Kafka vs RabbitMQ:架构设计与应用场景深度对比
·
在分布式系统中,消息队列(Message Queue)几乎是标配组件。而在实际选型中,最常被拿来对比的就是 Apache Kafka 和 RabbitMQ。
很多文章停留在“Kafka 吞吐高、RabbitMQ 灵活”这种表层对比,但如果你要做系统设计或面试高级岗位,这远远不够。
这篇文章,我们从架构设计、消息模型、性能机制、可靠性、使用场景几个维度,做一次“工程级”拆解。
🧠 一、核心定位差异(本质区别)
| 对比维度 | Kafka | RabbitMQ |
|---|---|---|
| 本质定位 | 分布式流处理平台 | 传统消息队列 |
| 设计目标 | 高吞吐、日志存储、流式处理 | 可靠投递、复杂路由 |
| 消息模型 | 基于日志(Log-based) | 基于队列(Queue-based) |
👉 一句话总结:
- Kafka:更像“分布式日志系统”
- RabbitMQ:更像“智能消息中间件”
🏗 二、架构设计对比
1️⃣ Kafka 架构
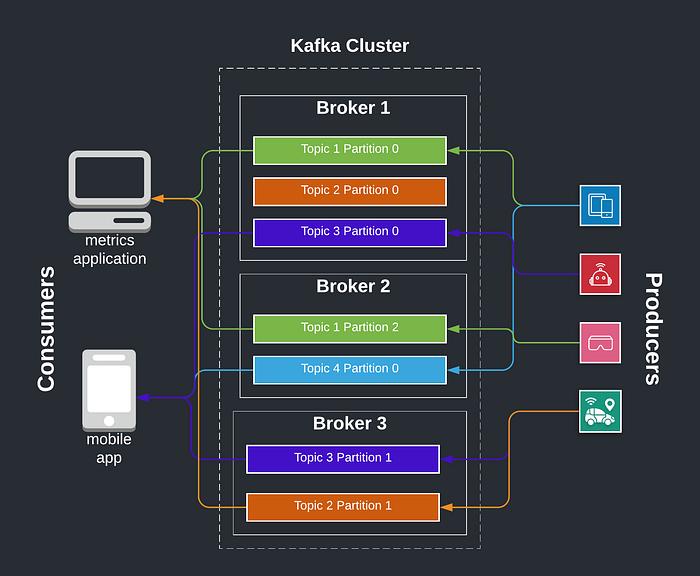
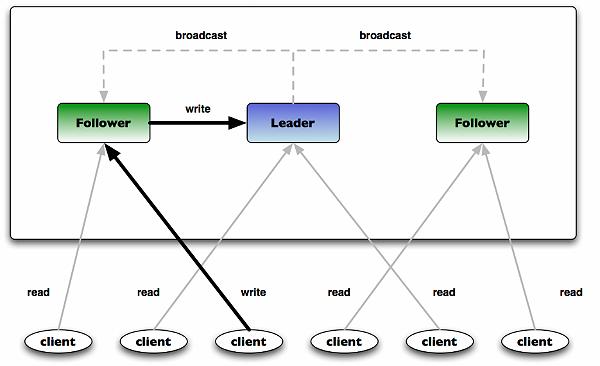
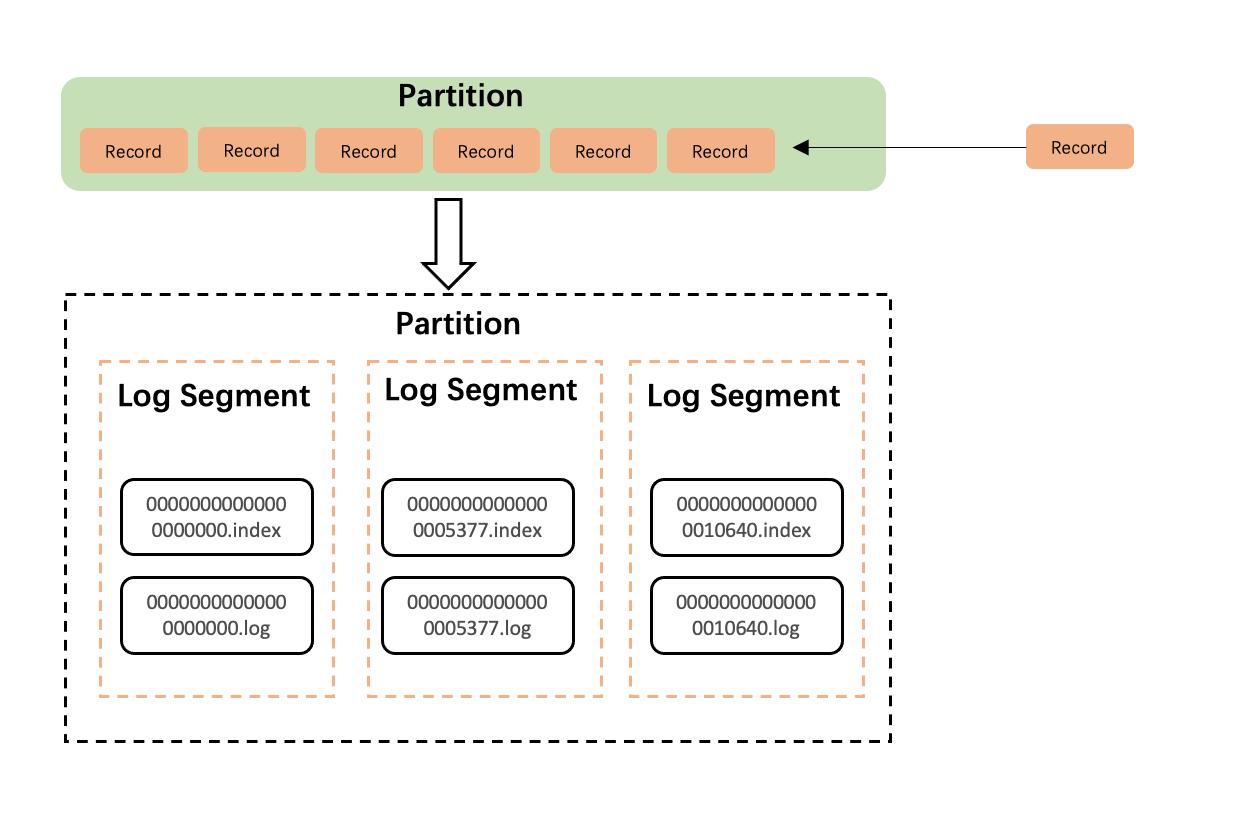
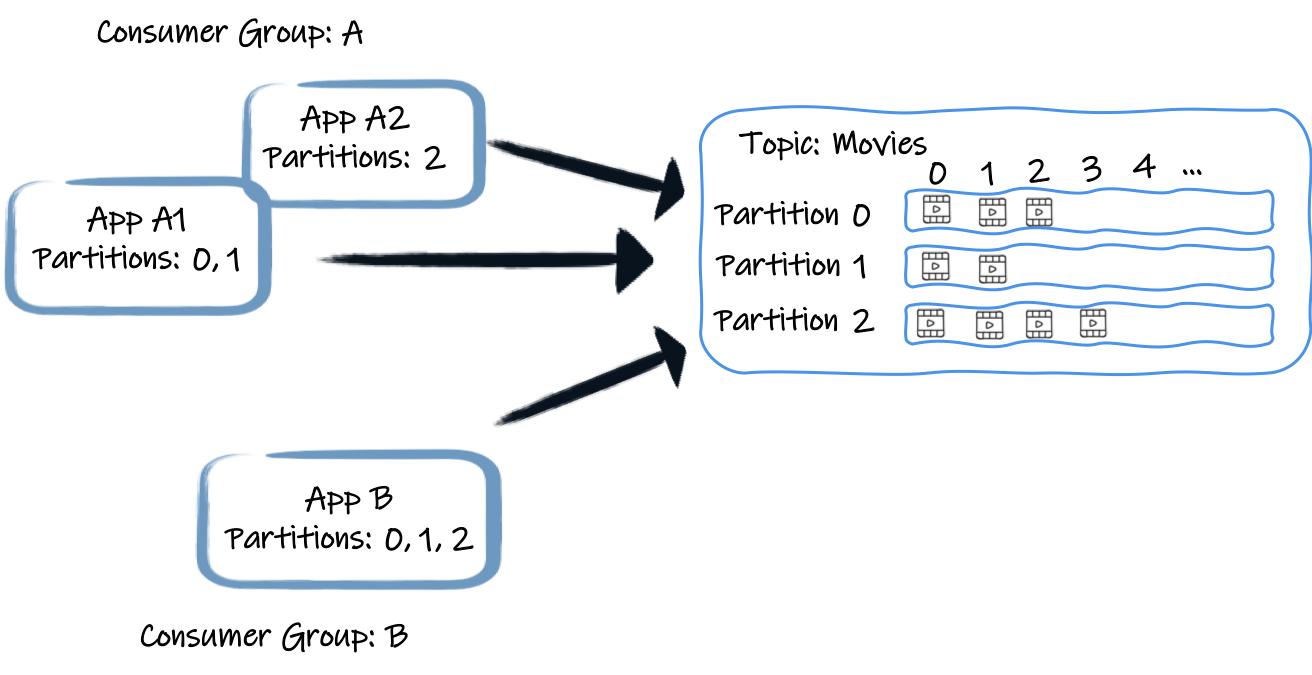
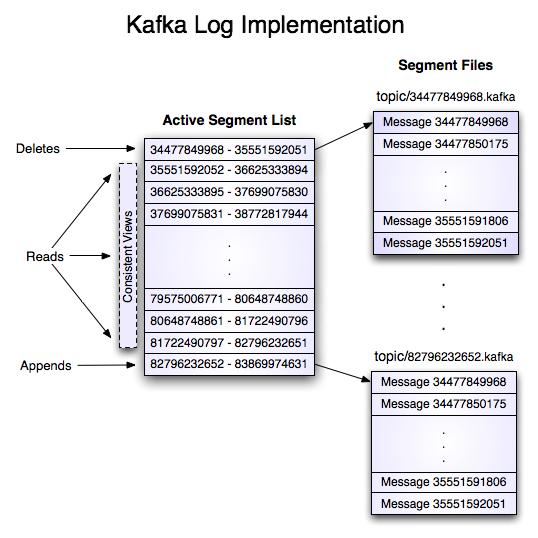
Kafka 的核心组件:
- Broker:节点
- Topic:逻辑分类
- Partition:物理分区(核心)
- Replica:副本机制(Leader / Follower)
- Consumer Group:消费组
👉 核心设计思想:
顺序写磁盘 + 分区并行 + 批量处理
2️⃣ RabbitMQ 架构
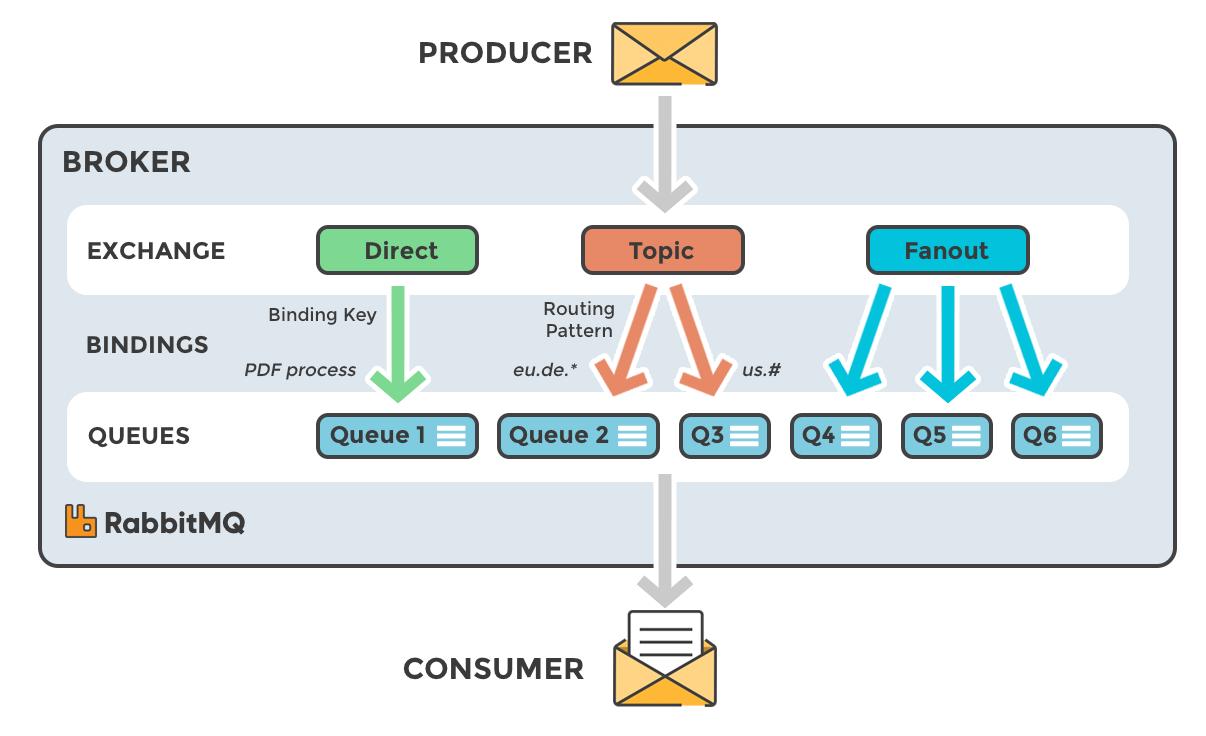
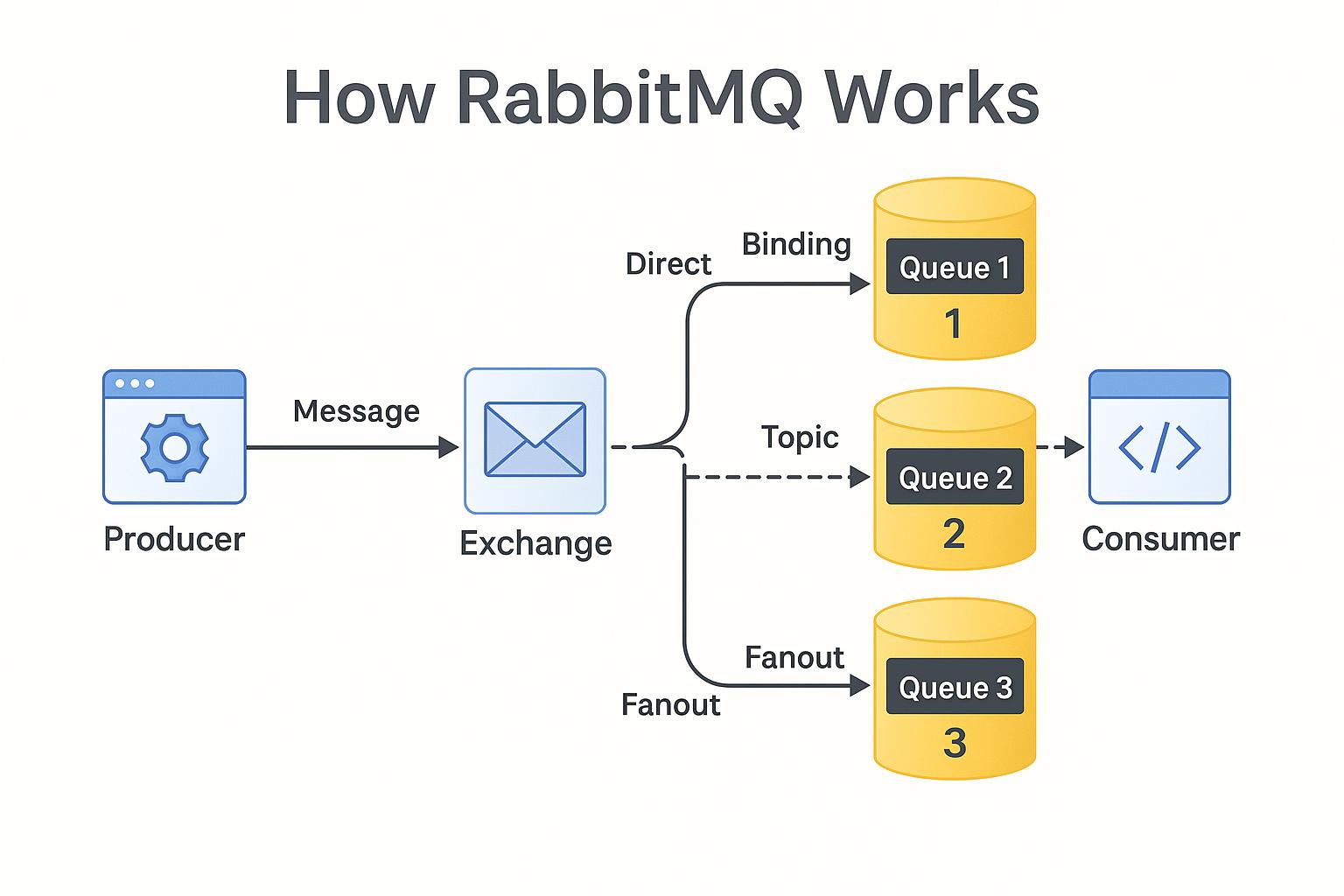
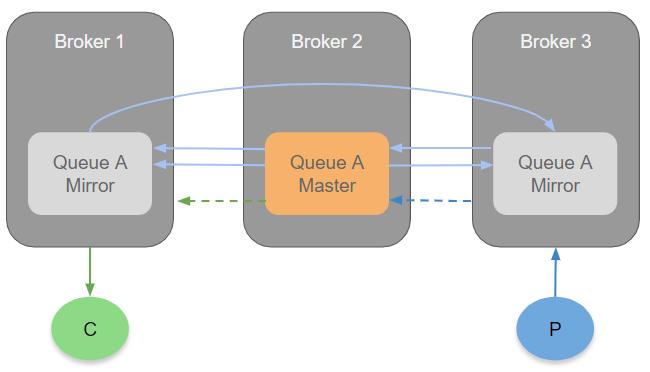
RabbitMQ 基于 AMQP 协议,核心组件:
- Producer
- Exchange(交换机)
- Queue(队列)
- Binding(绑定规则)
- Consumer
👉 核心设计思想:
消息路由(Exchange)驱动一切
⚙️ 三、消息模型对比(设计哲学差异)
Kafka:Pull + 顺序日志
- Consumer 主动拉取(Pull)
- 消息按 Partition 顺序存储
- Offset 由消费者控制
- 支持消息回溯(Replay)
👉 特点:
- 天然支持事件溯源
- 支持大数据/流处理
RabbitMQ:Push + 路由机制
- Broker 主动推送(Push)
- Exchange 决定消息路由
- 消费者确认(ACK)机制
👉 支持多种模式:
- Direct(精准匹配)
- Topic(模糊匹配)
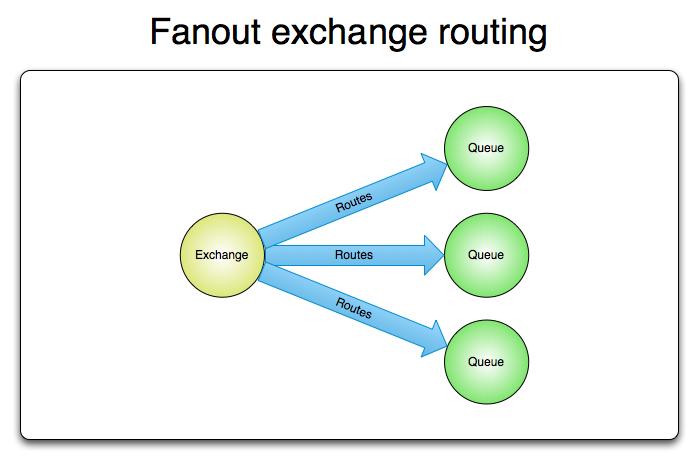
- Fanout(广播)
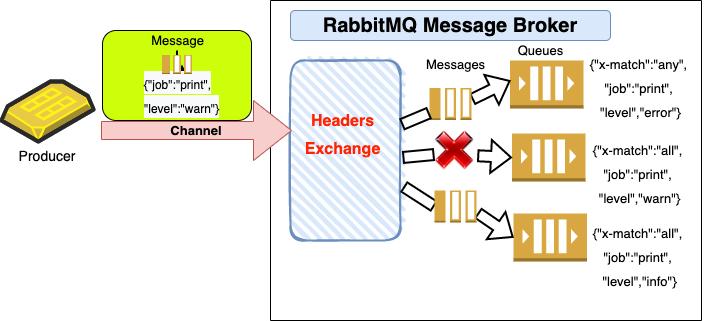
- Headers(复杂匹配)
🚀 四、性能与吞吐量对比
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 吞吐量 | ⭐⭐⭐⭐⭐(百万级 QPS) | ⭐⭐~⭐⭐⭐ |
| 延迟 | 较低(批处理优化) | 更低(实时推送) |
| 磁盘利用 | 顺序写(极高效) | 随机写 |
| 扩展性 | 水平扩展强 | 相对有限 |
👉 Kafka 为什么快?
- 顺序写磁盘(避免随机 IO)
- 零拷贝(Zero Copy)
- 批量发送(Batch)
- Page Cache 利用
👉 RabbitMQ 为什么相对慢?
- 消息路由开销大
- Erlang 实现(并发强但吞吐有限)
- 多队列调度成本高
🔐 五、可靠性与一致性
Kafka
- 副本机制(ISR)
- ACK 机制(0 / 1 / all)
- 至少一次(At-least-once)
- 支持幂等生产者 + 事务(Exactly-once)
👉 特点:
更偏向“最终一致性 + 高吞吐”
RabbitMQ
- ACK 确认机制
- 持久化(Queue + Message)
- 死信队列(DLQ)
- 消息重试机制
👉 特点:
更偏向“强可靠投递”
🧩 六、功能特性对比
| 功能 | Kafka | RabbitMQ |
|---|---|---|
| 消息顺序 | 分区内有序 | 可控但复杂 |
| 延迟队列 | ❌(需额外实现) | ✅(原生支持) |
| 死信队列 | ❌(需实现) | ✅ |
| 路由能力 | 弱 | 极强 |
| 消息回溯 | ✅ | ❌ |
| 多协议支持 | 较少 | AMQP/MQTT/STOMP |
🎯 七、典型应用场景
Kafka 适合
- 日志收集(ELK)
- 大数据流处理(Flink / Spark)
- 用户行为埋点
- 实时数据管道(Data Pipeline)
👉 关键词:
高吞吐 + 可回放 + 数据流
RabbitMQ 适合
- 订单系统(解耦)
- 异步任务(邮件、短信)
- 延迟任务(定时关闭订单)
- 复杂业务路由
👉 关键词:
可靠性 + 灵活路由
🧠 八、选型建议(实战结论)
如果你是做:
👉 高并发数据系统
选 Kafka:
- 日志系统
- 埋点系统
- 数据中台
👉 业务系统解耦
选 RabbitMQ:
- 电商系统
- 支付系统
- 通知系统
👉 需要 BOTH?
👉 很多公司是:
Kafka + RabbitMQ 混合架构
- Kafka:数据流
- RabbitMQ:业务流
⚠️ 九、常见误区(高级面试加分点)
❌ 误区1:Kafka 可以替代 RabbitMQ
👉 错:
- Kafka 不擅长复杂路由
- 不适合低延迟业务通知
❌ 误区2:RabbitMQ 性能差
👉 错:
- 在中小规模系统完全够用
- 延迟更低(实时性更好)
❌ 误区3:Kafka 一定更高级
👉 错:
- 是场景适配问题,不是技术等级问题
🧾 十、总结(面试速记版)
👉 一句话版本:
- Kafka:高吞吐分布式日志系统
- RabbitMQ:高可靠消息路由系统
👉 核心对比:
- Kafka:吞吐 > 功能
- RabbitMQ:功能 > 吞吐
🏁 结尾
如果你只是“会用”,那只能写 CRUD。
如果你理解了它们的设计哲学,你才能做系统架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)