Text-DiFuse:基于文本调制扩散模型的交互式多模态图像融合框架-NeurIPS2024 spotlight
Text-DiFuse: An Interactive Multi-Modal Image Fusion Framework based on Text-modulated Diffusion Model
Text-DiFuse:基于文本调制扩散模型的交互式多模态图像融合框架
会议:Conference on Neural Information Processing Systems
论文链接:Text-DiFuse:基于文本调制扩散模型的交互式多模态图像融合框架
年份:2024
关键词:图像融合,扩散模型

创新点
1. 首次把“信息融合”显式、深度地嵌入到扩散过程里
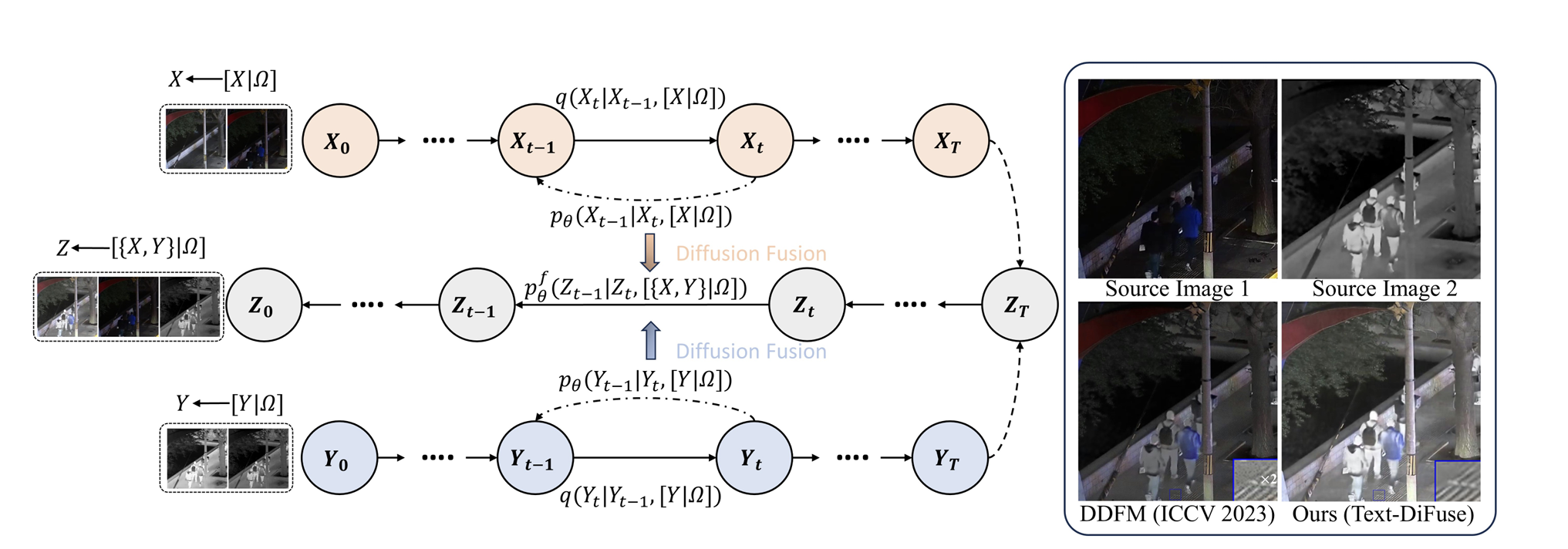
这篇文章最核心的贡献,是提出了一种 information fusion 与 diffusion 的显式耦合范式。以往一些扩散融合方法,要么是把扩散模型当附属模块来增强 CNN,要么只是把多模态图像当条件输入,实际上并没有真正把“融合”这件事放进扩散采样过程内部。而 Text-DiFuse 直接在扩散的编码—解码链路中插入融合控制模块,让多模态特征在 T 步反向采样过程中持续融合,从而同时完成退化去除和信息融合。论文图 1 和图 2(a) 都在强调这一点。
2. 面向复合退化场景,把“去退化”和“图像融合”一起做
作者指出,现有多模态图像融合方法通常只关心“怎么把红外和可见信息拼起来”,却忽略了源图像本身可能已经带有 噪声、颜色偏差、曝光不当 等复合退化。Text-DiFuse 先训练一个针对复合退化的条件扩散模型,把去退化先验嵌入编码器和解码器,再在扩散过程中同步做融合,因此它能在融合的同时去掉噪声、纠正偏色、改善光照。这个点是论文想解决的第一个核心问题,也就是 compound degradation challenge。
3. 引入文本控制的融合重调制策略,实现“按用户兴趣来融合”
除了做更干净的融合图像,这篇文章还想解决“前景目标不够突出”的问题。作者认为,很多融合方法对前景和背景一视同仁,不管你关心的是行人、车辆还是其他目标,融合规则都差不多,这其实不合理。于是他们引入 文本 + 零样本定位模型,根据用户输入的语言命令去定位感兴趣目标,再在扩散融合过程中做二次调制,增强这些目标的显著性。这个设计不仅改善视觉效果,还提升了分割和检测等下游语义任务表现。
方法简介
这篇文章主要研究的是:在源图像本身已经退化的情况下,如何做高质量的多模态图像融合,并且支持用户通过文字来指定“我更想突出什么目标”。
作者把这个任务拆成了两个子目标:
- 去掉多模态图像中的复合退化,比如低照度、噪声、偏色。
- 在融合过程中突出用户关心的对象,比如行人、车辆、病灶等。
为了解决这两个问题,Text-DiFuse 提出了一个新的框架:先利用条件扩散模型学习“如何从退化图像恢复到干净图像”,然后把多模态特征融合直接嵌入这个恢复过程;再结合文本和零样本定位模型,对感兴趣目标进行重调制。最终得到的融合图像不仅更干净,而且更符合用户语义偏好。
一句话概括这篇文章的核心思路就是:
让扩散模型不只是做去噪/复原,而是在反向采样过程中一边去退化,一边融合多模态信息,并且还能通过文本指令强调用户感兴趣的前景目标。
一、这篇文章到底想解决什么问题?
作者认为,现有多模态图像融合方法主要有两个明显短板。
第一个短板是:复合退化下的融合性能差。
现实场景中的源图像常常不是理想输入,尤其在红外—可见融合和医学融合任务里,源图像可能存在颜色偏差、噪声、曝光不当等问题。但多数方法只专注于“融合”,忽略了“恢复”,所以最终融合图像仍然会带着这些问题。论文把这个问题称为 compound degradation challenge。
第二个短板是:对前景目标缺乏定制化关注。
比如在安防或自动驾驶里,人和车显然比背景更重要;在医学图像里,病灶区域也比背景更重要。但很多融合方法对整幅图使用统一融合规则,没有让模型知道“哪些区域更值得被强调”。论文把这个问题称为 under-customization objects limitation。
作者把多模态图像对记作 ,其中 Ω 表示复合退化。目标是学到一个映射:
- 源图像有退化时,融合图还能保持高质量;
- 用户关心的对象,在融合结果里能被明显突出
二、整体框架:Text-DiFuse 是怎么搭起来的?
论文图 2 给出了整套框架。整体上可以分成三部分:
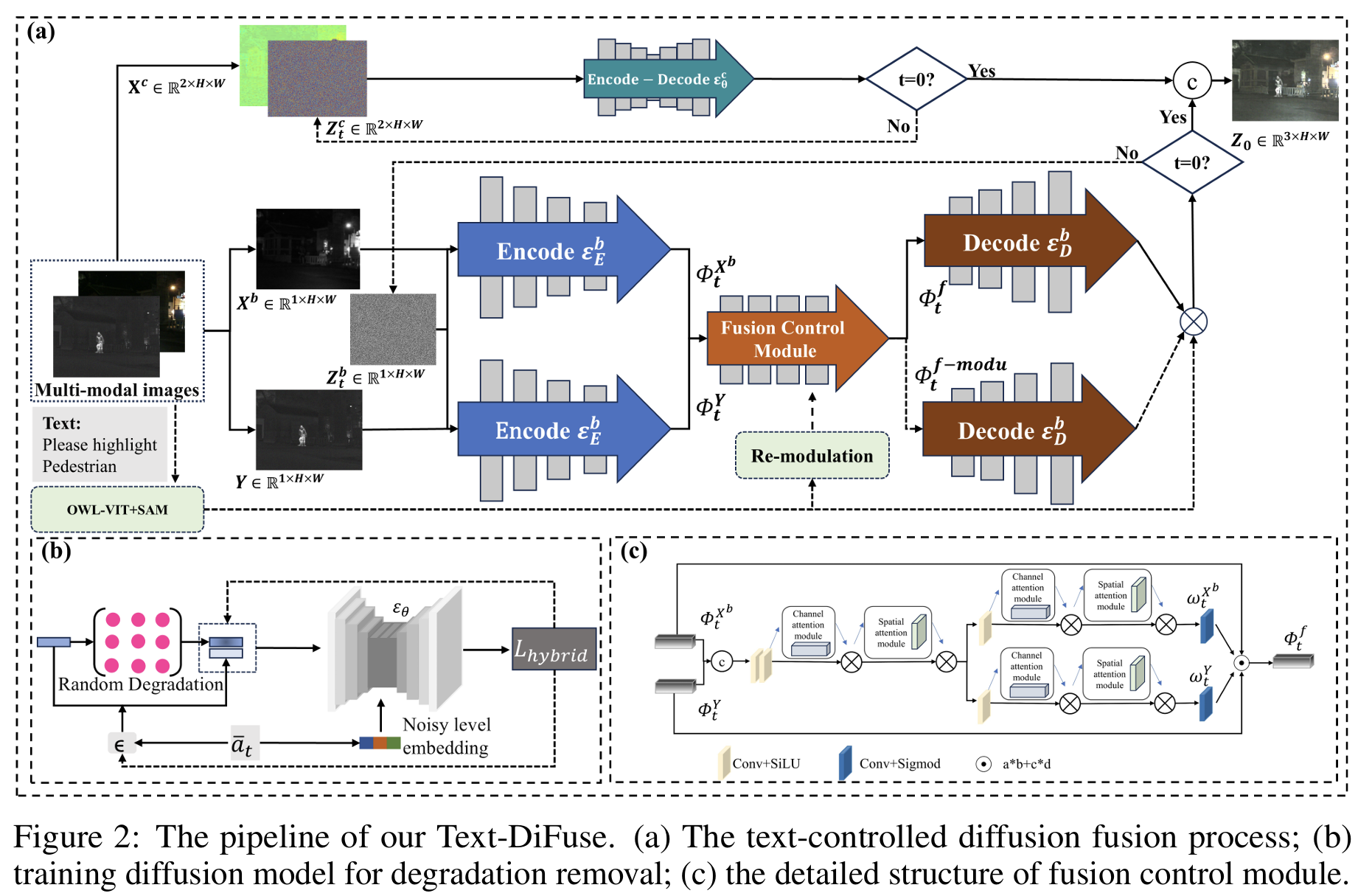
- 扩散模型负责去退化
- 融合控制模块 FCM 负责在扩散过程中聚合多模态特征
- 文本控制重调制模块负责突出感兴趣对象。
这里 Z 是最终融合图像,L 是用户输入的语言命令。也就是说,这个模型既要处理退化,又要融合模态,还要响应文本控制。
从框架图上看,作者采用的是 共享编码 + 融合控制 + 解码重建 的思路。不同模态在扩散采样的每个时间步都会编码成特征,然后交给 FCM 融合,最后由解码器在反向扩散过程中逐步重建出融合结果。
三、显式耦合信息融合与扩散:这篇文章最核心的地方
这一部分是全文最值钱的地方。
3.1 为什么以前的方法不够好?
论文第 3 页提到,扩散模型应用到图像融合上有两个难点:
- 图像融合本身是无监督的,没有“干净融合真值”可以直接监督;
- 扩散是连续采样过程,而融合通常被设计成一次性的特征聚合,很难自然接到一起。
所以作者不满足于“扩散先做增强,融合再单独做”,而是提出一个更激进的想法:
让融合过程本身就在扩散采样里发生。
3.2 用扩散模型先学“如何去退化”
作者首先单独训练一个面向退化恢复的扩散模型,退化类型主要包括:
- color casts(偏色)
- noise(噪声)
- improper lighting(曝光/亮度不当)。
这里有个细节挺重要:作者把图像分成 亮度分量 和 色度分量 分开处理。色度分量先通过训练好的扩散模型做去退化恢复,得到更合理的颜色结果;亮度分量则在后面的“扩散融合”过程中与另一模态一起处理。
论文第 5 页给出的 iDDPM 风格训练目标为:
当 t>1 时:
当 t=1 时:
其中,ϵt是前向扩散中加入的噪声,ϵθ 是噪声预测器,q和 pθ 分别是先验和后验分布。这个部分的核心目的很明确:
先把“退化去除能力”学扎实,再把这个能力带进融合过程里。
3.3 FCM:融合控制模块怎么工作?
为了在扩散中做融合,作者设计了一个 Fusion Control Module(FCM)。这个模块放在编码器和解码器之间,在每个时间步接收不同模态的编码特征,并输出它们的融合权重。
作者没有让 FCM 直接预测“融合后的特征值”,而是让它预测 融合权重系数。原因是这样做可以减少解空间,帮助模型在多步采样中更快收敛。FCM 主要由卷积层和 CBAM 组成,通过通道注意力和空间注意力来判断不同模态特征在不同位置的重要性。
论文第 5 页给出的编码与融合形式分别为:
这里 ωtXb 和 ωtY\就是 FCM 输出的融合权重,⊙ 表示 Hadamard 积。换句话说,FCM 的本质是一个 动态权重生成器,它在扩散采样的每一步都重新决定多模态特征怎么融合。
3.4 扩散融合到底是怎么做的?
在亮度分量的处理上,作者从随机高斯噪声 ZTb∼N(0,I)Z_T^b \sim \mathcal{N}(0,I)ZTb∼N(0,I) 出发,把退化的多模态图像 [{Xb,Y}∣Ω]\left[\{X^b,Y\}\mid \Omega\right][{Xb,Y}∣Ω] 作为条件输入共享编码器,得到两个模态在当前时间步的特征表示,再通过 FCM 融合,交给解码器去预测当前噪声和方差相关变量。
解码器输出为:
随后根据扩散反推公式估计均值和方差:
其中:
,
,
然后更新下一步采样状态:
其中,当 t>1 时,z∼N(0,I),否则 z=0。
同时,每一步采样都可以导出当前时刻对应的“假最终融合图”:
为了让 FCM 真正学会“保留有价值的信息”,作者设计了两个约束。
强度损失:
梯度损失:
最终总损失为:
其中 γint=1,γgrad=0.2。
最终亮度图 Zb与恢复后的色度分量 X0c拼接,得到最终融合图像 Z。
所以 Text-DiFuse 不是“先恢复后融合”或者“先融合后恢复”,而是:
在扩散反向采样过程中,同时完成恢复和融合。
四、文本控制融合重调制:怎么做到“你关心什么我就突出什么”?
这部分是这篇文章最有意思、也最有“交互式”味道的地方。
作者认为,基础版的扩散融合虽然已经能得到不错的图像,但还不够个性化。用户可能会说:
- “请突出行人”
- “请突出车辆”
- “请强调病灶区域”
那模型就应该按照这些语义要求重新调节融合结果。
为此,作者引入了两个模块配合:
- OWL-VIT:根据开放词汇文本命令检测目标
- SAM:对这些目标做更精细的像素级定位,得到掩码 MMM。
有了这个掩码之后,模型会在扩散融合中加入额外的调制系数 κXb,κY,也就是论文第 6 页的公式 (12):
这个调制本质上是在目标区域内进一步增强感兴趣对象和背景之间的对比度,使目标在融合图中更加显著。
同时,为了保证背景区域分布不被破坏,论文又给出了:
也就是说,只有目标区域会被重新调制,背景区域依然保持基础版扩散融合的结果。直白讲就是:
先正常融合整张图,再在“你说你关心的地方”额外做一层增强。
五、实验部分:效果到底怎么样?
5.1 基础融合性能
作者在两个典型多模态融合场景上做了实验:
- 红外—可见图像融合(IVIF)
- 医学图像融合(MIF)。
其中 IVIF 使用 MSRS 数据集,MIF 使用 Harvard medicine 数据集。比较方法包括 RFN-Nest、GANMcC、SDNet、U2Fusion、TarDAL、DeFusion、LRRNet、DDFM、MRFS 等 9 种方法。评价指标包括 EN、AG、SD、SCD、VIF。
从图 3 和表 1 可以看出,Text-DiFuse 在两个场景下都取得了非常强的结果。尤其在 MSRS 数据集上,它在 EN、AG、SD、SCD、VIF 五项指标里几乎都是最优或接近最优;在 Harvard medicine 上也取得了最优的 AG、SD、SCD、VIF。论文给出的结果是,Text-DiFuse 在 MSRS 上的 AG 达到 3.31,SD 达到 47.44,在 Harvard 上的 AG 达到 7.31,SD 达到 80.19。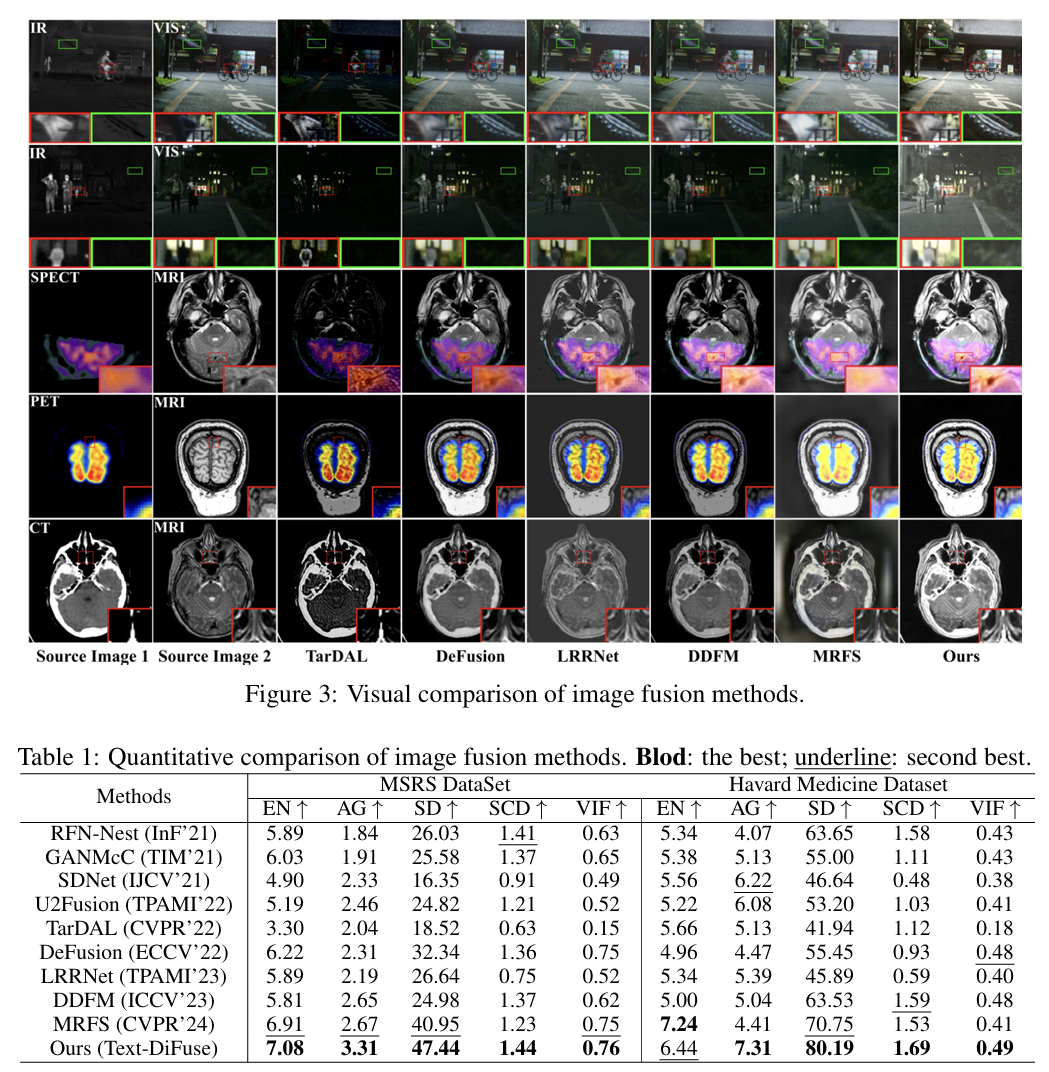
从可视化上看,这篇方法确实体现出“边融合边恢复”的优势:
- 在红外—可见场景中,它能同时做到低照增强、偏色纠正、细节恢复;
- 在医学融合场景中,它既能保住生理结构,又能保留功能分布信息。
5.2 和“增强 + 融合”串联方案相比如何?
为了证明自己的设计不是“碰巧有效”,作者还做了一个很公平的对照:给其他融合方法额外加上最先进的低照增强、去噪和白平衡算法作为预处理,再去做融合。结果见图 4 和表 2。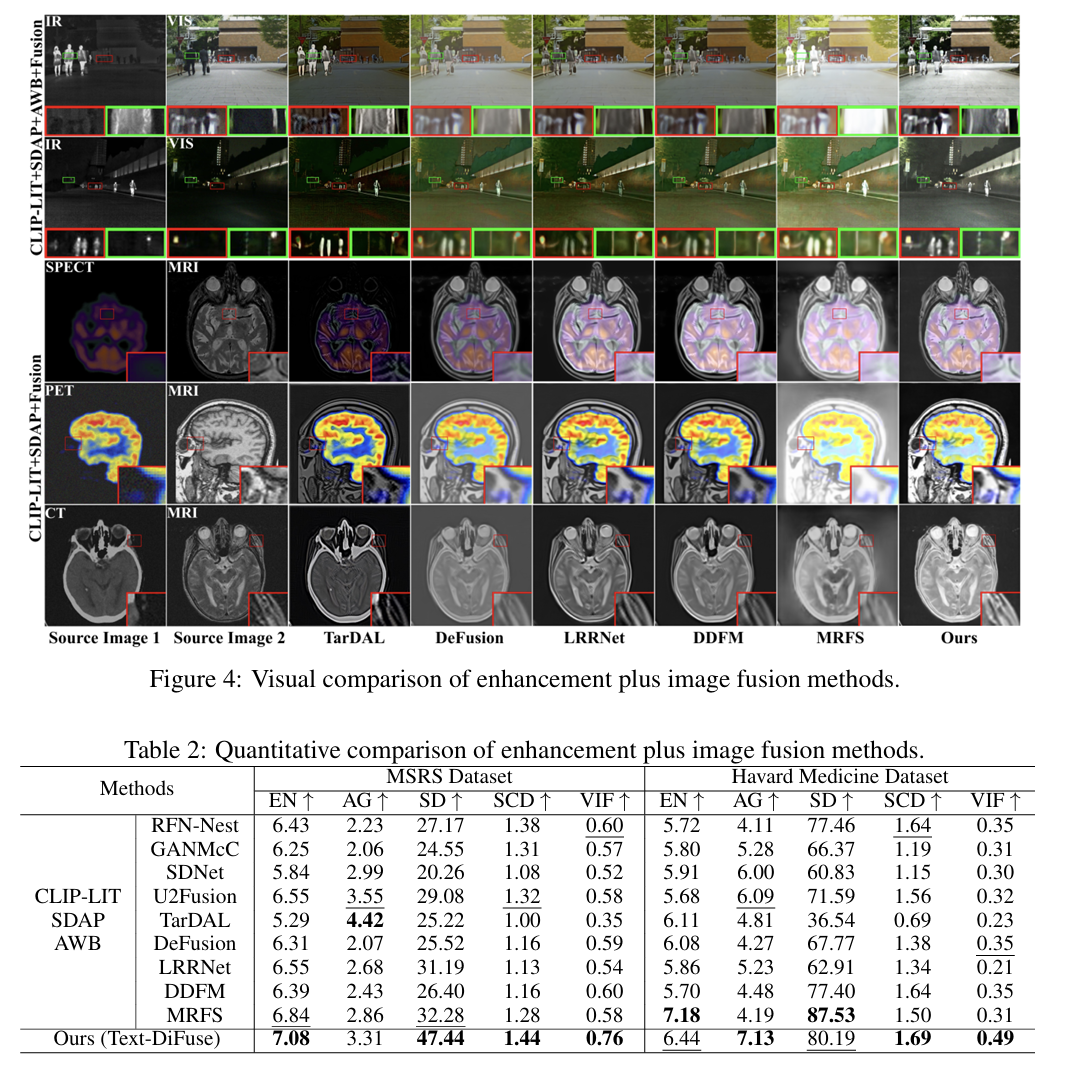
结果说明,即使给其他方法先做增强、去噪、白平衡,Text-DiFuse 仍然整体更强。作者解释得很直接:
因为这些预处理步骤和融合本身是彼此独立的,没法在恢复过程中考虑模态互补性;而 Text-DiFuse 则是在同一个扩散过程中同时做恢复和融合。
5.3 泛化能力怎么样?
作者还把在 MSRS 上训练好的模型直接拿去测 LLVIP 和 RoadScene,检查泛化能力。图 5 和表 3 显示,Text-DiFuse 在这些新数据集上依然能保持不错的退化去除能力和融合质量。比如在 LLVIP 上,它的 EN 达到 7.08,AG 达到 3.99,SD 达到 41.78;在 RoadScene 上,EN 达到 7.46,SD 达到 52.84。
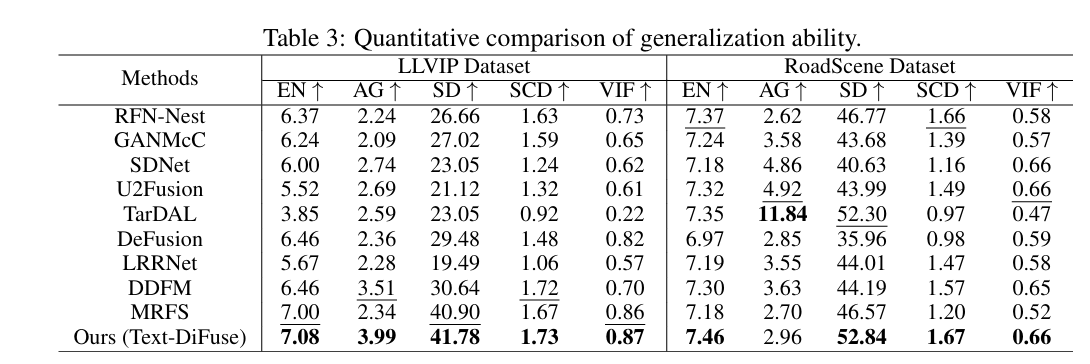
这说明它不是只会在训练集上表现好,而是在真实场景迁移上也比较稳。
六、文本重调制真的有用吗?
这个问题作者专门做了验证,而且做得还挺全面。
6.1 语义分割验证
作者在 MFNet 数据集上做了语义分割实验,把不同来源的图像输入同一个分割器 SegNext 进行比较,包括:
- 单独红外图像
- 单独可见图像
- 基础版 Text-DiFuse 融合图
- 可调制版 Text-DiFuse 融合图。
结果见图 6 和表 4。
其中最关键的结论是:可调制版比基础版 mIoU 更高。
论文给出的结果是,基础版 mIoU 为 57.53,而可调制版达到 58.63,为所有比较方法里最高。说明文本控制重调制不仅在视觉上让目标更突出,也确实给下游语义分割带来了收益。
6.2 目标检测验证
作者还在 MSRS 数据集上做了检测实验,检测类别主要是 person 和 car,并把文本指令设为:
“Please highlight the person and car”。

然后用 YOLO-v5 在不同图像上做检测。图 7 和表 5 显示,Text-DiFuse 的可调制版本在检测精度上最好,mAP@0.5=89.7,mAP@[0.5:0.95]=60.9。可见这个文本调制策略不是“看起来有意思”,而是真的能让语义目标更容易被机器识别。
七、总结
Text-DiFuse 提出了一种很新颖的多模态图像融合思路:
把信息融合显式嵌入扩散过程,在去除复合退化的同时完成模态融合,并通过文本控制对前景目标进行二次调制。
它的核心贡献可以概括为三句话:
- 融合不再是扩散外部的附属步骤,而是扩散采样过程的一部分;
- 去退化与多模态融合不再分开做,而是在同一个框架里协同优化;
- 文本指令让融合结果具备交互性和语义可控性,从而更适合下游任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)