MASS-EDITING MEMORY IN A TRANSFORMER
 ICLR2023
ICLR2023
摘要
近期研究表明,为大语言模型新增记忆信息展现出广阔前景,借此可以替换过时内容或补充专业知识。但该方向的现有研究,大多仅局限于单次单条关联信息的更新。本文提出 MEMIT 方法,可对语言模型进行批量记忆直接更新。实验证明:该方法能够为 GPT-J(60 亿参数)、GPT-NeoX(200 亿参数)模型一次性更新数千条关联知识,性能相比过往研究提升数个数量级。项目代码与数据集已开源:memit.baulab.info
1 引言
我们通过直接修改深度神经网络的权重,最多能为其新增多少条知识记忆?
当下大型自回归语言模型(Radford 等人,2019;Brown 等人,2020;Wang & Komatsuzaki, 2021;Black 等人,2022)能够识记海量常识信息,例如 “蒂姆・库克是苹果公司首席执行官”“北极星位于小熊星座” 等(Petroni 等人,2020;Brown 等人,2020)。但即便是超大规模模型,往往也缺乏专业领域知识;并且如果无法定期迭代更新,模型还会输出过时、陈旧的错误信息(Lazaridou 等人,2021;Agarwal & Nenkova, 2022;Liska 等人,2022)。
在问答检索、知识搜索、内容生成等众多应用场景中,模型实时更新知识、支持个性化定制信息的能力至关重要。举例来说:搜索引擎模型需要持续同步突发新闻、最新用户反馈;内容创作者与企业也希望在模型中,专属植入自身作品、产品的定制化知识。
由于完整重新训练大模型成本极高、难以落地(Patterson 等人,2021),因此学界亟需可以直接快速更新模型知识的技术方案。围绕这一需求,现有多项知识编辑算法,可直接修改模型指定参数、写入全新知识记忆,主流技术包括:约束微调(Zhu 等人,2020)、超网络知识编辑(De Cao 等人,2021;Hase 等人,2021;Mitchell 等人,2021、2022)、一阶秩模型编辑(Meng 等人,2022)。
然而,现有研究普遍存在更新规模受限的问题:多数方法仅支持单次修改少量知识,现有最高测试规模仅 75 条事实知识(Mitchell 等人,2022),大量研究更是只针对单次单条编辑场景。但在实际落地场景中,往往需要一次性批量写入数百甚至数千条知识;若简单串行叠加现有最优编辑方法,会出现严重的扩展性缺陷,无法满足大规模更新需求(详见 5.2 节)。
本文提出 MEMIT—— 一种可扩展的多层级模型更新算法,通过精确计算参数增量,实现大规模知识记忆的批量写入。本方法借鉴 ROME 直接编辑方案(Meng 等人,2022)的核心思路,精准定位 Transformer 模块权重;经实验验证,该部分权重是模型调取事实知识的关键因果中介层。
本文基于 GPT-J(60 亿参数,Wang & Komatsuzaki, 2021)与 GPT-NeoX(200 亿参数,Black 等人,2022)开展大量实验,结果证明:MEMIT 具备极强的扩展能力,可批量稳定存入数千条知识记忆。
实验覆盖多类场景:真实事实知识、反事实内容、27 类特定语义关系、多类型混合知识集。在每类场景下,本文从泛化能力、知识专一性、文本流畅度三大维度,综合评测模型鲁棒性;同时将 MEMIT 与一阶秩编辑、超网络编辑、传统微调等基线方法,进行全方位的规模化性能对比。
2 相关研究
可扩展知识库
现实世界知识的表示是人工智能领域的核心问题(Richens, 1956;Minsky, 1974),传统解决方案是构建包含现实概念的知识库。早期以人工整理构建知识库为代表(Lenat, 1995;Miller, 1995),后续逐步发展出基于互联网的知识图谱(Auer 等,2007;Bollacker 等,2007;Suchanek 等,2007;Havasi 等,2007;Carlson 等,2010;Dong 等,2014;Vrandečić & Krötzsch, 2014;Bosselut 等,2019),能够从海量数据源中抽取知识。
结构化知识库支持精准查询、量化评估与内容更新(Davis 等,1993),但存在覆盖范围局限的问题,难以收录常识类等未系统化整理的知识(Weikum, 2021)。
作为知识库的语言模型
大语言模型能够回答关于客观事实的自然语言问题,因此有研究提出可将大语言模型直接用作知识库(Petroni 等,2019;Roberts 等,2020;Jiang 等,2020;Shin 等,2020)。
但大模型中的知识属于隐式编码知识:模型回答高度依赖提示词的具体表述方式(Elazar 等,2021;Petroni 等,2020),同时难以对知识进行系统化梳理、新增与修改(AlKhamissi 等,2022)。即便如此,大语言模型仍具备巨大潜力 —— 扩展性强,且不受固定数据架构的限制(Safavi & Koutra, 2021)。本文聚焦知识更新问题,探究如何对编码在模型参数中的隐式知识进行批量编辑。
超网络知识编辑方法
学界已提出多种元学习方案,实现模型内部知识的编辑修改。Sinitsin 等人(2019)设计了一种训练目标,使模型能够通过梯度下降完成知识编辑。De Cao 等人(2021)提出知识编辑器(KE)超网络,依据新增事实语句预测参数更新量,从而对基础模型进行修改。
在对知识编辑器的进一步研究中,Hase 等人(2021)发现该方法仅能支持少量编辑操作,改进优化后也仅可实现 10 条知识的修改。MEND(Mitchell 等,2021)同样基于元学习,通过待插入事实的梯度推导模型权重更新。为提升方法扩展性,Mitchell 等人(2022)提出 SERAC 系统:在保留原始模型权重不变的前提下,通过独立参数模块处理改写后的知识,该方法最高仅支持 75 条知识编辑。不同于以上元学习方案,本文方法通过显式计算映射关系,直接完成模型参数更新。
直接式模型编辑
本研究紧密依托大语言模型内部机理定位与机理解析的相关工作(Elhage 等,2021;Dar 等,2022)。Geva 等人(2021;2022)研究证实,Transformer 的多层感知机(MLP)层承担键值记忆存储功能,因此本文将编辑目标聚焦于该网络层。
同时,本文引入因果中介分析(Pearl, 2001;Vig 等,2020;Meng 等,2022),锁定参与事实知识调取与回忆的特定网络层。过往研究中,Dai 等人(2022)与 Yao 等人(2022)提出通过修改少量神经元实现知识编辑;而本文沿用经典理论,将线性层视作关联记忆载体(Anderson, 1972;Kohonen, 1972)。
本研究与 Meng 等人(2022)的工作高度相关,二者均将 GPT 模型当作显式关联记忆体进行权重更新。区别在于:过往研究仅支持单次单条编辑,而本文通过多层联合修改,实现数千条知识同步批量更新。
3 预备知识:语言建模与记忆编辑
MEMIT 的目标是修改自回归大语言模型参数中存储的事实关联知识。此类模型基于条件词概率分布 P(x[t]∣x[1],…,x[E]) 逐词采样生成文本,该分布由一个含 D 层的 Transformer 解码器 G 参数化构建(Vaswani 等人,2017):
P(x[t]x[1],…,x[E])≜G([x[1],…,x[E]])=softmax(WyhDh[E]D)(1)
其中 h[E]D 为 Transformer 第 D 层(最后一层)、结束位置 E 的隐藏状态表征。
隐藏状态通过如下递推公式计算:h[t]l(x)=h[t]l−1(x)+a[t]l(x)+m[t]l(x)(2)
式中:a[t]l=attnl(h[1]l−1,h[2]l−1,…,h[t]l−1)(3)m[t]l=Woutlσ(Winlγ(h[t]l−1))(4)
h[t]0(x) 代表词元 x[t] 的嵌入向量,γ 为层归一化操作。本文沿用 Black 等人(2021)与 Wang & Komatsuzaki(2021)的写法,将注意力机制与多层感知机(MLP)以并行结构表示。
已有研究证实,大语言模型内部存储了大量记忆化事实知识(Petroni 等人,2020;Brown 等人,2020;Jiang 等人,2020;Chowdhery 等人,2022)。本文研究 **(主体、关系、客体)** 三元组形式的事实知识,例如:(主体:迈克尔・乔丹,关系:从事运动,客体:篮球)。
给定自然语言提示词 pi=p(si,ri),如「迈克尔・乔丹从事的运动是」,若模型能够正确预测客体 oi 对应的后续词元,则称生成器 G 成功调取该条记忆。本文核心目标:一次性批量编辑大量记忆知识。
我们将一组编辑请求形式化定义为:E={(si,ri,oi)∣∀i},满足:不存在 i,j 使得 (si=sj)∧(ri=rj)∧(oi=oj)(5)
该逻辑约束用于避免冲突编辑。举例:可以将迈克尔・乔丹的运动知识修改为「棒球」,同时禁止再为其绑定足球等相互矛盾的客体信息。
高质量记忆编辑的评价标准
表层层面的有效编辑:模型修改后,在「迈克尔・乔丹从事的运动是」这句提示下,分配给「棒球」的概率高于原本的标准答案「篮球」,即视为编辑有效。
除此之外,还需从泛化性、专一性、语言流畅度三个维度综合评估:
-
泛化性改写提问句式进行测试,例如:「迈克尔・乔丹的专长运动是什么?」「他的职业运动项目是什么?」若模型仅机械适配单一原提示、无法在同义问句中沿用修改后的「棒球」知识,则代表编辑浅层化、存在过拟合问题。
-
专一性测试同类相近主体,保证无关知识不受干扰。例如询问「科比・布莱恩特从事什么运动?」「魔术师约翰逊的运动项目?」若模型无差别乱输出「棒球」、错误篡改未编辑对象的知识,说明编辑缺乏专一性。
-
文本流畅度模型更新后必须保证生成文本通顺自然。若出现「棒球 棒球 棒球」这类重复、破碎、不通顺的输出,视为编辑失败。
即便仅完成少量知识编辑,同时满足以上三项要求也极具挑战(Hase 等人,2021;Mitchell 等人,2022;Meng 等人,2022)。本文进一步探究:在一次性编辑数千条知识的大规模场景下,能否同时实现高效、稳定、合规的模型知识更新。
4 研究方法
MEMIT 依托因果中介分析最新揭示的 Transformer 内部机制,通过更新关键网络层来向模型写入新增知识记忆(Meng 等人,2022)。在 GPT-2 XL 模型中,研究者发现:存在一组关键 MLP 层序列 R,专门负责在主体最后一个词元 S 位置,调控事实关联知识的提取与回忆(见图 2)。
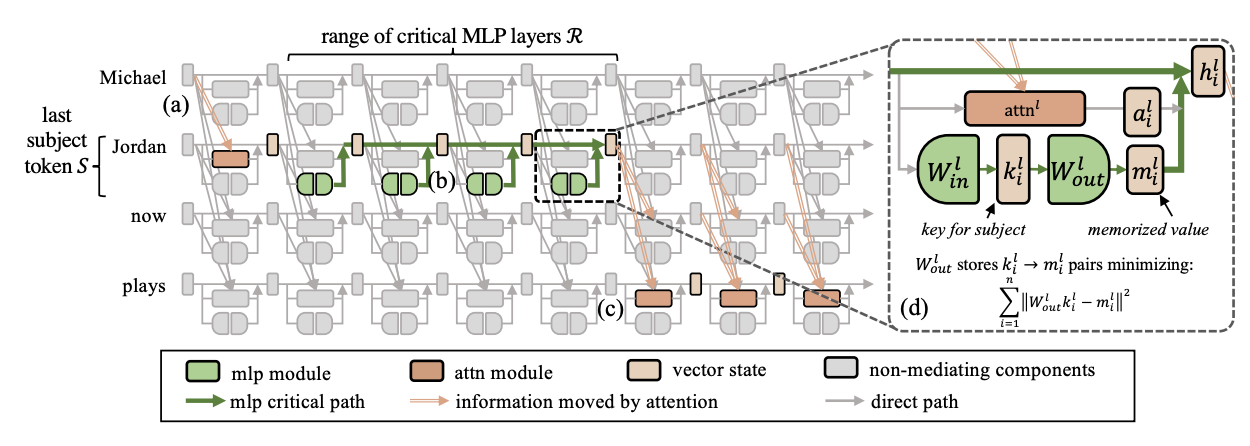
本文依据因果中介规律对模型存储的事实关联进行编辑:(a) 浅层注意力模块先将主体名称聚合为向量表征,并集中在 主体末尾词元 S;(b) 关键层集合 l∈R 中的 MLP 读取该编码,再将知识记忆写入残差流;(c) 后续注意力模块读取整合后的隐藏状态,最终输出预测结果;(d) MEMIT 通过在多组关键 MLP 中写入向量关联,实现大规模知识记忆编辑。
MEMIT 的整体流程分为两步:
- 计算目标关联向量,使关键网络层需要记住的知识表征;
- 将批量目标记忆分散存储到每一个关键层 l∈R 中。
全文统一聚焦提示词 pi 里主体末尾词元 S 对应的隐藏状态,做简写约定:hil=h[S]l(pi)同理:mil、ail 分别代表该位置上的 MLP 输出与注意力输出。
4.1 定位 MLP 关键传导通路
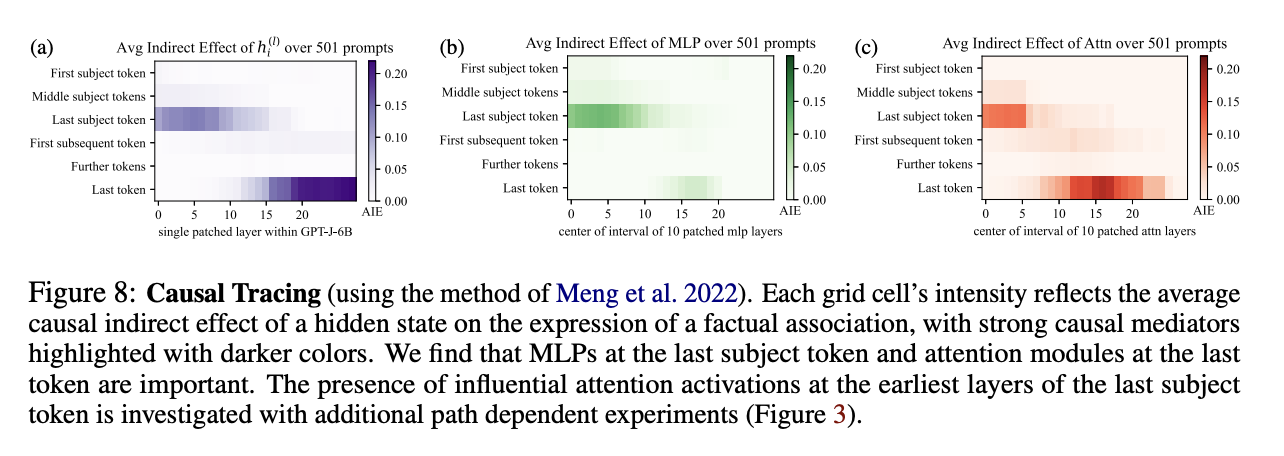
图 3 展示了在更大规模 GPT-J(60 亿参数)模型上的因果追踪实验结果(实现细节见附录 A)。实验禁用主体词元 S 的注意力模块或 MLP 模块,分别测算每层隐藏状态 hil 对知识类提示词的平均间接因果效应。
附录 A 因果追踪
每个网格色块的颜色深浅,代表隐藏状态对事实关联表达的平均间接因果效应;颜色越深,代表该位置是强因果中介单元。实验发现:主体末尾词元处的 MLP 与整句末尾词元处的注意力模块,是事实回忆的关键结构。同时,主体末尾词元的浅层注意力激活也具备显著影响力,本文结合更多路径依赖实验进一步验证该现象(见图 3)。
MEMIT 算法的第一步:定位模型中负责事实回忆的 MLP 因果中介层。本文基于 GPT-J 模型,完全沿用 Meng 等人(2022)开源代码开展实验:
- 首先筛选 501 条可被 GPT-J 正确预测的真实事实语句 作为测试样本;
- 向主体词元编码中注入噪声,降低模型预测准确率,获取基准预测概率;
- 针对图 8 (a):逐一对单个隐藏状态 htl 进行复原,将其恢复为无噪声干扰的原始取值,统计模型事实预测概率的平均提升幅度。
实验统一使用标准差 3σ 的高斯噪声(σ2 为词嵌入激活值的实测方差);对全部 501 条事实、10 组不同噪声样本取平均值,保证结果稳定。
图 8 (b)(c) 沿用相同实验流程,区别仅在于:不再复原完整隐藏状态,而是分别连续复原 10 层 MLP 输出 mtl 与 10 层注意力输出 atl。
实验结果表明:GPT-J 的因果结构与 Meng 等人(2022)在 GPT2-XL 上的结论高度相似。但二者存在一处关键差异:GPT-J 在主体末尾词元的浅层注意力层表现出极强的因果效应。该现象大概率源于:GPT-J 在识别、切分主体名词短语时,会集中完成注意力计算;但结合路径依赖实验(图 3)可证明:注意力模块并非主体相关知识回忆的核心因果中介。
正文图 3 基于图 8 (a) 的同源数据,仅聚焦主体末尾词元并改为柱状图呈现,同时新增两组对照实验:
- 🔴 红色柱:固定主体末尾词元的注意力模块为受损噪声状态,阻断其交互影响,重新测算隐藏状态的因果效应;
- 🟢 绿色柱:固定主体末尾词元的 MLP 模块为受损状态,同理隔离 MLP 干扰。
实验结论:
- 阻断注意力模块后,整体效应曲线几乎无变化 → 注意力不主导事实记忆回忆;
- 阻断 MLP 模块后,因果效应出现大幅落差 → 落差最大的层级,就是 MLP 发挥核心作用的关键区间。
最终,本文将该落差最显著的连续层级划定为关键层集合 R,作为 MEMIT 批量编辑、参数干预的目标层级。
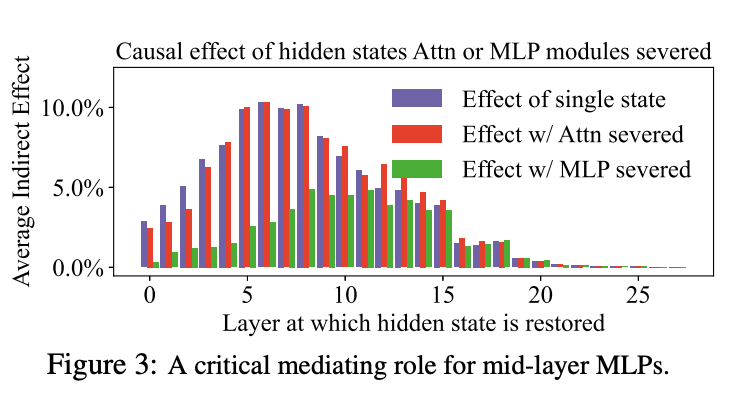 实验结论:
实验结论:
- GPT-J 模型的知识中介状态高度集中在特定层级;
- 一整段连续的 MLP 模块共同承担因果中介作用:单层单独作用(紫色柱)与切断 MLP 后的作用差距(绿色柱)差距显著,证明 MLP 对知识调取至关重要;
- 该效应差距在第 8 层之后明显衰减。
不同于 Meng 等人(2022)只选取单一网络层进行编辑,本文选取一整段连续关键 MLP 层作为编辑集合:
对 GPT-J:关键层集合 R={3,4,5,6,7,8}
既然多层 MLP 会共同参与事实回忆,本文进一步探究:单个 MLP 在知识存储中承担什么作用?
Transformer 中所有词元状态都共享残差流:注意力模块与 MLP 模块都会从残差流读取信息、并向残差流写入增量信息(Elhage 等,2021)。
对最终层主体隐藏状态 hiL=h[S]L(pi),展开前文递推公式 (2),可得:hiL=hi0+l=1∑Lail+l=1∑Lmil(6)
公式 (6) 说明:每一层独立的 MLP,都会通过累加的方式,共同贡献最终记忆表征(见图 2b);这些整合后的记忆信息,最终会被模型尾层的注意力模块读取并用于生成预测(见图 2c)。
因此,在向模型 G 写入大量新记忆时,可以把需要修改的总量分摊、分散到所有关键层 l∈R 的 MLP 分支 mil 上,从而实现大规模、稳定的批量知识编辑。
4.2 单个线性关联记忆的批量更新
在每一层 l 中,我们希望一次性存入大批量记忆(数量 u≫1)。本节推导单层最优参数更新公式:在尽量保留模型原有旧记忆的前提下,最小化新增关联的平方误差。
记待更新的输出权重:W0≜Woutl将该层视作线性关联记忆模块(Kohonen, 1972;Anderson, 1972):
- 输入键向量:ki≜kil(对主体的编码)
- 记忆值向量:mi≜mil(事实属性编码)
原始权重 W0 是最小化原有关联平方误差的最优解:W0=argminW^i=1∑nW^ki−mi2(7)
把所有旧键、旧记忆按列拼接为矩阵:K0=[k1∣k2∣⋯∣kn],M0=[m1∣m2∣⋯∣mn]通过正规方程求解最优权重:W0K0K0⊤=M0K0⊤(8)
假设预训练后 Transformer MLP 权重已收敛到式 (8) 的最优解 W0。现在需要给 W0 加上微小增量 Δ,得到新权重 W1=W0+Δ,从而批量新增大量事实关联。
不同于仅支持单条编辑的前人工作,本文定义新旧联合优化目标:W1=argminW^(i=1∑nW^ki−mi2+i=n+1∑n+uW^ki−mi2)(9)
再次用正规方程求解,分块写成:W1[K0 K1][K0 K1]⊤=[M0 M1][K0 K1]⊤(10)
展开:(W0+Δ)(K0K0⊤+K1K1⊤)=M0K0⊤+M1K1⊤(11)W0K0K0⊤+W0K1K1⊤+Δ(K0K0⊤+K1K1⊤)=M0K0⊤+M1K1⊤(12)
用式 (12) 减去原式 (8),消去旧项:Δ(K0K0⊤+K1K1⊤)=M1K1⊤−W0K1K1⊤(13)
引入两个简化变量:
- C0≜K0K0⊤:原有旧键的非中心化协方差聚合矩阵
- R≜M1−W0K1:旧权重 W0 在新关联上的残差误差
最终得到权重增量闭式解:Δ=RK1⊤(C0+K1K1⊤)−1(14)
由于预训练过程不可见,无法直接获取历史全部旧键矩阵 K0,M0。因此不直接计算 C0,而是用统计估计:假设历史记忆键可看作输入随机样本,用层输入向量的期望外积近似:C0=λ⋅Ek[kk⊤](15)
- Ek[kk⊤]:通过实际采样统计得到的非中心化协方差
- λ:超参数,用于平衡新旧记忆权重,典型取值:λ=1.5×104

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)