别往你的skills目录里堆狗屎了
自Anthropic发明skills以来,我发现大家对skills是越来越青睐了,原先skills用来辅助工作 开发,后来进化出了不少新玩法啊,
什么同事.skill,前任.skill,更有甚者:张雪峰.skill(尊重逝者🙏)
这些都是蒸馏玩法,属实是被玩出花来了
玩归玩,不要把这些🐮🐴玩意放到工作和开发的skills目录里,因为这会增加你的skills数量,增加无用上下文,降低ai使用skills的命中率。
有篇paper专门分析了skills的数量-内容与准确性的关系:When Single-Agent with Skills Replace Multi-Agent Systems and When They Fail
论文用gpt-4o和gpt-4o-mini做了skills数量与选择准确率关系的实验,实验结果放在这个表里
| skills数量 | 选择准确率 |
|---|---|
| ≤ 10 | > 97% |
| 10 ~ 30 | 90% ~ 97% |
| 30 ~ 50 | 85% ~ 93% |
| 50 ~ 80 | 60% ~ 85% |
| 80 ~ 100 | 45% ~ 55% |
| 100 ~ 150 | 15% ~ 40% |
| ≥ 150 | < 15% |
也有拟合曲线:
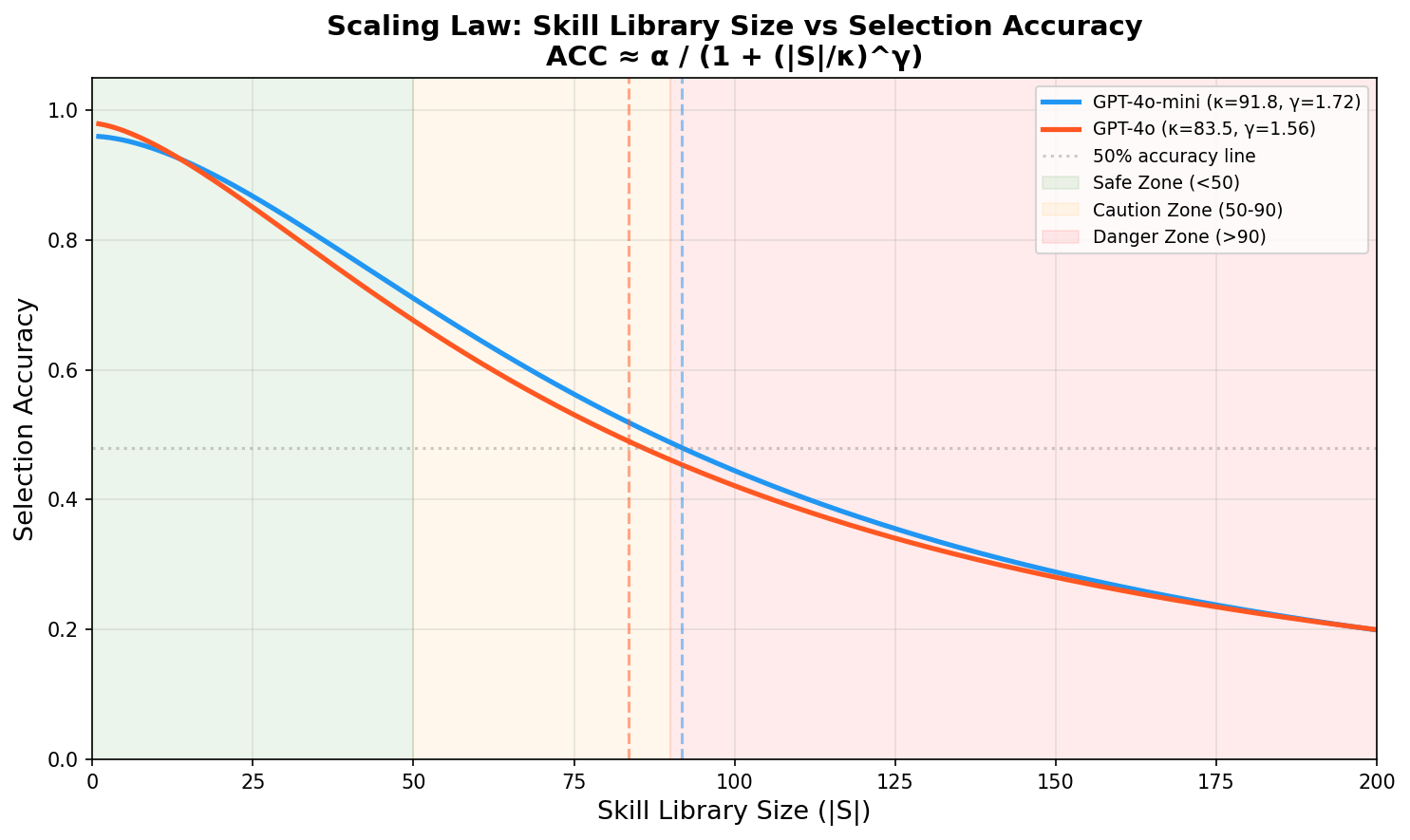
skills数量在50个以内,选择准确率都是比较高的(当然,不同AI跑出来的结果必然不同,这里的结果仅做参考),尤其是skills在25个以内时,命中率是相当高的
我在开发中也有类似的感受,曾经我在全局skills目录里塞了不少五花八门的skills,打开cc后一问才知道,总skills数量有60+,怪不得ai经常不选我希望ai用的skills。
后来我去繁从简,精挑细选,屎里淘金,把skills数量压到了40以内。按实验结果,我为什么没有压倒20-30呢,因为上文也说了,这个实验是基于gpt-4o系列ai做的,我用的ai性能比4o强,不必对号入座。
不只是数量,相似的skills也会大大降低选择准确率
论文做的实验,每个skills有一个相似的“竞争者”,准确率降到~82%,有两个相似的“竞争者”,准确率骤降到 ~52%。如果有从几个功能很相似的skills里选,ai往往会遮着眼睛瞎选(ai没眼睛 说是)。
打个比方
你和你老婆晚上准备双排了,你老婆的双胞胎妹妹趁着黑灯瞎火,悄无声息地摸进来,你能分清谁是谁吗?如果你硬上的话,我打赌要出事故的
所以,功能相似的skills只保留一个
如果skills实在是多,怎么办呢,论文里给出了层级路由的选法,简单来说就是“先选类别,再选skills”
比如开发会用到code-review,test-dirven-development,subagent-driven-development……那么就把这些归为“开发类”,依次类推还有“写作类”,“设计类”等等。ai选择使用skills的时候,就先判别应该用什么类别,再选择具体的skills。
论文里的层级路由的实验结果显示,这个方法在大数量skills的情况下会把准确率提高小几十个百分点。
当然嘛,据我所知 claude code 现在是没有“层级路由”的实现的,只是单纯的把skills全部平铺开来,让ai选。
不过没关系,我自己对于不同类别的skills是这样处理的:建立不同的skills仓库,把杂乱的skills给划分到不同的局部仓库里,让全局skills保持简洁,装你必备的,常用的;局部仓库里装其他类别的skills,分开使用。
比如我开一个名为“WPS-skills”的仓库,wps的skills就安装在这里面,要编辑WPS的文件的时候,就在这个仓库里工作;其他仓库是没有wps的skills的。
那我说白了,总的来说就是:降低skills数量,不要出现太相似的几个skills,skills分类管理。
skills不在于多,而在于精,选择最常用的,最适合自己的skills就是 The best。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)