CFC:基于双层世界模型的角色 - 流体耦合仿真
今天跟大家汇报一下我们的工作,内容是关于刚体和流体之间双向耦合(two-way coupling)的 world model。这次报告对应的是我们在 SIGGRAPH Asia 上发表的工作。

我叫窦志扬,英文名 Frank。这项工作是我和Peng Chen一起完成的,Peng Chen之前是我们香港大学课题组的博士后。同时也有很多合作者对这项工作付出了非常多的支持与贡献。Peng Chen和我是共同第一作者。今天我主要跟大家分享的,是我们如何高效地建模这类刚体和流体之间双向耦合的世界模型。
2. World Model基础概念与研究动机

相信大家对世界模型(world model)这个概念应该已经非常熟悉了。最早大家开始思考世界模型,尤其是在机器人领域,通常是这样的逻辑:
一般是策略根据当前的state和policy提供的action,而世界模型根据这个state和action来预测未来的state(状态),从而用于planning或者用它来训练控制器。
在我们这项工作之前,已经有很多针对世界模型的建模工作,有的是基于视频的方式做世界模型,也有很多工作是基于纯刚体场景的。比如大家在Isaac Gym里面,或者在 Mujoco 里面训练一个网络,去预测机器人未来的物理状态,这些模型里通常包含大量刚体信息。
而我们的工作,更多关注的是刚体跟流体之间的interaction。这个任务相对来说要更加复杂一些。
当然,关注机器人领域的同学应该知道,现在有大量sim-to-real的工作,也就是在仿真器中训练控制器。我们这套架构、这套思想,也可以用在机器人agent的训练和控制上。
第二部分,我会简单讨论一下我们在这个项目中遇到的一些困难和思考。我觉得这个领域现在整体非常火、非常热门,但里面仍然存在大量fundamental问题。这些最本质的问题,和机器学习、数据驱动深度学习的发展高度相关、高度绑定在一起。
我们最早做这个问题的初衷非常简单:我们本身来自graphics社区,所以希望尽可能高效、同时也尽可能准确地建模人体和各种场景、各种情况之间的交互——不管是人与人交互,还是人与各种物体交互。

我们发现,已经有很多工作在建模刚体和软体,也有人用刚体去建模一些偏粘稠的液体。于是我们就想:能不能把这个问题做得更有挑战性、更有意思一点?也就是去研究人和高度动态流体之间的交互。
背后的一个原因是,我们希望能够在计算机里复现人的各种运动技能(motor skills),尤其是和高度动态环境的交互,比如水、泥浆(mud)、波浪(wave)这类自由度非常高的场景。所以这个问题本身是比较困难的。
而且我们知道,人在和复杂流体环境交互的时候,会出现很多我们称之为涌现行为(emergent behavior)的现象。比如大家训练一个policy,最终学到并展现出来的技能,不只取决于你的数据,也不只取决于你的控制器,环境本身也会塑造行为。

比如我们希望看到机器人或者agent,能够在比较粘稠的泥潭里学会高抬腿走路;或者在面对海浪冲击的时候,能够学会保持平衡,不被海浪或者急流冲倒。
所以我们希望在这个项目里,尝试建模这样的行为,并且合成符合物理真实性、同时具有高度多样性的角色动画(animation)。
这里需要区分一点:在图形学领域,角色动画分为两类。 一类是kinematic based的动画,大家只关心每个关节的位置、位移,只关心视觉效果。这种方法通常无法保证物理真实性,很多时候会出现滑步、穿模等问题。

我们这里研究的动画是另一个分支:physics based animation。里面的角色是通过物理仿真得到的。这类基于物理的动画里的控制器和学习方法,已经被广泛用在人形机器人、四足机器人上,所以它天然和 sim-to-real 的需求高度契合。
3. 传统强化学习与物理仿真的瓶颈分析
那么一般来说,我们怎么训练一个角色?怎么得到一个控制器,让它能够比较自然、高效地和流体交互?
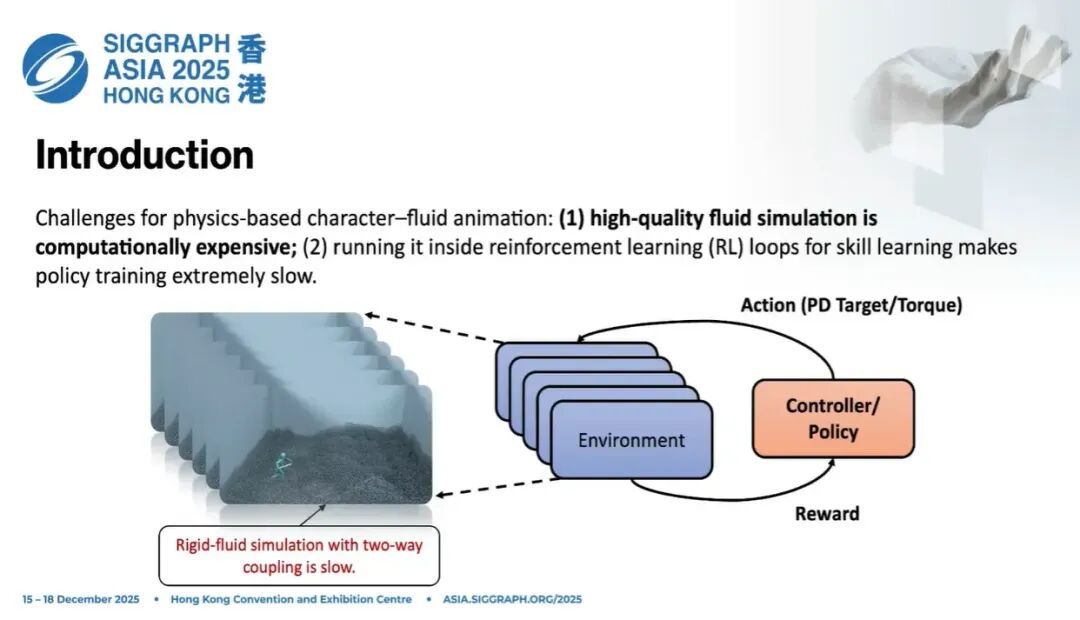
如果看传统的 PPO 算法,或者传统简单环境里的仿真,流程是这样的: 我们有一个控制器,通常是一个参数化的神经网络。我们希望这个神经网络去预测action,然后这个动作送入仿真环境。仿真环境根据这个动作解算出力矩(torque),再通过拉格朗日方程,更新每个关节的动态,处理碰撞(collision)、防穿模等,把整个仿真跑完。
我们可以定义reward,比如让一个物体移动到某个位置、抓取某个物体等。也可以用逆强化学习、生成对抗模仿学习等方式构建奖励,从而近似梯度、更新策略。
这套流程非常高效,对很多刚体、甚至刚体和软体之间的交互都有很好的效果,能够在这类环境里很好地训练和建模。
但是到了刚体-流体耦合的场景里,问题就不一样了。流体仿真有多种常见方法;本文采用的是基于SPH的拉格朗日粒子表示来建模流体—刚体耦合。这种Lagrangian particle的表示方式,我们认为更贴近真实世界的物理动态建模方式。
那么在流体环境里,我们能并行很多环境吗?其实非常困难。
因为强化学习本质上是在sample action,然后给每个采样的动作打分、得到奖励。在流体环境下,我们必须维护非常多的流体环境实例,才有可能采样到合理的、好的动作空间,从而得到有效的奖励。所以必须同时跑大量环境。
首先,刚体-流体耦合仿真本身计算代价非常高。 其次,为了采样又必须维护大量环境,这对内存、CPU 运算、GPU 运算都带来巨大压力,整体开销极大。
而且就像刚才说的,大量采样的目的是为了估计梯度,从而做policy gradient descent。这本身就是一个非常大的挑战。
4. 神经网络世界模型的核心优势
那么我们怎么解决这个问题?
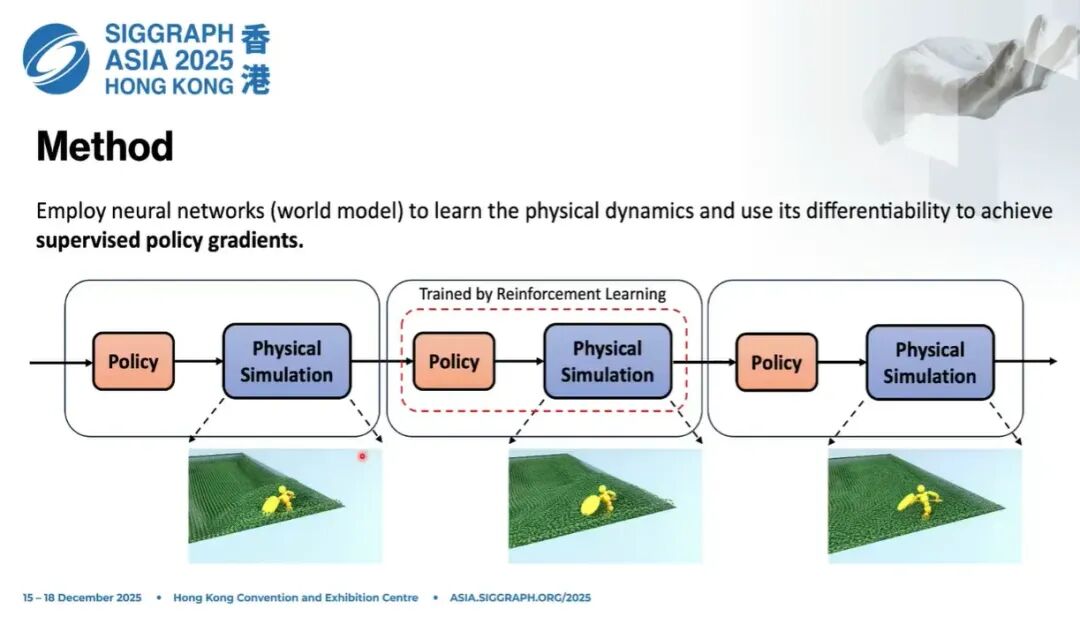
其实最早这个想法并不是我们提出来的,已经有很多优秀的前人工作在用神经网络,或者用differentiable simulation去建模系统动力学(dynamics)。主要原因有两个: 第一,网络推理更快; 第二,网络本身可以提供梯度。
所以一个非常自然的想法就是:用神经网络把原来复杂、计算代价很高的物理仿真,替换成轻量化、differentiable的版本。
从更高层面理解这件事:不管是刚体仿真、刚体-软体仿真,还是刚体-流体仿真,所有仿真本质上都是数学模型。比如机械臂里最经典的:
这就是经典的拉格朗日方程。
拿到这个方程你会发现,它本身就是一种近似。我们其实是在用高度简化的数学模型描述世界动态,再把它实现在 CPU、GPU 上,做成可微或者不可微的平台。这类平台本质上是解析的、基于模型的(analytical / model-based)。
但现实世界存在大量因素,都被高度简化了。比如我们可以用牛顿第二定律描述运动,可一旦放进仿真器,用理想模型表示之后,和真实世界永远存在差距,因为很多因素我们不是不想建模,而是根本无法在仿真器里建模。
而用神经网络有一个高层意义上的好处:它是一种天然的数据驱动方式。如果我们有一种高效、有效的方式,让仿真器从数据里学习动力学,神经网络就是一个非常好的候选。它可以以数据驱动的方式捕捉动态,让仿真更逼近真实,是用基于学习的方式帮助传统仿真、让传统管线更好匹配真实观测的有效手段。
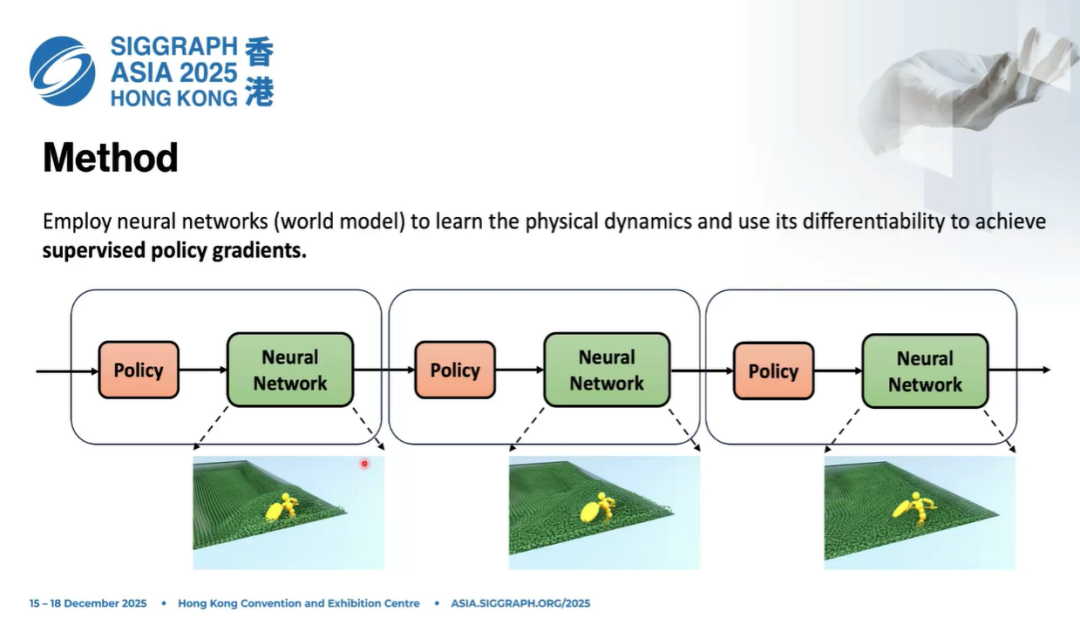
回到工程层面,优势就更直接: 第一,它更快,可以快速更新粒子动态,比 SPH 计算快得多; 第二,它可以提供梯度。有了梯度,就可以定义奖励,然后反向传播更新策略,直接获得梯度信息。
我们之前用 PPO 这类强化学习方法,本质原因就是要采样大量环境,去估计一个梯度来更新策略网络。现在梯度可以直接回传,我们就可以用监督学习的方式训练策略。
这是我们做这件事的两大动力:前向过程更快,反向过程有更可靠的梯度信息。
5. 相关工作对比与本研究创新点
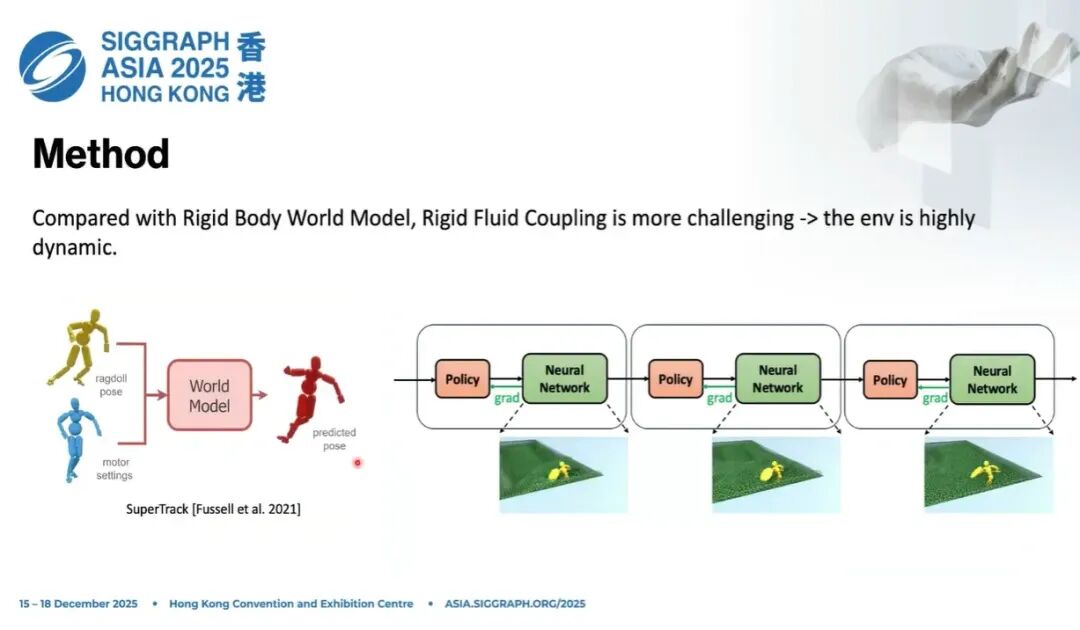
刚才也提到,之前已经有很多优秀的前期工作在做类似事情。一个非常经典的工作是 SuperTrack,SIGGRAPH Asia 2021 的文章。它讲的是在刚体里,用神经网络学习世界模型。那篇文章里有很多设计我们都借鉴了,比如把整个动力学状态空间定义在角色的局部坐标系(local frame)下,做归一化,让数据分布更规整,更好地表达各类特征。
我们和它的区别在哪里?
刚体相对简单,甚至大家用 Brax、Google Brax 都可以拿到梯度。但是梯度计算图一般很大,内存开销很高,所以在可微仿真、世界模型这类框架里,batch size 通常开不大。
同样的内存下,很多刚体仿真用 RSA-SIM 这类不可微方法,可以开到上万个环境;而可微仿真可能只能开到 20、30、40。从任务回报、奖励曲线来看,不可微仿真在大量采样下,效果不一定比可微仿真差,甚至效率更高、速度更快。
这件事在刚体上成立,在软体上就比较困难,在流体上则极端困难。因为流体仿真,不管是可变形还是不可变形,计算代价都非常大。
所以刚体-流体耦合在计算上更昂贵、更具挑战性。这也是我们想突出的一个重要点:世界模型本身的难度,和系统动态的自由度高度相关。刚体自由度非常有限,而拉格朗日流体每个粒子自由度都很高,建模难度极大。
因此我们想做的就是:设计一个神经网络、一个世界模型,去高效、有效地学习这种耦合动力学。
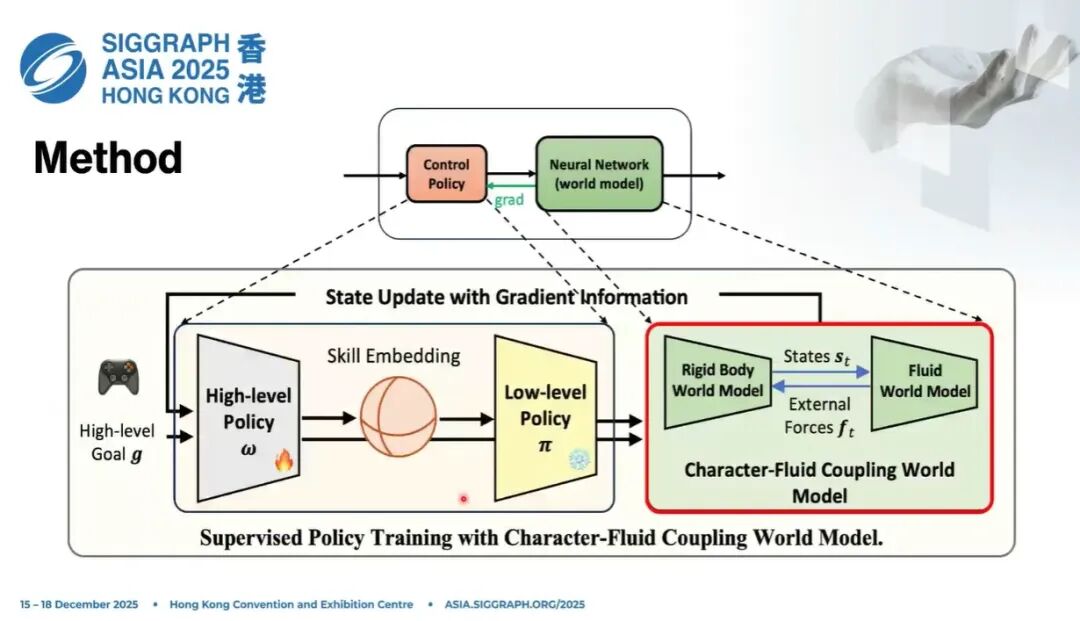
6. 整体框架与模块化设计总览
我们的整体思路是把设计做成模块化。这里先给一个大致的总览,说明我们是怎么做的。
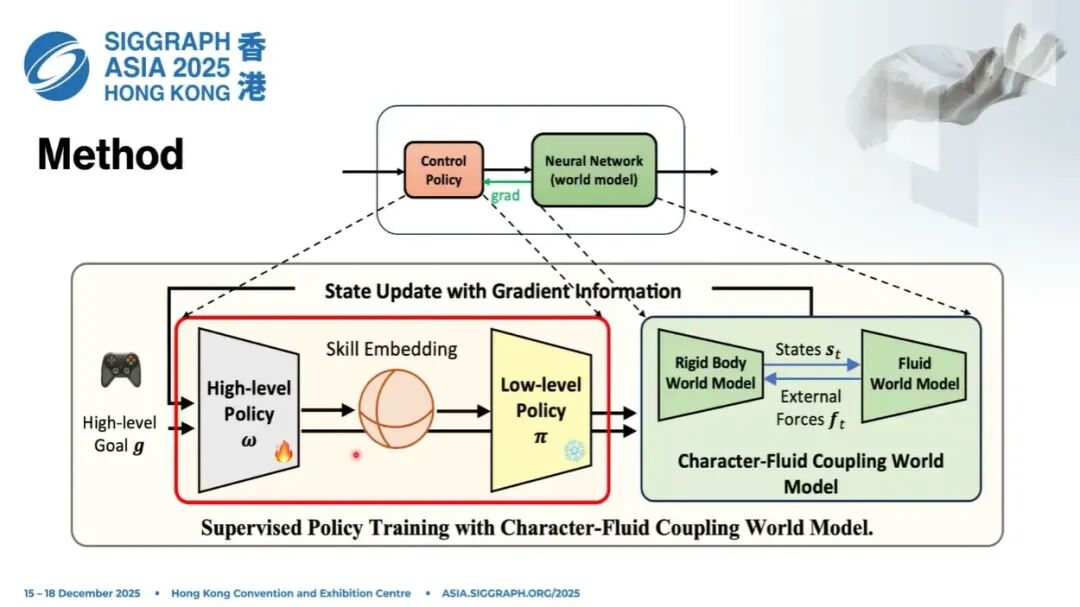
在讲细节之前,我先从高层思路说明:如何设计策略,完成策略训练和世界模型更新。
整个控制流程和最终效果里,有两个很重要的部分: 一个是角色本身的control policy; 另一个就是我们前面讨论了很多的world model。
我先从策略控制讲起,因为这部分相对直白、简单。讲完这部分,再讲我们怎么设计世界模型,去更好地更新策略。
7. Low-level Policy 设计
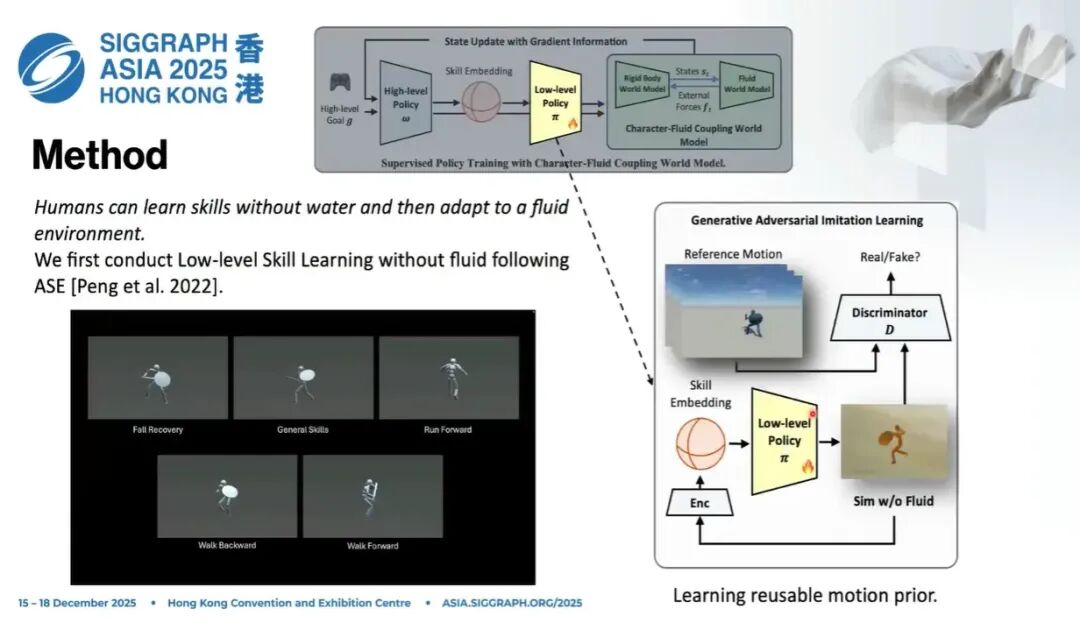
如果大家熟悉Jason Peng老师等人在SIGGRAPH 2021 的 AMP 和 SIGGRAPH 2022 的 ASE 相关工作,就会知道它延续了 AMP 的思路:把先验蒸馏到latent space,然后在隐空间里采样,控制角色。
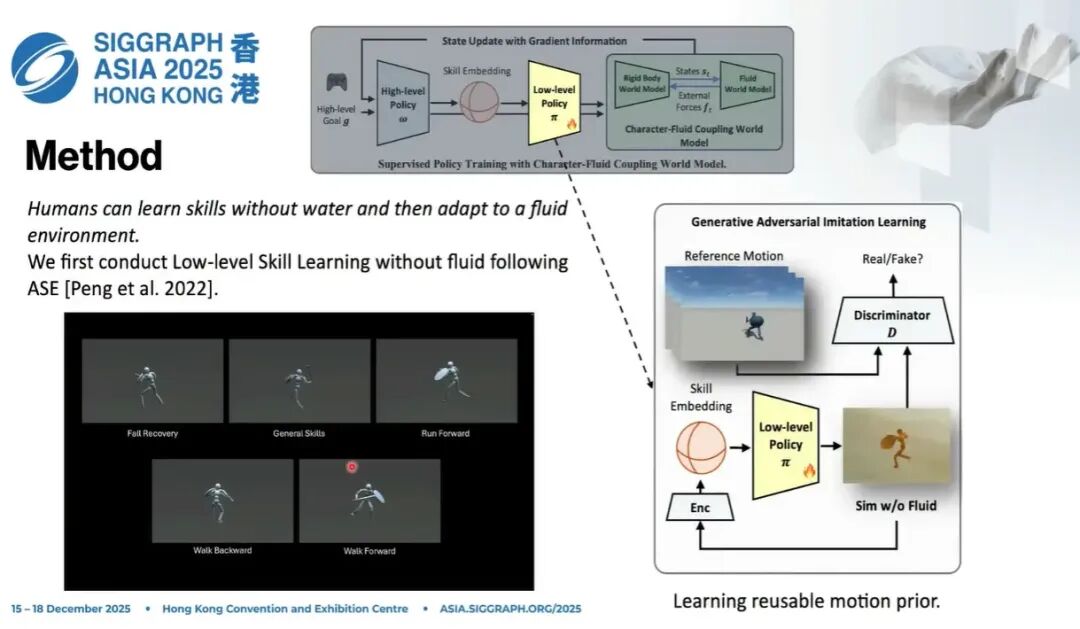
我们完全沿用了这一套思路:训练一个low-level policy。训练完成之后,就可以在这个底层策略里采样技能,得到动作。具体来说,是把技能嵌入到一个spherical Gaussian distribution上。
这里涉及到我们第一个设计:basic skill。
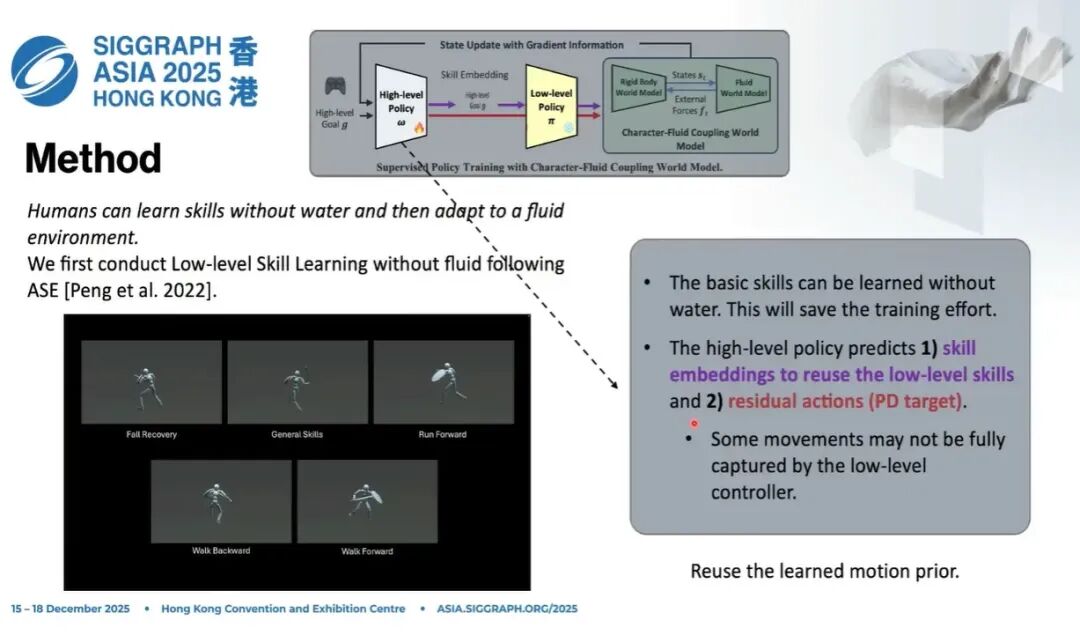
大家可以想象人:人生下来先在陆地上生存,之后去游泳池、水田、沼泽,依然可以学习在里面行走。但在学习这些特殊技能之前,人已经掌握了大量基础技能。
所以我们可以先在没有水的环境里学习基础技能,再把技能适配(adapt)到和水交互的环境,这样可以节省大量训练时间和成本。
这也说明策略和世界模型高度相关:你如果完全从零开始,把一个没有任何技能的角色扔进流体里训练,非常浪费;完全可以先学基础技能,再做迁移。
8. High-level Policy与残差动作设计
底层技能学好之后,我们把它固定。然后在隐空间里采样技能,再训练一个high-level policy复用这个隐空间。
高层策略的作用,就是在这个隐空间里预测如何控制角色,复用已经学到的技能。
更重要的一点是:我们底层先学习一组可复用的基础技能,如走路、跑步、摔倒恢复等动作先验,但我们更关心涌现行为,比如水来了自动降低重心、在泥潭里高抬腿以减小粘滞阻力、提高移动速度等。
因此高层策略还会预测一个residual action,形式是PD target。
也就是说,在隐编码解码出一个动作之后,网络同时预测一个残差动作,去修正这个动作空间,让策略具备泛化能力,能够学到基础技能覆盖不到的新行为。
简单总结:我们希望用底层技能把解空间压缩,无水环境训练成本低、速度快;同时又不希望被底层先验限制住,所以用残差动作捕捉基础技能之外的能力。
现在关键问题就变成:如何训练高层策略,让它学会和水交互。策略相当于把搜索空间限制在一个合理范围。如果完全从零开始训练和水交互,代价太高,所以我们先用底层策略压缩解空间。
底层策略学好并固定,高层策略的结构也明确之后,下一步就是:如何设计一个世界模型,高效、有效地训练控制器。
9. 刚体-流体耦合世界模型的朴素方案与缺陷
我们先看一个非常朴素的方案,这也是很多刚体世界模型的设计方式。
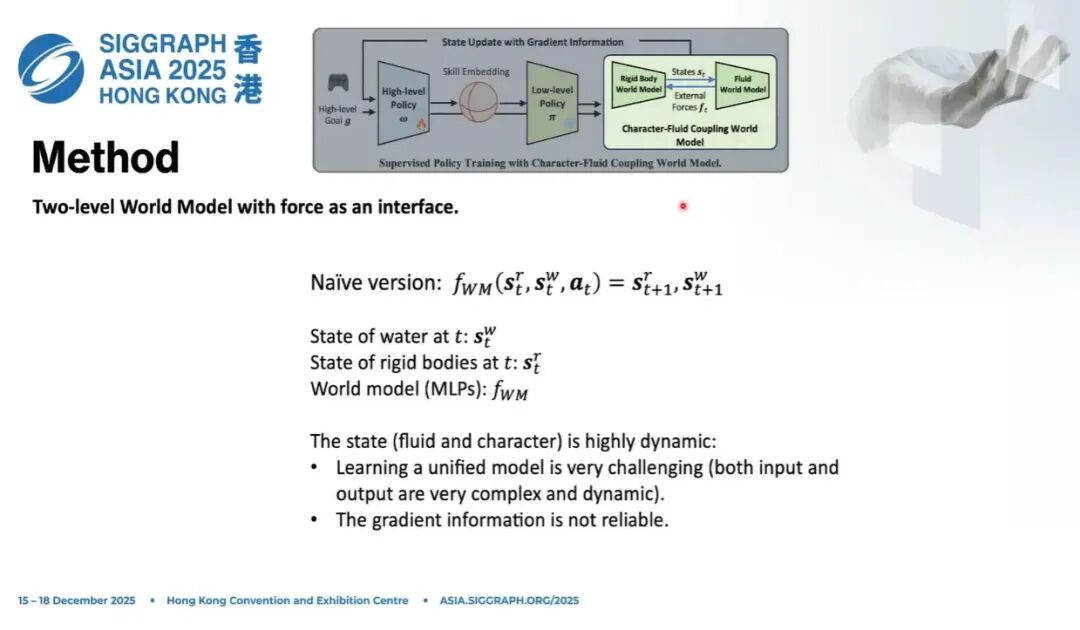
假设 是刚体(物理角色)的状态, 是流体的状态。 刚体状态包括根节点高度、每个关节角度、线速度、位置等,都在局部坐标系下; 流体状态就是拉格朗日粒子的位置、速度等; 是定义在刚体关节空间的动作。
我们可以训练一个自回归世界模型 ,让它去滚动预测下一帧的角色状态和流体状态:
这是一个很经典的自回归范式。在机器人领域,如果把状态换成视频帧,就是视频世界模型。很多研究也会结合扩散模型、self-forcing等,让滚动预测更准。
但直接这么做有什么问题?
我们最早的版本就是这么做的。流体动态变化极强、自由度极高,刚体相对简单,所以这个模型极难训练。
理论上,这种方式一定可以捕捉复杂行为,你甚至可以训一个超大模型、foundation model 去建模这种交互。但代价太大:参数量巨大,推理时间成本也很高。而我们在训练策略的过程中,不希望世界模型太慢。
所以要捕捉复杂行为,需要更精巧、更高效的方式去建模各部分动态。
另一个问题是:如果网络不能很好地捕捉动态,那么梯度下降、梯度信息就更不可靠,自然无法用来很好地训练策略。
在 2025 到 2026 年这段时间,我们做了很多探索,加了各种 trick,效果都不算特别成功。或许现在更快的 Transformer、更好的加速方案能让它跑起来,但在当时我们发现,这种方案并不能很好解决我们的问题。
10. 解耦式模块化世界模型设计
我们的高层思路是:模块化 + 解耦。
大家可以想一件事:我们控制的是人,不是液体。没有人能控制每一个水粒子怎么动。我们本质上是在控制人,最终关心的也是人的动作和行为。
而人和任何物体的交互——不管是刚体、软体还是流体——本质上的接口都是力(force)。
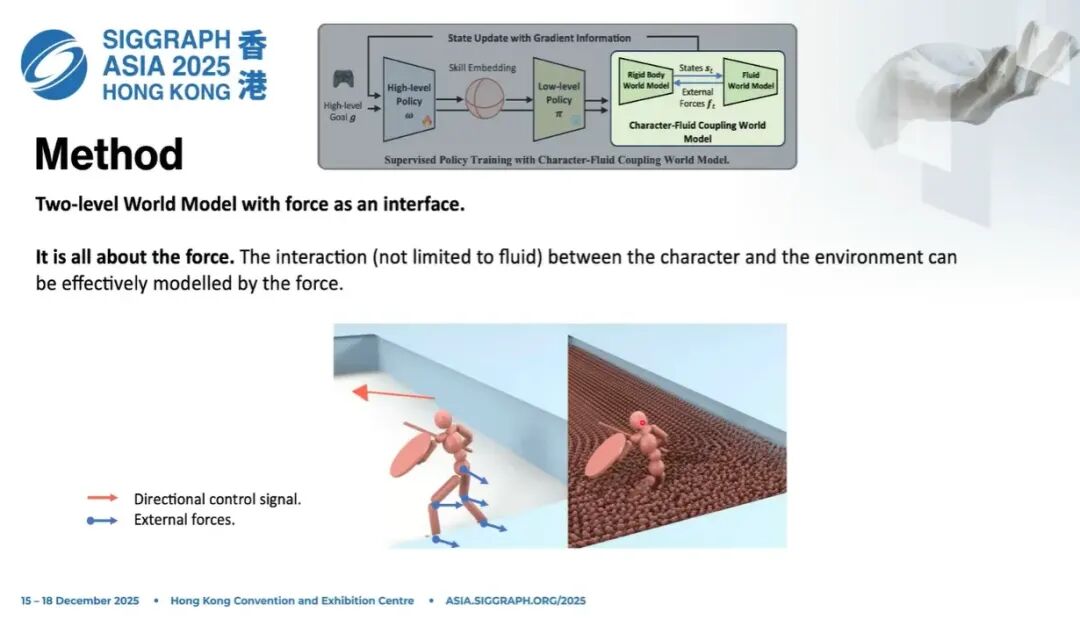
比如有人打我一拳,脸变形,是因为受到了力,产生形变。 人在水里走路,和水流接触的部分会受到外力。
所以我们可以把过程建模成: 流体 → 产生力 → 力作用在人身上。
这就是我们的核心思想:找到一个好的中间表示——力,把流体和角色两部分解耦开,从而获得巨大的设计自由度。
我们把整个系统拆成两部分。
10.1 Character World Model
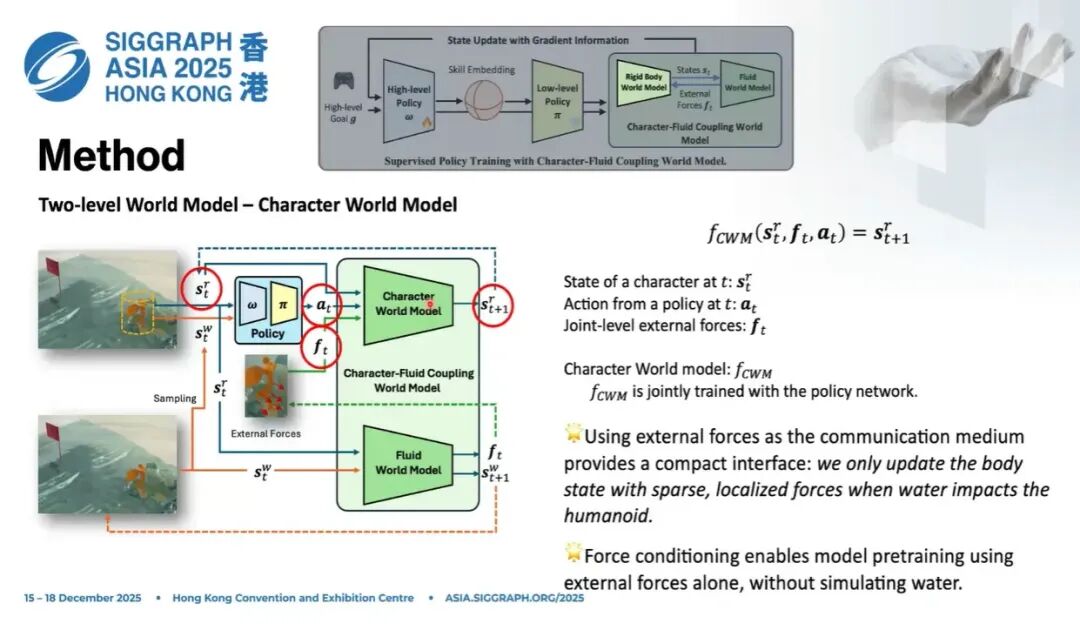
第一部分是角色,相对简单。 我们设计一个character world model,神经网络只做一件事: 输入刚体状态 、动作 、外力 ,输出下一帧的角色状态:
它只建模角色这一部分。如果去掉外力 ,其实就是前面提到的 SuperTrack 的思路:上一帧状态 + 动作 → 下一帧状态。 现在我们引入一个外力扰动,它可以来自流体,也可以来自刚体、软体,是一种通用表示。
这个模型的好处是compact。
在做刚体-流体耦合的时候,你可以在刚体表面采样,计算曲面级别的力。但精度太高、维度太大,我们把它压缩到joint level,累积到每个关节上。
比如一个14或17个关节的角色,我们只需要在对应的关节空间上学习;若是17个关节,就是17*3维。这是一个非常重要的压缩,把需要学习的状态表示空间高度压缩,让网络更容易学习。
更进一步,这个模型完全可以在没有水的环境下训练。
比如人在任何地方走路,都可以给他一个阻尼力,和速度相关;也可以随机施加外力拖拽、阻碍它。模型会学到如何应对各类外力扰动。这是第二次压缩: 第一次压缩:用底层策略把技能空间压缩; 第二次压缩:把流体-刚体交互解耦,单独训练角色应对外力的能力。
因此角色世界模型可以在无流体环境下预训练,效率极高。
10.2 Fluid World Model
第二部分是流体。 fluid world model做的事情是: 输入刚体状态、流体粒子状态,输出下一帧流体状态,以及作用在角色上的外力:
力是两者之间的接口,我们通过力来建模压缩后的刚体-流体交互。它既预测流体怎么动,也预测力如何施加在角色身上。
11. 模型训练与物理约束损失设计
我们使用reconstruction loss,让模型预测的粒子状态尽可能接近真值。 同时加入physics-aware loss,比如不可压缩性约束、barrier potential等,防止粒子坍缩、防止穿模。
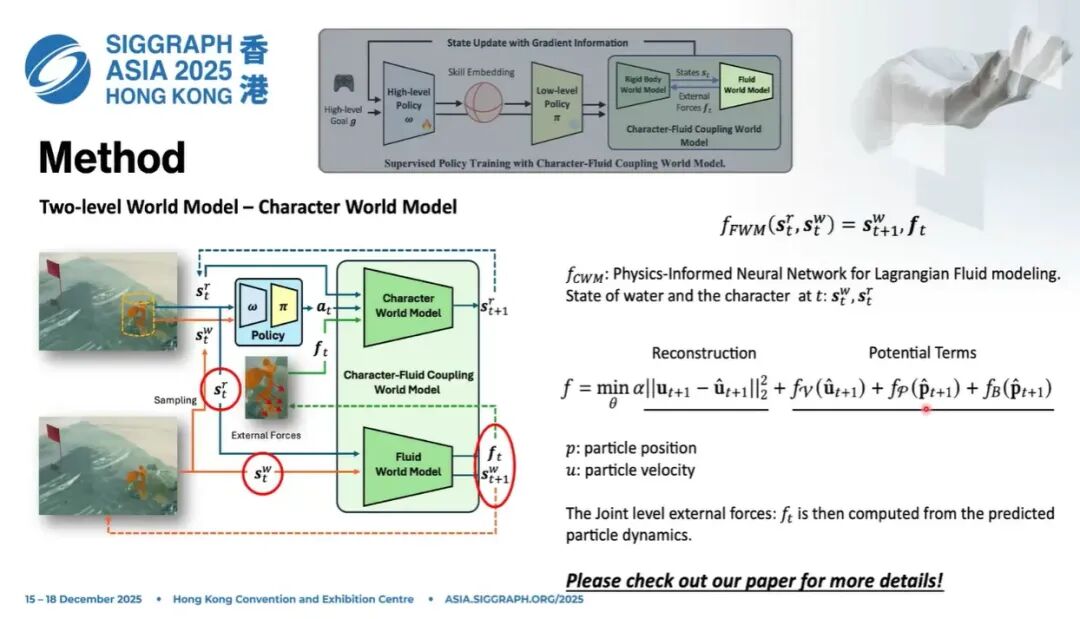
流体本身复杂度并没有降低很多,仍然在建模粒子运动,因此需要精心设计物理相关损失,让网络具备物理信息,更好地捕捉动态。
但因为角色部分可以单独快速训练,整体训练速度快了很多。
自回归模型在长序列rollout中会有严重的误差累积,自由度越高,粒子误差越大。但大家可以注意:我们更关心的是力对角色运动的影响,而不是流体粒子本身的绝对精度。哪怕粒子位置差一点,只要对角色的作用效果准,世界模型依然可以有效指导策略训练。

12. 实验效果与仿真性能提升
我们预先训练底层策略,把高维解空间压到低维紧致空间;然后策略学习复用技能、修正动作,完成流体交互。
世界模型的作用是:输入动作,给出状态更新;流体模型给出关节所受外力;角色模型根据外力更新状态,得到下一帧状态。整个过程可微,因此可以用梯度信息监督高层策略,控制角色在系统中运动。
整个系统包含四个网络,对应多组优化器,训练时需要协同更新。
监督梯度下降带来了非常明显的策略训练加速。比如可以让角色在泥潭里行走。
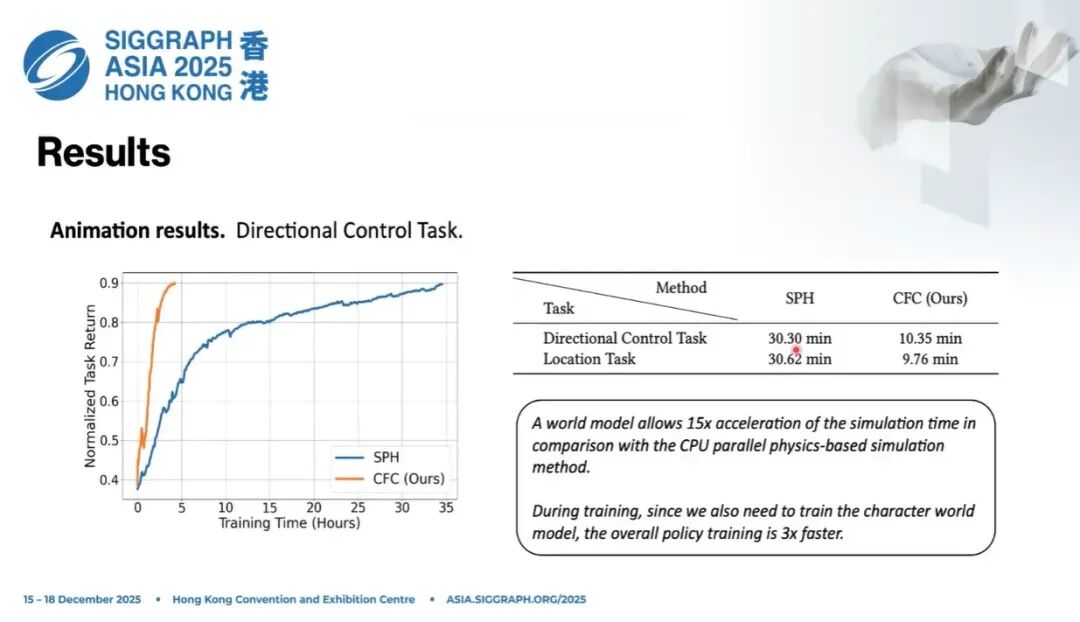
传统 SPH 仿真速度很慢,受限于普通工作站配置。神经网络世界模型可将仿真阶段加速约15倍;在策略训练阶段,整体加速约为3倍。原因在于:世界模型需要和策略同步更新。
13. 训练机制与探索-更新策略
如果把世界模型权重固定,策略一旦探索到从未见过的状态分布,世界模型就会失效:预测变差、梯度错误。
因此我们必须在策略训练过程中,周期性调度更新世界模型。
在我们的设置里,流体世界模型是固定的(frozen),而角色世界模型会随着策略训练持续进行监督更新。
策略训练和世界模型训练目前是串行的,策略需要等待世界模型更新,这就是速度提升存在差距的原因。未来可以用并行进一步压缩时间。

实验中,角色可以学到涌现行为:在不同粘度液体下动作模式不同,环境会塑造机器人的动作和表现。
14. 模型泛化能力与应用拓展

我们的框架是通用的:
-
可以训练角色在泥潭中行走;
-
可以泛化到多个角色,实现角色之间的互动、对战;
-
可以合成高度真实的物理动画;
-
可以迁移到四足角色,学习利用泥浆粘性行走,尽可能增加腾空时间,提升移动能力。

15. 核心挑战与本质问题分析
我认为这项工作,乃至整个高度动态世界模型建模领域,仍然有大量可以探索的空间,也面临大量挑战。
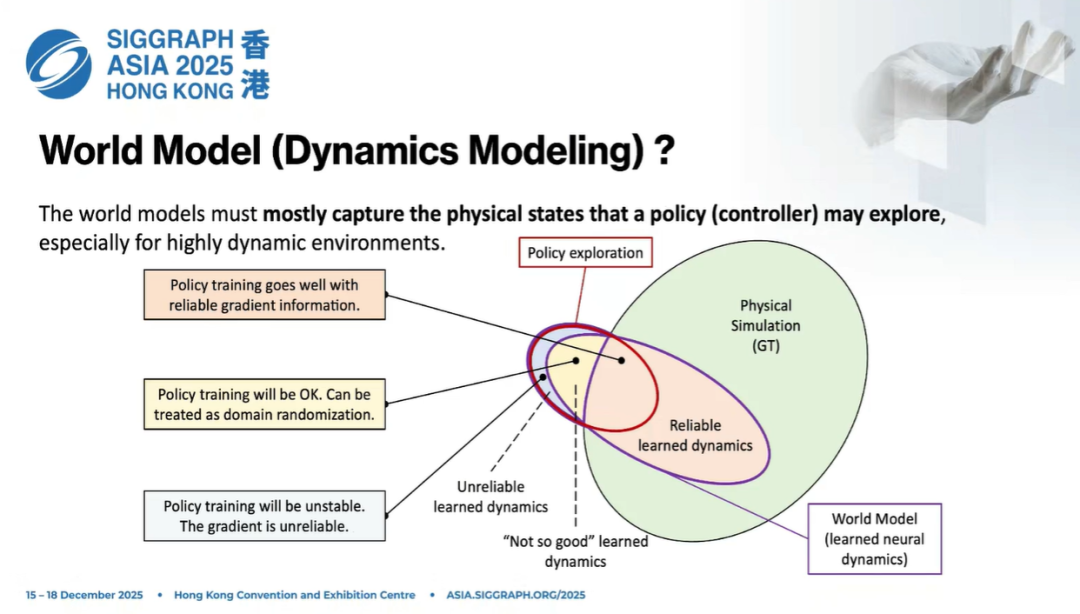
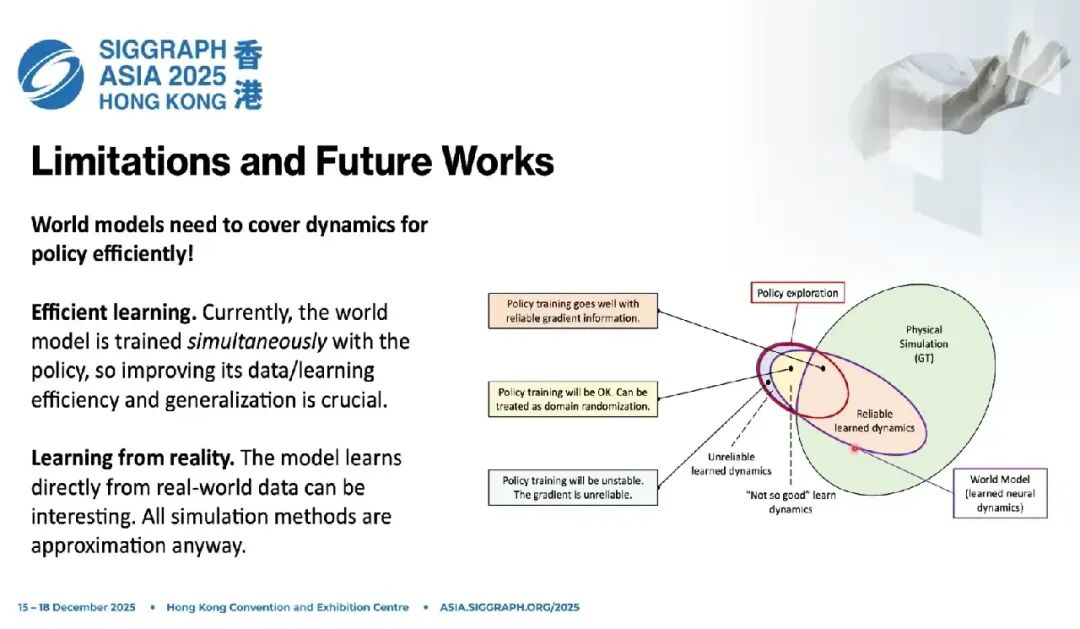
用一张图来理解: 外面更大的圆圈是物理仿真,是我们训练世界模型的ground truth。 神经网络学到的只是其中一个子集,一个椭圆区域。
目前为止,任何世界模型都不可能学会所有物理仿真状态、接触、覆盖情况。泛化能力有限,说明学到的神经动力学并没有覆盖全部情况。
而策略的动作是在一个分布里采样的:
-
如果落在世界模型可靠动力学区域,梯度可信,训练稳定;
-
如果落在一般区域,模型有误差,但仍然可用,对策略来说相当于数据增广;
-
如果探索到完全不可靠的区域,预测完全错误、梯度无效,策略就会卡住、reward就会停滞甚至下降。
这就是为什么监督梯度下降训练曲线会出现:上升快 → 卡住 → 再上升 → 再卡住。
根本原因就是:策略探索到了神经动力学没有建模的状态空间,未来状态和梯度都不可靠。
这是一个非常根本性的问题,也是所有世界模型建模的共同难点: 策略在不断探索、移动分布,世界模型必须尽可能跟上、覆盖这个分布。
16. 未来研究方向与价值
问题本质上是高效模型学习:如何设计一个世界模型,能和策略同步学习,提升学习效率和泛化能力。
我们的探索包括:尽可能压缩表征空间、用物理知情项强制网络保持物理特性。
为什么我们仍然坚持这条路? 因为所有传统仿真器本质上都是对物理的数学近似。而神经网络的一个重要优势,是可以利用真实世界观测数据,让仿真更贴近现实,是缩小(或弥合)sim-to-real差距的有效方式。
未来如果能从现实中高效学习动力学,世界模型的价值会大幅提升。
同时有一个硬约束:世界模型不能太大、太重,否则会抵消掉神经网络在效率上的优势。这是一个非常有前景的研究方向。
以上是我们对这个问题一些比较基础、初步的探索,非常感谢大家参加这次分享。
17. 问答
问:这个领域的数据集怎么来?如果真值也是仿真的,凭什么说它是真值?数据集包括流体和角色动作的哪些部分?
答: 我们现在的主要目的,是用神经网络替代代价高昂的仿真,所以ground truth 直接来自仿真器。
在这篇文章里我们明确:用仿真生成数据。
-
流体粒子数据:用 SPH 做刚体-流体耦合合成;
-
角色交互力:通过积分计算得到;
-
角色基础技能:来自动捕数据集,用对抗模仿学习让物理角色匹配动捕的动作分布。
训练数据主要包括:1)由SPH生成的流体粒子与刚体交互数据;2)角色在外力扰动下的状态转移数据。其中特别是角色世界模型,可以在无流体环境下预训练。
未来从真实世界学习是非常重要的一步,因为仿真仍然是近似,网络只是在逼近这个近似。
问:从真实数据学习,对数据形式、数据量、数据分布有什么要求?
答:刚体上已经有很多进展,比如 Diff-LfD 这类工作,用可微仿真 + 视觉重建,缩小仿真和现实的差距。
视觉信号是成本最低、最通用的信号,但流体透明或浑浊,很难直接视觉重建,通常要加发光的光源、用折射重建,成本很高。
数据形式可以是点云、占用场、网格、纹理等; 数据量高度依赖任务:简单任务数据量小,通用物体操作则需要大量数据。
问:你们框架是不是借鉴了 PINN?有没有把物理约束嵌进去?
答: 对,我们用的就是 PINN 思路。 除了重建损失,让下一帧状态尽量匹配真值,我们还对速度、位置施加物理约束,比如不可压缩性损失等。
科学仿真领域还有很多更好的流体建模方法,未来完全可以替换我们现在的方案。
问:两个模块分别监督,流体模型输出的力有没有单独的损失去拟合?
答: 有的, exactly。 我们在仿真中让角色在水里运动、受水流冲击,计算出表面力,再积分映射到关节级别,用这个力作为监督信号训练网络。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)