告别离散网格:InfiniDepth用神经隐式场重新定义深度估计
论文信息
-
标题:InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
-
作者:Hao Yu*, Haotong Lin*, Jiawei Wang*(共同一作), Jiaxin Li, Yida Wang, Xueyang Zhang, Yue Wang, Xiaowei Zhou, Ruizhen Hu, Sida Peng†
-
机构:浙江大学、理想汽车(Li Auto)、深圳大学
-
arXiv: 2601.03252(2026年1月)
-
项目页面:https://zju3dv.github.io/InfiniDepth/
-
代码:https://github.com/zju3dv/InfiniDepth (Apache-2.0)
亮点
-
首次将神经隐式场引入单目深度估计,深度不再是像素格点上的离散值,而是连续2D坐标到深度值的隐式函数,天然支持任意分辨率输出
-
多尺度局部隐式解码器仅15M参数,从DINOv3 ViT-Large的不同层构建特征金字塔,双线性插值+层级门控融合,同类最轻量却达到SOTA
-
Infinite Depth Query策略根据每个像素对应的3D表面微元自适应分配子像素查询预算,生成均匀分布的3D点云,大视角变化下的新视角合成质量显著改善
-
构建Synth4K基准(5款游戏、4K分辨率RGB-D数据+高频掩码),填补高分辨率深度估计评测空白
-
Synth4K上全面超越DepthAnything V2、MoGe-2、Marigold、PPD等方法,高频细节区域δ₁领先5-8个百分点;真实数据集上与SOTA持平
一、高分辨率深度图的细节,其实不好
单目深度估计这两年进步飞快。DepthAnything系列、MoGe系列、Marigold、PPD,KITTI和NYUv2上的指标快卷到饱和了。
但有一件事被反复忽视:放大来看,高分辨率深度图的几何细节并不好。
很多方法能输出4K的深度图,表面看起来精细。真正用到三维重建和新视角合成里,物体边缘发虚,细小结构对不齐。自动驾驶里更直接——路缘、护栏、交通标志杆这些高频几何结构预测错了,障碍物边界判断直接出问题。
原因不复杂。现有方法都在固定分辨率的离散像素格点上预测深度。想要更高分辨率?插值放大。这就是在放大误差。
两个结构性缺陷:
-
卷积上采样天然平滑。低分辨率feature map到高分辨率深度图,卷积操作会抹平高频细节。
-
线性投影缺乏局部感知。从latent直接投影到depth patch,全局统一的映射关系不足以表达局部几何的复杂变化。
问题不在模型不够大、数据不够多,在于深度的表示方式本身。
二、把深度变成连续函数


三个直接好处:
-
不受训练分辨率约束。504×672上训练,推理时直接在4K甚至16K坐标位置查询深度,不做任何后处理上采样。
-
局部化预测。每个坐标的深度从局部邻域特征解码,天然擅长捕捉局部几何变化。
-
完全可微。连续隐式场支持autograd直接计算表面法向量,后面会讲到这在Infinite Depth Query里有用。
三、多尺度局部隐式解码器
网络结构很简洁,两个模块:特征查询和深度解码。
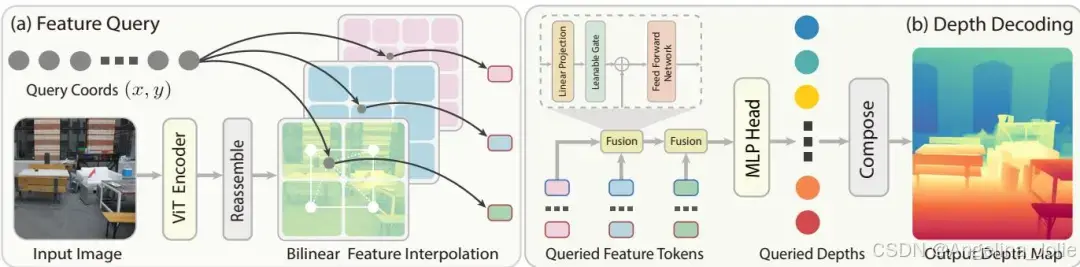
3.1 特征查询
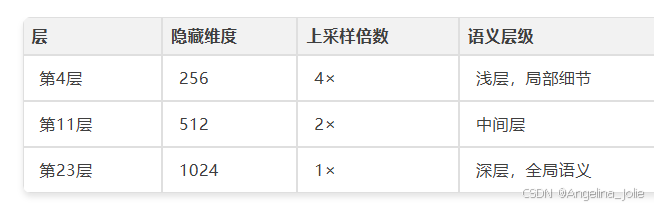
编码器是DINOv3 ViT-Large——Meta AI 2025年8月发布,67亿参数教师模型在17亿无标注图像上训练,核心创新Gram Anchoring解决长训练中密集特征退化问题。InfiniDepth用的是蒸馏后的ViT-Large。
从第4、11、23层分别提取特征token,投影到不同隐藏维度:

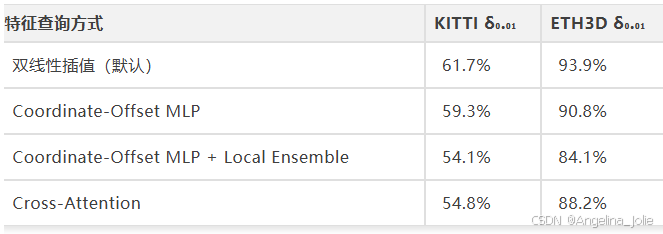
双线性插值最少计算、最少参数、最好性能。更复杂的方案反而不如它。
说明核心价值在多尺度特征金字塔本身的信息质量,不在查询机制的花哨程度。
3.2 深度解码

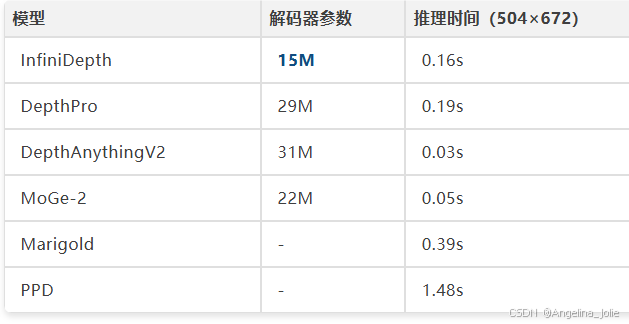
速度慢于DepthAnythingV2和MoGe-2——但这两者卷积解码器的细节捕捉能力明显弱。和同样追求细粒度的DepthPro、Marigold、PPD比,InfiniDepth快不少。
四、Infinite Depth Query:让点云不再稀疏
InfiniDepth的另一个贡献面向下游新视角合成(NVS)任务。
4.1 逐像素反投影的密度灾难
把深度图反投影到3D空间,点云密度严重不均。两个几何因素:
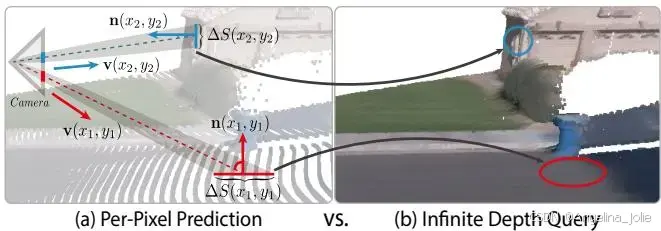
深度平方缩放。远处像素覆盖的3D表面面积 。深度从10米到100米,面积差100倍。
表面朝向效应。法向偏离视线时,每像素覆盖的实际面积更大。极端情况下一个像素覆盖一大片。
结果就是远处和倾斜表面极其稀疏,近处正对的区域过度密集。高斯散射渲染大视角变化,孔洞和伪影跑不掉。
4.2 自适应子像素查询


上图是通过autograd算出的法向图,内部几何细节非常清晰。这是连续表示的附加价值。
4.3 采样流程

五、训练细节
5.1 纯合成数据
全部使用合成数据训练。真实数据集的深度标注含噪且不完整,和InfiniDepth追求的细粒度精度目标矛盾。
训练集包括Hypersim、VKITTI、TartanAir、IRS,高分辨率数据集UnrealStereo4K、UrbanSyn,以及MatrixCity、MVS-Synth、BlendedMVS、CREStereo、FSD、DynamicReplica。
5.2 子像素监督
隐式表示带来一个巧妙的训练trick。
传统方法把输入图像和GT深度图resize到同一分辨率逐像素对齐。InfiniDepth不这么做——输入RGB图像resize,但GT深度图保持原始高分辨率。

5.3 深度归一化

六、Synth4K基准
现有真实数据集(KITTI、NYUv2、ScanNet)的深度GT分辨率低、稀疏,根本没法评估细粒度几何恢复能力。InfiniDepth构建了Synth4K填补这个空白。
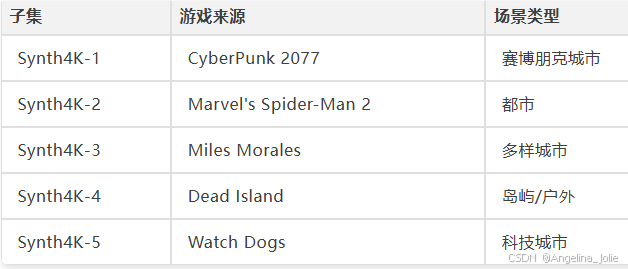

3840×2160(4K),用ReShade从游戏渲染管线采集RGB和深度buffer,五款游戏覆盖多种室内外场景。
还构建了高频掩码(HF mask):多尺度高斯模糊 → 绝对拉普拉斯响应 → 逐像素取最大值 → 98%分位归一化 → 温度锐化 → 概率采样。这个掩码标出几何变化剧烈的区域——边缘、棱角、细小结构——单独评测细节恢复能力。
七、实验
7.1 Synth4K相对深度
所有方法输入504×896,baseline输出双线性插值上采样到4K,InfiniDepth直接在4K坐标查询。
全图:五个子集全面领先。
-
• Synth4K-1: δ₁=89.0%(vs DepthAnything 83.8%, MoGe-2 84.2%)
-
• Synth4K-3: δ₁=93.9%(vs 最佳baseline 88.6%)
-
• Synth4K-5: δ₁=96.3%(vs 最佳baseline 93.0%)
更严格的δ₀.₅指标差距更大——Synth4K-5: 88.5% vs MoGe-2 80.7%。
高频细节区域——这才是这篇文章真正要看的东西。所有方法高频区域性能大幅下降,InfiniDepth下降最小:
-
• Synth4K-1 高频: δ₁=67.5% vs MoGe-2 66.5% vs DepthAnything 61.3%
-
• Synth4K-3 高频: δ₁=69.0% vs MoGe-2 63.4%
-
• Synth4K-5 高频: δ₁=79.5% vs MoGe-2 77.3% vs PPD 70.1%
领先5-8个百分点,细节区域优势比全图更明显。连续深度表示的价值就在这里。

定性比较看得更直观。Synth4K数据里,DepthAnythingV2和PPD的边缘发虚、结构模糊。InfiniDepth在细节区域直接在目标分辨率预测,不需要上采样。
7.2 真实数据集相对深度
五个真实数据集zero-shot评估:
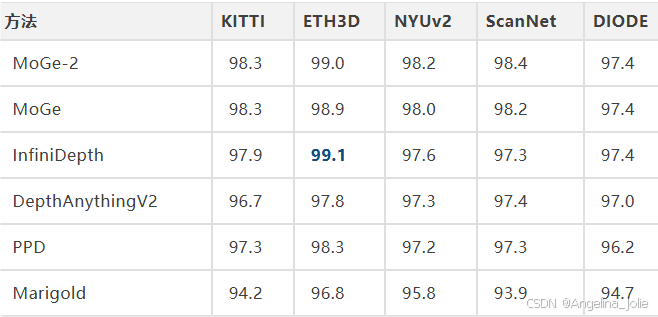
和MoGe-2基本持平,ETH3D上微幅领先(99.1% vs 99.0%)。
坦白说,这些数据集的GT深度本身分辨率低且稀疏,δ₁指标已经饱和(全在97%以上),分辨率和细节上的差距根本体现不出来。Synth4K存在的意义就在这里。
InfiniDepth完全合成数据训练,真实数据零样本泛化不打折扣,连续表示没有对泛化产生负面影响。
7.3 度量深度
结合1500个稀疏深度采样点做度量深度估计,InfiniDepth的优势更突出。
Synth4K全图:
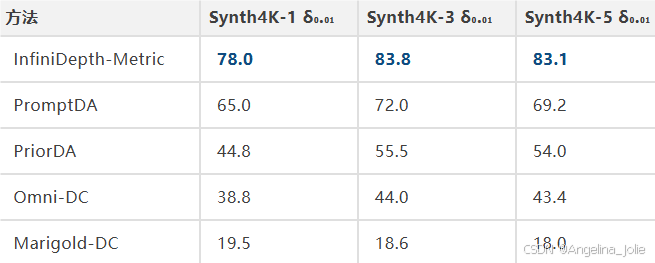
领先PromptDA 13-15个百分点。两个工作共享一位一作Haotong Lin,InfiniDepth-Metric直接用了PromptDA的深度提示模块,区别在于把下游的离散网格深度换成了隐式场深度——这个对照非常干净。
高频区域差距更大。Synth4K-3高频: 37.2% vs PromptDA 24.7%。
真实数据集:
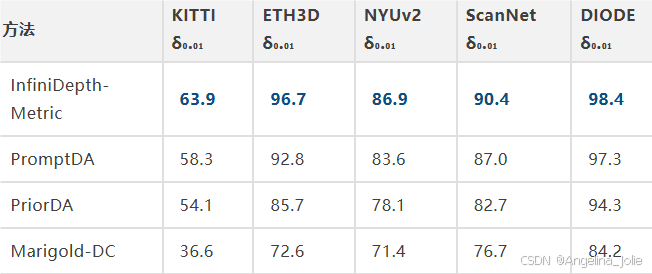
全面超越。
为什么度量深度的提升比相对深度明显得多?稀疏深度输入大幅减少了歧义性,此时细粒度几何恢复能力成为决定性因素。相对深度因为缺尺度约束不确定性高,指标趋近饱和,表示方式的差异被掩盖。
7.4 消融
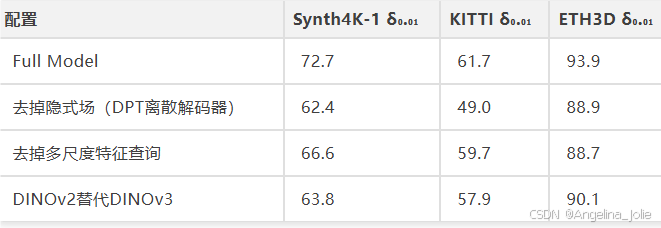
三条结论:
-
隐式场是最大因素。换成DPT离散解码器(同编码器、同数据),度量深度直降8-12个百分点。
-
多尺度查询有实质贡献。只用单层feature map,性能一致下降。
-
DINOv3 > DINOv2。同为ViT-Large,DINOv3在度量深度上提升明显。

定性消融也很清晰——去掉隐式场,物体边缘和细小结构的深度立刻模糊。
八、NVS应用:大视角变化
InfiniDepth + Infinite Depth Query在单视角新视角合成上的效果
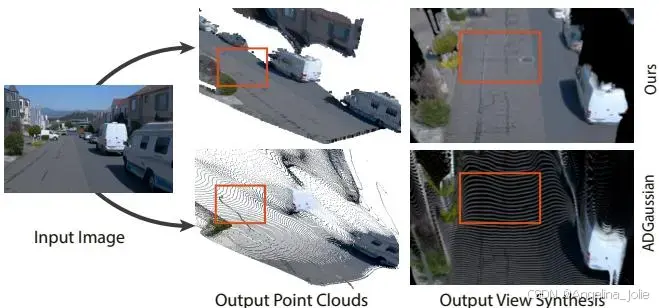
ADGaussian是自动驾驶场景SOTA前馈NVS方法,预测像素对齐深度和高斯参数。大视角变化(鸟瞰)下,几何孔洞和伪影跑不掉。
InfiniDepth的流程:Infinite Depth Query生成均匀3D点 → 提取颜色+Plücker射线特征 → 结合ViT编码器特征 → MLP+线性头预测高斯属性(位置偏移、颜色偏移、尺度、不透明度、旋转)→ 高斯散射渲染。
对比结果:InfiniDepth的NVS在大视角偏移下更完整,孔洞和伪影大幅减少。均匀点云保证了每个表面区域有足够高斯覆盖。
九、竞争格局
梳理一下InfiniDepth面对的竞争环境。
DepthAnything系列(Lihe Yang et al.)。V1用62M无标注数据提升泛化,V2改用合成数据训教师+大规模伪标签训学生。速度极快(0.03s),但卷积解码器限制细节。
MoGe系列(Microsoft)。仿射不变点图+最优训练监督,MoGe-2加入度量尺度和细节恢复。0.05s,真实数据集上很强。
Marigold(ETH Zurich, CVPR 2024 Oral)。Stable Diffusion视觉先验做深度估计。VAE编码引入量化损失,推理0.39s。
PPD(HUST/小米/浙大, NeurIPS 2025)。像素空间扩散避免VAE量化损失,语义提示DiT+级联DiT。质量好但推理1.48s。
DepthPro(Apple)。多尺度ViT,零样本度量深度,0.3s处理2.25M像素。
PromptDA(浙大/NUS, CVPR 2025)。低成本LiDAR深度提示引导DepthAnything做度量深度,支持4K。InfiniDepth-Metric正是基于PromptDA的深度提示模块。
上面这些方法,回归、扩散、点图,走的路线各不相同,但共同点是都在离散网格上输出深度。InfiniDepth改变的是表示本身——从离散到连续。这个改变正交于模型容量和训练数据,理论上可以和任何backbone组合。
十、局限与思考
论文指出两个局限:没有时序一致性(单帧处理,视频应用会闪烁);只用了单视图深度数据(扩展到多视图有望改善3D一致性)。
从个人角度看,还有几个问题值得想。
训练和推理分辨率的gap。模型在504×672上训练,特征提取分辨率就那么大。推理在4K坐标查询,本质上是在低分辨率特征上做高精度插值。Synth4K的结果说明效果好,但更极端的倍数(16K、32K)下是否退化?还不清楚。
实时性。0.16s/帧,自动驾驶要求30fps以上(<33ms/帧),差了一个量级。隐式解码逐点查询,batch化和算子优化的空间有多大?工程落地绕不开这个问题。
和扩散方法的正交性。InfiniDepth是判别式方法(ViT+隐式解码),PPD是生成式路线(像素空间扩散)。一个解决分辨率扩展和几何细节,一个解决边界锐度和不确定性。隐式连续表示+扩散生成——一个可能有意思的方向。
总结
InfiniDepth做的事情概括起来就一个:把深度从像素格点上的值变成连续坐标上的函数。表示层面的改变带来两个直接后果:分辨率不再受限,细节恢复质量大幅提升。加上Infinite Depth Query对下游3D应用的增益、Synth4K对评测的完善,整体工作从问题定义到实验评估都做得很扎实。高分辨率深度图的细节为什么总是不好?答案很直接——因为你在用离散网格表示一个连续的深度场。InfiniDepth换了一种表示方式,问题就解了大半。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)