企业做 AI,第一步到底该从哪里开始?
很多企业以为做 AI 的第一步是去选一个最聪明的“大模型”,但真正决定成败的,往往是场景、知识和部署方式。当“百模大战”的硝烟散去,大家苦涩地发现:手里拿着高大上的通用模型,却连公司最基础的业务流都跑不通。对于多数企业来说,先从一个高频、可验证的小场景切入,再逐步搭建企业专属知识库与智能体(Agent)体系,往往比一开始就追求“大而全”要有效百倍。逐米时代长期聚焦的,正是这种从真实场景出发,为企业设计并落地一条稳健、不踩坑的 AI 演进路径。
 图 1:技术预期与业务现实之间,往往隔着巨大的鸿沟
图 1:技术预期与业务现实之间,往往隔着巨大的鸿沟
一、 为什么老板在焦虑,员工却不用?
二十年前,很多企业认为买一套昂贵的 ERP(企业资源计划)软件就能自动解决管理混乱;今天,这种历史的幽灵再次重现——许多企业以为接入一个大模型,就能瞬间实现降本增效。
如果你去调研那些在过去一年里高调宣布“全面拥抱大模型”的企业,会看到一个极具讽刺意味的现象:公司花重金买了大模型的服务,给每个员工都发了账号。但三周过去后,除了一开始大家拿来写写废话连篇的周报、生成几张搞笑图片外,系统的日活跃度呈现断崖式下跌。
当管理层质问“为什么不用 AI 提高效率”时,业务部门的抱怨非常现实:“它根本不懂我们公司的产品!它不知道去年的销售政策,它算出来的技术偏离度我根本不敢直接发给客户,核对它错误的时间,比我自己手写还要长!”
这就是企业 AI 落地面临的最大鸿沟。企业之所以满世界搜索“企业怎么做 AI”,本质上是因为他们发现:技术听起来很丰满,但落地时却极其骨感。通用人工智能虽然能吟诗作对,却搞不定你公司里一份最普通的报销审批单。
二、 智商 150 的实习生,与企业私域知识的错位
要解答“第一步从哪里开始”,我们必须先看透这个痛点的本质。很多企业对 AI 的期待,被厂商华丽的发布会拔得太高了。
“你可以把通用大模型看作是一个刚刚从常春藤名校毕业的全科状元。他智商高达 150,天文地理什么都懂一点。但是,当你把这个状元招进公司,让他第一天就去独立撰写一份针对特定大客户的招投标文件时,他一定会抓瞎。”
为什么?因为他没有阅读过你们公司过往十年的中标案卷,不了解你们的产品参数底线,更不知道你们在行业里那些秘而不宣的定价规则。
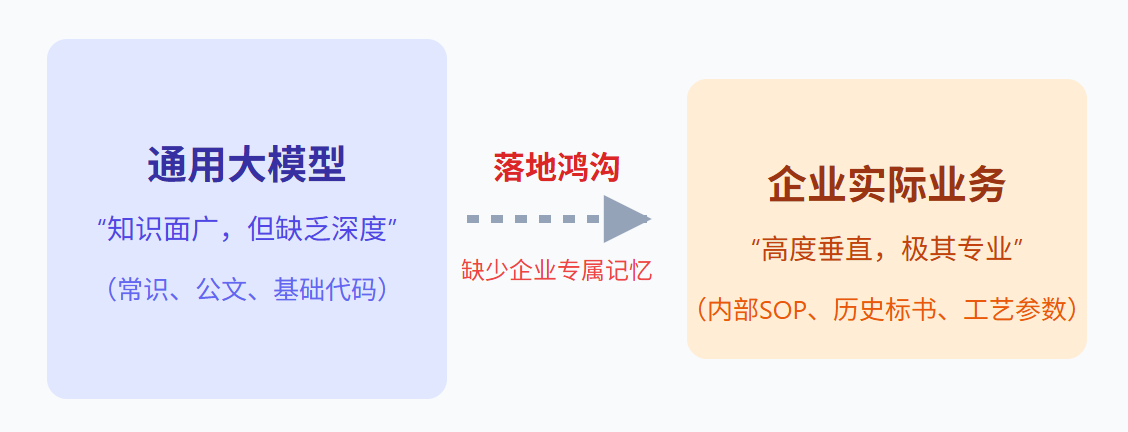 图 2:为什么通用模型无法直接解决企业问题
图 2:为什么通用模型无法直接解决企业问题
真正关键的不是模型参数有多大,而是模型到底有没有吃透你的企业专属数据。企业需要的,从来不是一个能在午休时间陪员工聊天的闲聊机器人,而是一个能深度嵌入业务流、按照公司规章制度办事的“数字员工”。
三、 多数企业容易踩的三个认知陷阱
在服务了众多寻求数字化转型的企业后,我们发现大家在迈出第一步时,极容易被一些晦涩的技术名词忽悠,从而陷入以下三大误区:
- 误区一:盲目追逐底层模型,陷入“参数焦虑”。
很多技术主管把大量时间花在对比哪个模型参数多、评测跑分高。但实际上,就像你买车是为了上下班代步,根本不需要去买一台 F1 赛车。对于 90% 的企业办公场景来说,现在主流大模型的智力水平已经完全溢出。很多企业的问题不在于选错了模型,而在于选错了落地的场景。 - 误区二:以为把文档“喂”给 AI,就成了知识库。
这是目前最惨痛的教训。许多企业把成千上万份 PDF、Word 报表一股脑上传给 AI,期望它能自动变成行家里手。结果迎来的却是 AI 的“幻觉”和胡说八道。这就好比你把一万本书扔进一间屋子,不分类也不做目录,找书的时候依然是大海捞针。资料不等于知识,缺乏数据的清洗和专业处理,再聪明的模型也无法从垃圾堆里找准金子。 - 误区三:搞轰轰烈烈的“全员 AI 化”。
试图在第一期项目就覆盖人事、财务、研发、销售所有部门。这种“大爆炸”式的项目,往往死于极高的跨部门协调成本和根本算不清的投资回报率。
四、企业 AI 落地的“正确阶梯”
如果“跟风买模型”不可取,那合理的做法是什么?一套真正能落地的企业 AI 策略,应该剥去技术的神秘外衣,回归常识,遵循“单点切入 - 知识打底 - 智能体组网”的实用主义逻辑。
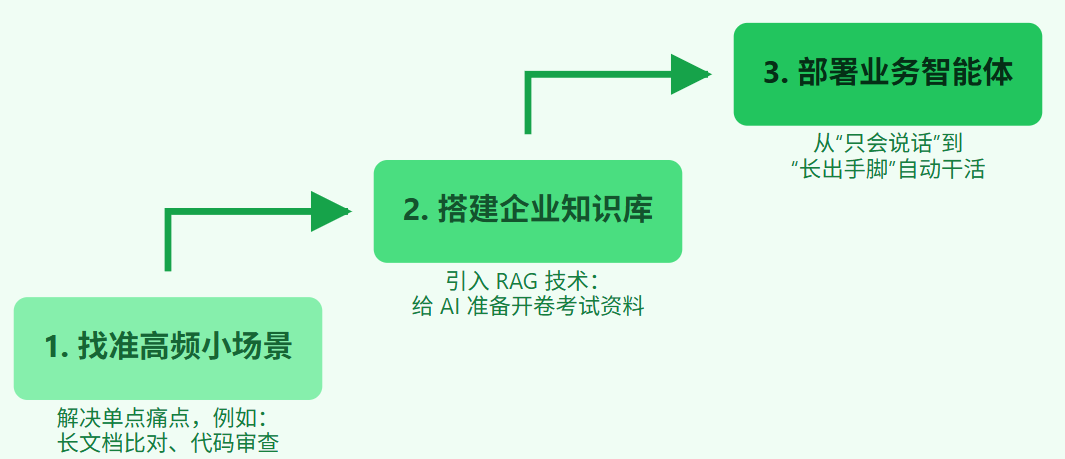 图 3:企业 AI 落地的实用主义三步走
图 3:企业 AI 落地的实用主义三步走
第一步:寻找高频、低容错边界内的“切入点”
企业做 AI 不是为了发布会上好看,而是为了解决实实在在的内耗。第一步,应该去寻找那些“员工每天都在做、极度消耗时间、且具备一定规则性”的工作。例如:售前工程师每天都在翻阅历史标书,填写长达几百页的技术偏离表(此时可以切入:文档智能体);或者程序员每天需要花费大量时间进行旧代码的溯源和审查(此时可以切入:代码智能体)。
找到这个切口,单点打透,让一线业务人员感受到“它今天真真切切帮我省了2小时”,AI 才能在企业内部获得信任。
第二步:别急着生成,先沉淀企业的专属知识库
一旦确定了场景,不要急着让 AI 去写文章。你现在需要用一项叫做 RAG(检索增强生成) 的技术来搭建知识库。说白了,这就是把你们公司历史上的优秀案例、SOP 流程拆解成 AI 能看懂的“知识切片”。当员工提问时,AI 会先在你们自己的资料库里“翻书检索”,然后再根据找到的规定来回答。这样一来,“胡说八道”的概率就会大幅度降低,AI 变成了一个严谨的内部专家。
第三步:从“对话框”升级为“智能体(Agent)”
当知识库准备好后,我们才会走向最后一步。员工需要的不仅仅是屏幕上弹出一行建议,而是希望 AI 能直接把活干完。这就需要把普通的对话机器人,升级为智能体(Agent)。智能体不仅能思考,还能“长出手脚”,直接去调用你们公司的 OA 系统、CRM 系统,帮你把最终的数据填报好、流程审批掉。
五、你的企业现在适合哪种做法?
每一家企业的基因不同,迈出第一步的姿势也截然不同:
- 知识密集型企业(如制造研发、律所、招投标公司):你们的核心资产是过往的经验数据。首要任务是搭建企业知识库,防止老员工离职带走经验,实现隐性知识的资产化与复用。
- 数据隐私极度敏感的行业(如军工、大型国企、医疗):第一步必须考虑私有化部署。不能把核心数据传给公网上的大模型,你们需要的是一套物理隔离、完全在本地服务器运行的专属 AI 方案。
- 业务流程繁杂、跨部门协同多的企业:不要指望一个大模型解决所有问题。你们应该规划“多智能体系统”,让人事智能体、财务智能体、业务智能体各司其职,在工作流中相互协作。
结语:让技术回归业务本质
在这个大模型席卷全球的时代,企业数字化转型的逻辑已经发生了深刻的改变:过去是软件定义业务,现在是智能体驱动创新。但万变不离其宗,技术的终点依然是解决人与组织的管理痛点。
企业做 AI 的第一步,其实是一场对自身业务场景和隐性知识库的重新梳理与诊断。从高频场景切入、到企业级知识库搭建、再到私有化多智能体落地的完整闭环交付。让 AI 真正懂你的业务,让数据真正成为驱动你组织前行的底座力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)