基于FPGA的Qlearning强化学习模型设计指南
目录
随着人工智能技术的飞速发展,深度学习和强化学习已经在图像识别、自然语言处理、自动驾驶、机器人控制等领域取得了突破性进展。然而,传统的GPU和CPU平台在部署这些模型时,往往面临功耗高、延迟大、体积大等问题,难以满足边缘计算和实时推理的需求。FPGA凭借其高度并行的计算架构、可重构性、低功耗和低延迟等优势,成为部署AI模型的理想硬件平台。本文将以Q-Learning作为强化学习的代表,系统阐述如何在FPGA上实现这两种模型。文章将从数学原理出发,逐步分析每一个关键计算步骤,并给出相应的Verilog硬件描述语言实现代码,帮助读者建立从算法到硬件的完整映射关系。
1.Q-Learning基本原理
Q-Learning是一种无模型(Model-Free)的强化学习算法,属于时序差分(Temporal Difference, TD)学习方法。其核心思想是学习一个动作价值函数Q(s,a),表示在状态s下采取动作a所能获得的期望累积奖励。
1.1 Q值更新公式
Q-Learning的核心更新公式为:
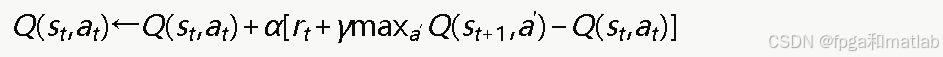
其中:

将此公式展开:
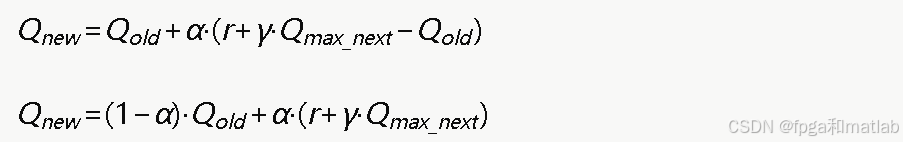
1.2 ε-贪心策略
在选择动作时,Q-Learning通常采用ε-贪心(ε-greedy)策略来平衡探索和利用:

2.Q-Table的FPGA存储设计
Q-Learning需要维护一个Q表,存储所有状态-动作对的Q值。假设有Ns个状态和Na个动作,Q表的大小为Ns×Na。在FPGA中,Q表可用Block RAM实现:
module q_table #(
parameter NUM_STATES = 16,
parameter NUM_ACTIONS = 4,
parameter DATA_WIDTH = 16,
parameter ADDR_WIDTH = 6 // log2(16*4) = 6
)(
input wire clk,
input wire we, // 写使能
input wire [ADDR_WIDTH-1:0] addr_rd, // 读地址
input wire [ADDR_WIDTH-1:0] addr_wr, // 写地址
input wire [DATA_WIDTH-1:0] data_in, // 写入数据
output reg [DATA_WIDTH-1:0] data_out // 读出数据
);
// Q表存储:使用BRAM
reg [DATA_WIDTH-1:0] q_mem [0:NUM_STATES*NUM_ACTIONS-1];
// 初始化Q表为0
integer i;
initial begin
for (i = 0; i < NUM_STATES * NUM_ACTIONS; i = i + 1)
q_mem[i] = 0;
end
// 同步读写
always @(posedge clk) begin
if (we)
q_mem[addr_wr] <= data_in;
data_out <= q_mem[addr_rd];
end
endmodule
地址映射关系:对于状态s和动作a,Q表中的地址为:
addr=s×Na+a
// 地址计算模块
module addr_calc #(
parameter NUM_ACTIONS = 4
)(
input wire [3:0] state,
input wire [1:0] action,
output wire [5:0] addr
);
// 当NUM_ACTIONS为2的幂时,乘法可用移位实现
assign addr = (state << 2) + action; // state * 4 + action
endmodule
3. 求最大Q值模块
在Q值更新和动作选择中,都需要找到maxa′Q(st+1,a′)及其对应的动作。假设有4个动作:
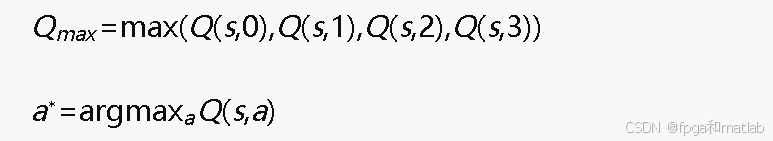
对应的verilog设计如下:
module find_max_q #(
parameter NUM_ACTIONS = 4
)(
input wire signed [15:0] q_values [0:NUM_ACTIONS-1],
output reg signed [15:0] max_q,
output reg [1:0] best_action
);
integer i;
always @(*) begin
max_q = q_values[0];
best_action = 2'd0;
for (i = 1; i < NUM_ACTIONS; i = i + 1) begin
if (q_values[i] > max_q) begin
max_q = q_values[i];
best_action = i[1:0];
end
end
end
endmodule
4.TD误差计算
时序差分(TD)误差是Q-Learning更新的核心,定义为:
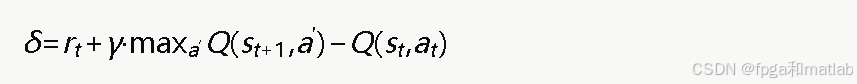
其中每一步运算都需要用定点数实现:
即:
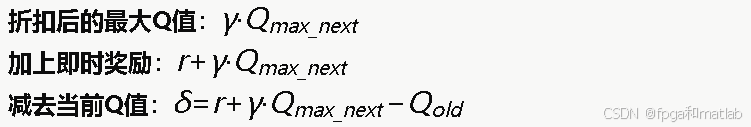
对应的verilog设计如下:
module td_error_calc (
input wire signed [15:0] reward, // r_t (Q7.8)
input wire signed [15:0] gamma, // 折扣因子 (Q7.8), e.g., 0.9 = 230
input wire signed [15:0] max_q_next, // max Q(s_{t+1}, a')
input wire signed [15:0] q_current, // Q(s_t, a_t)
output wire signed [15:0] td_error // δ
);
// Step 1: gamma * max_q_next
wire signed [31:0] gamma_q_full;
wire signed [15:0] gamma_q;
assign gamma_q_full = gamma * max_q_next;
assign gamma_q = gamma_q_full[23:8]; // 截断回Q7.8
// Step 2: r + gamma * max_q_next
wire signed [15:0] target;
assign target = reward + gamma_q;
// Step 3: td_error = target - q_current
assign td_error = target - q_current;
endmodule
5.Q值更新模块
完整的Q值更新公式:
![]()
其中α是学习率,δ是TD误差。
module q_update (
input wire signed [15:0] q_old, // 当前Q值
input wire signed [15:0] alpha, // 学习率 (Q7.8), e.g., 0.1 = 26
input wire signed [15:0] td_error, // TD误差
output wire signed [15:0] q_new // 更新后的Q值
);
// alpha * td_error
wire signed [31:0] update_full;
wire signed [15:0] update_step;
assign update_full = alpha * td_error;
assign update_step = update_full[23:8]; // 截断回Q7.8
// Q_new = Q_old + alpha * td_error
assign q_new = q_old + update_step;
endmodule
6.ε-贪心策略的FPGA实现
ε-贪心策略需要一个随机数生成器。在FPGA中,通常使用线性反馈移位寄存器(LFSR)来生成伪随机数:
module lfsr_random #(
parameter WIDTH = 16
)(
input wire clk,
input wire rst_n,
input wire [WIDTH-1:0] seed,
output wire [WIDTH-1:0] rand_out
);
reg [WIDTH-1:0] lfsr_reg;
// 16位LFSR,反馈多项式:x^16 + x^14 + x^13 + x^11 + 1
wire feedback;
assign feedback = lfsr_reg[15] ^ lfsr_reg[13] ^ lfsr_reg[12] ^ lfsr_reg[10];
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
lfsr_reg <= seed;
else
lfsr_reg <= {lfsr_reg[WIDTH-2:0], feedback};
end
assign rand_out = lfsr_reg;
endmodule
ε-贪心动作选择模块:
module epsilon_greedy #(
parameter NUM_ACTIONS = 4
)(
input wire clk,
input wire rst_n,
input wire enable,
input wire signed [15:0] epsilon, // ε值 (Q7.8), e.g., 0.1 = 26
input wire [15:0] rand_value, // 随机数
input wire [1:0] best_action, // argmax Q(s,a)
output reg [1:0] selected_action,
output reg action_valid
);
// 将随机数映射到[0, 1)范围(取高8位作为Q0.8)
wire [7:0] rand_normalized;
assign rand_normalized = rand_value[15:8];
// epsilon的小数部分
wire [7:0] eps_frac;
assign eps_frac = epsilon[7:0];
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
selected_action <= 2'd0;
action_valid <= 1'b0;
end else if (enable) begin
if (rand_normalized < eps_frac) begin
// 探索:随机选择动作
selected_action <= rand_value[1:0]; // 用随机数低2位
end else begin
// 利用:选择最佳动作
selected_action <= best_action;
end
action_valid <= 1'b1;
end else begin
action_valid <= 1'b0;
end
end
endmodule
7. Q-Learning完整控制器
综上所述,整个系统的流程图如下:
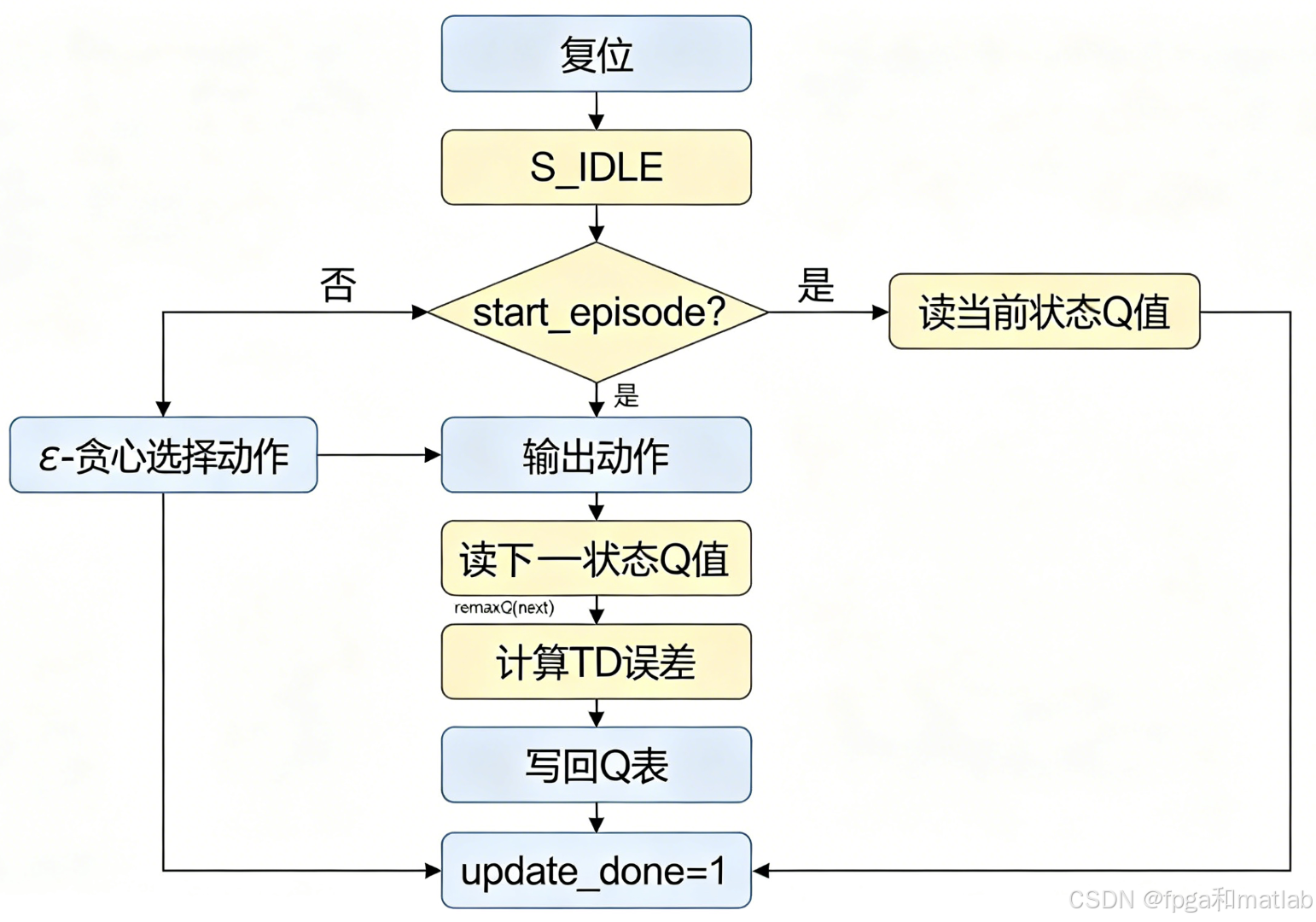
将以上模块整合成一个完整的Q-Learning控制器,通过状态机管理整个学习流程:
module q_learning_controller #(
parameter NUM_STATES = 16,
parameter NUM_ACTIONS = 4,
parameter DATA_WIDTH = 16
)(
input wire clk,
input wire rst_n,
input wire start_episode,
input wire [3:0] current_state,
input wire signed [15:0] reward,
input wire [3:0] next_state,
input wire episode_done,
output reg [1:0] action_out,
output reg action_valid,
output reg update_done
);
// 参数(Q7.8格式)
localparam signed [15:0] ALPHA = 16'sd26; // 0.1
localparam signed [15:0] GAMMA = 16'sd230; // 0.9
localparam signed [15:0] EPSILON = 16'sd26; // 0.1
// 状态机状态
localparam S_IDLE = 4'd0;
localparam S_READ_Q_ALL = 4'd1;
localparam S_WAIT_READ = 4'd2;
localparam S_SELECT_ACTION = 4'd3;
localparam S_WAIT_ENV = 4'd4;
localparam S_READ_NEXT_Q = 4'd5;
localparam S_WAIT_NEXT = 4'd6;
localparam S_FIND_MAX = 4'd7;
localparam S_COMPUTE_TD = 4'd8;
localparam S_UPDATE_Q = 4'd9;
localparam S_WRITE_Q = 4'd10;
localparam S_DONE = 4'd11;
reg [3:0] fsm_state;
reg [1:0] action_idx; // 动作遍历索引
reg signed [15:0] q_vals_current [0:NUM_ACTIONS-1];
reg signed [15:0] q_vals_next [0:NUM_ACTIONS-1];
// Q表接口信号
reg q_we;
reg [5:0] q_addr_rd, q_addr_wr;
reg signed [15:0] q_data_in;
wire signed [15:0] q_data_out;
// LFSR随机数
wire [15:0] rand_val;
// 内部计算信号
wire signed [15:0] max_q_next;
wire [1:0] best_action;
wire signed [15:0] td_err;
wire signed [15:0] q_new;
// 实例化Q表
q_table #(
.NUM_STATES(NUM_STATES),
.NUM_ACTIONS(NUM_ACTIONS)
) u_qtable (
.clk(clk), .we(q_we),
.addr_rd(q_addr_rd), .addr_wr(q_addr_wr),
.data_in(q_data_in), .data_out(q_data_out)
);
// 实例化LFSR
lfsr_random u_lfsr (
.clk(clk), .rst_n(rst_n),
.seed(16'hACE1), .rand_out(rand_val)
);
// 实例化最大值查找
find_max_q u_find_max (
.q_values(q_vals_next),
.max_q(max_q_next),
.best_action(best_action)
);
// 实例化TD误差计算
td_error_calc u_td (
.reward(reward), .gamma(GAMMA),
.max_q_next(max_q_next),
.q_current(q_vals_current[action_out]),
.td_error(td_err)
);
// 实例化Q值更新
q_update u_qupdate (
.q_old(q_vals_current[action_out]),
.alpha(ALPHA), .td_error(td_err),
.q_new(q_new)
);
// 主状态机
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
fsm_state <= S_IDLE;
action_idx <= 0;
action_out <= 0;
action_valid <= 0;
update_done <= 0;
q_we <= 0;
end else begin
case (fsm_state)
S_IDLE: begin
update_done <= 0;
q_we <= 0;
if (start_episode) begin
action_idx <= 0;
fsm_state <= S_READ_Q_ALL;
end
end
S_READ_Q_ALL: begin
// 逐个读取当前状态的所有Q值
q_addr_rd <= (current_state << 2) + action_idx;
fsm_state <= S_WAIT_READ;
end
S_WAIT_READ: begin
q_vals_current[action_idx] <= q_data_out;
if (action_idx == NUM_ACTIONS - 1) begin
action_idx <= 0;
fsm_state <= S_SELECT_ACTION;
end else begin
action_idx <= action_idx + 1;
fsm_state <= S_READ_Q_ALL;
end
end
S_SELECT_ACTION: begin
// ε-贪心选择
if (rand_val[15:8] < EPSILON[7:0])
action_out <= rand_val[1:0];
else begin
// 找当前状态最大Q值对应动作
// 简化实现:遍历比较
action_out <= 0;
if (q_vals_current[1] > q_vals_current[0])
action_out <= 1;
if (q_vals_current[2] > q_vals_current[action_out])
action_out <= 2;
if (q_vals_current[3] > q_vals_current[action_out])
action_out <= 3;
end
action_valid <= 1;
fsm_state <= S_WAIT_ENV;
end
S_WAIT_ENV: begin
action_valid <= 0;
// 等待环境返回reward和next_state
// 此处简化,假设下一周期就能获取
action_idx <= 0;
fsm_state <= S_READ_NEXT_Q;
end
S_READ_NEXT_Q: begin
q_addr_rd <= (next_state << 2) + action_idx;
fsm_state <= S_WAIT_NEXT;
end
S_WAIT_NEXT: begin
q_vals_next[action_idx] <= q_data_out;
if (action_idx == NUM_ACTIONS - 1) begin
fsm_state <= S_FIND_MAX;
end else begin
action_idx <= action_idx + 1;
fsm_state <= S_READ_NEXT_Q;
end
end
S_FIND_MAX: begin
// find_max_q组合逻辑已计算好max_q_next
fsm_state <= S_COMPUTE_TD;
end
S_COMPUTE_TD: begin
// td_error_calc组合逻辑已计算好td_err
fsm_state <= S_UPDATE_Q;
end
S_UPDATE_Q: begin
// q_update组合逻辑已计算好q_new
fsm_state <= S_WRITE_Q;
end
S_WRITE_Q: begin
q_we <= 1;
q_addr_wr <= (current_state << 2) + action_out;
q_data_in <= q_new;
fsm_state <= S_DONE;
end
S_DONE: begin
q_we <= 0;
update_done <= 1;
fsm_state <= S_IDLE;
end
default: fsm_state <= S_IDLE;
endcase
end
end
endmodule
8.ε衰减机制
在Q-Learning训练过程中,ε值通常需要逐步衰减,从较多探索逐渐过渡到更多利用:
![]()
其中ϵdecay通常为0.995或0.99。
module epsilon_decay (
input wire clk,
input wire rst_n,
input wire decay_trigger, // 触发衰减
input wire signed [15:0] decay_factor, // 衰减因子 (Q7.8),e.g., 0.995=255
input wire signed [15:0] epsilon_min, // 最小epsilon
output reg signed [15:0] epsilon // 当前epsilon
);
localparam signed [15:0] EPSILON_INIT = 16'sd256; // 1.0
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
epsilon <= EPSILON_INIT;
end else if (decay_trigger) begin
// epsilon = epsilon * decay_factor
// 注意:两个Q7.8相乘后右移8位
reg signed [31:0] new_eps;
new_eps = (epsilon * decay_factor) >>> 8;
// 下限约束
if (new_eps[15:0] < epsilon_min)
epsilon <= epsilon_min;
else
epsilon <= new_eps[15:0];
end
end
endmodule
9.总结
并行Q值读取:使用多端口RAM或将Q表分成多个Bank,允许同时读取一个状态对应的所有动作的Q值,从而将Q值读取从多个周期缩短到单个周期。
查找表加速:对于状态空间和动作空间较小的问题,可以将整个Q表分布在FPGA的分布式RAM(LUT RAM)中,实现单周期读写。
流水线化:将TD误差计算、Q值更新等步骤进行流水线化处理,使得在更新一个状态-动作对的同时,可以开始下一个状态的Q值读取。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)