零基础学AI人工智能: 5.2 python基础语法之容器类型
上一篇Python基础语法的学习中,我们已经完整掌握了注释、变量、基础数据类型、运算符以及输入输出的核心逻辑,搭建了Python编程的基础骨架。
但在实际的AI开发和编程场景中,我们经常需要同时处理多个数据,比如存储一串用户的问答历史、管理多组模型参数、记录多个样本的特征数据,或者去重统计某类关键词的出现次数。这就需要用到Python中最强大、最核心的数据结构——容器类型。
今天是Python基础语法的第二篇,我们将专门补充讲解容器类型,不涉及复杂代码,仅从底层逻辑、核心特性、使用场景三个维度,帮大家彻底搞懂字符串、列表、元组、集合、字典这五大容器,轻松实现多数据的高效管理与处理。
一、容器类型的核心定义
在深入讲解具体容器之前,我们必须先明确一个核心概念:什么是容器类型?
容器类型是Python中一类特殊的数据类型,它们的核心作用是**“打包”**——即可以同时存储多个不同类型或相同类型的数据,并提供一套规则来管理和访问这些数据。
你可以把容器想象成一个多功能的收纳箱:
- 不同的收纳箱有不同的设计(比如列表像抽屉、字典像标签索引的柜子、集合像去重的篮子);
- 我们可以往里面放不同的物品(数据);
- 并根据需要进行查找、添加、删除或排序操作。
容器类型的共同特性包括:
- 可存储性:能存放多个数据元素;
- 可变性:部分容器支持修改内部元素(增删改);
- 可访问性:提供特定的规则来获取内部的元素。
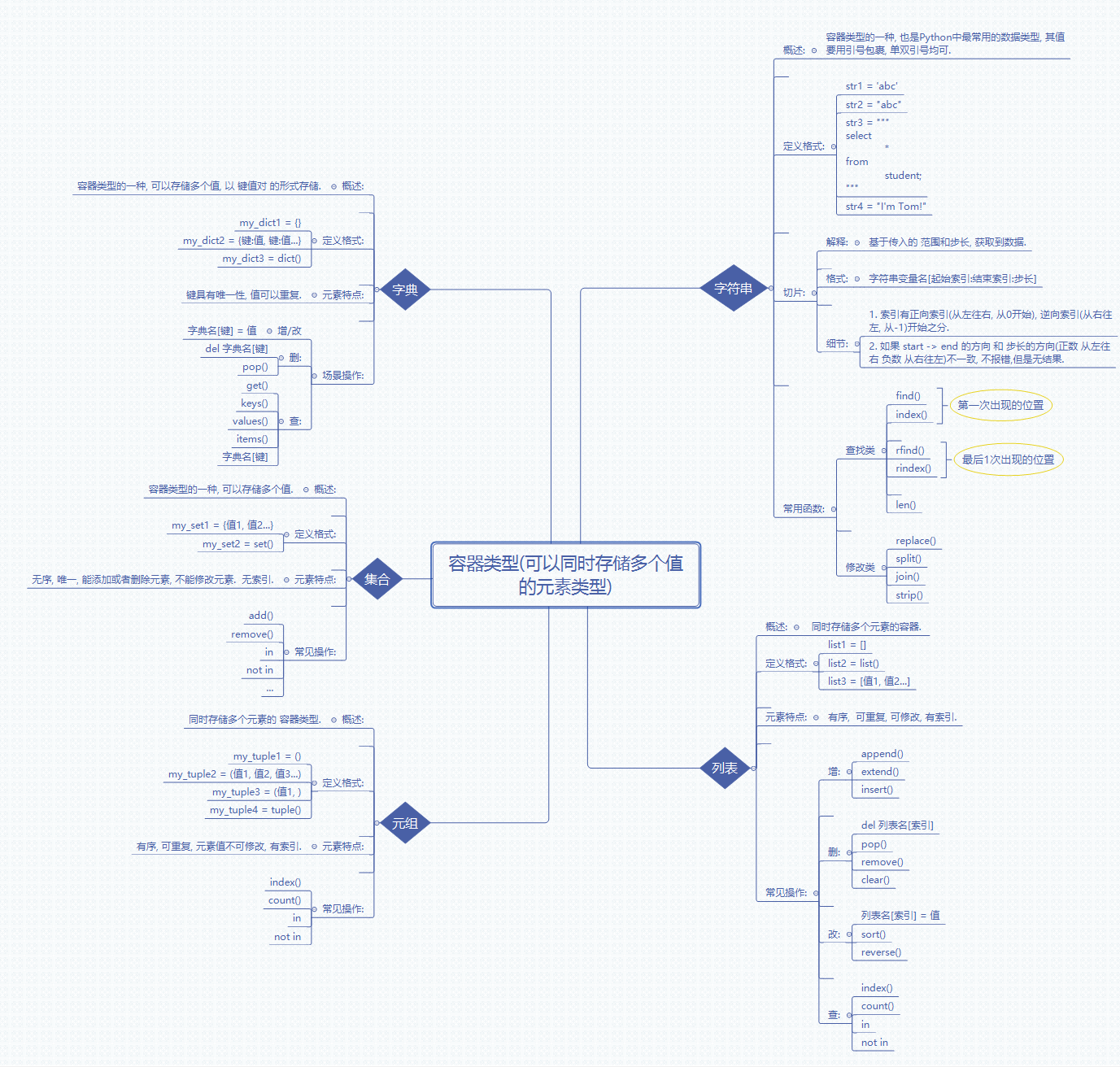
二、字符串:最基础的文本容器
虽然我们在上一篇讲了数据类型,但字符串作为Python中最常用的序列型容器,有其特殊的地位和操作逻辑,在这里我们做进一步的深化。
2.1 字符串的核心定义
字符串是由字符组成的有序序列,是Python中表示文本信息的载体。它的核心逻辑是:将多个字符按顺序排列在一起,形成一个整体的文本块。
2.2 字符串的核心特性
- 有序性:字符串中的字符是有固定顺序的,第一个字符、第二个字符……可以通过位置索引来访问;
- 不可变性:字符串一旦创建,其内部的字符内容就不能被修改。你不能直接替换其中的某个字符,只能通过生成新的字符串来实现内容的调整;
- 索引规则:支持正向索引(从左往右,从0开始计数)和反向索引(从右往左,从-1开始计数)。
2.3 字符串的常用操作
- 查找与替换:可以快速查找某个子字符串在整体中的位置,也可以将指定的内容替换为新的内容;
- 切片操作:可以提取字符串中的某一部分,获取子串,非常适合处理文本片段;
- 格式处理:可以对字符串进行大小写转换、去除首尾空格、按指定分隔符拆分等操作,是AI项目中数据清洗的必备工具。
三、列表:最灵活的可变容器
列表(List)是Python中使用频率最高的容器类型,也是可变序列的代表。它像一个动态的购物清单,可以随时添加、删除、修改商品。
3.1 列表的核心定义
列表是一种有序、可变、可重复的容器,使用特定的符号包裹元素,元素之间用逗号隔开。
3.2 列表的核心特性
- 有序性:列表中的元素有固定的顺序,通过索引可以直接定位到任意元素;
- 可变性:列表是“活”的,定义完成后,可以随时添加新元素、删除已有元素、修改指定位置的元素;
- 可重复性:列表中可以包含完全相同的元素,允许重复;
- 异构性:列表中可以存储不同类型的数据(比如同时存放整数、字符串、布尔值),在AI开发中,这非常适合存储混合类型的特征数据。
3.3 列表的常用操作
- 添加元素:可以在列表的末尾、指定位置添加元素;
- 删除元素:可以删除指定位置、指定内容的元素,或者清空整个列表;
- 排序与反转:可以对列表中的元素进行升序、降序排序,或者反转列表的顺序;
- 查找与统计:可以快速查找元素是否存在,统计元素出现的次数。
四、元组:不可变的“只读”容器
元组(Tuple)与列表非常相似,它是另一种有序序列,但核心区别在于不可变性。
4.1 元组的核心定义
元组是一种有序、不可变、可重复的容器。它的定义方式与列表类似,使用特定的符号包裹元素。
4.2 元组的核心特性
- 不可变性:这是元组与列表的最大区别。元组一旦创建,其内部的元素就不能被修改、删除或添加。这种特性保证了数据的安全性和不可篡改性;
- 有序性与可索引:虽然不可变,但它依然是有序的,可以通过索引访问元素;
- 性能优势:在某些场景下,不可变的元组比可变的列表运行效率更高。
4.3 元组的适用场景
在AI开发中,元组通常用于存储不需要修改的固定数据,比如函数的返回值、配置参数、固定的坐标点等。如果你的数据需要被保护或不希望被意外修改,优先选择元组。
五、集合:去重与逻辑运算的神器
集合(Set)是一种非常特殊的容器,它摒弃了列表的“顺序”和“重复”,引入了数学中的集合概念。
5.1 集合的核心定义
集合是一种无序、不重复、无索引的容器。它的核心作用是去重和进行集合间的运算。
5.2 集合的核心特性
- 唯一性:集合中自动去重,同一个元素只会出现一次。这是它最强大的功能,在AI数据处理中,用于快速去重、统计唯一样本非常高效;
- 无序性:集合中的元素没有固定的顺序,因此不支持索引操作;
- 确定性:集合中的元素必须是不可变的(不能是列表、字典等容器)。
5.3 集合的常用操作
- 添加与删除:可以向集合中添加元素(自动去重),也可以删除元素;
- 集合运算:支持求交集、并集、差集等逻辑运算。例如,求两个样本集合的交集(共同出现的样本),或者求并集(合并所有样本),是AI数据分析中的高频操作。
六、字典:键值对映射的查询容器
字典(Dictionary)是Python中效率极高的映射类型容器,与之前的序列型容器(字符串、列表、元组、集合)完全不同,它通过“键”来查找“值”。
6.1 字典的核心定义
字典是一种键值对(Key-Value)的集合。每一个元素都是一个键值组合,通过唯一的“键”,可以快速定位到对应的“值”。
6.2 字典的核心特性
- 键的唯一性:字典中的键必须是唯一的,不能重复;
- 值的任意性:字典中的值可以是任何数据类型;
- 可变性:字典是可变的,可以随时添加、修改、删除键值对;
- 极速查询:基于哈希表实现,查询速度极快,无论字典有多少个元素,查找一个值的时间几乎是固定的。
6.3 字典的常用操作
- 增删改:可以轻松地添加新的键值对、修改已有键对应的值、删除指定的键值对;
- 键值遍历:可以分别获取字典中的所有键、所有值,或者遍历所有键值对;
- 键值查找:通过键直接获取值,是实现快速数据映射的核心工具。在AI开发中,常用于存储配置信息、标签与ID的映射关系等。
七、逻辑图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)