全网最通俗机器学习梳理文档|从炒菜到算命,小白也能无痛吃透AI全流程
🔥 家人们谁懂啊!刚入门机器学习时,被“特征工程”“过拟合”“Embedding”这些词按在地上摩擦,翻遍教程全是晦涩公式,越看越懵? 别慌!这篇文章堪称「机器学习小白救星」,全程不用复杂公式,只用炒菜、认人、养狗、算命等你每天都能接触到的生活场景,把机器学习全流程拆解得明明白白、生动有趣,甚至能让你像听相声一样轻松听懂! 文末附实操代码、避坑指南,还有进阶方向,专门为CSDN小伙伴定制,助力小白入门、大佬查漏补缺,求点赞、收藏、关注三连,一起抱团学AI,冲就完事儿了!🚀
写在前面:为什么你学不会机器学习?
AI时代已经全面来临,不管是面试、工作还是搞副业,机器学习都是加分项,但大多数人入门就劝退——不是教程太专业,就是比喻太生硬,明明是简单的逻辑,被讲得比高数还难。 今天,我们打破常规:不用背公式、不用死记概念,全程用「生活类比+实操案例」,以“房价预测”为贯穿全文的主线,从数据收集到模型部署,一步一步带你走完机器学习全流程,让你看完就敢上手写代码!

一、先搞懂:AI、机器学习、深度学习,到底啥关系?
这三个词天天被混着用,其实它们是「俄罗斯套娃」的关系——大套小,层层递进,用“炒菜”类比,一秒就能懂!

套娃拆解(炒菜版)
• 人工智能(AI):相当于“整个厨房系统”,核心目标是「让机器像人一样会做事」——比如会做饭、会聊天、会预测房价,涵盖所有让机器“拟人化”的技术。
• 机器学习(ML):AI的“核心烹饪方法”,不给机器写死菜谱,而是让它看大量例子自己总结规律——比如让机器看1000张红烧肉照片、1000份红烧肉做法案例,它自己就摸透“五花肉+酱油+冰糖+慢炖=红烧肉”的规律,不用你一步步教。
• 深度学习(DL):机器学习的“高级玩法”,用多层“神经网络”模仿人脑神经元,相当于给机器配了个「米其林后厨团队」,专门擅长处理图片、语音、文字等复杂数据——比如能精准识别照片里的猫、能听懂你的语音指令、能生成连贯的文章。
• 大模型(LLM):深度学习的“天花板”,相当于“看过全网菜谱的超级大厨”——比如ChatGPT、DeepSeek,它不仅懂所有菜系的做法,还能自创融合菜,甚至能跟你聊烹饪技巧,本质是“参数量极大、泛化能力极强的深度学习模型”。
模型到底是什么?
很多人被“模型”这个词唬住,其实它超简单——模型就是机器学习训练出来的「成果」,相当于一个“智能计算器”,你给它输入“原料”(比如房子的面积、地段、卧室数),它就能吐出“成品”(预测的房价),本质就是一套固定的判断规则或函数公式。
二、机器学习的3种“学习姿势”:有老师教、自己悟、靠奖惩
机器学习的核心就一句话:让机器从数据中找规律,再用规律预测新东西。根据“有没有人给机器喂标准答案”,分为3种学习方式,用生活场景类比,看完再也不会混!

1. 监督学习——有老师拿着答案教你(最常用、最基础)
类比:你教小孩认猫——拿100张猫的照片,指着照片说“这是猫”(给标准答案);再拿100张狗、兔子的照片,说“这不是猫”(给错误答案)。小孩看多了,自己就总结出猫的特征(尖耳朵、长胡须、会喵喵叫),下次看到新的猫,就能认出来。
核心:有“标签”(标准答案),机器跟着标签学规律。
常用算法(小白必记):
• 回归:预测「连续数值」——比如房价、股价、明天的温度,线性回归是入门级“Hello World”,简单粗暴,假设特征和结果是直线关系。
• 分类:判断「类别」——比如“这封邮件是垃圾邮件吗?”“这个图片是猫还是狗?”,常用逻 辑回归、决策树、随机森林。
2. 无监督学习——没答案,自己找规律(靠“悟性”)
类比:你给小孩一堆混在一起的乐高积木,不说话、不给任何提示,小孩自己会按“颜色”“形状”分堆——红色放一起、正方形放一起,这就是无监督学习的核心:聚类。
核心:没有标签(标准答案),机器自己从数据中找相似性,自动分组。
常用算法(小白必记):
聚类:把相似的数据自动分组——比如电商平台给客户分群(高消费客户、低消费客户)、 做用户画像。
降维:把复杂数据变简单——比如把100个特征(比如房子的面积、房龄、地段、装修等) 压缩成3个核心特征,方便后续处理(常用PCA算法)。
关联规则:发现隐藏的关联——比如超市发现“买啤酒的人,大概率会买尿布”,从而调整货 架摆放。
3. 强化学习——靠“奖惩”自学成才(靠“试错”)
类比:训练狗狗坐下——狗狗做对了(坐下),给它零食(奖励);做错了(站着不动),不理它(惩罚)。狗狗为了多吃零食,会不断试错,慢慢琢磨出“坐下=有零食”的规律,这就是强化学习。
核心:没有固定答案,机器通过“试错”获得奖惩,不断调整行为,最终找到最优策略。
常用算法:Q-learning、深度强化学习(AlphaGo下围棋就是这个原理——它不断和自己对弈,赢了就是奖励,输了就是惩罚,慢慢练出无敌棋艺)。
三、重点来了!10步走完机器学习全流程(房价预测实操版)
无论多复杂的AI项目,核心流程都逃不过这10步,我们用“房价预测”这个经典案例(小白最易上手),一步步拆解,每一步都配生活类比+实操代码,看完就能动手!
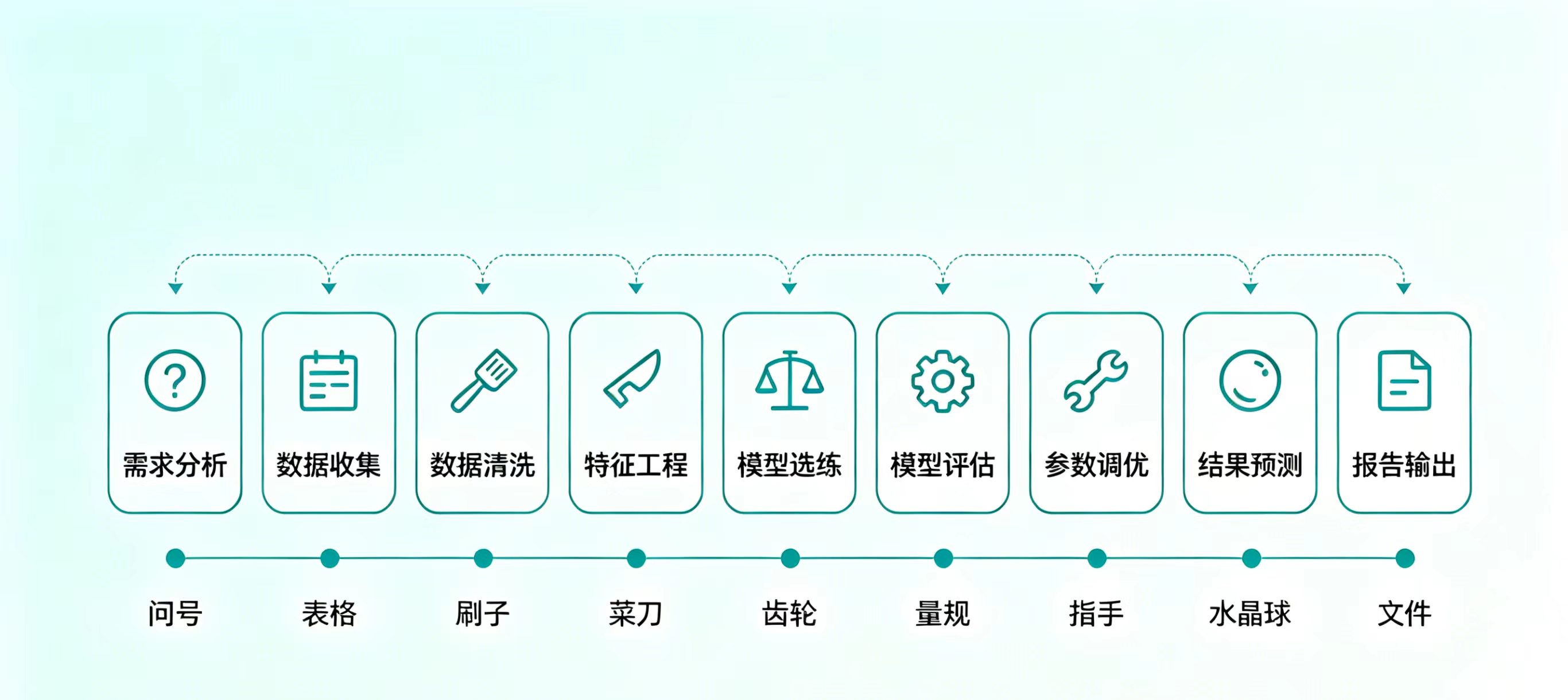 Step 1:需求分析——想清楚“要做什么”(相当于“确定要做什么菜”)
Step 1:需求分析——想清楚“要做什么”(相当于“确定要做什么菜”)
类比:做菜前要想清楚——做红烧肉还是番茄炒蛋?给老人吃还是小孩吃?口味要咸还是淡?需求分析就是干这个的,明确目标、指标和资源,不做无用功。
以房价预测为例:
• 目标:根据房屋的面积、卧室数、地段、房龄等信息,预测房屋的价格。
• 评估指标:用MSE(均方误差)衡量预测准不准,数值越小越好。
• 补充MSE:通俗说就是“预测值和真实房价的差值,平方后取平均值”。平方的作用有两 个: ① 消除正负抵消(比如预测高了5万和低了5万,不会相互抵消);
② 放大误差(比如误差3万,平方后变成9万,让模型更重视误差,拼命修 正)。
• 资源:Kaggle公开房价数据集(train.csv、test.csv)+ Python三件套(pandas、sklearn、 matplotlib)。
Step 2:数据收集——巧妇难为无米之炊(相当于“买菜”)
类比:做菜前要去菜市场买菜,没有新鲜的菜,再厉害的厨师也做不出好菜。数据就是机器学习的“菜”,没有数据,模型就无从学习。
实操步骤(直接复制代码就能用):
import pandas as pd
# 读取数据集
train = pd.read_csv('train.csv')
# 查看数据前5行,了解数据长什么样
print(train.head())
# 查看每列数据的缺失情况(有没有“坏菜”)
print(train.info())
# 查看数据的统计信息(均值、方差等,了解“菜的品质”)
print(train.describe())补充:EDA(探索性数据分析)——就像相亲前先看照片,心里有个底,知道数据长什么样、有没有缺失值、有没有异常值(比如“1平米的豪宅”这种明显不合理的数据)。
可视化房价分布(看“菜的整体情况”):
import seaborn as sns
# 直方图+密度曲线,查看房价分布
sns.histplot(train['SalePrice'], kde=True)
Step 3:划分数据集——考试不能做作业题(相当于“分菜”)
类比:你不能把所有菜都用来练习炒菜(训练),得留一部分菜用来试味(验证),最后留一部分菜用来正式上菜(测试)。数据集也一样,要分成3部分,避免“作弊”。

| 数据集 | 作用 | 比例 |
| 训练集 | 用来训练模型,让它学习房价和特征的规律(练习炒菜) | 60%~80% |
| 验证集 | 训练时调参,检验模型是否“学偏”(试味,调整咸淡) | 10%~20% |
| 测试集 | 最终检验模型真实水平,模型从未见过的数据(正式上菜,看客人反馈) | 10%~20% |
实操代码(划分数据集):
from sklearn.model_selection import train_test_split
# X是特征(房子的面积、卧室数等),y是标签(房价)
X = train.drop(['SalePrice', 'Id'], axis=1)
y = train['SalePrice']
# 划分训练集和验证集(test_size=0.2表示验证集占20%)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)关键提醒:为什么需要验证集?如果用训练集调参,相当于“做作业时偷看答案”,考试(测试集)肯定露馅;验证集就是“模拟考”,帮你调整模型参数,避免作弊。
Step 4:特征工程——数据界的“洗菜切菜”(最耗时、最拉差距)
类比:刚从菜市场买回来的菜,带泥、带根、有坏叶子,不能直接下锅,得洗、削、切、焯水,变成能直接烹饪的净菜。特征工程就是对原始数据做“预处理”,把“脏数据”变成“有用的数据”。
重点:特征工程占机器学习工作的60%~80%,是新手和高手的核心差距——新手直接用原始数据训练,高手会通过特征工程“喂给模型更好的料”,模型效果天差地别。

| 操作 | 通俗解释 | 具体例子 |
| 缺失值处理 | 填补数据中的“空缺”(比如有的房子没记录房龄) |
数值型特征(面积、房龄)用中位数填, 类别型特征(地段、装修)用众数填 |
| 缺失值处理 | 把文字变成数字(机器只认数字,不认文字) |
性别:男→1,女→0;城市:北京→1,上海→2 (或用独热编码) |
| 特征缩放 | 统一数据尺度(避免“面积0~500”和“房龄0~100”差距太大,影响模型) | 把面积和房龄都缩放到0~1之间,让它们“公平竞争” |
| 特征创造 | 组合现有特征,创造新的有用特征 |
“总面积 = 地上面积 + 地下室面积”“每平米单价 = 房价 ÷ 面积” |
| 特征选择 | 去掉没用的特征(避免“冗余信息”干扰模型) | 去掉和房价相关性极低的特征(比如“房屋编号”) |
重点补充:独热编码(One-Hot Encoding)——处理“城市”“装修风格”这类无序类别变量的“必技”。
比如处理“城市”特征:北京→[1, 0, 0]、上海→[0, 1, 0]、深圳→[0, 0, 1],这样能避免模型误以为“深圳(3)> 北京(1)”,导致判断出错。
Step 5:模型选择——挑个趁手的“锅”(适合的才是最好的)
类比:做红烧肉用炒锅,做排骨汤用高压锅,不同的菜用不同的锅,模型也一样——不同的任务,选不同的模型,房价预测是“回归任务”,这3个模型小白必学!

| 模型 | 核心特点 | 生活类比 |
| 线性回归 | 简单粗暴,假设特征和房价是直线关系,入门首选 |
用一把直尺量天下,不管数据多复杂, 都用直线拟合 |
| 岭回归(L2正则) | 在 linear regression 基础上加惩罚项,防止过拟合 |
直尺上绑了橡皮筋,不让它乱晃, 避免“拟合过度” |
| 随机森林 | 多棵决策树投票,抗过拟合能力强,效果更稳定 |
一群专家会诊,每个人(每棵树) 给出判断,少数服从多数 |
实操代码(导入模型):
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor
# 初始化模型
lr = LinearRegression() # 线性回归
ridge = Ridge(alpha=1.0) # 岭回归
rf = RandomForestRegressor(n_estimators=100, random_state=42) # 随机森林Step 6:训练与调优——“炼丹”开始(让模型学会预测)
类比:把处理好的净菜放进锅里,开火、调味、控制火候,不断试味调整,直到做出满意的味道。模型训练就是让模型不断“看”训练数据,调整内部参数,让预测值越来越接近真实房价。
核心概念:
• 训练:模型通过训练集,学习“面积、地段等特征”和“房价”之间的规律,调整内部的权重 (w)和偏置(b)。
• 超参数:训练前由你设定的“旋钮”,比如随机森林里有多少棵树(n_estimators)、每棵树 的最大深度(max_depth),相当于“做菜时的火候、盐量”。
• 调优:找到最优的超参数组合,让模型效果最好,常用“网格搜索 (GridSearchCV)”——相当于自动尝试各种火候和盐量,找到最好的配方。
实操代码(训练与调优):
from sklearn.model_selection import GridSearchCV
# 设定超参数组合(要尝试的“火候”和“盐量”)
param_grid = {
'n_estimators': [100, 200], # 树的数量
'max_depth': [10, 20, None], # 树的最大深度
}
# 网格搜索,自动找最优超参数
grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 输出最优超参数
print(grid_search.best_params_)重点避坑:过拟合 vs 欠拟合(小白最容易踩的坑)
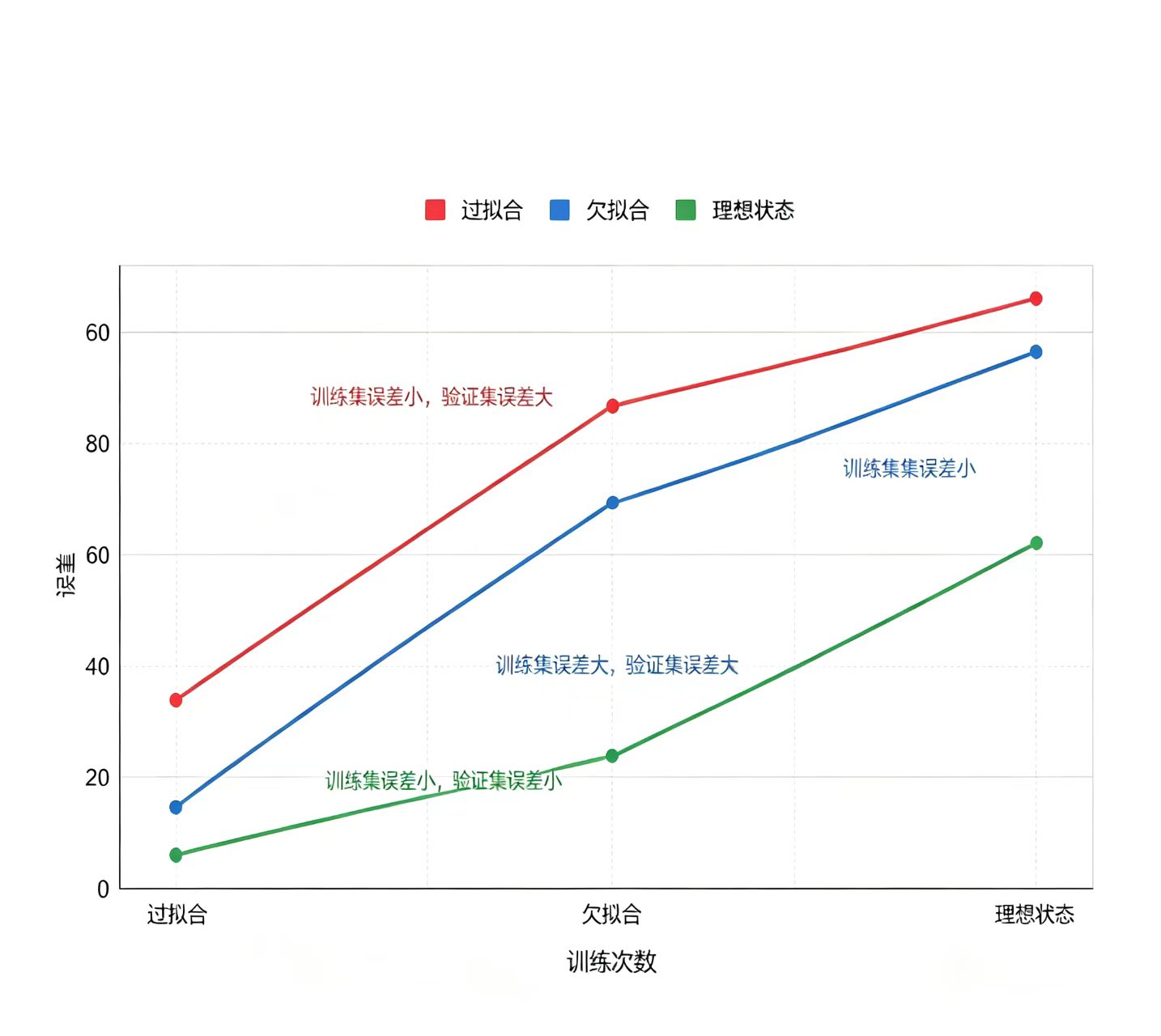
•欠拟合:模型太简单,连训练集(作业题)都做不对——训练集、验证集误差都很大,相当于“菜没煮熟,连自己都觉得难吃”。
• 过拟合:模型把训练集的“答案”背下来了,但测试集(考试题)稍微变一下就蒙圈——训练集误差极小,验证集误差飙升,相当于“把作业答案背得滚瓜烂熟,考试换个问法就不会做”。
• 理想状态:训练集误差低,验证集误差也低,模型真正理解了规律,相当于“菜煮得恰到好处,自己试味满意,客人吃了也称赞”。
Step 7:模型评估——看看“考了多少分”(检验模型效果)
类比:菜做好了,得尝一口,看看咸淡、火候对不对;模型训练好后,得用测试集(从未见过的数据)检验,看看预测准不准。
实操代码(模型评估):
from sklearn.metrics import mean_squared_error
import numpy as np
# 用最优模型预测测试集
best_rf = grid_search.best_estimator_
preds = best_rf.predict(X_test)
# 计算MSE和RMSE(RMSE单位和房价一致,更易理解)
mse = mean_squared_error(y_test, preds)
rmse = np.sqrt(mse)
print(f'模型最终RMSE:{rmse}')可视化预测效果(更直观):
sns.scatterplot(x=y_test, y=preds)
# 画一条对角线,点越靠近对角线,预测越准
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--')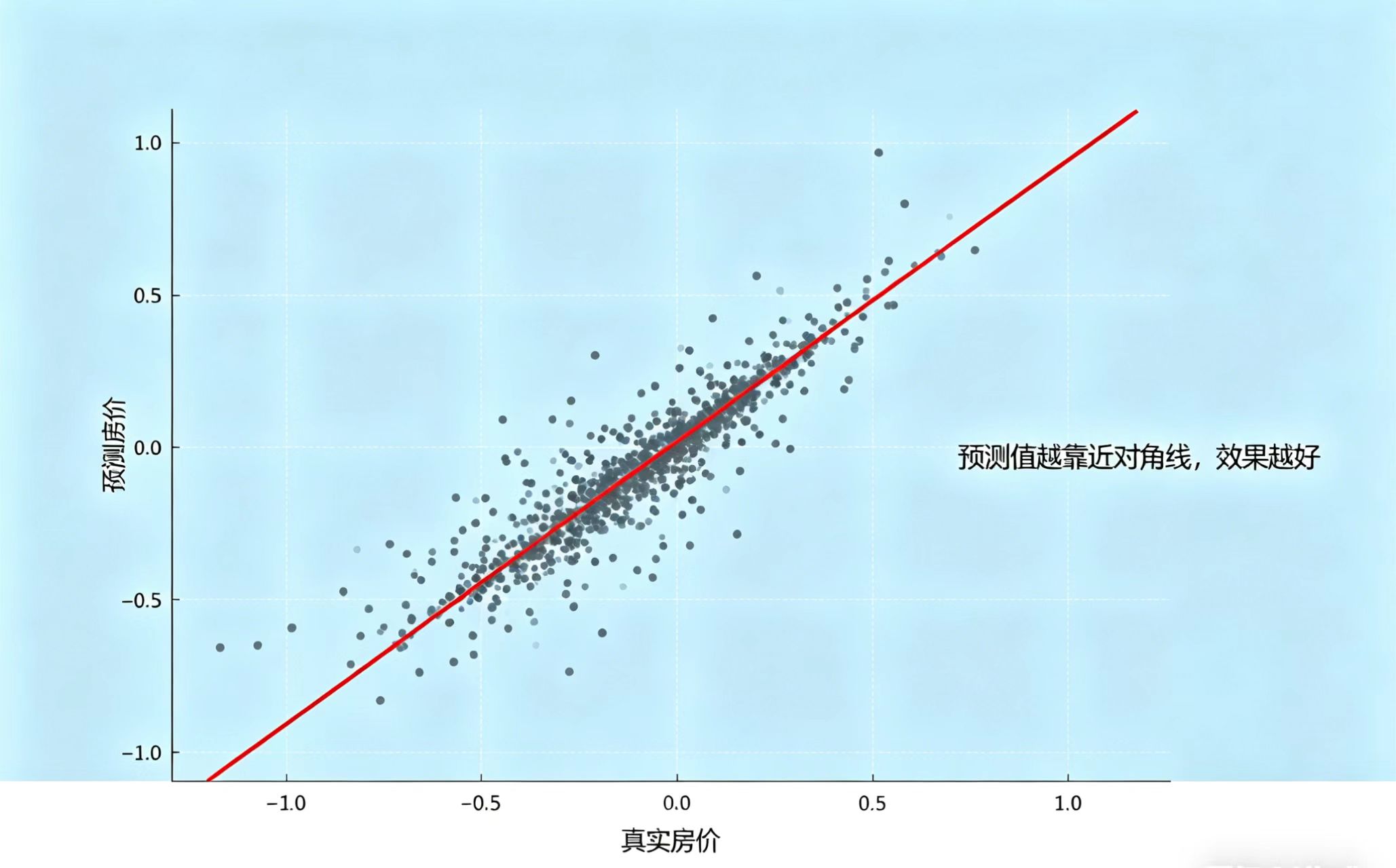 Step 8:优化改进——迭代才是王道(不好吃就调整)
Step 8:优化改进——迭代才是王道(不好吃就调整)
类比:如果尝一口菜,觉得太咸、太淡,或者火候不够,就调整盐量、火候,重新烹饪;模型如果RMSE太高(预测不准),就从3个方向优化,没有一蹴而就的模型,只有不断迭代的效果。
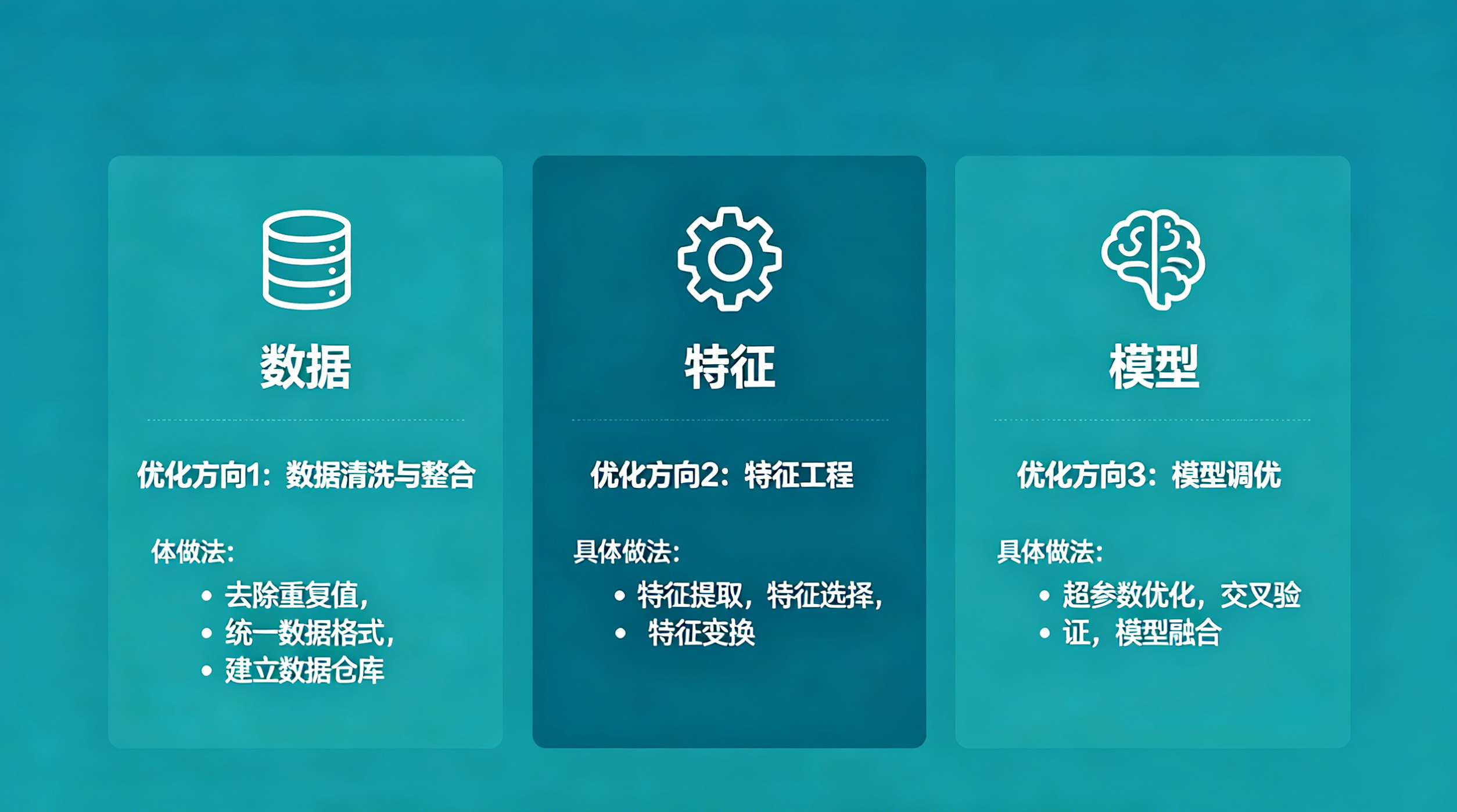
| 优化方向 | 具体做法 |
| 数据层面 | 收集更多数据、处理异常值(比如删掉“1平米豪宅”)、补充缺失值 |
| 特征层面 | 创造新特征(比如“每平米单价”)、剔除无用特征、优化编码方式 |
| 模型层面 | 换更强的模型(XGBoost、LightGBM)、更精细调参、尝试集成学习 |
提醒:机器学习没有“银弹”,不存在“一劳永逸”的模型,迭代优化才是核心——哪怕是大佬,也会不断调整模型,追求更好的效果。
Step 9:部署与监控——把模型送上“生产线”(让模型发挥作用)
类比:菜做好了,不能只放在厨房里自己吃,要端上桌,让客人品尝;模型训练好后,不能只活在Jupyter Notebook里,要部署上线,让别人能用(比如做一个房价预测网站、API接口)
实操步骤:
1.保存模型:用joblib保存训练好的模型,方便后续调用,不用重新训练。
import joblib
# 保存最优模型
joblib.dump(best_rf, 'house_price_model.pkl')2.部署模型:用Flask/FastAPI写一个API接口,让别人能通过接口输入房屋特征,获取预测房价。
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
# 加载模型
model = joblib.load('house_price_model.pkl')
# 定义预测接口
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
# 预处理数据(必须和训练时的特征工程一致,不然预测会出错)
features = preprocess(data)
# 预测房价
pred = model.predict(features)
return jsonify({'预测房价': pred[0]})
if __name__ == '__main__':
app.run(debug=True)重点提醒:部署后一定要持续监控——模型预测还准吗?新的数据分布变了吗?(比如疫情后郊区房价暴涨,旧模型的规律就不适用了),一旦发现性能下降,就得重新训练模型。
Step 10:反馈与迭代——活到老学到老(持续优化)
类比:客人吃了菜,反馈“太咸了”“不够烂”,下次做就调整;模型上线后,收集用户反馈(比如预测值和实际成交价差距太大),结合新的数据,重新训练模型,让模型“与时俱进”。
这就是MLOps的核心——让模型像软件一样,持续集成、持续交付、持续优化,不是训练一次就万事大吉,而是不断迭代,越用越精准。
四、进阶必知:Token、向量化、Embedding(小白也能懂)
前面的房价预测用的是“结构化数据”(表格形式,比如面积、房龄),但现实中大部分数据是非结构化的——文本(文章、评论)、图片、语音,计算机只认数字,怎么让它“读懂”这些数据? 「图片渲染提示」:此处插入一张流程示意图,从“文本”到“Token”,再到“向量化”,最后到“Embedding”,每个步骤配对应的卡通图标(文本→文字,Token→碎片,向量化→身份证,Embedding→语义坐标),直观展示转化过程。」
1. Tokenization(分词)——把句子“切碎”
类比:把一篇文章切成一个个词语,就像把一块肉切成小块,方便后续处理。
例子:“机器学习很有趣” • 单词级分词:["机器学习", "很", "有趣"] • 字符级分词:["机", "器", "学", "习", "很", "有", "趣"]
2. 向量化(Vectorization)——给每个词发“身份证号”
类比:给每个词语分配一个唯一的数字,就像给每个人发身份证号,让计算机能识别。
传统方法(One-Hot、TF-IDF):缺点很明显——向量维度会爆炸(比如有10000个词,向量就有10000维),而且词与词之间毫无关系(比如“猫”和“狗”的向量没有关联)。
3. Embedding(嵌入)——让向量“懂语义”
Embedding是向量化的“高级版”,核心思想:把每个词映射到一个低维的“语义空间”,语义相近的词,距离也近,让计算机真正“理解”词语的含义。
类比:把所有词语放在一张“地图”上,“猫”和“狗”挨得很近(都是动物),“猫”和“汽车”离得很远(毫无关联),这张“地图”就是Embedding空间。
常见Embedding方法:
• Word2Vec:静态词向量——“苹果”无论出现在“我吃苹果”还是“我用苹果手机”中,向量都 一样。
• BERT:动态词向量——“我吃苹果”(水果)和“我用苹果手机”(品牌)中的“苹果”,向量完 全不同,更贴合语境。
超有趣的向量运算:国王 - 男人 + 女人 ≈ 王后(计算机能通过向量,理解“国王”和“王后”的关系),这就是大模型能“读懂”语言的根本原因!
五、大模型微调三把斧:SFT、LoRA、蒸馏(平民也能玩)
现在大模型很火(比如LLaMA、DeepSeek),很多人觉得“大模型微调需要高配置,平民玩不起”,其实不然,这三把斧,让你用消费级显卡也能微调大模型,做自己的专属AI工具!
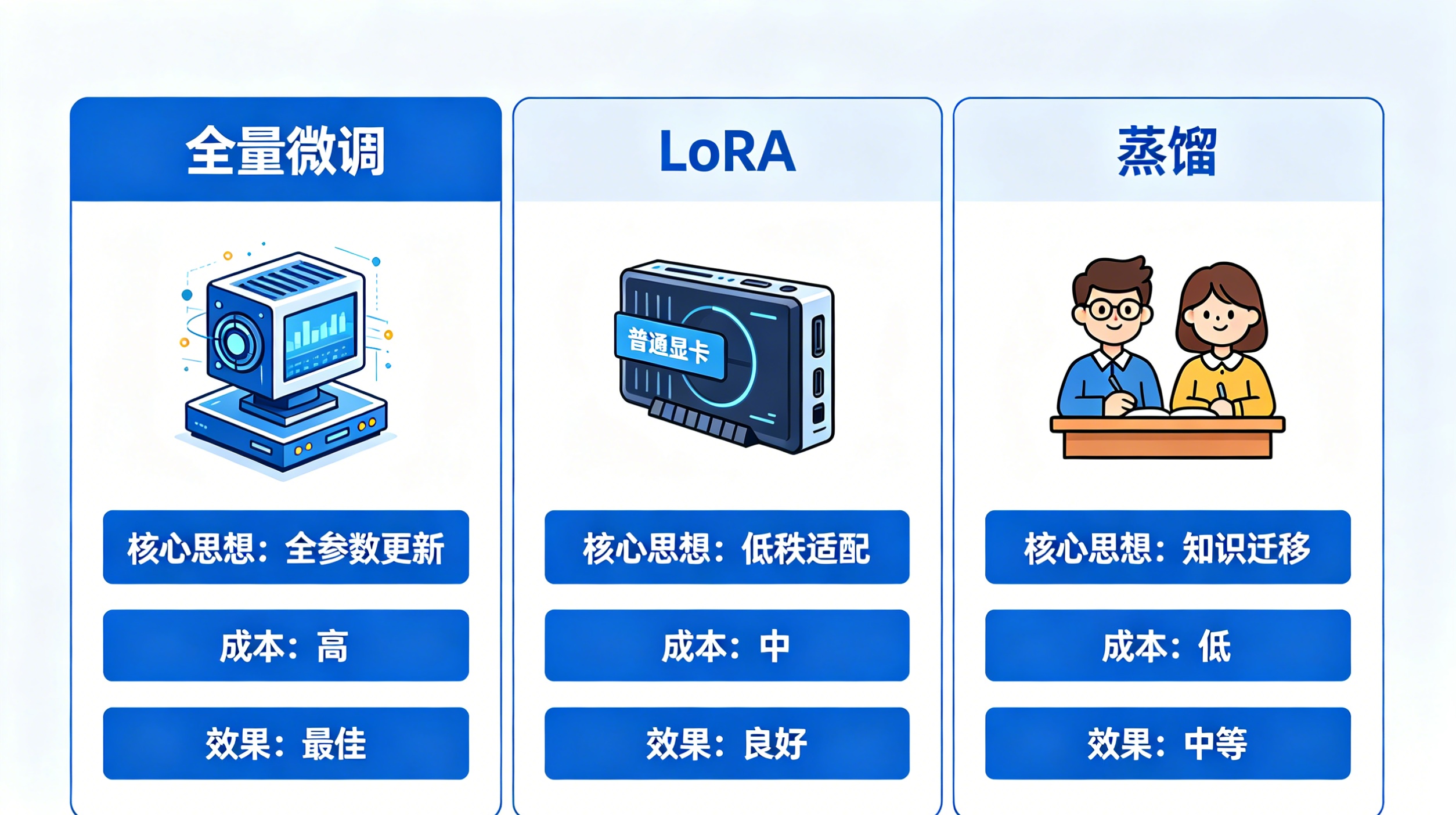
| 微调方法 | 核心思想 | 成本 | 效果 |
| 全量微调 | 更新大模型的所有参数,让模型完全适配你的任务 | 极高(需要多张A100显卡,普通人承担不起) | 上限最高,适配性最好 |
| LoRA/QLoRA | 不更新所有参数,只训练两个小矩阵(参数量<1%) | 极低(消费级显卡,比如RTX 4090就能跑) | 接近全量微调,性价比拉满 |
| 知识蒸馏 | 让大模型当“老师”,教小模型做题,把大模型的知识“浓缩”到小模型里 | 中等(普通显卡即可) | 小模型也能有不错效果,适合部署到手机、小程序 |
重点推荐:QLoRA——平民玩家的福音!它把大模型压缩成4-bit存储,训练时临时解压计算,一张RTX 4090就能微调70B大模型,不用花大价钱买高端显卡,小白也能玩转大模型微调!
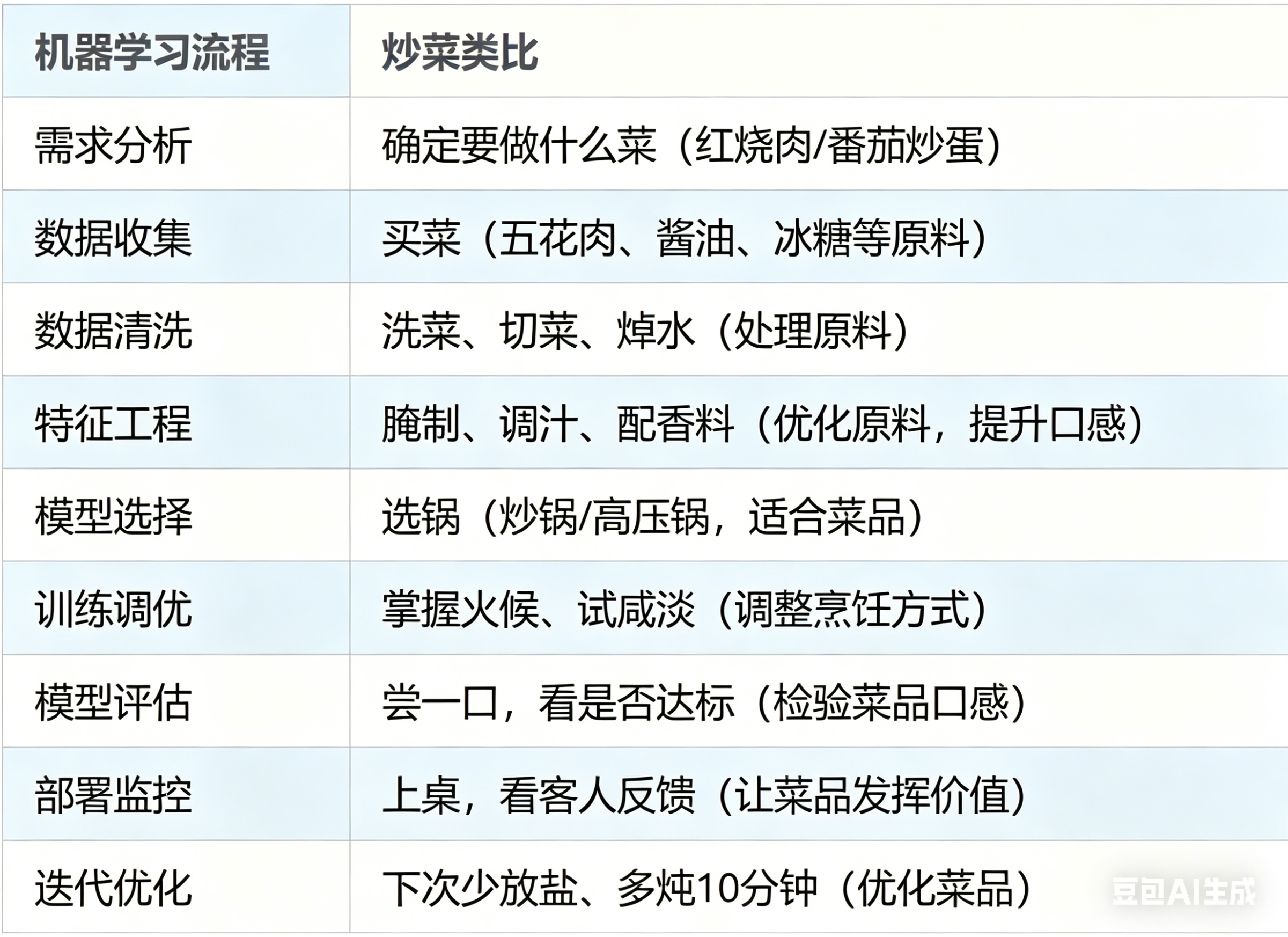
六、总结:一张“炒菜地图”,AI学习不迷路
其实机器学习全流程,本质就是“做一道大菜”,每一步都对应炒菜的环节,记住这个类比,再也不会记混流程!
 下一步学什么?(小白进阶指南)
下一步学什么?(小白进阶指南)
• 想深入理论:搞懂神经网络、反向传播、Transformer(大模型的核心),不用死记公式,先理解逻辑。
• 想动手实践:跑通一个Kaggle项目(房价预测、泰坦尼克号生存预测),把本文的代码实操一遍,动手比看教程更重要。
• 想玩大模型:学习LangChain、RAG、Agent,用大模型做实用工具(比如PDF问答、聊天机器人)。
最后说一句
AI学习没有捷径,没有“看完就能封神”的教程,但有了这张“全流程地图”,你至少知道每一步在干什么,不会再被晦涩的概念劝退。 小白不用怕,大佬也可以查漏补缺,希望这篇文档能帮到每一个正在学习机器学习的你!
🔥 求点赞、收藏、关注三连!关注我,下一篇带你吃透《深度学习入门:从神经元到Transformer,一文打尽》,一起从小白成长为AI大佬,冲!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)