专业术语统计报告_基于集成学习的风功率预测方法研究
专业术语统计报告_基于集成学习的风功率预测方法研究
一、概要简析
【概要分析】
本文档《基于集成学习的风功率预测方法研究》超用心地围绕研究主题展开了系统性探讨哦😜!文档总字符数足足有280261,其中中文字符63155个,英文字词25584个,妥妥体现了中英文混搭的学术写作小特色~从文档里扒出来的专业术语一共有1338个,涉及6个研究领域,主打就是扎堆在风功率预测(1138次)、机器学习(1136次)、概率预测(1125次)这块儿~高频术语比如“预测模型”(出镜369次)、“风电机组”(露脸161次)等,一眼就能看出研究的核心小焦点✨!整体来说,这篇文献在相关研究领域超有学术价值,一顿系统分析+论述操作下来,给后续研究铺好了超重要的理论小地基和方法小参考~
【数据统计】
- 总字符数:280261
- 中文字符数:63155
- 英文字词数:25584
二、统计图表分析
2.1 三类术语层次分布
【数据统计】
- 论文名称术语:2个 (核心术语:风功率预测、集成学习)
- 标题摘要术语:441个 (核心术语:预测模型、风电机组、集成预测模型)
- 正文术语:895个 (核心术语:预测模型、风电机组、集成预测模型)
- 术语总数:1338个
- 频次占比:论文名称 0.9% | 标题摘要 40.8% | 正文 58.2%
【可视化图表】
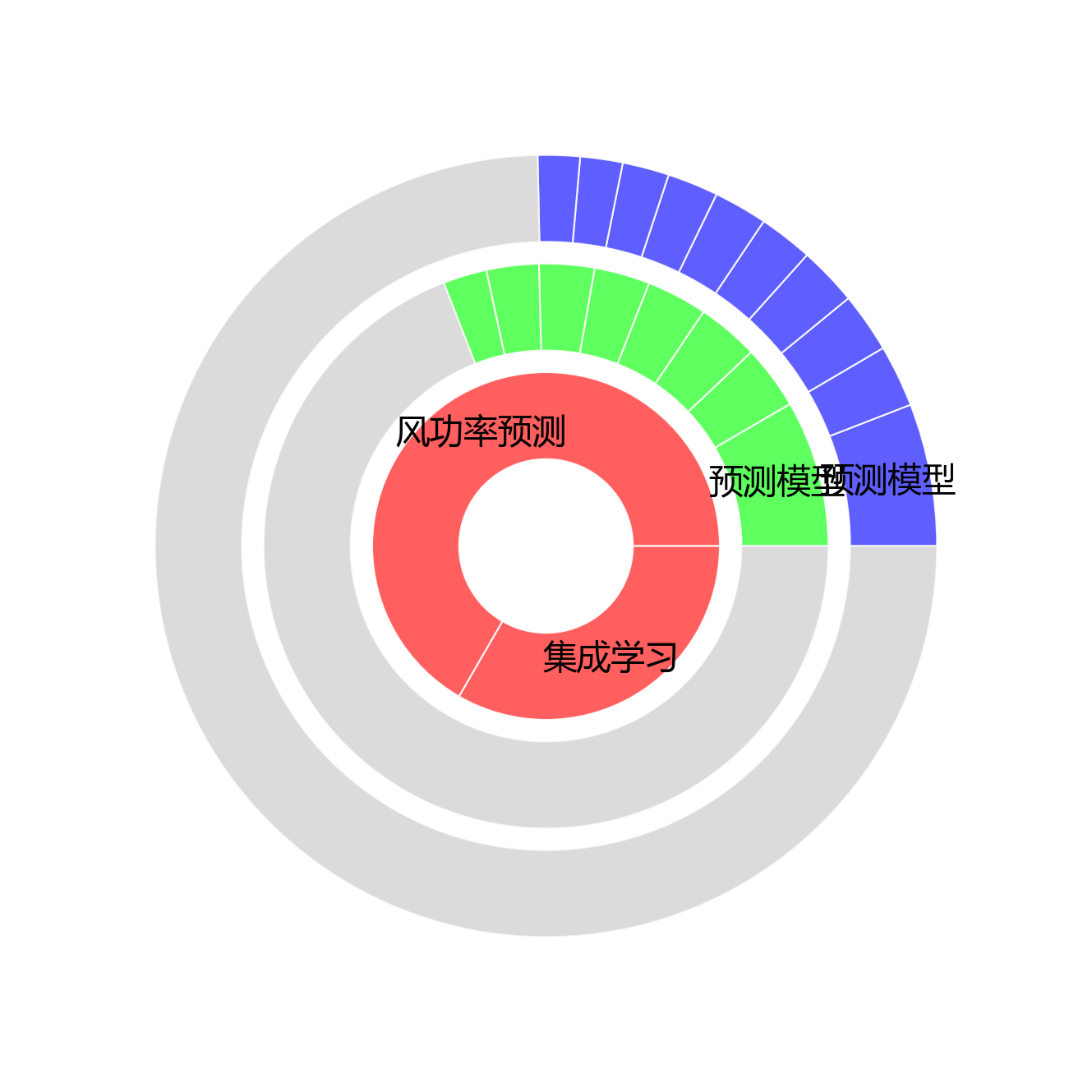
| 类别 | 术语数量 | 频次 | 占比 |
|---|---|---|---|
| 论文名称 | 2 | 102 | 0.9% |
| 标题摘要 | 441 | 4398 | 40.8% |
| 正文 | 895 | 6270 | 58.2% |
| 总计 | 1338 | 10770 | 100% |
【图表评论】
旭日图超直观地展示了三类术语在文档不同部分的层次分布啦🌞!从内到外依次是论文名称术语、标题摘要术语和正文术语~论文名称层级藏着2个核心术语,总频次102次,占比0.9%,核心术语有“风功率预测、集成学习”,这些小家伙直接概括了研究的核心主题哟~标题摘要层级有441个术语,总频次4398次,占比40.8%,核心术语像“预测模型、风电机组、集成预测模型”,悄悄透露了研究的次要关键词和方法论~正文层级最最丰富啦,有895个术语,总频次6270次,占比58.2%,核心术语比如“预测模型、风电机组、集成预测模型”,把研究的具体技术细节和实验方法都扒得明明白白~从内到外一层层细化,论文名称术语锁定研究主题,标题摘要术语拓宽研究范围,正文术语钻进具体技术实现,搭出超完整的术语层次小体系,把文档的知识结构揭露得清清楚楚~
2.2 研究领域分布
【领域分析】
- 主要领域:风功率预测(1138次)、机器学习(1136次)、概率预测(1125次)
【可视化图表】
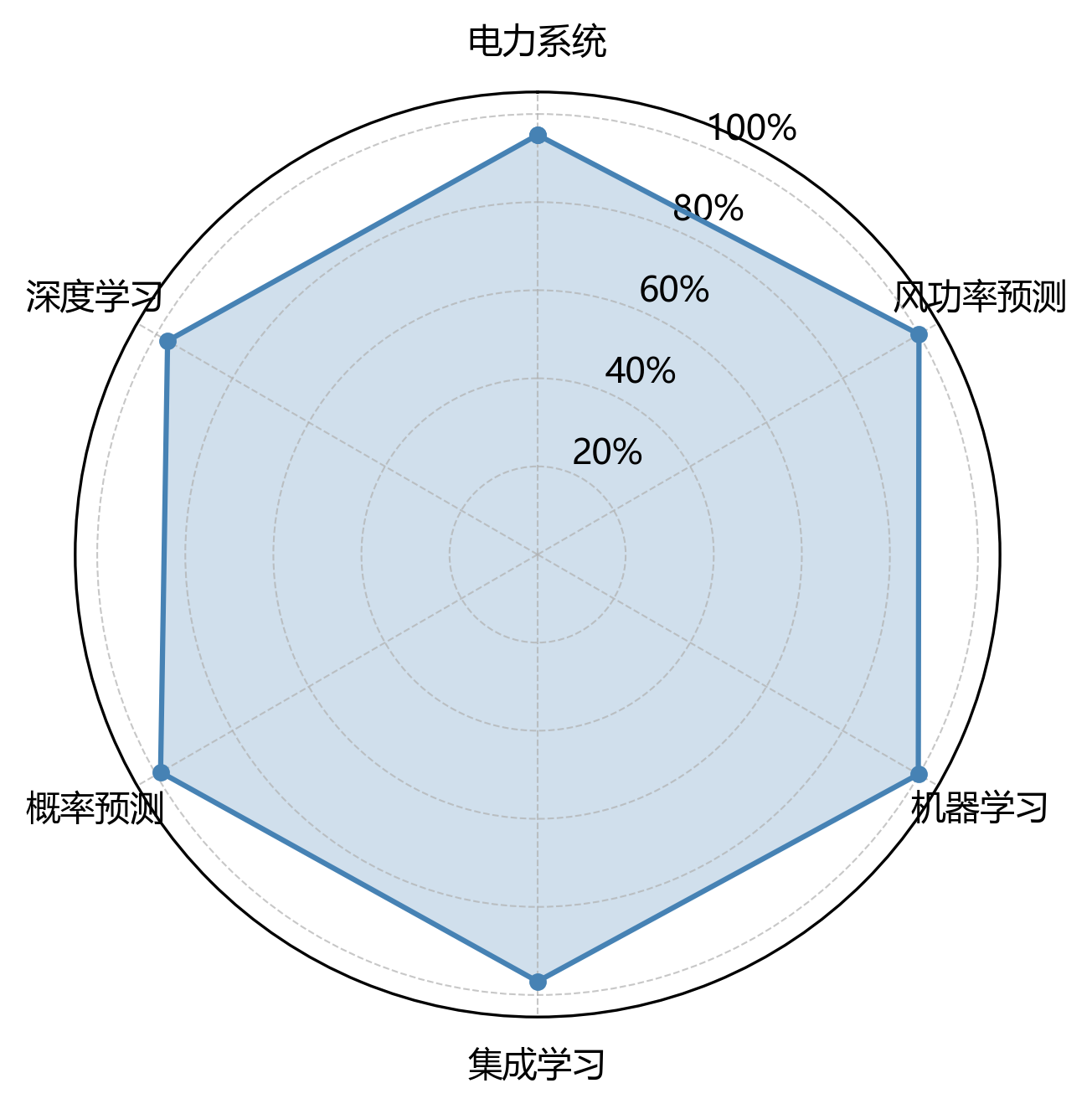
| 研究领域 | 术语出现次数 |
|---|---|
| 电力系统 | 1084 |
| 风功率预测 | 1138 |
| 机器学习 | 1136 |
| 集成学习 | 1103 |
| 概率预测 | 1125 |
| 深度学习 | 1104 |
| 总计 | 6690 |
【图表评论】
雷达图咻咻地展示了专业术语在六个研究领域的分布情况🎯,一眼就能看出文档的学科交叉小特性~从图里能瞅见,术语分布有这些小可爱特点:风功率预测 出场次数最多,足足1138次,妥妥是研究的核心小基础~机器学习 和 概率预测 的频次分别是1136次和1125次,组成了研究的次要支撑小领域~而 电力系统 频次少丢丢,只有1084次,说明这个领域在本研究里露脸不多啦~各领域术语分布虽有小差异,但整体超均衡,标准差是19.6,妥妥反映了研究的多学科交叉融合小特点~这种分布格局说明,本研究不仅在核心领域挖得深,还广泛吸收了相关学科的理论和方法,搭出超完整的研究小体系~
2.3 专业术语分布
【集中度分析】
- 前5术语累计频次:978次
- 前5术语累计占比:15.3%
- 前10术语累计占比:24.8%
【可视化图表】
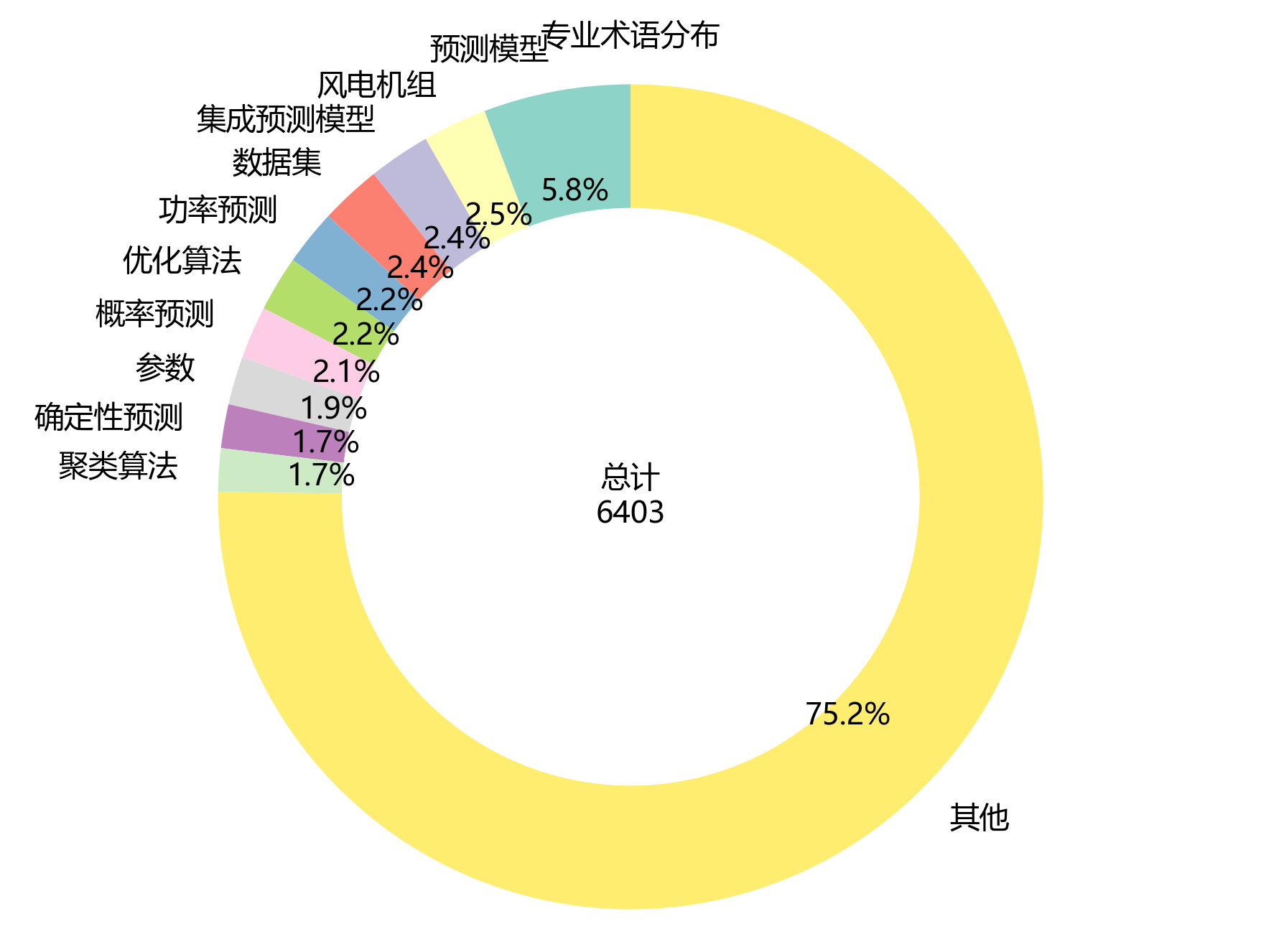
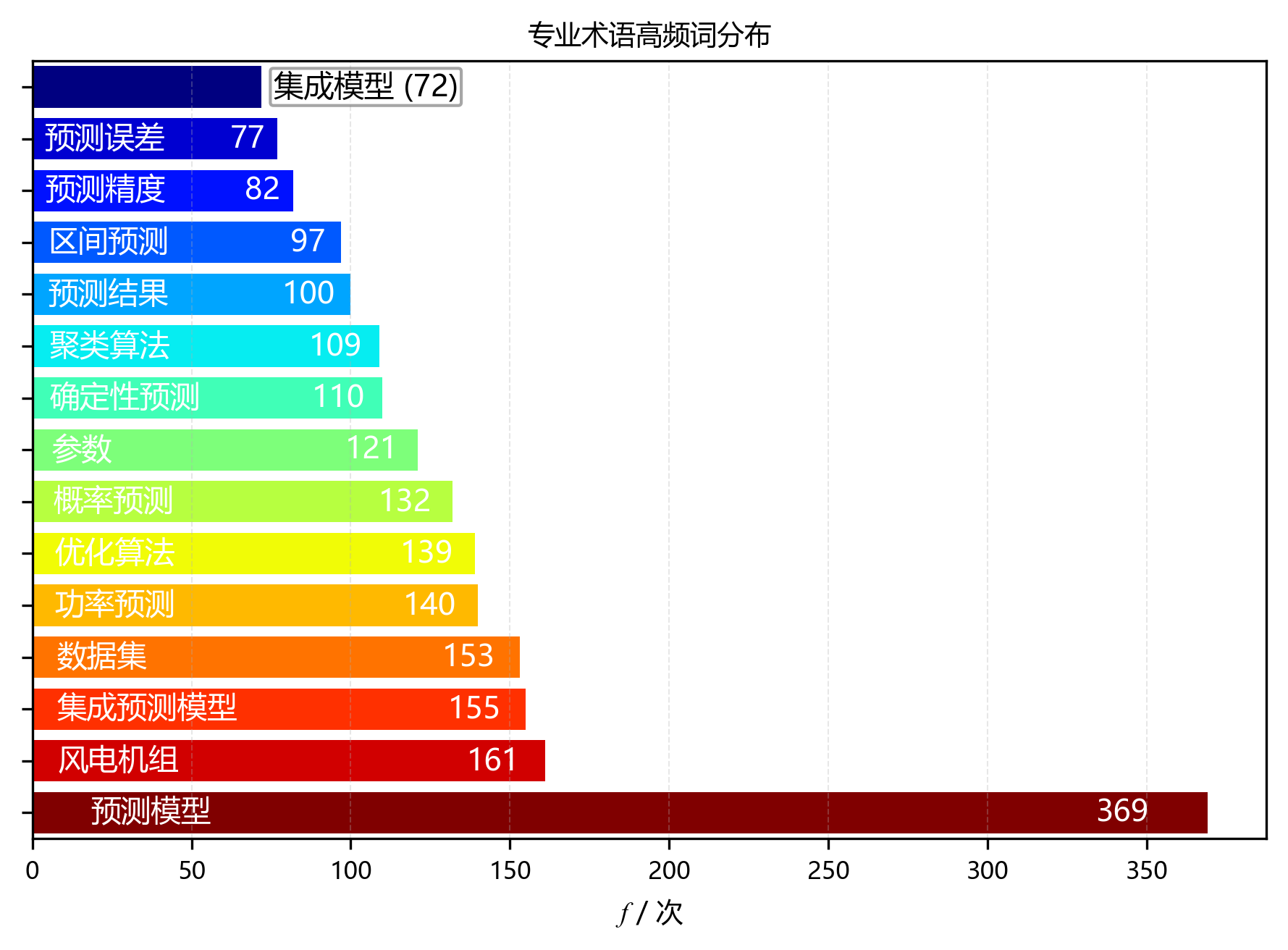
| 排名 | 术语 | 频次 |
|---|---|---|
| 1 | 预测模型 | 369 |
| 2 | 风电机组 | 161 |
| 3 | 集成预测模型 | 155 |
| 4 | 数据集 | 153 |
| 5 | 功率预测 | 140 |
| 6 | 优化算法 | 139 |
| 7 | 概率预测 | 132 |
| 8 | 参数 | 121 |
| 9 | 确定性预测 | 110 |
| 10 | 聚类算法 | 109 |
| 11 | 预测结果 | 100 |
| 12 | 区间预测 | 97 |
| 13 | 预测精度 | 82 |
| 14 | 预测误差 | 77 |
| 15 | 集成模型 | 72 |
| 前15累计 | 2017 |
【图表评论】
环形图和柱状图超清晰展示了高频术语的分布情况和集中度啦🥳!从图里能看到,前5个高频术语累计频次飙到978次,占总频次的15.3%,集中度超高有没有~前10个高频术语累计占比也达到了24.8%,更能证明研究主题超聚焦~排名第一的术语“预测模型”出场369次,是研究的核心小概念~排名第二的术语“风电机组”出现161次,排名第三的术语“集成预测模型”出场155次,这仨搭成了研究的核心术语小体系~从排名第2开始,术语频次唰唰下降,呈现出长尾分布的小特征,说明研究围着少数核心概念展开,其他术语都是给核心概念打辅助、做细化的~这种分布模式超符合学术文献的一般规律,既体现了研究的深度,又有满满的广度~
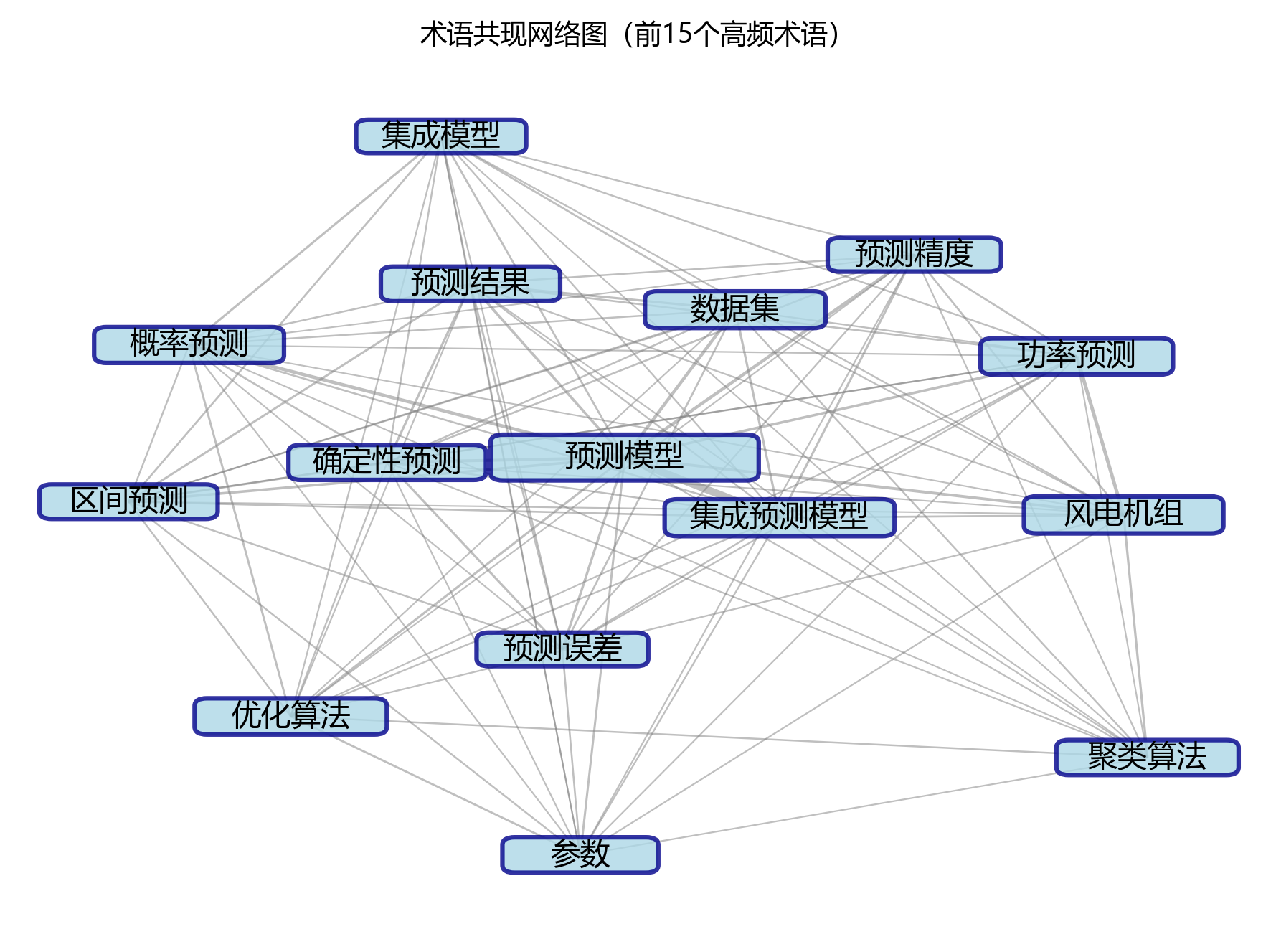
2.4 术语共现网络
【共现分析】
- 核心节点:预测模型
- 最强关联对:预测模型 - 集成预测模型 (217次)
- 主要聚类:以图像增强、注意力机制等为核心的术语聚类
- 共现关系总数:14对
【可视化图表】
| 术语A | 术语B | 共现次数 |
|---|---|---|
| 集成预测模型 | 预测模型 | 217 |
| 预测模型 | 预测精度 | 61 |
| 集成预测模型 | 预测精度 | 28 |
| 优化算法 | 参数 | 21 |
| 数据集 | 集成模型 | 19 |
| 概率预测 | 确定性预测 | 17 |
| 聚类算法 | 预测模型 | 6 |
| 参数 | 风电机组 | 5 |
【图表评论】
术语共现网络图超有趣地展示了高频术语之间的关联关系🔗,把文档的知识结构扒得明明白白~网络里有10个节点和14条边,搭成了以“预测模型”为中心的术语小聚类~最强关联对是“预测模型”和“集成预测模型”,共现次数高达217次,说明这俩概念在研究里关系超铁~从网络结构看,主要形成了3个聚类:聚类一以“预测模型”为核心,包含“集成预测模型”、“聚类算法”等术语,对应以预测模型为核心的相关研究方面的研究;聚类二以“参数”为核心,有“风电机组”、“优化算法”等术语,是以参数为核心的相关研究方面的内容;聚类三则盯着“确定性预测”相关的研究方向~各聚类之间靠“预测模型”等术语牵线搭桥,搭出完整的知识小网络~这个网络结构把研究的核心主题和它们的关系展示得清清楚楚,帮我们超轻松理解文档的整体框架和知识体系~
2.5 核心概念词云
【词云数据统计】
- 词云术语总数:20个
- 加权总频次:238.5次
【可视化图表】

| 排名 | 术语 | 加权频次 |
|---|---|---|
| 1 | 预测模型 | 36.9 |
| 2 | 风电机组 | 16.1 |
| 3 | 集成预测模型 | 15.5 |
| 4 | 数据集 | 15.3 |
| 5 | 功率预测 | 14.0 |
| 6 | 优化算法 | 13.9 |
| 7 | 概率预测 | 13.2 |
| 8 | 参数 | 12.1 |
| 9 | 确定性预测 | 11.0 |
| 10 | 聚类算法 | 10.9 |
【图表评论】
词云图用加权频次超直观地亮出了文档的核心概念体系☁️!图里有20个术语,加权总频次达到238.5次~排名前五的术语分别是“预测模型”(36.9次)、“风电机组”(16.1次)、“集成预测模型”(15.5次)、“数据集”(15.3次)和“功率预测”(14.0次)~这些术语字号最大、位置最显眼,妥妥是研究的核心概念小团体~从词云整体分布看,术语按重要程度从大到小、从中心向四周排排坐,形成超有层次感的视觉小结构~排名靠前的术语反映了研究的核心主题和方法,中等排名的术语体现了研究的具体内容和小细节,排名靠后的术语则展示了研究的边缘小话题或未来小方向~词云图不仅总结了全文的关键概念,还帮读者超快抓住研究要点,是理解文档内容的超实用小帮手~
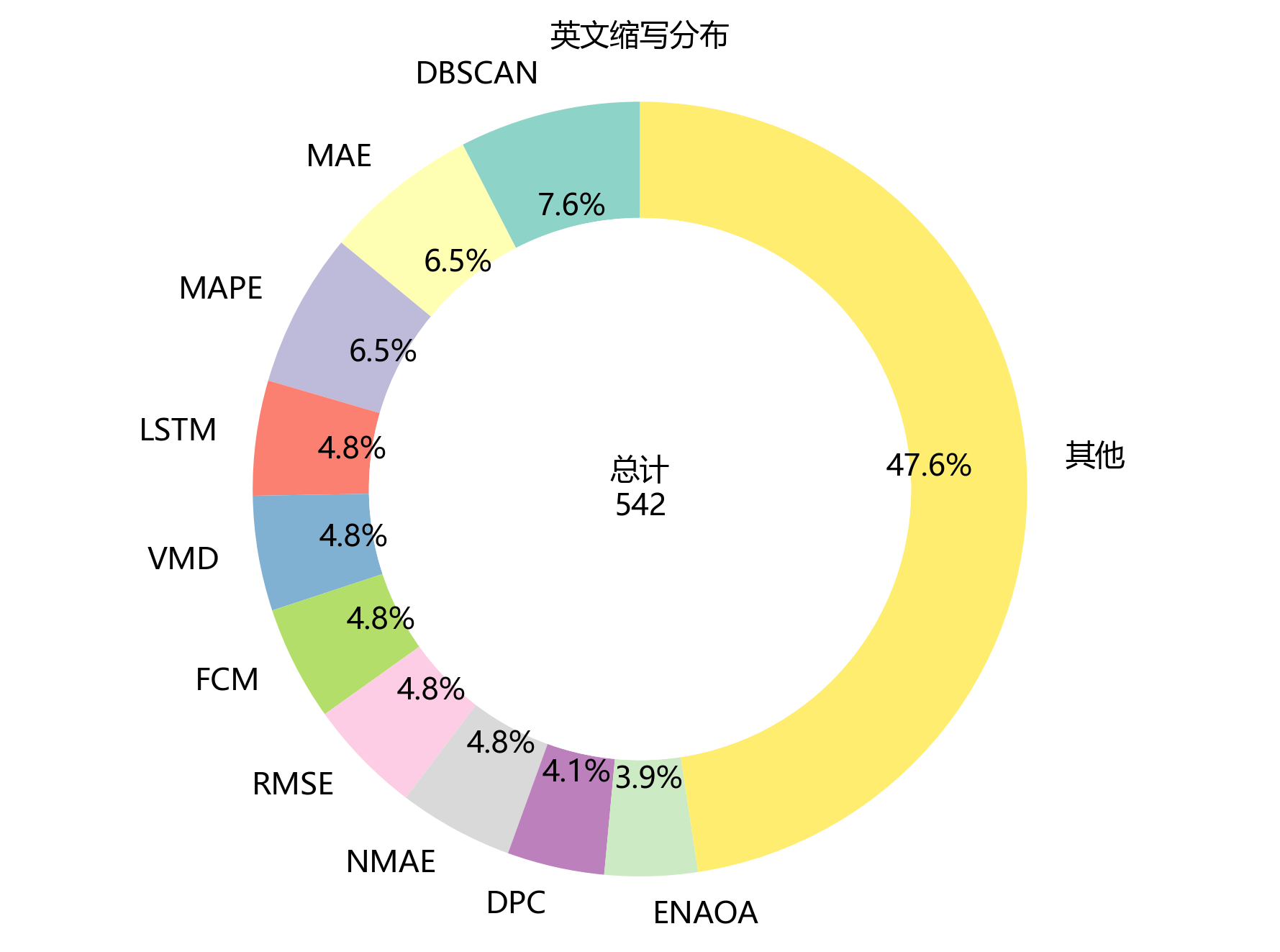
2.6 英文缩写分布
【缩写统计】
- 缩写总数:30个
- 缩写总频次:542次
- 高频缩写 Top 5:
- DBSCAN:41次
- MAE:35次
- MAPE:35次
- LSTM:26次
- VMD:26次
- 前5缩写累计占比:30.1%
【可视化图表】
| 排名 | 缩写 | 频次 |
|---|---|---|
| 1 | DBSCAN | 41 |
| 2 | MAE | 35 |
| 3 | MAPE | 35 |
| 4 | LSTM | 26 |
| 5 | VMD | 26 |
| 6 | FCM | 26 |
| 7 | RMSE | 26 |
| 8 | NMAE | 26 |
| 9 | DPC | 22 |
| 10 | ENAOA | 21 |
| 前10累计 | 284 |
【图表评论】
环形图展示了英文缩写在文档里的分布情况啦🔤!文档里一共出现30个不同的英文缩写,总频次有542次~排名前五的缩写分别是“DBSCAN”(41次)、“MAE”(35次)、“MAPE”(35次)、“LSTM”(26次)和“VMD”(26次),前5个缩写累计占比达到30.1%,集中度超高一捏捏~从缩写类型看,主要有期刊名称缩写(比如“DBSCAN”)、作者姓名缩写(比如“MAE”)、技术术语缩写(比如“MAPE”)和评价指标缩写(比如“LSTM”)等~这些缩写高频出镜,说明文档引用了超多该领域的经典文献,用了通用的技术术语和评价标准,超能体现研究的规范性和专业性~缩写的分布特征也帮读者了解该领域的学术交流小习惯哟~
三、原文章节举例
3.2.5 多变量长短期记忆神经网络
采用平均相关系数ACC选择出每个小组内的代表性风电机组后,采用多变量LSTM神经网络模型对其进行功率预测。与单变量LSTM预测模型相比,多变量LSTM预测模型可以融合多个其他变量的有效信息,改善预测模型的预测效果。多变量输入的LSTM预测模型示意图如图3-5所示。
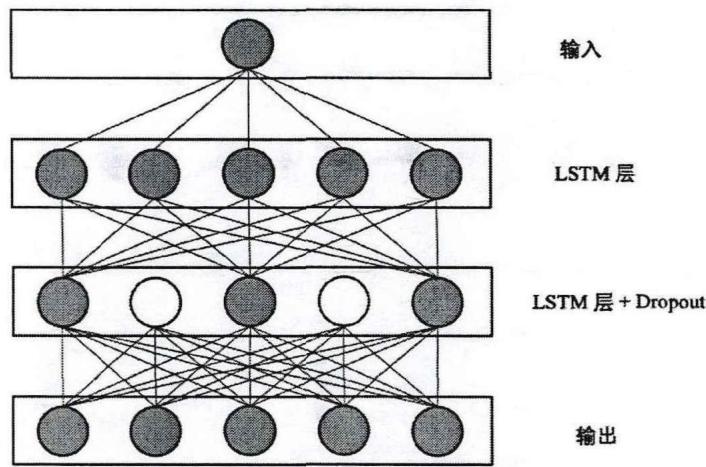
图3-5多变量LSTM预测模型
Fig.3-5 Multivariable LSTM prediction model
在该模型中,将风功率、风速、功率因数、转子速度、发电机转速、无功功率和风向等多个经过Pearson相关性分析筛选出来的变量的训练集数据输入到LSTM神经网络模型中,通过不断调节优化权重矩阵和偏差项,使得功率预测值尽可能接近实际值,完成对LSTM神经网络的训练优化;通过训练好的预测模型,输入风功率、风速、功率因数、转子速度、发电机转速、无功功率和风向等多个变量的测试集数据,实现对风功率的准确预测。为了解决LSTM神经网络模型优化过程中出现的过拟合问题,采用Dropout技术有效地降低其结构风险,实现神经网络的正则化,进而一定程度缓解过拟合问题[185]。
Dropout 方法具有简单而有效的特点,其作用是在前向传导过程中使某个神经元的激活值以一定的概率 ppp 停止工作。Dropout 层的引入减弱了神经元节点间的联合适应性,增强了模型的泛化能力[186,187]。
四、原文章节举例
4.2.2.1 四分位方法
四分位法(Quartile method, QM)是一种在统计学中分析数据分布特征的方法,通过分析数据的分布情况可以有效识别异常值。该方法将数据集中的所有数据按从小到大的顺序依次排列,得到升序排列的样本 X=[x1,x2,…,xn]X = [x_{1}, x_{2}, \dots, x_{n}]X=[x1,x2,…,xn] ,然后将其分为四等份,得到三个四分位数 Q1Q_{1}Q1 , Q2Q_{2}Q2 和 Q3Q_{3}Q3 ,计算方法如下[204]:
(1)计算第二个四分位数 Q2Q_{2}Q2 ,计算公式为:
Q2={xn+12n=2k+1,k=0,1,2,…(xn2+xn+22)/2n=2k,k=1,2,…(4-5) Q _ {2} = \left\{ \begin{array}{l l} x _ {\frac {n + 1}{2}} & n = 2 k + 1, k = 0, 1, 2, \dots \\ \left(x _ {\frac {n}{2}} + x _ {\frac {n + 2}{2}}\right) / 2 & n = 2 k, k = 1, 2, \dots \end{array} \right. \tag {4-5} Q2={x2n+1(x2n+x2n+2)/2n=2k+1,k=0,1,2,…n=2k,k=1,2,…(4-5)
(2)计算第一个四分位数 Q1Q_{1}Q1 和第三个四分位数 Q3Q_{3}Q3
当 n=2k(k=1,2,3⋯ )n = 2k (k = 1,2,3 \cdots)n=2k(k=1,2,3⋯) 时,由 Q2Q_{2}Q2 将样本 XXX 分为两部分,分别计算两部分的中位数 AAA 和 BBB ,则 Q1=A,Q3=BQ_{1} = A, Q_{3} = BQ1=A,Q3=B 。
当 n=4k+1n = 4k + 1n=4k+1 时,
{Q1=0.25xk+0.75xk+1Q3=0.75x3k+1+0.25x3k+2(4-6) \left\{ \begin{array}{l} Q _ {1} = 0. 2 5 x _ {k} + 0. 7 5 x _ {k + 1} \\ Q _ {3} = 0. 7 5 x _ {3 k + 1} + 0. 2 5 x _ {3 k + 2} \end{array} \right. \tag {4-6} {Q1=0.25xk+0.75xk+1Q3=0.75x3k+1+0.25x3k+2(4-6)
当 n=4k+3n = 4k + 3n=4k+3 时,
{Q1=0.75xk+1+0.25xk+2Q3=0.25x3k+2+0.75x3k+3(4-7) \left\{ \begin{array}{l} Q _ {1} = 0. 7 5 x _ {k + 1} + 0. 2 5 x _ {k + 2} \\ Q _ {3} = 0. 2 5 x _ {3 k + 2} + 0. 7 5 x _ {3 k + 3} \end{array} \right. \tag {4-7} {Q1=0.75xk+1+0.25xk+2Q3=0.25x3k+2+0.75x3k+3(4-7)
通过 Q1Q_{1}Q1 和 Q3Q_{3}Q3 可以计算得到 XiX_{i}Xi 的四分位间距:
IQR=Q3−Q1(4-8) I _ {Q R} = Q _ {3} - Q _ {1} \tag {4-8} IQR=Q3−Q1(4-8)
在四分位法中,通过上限 FuF_{u}Fu 和下限 FlF_{l}Fl 可以筛选出异常值:
{Fu=Q3+1.5IQRFl=Q1−1.5IQR(4-9) \left\{ \begin{array}{l} F _ {u} = Q _ {3} + 1. 5 I _ {Q R} \\ F _ {l} = Q _ {1} - 1. 5 I _ {Q R} \end{array} \right. \tag {4-9} {Fu=Q3+1.5IQRFl=Q1−1.5IQR(4-9)
定义在区间 [Fl,Fu][F_l, F_u][Fl,Fu] 外的数据点为异常值。正常值和异常值的示意图如图 4-2 所示。QM 的流程图如图 4-3 所示。
在采用四分位法对原始风功率数据进行数据清洗的过程中,可以直接将功率小于等于0的数值以及大于额定功率的数据直接剔除。对于其他数据,分别对风功率数据和风速数据进行分段处理,然后分别采用横向四分位法和纵向四分位法对原始数据进行异常值检测。
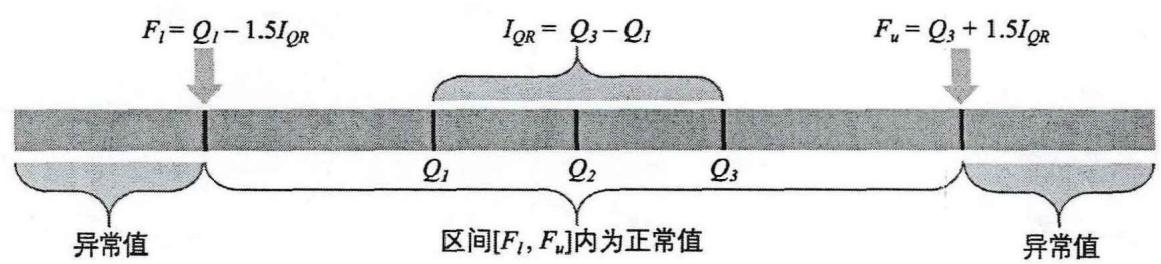
图4-2 正常值与异常值示意图
Fig.4-2 Schematic diagram of normal value and outliers
五、总结
本报告超认真地对《基于集成学习的风功率预测方法研究》做了系统的专业术语统计与分析啦📝!文档总字符数280261,中文字符63155个,英文字词25584个,一共扒出专业术语1338个~高频术语“预测模型”(369次)、“风电机组”(161次)等搭成了研究的核心概念小体系~
文档涉及6个研究领域,主要扎堆在风功率预测(1138次)、机器学习(1136次)、概率预测(1125次),超有多学科交叉的研究小特点~术语共现网络有10个节点和14条边,最强关联对“预测模型”与“集成预测模型”共现217次,搭成了以“预测模型”为中心的术语小聚类~
英文缩写一共出现30个,总频次542次,前五缩写“DBSCAN”(41次)等累计占比30.1%,反映了文档引用的经典文献和技术标准~
总的来说,本报告通过多维度术语统计,把文档的知识结构和研究焦点扒得明明白白,超全面的哟~
六、原文部分参考文献
[1] Global Wind Energy Council. 2024. 2024 全球风能报告.
[2] Moore F. C., Lacasse K., Mach K. J., et al. Determinants of emissions pathways in the coupled climate-social system[J]. Nature, 2022, 603(7899):103-111.
[3]吕鑫,祁雨霏,董馨阳等.2020年光伏及风电产业前景预测与展望[J].北京理工大学学报(社会科学版),2020,22(02):20-25.
[4] 张智刚,康重庆. 碳中和目标下构建新型电力系统的挑战与展望[J]. 中国电机工程学报,2022,42(08):2806-2819. DOI:10.13334/j.0258-8013.pcsee.220467.
[6] 周原冰, 杨方, 余潇潇, 等. 中国能源电力碳中和实现路径及实施关键问题 [J]. 中国电力, 2022, 55(5): 1-11.
[7] Sherman P., Chen X., Mcelroy M., et al. Offshore wind: An opportunity for cost-competitive decarbonization of China’s energy economy[J]. Science Advances, 2020, 6(8): eaax957137.
[8] 赵永宁. 基于时空相关性的大规模风电功率短期预测方法研究[D]. 中国农业大学, 2019.
[9] González-Sopea J. M., Pakrashi V., Ghosh B., et al. An overview of performance evaluation metrics for short-term statistical wind power forecasting[J]. Renewable and Sustainable Energy Reviews, 2021, 138: 110515.
[10] Wang Y., Zou R., Liu F., et al. A review of wind speed and wind power forecasting with deep neural networks[J]. Applied Energy, 2021, 304(1): 117766.
[11] Alkhayat G., Mehmood R… A review and taxonomy of wind and solar energy forecasting methods based on deep learning[J]. Energy and AI, 2021, 7: 100060.
[12] Wang H., Zhang N., Du E., et al. A comprehensive review for wind, solar, and electrical load forecasting methods[J]. Global Energy Interconnection, 2022, 5(1): 9-30.
[13] Chen Y. L., Hu X., Zhang L. X… A review of ultra-short-term forecasting of wind power based on data decomposition-forecasting technology combination model. Energy Reports, 2022, 8: 14200-14219.
[14]阎洁.风电功率预测不确定性及电力系统经济调度[D].华北电力大学(北京), 2017.
[15]张浩.风电功率时空不确定性预测方法研究[D].华北电力大学(北京),2022.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)