
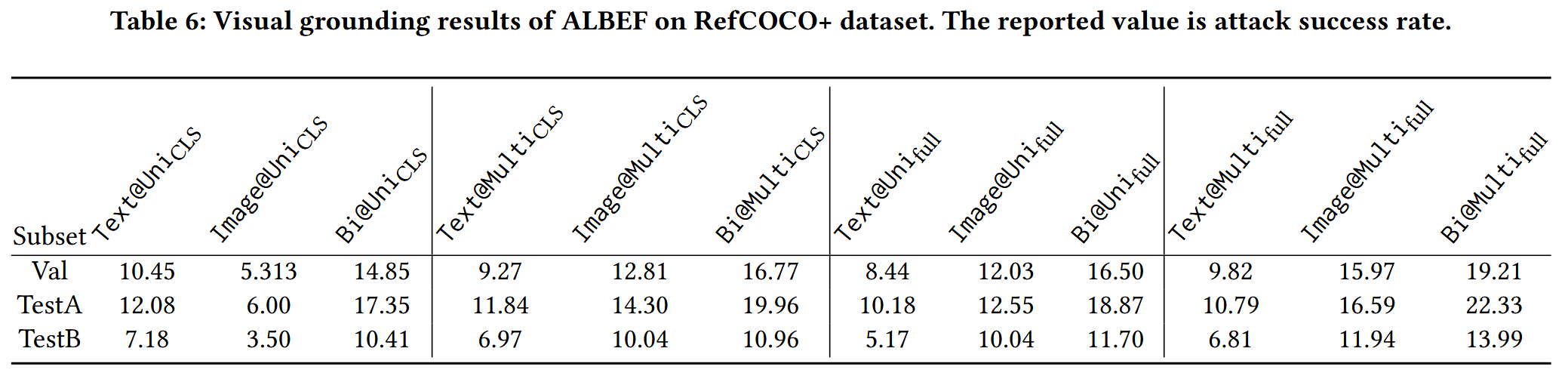
- 核心结论:双模态扰动(Bi@)强于单模态,且 Bi@Multifull 在所有攻击设置中性能最优,进一步验证 “攻击多模态嵌入更适用于依赖多模态交互的任务”。
-
跨任务与模型的总结观察
- 通用规律:双模态扰动是更强的攻击策略;单模态中,图像需重点防御全嵌入,文本需重点防御[CLS]嵌入;ViT 编码器比 CNN 更鲁棒。
- 任务适配:
- 需单模态嵌入推理的任务(如图文检索):攻击单模态与多模态嵌入效果相当;
- 依赖多模态交互的任务(如 VE、VG):攻击多模态嵌入效果更优。
- 鲁棒性建设启示:VLP 模型鲁棒性提升可优先选择 ViT 编码器,并针对不同模态的嵌入弱点设计防御策略。
VLP 模型中的协同多模态对抗攻击-Collaborative Multimodal Adversaarial Attack In VLP Model
方法设计背景与核心目标
- 现有问题:前文分析虽证实 “双模态扰动比单模态更有效”,但独立扰动图像与文本模态可能产生 “1+1<1” 的抵消效应(如图1中,独立双模态扰动因方向冲突导致攻击失败,而仅扰动图像即可改变预测结果),无法充分发挥双模态攻击的潜力。
- 核心目标:提出协同多模态对抗攻击(Co-Attack),通过协同设计图像与文本模态的扰动方向和强度,避免抵消效应,实现更高效的 VLP 模型攻击;同时确保方法适配两类 VLP 模型(融合型、对齐型),可分别攻击多模态嵌入与单模态嵌入。
Co-Attack 方法实现
- 核心设计逻辑
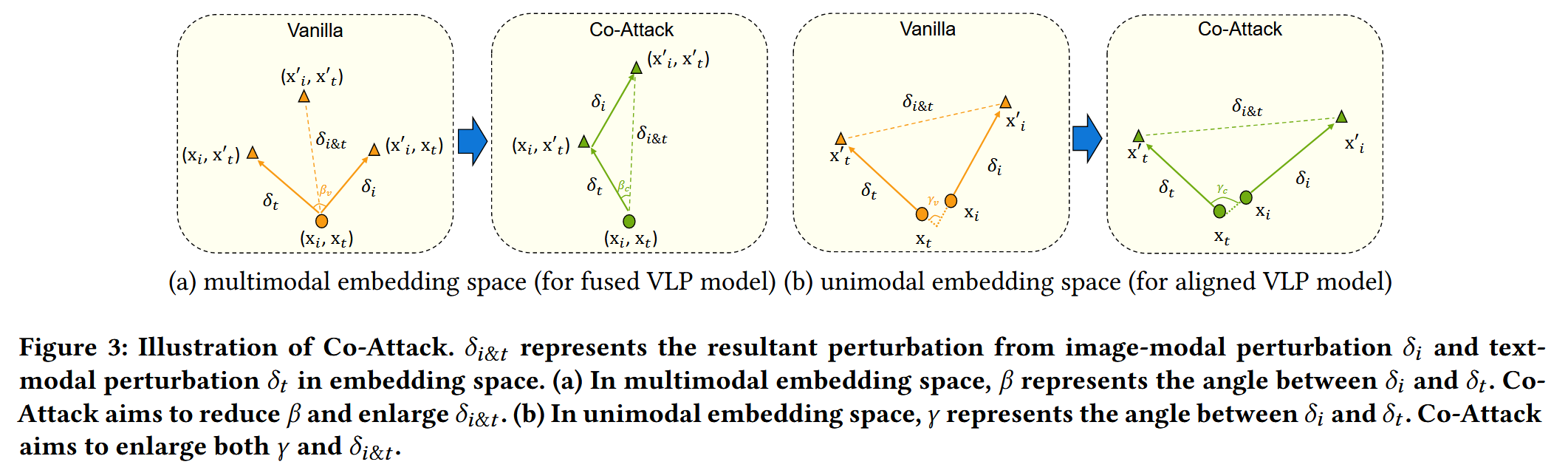
基于 VLP 模型的嵌入空间特性,分两种场景设计协同策略,通过图3(嵌入空间扰动示意图)直观展示:- 核心变量定义: δ i \delta_i δi 为图像模态扰动, δ t \delta_t δt 为文本模态扰动, δ i & t \delta_{i\&t} δi&t 为双模态总扰动;
- 协同核心:通过控制 δ i \delta_i δi 与 δ t \delta_t δt 的夹角及 δ i & t \delta_{i\&t} δi&t 的大小,确保两者目标一致,避免冲突。
- 攻击多模态嵌入
- 目标:让扰动后的多模态嵌入远离原始多模态嵌入,破坏模型对图像-文本关联的理解。
- 协同策略:
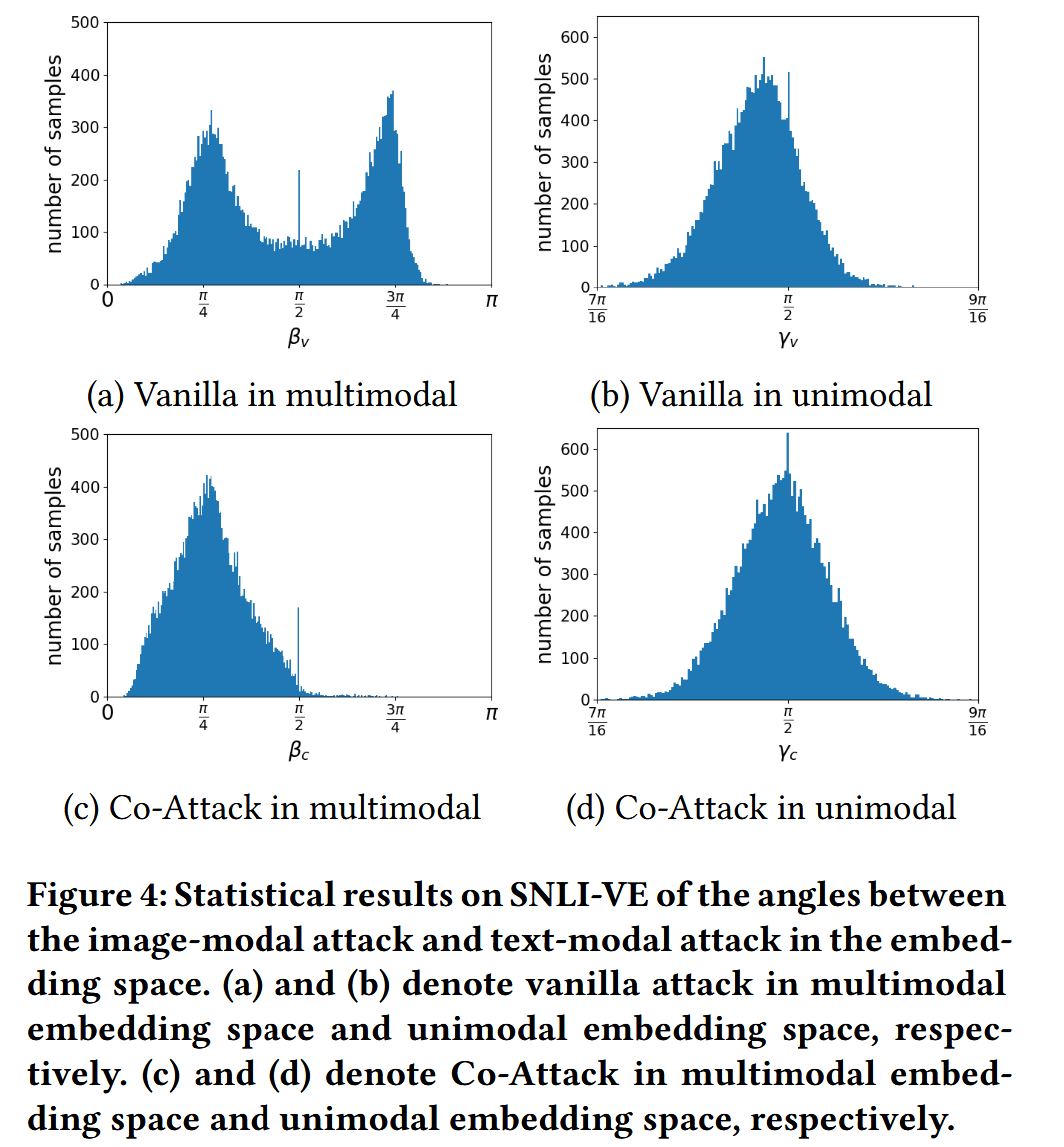
- 减小 δ i \delta_i δi 与 δ t \delta_t δt 的夹角 β \beta β( Co-Attack 使 β c \beta_c βc 集中在 [ 0 , π 2 ] [0, \frac{\pi}{2}] [0,2π],如 图4(a)(c) 所示),确保两者扰动方向一致;
- 扩大总扰动 δ i & t \delta_{i\&t} δi&t 的幅度,增强对多模态嵌入的破坏。
- 优化实现:
- 先扰动文本模态:因文本属离散空间(token 替换),难以直接梯度优化,通过 BERT-Attack 生成语义一致的扰动文本 x t ′ x_t' xt′;
- 再扰动图像模态:以 x t ′ x_t' xt′ 为基准,通过 PGD 优化图像扰动 x i ′ x_i' xi′,目标函数为:
max L ( E m ( E i ( x i ′ ) , E t ( x t ′ ) ) , E m ( E i ( x i ) , E t ( x t ′ ) ) ) + α 1 ⋅ L ( E m ( E i ( x i ′ ) , E t ( x t ′ ) ) , E m ( E i ( x i ) , E t ( x t ) ) ) \max \mathcal{L}\left(E_m(E_i(x_i'),E_t(x_t')),E_m(E_i(x_i),E_t(x_t'))\right) + \alpha_1 \cdot \mathcal{L}\left(E_m(E_i(x_i'),E_t(x_t')),E_m(E_i(x_i),E_t(x_t))\right) maxL(Em(Ei(xi′),Et(xt′)),Em(Ei(xi),Et(xt′)))+α1⋅L(Em(Ei(xi′),Et(xt′)),Em(Ei(xi),Et(xt))) 其中,第一项确保 x i ′ x_i' xi′ 与 x t ′ x_t' xt′ 协同破坏多模态嵌入,第二项扩大总扰动 δ i & t \delta_{i\&t} δi&t, α 1 \alpha_1 α1 为控制第二项权重的超参数。
- 攻击单模态嵌入
- 目标:让扰动后的图像嵌入与文本嵌入相互远离,切断两者的对齐关系。
- 协同策略:
- 扩大 δ i \delta_i δi 与 δ t \delta_t δt 的夹角 γ \gamma γ(Co-Attack 使 γ c \gamma_c γc 分布向大角度偏移,如 图4(b)(d) 所示),确保两者分别远离原始嵌入方向;
- 同时扩大总扰动 δ i & t \delta_{i\&t} δi&t 的幅度,增强对单模态嵌入对齐关系的破坏。
- 优化实现:
- 同攻击多模态嵌入,先通过 BERT-Attack 生成 x t ′ x_t' xt′;
- 再优化图像扰动 x i ′ x_i' xi′,目标函数与多模态嵌入攻击类似,仅将多模态编码器 E m ( ⋅ , ⋅ ) E_m(\cdot,\cdot) Em(⋅,⋅) 替换为单模态编码器 E i ( ⋅ ) E_i(\cdot) Ei(⋅)、 E t ( ⋅ ) E_t(\cdot) Et(⋅),超参数 α 2 \alpha_2 α2 控制总扰动权重。
实验验证
- 实验设置
- 基础配置:与前文分析设置一致(模型、任务、数据集、攻击参数),新增超参数 α 1 = α 2 = 3 \alpha_1=\alpha_2=3 α1=α2=3,MIM 动量设为 0.9,SI 尺度副本数设为 5;
- 基线方法:选取 5 类代表性攻击方法对比,确保公平性:
- Fooling VQA:针对 VQA 模型的图像扰动攻击,用 ADAM 优化交叉熵损失;
- SSAP:针对 VLP 模型的图像扰动攻击,用 PGD 优化交叉熵损失;
- SSAP-MIM/SSAP-SI:SSAP 的改进版,分别用 MIM、SI 替换 PGD 优化器;
- Vanilla:性能最优的独立双模态攻击(如 ALBEF 的 Bi@Multifull);
- 评价标准:攻击成功率(值越大表示攻击效果越强),非分类任务(图文检索)攻击嵌入表示,分类任务(VE、VG)攻击 logit 表示。
- 对比实验结果
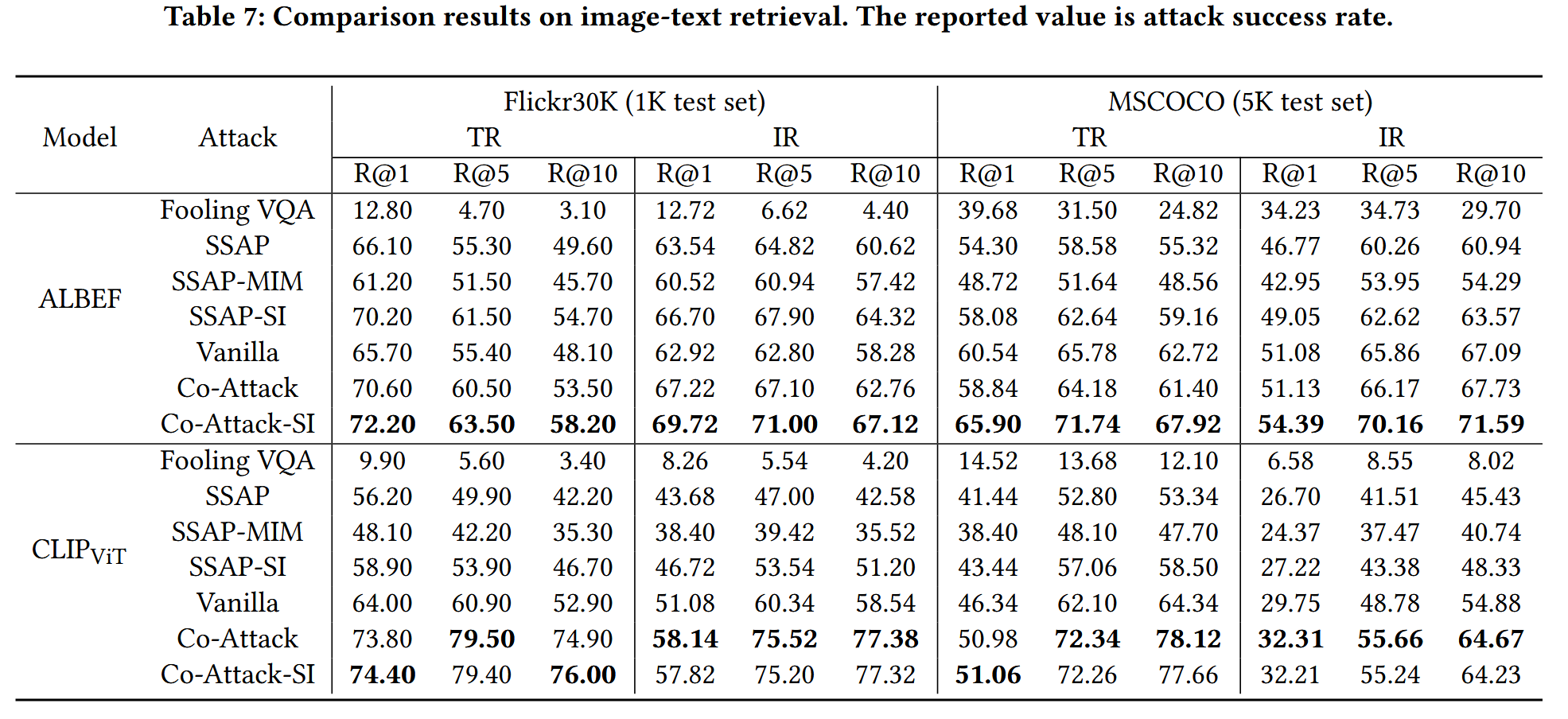
- 图文检索任务
- ALBEF:Co-Attack-SI(Co-Attack+SI优化器)性能最优,在Flickr30K TR任务R@1达72.20%,比Vanilla(65.70%)高6.5个百分点,比SSAP-SI(70.20%)高2个百分点;
- CLIP_ViT:Co-Attack在Flickr30K IR任务R@10达77.38%,比Vanilla(58.54%)高18.84个百分点,显著优于其他基线。
- 视觉蕴含任务
- ALBEF 的 Co-Attack 成功率达 79.27%,比 Vanilla(70.57%)高 8.7 个百分点;
- TCL 的 Co-Attack 成功率达 76.43%,比 Vanilla(66.46%)高 9.97 个百分点,均优于所有基线。

- 图文检索任务
- 可视化验证
- 单模态攻击(文本/图像):模型注意力仍聚焦目标区域(如 “吉他”),热力图无显著偏移;
- Vanilla 攻击:注意力轻微偏移,但仍有部分聚焦目标区域;
- Co-Attack:注意力完全偏离目标区域(转向背景或无关物体),成功误导模型推理,直观验证协同攻击的有效性。

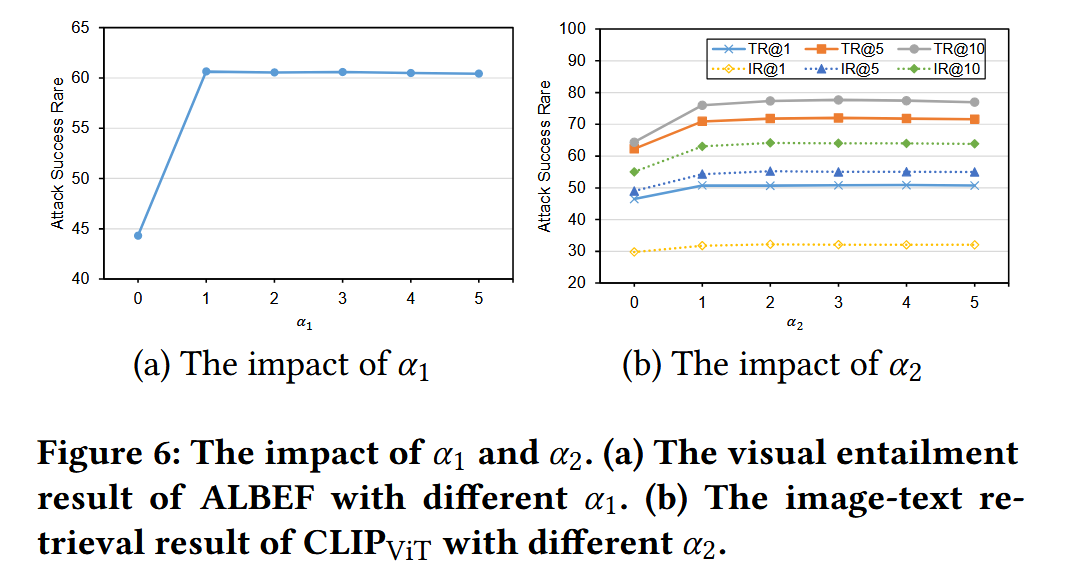
- 消融实验
- 实验设计:调整 α 1 \alpha_1 α1、 α 2 \alpha_2 α2 在 [0,5] 范围内取值,观察对 ALBEF(VE 任务)、CLIP_ViT(图文检索任务)的影响;
- 核心结论:
- 当 α 1 > 0 \alpha_1>0 α1>0、 α 2 > 0 \alpha_2>0 α2>0 时,攻击成功率显著高于 α = 0 \alpha=0 α=0(无总扰动项),证明协同策略中 “总扰动控制” 的必要性;
- 当 α 1 ≥ 1 \alpha_1\geq1 α1≥1、 α 2 ≥ 1 \alpha_2\geq1 α2≥1 时,成功率趋于稳定(波动 <2%),说明 Co-Attack 对超参数不敏感,无需精细调参。
方法价值
- 性能提升:Co-Attack 通过协同扰动解决抵消效应,在三类下游任务、两类 VLP 模型上均超越现有基线,证明其通用性与有效性;
- 可解释性:通过热力图可视化与消融实验,明确协同策略(夹角控制、总扰动)的作用机制,为多模态攻击设计提供可解释依据;
- 实用价值:方法适配离散文本与连续图像模态,可直接应用于主流 VLP 模型,为 VLP 模型的对抗鲁棒性测试提供高效工具。
结论-Conclusion
- 核心研究工作:本文围绕视觉-语言预训练(VLP)模型的对抗性攻击展开研究,一是系统分析了不同攻击设置(攻击目标、扰动对象)在两类 VLP 模型(融合型如 ALBEF、TCL,对齐型如 CLIP)及三类下游视觉-语言(V+L)任务(图文检索、视觉蕴含、视觉定位)中的攻击性能;二是针对独立双模态攻击的 “1+1<1” 抵消效应,提出了协同多模态对抗攻击方法(Co-Attack)。
- 关键研究成果:通过分析得出多模态攻击设计与 VLP 模型鲁棒性的核心规律(如双模态扰动比单模态更有效、ViT 编码器比 CNN 更鲁棒等);实验验证 Co-Attack 在各任务和模型上均优于现有基线攻击方法,有效提升了对 VLP 模型的攻击效果。
- 研究意义:研究成果为理解 VLP 模型的对抗鲁棒性特性提供了新视角,既为设计更强的多模态对抗攻击提供指导,也为构建更安全可靠的 VLP 模型、推动其在实际场景中的部署奠定基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)