SIG-Chat 论文总结
一、论文要解决的问题
人在对话时,手势不只是"在空中比划",而是会和环境中的物体产生真实的交互。比如说"就在那边"时,人会自然地把头和身体转向目标,同时用手指向它。
现有方法只解决了 HOW(手势风格和节奏),忽略了 WHEN(什么时候触发交互)和 WHERE(朝向哪里),论文的目标就是同时解决这三个问题。
二、核心概念基础
SMPL 人体模型
论文使用 SMPL-H(SMPL的手部扩展版本,52个关节)作为人体表示格式。SMPL 的输入参数有三类:
形状参数 β → 控制体型(高矮胖瘦),固定不变
姿态参数 θ → 控制动作(关节旋转),逐帧变化
全局平移 t → 控制位置(在空间哪里),逐帧变化每帧姿态表示为:
:水平位移
:根节点高度
- :所有关节的6D旋转
为什么用6D旋转:比欧拉角(万向节死锁)和四元数(双重覆盖)更连续,对神经网络更友好。
旋转矩阵是3×3矩阵,满足正交约束()和行列式为+1,其三列分别表示原坐标系三个轴旋转后的朝向。6D旋转取旋转矩阵前两列,第三列通过叉积恢复。
三、数据集:SIG-Chat为什么用空间位置而不是视觉信号
端到端视觉方案会把相机外参也学进去,换相机或机器人平台就会失效。用3D坐标把感知和生成解耦,只需重新标定坐标变换即可,泛化能力更强。
数据规模和多样性
总量:7123条,80M帧,11.4小时,6位说话者
语言:中英文(4:6)
时长:1~60秒/条
初始姿态:站(54%)、坐(43%)、蹲(0.5%)、躺(2.5%)
意图类别:视觉注视(77%)、左手指向(11%)、右手指向(12%)
空间覆盖:6种静态方向 + 9种动态轨迹 = 15种空间模式两个Track的设计
| Track-I | Track-II | |
|---|---|---|
| 特点 | 无明确指示词,交互自发隐式 | 有明确指示词("就在那边"等) |
| 时间对应 | 音频和交互无明确对应 | 有精确的交互时间段标注 |
| 数量 | 6009条 | 1114条 |
| 用途 | 学习自然手势风格 | 学习精确交互时机 |
每条数据包含的完整字段
3D手势序列 + 音频 + 文本 + 意图类别(one-hot编码) + 初始姿态描述 + 3D目标位置/轨迹
四、评估指标
IAD(Intent Angular Deviation,意图角度偏差)
每帧计算"实际朝向"和"目标方向"之间的夹角 θ:
视觉注视:脸部朝向 vs 眼睛→目标向量
手部指向:手臂/手指方向 vs 关节→目标向量(取三者最小值)
├── 食指方向偏差
├── 手部朝向偏差
└── 前臂方向偏差IAR@k(Intent Alignment Ratio)
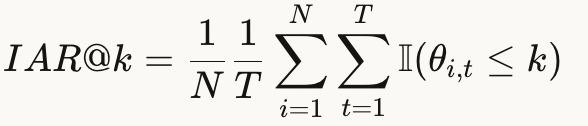
有多少比例的帧角度误差在k度以内。阈值基于人类真实数据的 mean+std 设定:
指向:k = 15°,注视:k = 30°
IoU@k(Intersection over Union)
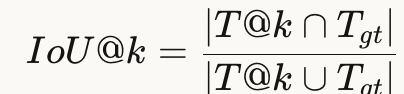
衡量交互时间段的重叠率,只在Track-II中使用(因为只有Track-II有精确的时间段标注)。
通用指标
| 指标 | 含义 | 方向 |
|---|---|---|
| FGD | 手势真实感(特征分布距离) | ↓越小越好 |
| BC | 语音-动作节拍一致性 | ↑越大越好 |
| Diversity | 生成结果的多样性(L1距离均值) | ↑越大越好 |
| min IAD | 整条序列中角度误差的最小值(峰值精度) | ↓越小越好 |
BC的检测方式:分别检测音频能量突变时刻(语音节拍)和关节速度峰值时刻(手势节拍),计算两者的时间对齐程度。
五、模型架构
整体框架
基于 Diffusion Transformer(DiT),核心思想是扩散模型:
训练:真实手势 → 逐步加噪声(1000步)→ 学习去噪
生成:纯噪声 → 逐步去噪 → 生成手势多模态编码器
| 输入 | 编码器 | 输出 | 特点 |
|---|---|---|---|
| 音频 | WavLM Large | 逐帧,节奏特征 | |
| 文本 | FastText+Gentle对齐 | 逐帧,语义特征 | |
| 初始姿态 | CLIP ViT-B/32 | 全局向量 | |
| 意图类别+轨迹 | 线性投影 | 逐帧,64维(经验选择) |
所有模态统一到256维(意图特征64维因为信息量本身较小),便于后续注意力融合。线性投影的作用不只是维度变换,更重要的是把不同来源的特征对齐到同一个语义空间。
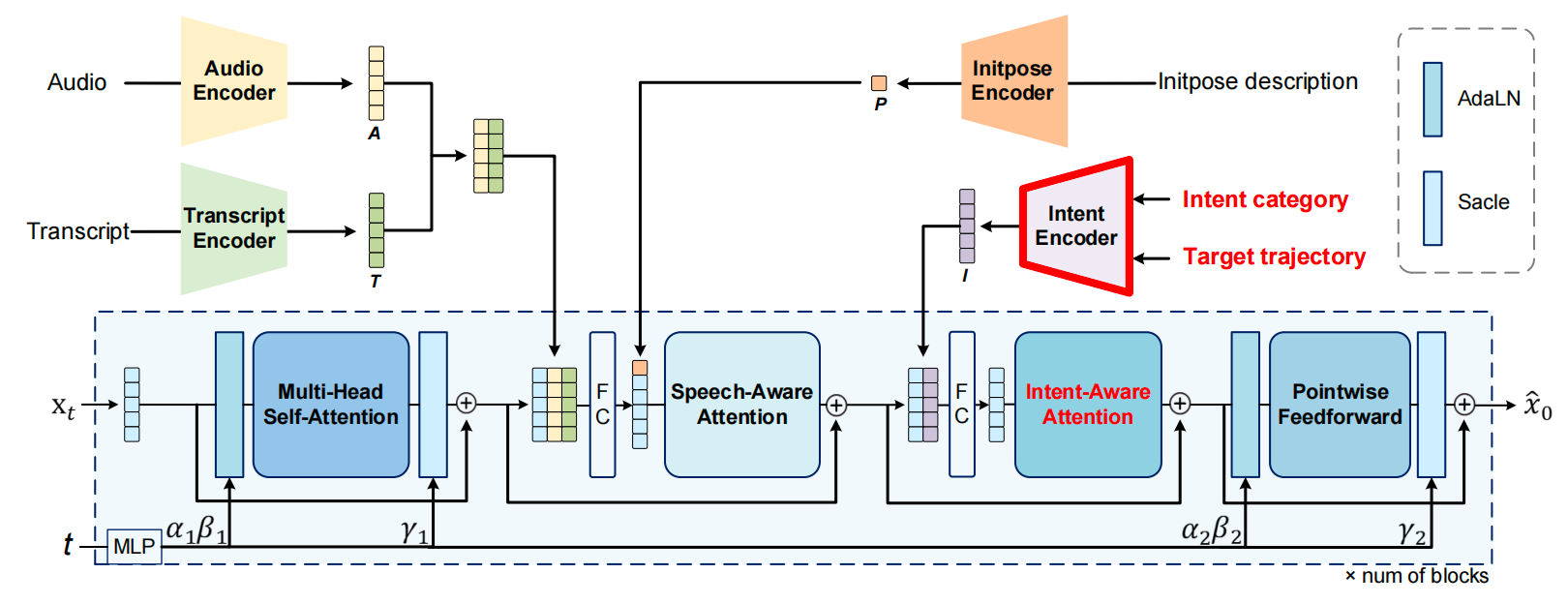
DiT Block 内部结构(重复多次)
含噪声手势 x_t
↓
① Multi-Head Self-Attention(多头自注意力)
Q = K = V = Gesture states
作用:建立帧间时序依赖,理解动作内部结构
→ 输出:上下文感知的 Gesture states
↓
② Speech-Aware Attention(语音感知注意力)
输入:Gesture states + 音频A + 文本T + 初始姿态P
Q = Gesture states
K = V = 语音特征(交叉注意力)
特殊设计:在序列最前面加入姿态token(类似BERT的CLS)
作用:解决 HOW + WHEN
→ 输出:包含语音信息的 Gesture states
↓
③ Intent-Aware Attention(意图感知注意力)
输入:语音融合后的Gesture states + 意图特征I
拼接后做自注意力(不是交叉注意力)
作用:解决 WHERE,建模运动学-意图依赖
→ 输出:包含空间意图的 Gesture states
↓
④ Pointwise Feedforward
两个FC层(256→1024→256)+ 激活函数
对每帧独立处理,不是卷积
作用:特征提炼
↓
预测干净手势 x̂_0每个操作后都有残差连接(⊕),AdaLN 根据扩散时间步 t 自适应调整每层的归一化参数。
为什么分两步融合
语音信号(节奏/语义)和意图信号(空间方向)性质根本不同,分开处理让模型专注学习各自规律。消融实验(Table 8)验证:两步融合 > 一步融合 > 预融合。
混合训练策略
Track-I(6009条)远多于Track-II(1114条),直接均匀采样会让模型忽视交互时机的学习。解决方案:
每个batch:Track-II : Track-I = 8 : 2优于两阶段训练(先Track-I预训练再Track-II微调),因为两阶段训练存在灾难性遗忘问题。
六、机器人部署
模型输出(SMPL-H)
↓ 6D旋转→轴角,打包成AMASS格式
↓ Mink逆运动学重定向(SMPL-H→Unitree G1关节)
↓ 动作追踪策略
Unitree G1 执行
视觉感知:YOLOWorld 实时检测目标,提供3D坐标输入九、领域背景和研究价值
这篇论文在人体动作生成领域的位置:
早期:规则系统(关键词触发)
中期:音频/文本驱动,解决 HOW
近期:加入语义和风格
本论文:同时解决 HOW + WHEN + WHERE
填补了空间感知在对话手势生成中的空白对于想深入这个领域的研究者,核心的后续问题包括:更丰富的意图类型、实时生成、多人交互、跨平台迁移、生成结果的局部可控性等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)