【端侧部署系列-CLIP】CLIP部署至全志开发板
注:awnpu_model_zoo\docs里有详细的开发文档以及参考指南
本文是根据《NPU开发环境部署参考指南》,部署PC的ubuntu环境,使用Docker镜像环境为例进行说明。
如果想对部署流程进行更加详细的了解,可以参考《NPU_模型部署_开发指南》
重要说明:在awnpu_model_zoo内没有的模型,可参考awnpu_model_zoo\examples里面对应系列的模型进行修改部署,需要自行编写对应模型cpp前后处理代码以及修改相应的配置文件(如model_config.h、CMakeLists.txt等)。如果遇到模型导出量化失败的情况,需要对模型进行相应的裁剪、或者采用不同的量化方式等。本文的CLIP已经在板端经过了推理验证。
clip目录结构如下:
|-- CMakeLists.txt
|-- README.md
|-- clip-images_pre.cpp
|-- clip_post.cpp
|-- clip_tokenizer.cpp
|-- clip_tokenizer.h
|-- figures
| |-- 1.png
| `-- 2.png
|-- images_convert_model # 图像编码器
| |-- config_yml.py # 图像模型的配置文件
| `-- convert_model_env.sh
|-- main.cpp
|-- model
| |-- demo.png
| |-- demo.txt
| `-- merges.txt
|-- model_config.h
`-- text_convert_model # 文本编码器
|-- config_yml.py # 文本模型的配置文件
|-- convert_model_env.sh
`-- python
|-- onnx_fixed.py
`-- truncated_onnx.py
环境配置
关于环境配置所有模型都是一样的,采用Docker容器的方式,具体关于参考之前部署yolox的文章【端侧部署yolo系列】yolox部署至全志开发板T736![]() https://blog.csdn.net/troyteng/article/details/155444386?spm=1011.2124.3001.6209
https://blog.csdn.net/troyteng/article/details/155444386?spm=1011.2124.3001.6209
下载镜像文件和AWNPU_Model_Zoo,创建自己的容器。
模型准备
官方原始pytorch模型
https://huggingface.co/openai/clip-vit-base-patch32/tree/main![]() https://huggingface.co/openai/clip-vit-base-patch32/tree/main如不想进行后续模型准备步骤,这里已经将官方的模型导出为了onnx模型clip-images、clip-text
https://huggingface.co/openai/clip-vit-base-patch32/tree/main如不想进行后续模型准备步骤,这里已经将官方的模型导出为了onnx模型clip-images、clip-text
模型导出
安装从https://huggingface.co/openai/clip-vit-base-patch32 文件库导出onnx模型需要的环境,执行以下命令导出onnx模型(这里的onnx是包含了图像编码和文本编码,后续需要将两个模型拆分出来):
cd examples/clip
optimum-cli export onnx --model ./clip-vit-base-patch32/ --task feature-extraction --opset 18 ./clip_onnx/
#将从开源项目下载的权重相关文件放在clip-vit-base-patch32下
#执行导出命令后生成的model.onnx在clip_onnx文件下利用truncated_onnx.py从model.onnx模型中裁剪出图像模型(clip_images.onnx)和文本模型(clip_text.onnx);
cd examples/clip/text_convert_model/python
mkdir model
python truncated_onnx.py --model ../../clip_onnx/model.onnx
#得到图像模型clip_images.onnx和文本模型clip_text.onnx模型图优化
模型输入被固定为 (1, 20),即batch_size=1,序列长度=20。当输入长度固定且所有token都有效时,attention_mask就是一个全1张量,没有动态变化的必要。简化了NPU部署复杂度并提升了推理效率。代价是模型只能处理固定长度的有效输入序列。
利用onnx-modify(链接里有详细的工具使用指导)从clip-text模型中移除attention_mask 输入,即移除图中的节点及where节点12个输出关联的12 add节点。
在clip环境中安装库
# 安装依赖
pip install onnx-modifier
# 运行
onnx-modifier输出结果如下:
* Serving Flask app 'onnx_modifier.app'
* Debug mode: off
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:5000
INFO:werkzeug:Press CTRL+C to quit
进入 http://127.0.0.1:5000
将导出的文本模型(clip_text.onnx)拖入,找到attention_mask输入,然后找到where节点,点击where节点,删除单个节点。
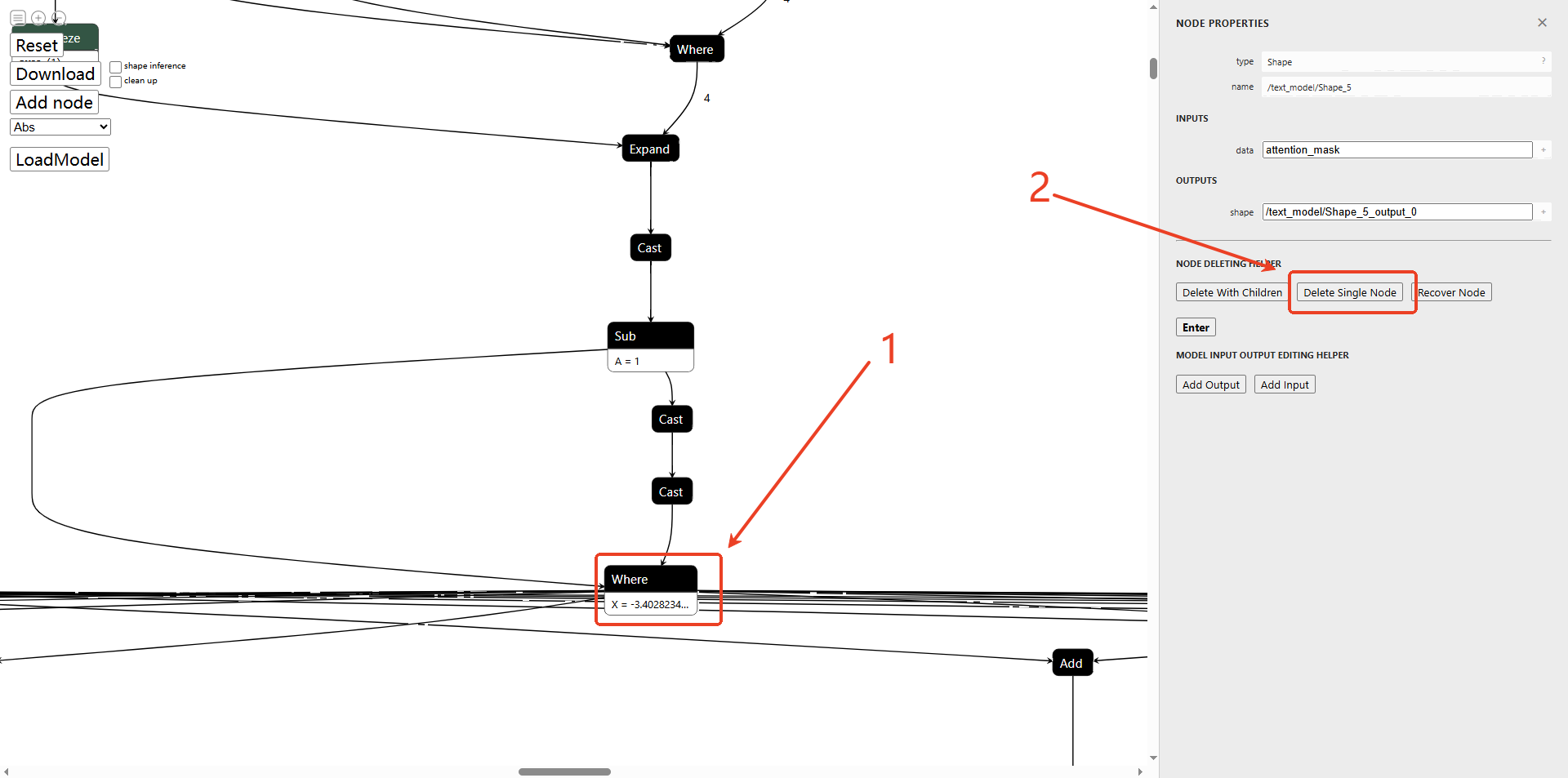
然后删除attention_mask的所有子节点,其他节点同理。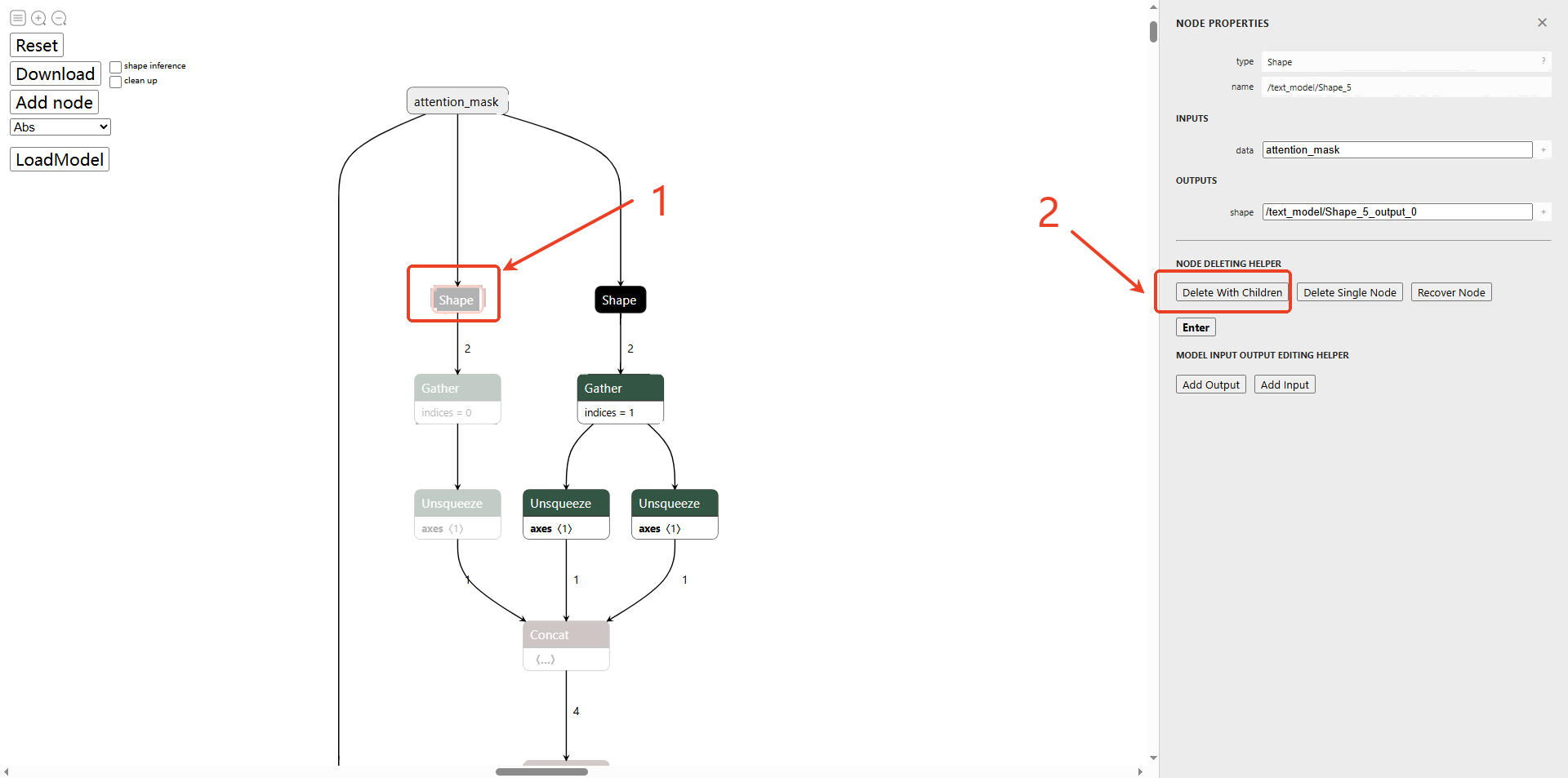
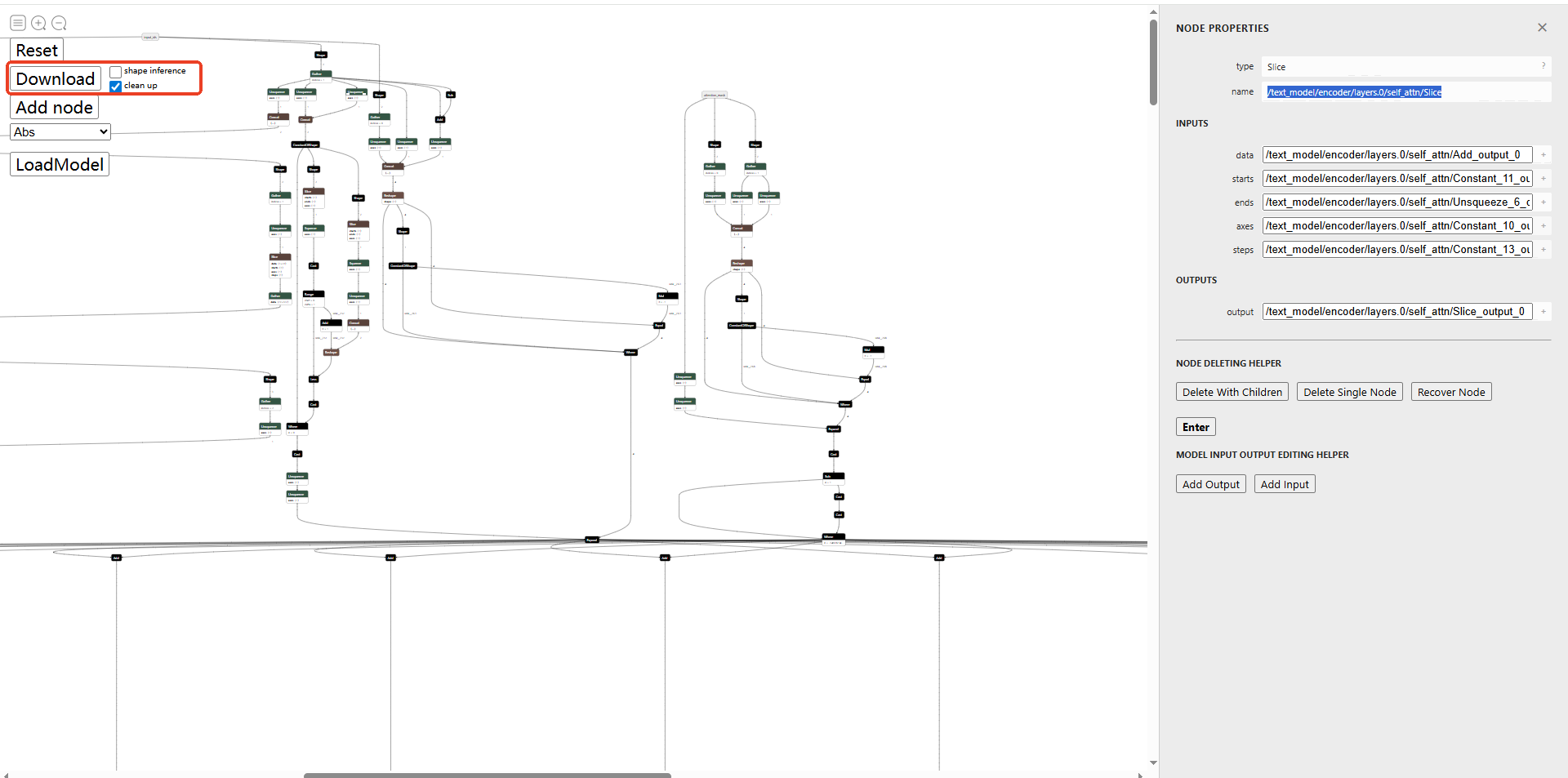
由于已经把where节点删除,导致下一个节点add算子无效,因此12个输出关联的add节点也需要删除。具体操作:找到add的输入Expand,将Expand输出改为add节点的输出(类似于删除链表),也就是将步骤2这里的name改为Slice的name,其他add节点同理。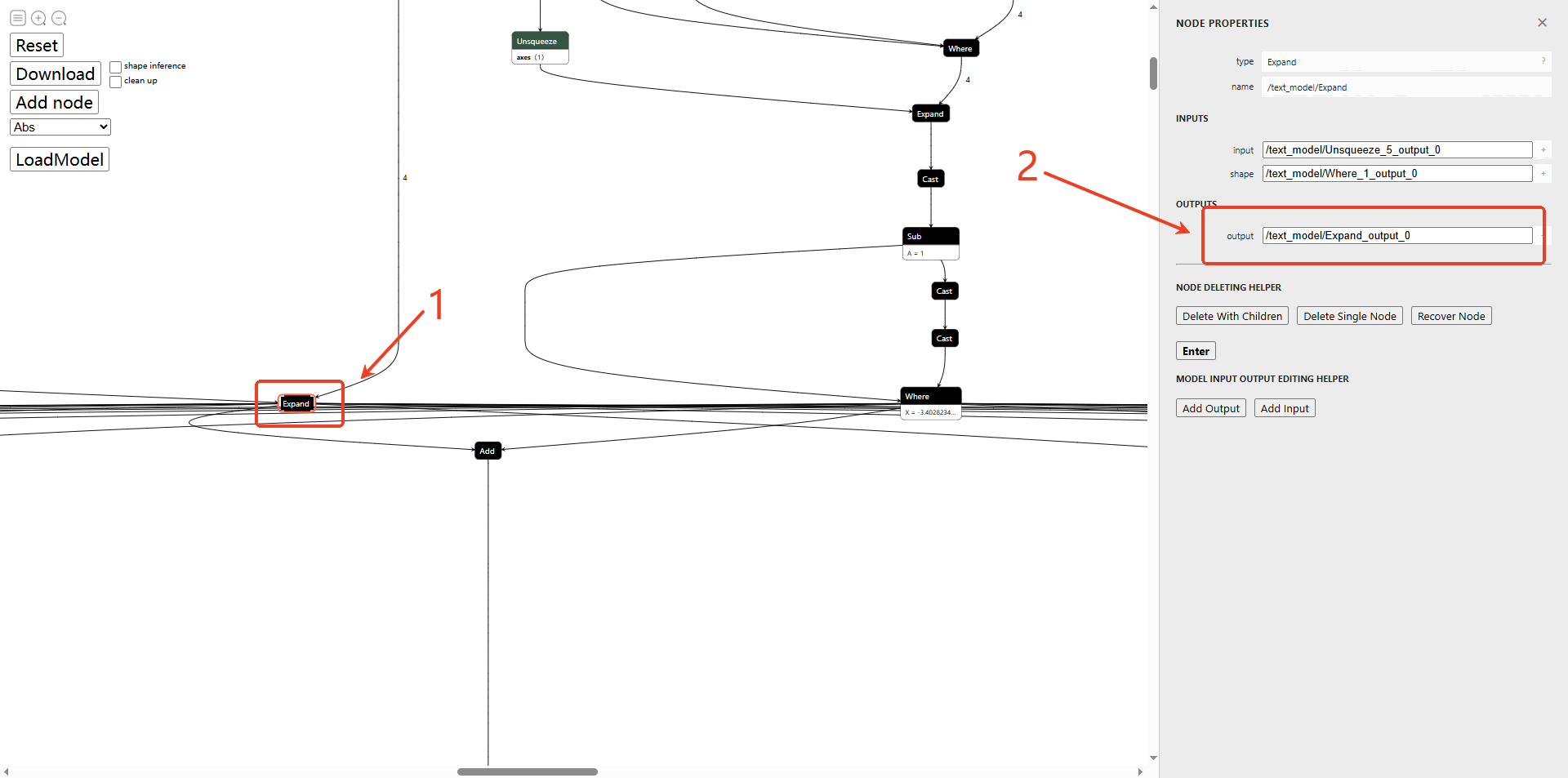
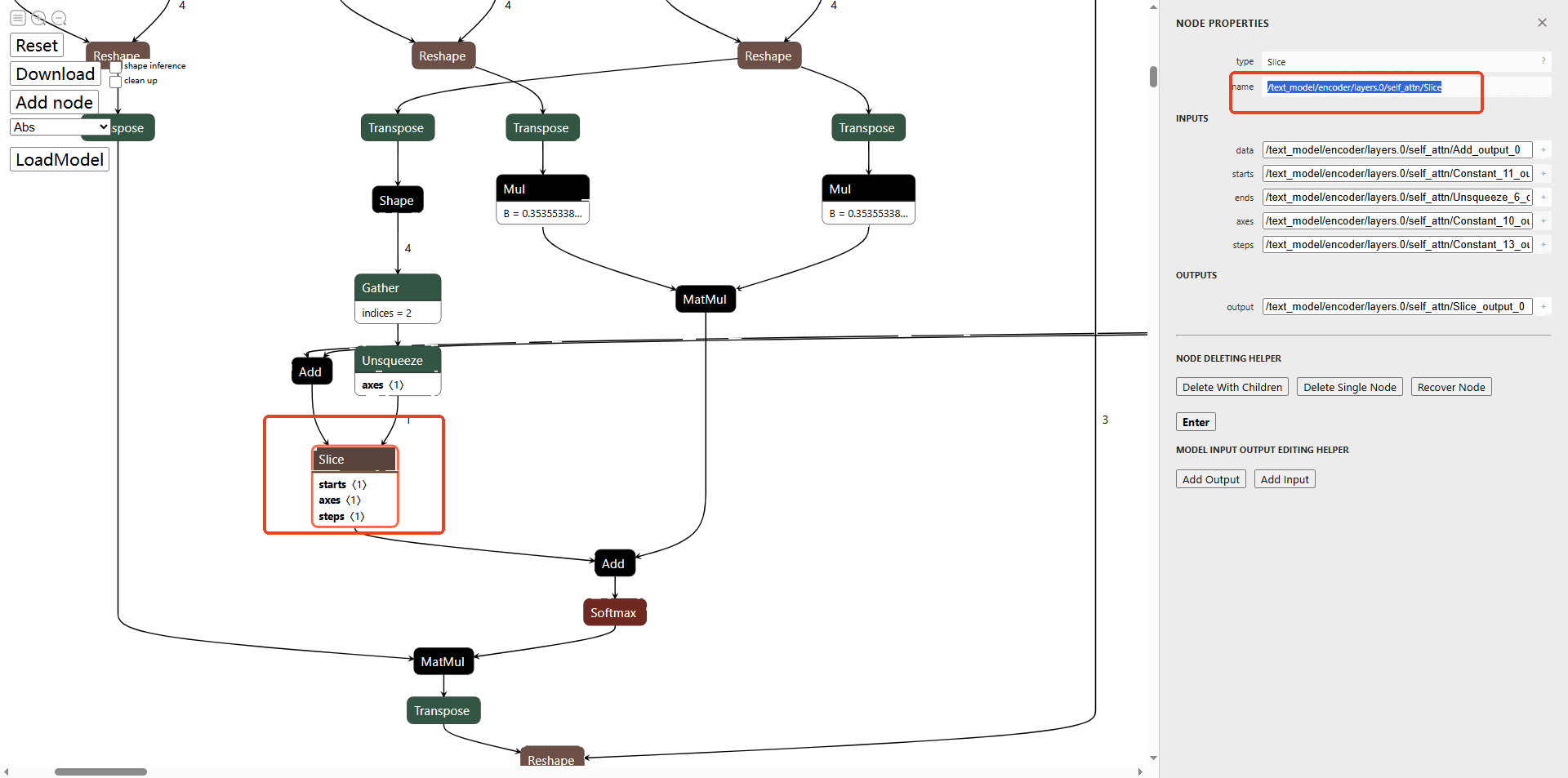
最后打钩clean up,点击Download。模型会保存至指定路径(下载onnx-modifier库路径下的modified_onnx文件夹内)。
固定尺寸
#将固定模型输入序列
cd examples/clip/text_convert_model/python/model
#clip_text
python -m onnxruntime.tools.make_dynamic_shape_fixed --input_name input_ids --input_shape 1,20 clip_text.onnx clip_text-fixed.onnx
#clip_images
python -m onnxruntime.tools.make_dynamic_shape_fixed --input_name pixel_values --input_shape 1,3,224,224 clip_images.onnx clip_images-fixed.onnx
#模型简化
#clip_text
python -m onnxsim clip_text-fixed.onnx clip_text-sim.onnx --overwrite-input-shape=1,20
#clip_images
python -m onnxsim clip_images-fixed.onnx ../../../images_convert_model/clip-images.onnx --overwrite-input-shape=1,3,224,224固定模型尺寸后,通过onnx_fixed.py修改add输入产量,将-3.4028234663852886e+38这个值修改为-10000,提高后续的量化精度。
这样做的目的是极小值在量化时容易造成精度损失。在Transformer的Self-Attention中,attention_mask的作用是在计算attention分数时,给padding位置加上一个极大的负数(如 -3.4e38),这样经过softmax后padding位置的权重趋近于0。为了避免这种情况,将极小值 -3.4e38改为 -10000,-10000对于softmax来说已经足够使得padding位置权重趋近于0,对量化更友好。
cd examples/clip/text_convert_model/python
python onnx_fixed.py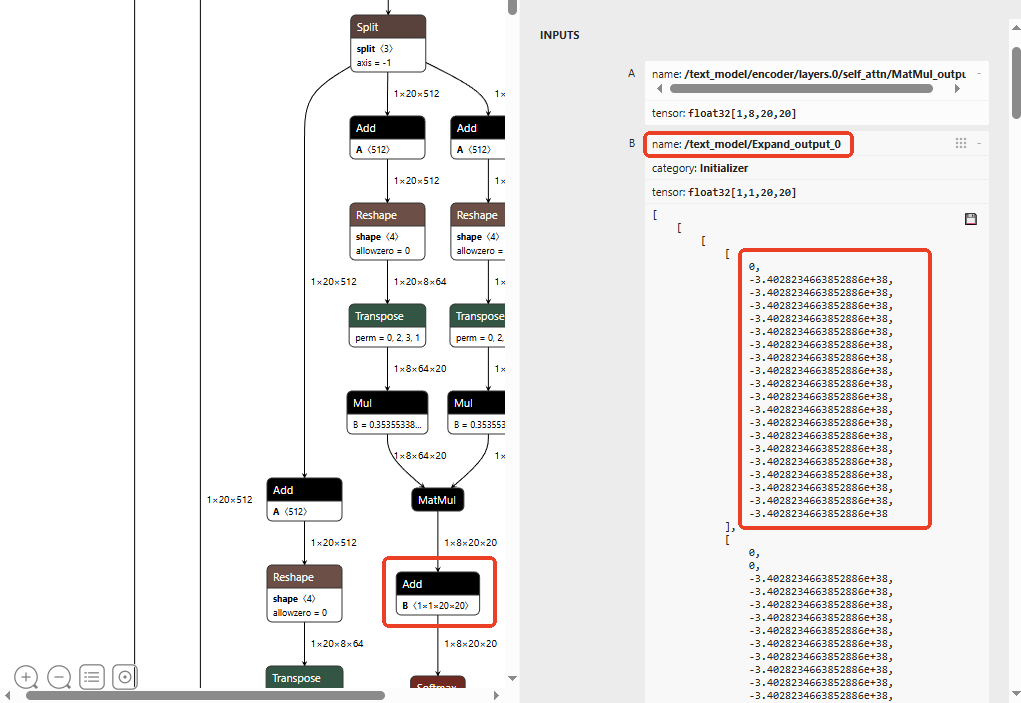
量化数据集
数据集来源OpenAI关于clip的博客页面,链接:https://openai.com/index/clip/,从网页挑选其中10张图片与描述作为量化数据集,本文使用的数据集如下:
a photo of a motorcycle
a photo of guacamole
a photo of a television studio
a photo of a building
a photo of a airplane
a photo of a barn
a photo of a kangaroo
a photo of a beer bottle
a photo of a pill bottle
a photo of a horse
将数据集读进clip的python推理代码中,获取input_id部分的输入张量,将其转换为.npy文件,即可获得clip-text量化数据集。
模型配置
clip-images
cd ./images_convert_model/修改config_yml.py文件的相关参数配置;
# "database" allowed types: "TEXT, NPY, H5FS, SQLITE, LMDB, GENERATOR, ZIP"
DATASET = '../../dataset/clip_10/images/dataset.txt'
DATASET_TYPE = "TEXT"# mean, scale
MEAN = [122.770938, 116.746013, 104.093736]
SCALE = [0.014598, 0.015007, 0.014220]# reverse_channel: True bgr, False rgb
REVERSE_CHANNEL = False# add_preproc_node, True or False
ADD_PREPROC_NODE = True
# "preproc_type" allowed types:"IMAGE_RGB, IMAGE_RGB888_PLANAR, IMAGE_RGB888_PLANAR_SEP, IMAGE_I420,
# IMAGE_NV12,IMAGE_NV21, IMAGE_YUV444, IMAGE_YUYV422, IMAGE_UYVY422, IMAGE_GRAY, IMAGE_BGRA, TENSOR"
PREPROC_TYPE = "IMAGE_RGB"# add_postproc_node, quant output -> float32 output
ADD_POSTPROC_NODE = True
clip-text
cd ./text_convert_model/修改config_yml.py文件的相关参数配置;
# "database" allowed types: "TEXT, NPY, H5FS, SQLITE, LMDB, GENERATOR, ZIP"
DATASET = '../../dataset/clip_10/text/dataset.txt'
DATASET_TYPE = "TEXT"# mean, scale
MEAN = [0, 0, 0]
SCALE = [1, 1, 1]# reverse_channel: True bgr, False rgb
REVERSE_CHANNEL = False# add_preproc_node, True or False
ADD_PREPROC_NODE = False
# "preproc_type" allowed types:"IMAGE_RGB, IMAGE_RGB888_PLANAR, IMAGE_RGB888_PLANAR_SEP, IMAGE_I420,
# IMAGE_NV12,IMAGE_NV21, IMAGE_YUV444, IMAGE_YUYV422, IMAGE_UYVY422, IMAGE_GRAY, IMAGE_BGRA, TENSOR"
PREPROC_TYPE = "TENSOR"# add_postproc_node, quant output -> float32 output
ADD_POSTPROC_NODE = True
模型前后处理
配置文件
model_config.h
/****************************************************************************
* model config header file
****************************************************************************/
#ifndef _MODEL_CONFIG_H_
#define _MODEL_CONFIG_H_
#include <iostream>
#include <vector>
/* 224 x 224 */
#define LETTERBOX_ROWS 224
#define LETTERBOX_COLS 224
#define SEQ_LEN 20
#define FEAT_DIM 512
#define MAX_TEXT_LINE_LENGTH 1024
#define MAX_TEXT_COUNT 100
#define MERGES_TXT_PATH "./model/merges.txt"
#endif
clip_tokenizer.h
#ifndef _CLIP_TOKENIZER_H
#define _CLIP_TOKENIZER_H
#include <string>
#include <regex>
#include <set>
#include <codecvt>
#include <locale>
#include <map>
const int UNK_TOKEN_ID = 49407;
const int BOS_TOKEN_ID = 49406;
const int EOS_TOKEN_ID = 49407;
const int PAD_TOKEN_ID = 49407;
std::u32string utf8_to_utf32(const std::string& utf8_str);
std::string utf32_to_utf8(const std::u32string& utf32_str);
std::u32string unicode_value_to_utf32(int unicode_value);
class CLIPTokenizer {
private:
std::map<int, std::u32string> byte_encoder;
std::map<std::u32string, int> encoder;
std::map<std::pair<std::u32string, std::u32string>, int> bpe_ranks;
std::string merges_utf8_str;
public:
CLIPTokenizer() {
}
void load_from_merges(const std::string& merges_utf8_str);
bool load_from_file(const std::string& merges_file_path);
std::u32string bpe(const std::u32string& token);
std::vector<int> tokenize(std::string text, size_t max_length = 0, bool padding = false);
std::vector<int> encode(std::string text);
};
#endif图像前处理clip-images_pre.cpp
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <math.h>
#include <chrono>
#include "model_config.h"
/* model_inputmeta.yml file param modify, eg:
preproc_node_params:
add_preproc_node: true
preproc_type: IMAGE_RGB
demo model: model_rgb_xxx.nb.
*/
void get_input_data(const char* image_file, unsigned char* input_data, int letterbox_rows, int letterbox_cols)
{
std::chrono::steady_clock::time_point Tbegin, Tend;
Tbegin = std::chrono::steady_clock::now();
cv::Mat sample = cv::imread(image_file, 1);
if (sample.empty()) {
fprintf(stderr, "cv::imread %s failed\n", image_file);
return;
}
Tend = std::chrono::steady_clock::now();
float f = std::chrono::duration_cast<std::chrono::milliseconds>(Tend - Tbegin).count();
// std::cout << "preprocess cv::imread image file cost time : " << f << " ms" << std::endl;
cv::Mat img;
cv::cvtColor(sample, img, cv::COLOR_BGR2RGB);
/* letterbox process to support different letterbox size */
float scale_letterbox = 1.f;
if ((letterbox_rows * 1.0 / img.rows) < (letterbox_cols * 1.0 / img.cols))
{
scale_letterbox = letterbox_rows * 1.0 / img.rows;
}
else
{
scale_letterbox = letterbox_cols * 1.0 / img.cols;
}
int resize_cols = int(round(scale_letterbox * img.cols));
int resize_rows = int(round(scale_letterbox * img.rows));
float dh = (float)(letterbox_rows - resize_rows);
float dw = (float)(letterbox_cols - resize_cols);
dh /= 2.0f;
dw /= 2.0f;
cv::resize(img, img, cv::Size(resize_cols, resize_rows));
// create a mat with input_data ptr
cv::Mat img_new(letterbox_rows, letterbox_cols, CV_8UC3, input_data);
int top = (int)(round(dh - 0.1));
int bot = (int)(round(dh + 0.1));
int left = (int)(round(dw - 0.1));
int right = (int)(round(dw + 0.1));
// Letterbox filling
cv::copyMakeBorder(img, img_new, top, bot, left, right, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114));
}
int clip_images_preprocess(const char* imagepath, void* buff_ptr, unsigned int buff_size)
{
int img_c = 3;
// set default letterbox size
int letterbox_rows = LETTERBOX_ROWS;
int letterbox_cols = LETTERBOX_COLS;
int img_size = letterbox_rows * letterbox_cols * img_c;
unsigned int data_size = img_size * sizeof(uint8_t);
if (data_size > buff_size) {
printf("data size > buff size, please check code.\n");
return -1;
}
get_input_data(imagepath, (unsigned char*)buff_ptr, letterbox_rows, letterbox_cols);
return 0;
}
文本分词器clip_tokenizer.cpp
#include "clip_tokenizer.h"
#include <regex>
#include <algorithm>
#include <set>
#include <map>
#include <iostream>
#include <fstream>
#include <climits>
std::u32string utf8_to_utf32(const std::string& utf8_str) {
std::wstring_convert<std::codecvt_utf8<char32_t>, char32_t> converter;
try {
return converter.from_bytes(utf8_str);
} catch (const std::range_error& e) {
std::cerr << "UTF8 to UTF32 conversion error: " << e.what() << std::endl;
return U"";
}
}
std::string utf32_to_utf8(const std::u32string& utf32_str) {
std::wstring_convert<std::codecvt_utf8<char32_t>, char32_t> converter;
try {
return converter.to_bytes(utf32_str);
} catch (const std::range_error& e) {
std::cerr << "UTF32 to UTF8 conversion error: " << e.what() << std::endl;
return "";
}
}
std::u32string unicode_value_to_utf32(int unicode_value) {
std::u32string utf32_string = {static_cast<char32_t>(unicode_value)};
return utf32_string;
}
std::vector<std::pair<int, std::u32string>> bytes_to_unicode() {
std::vector<std::pair<int, std::u32string>> byte_unicode_pairs;
std::set<int> byte_set;
for (int b = static_cast<int>('!'); b <= static_cast<int>('~'); ++b) {
byte_set.insert(b);
byte_unicode_pairs.emplace_back(b, unicode_value_to_utf32(b));
}
for (int b = 161; b <= 172; ++b) {
byte_set.insert(b);
byte_unicode_pairs.emplace_back(b, unicode_value_to_utf32(b));
}
for (int b = 174; b <= 255; ++b) {
byte_set.insert(b);
byte_unicode_pairs.emplace_back(b, unicode_value_to_utf32(b));
}
int n = 0;
for (int b = 0; b < 256; ++b) {
if (byte_set.find(b) == byte_set.end()) {
byte_unicode_pairs.emplace_back(b, unicode_value_to_utf32(n + 256));
++n;
}
}
return byte_unicode_pairs;
}
static std::string strip(const std::string& str) {
std::string::size_type start = str.find_first_not_of(" \t\n\r\v\f");
std::string::size_type end = str.find_last_not_of(" \t\n\r\v\f");
if (start == std::string::npos) {
return "";
}
return str.substr(start, end - start + 1);
}
static std::string whitespace_clean(std::string text) {
text = std::regex_replace(text, std::regex(R"(\s+)"), " ");
text = strip(text);
return text;
}
static std::set<std::pair<std::u32string, std::u32string>> get_pairs(const std::vector<std::u32string>& subwords) {
std::set<std::pair<std::u32string, std::u32string>> pairs;
if (subwords.size() < 2) {
return pairs;
}
std::u32string prev_subword = subwords[0];
for (size_t i = 1; i < subwords.size(); i++) {
std::u32string subword = subwords[i];
pairs.emplace(prev_subword, subword);
prev_subword = subword;
}
return pairs;
}
bool CLIPTokenizer::load_from_file(const std::string& merges_file_path) {
std::ifstream file(merges_file_path);
if (!file.is_open()) {
std::cerr << "Failed to open merges file: " << merges_file_path << std::endl;
return false;
}
std::string merges_str((std::istreambuf_iterator<char>(file)), std::istreambuf_iterator<char>());
file.close();
load_from_merges(merges_str);
return true;
}
void CLIPTokenizer::load_from_merges(const std::string& merges_utf8_str) {
auto byte_unicode_pairs = bytes_to_unicode();
byte_encoder = std::map<int, std::u32string>(byte_unicode_pairs.begin(), byte_unicode_pairs.end());
std::vector<std::u32string> merges;
size_t start = 0;
size_t pos;
std::u32string merges_utf32_str = utf8_to_utf32(merges_utf8_str);
while ((pos = merges_utf32_str.find(U'\n', start)) != std::u32string::npos) {
merges.push_back(merges_utf32_str.substr(start, pos - start));
start = pos + 1;
}
if (!merges.empty()) {
merges = std::vector<std::u32string>(merges.begin() + 1, merges.end());
}
std::vector<std::pair<std::u32string, std::u32string>> merge_pairs;
for (const auto& merge : merges) {
size_t space_pos = merge.find(U' ');
if (space_pos == std::u32string::npos) continue;
merge_pairs.emplace_back(merge.substr(0, space_pos), merge.substr(space_pos + 1));
}
std::vector<std::u32string> vocab;
for (const auto& pair : byte_unicode_pairs) {
vocab.push_back(pair.second);
}
for (const auto& pair : byte_unicode_pairs) {
vocab.push_back(pair.second + U"</w>");
}
for (const auto& pair : merge_pairs) {
vocab.push_back(pair.first + pair.second);
}
vocab.push_back(U"<|startoftext|>");
vocab.push_back(U"<|endoftext|>");
encoder.clear();
for (size_t i = 0; i < vocab.size(); i++) {
encoder[vocab[i]] = static_cast<int>(i);
}
bpe_ranks.clear();
for (size_t i = 0; i < merge_pairs.size(); i++) {
bpe_ranks[merge_pairs[i]] = static_cast<int>(i);
}
}
std::u32string CLIPTokenizer::bpe(const std::u32string& token) {
if (token.empty()) return U"";
std::vector<std::u32string> word;
for (char32_t c : token) {
word.emplace_back(1, c);
}
if (!word.empty()) {
word.back() += U"</w>";
}
std::set<std::pair<std::u32string, std::u32string>> pairs = get_pairs(word);
if (pairs.empty()) {
return token + U"</w>";
}
while (true) {
auto min_pair_iter = pairs.end();
int min_rank = INT_MAX;
for (const auto& pair : pairs) {
auto it = bpe_ranks.find(pair);
if (it != bpe_ranks.end() && it->second < min_rank) {
min_rank = it->second;
min_pair_iter = pairs.find(pair);
}
}
if (min_pair_iter == pairs.end()) break;
const auto& bigram = *min_pair_iter;
std::u32string first = bigram.first;
std::u32string second = bigram.second;
std::vector<std::u32string> new_word;
size_t i = 0;
while (i < word.size()) {
auto it = std::find(word.begin() + i, word.end(), first);
if (it == word.end()) {
new_word.insert(new_word.end(), word.begin() + i, word.end());
break;
}
new_word.insert(new_word.end(), word.begin() + i, it);
i = std::distance(word.begin(), it);
if (i < word.size() - 1 && word[i] == first && word[i+1] == second) {
new_word.push_back(first + second);
i += 2;
} else {
new_word.push_back(word[i]);
i += 1;
}
}
word = new_word;
if (word.size() == 1) break;
pairs = get_pairs(word);
}
std::u32string result;
for (size_t i = 0; i < word.size(); i++) {
if (i > 0) result += U" ";
result += word[i];
}
return result;
}
std::vector<int> CLIPTokenizer::encode(std::string text) {
std::vector<int> bpe_tokens;
text = whitespace_clean(text);
std::transform(text.begin(), text.end(), text.begin(), [](unsigned char c) {
return std::tolower(c);
});
std::regex pat(R"(<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[a-zA-Z]+|[0-9]+|[^\s\w]+)");
std::sregex_iterator it(text.begin(), text.end(), pat);
std::sregex_iterator end;
for (; it != end; ++it) {
std::string token_str = it->str();
std::u32string utf32_token;
for (char b : token_str) {
auto encoder_it = byte_encoder.find(static_cast<unsigned char>(b));
if (encoder_it != byte_encoder.end()) {
utf32_token += encoder_it->second;
}
}
std::u32string bpe_strs = bpe(utf32_token);
if (bpe_strs.empty()) continue;
size_t start = 0;
size_t pos;
while ((pos = bpe_strs.find(U' ', start)) != std::u32string::npos) {
auto bpe_str = bpe_strs.substr(start, pos - start);
auto token_it = encoder.find(bpe_str);
if (token_it != encoder.end()) {
bpe_tokens.push_back(token_it->second);
}
start = pos + 1;
}
auto bpe_str = bpe_strs.substr(start);
auto token_it = encoder.find(bpe_str);
if (token_it != encoder.end()) {
bpe_tokens.push_back(token_it->second);
}
}
return bpe_tokens;
}
std::vector<int> CLIPTokenizer::tokenize(std::string text, size_t max_length, bool padding)
{
std::vector<int> tokens = encode(text);
tokens.insert(tokens.begin(), BOS_TOKEN_ID);
if (max_length > 0) {
if (tokens.size() > max_length - 1) {
tokens.resize(max_length - 1);
tokens.push_back(EOS_TOKEN_ID);
} else {
tokens.push_back(EOS_TOKEN_ID);
if (padding && tokens.size() < max_length) {
tokens.insert(tokens.end(), max_length - tokens.size(), PAD_TOKEN_ID);
}
}
}
return tokens;
}后处理clip_post.cpp
/*
* Company: AW
* Author: zhongzixins
* Date: 2026/02/09
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include "model_config.h"
typedef struct {
int img_index;
int text_index;
float score;
} clip_res;
typedef struct {
float value;
int index;
} element_t;
static void swap(element_t* a, element_t* b) {
element_t temp = *a;
*a = *b;
*b = temp;
}
static int partition(element_t arr[], int low, int high) {
float pivot = arr[high].value;
int i = low - 1;
for (int j = low; j <= high - 1; j++) {
if (arr[j].value >= pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
static void quick_sort(element_t arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quick_sort(arr, low, pi - 1);
quick_sort(arr, pi + 1, high);
}
}
static void softmax(float* arr, int size) {
float max_val = arr[0];
for (int i = 1; i < size; i++) {
if (arr[i] > max_val) {
max_val = arr[i];
}
}
for (int i = 0; i < size; i++) {
arr[i] -= max_val;
}
float sum = 0.0;
for (int i = 0; i < size; i++) {
arr[i] = expf(arr[i]);
sum += arr[i];
}
for (int i = 0; i < size; i++) {
arr[i] /= sum;
}
}
static void element_multiply(float* arr, int size, const float scale) {
for (int i = 0; i < size; i++) {
arr[i] *= scale;
}
}
static void matmul_by_cpu(float* A, float* B, float* out, int A_rows, int A_B_cols, int B_rows) {
float temp;
for (int i = 0; i < A_rows; i++) {
for (int j = 0; j < B_rows; j++) {
temp = 0;
for (int k = 0; k < A_B_cols; k++) {
temp += A[i * A_B_cols + k] * B[j * A_B_cols + k];
}
out[i * B_rows + j] = temp;
}
}
}
static void get_result_with_index(float* arr, int size, int text_num, clip_res* res) {
element_t* elements = (element_t*)malloc(size * sizeof(element_t));
for (int i = 0; i < size; i++) {
elements[i].value = arr[i];
elements[i].index = i;
}
quick_sort(elements, 0, size - 1);
res->img_index = elements[0].index / text_num;
res->text_index = elements[0].index % text_num;
res->score = elements[0].value;
free(elements);
}
int post_process(float* img_output, float* text_output, int img_num, int text_num, clip_res* out_res) {
int out_size = img_num * text_num;
float* matmul_out = (float*)malloc(out_size * sizeof(float));
float logit_scale = 4.605170249938965;
matmul_by_cpu(img_output, text_output, matmul_out, img_num, FEAT_DIM, text_num);
element_multiply(matmul_out, out_size, expf(logit_scale));
softmax(matmul_out, out_size);
get_result_with_index(matmul_out, out_size, text_num, out_res);
if (matmul_out != NULL) {
free(matmul_out);
}
return 0;
}主函数 main()
/*
* Company: AW
* Author: zhuzhiyongs
* Date: 2026/03/19
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>
#include <opencv2/core/core.hpp>
#include "npulib.h"
#include "model_config.h"
/*-------------------------------------------
Macros and Variables
-------------------------------------------*/
extern int mobilesam_preprocess(const char* imagepath, void* buff_ptr, unsigned int buff_size);
extern int mobilesam_postprocess(const char *imagepath, float **output);
extern void calculate_scale_and_padding(const char* image_file, float& scale_letterbox, int& top, int& left);
const char *usage =
"model_demo -encoder encoder_model_path -decoder decoder_model_path -i input_path -l loop_run_count -m malloc_mbyte \n"
"-encoder encoder_model_path: the encoder NBG file path.\n"
"-decoder decoder_model_path: the decoder NBG file path.\n"
"-i input_path: the input file path.\n"
"-l loop_run_count: the number of loop run network.\n"
"-m malloc_mbyte: npu_unit init memory Mbytes.\n"
"-h : help\n"
"example: model_demo -encoder encoder.nb -decoder decoder.nb -i input.jpg -l 10 -m 20 \n";
enum time_idx_e {
NPU_INIT = 0,
NETWORK_CREATE,
NETWORK_PREPARE,
NETWORK_PREPROCESS,
NETWORK_RUN,
NETWORK_LOOP,
TIME_IDX_MAX = 9
};
// float -> fp16
uint16_t float_to_fp16(float value) {
uint32_t f32 = *(uint32_t*)&value;
uint32_t sign = (f32 >> 31) & 0x1;
uint32_t exponent = (f32 >> 23) & 0xff;
uint32_t mantissa = f32 & 0x7fffff;
if (exponent == 0xff) {
return (sign << 15) | 0x7c00 | (mantissa >> 13);
} else if (exponent == 0) {
if (mantissa == 0) {
return sign << 15;
} else {
int shift = __builtin_clz(mantissa) - 8;
mantissa <<= shift;
exponent = 1 - shift;
return (sign << 15) | ((exponent & 0x1f) << 10) | (mantissa >> 13);
}
} else {
int new_exponent = exponent - 127 + 15;
if (new_exponent > 0x1f) {
return (sign << 15) | 0x7c00;
} else if (new_exponent < 1) {
int shift = 1 - new_exponent;
mantissa = (0x800000 | mantissa) >> shift;
return (sign << 15) | (mantissa >> 13);
} else {
return (sign << 15) | ((new_exponent & 0x1f) << 10) | (mantissa >> 13);
}
}
}
// float -> fp16
void float_array_to_fp16(const float* float_array, uint16_t* fp16_array, size_t size) {
for (size_t i = 0; i < size; i++) {
fp16_array[i] = float_to_fp16(float_array[i]);
}
}
int main(int argc, char** argv)
{
int status = 0;
int i = 0;
unsigned int count = 0;
long long total_infer_time = 0;
char *encoder_model_file = nullptr;
char *decoder_model_file = nullptr;
char *input_file = nullptr;
unsigned int loop_count = 1;
if (argc < 2) {
printf("%s\n", usage);
return -1;
}
for (i = 0; i< argc; i++) {
if (!strcmp(argv[i], "-encoder")) {
encoder_model_file = argv[++i];
}
else if (!strcmp(argv[i], "-decoder")) {
decoder_model_file = argv[++i];
}
else if (!strcmp(argv[i], "-i")) {
input_file = argv[++i];
}
else if (!strcmp(argv[i], "-l")) {
loop_count = atoi(argv[++i]);
}
else if (!strcmp(argv[i], "-h")) {
printf("%s\n", usage);
return 0;
}
}
printf("encoder_model_file=%s, decoder_model_file=%s, input=%s, loop_count=%d \n", encoder_model_file, decoder_model_file, input_file, loop_count);
if (encoder_model_file == nullptr || decoder_model_file == nullptr)
return -1;
/* NPU init*/
NpuUint npu_uint;
int ret = npu_uint.npu_init();
if (ret != 0) {
return -1;
}
// encoder
NetworkItem encoder;
unsigned int encoder_id = 0;
status = encoder.network_create(encoder_model_file, encoder_id);
if (status != 0) {
printf("encoder network create failed.\n");
return -1;
}
status = encoder.network_prepare();
if (status != 0) {
printf("encoder network prepare fail, status=%d\n", status);
return -1;
}
// decoder
NetworkItem decoder;
unsigned int decoder_id = 1;
status = decoder.network_create(decoder_model_file, decoder_id);
if (status != 0) {
printf("decoder network create failed.\n");
return -1;
}
status = decoder.network_prepare();
if (status != 0) {
printf("decoder network prepare fail, status=%d\n", status);
return -1;
}
TimeBegin(NETWORK_PREPROCESS);
// input jpg file, no copy way
void *input_buffer_ptr = nullptr;
unsigned int input_buffer_size = 0;
encoder.get_network_input_buff_info(0, &input_buffer_ptr, &input_buffer_size);
printf("encoder input buffer ptr: %p, buffer size: %d \n", input_buffer_ptr, input_buffer_size);
mobilesam_preprocess(input_file, input_buffer_ptr, input_buffer_size);
TimeEnd(NETWORK_PREPROCESS);
printf("feed input cost: %lu us.\n", (unsigned long)TimeGet(NETWORK_PREPROCESS));
// create encoder output buffer
int encoder_output_cnt = encoder.get_output_cnt();
float **encoder_output_data = new float*[encoder_output_cnt]();
for (int i = 0; i < encoder_output_cnt; i++)
encoder_output_data[i] = new float[encoder.m_output_data_len[i]];
// create decoder output buffer
int decoder_output_cnt = decoder.get_output_cnt();
float **decoder_output_data = new float*[decoder_output_cnt]();
for (int i = 0; i < decoder_output_cnt; i++) {
decoder_output_data[i] = new float[decoder.m_output_data_len[i]];
}
i = 0;
/* run network */
TimeBegin(NETWORK_LOOP);
while (count < loop_count) {
count++;
// run encoder
status = encoder.network_input_output_set();
if (status != 0) {
printf("set encoder input/output failed.\n");
return -1;
}
#if defined (__linux__)
TimeBegin(NETWORK_RUN);
#endif
status = encoder.network_run();
if (status != 0) {
printf("fail to run encoder, status=%d\n", status);
return -2;
}
#if defined (__linux__)
TimeEnd(NETWORK_RUN);
printf("encoder run time: %lu us.\n", (unsigned long)TimeGet(NETWORK_RUN));
#endif
total_infer_time += (unsigned long)TimeGet(NETWORK_RUN);
// get encoder output
encoder.get_output(encoder_output_data);
// Use the encoder output as the decoder input (1, 256, 28, 28).
void *decoder_input_ptr = nullptr;
unsigned int decoder_input_size = 0;
int ret = decoder.get_network_input_buff_info(0, &decoder_input_ptr, &decoder_input_size);
if (ret == 0 && decoder_input_ptr != nullptr && decoder_input_size > 0) {
// fp32 -> fp16
float_array_to_fp16(encoder_output_data[0], (uint16_t*)decoder_input_ptr, encoder.m_output_data_len[0]);
} else {
printf("Error: Failed to get decoder input 0 buffer info\n");
return -1;
}
// point_coords input (1, 2, 2)
void *point_coords_ptr = nullptr;
unsigned int point_coords_size = 0;
ret = decoder.get_network_input_buff_info(1, &point_coords_ptr, &point_coords_size);
if (ret == 0 && point_coords_ptr != nullptr && point_coords_size > 0) {
float scale_letterbox;
int top, left;
calculate_scale_and_padding(input_file, scale_letterbox, top, left);
float point_coords_float[4] = {
TOP_LEFT_X * scale_letterbox + left, // x1
TOP_LEFT_Y * scale_letterbox + top, // y1
BOTTOM_RIGHT_X * scale_letterbox + left, // x2
BOTTOM_RIGHT_Y * scale_letterbox + top // y2
};
for (int i = 0; i < 4; i++) {
if (point_coords_float[i] < 0.0f) point_coords_float[i] = 0.0f;
if (point_coords_float[i] > LETTERBOX_ROWS) point_coords_float[i] = LETTERBOX_ROWS;
}
// float32 -> fp16
uint16_t point_coords_fp16[4];
float_array_to_fp16(point_coords_float, point_coords_fp16, 4);
memcpy(point_coords_ptr, point_coords_fp16, sizeof(point_coords_fp16));
} else {
printf("Error: Failed to get decoder input 1 buffer info\n");
return -1;
}
// point_labels
void *point_labels_ptr = nullptr;
unsigned int point_labels_size = 0;
ret = decoder.get_network_input_buff_info(2, &point_labels_ptr, &point_labels_size);
if (ret == 0 && point_labels_ptr != nullptr && point_labels_size > 0) {
float point_labels_float[2] = {2.0f, 3.0f};
// float32 -> fp16
uint16_t point_labels_fp16[2];
float_array_to_fp16(point_labels_float, point_labels_fp16, 2);
memcpy(point_labels_ptr, point_labels_fp16, sizeof(point_labels_fp16));
} else {
printf("Error: Failed to get decoder input 2 buffer info\n");
return -1;
}
// mask_input (1, 1, 112, 112)
void *mask_input_ptr = nullptr;
unsigned int mask_input_size = 0;
ret = decoder.get_network_input_buff_info(3, &mask_input_ptr, &mask_input_size);
if (ret == 0 && mask_input_ptr != nullptr && mask_input_size > 0) {
memset(mask_input_ptr, 0, mask_input_size);
} else {
printf("Error: Failed to get decoder input 3 buffer info\n");
return -1;
}
// has_mask_input
void *has_mask_input_ptr = nullptr;
unsigned int has_mask_input_size = 0;
ret = decoder.get_network_input_buff_info(4, &has_mask_input_ptr, &has_mask_input_size);
if (ret == 0 && has_mask_input_ptr != nullptr && has_mask_input_size > 0) {
uint8_t has_mask_input_uint8 = 0;
memcpy(has_mask_input_ptr, &has_mask_input_uint8, sizeof(has_mask_input_uint8));
} else {
printf("Error: Failed to get decoder input 4 buffer info\n");
return -1;
}
// run decoder
status = decoder.network_input_output_set();
if (status != 0) {
printf("set decoder input/output failed.\n");
return -1;
}
#if defined (__linux__)
TimeBegin(NETWORK_RUN);
#endif
status = decoder.network_run();
if (status != 0) {
printf("fail to run decoder, status=%d\n", status);
return -2;
}
#if defined (__linux__)
TimeEnd(NETWORK_RUN);
printf("decoder run time: %lu us.\n", (unsigned long)TimeGet(NETWORK_RUN));
#endif
total_infer_time += (unsigned long)TimeGet(NETWORK_RUN);
// get decoder output
decoder.get_output(decoder_output_data);
// postprocess
mobilesam_postprocess(input_file, decoder_output_data);
}
TimeEnd(NETWORK_LOOP);
if (loop_count > 1) {
printf("this network run avg inference time=%d us, total avg cost: %d us\n",
(uint32_t)(total_infer_time / loop_count), (unsigned int)(TimeGet(NETWORK_LOOP) / loop_count));
}
// free output buffer
for (int i = 0; i < encoder_output_cnt; i++) {
delete[] encoder_output_data[i];
encoder_output_data[i] = nullptr;
}
if (encoder_output_data != nullptr)
delete[] encoder_output_data;
for (int i = 0; i < decoder_output_cnt; i++) {
delete[] decoder_output_data[i];
decoder_output_data[i] = nullptr;
}
if (decoder_output_data != nullptr)
delete[] decoder_output_data;
return ret;
}
模型转换
注:进入全志的docker环境,并进入awnpu_model_zoo\examples\clip\进行后续操作。
clip-images
# using xxx_env.sh to create softlink
./convert_model_env.sh
# 导入
# pegasus_import.sh <model_name>
./pegasus_import.sh clip-images
# 量化
# pegasus_quantize.sh <model_name> <quantize_type> <calibration_set_size>
./pegasus_quantize.sh clip-images uint8 10
# 仿真(可选)
# pegasus_inference.sh <model_name> <quantize_type>
./pegasus_inference.sh clip-images uint8
# 导出nb模型
# pegasus_export_ovx_nbg.sh <model_name> <quantize_type> <platform>
./pegasus_export_ovx_nbg.sh clip-images uint8 mr536
# 导出的模型文件存放在../model目录
# 例如 ../model/clip-images_uint8_mr536.nbclip-text
# using xxx_env.sh to create softlink
./convert_model_env.sh
# 导入
# pegasus_import.sh <model_name>
./pegasus_import.sh clip-text
# 量化
# pegasus_quantize.sh <model_name> <quantize_type> <calibration_set_size>
./pegasus_quantize.sh clip-text int16 10
# 仿真(可选)
# pegasus_inference.sh <model_name> <quantize_type>
./pegasus_inference.sh clip-text int16
# 导出nb模型
# pegasus_export_ovx_nbg.sh <model_name> <quantize_type> <platform>
./pegasus_export_ovx_nbg.sh clip-text int16 mr536
# 导出的模型文件存放在../model目录
# 例如 ../model/clip-text_int16_mr536.nb交叉编译
编译工具链参考其他模型,这里直接给出编译命令
cd ../examples/clip/
./../build_linux.sh -t mr536在./examples/clip/目录下生成install目录,目录结构如下:
`-- clip_demo_linux_mr536
|-- clip_demo_mr536
`-- model
|-- clip-images_uint8_mr536.nb
|-- clip-text_int16_mr536.nb
|-- demo.png
|-- demo.txt
`-- merges.txt
模型推理
将上述生成的文件推送至开发板,方式不限于adb这一种
adb push .\install\clip_demo_linux_mr536 /mnt/UDISK/运行推理:
chmod +x ./clip_demo_mr536
./clip_demo_mr536 -ib model/clip-images_uint8_mr536.nb -tb model/clip-text_int16_mr536.nb -i model/demo.png -t
model/demo.txt板端的运行结果:
images: model/demo.png
text : a photo of a motorcycle
score : 0.998
destory npu finished.
~NpuUint.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)