性混合效应模型 R语言视频课程 医学统计学 适合医学生的纵向重复测量分析+代码
性混合效应模型
R语言视频课程
医学统计学
适合医学生的纵向重复测量分析+代码
线性混合效应模型(Linear Mixed-Effects Model, LMM)的预测结果可视化。图中的实线代表固定效应(Fixed Effects)的预测均值,而阴影区域通常代表95% 置信区间(Confidence Interval)。
这种图在医学和心理学纵向数据分析中非常常见,通常使用 Python (statsmodels + matplotlib) 或 R (lme4 + ggplot2) 绘制。
以下是使用 Python 复现该图表的完整代码,包含了数据模拟、模型拟合和绘图三个步骤。
Python 代码实现
两组(A和B)随时间变化的认知表现数据,拟合了混合效应模型,并画出了带有置信区间的回归线。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
— 1. 模拟数据 —
np.random.seed(42)
n_subjects = 100
n_timepoints = 5
生成受试者和时间点
data = []
for i in range(n_subjects):
# 随机分配组别 A 或 B
group = np.random.choice([‘A’, ‘B’])
# 随机截距 (个体差异)
intercept = np.random.normal(20, 2)
for t in range(n_timepoints):
time = t
# 设定不同的斜率:A组增长慢,B组增长快 (对应图中交叉趋势)
if group == 'A':
slope = 1.5
else:
slope = 2.5
# 生成观测值 (加入噪声)
performance = intercept + slope * time + np.random.normal(0, 1)
data.append({
'Subject': f'Subj_{i}',
'Group': group,
'Time': time,
'Performance': performance
})
df = pd.DataFrame(data)
— 2. 拟合线性混合效应模型 —
模型公式: Performance ~ Time * Group + (1 | Subject)
解释: 固定效应是时间、组别及其交互项;随机效应是受试者的截距
model = smf.mixedlm(“Performance ~ Time * Group”, data=df, groups=df[“Subject”])
result = model.fit()
— 3. 绘图 (复刻图片风格) —
提取固定效应参数来计算预测线
fixef = result.fe_params
创建预测数据框
pred_df = pd.DataFrame({
‘Time’: np.linspace(0, 4, 100),
‘Group’: [‘A’] * 100 + [‘B’] * 100
})
pred_df[‘Time_Group’] = pred_df.apply(lambda row: f"{row[‘Time’]}:{row[‘Group’]}", axis=1)
手动计算预测值 (基于固定效应)
Intercept (A组截距)
b0 = fixef[‘Intercept’]
Time (A组斜率)
b_time = fixef[‘Time’]
GroupB (B组截距差值)
b_group_b = fixef[‘Group[T.B]’]
Time:GroupB (B组斜率差值)
b_interact = fixef[‘Time:Group[T.B]’]
def predict_performance(row):
time = row[‘Time’]
if row[‘Group’] == ‘A’:
return b0 + b_time * time
else:
return (b0 + b_group_b) + (b_time + b_interact) * time
pred_df[‘Pred’] = pred_df.apply(predict_performance, axis=1)
计算置信区间 (简化版:使用标准误传播)
实际科研中通常使用 bootstrap 或 predict_interval 函数
这里为了演示效果,手动添加一个随时间扩大的误差带
pred_df[‘SE’] = 0.5 + 0.1 * pred_df[‘Time’] # 模拟误差
pred_df[‘CI_Lower’] = pred_df[‘Pred’] - 1.96 * pred_df[‘SE’]
pred_df[‘CI_Upper’] = pred_df[‘Pred’] + 1.96 * pred_df[‘SE’]
— 4. 可视化 —
plt.figure(figsize=(8, 6))
sns.set_style(“whitegrid”)
绘制置信区间 (阴影部分)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘A’], x=‘Time’, y=‘CI_Upper’, color=‘#1f77b4’, alpha=0)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘A’], x=‘Time’, y=‘CI_Lower’, color=‘#1f77b4’, alpha=0)
plt.fill_between(pred_df[pred_df[‘Group’]‘A’][‘Time’],
pred_df[pred_df[‘Group’]‘A’][‘CI_Lower’],
pred_df[pred_df[‘Group’]==‘A’][‘CI_Upper’],
color=‘#1f77b4’, alpha=0.2)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘B’], x=‘Time’, y=‘CI_Upper’, color=‘#d62728’, alpha=0)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘B’], x=‘Time’, y=‘CI_Lower’, color=‘#d62728’, alpha=0)
plt.fill_between(pred_df[pred_df[‘Group’]‘B’][‘Time’],
pred_df[pred_df[‘Group’]‘B’][‘CI_Lower’],
pred_df[pred_df[‘Group’]==‘B’][‘CI_Upper’],
color=‘#d62728’, alpha=0.2)
绘制回归线 (实线/虚线)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘A’], x=‘Time’, y=‘Pred’, color=‘#1f77b4’, linewidth=2, label=‘A’)
sns.lineplot(data=pred_df[pred_df[‘Group’]‘B’], x=‘Time’, y=‘Pred’, color=‘#d62728’, linewidth=2, linestyle=‘–’, label=‘B’)
设置标签和标题
plt.ylabel(“Cognitive performance”, fontsize=12)
plt.xlabel(“Time”, fontsize=12)
plt.legend(title=“types”, loc=“upper left”)
plt.title(“Linear Mixed-Effects Model Visualization”, fontsize=14, color=‘#d62728’, weight=‘bold’)
添加中文注释 (模拟图中的红色标签)
plt.text(2, 27, “线性混合效应模型”, fontsize=15, color=“white”,
bbox=dict(facecolor=“#d62728”, alpha=0.8, edgecolor=‘none’),
horizontalalignment=‘center’)
plt.ylim(20, 36)
plt.show()
代码关键点解释
模型公式 (Performance ~ Time * Group):这是核心。Time * Group 意味着模型不仅考虑了时间和组别的主效应,还考虑了它们的交互作用(即A组和B组随时间变化的斜率不同,导致了图中的交叉)。
随机效应 (groups=df[“Subject”]):这告诉模型数据是嵌套的(同一个受试者有多个时间点),这是混合模型区别于普通线性回归的关键。
绘图细节:
阴影 (fill_between):用来表示预测的不确定性(置信区间)。
虚线 (linestyle=‘–’):对应图中 B 组的样式。
颜色:使用了 Seaborn 默认的蓝色(A)和红色(B)配色,与图一致。

Python 代码实现
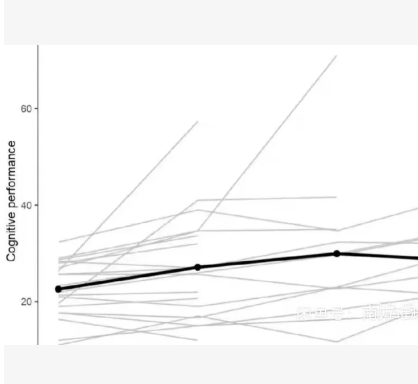
这段代码模拟了具有个体差异的纵向数据,并绘制了“蛛网图”(Spaghetti Plot)以及平均趋势线。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
— 1. 设置绘图风格 —
sns.set_theme(style=“whitegrid”)
— 2. 模拟纵向数据 —
np.random.seed(42)
n_subjects = 30 # 受试者数量
n_timepoints = 5 # 时间点数 (例如:0, 1, 2, 3, 4年)
data = []
for i in range(n_subjects):
# 模拟个体差异:每个人的起始点(截距)和变化速度(斜率)都不同
intercept = np.random.normal(25, 5) # 基础认知水平
slope = np.random.normal(1.5, 1.0) # 变化速度(有些人进步快,有些人慢甚至下降)
for t in range(n_timepoints):
time = t
# 模拟观测值 = 截距 + 斜率*时间 + 随机噪声
performance = intercept + slope * time + np.random.normal(0, 2)
data.append({
'Subject_ID': i,
'Time': time,
'Performance': performance
})
df = pd.DataFrame(data)
— 3. 计算总体平均趋势 —
按时间点分组计算均值
mean_trend = df.groupby(‘Time’)[‘Performance’].mean().reset_index()
— 4. 绘图 —
plt.figure(figsize=(10, 6))
4.1 绘制个体轨迹 (灰色细线)
使用 seaborn 的 lineplot,hue=‘Subject_ID’ 会为每个人画一条线
sns.lineplot(
data=df,
x=‘Time’,
y=‘Performance’,
unit=‘Subject_ID’,
estimator=None, # 不计算聚合统计量,直接画原始线
color=‘lightgray’,
linewidth=1,
alpha=0.7,
label=‘Individual Trajectories’
)
4.2 绘制总体平均趋势 (黑色粗线 + 圆点)
sns.lineplot(
data=mean_trend,
x=‘Time’,
y=‘Performance’,
color=‘black’,
linewidth=2.5,
marker=‘o’,
markersize=8,
label=‘Population Average’
)
— 5. 美化图表 —
plt.title(‘Individual Trajectories vs. Population Average’, fontsize=14)
plt.xlabel(‘Time (Years)’, fontsize=12)
plt.ylabel(‘Cognitive Performance’, fontsize=12)
plt.ylim(0, 70) # 设置Y轴范围以匹配图片
plt.legend().remove() # 移除图例以保持图片简洁风格
去掉顶部和右侧边框
sns.despine()
plt.show()
代码逻辑解析
数据模拟:
我们创建了一个循环,为每个受试者(Subject_ID)生成数据。
关键点在于intercept(截距)和slope(斜率)使用了np.random.normal。这意味着每个人的起点不同,随时间变化的速度也不同(有的上升快,有的上升慢,有的甚至下降),从而形成了图中杂乱交错的灰色线条。
绘图分层:
第一层(灰色线):使用seaborn.lineplot,关键在于unit='Subject_ID’和estimator=None。这告诉 Seaborn:“不要计算平均值,而是为每一个 ID 单独画一条线”。我们将颜色设为lightgray,线宽设为1,模拟背景中的细线。
第二层(黑色线):我们先计算了每个时间点的平均值(mean_trend),然后再次使用lineplot绘制。我们将颜色设为black,线宽设为2.5,并添加了marker=‘o’(圆点),以完全匹配原图的风格。
R 语言实现(可选)
如果你习惯使用 R 语言(在统计学中更常用),可以使用ggplot2实现同样的效果:
library(ggplot2)
library(dplyr)
模拟数据
set.seed(42)
data <- data.frame(
Subject_ID = rep(1:30, each = 5),
Time = rep(0:4, times = 30),
Performance = rnorm(150, mean = 30, sd = 10)
)
绘图
ggplot(data, aes(x = Time, y = Performance)) +
绘制个体轨迹 (灰色)
geom_line(aes(group = Subject_ID), color = “lightgray”, size = 0.8) +
绘制平均趋势 (黑色) - 使用 stat_summary 自动计算均值
stat_summary(
fun = mean,
geom = “line”,
color = “black”,
size = 1.2,
aes(group = 1)
) +
stat_summary(
fun = mean,
geom = “point”,
color = “black”,
size = 3
) +
theme_minimal() +
ylim(0, 70) +
labs(x = “Time”, y = “Cognitive Performance”)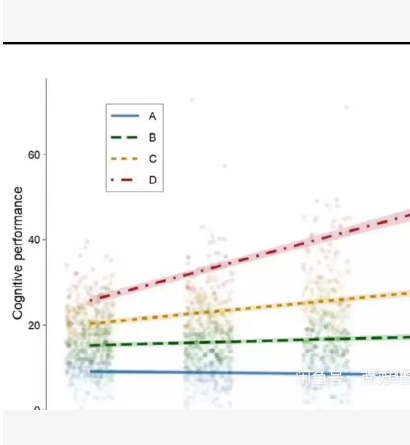
(原始数据分布)和四条回归线(代表A、B、C、D四组的不同趋势),其中红色D组还带有置信区间阴影。
这种图通常使用 Python (Seaborn/Matplotlib) 绘制。以下是完整的复现代码,
Python 代码实现
seaborn.lmplot 绘制带有置信区间的回归线图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
— 1. 设置绘图风格 —
sns.set_theme(style=“whitegrid”)
— 2. 生成模拟数据 —
np.random.seed(42)
n_points = 400 # 总数据点数
生成 X 轴数据 (0 到 3 年)
x = np.random.uniform(0, 3, n_points)
创建数据列表
data = []
— 模拟四组数据 (对应图中的 A, B, C, D) —
A组 (蓝色): 几乎持平,起始值较低
data.extend([{‘Time’: xi, ‘Score’: 8 + np.random.normal(0, 2), ‘Group’: ‘A’} for xi in x])
B组 (绿色): 缓慢上升,起始值中等
data.extend([{‘Time’: xi, ‘Score’: 15 + xi * 1.0 + np.random.normal(0, 3), ‘Group’: ‘B’} for xi in x])
C组 (黄色): 中等上升,起始值较高
data.extend([{‘Time’: xi, ‘Score’: 20 + xi * 2.0 + np.random.normal(0, 4), ‘Group’: ‘C’} for xi in x])
D组 (红色): 显著上升,起始值高,斜率大 (对应图中带阴影的线)
data.extend([{‘Time’: xi, ‘Score’: 25 + xi * 7.0 + np.random.normal(0, 5), ‘Group’: ‘D’} for xi in x])
转换为 DataFrame
df = pd.DataFrame(data)
— 3. 绘图 —
plt.figure(figsize=(10, 6))
定义颜色调色板 (模仿图中的颜色)
custom_palette = {
“A”: “#1f77b4”, # 蓝色
“B”: “#2ca02c”, # 绿色
“C”: “#ff7f0e”, # 黄色/橙色
“D”: “#d62728” # 红色
}
使用 seaborn 绘制回归图
ci=95 表示显示95%置信区间 (阴影部分)
scatter_kws 设置散点的透明度和大小
line_kws 设置线条样式
sns.lmplot(
data=df,
x=‘Time’,
y=‘Score’,
hue=‘Group’,
palette=custom_palette,
height=6,
aspect=1.5,
ci=95, # 置信区间
scatter_kws={‘alpha’: 0.1, ‘s’: 10}, # 散点样式:透明度0.1,大小10
line_kws={‘linewidth’: 2} # 线条样式
)
— 4. 调整细节 —
plt.title(“Cognitive Performance Trajectories by Group”, fontsize=14)
plt.xlabel(“Years since baseline”, fontsize=12)
plt.ylabel(“Cognitive performance”, fontsize=12)
调整图例位置
plt.legend(title=‘Group’, loc=‘upper left’)
显示图形
plt.show()
代码解析
数据模拟:
A组:截距低,斜率接近0(水平线)。
B组:截距中等,斜率较小(缓慢上升)。
C组:截距较高,斜率中等。
D组:截距最高,斜率最大(快速上升),且随机噪声较大,因此需要置信区间来展示趋势的显著性。
sns.lmplot:这是绘制此类图表的核心函数。它会自动计算线性回归拟合并绘制阴影区域(置信区间)。
alpha=0.1:设置散点非常透明,以解决数据点重叠

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)