GPU服务器全景解读(二):国外三大芯片巨头——NVIDIA、AMD与Intel
在上一篇文章中,我们勾勒了GPU服务器市场的三层架构。芯片层,作为这个架构的基石,其技术路线与生态格局,直接决定了上层所有选择的边界。今天,我们就将目光聚焦于这一核心层,来聊聊国外三大芯片巨头(NVIDIA、AMD与Intel)如何以不同的策略,争夺AI算力的制高点。
Part 01 NVIDIA:软件生态构建的绝对主导
在数据中心AI加速器市场,NVIDIA占据着无可争议的主导地位。回顾2024年,根据富国银行等机构统计,英伟达在数据中心 AI 加速器市场份额约94%。这种统治力并非仅源于硬件性能,而是软件与硬件深度耦合的结果。
核心优势:CUDA生态的“事实标准”
NVIDIA最强大的壁垒,是其构建的CUDA软件生态。这包含了从底层驱动、编译器、数学库到与所有主流AI框架深度集成的完整工具链。全球数百万AI开发者在此生态上进行开发,使得几乎任何新的AI算法,都会优先、甚至仅在CUDA上获得最佳优化。选择NVIDIA,意味着选择了最成熟、风险最低的开发环境。
产品矩阵与场景匹配
NVIDIA通过精细化的产品矩阵覆盖不同需求:
H100/H200:面向千亿参数大模型训练与推理的旗舰。基于Hopper架构,H200更是配备了141GB的HBM3e高带宽显存,专为处理超长上下文窗口设计,是大模型云服务与前沿研究的基石。

NVIDIA H100
A100:虽然已被迭代,但其80GB显存版本在需要大显存的中等规模训练和批量推理场景中,因其出色的性价比和稳定性,依然保有巨大的二手及存量市场,常作为预算受限场景下的高性价比训练选择。

L40S/L4:基于Ada Lovelace架构,是兼顾强大AI推理(特别是FP8精度)与专业图形渲染的全能芯片。非常适合AIGC内容生成、数字孪生、云游戏与虚拟化工作站等融合负载。

NVIDIA L4
Part 02 AMD:以开放生态与硬件优势寻求破局
作为主要的市场挑战者,AMD的策略清晰:在核心硬件规格上提供对标或超越竞品的选择,同时以更具竞争力的性价比,并推动开放的软件生态,吸引那些希望打破单一供应商依赖的客户。
硬件优势:显存容量与带宽
AMD的Instinct MI300系列是其当前的主力。
以MI300X加速器为例,其提供了高达192GB的HBM3显存和5.3TB/s的带宽,在纸面参数上超越了同期竞品。最新的MI325X更将显存提升至256GB。对于需要加载超大模型或进行海量数据批处理的场景,更大的显存可以直接减少与系统内存的数据交换,从而提升效率。

软件生态:ROCm的进展与挑战
为挑战CUDA,AMD推出了ROCm开放软件平台。其进展显著,最新版本在Llama、Stable Diffusion等主流模型上的性能已大幅优化。AWS、Azure等全球云服务商也已提供基于MI300的实例,为其生态提供了关键背书。
然而,ROCm在开箱即用的体验、对复杂或前沿模型的支持广度,以及第三方工具链的丰富度上,与CUDA生态仍存在差距,且目前主要依赖Linux环境,对Windows开发者的友好度不如CUDA。
市场定位:高性价比的“第二选择”
对于有较强技术团队、且对算力成本敏感的企业与机构,AMD提供了极具吸引力的替代方案。在云端,它也成为大型云商优化采购成本、避免供应链单一化风险的重要选项。
Part 03 Intel:聚焦性价比与开放集成的差异化路径
Intel并未在绝对峰值算力上与NVIDIA和AMD正面竞争,而是选择了一条差异化路径:聚焦于总拥有成本优化,并利用其数据中心产品组合与开放网络标准,提供易于集成的解决方案。
核心产品:Gaudi系列加速器
对于Intel的Gaudi 3 AI加速器,官方信息强调其核心价值主张是“领先的性价比”。在部分大语言模型推理的基准测试中,Intel宣称其性价比显著优于竞品。这对于推理成本占主导、且对预算敏感的应用场景具有吸引力。

关键差异化:基于标准以太网的扩展性
Gaudi架构的一个显著特点是深度集成以太网。每个加速器配备多个高速以太网端口,支持RDMA。这意味着企业可以利用数据中心现有的、成熟的以太网网络来构建多卡AI集群,无需采购专用的InfiniBand交换设备和线缆。这大幅降低了集群的组网复杂性和成本,尤其适合从传统数据中心向AI平滑扩展的企业。
全栈协同:OneAPI与CPU联动
Intel利用其在CPU市场的领导地位,推动“至强(Xeon)CPU + Gaudi加速器”的协同优化。其OneAPI编程模型旨在为不同计算架构提供统一的开发接口。同时,Intel也提供从CPU、加速卡到傲腾存储的完整解决方案,对于青睐“一站式”采购和集成的客户具有一定吸引力。
Part 04 总结与选型考量
针对这三条技术路线,我们为大家总结了核心差异:
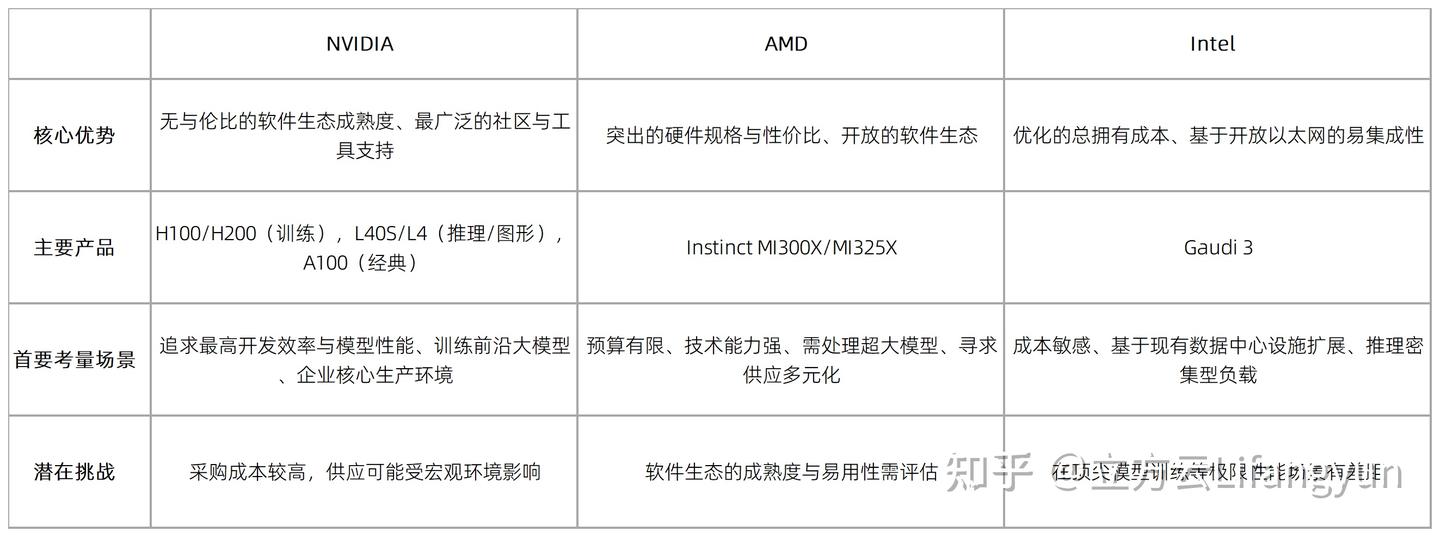
一点选型的初步建议:
- 追求效率与稳定:如果目标是快速推进AI项目落地,最小化技术风险,并需要训练或部署最前沿的模型,NVIDIA的完整生态是目前最高效的选择。
- 追求性价比与可控:如果企业拥有强大的工程团队,希望优化算力成本,并愿意在软件调优上投入以获取更高的硬件收益,AMD是值得认真评估的选项。
- 追求集成与总成本:如果是对成本高度敏感,负载以推理为主,且希望基于现有的标准数据中心网络(以太网)进行扩展,Intel的解决方案提供了独特的价值。
当然,在最终决定前,最可靠的方式还是使用您的实际工作负载和数据,在目标芯片上进行详尽的测试验证。
下一篇,让我们继续深入,对英伟达系列芯片进行详解,欢迎关注立方云Lifangyun。
网鼎科技旗下“立方云”平台致力于为企业客户打造全球算力与网络解决方案。通过云主机、裸金属服务器、云连接及AI算力等核心服务,助力企业实现核心应用灵活部署、边缘业务高效运行与AI创新快速落地,全面满足多样化计算需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)