论文阅读:Robust Graph Based Social Recommendation Through Contrastive Multi-View Learning
论文基本信息
标题:基于对比多视图学习的鲁棒图基社交推荐(Robust Graph Based Social Recommendation Through Contrastive Multi-View Learning)
会议:第三十九届人工智能促进协会会议(AAAI-25)
这篇论文干了一件事:
👉 在推荐系统(Recommendation System)里,引入:
- 社交关系(谁认识谁)
- 多视角信息(用户兴趣 + 社交 + 意图)
- 对比学习(Contrastive Learning)
👉 目标:
解决推荐系统里的“噪声 + 稀疏”问题
1️⃣ Social Recommendation(社交推荐)
👉 利用“用户之间的社交关系”来做推荐
比如:
- 朋友喜欢的东西,你也可能喜欢
2️⃣ Graph Based(基于图)
👉 用**图结构(Graph)**建模:
- 用户 = 节点(node)
- 商品 = 节点
- 用户-商品交互 = 边(edge)
- 用户-用户社交关系 = 边
👉 本质是:图神经网络(GNN)推荐系统
3️⃣ Multi-View Learning(多视角学习)
👉 从多个角度理解用户:
- 用户行为(点击/评分)
- 社交关系
- 用户意图(intent)
👉 每个角度 = 一个“view(视图)”
4️⃣ Contrastive Learning(对比学习)
👉 核心思想:
- 拉近“同一个用户的不同表示”
- 拉远“不同用户”
👉 本质:让表示更区分、更干净(去噪)
5️⃣ Robust(鲁棒)
👉 重点:抗噪声能力强
✅ 一句话总结标题:
👉 用图神经网络 + 多视角信息 + 对比学习
👉 解决“社交推荐中的噪声问题”
Abstract 摘要
社交推荐利用用户间的社交关联缓解数据稀疏问题,提升推荐质量。
尽管现有相关研究已展现出有效性,但仍存在两个关键问题:其一,用户间的偏好交互模式具有多样性和异质性,现有模型难以在含噪的社交环境中准确捕捉用户交互带来的偏好变化;其二,现有方法对辅助信息的融合处理较为粗糙,可能引入噪声并导致用户偏好建模出现偏差。
为解决上述局限性,本文提出一种新型框架 —— 基于对比多视图学习的鲁棒图基社交推荐模型(RGCML)。该框架将去噪后的社交关系与全局意图作为双辅助信息源,实现对用户的全面表征。首先,RGCML 引入观点动力学的概念,模拟含噪社交关系下用户偏好的演化过程;其次,通过专门设计的信息融合模块,从多语义视角提取关键的上下文信息,实现个性化的信息融合;最后,采用设计的全局 - 局部对比学习范式,将用户偏好与全局意图解耦并加以区分,进一步解决噪声问题,提升用户表征质量。
在三个真实数据集上开展的大量实验表明,与多个当前最优(SOTA)的基线模型相比,RGCML 取得了更优的性能。
(1)👉 数据稀疏(Data Sparsity)就是:用户点过的东西太少 → 模型学不到东西
数据稀疏(data sparsity)= 用户交互太少
一个用户只点过3个电影 👉 很难判断他喜欢啥
👉 解决思路:
- 普通推荐:只看“用户-物品”
- 社交推荐:加上“用户-用户关系”(用“朋友信息”补“行为数据不足”)
(2)👉 社交噪声(Social Noise):
👉 举个例子(论文也举了类似的):
- 母亲喜欢:生活用品
- 孩子喜欢:体育用品
👉 但他们是“好友”,问题:社交关系 ≠ 兴趣相同
什么是“异质(heterogeneous):不同用户之间差异很大
👉 母亲和儿子,虽然是好友,但兴趣完全不同
但是GNN默认假设:邻居相似
但现实:邻居可能完全不同----->总结:社交信息里面有噪声
(3)👉 什么是“辅助信息(Auxiliary Information)”:社交关系、用户意图、图结构
👉 现在的问题:直接拼接(concat)、或简单加权
👉 ❗结果:信息混乱 → 推荐变差,信息融合不科学 → 引入噪声
(4)RGCML 做了三件关键事:
✅ 1. 社交去噪(最核心创新之一)
👉 用一个物理模型:Opinion Dynamics(意见动力学)处理社交关系
✅ 2. 多信息融合
👉 把:社交信息、用户意图、用户行为 做个性化融合
多视图信息:两类辅助信息:去噪后的社交关系、用户全局意图(global intent)
信息融合模块:从多个语义角度提取信息、个性化融合(重点创新点)
✅ 3. 对比学习(Contrastive Learning)
👉 拉近(相似的):同一个用户的不同表示
👉 拉远(不相似的):不同用户
👉 分两种:global(全局)、local(局部)
👉 用来:✔ 去噪✔ 提升表示质量
总结 Abstract
👉 这篇论文解决了两个核心问题:
- 社交关系有噪声
- 多信息融合不合理
👉 提出了一个三模块方法:
- 社交去噪(Opinion Dynamics)
- 多视角融合、多视图建模(intent + social)
- 全局-局部对比学习优化表示
👉 最终显著提升推荐效果
摘要(Abstract)
- 研究背景:社交推荐是缓解推荐系统数据稀疏的有效手段,但现有模型存在两大核心问题 —— 无法准确捕捉含噪社交环境中的用户偏好演化、对辅助信息的融合处理粗糙易引入噪声。
- 核心方法:提出新型模型 RGCML,以去噪社交关系和用户全局意图为双辅助信息源,通过三步核心设计解决上述问题:①观点动力学模拟含噪社交下的偏好演化;②多语义信息融合模块实现个性化辅助信息融合;③全局 - 局部对比学习解耦用户偏好与全局意图,解决融合噪声。
- 实验结果:在 Douban、Ciao、Yelp 三个真实数据集上的实验表明,RGCML 性能显著优于当前最优(SOTA)的基线模型。
- 核心价值:为社交推荐的噪声处理和多视图辅助信息融合提供了新的解决方案,提升了模型对数据稀疏和社交噪声的鲁棒性。
Introduction 引言
在信息爆炸的时代,推荐系统能够过滤复杂信息,在挖掘用户偏好、提供个性化服务方面发挥着重要作用(Sharma 等,2024;Wu 等,2022)。协同过滤(CF)是一种主流方法,它从用户的历史交互行为中推断偏好,为用户推荐符合其兴趣的物品(Su 和 Khoshgoftaar,2009)。近年来,基于图神经网络(GNN)的协同过滤模型取得了优异的性能,成为推荐系统的主流范式(He 等,2020;Mao 等,2021;Wang 等,2019)。这一成功得益于 GNN 模型的消息传播和邻居聚合机制,使其能够捕捉高阶连接关系,得到更具关联性的用户和物品表征。然而,数据稀疏性—— 即用户历史交互行为数量有限 —— 这一挑战严重阻碍了推荐系统的发展。
(1)👉 推荐系统本质:信息过滤器 + 个性化引擎
(现在问题不是“信息不够”,而是: ❗信息太多)
(2)协同过滤(Collaborative Filtering, CF)核心思想:“相似用户喜欢相似东西”
协同过滤有两种核心逻辑:User-based CF 找“相似用户”
Item-based CF👉 找“相似物品”
本质:相似性建模
(3)✅ GNN(Graph Neural Network,图神经网络)GNN = 更强的“关系建模工具”
用图结构建模:用户节点、物品节点、社交边
👉 优点:能捕捉高阶关系(multi-hop)
👉 核心机制:✔ Message Passing(消息传递)👉 邻居影响你
✔ Neighbor Aggregation(邻居聚合)👉 汇总邻居信息
(4)高阶关系(high-order connectivity):二阶关系:你 → 朋友 → 朋友的朋友
GNN可以捕捉:✔ 二跳✔ 三跳👉 这就是比传统CF更强的原因
(5)数据稀疏性:👉 推荐系统最大敌人:❗用户行为太少
举例:一个新用户:只点过1个商品👉 模型几乎无法判断偏好
👉 这就是:👉 冷启动问题(Cold Start)
根据社交同质性假设(McPherson、Smith-Lovin 和 Cook,2001;Jiang 等,2024),存在社交关联的用户更可能拥有相似的交互偏好,因此挖掘用户的社交关系能够提供有价值的用户侧信息,缓解数据稀疏问题。因此,众多学者将社交关系作为补充信息融入推荐系统,以提升推荐质量(Fan 等,2019;Yang 等,2021)。
social homophily:社会同质性。“物以类聚,人以群分”
举例:你朋友喜欢篮球👉 你也可能喜欢
👉 所以:社交关系 = 有用信息
👉 社交推荐 = CF + 社交图,本质:用户行为 + 用户关系
此外,为进一步缓解数据稀疏问题,自监督学习被广泛应用于推荐系统中,使其能够利用无标签数据,提升模型的鲁棒性和泛化能力(Yu 等,2023)。自监督学习的核心思想是通过对原始数据构建辅助视图生成自监督信号,例如 SGL(Wu 等,2021)通过扰动图结构构建增强视图,提供有效的自监督信号以提升推荐性能。
(1)👉 自监督学习(Self-Supervised Learning, SSL)👉 不需要人工标签
举例:原始数据:用户-商品图
👉 人为构造两个“视图”:删一些边、加一些噪声
👉 然后让模型:👉学会“保持一致”
👉 本质: 用数据自己监督自己
(2)👉 SGL做什么? 对图做“破坏”:删除边、删除节点
👉 然后要求:模型学到“稳定表示”
👉 好处:✔ 提高鲁棒性 ✔ 降低过拟合
尽管现有模型取得了令人信服的结果,但本文认为其仍存在若干不足:
- 盲目融入社交信息可能引入噪声,降低模型性能。例如,母亲和孩子之间存在社交关联,但母亲可能偏好家居用品,而孩子偏好运动用品,这表明即使是存在社交连接的个体,其偏好也可能存在异质性。若处理不当,直接将 GNN 应用于获取用户社交嵌入会引入噪声。尽管部分模型已开始关注社交噪声问题,并尝试通过自监督学习等策略缓解该问题(Wang、Xia 和 Huang,2023),但准确模拟社交网络中偏好的传播和演化过程仍是一个亟待深入研究的挑战。
- 现有模型虽通过融合各类辅助信息缓解数据稀疏问题,但缺乏科学严谨、具有普适性的方法来融合多视角的辅助信号。这一缺陷往往导致生成的嵌入并非最优,从而限制了推荐系统的整体性能。例如,GraphRec(Fan 等,2019)采用拼接不同语义下的嵌入并输入多层感知机(MLP)以得到最终用户表征的方法,这一方式可能引入噪声;IDVT(Yang 等,2023)使用的门控机制未能充分考虑用户间的差异;尽管部分方法尝试利用注意力机制进行融合,但这类方法计算成本高、资源消耗大。因此,学界亟需一种高效、鲁棒的个性化融合策略。
问题一:盲目使用社交信息会引入噪声。
👉 母亲 vs 孩子:有社交关系 ✔ 兴趣完全不同 ❌
👉 结论: 社交边 ≠ 有用信息
问题二(信息融合)辅助信息融合方式不合理,会导致表示不准确
👉 为什么融合难?因为:
信息类型 特点 社交关系 有噪声 用户行为 稀疏 用户意图 隐含 👉 简单拼接 = ❌
本文提出一种新型的全局 - 局部对比学习模型 RGCML,通过引入丰富的用户侧辅助信息全面刻画用户特征。为捕捉社交关系带来的用户偏好变化,本文从社会物理学中引入黑格塞尔曼 - 克劳斯(HK)观点动力学模型的概念,过滤不可靠的社交连接,聚焦于从可靠连接中学习。为捕捉用户与物品之间更细粒度的交互模式,本文进一步将用户全局意图作为用户侧辅助信息。随后,RGCML 通过一个侧信息融合模块提取不同语义下的核心特征,促进有效的表征学习。最后,本文设计了一个全局 - 局部对比学习模块,将最终的用户嵌入与偏好嵌入、意图嵌入对齐,旨在进一步解决信息融合中固有的噪声问题。
综上,本文的贡献如下:
- 提出一种新型社交推荐模型,该模型基于观点动力学对社交关系去噪,并利用用户全局意图提供有价值的辅助信息;
- 设计一个有效的信息融合模块,能够根据不同用户的特征实现辅助信息的个性化融合;同时利用全局 - 局部对比学习进一步解决信息融合中的噪声问题,得到可靠的用户表征;
- 在三个真实数据集上开展大量实验,验证了 RGCML 相比多个当前最优模型的性能提升效果。
本文解决方案:
🧩 1️⃣ Opinion Dynamics(意见动力学)
👉 用来:✔ 模拟用户偏好传播、✔ 去掉不可靠社交关系
👉 本质:👉 社交去噪模型
🧩 2️⃣ Global Intent(全局意图)
👉 用户行为背后有“动机”
举例:你看《奥本海默》可能因为:喜欢历史、评分高、导演
👉 这些叫:intent(意图)
🧩 3️⃣ 信息融合模块(核心创新🔥)
👉 不是简单拼接
👉 而是:✔ 个性化融合✔ 动态权重
🧩 4️⃣ Global-Local Contrastive Learning
设计了一个全局 - 局部对比学习模块,将最终的用户嵌入与偏好嵌入、意图嵌入对齐,进一步解决信息融合中固有的噪声问题,得到可靠的用户表征。
👉 两层对比:
类型 作用 local 保持局部一致 global 对齐用户意图 👉 本质:👉 去噪 + 表示优化
引言(Introduction)
本章从推荐系统的研究现状出发,层层递进引出研究问题,明确本文的研究动机和核心贡献,逻辑链为:
- 推荐系统的重要性:信息爆炸时代,推荐系统是个性化服务的核心,基于 GNN 的协同过滤是当前主流范式,但其受数据稀疏性制约。
- 社交推荐的解决思路:基于社交同质性假设,将社交关系作为辅助信息融入推荐系统,缓解数据稀疏;同时自监督学习被广泛用于挖掘无标签数据,提升模型泛化能力。
- 现有研究的两大核心缺陷:
- 社交信息盲目融合易引入噪声,且难以模拟社交网络中偏好的传播演化;
- 多视图辅助信息的融合方法缺乏严谨性和普适性,现有方法(拼接 + MLP、门控机制、注意力)或引入噪声、或未考虑用户差异、或计算成本过高。
- 本文的核心解决方案:提出 RGCML 模型,结合观点动力学(社交去噪)、用户全局意图(细粒度交互建模)、个性化融合模块(多视图信息融合)、全局 - 局部对比学习(融合噪声处理)解决上述问题。
- 三大研究贡献:①提出观点动力学去噪 + 全局意图辅助的社交推荐框架;②设计个性化多视图融合模块 + 全局 - 局部对比学习,解决融合噪声;③在三个真实数据集验证模型优于 SOTA。
Related Work 相关工作
自监督学习(Self-Supervised Learning)
鉴于自监督学习在计算机视觉和自然语言处理领域的优异表现(He 等,2019;Devlin 等,2018),许多推荐模型都融入了对比学习组件(Cai 等,2023;Chen 等,2023)。这些模型通过构建增强视图,最大化正样本对的相似度、降低负样本对的相似度,从而提升推荐准确率,缓解数据稀疏问题。
现有研究有多种构建增强视图的方法,例如 SGL(Wu 等,2021)采用随机边 / 节点丢弃的方式,SimGCL(Yu 等,2022b)对节点特征引入扰动;NCL(Lin 等,2022)在特定用户、结构邻居和语义中心节点之间进行表征对齐;DCCF(Ren 等,2023)利用图对比学习将用户意图与偏好解耦。本文方法的不同之处在于,不改变图的结构,从而保留关键的交互信息。
社交推荐(Social Recommendation)
由于 GNN 具备捕捉节点间复杂依赖关系的卓越能力,基于 GNN 的社交推荐模型已成为主流范式。这类模型主要利用 GNN 学习用户的社交特征和偏好特征,随后通过各种融合方法得到最终的用户表征。例如,DiffNet(Wu 等,2019)考虑了社交扩散的影响,并通过按元素相加的方式进行嵌入融合;DESIGN(Tao 等,2022)利用知识蒸馏的方法增强学习过程。此外,部分模型融入自监督学习的概念,进一步优化表征效果,例如 SEPT(Yu 等,2021a)提出了三训练自监督框架;MHCN(Yu 等,2021b)引入了带自监督学习的多通道超图卷积网络;DSL(Wang、Xia 和 Huang,2023)利用双语义信息进行社交去噪;SMIN(Long 等,2021)通过元路径引导的节点连接,研究自监督信号添加后图拓扑的变化。
本文的创新点:提出一种基于观点动力学的社交去噪方法,并设计了一个个性化的信息融合模块,能够充分考虑用户间的个体差异。
Methodology 方法论
4.1 Preliminaries 预备知识
本文首先介绍所使用的定义和符号。在社交推荐中,涉及两个核心图:交互图Gr和社交图Gs。
将用户集U=(u1,...,uM)与物品集I=(v1,...,vN)之间的交互矩阵表示为R∈RM×N,其中M和N分别为用户数和物品数。若用户ui曾与物品vj产生交互,则Ri,j=1,否则Ri,j=0。
类似地,将社交关系矩阵表示为As∈RM×M。
1️⃣ 交互图(Interaction Graph)
👉 用户 ↔ 商品:用户点了什么、用户买了什么
2️⃣ 社交图(Social Graph)
👉 用户 ↔ 用户:谁和谁是朋友
模型的整体架构如图 1 所示。
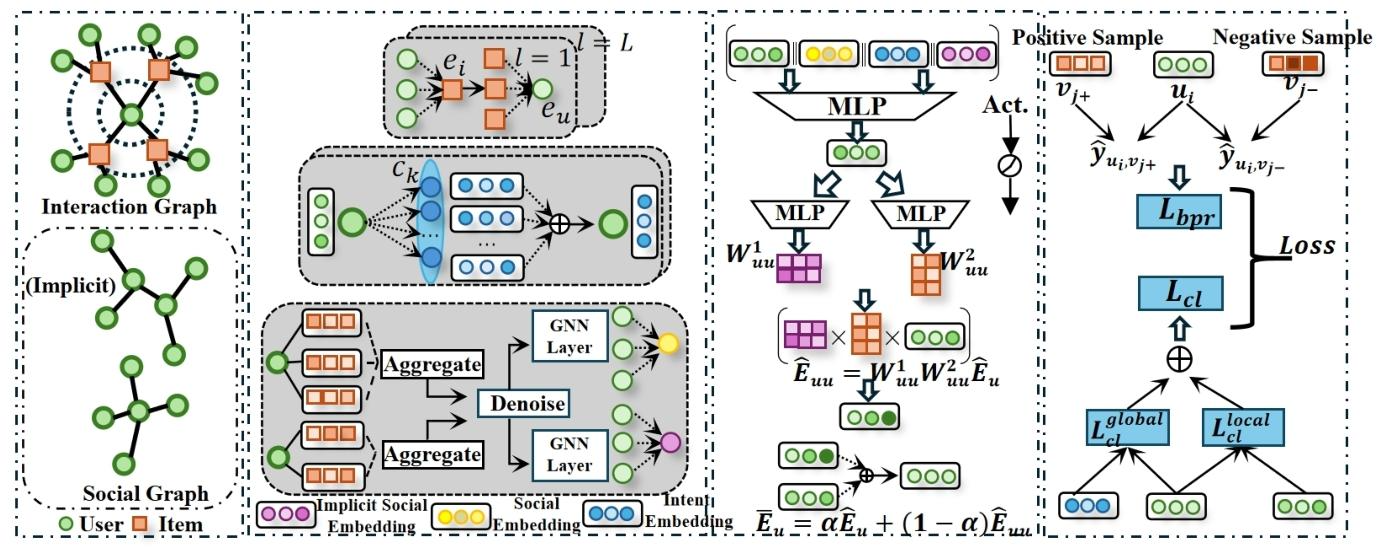
4.2 Social Relation Modeling based on Opinion Dynamics
基于观点动力学的社交关系建模
【第一部分:社交去噪(Opinion Dynamics)】
为在含社交噪声的场景下有效建模用户间的交互,本文引入观点动力学的概念(Weng 等,2023),该理论能够模拟群体中个体观点的演化过程。
👉 问题: 社交关系有噪声(假朋友)
👉 解决: 用“意见动力学”筛选可靠关系
观点动力学:人会被周围人影响, 观点会变化
👉 这个思想被用来:模拟用户兴趣变化
根据 Hegselmann-Krause(HK) 模型(Hegselmann 和 Krause,2002),个体的观点会向置信区间内所有观点的平均值偏移。一个人的观点会向其“信任范围内”的其他人的平均观点靠近。

👉 核心规则: 只听“和自己差不多的人”
公式解释:👉 如果 j 在 i 的“可信集合”里: 平均分配权重
否则: 权重 = 0(直接忽略)
👉 本质:筛掉不相似的朋友
- 置信区间:只有观点(偏好)相似的好友,才会互相影响;偏好差异太大的好友,直接权重设为 0(删掉这条社交边)。
- 核心逻辑:用用户偏好的相似度,过滤不可靠的社交关系,实现社交去噪。
在推荐系统中,用户的历史交互行为直接反映其观点,可用于准确刻画用户的相关性。本文将用户交互过的所有物品嵌入的平均值作为用户的初始观点,公式表示为:

🔹解释: 用户“原始观点”: = 看过物品的平均

👉 把朋友影响加入
👉 用余弦相似度判断是否保留关系

👉 用 GNN 在“去噪社交图”上传播信息
总结:不是所有朋友都影响你 👉 只有“观点相似”的朋友才影响你。
举例:用户 A:喜欢电影 🎬 朋友 B:喜欢电影 ✔ 朋友 C:喜欢运动 ❌
👉 那么:B 有影响 C 被过滤
👉 这就是: 社交去噪的第一步
核心思想总结 👉 “只相信和你相似的人”
公式2:用户初始意见 = 他看过的东西的平均,用户兴趣 = 历史行为的总结
公式3:加入社交影响👉 把“朋友的意见”加进来,更新后你会“稍微被影响”
本质:👉 矩阵乘法 = 聚合邻居信息
公式4:相似度判断 用余弦相似度判断:👉 两个人是否“真的相似”
👉 如果相似度 > ε:✔ 保留社交关系。否则:❌ 删除
🧠 直觉:👉 过滤掉“假朋友”
公式5:最终社交 embedding:👉 用标准 GNN 方式传播信息
把“干净社交图”(去噪社交图)再做一层 GNN
讲解:
- 用户观点 = 交互物品嵌入均值:用用户的真实行为定义偏好,最客观;
- 双社交嵌入:显式去噪社交(好友)+ 隐式社交(同交互物品),覆盖更全面的用户关联;
- 核心结果:得到无噪声的社交嵌入,解决第一个痛点。
4.3 Graph Convolution and Multi Global Intent Modeling 图卷积与多全局意图建模
- HK 观点动力学:社会物理学里的理论,模拟人群中观点的传播、演化,本文用它给社交关系打分,删掉不可靠的好友边,实现社交去噪。
- 用户全局意图:用户交互物品的潜在目的(比如看电影是因为喜欢传记片,还是因为评分高),解耦意图和偏好,建模更细粒度。
(1)消息传播(Message Propagation)得到用户偏好嵌入embedding
【🧩 第二部分:GNN传播(用户偏好)】

这是LightGCN 的经典图卷积公式(推荐系统最常用的 GNN),核心是加权聚合邻居信息,学到纯净的用户偏好嵌入(不包含社交噪声)。
👉 标准 GNN 更新:👉 用户 ← 商品 ← 用户(信息传递)
举例:你看:商品A。别人也看:商品A 👉 你们变相似
(2)全局意图建模(Global Intent Modeling)得到用户意图 embedding
【🧩 第三部分:Global Intentd】得到用户意图embedding
在实际场景中,用户与物品产生交互的意图(背后的动机)具有多样性,且这些意图往往与用户的历史交互高度关联。例如,用户观看《奥本海默》可能是因为偏好传记类电影,也可能是因为该影片评分较高。忽略用户的全局意图往往会导致用户表征效果不佳,进而限制推荐质量。
因此,为捕捉用户与物品之间更细粒度的交互模式,RGCML 将用户全局意图作为用户侧辅助信息。每层 GNN 得到用户偏好嵌入后,同步生成全局意图嵌入。
intent?👉 用户行为背后的“动机”,用户的意图。
这是本文第二个辅助信息源(第一个是去噪社交)。
- 意图 vs 偏好:偏好是长期喜欢的类型,意图是短期交互的目的,解耦两者能让建模更精准;
看电影可能因为:喜欢科幻、喜欢导演、评分高
👉 每个 intent = 一个向量 ck(意图原型)
首先,初始化K个全局意图原型ck∈RD(k=1,...,K);
随后,利用 softmax 函数计算用户嵌入与意图原型之间的相关性,也就是关联概率。
以用户u为例: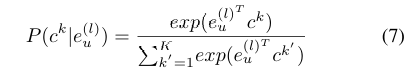
通过该方式,可得到用户偏好与全局意图之间的相关性,从而捕捉更细粒度的用户交互模式。
接着,将K个可学习的意图原型聚合,生成第l层的用户意图嵌入: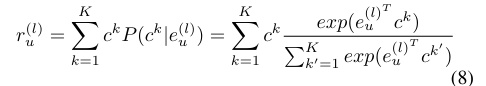
其中,ru(l)∈RD为第l层的用户意图嵌入。
- 意图原型:相当于人工定义 K 种潜在意图,模型自动学习每个用户属于哪种意图;
- 最终得到用户意图嵌入,作为辅助信息。
公式7:计算用户属于某个意图的概率。
公式8:得到用户意图嵌入👉 用户意图 embedding
👉 本质:👉 加权平均, 用户意图 = 多个意图加权
(3)嵌入聚合(Embedding Aggregation)
🧩 第四部分:Embedding 聚合
为得到最终的嵌入表示,本文采用均值池化的方法,公式表示为:
![]()
其中,Ru为用户全局意图嵌入,E^u为用户偏好嵌入,E^i为物品嵌入,L为网络的总层数。
👉 多层GNN结果取平均
直觉👉 综合不同层信息(防止过拟合)
嵌入聚合:用均值池化得到最终嵌入:
Ru:用户全局意图嵌入;Eu:用户偏好嵌入;Ei:物品嵌入。
讲解:把 GNN 每一层的特征取平均,得到更稳定的最终特征,避免单层特征波动。
4.4 Multi-View Information Fusion 多视图信息融合
前文已引入了多视角下丰富的用户侧辅助信息,但现有研究尚未提出高效的个性化融合策略来整合这些信息。在 RGCML 中,本文设计了一个通用融合模块,高效融合辅助信息并解决噪声问题。
首先,RGCML 从不同视角提取显著特征,以保留每个语义下的重要用户特征,公式表示为:
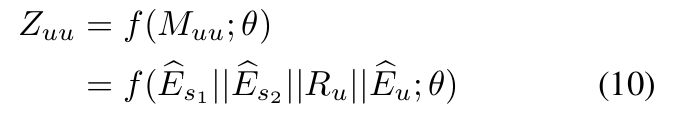
其中,Muu∈R(M×4D)由不同的侧信息嵌入拼接得到,f(⋅)为一个三层感知机(MLP);
Muu包含显式社交嵌入E^s1、隐式社交嵌入E^s2、全局意图嵌入Ru,同时为了将融合后的信息映射到与用户偏好嵌入E^u相同的语义空间,Muu也包含了E^u。
- 多视图:社交视图、意图视图、偏好视图;
- 拼接是为了保留所有信息,MLP 是为了提取关键特征。
1️⃣ 用户偏好 embedding👉 来自 GNN
2️⃣ 用户意图 embedding👉 来自 intent 模型
3️⃣ 社交 embedding👉 去噪后社交图
到这里我们已经完成了✔ 预备知识✔ 社交去噪✔ GNN✔ 意图建模
融合方式:个性化信息融合模块
先拼接👉 “||” = 拼接(concatenate)
👉 f(·)👉 一个 MLP(多层感知机)👉 用来提取重要特征
- 拼接 4 类嵌入:显式去噪社交Es1+ 隐式社交Es2+ 全局意图Ru+ 用户偏好Eu;
- 用三层 MLP 提取显著特征,得到Zuu。
把所有信息放在一起👉 让神经网络学:👉 哪些信息重要
举例: 用户A:社交信息不可靠👉 模型会自动降低权重
用户B:社交信息很有用👉 模型会增强它
随后,将Zuu作为输入,生成个性化知识转移矩阵;
同时,本文引入低秩矩阵分解的思想(Xia 等,2021;Chen 等,2023),为每个用户高效生成个性化知识转移矩阵:
![]()
其中,Wuu1∈RM×D×D′和Wuu2∈RM×D′×D为两个动态网络权重;
f(a)=softmax(a+glo(a)),glo(⋅)为引入的全局信息(本任务中采用均值池化获取);
低秩矩阵分解:为减少模型参数,本文设置D′<D(实验中取D′=3);w1 , v1 , w2 and v2为可训练参数。在学习过程中,该方法能够充分考虑用户间的差异,实现辅助信息的高效个性化融合。
这里是论文最创新的地方:👉 每个用户都有自己的“融合方式”
👉 不是一个统一权重,而是:👉 ❗每个用户一个矩阵
- 生成两个动态权重矩阵Wuu1、Wuu2;矩阵是👉 动态参数(dynamic weights)
- 加入全局信息glo(⋅),用 softmax 归一化;
- 设D′=3(远小于嵌入维度 D),大幅减少参数;
- 模型自动学习每个用户的融合权重,充分考虑用户差异,实现个性化融合。
- 低秩分解:解决注意力机制计算量大的问题,轻量化、高效;
- 个性化:每个用户的融合权重不一样,比如有的用户依赖社交,有的依赖意图,模型自动适配。
最后,利用得到的矩阵Wuu1和Wuu2实现个性化多视图信息融合,使融合后的嵌入E^uu同时包含社交语义和全局意图语义的上下文信息:![]()
其中,E^uu融合了多视图的辅助信息,可作为增强型辅助信息嵌入提升模型的表征能力。
最终的用户嵌入通过加权融合得到:Eˉu=αEu+(1−α)Euu其中,α为权重调节参数,Eˉu∈RM×D为最终的用户嵌入。
公式12:👉 用两个矩阵对用户embedding进行变换,
用两个矩阵完成多视图个性化融合,得到Euu(包含社交 + 意图语义);
原始用户表示:Eu
👉 经过个性化融合:👉 Euu,👉 = “融合后更强的表示”
最终用户嵌入:偏好嵌入 + 融合嵌入加权求和 (最终表示 =原始偏好 + 融合信息)
α 是可学习的权重系数,平衡原始偏好和辅助信息。
( α = 1 → 只用原始信息、α = 0 → 只用融合信息 )
- 加权的目的:不丢失原始偏好,同时加入辅助信息,避免融合过度引入噪声;
- 解决第二个痛点:个性化、轻量化、低噪声的多视图融合。
总结融合模块 👉 每个用户用不同方式融合多种信息
4.5 Global-Local Contrastive Learning 全局 - 局部对比学习
为进一步解决信息融合过程中的噪声问题,本文提出全局 - 局部对比学习方法。
具体而言,采用InfoNCE 损失,优化同一用户在不同视角下嵌入的相似度:
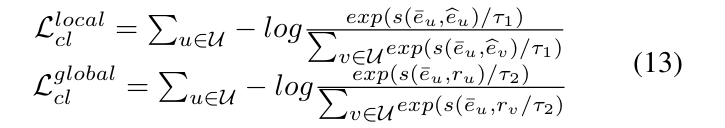
其中,τ1/τ2为温度系数,用于自动区分不同的负样本;s(⋅)为余弦相似度函数;v表示负样本用户。
为进一步解决融合中的噪声,提出全局 - 局部对比学习,用InfoNCE 损失优化同一用户的多视角嵌入相似度:
👉 同一个用户:👉 不同表示要接近 ✔👉 不同用户:👉 要远离 ❌
👉 用户表示要符合其“意图”
- 局部对比损失:让 最终用户嵌入eˉu与原始偏好嵌入e^u 尽可能相似;
- 全局对比损失:让 最终用户嵌入eˉu与全局意图嵌入ru 尽可能相似;
- τ1/τ2是温度系数(控制负样本权重),s(⋅)是余弦相似度。
- 局部对比:对齐 “最终特征” 和 “原始偏好”,保证不丢失核心偏好;
- 全局对比:对齐 “最终特征” 和 “全局意图”,保证细粒度意图被保留;
- 双重对比进一步降噪,让特征更纯净、更有区分度。
对于主推荐任务,本文采用经典的贝叶斯个性化排序(BPR)损失函数:
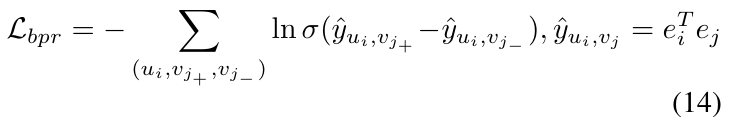
其中,ei∈RD和ej∈RD分别为从Eˉu和E^i中提取的用户 / 物品嵌入;y^ui,vj为推荐预测分数,由用户和物品嵌入的内积得到;σ(⋅)为 sigmoid 函数;vj+为正样本物品,vj−为负样本物品。
最后,将自监督损失与主推荐损失融合,构建多任务学习范式,总损失函数为:
![]()
其中, λ1 , λ2 , λ3为权重调优参数;Θ表示模型中所有可训练参数的集合;∥Θ∥2为 L2 正则项,用于防止模型过拟合。
主任务损失(推荐):用经典BPR 损失(推荐系统排序标准损失),优化用户对正样本物品的打分高于负样本;👉 正样本 > 负样本,模型要学:👉 score(A) > score(B)
总损失:主任务损失 + 全局对比损失 + 局部对比损失 + L2 正则化;λ1/λ2/λ3是权重系数,Θ 是模型所有可学习参数。
👉 这个模型做了三件核心事情:
🧩 1️⃣ 社交去噪 👉 用意见动力学过滤无效关系
🧩 2️⃣ 多视图建模 👉 用户 = 偏好 + 社交 + 意图
🧩 3️⃣ 个性化融合 + 对比学习 👉 提高表示质量
六、Model Analysis 模型分析
全局对比损失中,关于负样本节点v 的梯度可计算为:∥cv∥2∝1−(suTgv)2exp(suTgv/τ)其中,su=eˉu/∥eˉu∥,gv=rv/∥rv∥。
若正样本节点u 与负样本节点v 的相似度较高,在温度系数τ设置合理的情况下,∥cv∥2会更大,(Wu 等,2021)。合理设置温度系数 τ 后,正样本 u 和负样本 v 越相似,负节点的梯度越大。
换言之,相似度高的负样本会提供更大的梯度,从而引导模型的优化过程。这一特性能够充分利用辅助信息提供的监督信号,使节点嵌入更具判别性。
由此,局部和全局两个对比学习任务构成了联合优化目标。在优化过程中,最终用户嵌入Eˉu、全局意图嵌入Ru和用户偏好嵌入E^u会相互作用,找到满足两个对比任务的最优表征,从而保留不同视角的关联信息,更全面地刻画样本特征。
六、实验(Evaluation)
(一)数据集(Datasets)
实验用 3 个真实数据集:豆瓣(Douban,电影推荐)、Ciao(商品评论推荐)、Yelp(餐饮推荐)。共同特点:✔ 有用户-物品交互 ✔ 有社交关系
数据划分:训练:验证:测试 = 7:1:2。
评估指标:Recall(召回率)、NDCG(归一化折损累计增益)(Top-N 推荐核心指标)。
数据集统计见表 1,实验硬件:NVIDIA RTX 4090。
推荐数据集:共同特点 ✔ 有用户-物品交互 ✔ 有社交关系
标准机器学习流程:70%训练、10%调参、20%测试
- Recall@5/20:推荐的前 5/20 个物品中,用户真正喜欢的占比;
- NDCG@5/20:考虑排序的推荐精度,值越高效果越好;
- 3 个数据集覆盖不同稀疏度、不同场景,实验更有说服力。
📌 Recall 👉 找回多少“用户真正喜欢的物品”
📌 NDCG(重点)👉 不仅看“有没有推荐对”👉 还看“排得好不好”
👉 排得越靠前 → 分数越高
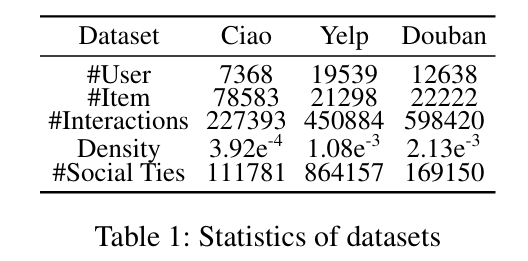
- Density密度越低 = 数据越稀疏:Ciao 最稀疏,Yelp 次之,Douban 最稠密;
- 本文核心优势就是处理稀疏数据,所以 Ciao 上提升最明显。
这个实验:👉 在极稀疏场景下进行👉 → 更能体现模型能力
(二)基线模型(Baselines)
基线分 4 类:
- 基础 GNN 模型:LightGCN(推荐系统 GNN 标杆);
- GNN 社交推荐:DiffNet、ESRF;
- 自监督推荐:SGL、NCL、DCCF;
- 自监督社交推荐:SEPT、MHCN。覆盖所有主流方法,对比全面。
👉 LightGCN ✔ 经典推荐模型 ✔ 不用复杂神经网络
👉 DiffNet, ESRF ✔ 加入社交信息
👉 SGL, NCL, DCCF ✔ 使用对比学习
👉 SEPT, MHCN ✔ 社交 + 自监督
(三)超参数设置(Hyperparameter Settings)
通用超参:嵌入维度 D=64,Xavier 初始化,Adam 优化器,GNN 层数 = 2。
RGCML 专属超参:
- 全局意图数 K:100/300/500/700/1000;
- 融合权重 α:0.5~0.99;
- 对比损失权重 λ1/λ2:0.01~0.5;
- 温度系数 τ1/τ2:0.05~0.2。
(四)整体性能对比(Table 2)
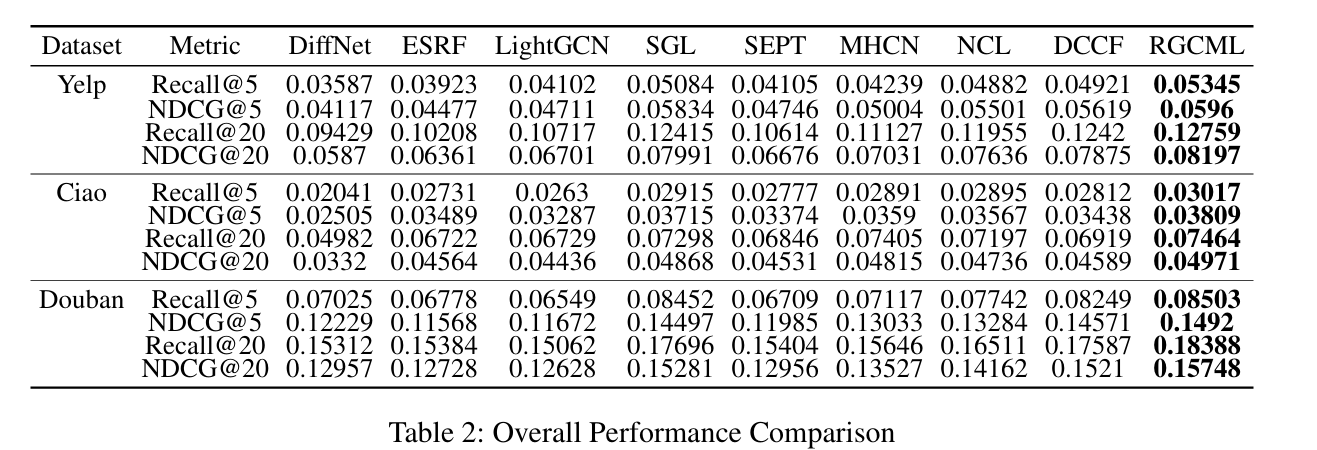
表 2 证明 RGCML 在 3 个数据集上均最优,核心结论:
- 越稀疏提升越大:Ciao(最稀疏)Recall@5 提升 3.5%,NDCG@5 提升 2.53%,验证稀疏鲁棒性;
- 自监督模型效果更优,本文全局 - 局部对比学习最大化多视角互信息,降噪效果极佳;
- 盲目用社交关系会掉点(Yelp 上 MHCN/SEPT 不如 SGL),但 RGCML社交去噪后,Yelp 上 Recall@5 提升 5.13%,证明社交噪声处理能力。
(1)在最稀疏的数据集Ciao上,RGCML提升最明显(Recall@5提升3.5%,NDCG@5提升2.53%)。
👉 因为:✔ 用了社交信息✔ 用了多视图融合
👉 稀疏数据 → 更依赖辅助信息
(2)使用自监督学习的方法通常表现更好,说明自监督信号的重要性。
👉 对比学习很关键 👉 RGCML优势:👉 global + local 双对比
(3)引入社交关系并不总是有效,例如在Yelp数据集上,一些社交模型表现不如SGL。
👉 社交信息可能是:❗噪声 ❗
👉 但:👉 RGCML仍然提升:Recall@5:+5.13%、NDCG@5:+2.16%
结论👉 RGCML = 能处理社交噪声
(五)消融实验(Table 3)
构建 RGCML 变体做消融实验,变体定义:
- w/o-imp:去掉隐式社交;
- w/o-exc:去掉显式社交;
- w/o-fus:用普通 MLP 替换本文融合模块;
- w/o-local:去掉局部对比;
- w/o-global:去掉全局对比;
- w/o-both:去掉所有对比学习。
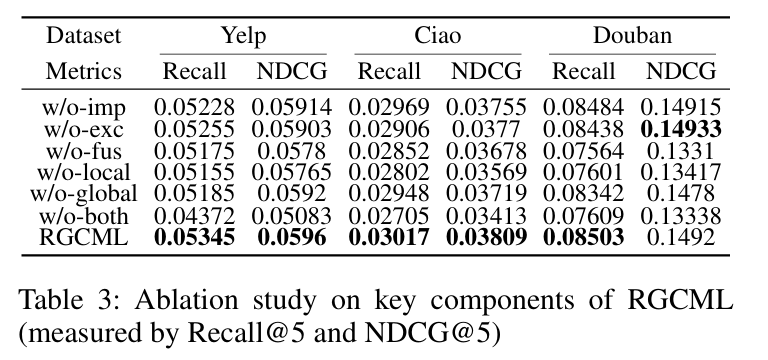
消融结果:
- 去掉所有对比学习(w/o-both):性能暴跌,NDCG@5 最多降 17.3%;
- 去掉局部 / 全局对比:性能均下降,局部对比影响更大;
- 去掉本文融合模块(w/o-fus):性能大幅下降,Douban 上降 12.1%;
- 去掉社交信息:Ciao/Yelp 下降明显,Douban 社交信息无用所以影响小。
消融实验验证创新点必要性:社交去噪、个性化融合、全局 - 局部对比学习,缺一不可,少任何一个模块效果都大幅下降。
👉 两种对比学习都重要、融合模块有效
(六)深度分析
1. 数据稀疏鲁棒性(Figure 2)
原文讲解:按用户交互物品数分 4 组,RGCML 在 交互越少(越稀疏)的用户上,提升越大,证明稀疏场景下优势极强。
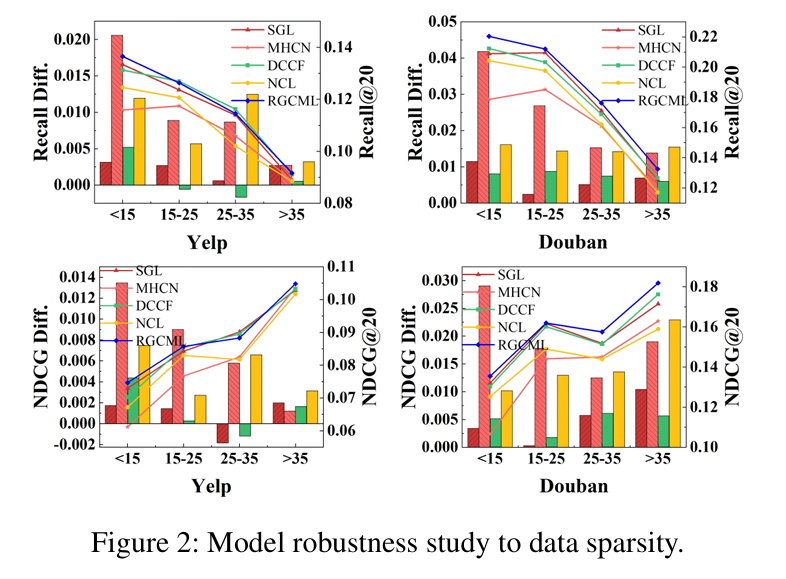
👉 在“交互少”的用户上提升最大
🧠 结论👉 RGCML特别适合:👉 ❗冷启动 / 稀疏用户
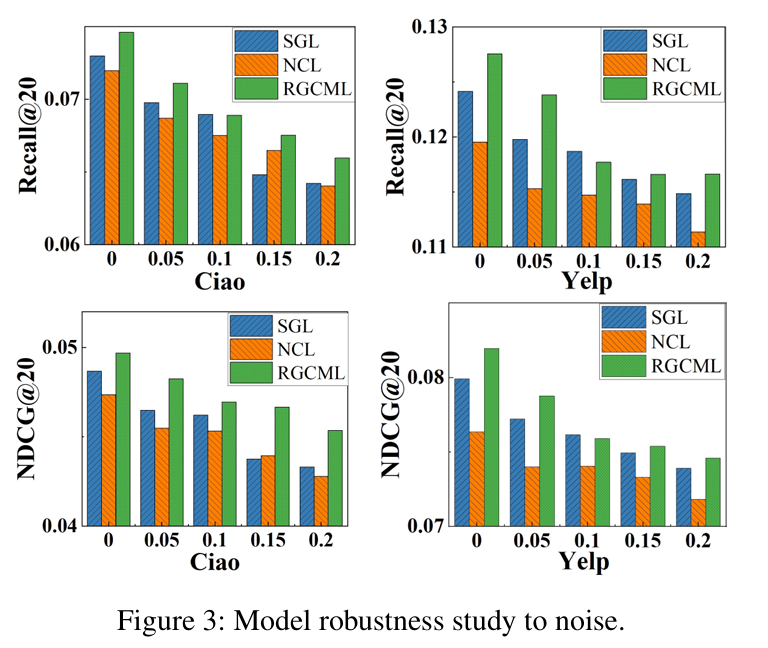
2. 噪声鲁棒性(Figure 3)
原文讲解:人工加 5%~20% 的噪声交互数据,RGCML 的性能几乎不下降,远优于 SGL、NCL,抗噪声能力碾压同类。
我们在训练集中加入不同比例的虚假交互数据(5%、10%、15%、20%)。
👉 人为加噪声👉 RGCML表现最稳定👉 抗噪能力强(核心卖点)
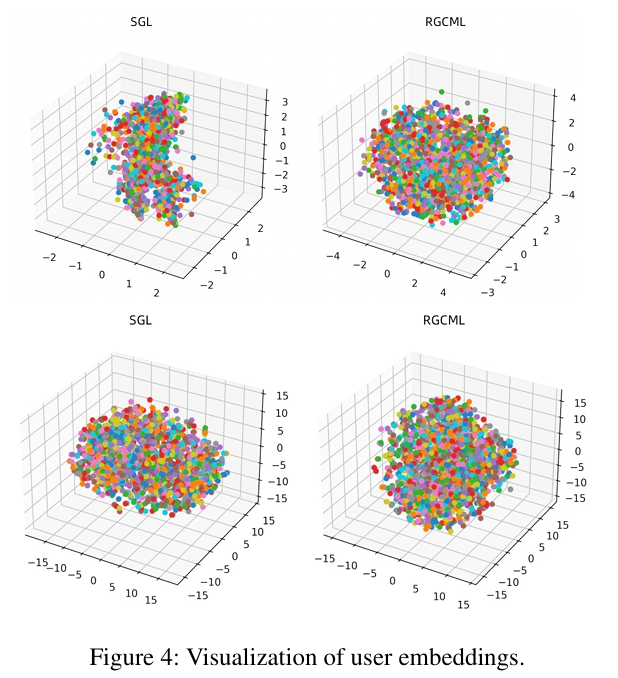
3. 嵌入可视化(Figure 4)
原文讲解:将用户嵌入投影到 3D 空间,RGCML 的嵌入分布更均匀、区分度更高,证明特征学习更有效。
我们将用户表示映射到三维空间进行可视化。
👉 看 embedding 分布 👉 RGCML更均匀、分布更清晰 👉 表示更好(区分度更强)
4. 训练效率(Figure 5)
原文讲解:每轮训练时间和主流模型相当,轻量化、高效,适合工业落地。
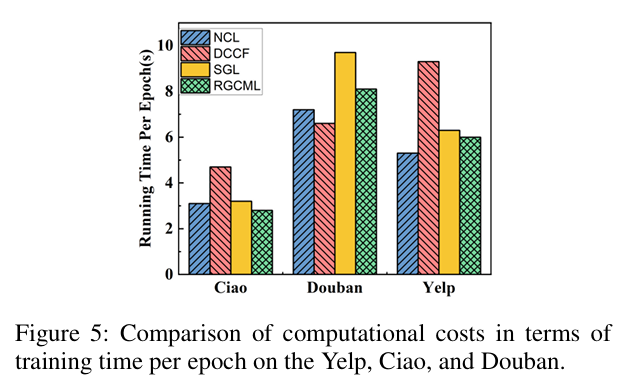
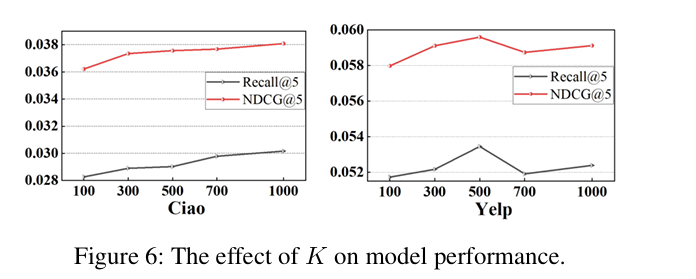
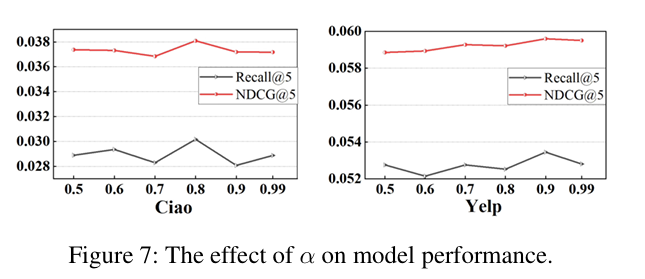
5. 超参分析(Figure 6-7)
原文讲解:
- 意图数 K:Yelp 上 K=500 最优,太多会引入噪声;
- 融合权重 α:0.8~0.9 最优,证明辅助信息必须融合,纯偏好效果差。
八、结论(Conclusion)
现有社交推荐模型虽优,但噪声破坏精度。本文提出 RGCML:
- 观点动力学社交去噪,解决社交噪声;
- 个性化多视图融合,解决辅助信息融合粗糙;
- 全局 - 局部对比学习,进一步降噪、优化表征。3 个真实数据集实验证明模型最优。
✅ 1️⃣ 效果好 👉 所有数据集最优
✅ 2️⃣ 抗稀疏 👉 对冷启动用户更强
✅ 3️⃣ 抗噪声 👉 加噪声仍稳定

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)