【晓天衡宇·评测社区】前沿物理推理-台球宇宙评测榜单正式发布
【榜单简介】
本榜单以BilliardPhys Bench为核心评测基准,系统性地对12个主流大语言模型在前沿物理相关能力上开展对比评测。
BilliardPhys Bench用于评估多模态大型语言模型(LMMs)物理推理和视觉动力学能力,通过合成台球场景的前向物理模拟预测来评估模型的物理直觉理解能力。
【查看完整榜单】👉🏻 https://skylenage.net/sla/leaderboard
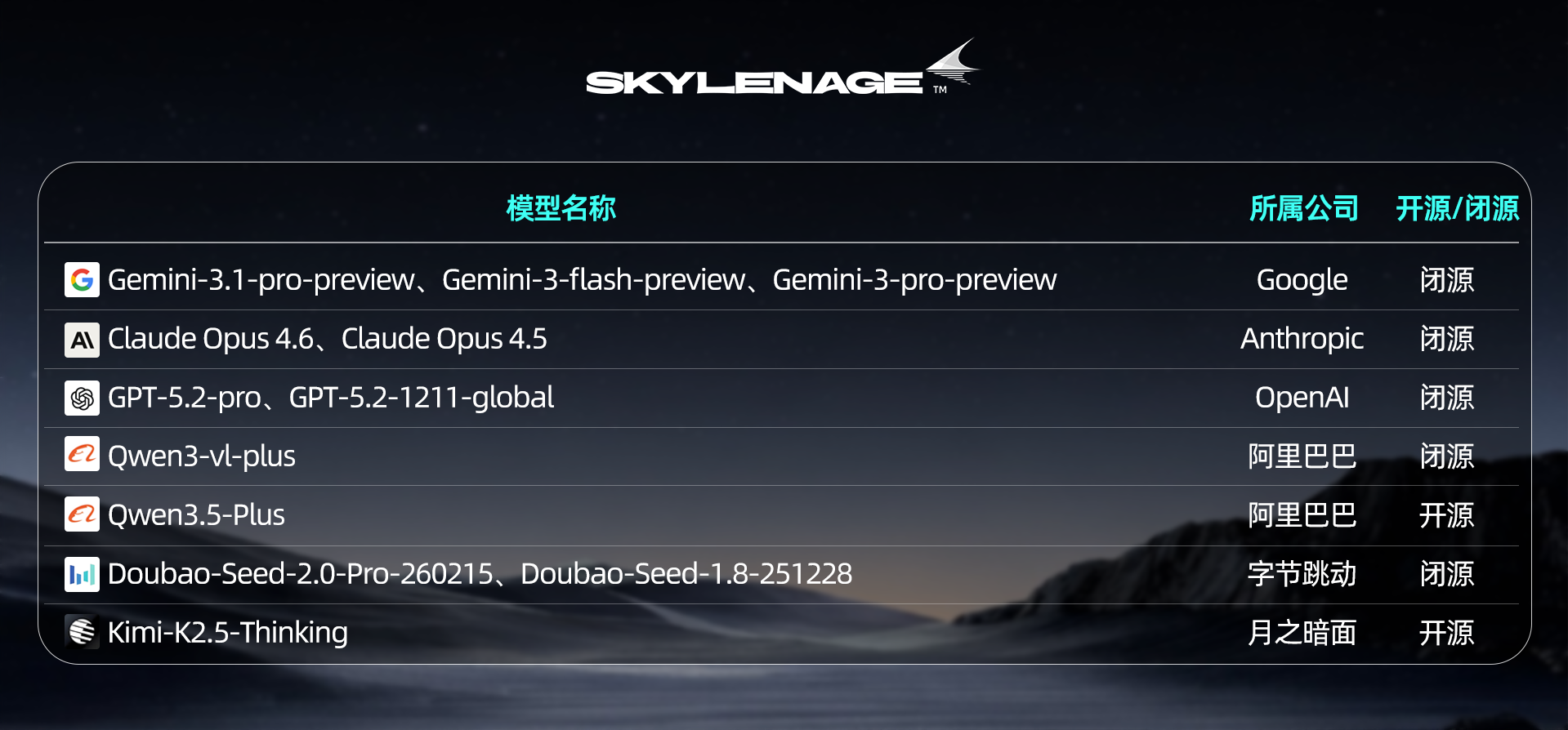
【参评模型】
【评测集解读】
评测维度
核心评估指标:
-
准确率 (Accuracy): 作为所有任务的主要评分标准。
-
时间维度平均: 每个任务需计算1s、2s、3s、4s、5s五个时间点的平均准确率(Acc\_T = \sum Acc@ns / 5)。
分层任务指标:

数据标准
1. 场景构成:
-
核心场景: 基于台球场景(BilliardPhys)的物理交互。
-
生成方式: 使用程序化引擎生成的合成场景,具有多样化和随机性。
-
数据形式: 给定台球场景的初始图像。
2. 物理仿真参数:
-
运动模型: 严格基于物理规律,包括摩擦力(\mu = 0.002)和重力加速度(g = 9.8 m/s²)。
-
碰撞模型: 完全弹性碰撞。
-
数学公式: 包含速度衰减公式 v(s) = \sqrt{v_0^2 - 2\mu gs} 和球停止距离公式 s_{stop} = v_0^2/(2\mu g)。
3. 数据特性:
-
敏感性: 对初始条件的微小偏差具有高度敏感性。
-
时间维度: 覆盖从1秒到5秒的连续时间跨度。
-
难度梯度: 分为三个难度等级(基础、中等、高等),从离散事件预测到连续状态估计。
【评分标准】
加权总分计算:

【榜单速览】
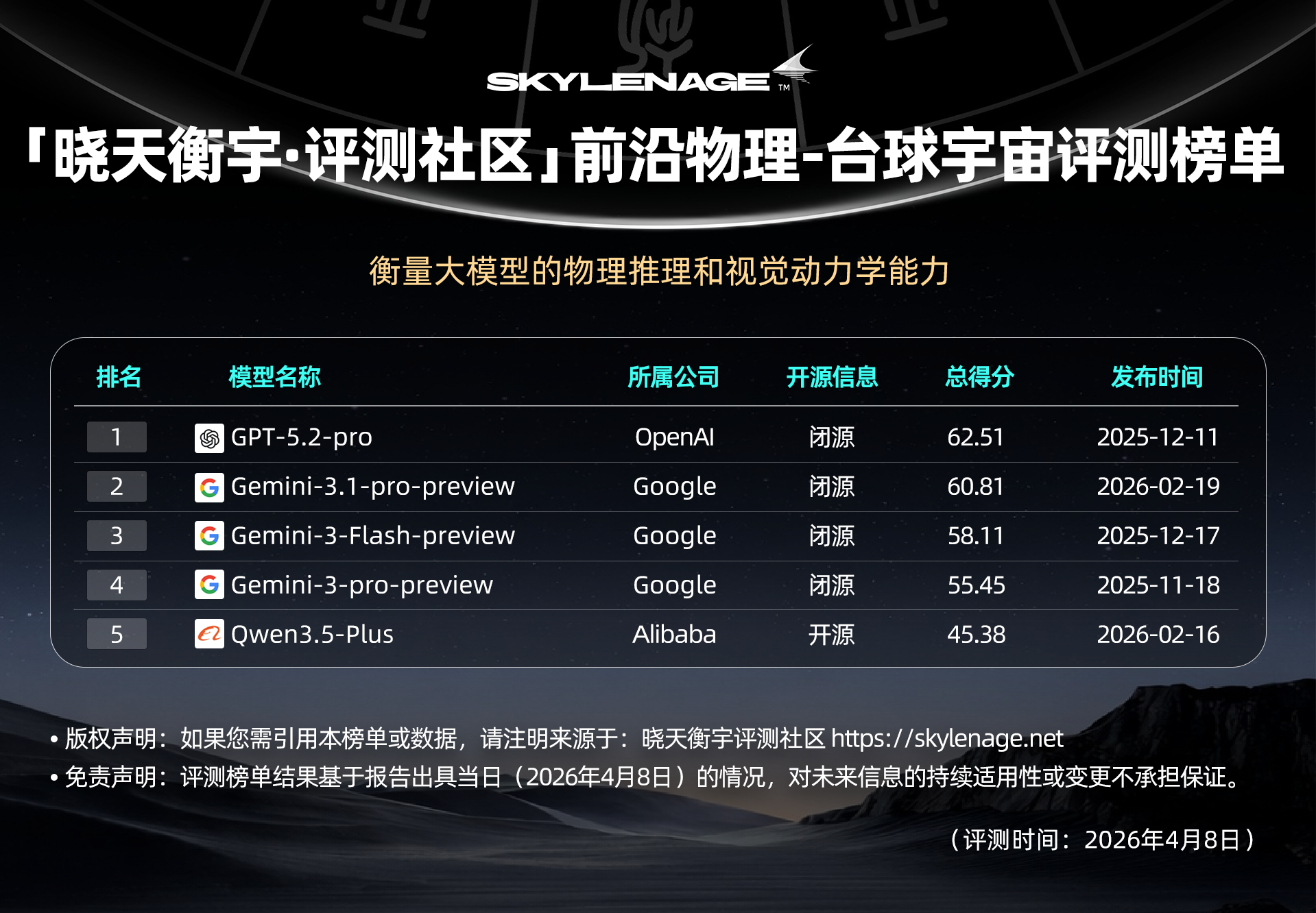
冠军:GPT-5.2-pro (62.51分)
全面无短板,在高权重的复杂推理和定量计算上表现稳健,没有明显的“静止偏见”,能够处理复杂的反弹逻辑和能量耗散计算。在Task 2(边界推理)上拿到了全场最高的78.66分,在Task 3(连续状态估计)上也表现出色(62.02分)。
强力挑战者:Gemini-3.1-pro-preview (60.81分)
在最难的Task 3(连续状态估计)中拿到了全场最高的65.80分。这说明Gemini在处理纯物理数值模拟(如精确坐标预测)方面极具潜力,虽然总分略低于GPT-5.2,但在最考验物理引擎能力的环节表现最强。
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网。https://skylenage.net/sla/leaderboard
【榜单结论】
1、感知-推理间隙(Perception-Reasoning Gap)
模型虽然能描述物理规则,但难以精确预测动态结果
2、准确率下降
-
随着模拟时间增加,准确率显著下降
-
随着几何复杂性增长,精确度急剧下降
3、系统性偏见:保守幻觉(Conservative Hallucination)
-
模型在面对复杂物理场景时倾向于预测没有相互作用
-
这被称为"stasis bias"(静止偏见)
【了解更多】
台球宇宙评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.alibaba-inc.com
👇关注晓天衡宇•评测社区官方平台,获取更多大模型相关知识~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)