工程化RAG架构深度解析,打造企业级智能问答系统!
·
熟悉了Loader、Splitter、Embedding、Retriever这都只是“零件”。而这一篇文章,要做的是一件更难的事:
把零件,变成一台真正能跑的机器。
RAG 不是一个流程,而是一个系统
很多文章会画这样一张图:
Query → 检索 → 拼接 → LLM → 输出
这没错,但不够。
工程视角下的 RAG:
RAG = 数据系统 + 检索系统 + 推理系统 + 服务系统
工程级 RAG 总体架构
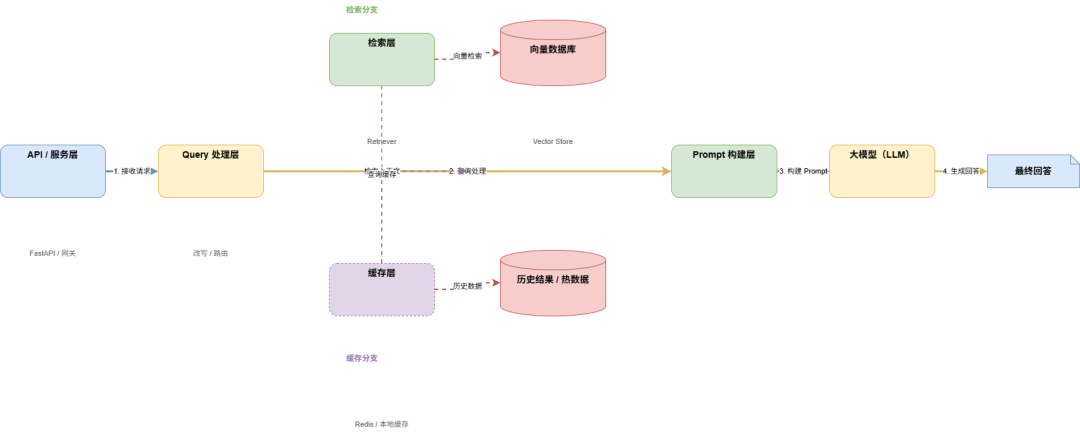
RAG 分层架构
用户请求 │ ┌───────▼────────┐ │ API / 服务层 │ ← FastAPI / 网关 └───────┬────────┘ │ ┌───────▼────────┐ │ Query 处理层 │ │(改写 / 路由) │ └───────┬────────┘ │ ┌───────────────┼───────────────┐ │ │┌───────▼────────┐ ┌────────▼────────┐│ 检索层 │ │ 缓存层 ││ Retriever │ │ Redis / 本地缓存 │└───────┬────────┘ └────────┬────────┘ │ │ ▼ ▼ 向量数据库 历史结果 / 热数据 (Vector Store) │ ▼┌────────────────────┐│ Prompt 构建层 │└────────┬───────────┘ ▼ 大模型(LLM) ▼ 最终回答
一句话总结:
Demo 是“一条线”,
工程是“一张网”。
数据层设计
这一层,90%的人会忽略,但它决定效果天花板。
数据处理流水线
原始数据 → 清洗 → 切分 → 向量化 → 入库
核心设计点
数据标准化
- • 去噪(HTML标签、乱码)
- • 统一格式(JSON / Document)
Chunk 设计
推荐策略:
- • 300~800 tokens
- • overlap 10%~20%
元数据
{ "source": "交通规划.pdf", "page": 12, "type": "政策", "city": "北京"}
👉 作用:
让检索从“模糊”变“可控”。
检索层设计
这里你可以呼应上一篇。
检索架构升级
从:
单一 Retriever
升级到:
多路检索 + 融合
``````plaintext
Query │ ┌────────┼────────┐ │ │ │向量检索 关键词检索 规则检索 │ │ │ └────────┴────────┘ │ 融合排序 │ Top-K
核心思想
不要相信单一检索器。
融合策略
- • 加权融合
- • 去重
- • rerank(强烈推荐)
uery 处理层
这一层,往往是“效果翻倍”的关键。
Query 改写
用户:这个怎么搞?→ 改写:“如何实现GIS交通数据分析流程?”
Query 路由
根据问题类型走不同链路:
| 类型 | 处理方式 |
|---|---|
| 知识问答 | RAG |
| 数值计算 | Tool |
| GIS分析 | Agent |
在 LangChain 中:
- • RouterChain
- • Agent
Prompt 构建层
典型 Prompt 模板
你是一个GIS专家,请基于以下内容回答问题:{context}问题:{question}
优化点
- • 限制回答范围(避免幻觉)
- • 标注来源
- • 指定风格(专业 / 简洁)
一句话:
Prompt 决定“表达方式”,
检索决定“内容质量”。
为什么要缓存?
两个原因:
- • 成本(LLM 很贵)
- • 延迟(用户体验)
常见缓存策略
- • Query → Answer
- • Query → 检索结果
工具:
- • Redis
- • 本地缓存
在线 vs 离线
离线
- • 数据处理
- • 向量构建
- • 索引更新
在线
- • Query 处理
- • 检索
- • 推理
👉 一句话总结:
重的活放离线,快的活留在线。
GIS 场景下的 RAG 架构
GIS 专属架构
Query │语义解析 │┌───────────────┐│ 语义检索 ││(政策/知识) │└──────┬────────┘ │┌──────▼────────┐│ 空间分析模块 │(QGIS / PostGIS)└──────┬────────┘ │ 数据结果 │ LLM解释
核心升级点
从“回答问题” → “解决问题”
示例
问题:北京哪些区域适合建设风电站?流程:1. 检索政策2. 分析风速数据3. 空间筛选4. LLM总结
这已经不是 RAG: 是 RAG + Agent推荐技术栈
- • 后端:FastAPI
- • 框架:LangChain
- • 向量库:Milvus / Chroma
- • Embedding:BGE
- • 前端:Mapbox / Vue
- • 缓存:Redis
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)