(207页PPT)工业大数据采集处理与应用(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接
https://download.csdn.net/download/AI_data_cloud/89624187
资料解读:工业大数据采集、处理与应用
详细资料请看本解读文章的最后内容。
本文件系统性地阐述了工业大数据从基础概念到实际应用的完整知识体系,为理解和实施工业大数据项目提供了清晰的路线图。课程内容结构严谨,层层递进,涵盖了工业大数据的认知、采集、预处理、建模、分析及可视化等核心环节。
一、工业大数据基础认知
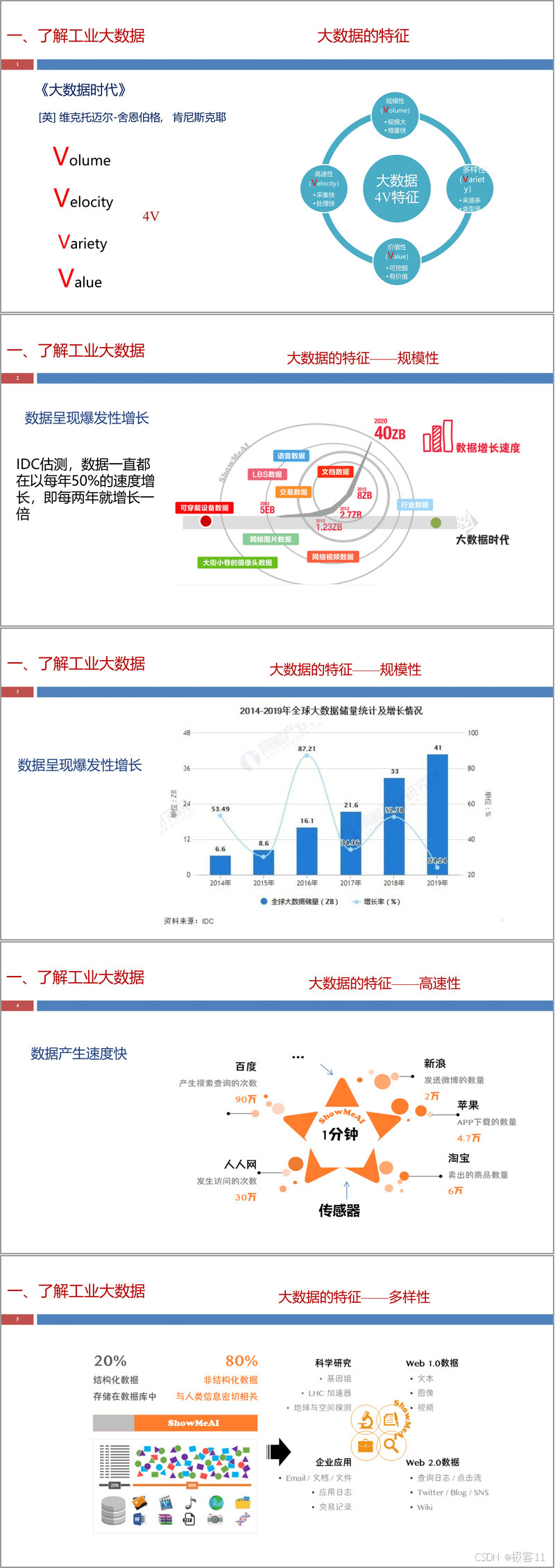
课程开篇明义,首先明确了工业大数据的概念。它并非简单指数据量巨大,而是指那些规模庞大到无法通过传统技术工具在合理时间内进行捕捉、管理和处理的数据集合,其核心在于需要新的处理模式才能发挥更强的决策力、洞察力和流程优化能力。工业大数据具备显著的4V特征:规模性(Volume,数据量爆发式增长)、高速性(Velocity,数据产生与处理速度快)、多样性(Variety,数据类型繁多,包括结构化、半结构化和非结构化数据)和价值性(Value,蕴含巨大潜在价值,需通过深度挖掘才能释放)。
工业大数据的主要来源广泛,可分为三类:一是企业内部信息化系统数据,如产品数据管理(PDM)、企业资源计划(ERP)、制造执行系统(MES)等;二是工业互联网数据,来自各类传感器、控制器和设备;三是外部数据,如市场信息、竞争对手动态、环境因素等。除了通用的大数据特征,工业大数据还具有时序性、实时性、高通量、高维度、多尺度和高噪性等独特特点。课程通过具体的计算案例,直观展示了工业场景下数据规模的庞大,例如机床制造车间和炼铁高炉每日产生的数据量级。
二、工业大数据采集技术
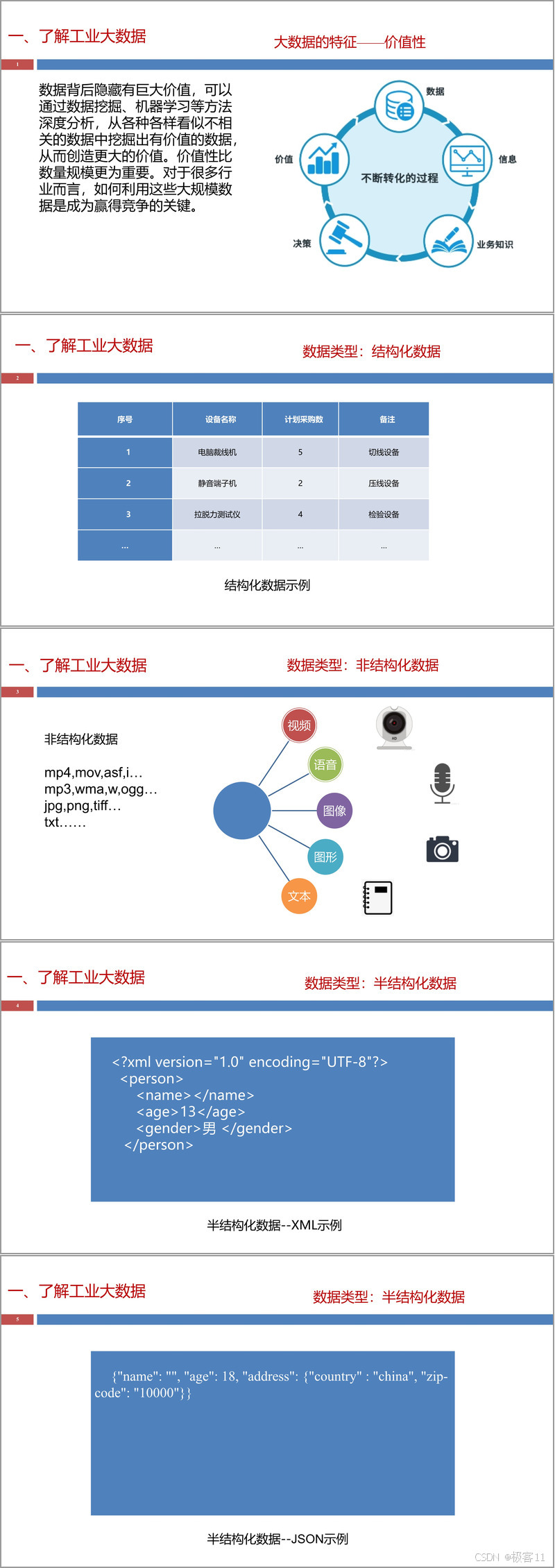
数据采集是工业大数据价值链的起点。文件详细介绍了工业数据的采集方式与相关技术。采集目标是从各类数据源中有效获取数据,为后续处理奠定基础。工业大数据贯穿产品全生命周期,其产生主体是人和工业设备,结构化数据占比相对较高,相关性和实时性要求强。
从物理架构看,工业大数据系统自下而上可分为设备层、控制层、车间层、企业层和协同层五层。工业现场网络是实现数据采集的关键,主要包括现场总线网络(如Profibus)和工业以太网(如PROFINET、EtherCAT)。现场总线模型通常包括物理层、数据链路层和应用层,而工业以太网则在底层采用标准IEEE 802.3和TCP/IP协议栈,高层定义特定工业应用协议。
在通信协议方面,文件重点解析了OPC UA和MQTT。OPC UA是一种独立于平台的标准,实现了从现场设备到管理系统的垂直数据集成,支持请求/响应和发布/订阅两种交互模式,具有良好的信息建模能力。MQTT则是一种轻量级的、基于发布/订阅模式的消息传输协议,特别适合在低带宽、高延迟或不可靠的网络环境中使用,是实现设备间通信的重要选择。
数据采集的具体手段多样,主要包括:(1)传感器,分为有线和无线两种,用于测量物理环境变量;(2)RFID(射频识别),用于非接触式自动识别与跟踪;(3)条码技术,用于快速采集商品信息;(4)人机交互界面、摄像头以及从其他业务系统获取数据。采集到的数据通常需要存储到数据库(如MySQL)或大数据平台的基础库中。课程还具体介绍了如何采集可编程逻辑控制器(PLC)和PTL(灯光拣选系统)的数据,并完成存储任务。
三、工业大数据预处理与存储
原始数据往往存在缺失、噪声、不一致等问题,必须经过预处理才能用于分析。本部分核心是ETL(抽取、转换、加载)过程和数据仓库的构建。
ETL过程中,抽取负责从异构数据源获取数据(全量或增量);转换是核心环节,包括数据清洗(去重、补缺失、去噪、去异常)、数据转换(格式转换、标准化、业务规则计算、数据粒度转换、降维)和数据校验;加载则是将处理后的数据导入目标数据仓库或数据集市。
课程介绍了开源ETL工具Kettle的使用,包括其界面(核心对象树、设计画布)、核心要素(转换、步骤、跳、数据流)以及基本操作流程(创建转换、定义步骤、建立连接、配置数据库连接)。
数据仓库被定义为面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策,与面向事务处理的数据库有所区别。作为大数据查询分析工具,Hive能够对存储在HDFS中的数据进行操作,其数据组织单元包括数据库、表(内部表与外部表)、分区和分桶。文件详细说明了使用Hive进行数据库/表创建、数据加载、分区/分桶管理以及数据查询(SELECT、WHERE、GROUP BY、ORDER BY等)和统计(如SUM)的语法和实例。分区和分桶技术能有效提升大数据查询效率。
四、工业大数据信息建模
为了有效管理和分析数据,需要建立能够反映现实世界工业实体及其关系的信息模型。课程引入统一建模语言(UML)类图作为描述信息模型的标准工具。UML类图通过类(Class,包含类名、属性和方法)以及类之间的关系(如泛化、关联、聚合、组合、依赖)来抽象表示业务领域中的对象。
文件讲解了如何将UML类图转换为关系数据库中的二维表结构,其中类转换为表,属性转换为列,类之间的关系则通过外键或关联表来实现。信息模型的核心三要素是对象、对象属性和对象关系。
应用UML,课程具体展示了如何建立设备信息模型(如拧紧机,包含设备管理信息、功能特性、构成信息、运行状态如扭矩、转速等)和生产过程信息模型。生产过程信息涉及生产线、工序、工位、工艺、零部件和设备等实体及其复杂关系。例如,一个生产线包含多个工位,一道工序可能由多个工步组成,并关联特定的工艺参数和设备。通过建立一个模拟数字化车间(如五彩棒生产)的案例,演示了如何运用UML进行建模。最后,简要提及了数字孪生概念,即通过数字化模型映射物理实体,利用数据驱动模型优化,从而提升生产效率。
五、工业大数据分析挖掘
数据分析是从数据中发现规律、构建模型以支持预测和决策的关键步骤。课程概述了大数据分析过程:包括业务理解、数据准备、算法选择、模型训练、模型评估和部署。机器学习是实现数据分析的重要技术,可分为有监督学习(用于预测和分类)、无监督学习(如聚类、关联规则发现)和强化学习。
预测分析主要分为两类:回归分析(预测连续值输出,如气温、能耗)和分类分析(预测离散类别输出,如天气晴雨、设备故障状态)。文件以线性回归为例解释了回归分析的思想(拟合曲线)和模型评估指标(如相关系数、各种误差)。对于分类分析,则介绍了决策树等算法思想,以及评估分类模型性能的指标,如查准率、查全率、ROC曲线和AUC值。
实践环节,课程介绍了开源数据分析工具Weka,包括其数据格式(ARFF文件)、界面功能,并演示了如何利用Weka进行回归和分类分析的具体操作流程,如导入数据、选择算法(如线性回归、决策树)、设置参数、划分训练/验证集、执行训练、评估结果和可视化决策树。此外,还拓展介绍了集成学习(组合多个模型提升效果)、聚类分析(如K-Means用于客户细分)、关联规则(如Apriori用于购物篮分析)和时间序列分析(如ARIMA用于预测)等高级分析技术。
六、工业大数据可视化呈现
数据可视化是将分析结果以直观、易懂的图形化方式呈现给用户的重要手段,有助于快速获取信息和洞察。课程指出,高质量的可视化工具对于数据分析至关重要。
文件介绍了两款可视化工具:一是IoTHub,这是一款轻量化的工业大数据平台软件,集成了丰富的可视化控件。通过案例展示了其应用,如使用轨距表(Gauge)显示变频电机转速,使用文本值(Text Value)和饼图(Pie Chart)展示立体库物料数量,使用折线图(Line Chart)展示订单生产趋势。二是Grafana,一款跨平台的开源度量分析与可视化工具,支持多种数据源,具有灵活的仪表盘设计和告警功能。案例演示了如何使用其状态控件(Stat)实时显示数字化车间各装配工位的当前订单编号,实现生产进度透明化。
最后,课程展望了工业数据可视化的发展,包括三维可视化技术在工业园区、工厂全局以及设备生产过程监控中的应用,并强调可视化的核心在于清晰的叙述和艺术化的呈现,最终目标是帮助用户理解数据、做出决策。
接下来请您阅读下面的详细资料吧。




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)