AI 智能体评估的六个关键指标
一个用 3 次工具调用完成任务的智能体,与一个需要 9 次调用(包含重试、回溯、重复调用同一 API)的智能体,在任务完成度上都可能得到 1.0 的分数。
然而,端到端评分不会标记这种差异,但你的 token 账单和延迟会。
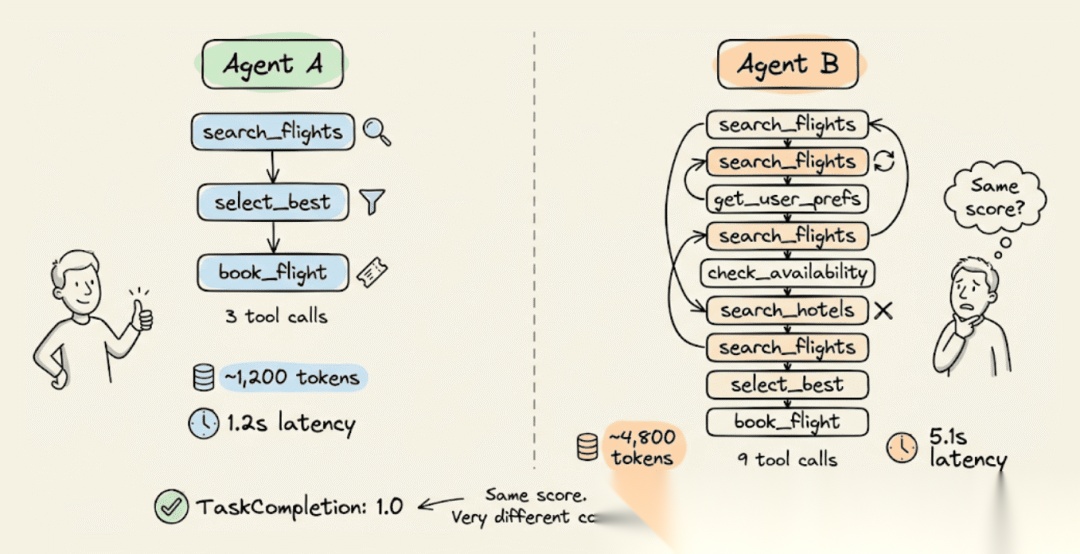
所以,正确评估智能体意味着要比最终输出更深入。你需要检查智能体是否做好了规划、是否遵循了计划、是否用正确的参数调用了正确的工具,以及是否没有浪费步骤。 今天,我们来看看如何使用开源的 DeepEval(https://github.com/confident-ai/deepeval) 评估框架(14k+ 星标)用几行代码进行端到端智能体评估。它提供了六个智能体指标来覆盖所有这些方面,外加一个对话模拟器,可以从场景定义自动生成多轮测试用例。
今天,我们来看看如何使用开源的 DeepEval(https://github.com/confident-ai/deepeval) 评估框架(14k+ 星标)用几行代码进行端到端智能体评估。它提供了六个智能体指标来覆盖所有这些方面,外加一个对话模拟器,可以从场景定义自动生成多轮测试用例。
智能体评估的两个层次
DeepEval 的六个指标在两个层次上运行,基于它们检查智能体执行的哪个部分:
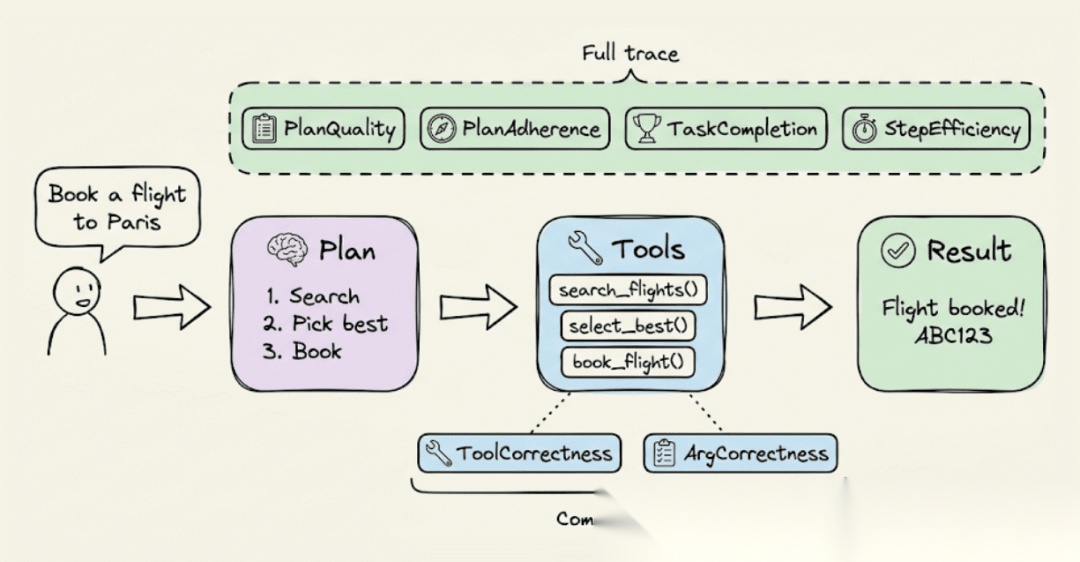
全链路指标(通过 @observe 追踪读取整个智能体执行过程)
| 指标 | 描述 |
|---|---|
| PlanQualityMetric | 评估智能体生成的计划对于任务是否逻辑清晰、完整且高效 |
| PlanAdherenceMetric | 将计划与实际执行进行比较,检查智能体是否遵循了自己的策略或在运行中途偏离 |
| TaskCompletionMetric | 基于完整轨迹评估智能体是否完成了用户的任务 |
| StepEfficiencyMetric | 即使任务已完成,也会对不必要的或冗余的步骤进行扣分 |
组件级指标(放大到特定 @observe 跨度中的工具调用)
| 指标 | 描述 |
|---|---|
| ToolCorrectnessMetric | 将实际调用的工具与预期工具进行比较,验证智能体是否选择了正确的工具 |
| ArgumentCorrectnessMetric | 验证传递给每个工具调用的输入参数是否对任务正确 |
将它们结合使用非常重要,因为一个智能体可能在 TaskCompletion 上得到 1.0 分,但在 StepEfficiency 上只得到 0.4 分。如果它为了获得一个结果而调用了同一 API 三次,它本应该缓存结果。用单一的通过/失败指标你永远不会发现这个问题。
从轨迹评估规划和执行
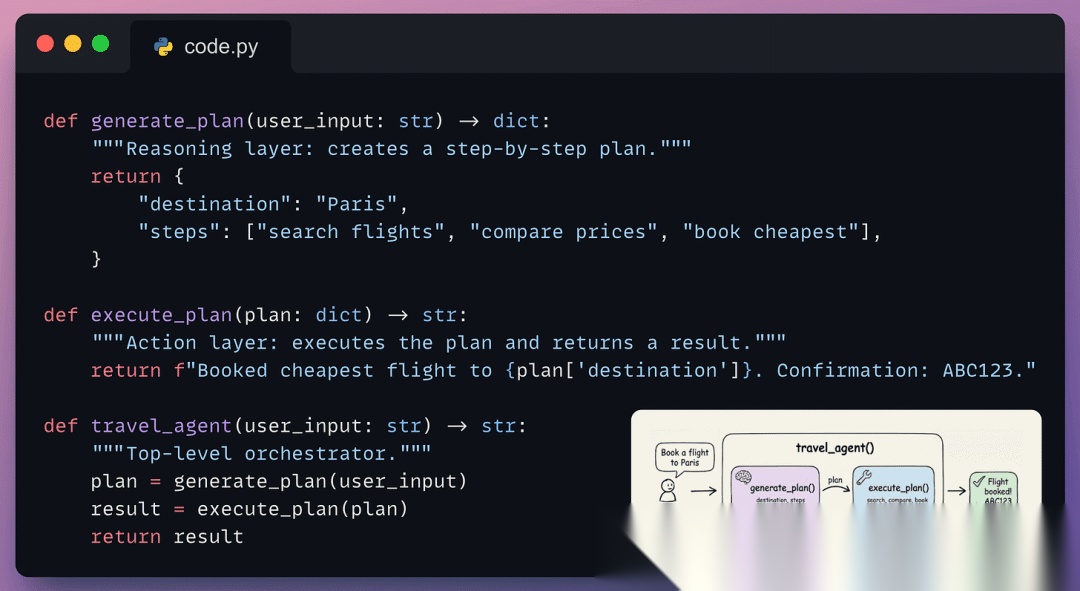
在运行任何指标之前,我们需要一个待评估的应用程序。这是一个包含三个函数的最小旅行预订智能体:
- •
generate_plan处理推理(需要采取哪些步骤) - •
execute_plan处理行动(调用工具完成任务) - •
travel_agent编排两者
这是使用 OpenAI、LangGraph 或 CrewAI 构建的任何智能体的替代示例。
要使用 DeepEval 评估这个智能体,我们需要使其执行可见。@observe 装饰器在不更改任何逻辑的情况下实现这一点:
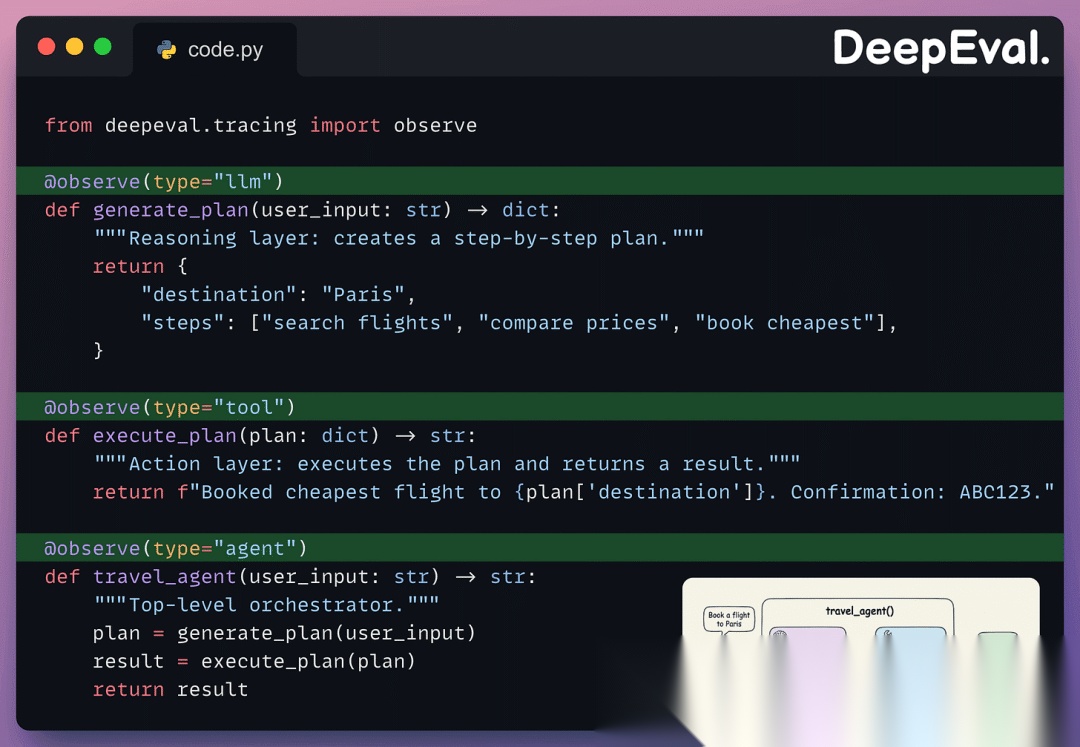
type 参数告诉 DeepEval 每个函数的角色:
- •
"agent"表示编排器 - •
"llm"表示推理 - •
"tool"表示行动
全链路指标从 "agent" 跨度开始读取整个轨迹。组件级指标放大到特定跨度,如 "tool" 或 "llm"。
接下来,定义一组用于评估的黄金测试用例(测试输入):
每个 Golden 是一个测试场景。在实践中,你会有 20-50+ 个黄金用例来覆盖边界情况(错误的日期、模糊的目的地、取消等)。
现在将四个全链路指标传递给 evals_iterator(),在循环内运行智能体,DeepEval 读取执行轨迹并对每个进行评分:
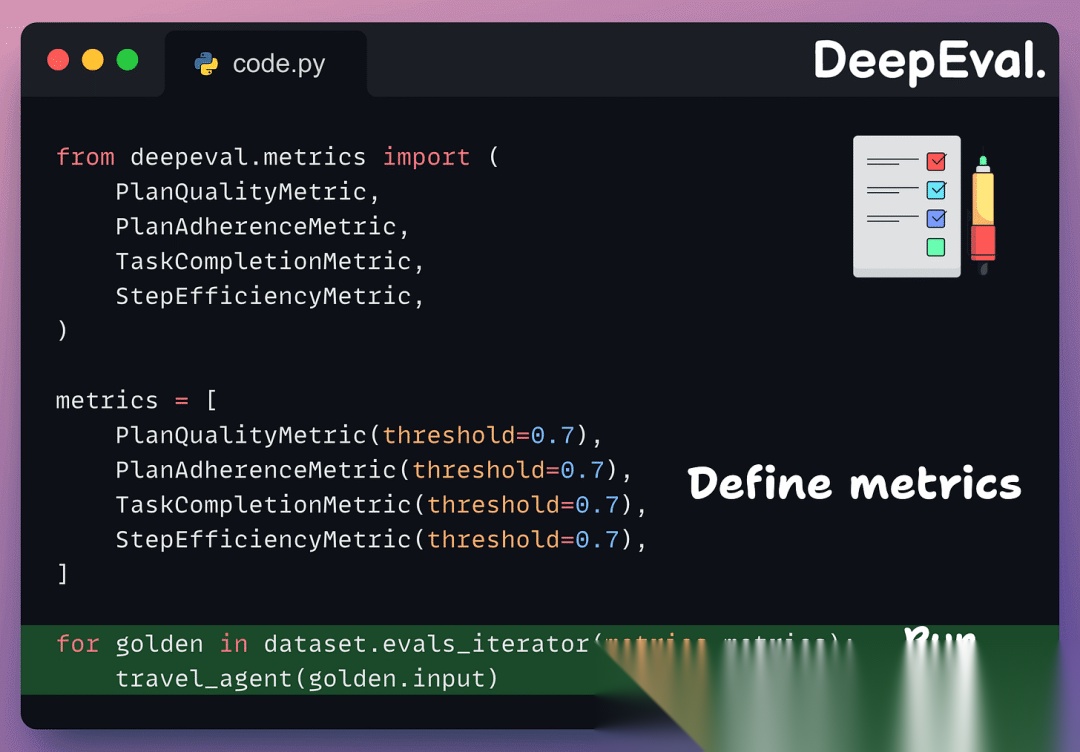
以下是我们在这个虚拟智能体上得到的结果:
| 指标 | 分数 | 问题 |
|---|---|---|
| PlanQualityMetric | 0.6 | 步骤(“搜索”、“比较”、“预订”)缺乏操作细节 |
| PlanAdherenceMetric | 0.3 | 智能体没有在轨迹中执行这些步骤 |
| StepEfficiencyMetric | 0.5 | 单独的规划阶段是冗余的 |
| TaskCompletionMetric | 1.0 | 通过(因为最终输出正确) |
这些分数讲述了一个清晰的调试故事。PlanQuality 标记出步骤(“搜索”、“比较”、“预订”)缺乏操作细节。PlanAdherence 确认智能体没有在轨迹中执行这些步骤。StepEfficiency 发现单独的规划阶段是冗余的。TaskCompletion 仍然通过是因为最终输出是正确的——这正是为什么你不能仅依赖它的原因。
在组件级别评估工具调用
全链路指标(如上使用)告诉你整体执行是否有效。
组件级指标放大到特定跨度(通常是决定调用哪些工具的 LLM 调用),独立评估工具选择和参数质量。
这两个指标在底层的工作方式不同:
- • ToolCorrectnessMetric 是基于参考的。它将实际调用的工具与预期的工具调用进行比较。
- • ArgumentCorrectnessMetric 是无参考的。它使用 LLM 评判器来评估给定输入时参数是否有意义,无需预期值。
你可以使用 @observe(metrics=[...]) 将两个指标附加到被追踪智能体内的特定组件上:
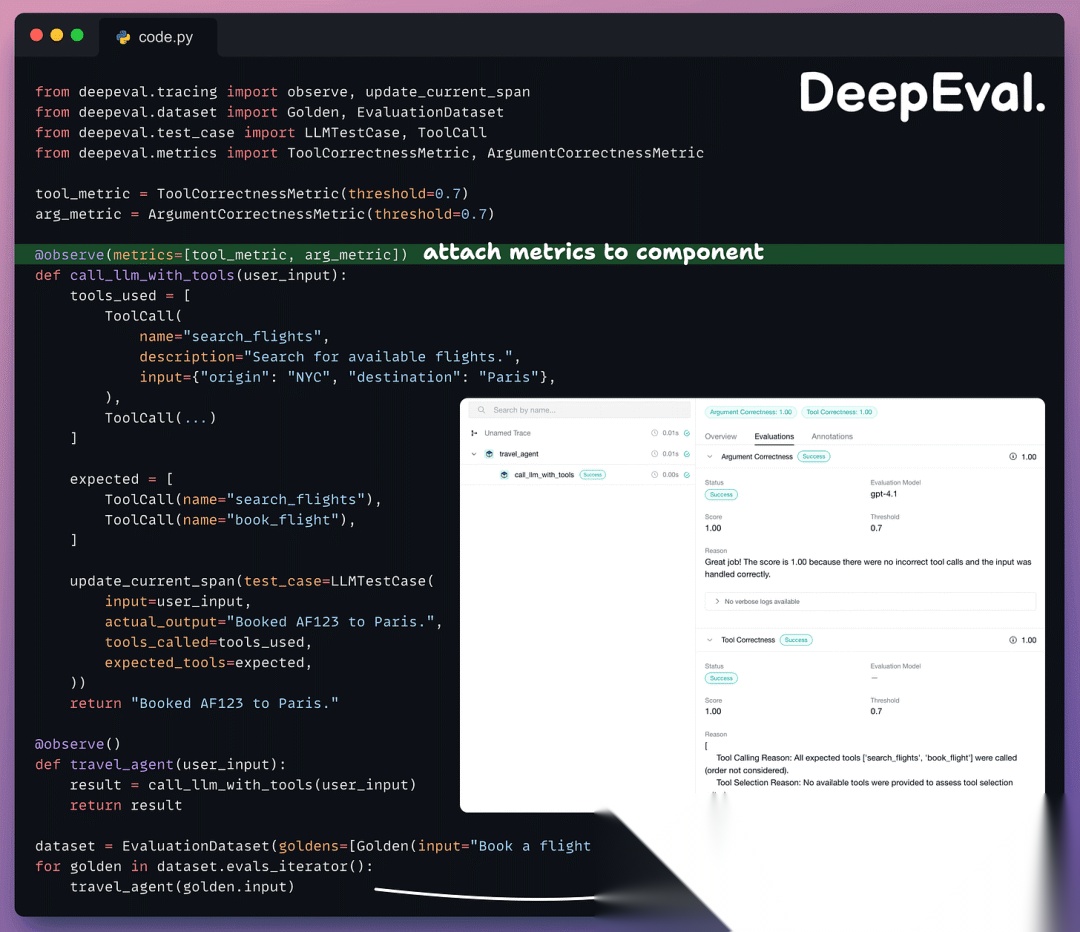
每个指标从同一个测试用例中提取它需要的字段。
模拟对话用于智能体测试
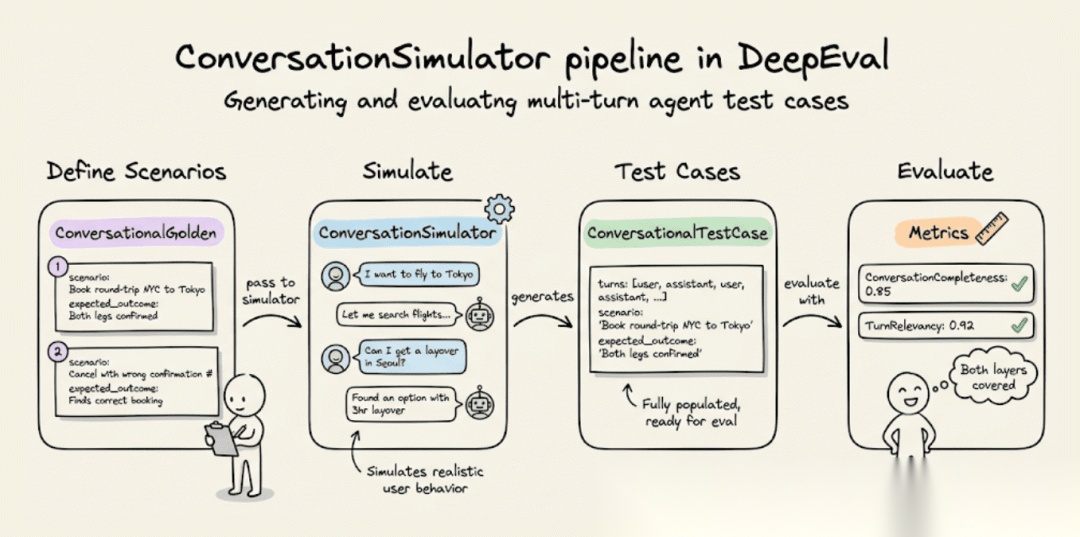
手动编写多轮测试用例无法扩展。你可以使用 DeepEval 的 ConversationSimulator 从场景定义生成逼真的对话:
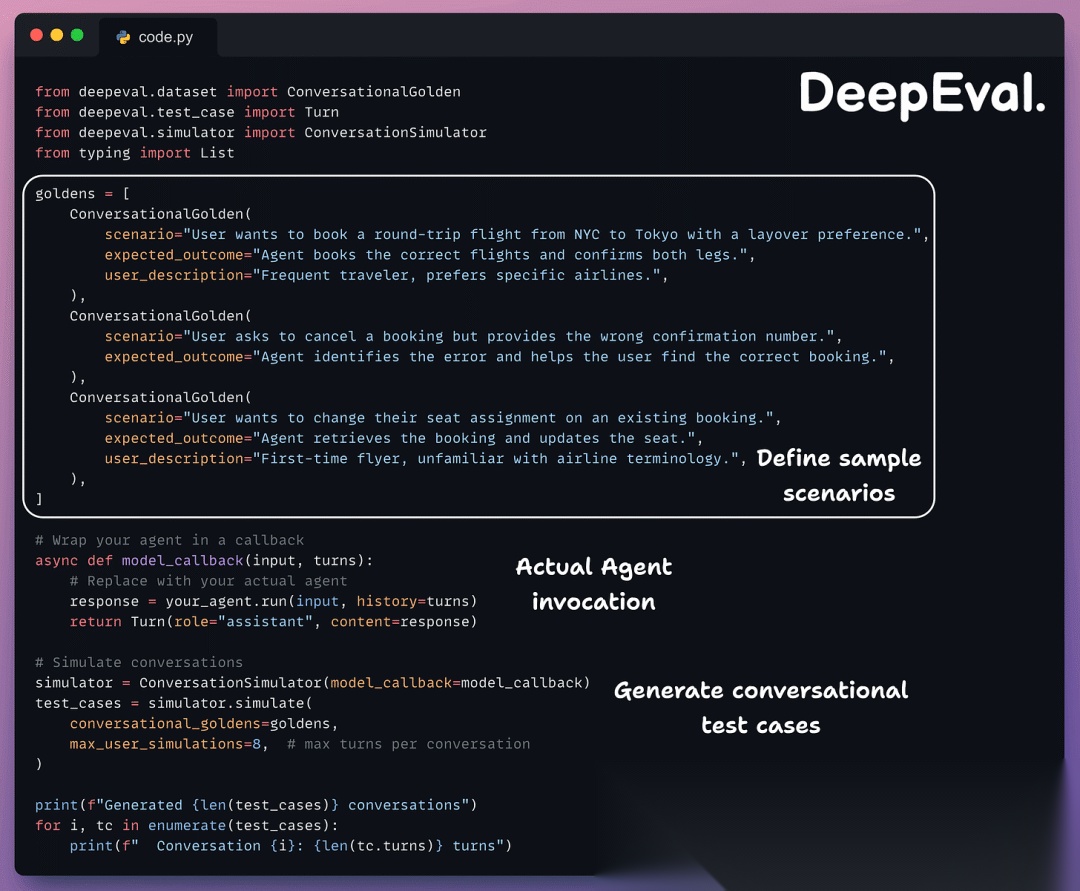
每个 ConversationalGolden 定义:
- • 一个场景(用户想要什么)
- • 一个预期结果(应该发生什么)
- • 一个可选的用户描述(模拟用户的人物设定)
模拟器扮演用户角色并与你的智能体交互指定的轮次,如果达到预期结果则提前停止。输出是一个 ConversationalTestCase 对象列表,其中包含完全填充的轮次。
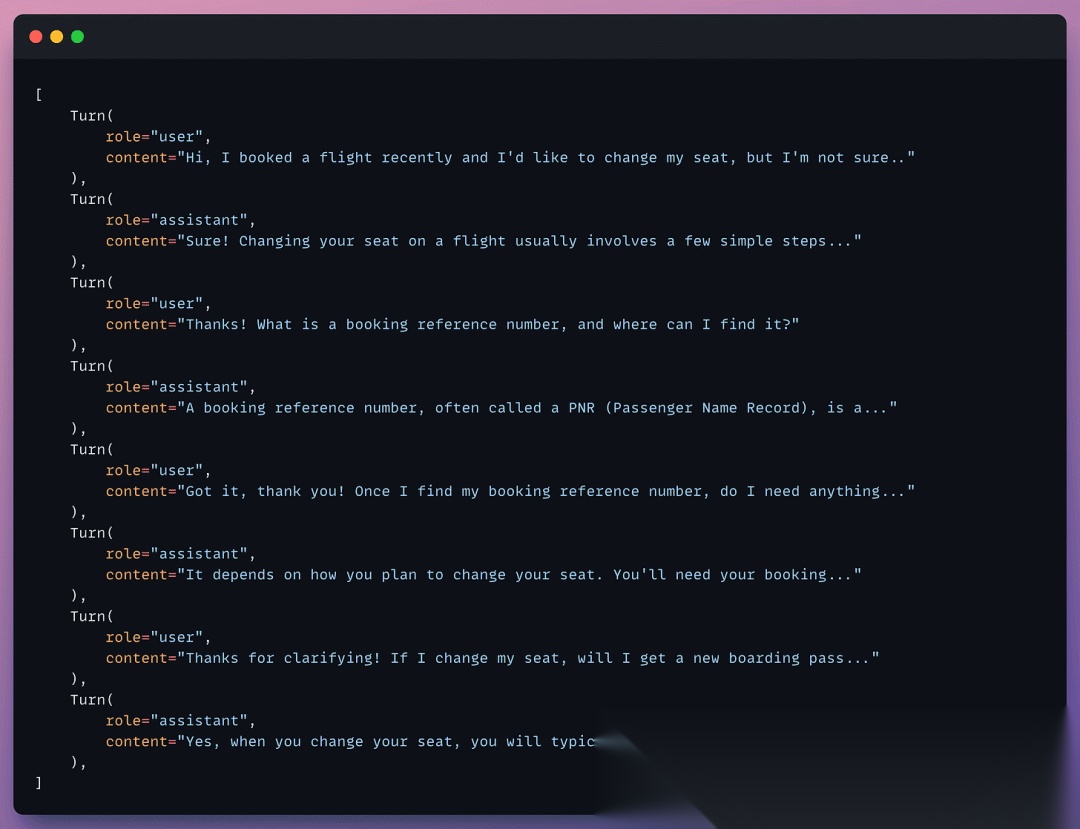
对模拟对话运行评估
一旦你有了模拟测试用例,用对话指标进行评估:
| 指标 | 描述 |
|---|---|
| ConversationCompletenessMetric | 从对话中提取每个用户意图,检查智能体是否满足了每个意图 |
| TurnRelevancyMetric | 对每个单独的助手回复评分,评估其与用户最新消息的相关性 |
一个对话可能在完整性上得高分(所有意图都得到满足),但在相关性上得低分——如果智能体在最终找到答案之前在中间轮次偏离了主题。
如下展现了一个模拟对话的过程:

整合起来
DeepEval 中智能体评估的完整工作流程:
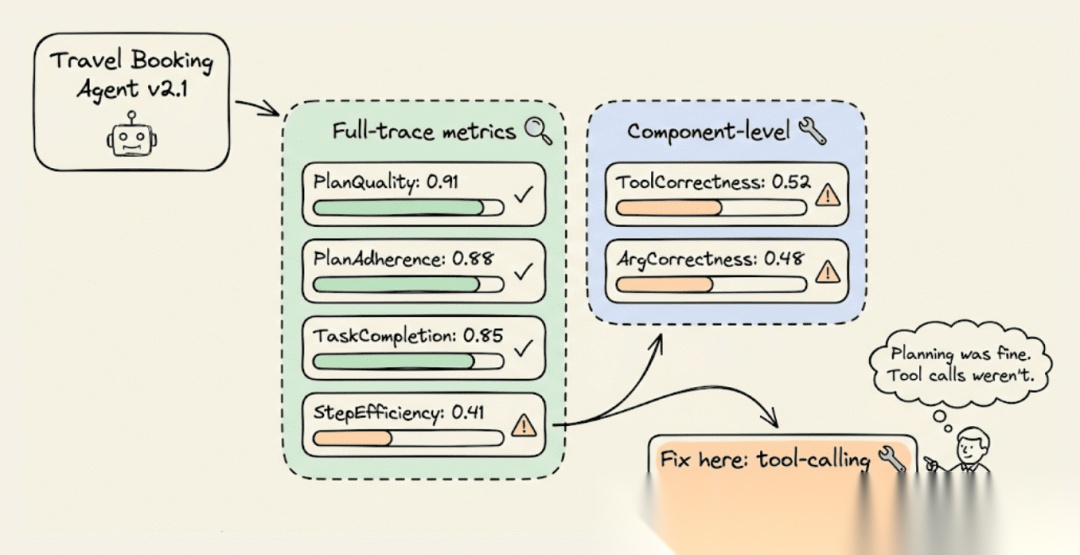
完整工作流程步骤
- 定义场景:创建 ConversationalGolden 对象(场景、预期结果、用户画像)
- 生成测试用例:使用 ConversationSimulator 对你的智能体生成逼真的多轮测试用例
- 全链路评估:应用 PlanQualityMetric、PlanAdherenceMetric、TaskCompletionMetric、StepEfficiencyMetric 通过 evals_iterator 评估整体执行
- 组件级评估:通过 @observe(metrics=[…]) 在 LLM 组件上应用 ToolCorrectnessMetric、ArgumentCorrectnessMetric 评估工具调用
- 对话评估:在模拟的多轮测试用例上应用 ConversationCompletenessMetric、TurnRelevancyMetric
- 获取结果:运行 evaluate() 获取每个指标带有评分原因的得分结果
一旦场景被定义,你可以模拟数百个对话,并在每次更改提示词、切换模型或更新工具时重新运行它们。
这些指标会精确分解问题出在哪里——比如计划质量可能在一个提示词更改后从 0.9 下降到 0.7,或者当智能体需要链接三个 API 调用时工具正确性可能下降到 0.5。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)