YOLO26实战:构建99.3% mAP50的数字识别系统(附全流程代码)
摘要
本报告基于YOLO26目标检测框架,构建了数字的识别系统。系统共包含10个类别,训练集、验证集和测试集分别为966张、99张和50张图像。模型在验证集上取得了mAP50为0.993、mAP50-95为0.917的优异性能,精度和召回率分别达到0.993和0.982。混淆矩阵分析显示,模型对各类别数字的识别准确率接近100%,无明显类别混淆问题。训练过程中的损失函数持续下降,mAP指标稳定上升,表明模型训练充分且收敛良好。该系统在低置信度下即可实现高召回率,在高置信度下仍保持高精度,具备良好的实际部署价值。
关键词:YOLO26;数字识别;目标检测;深度学习;计算机视觉
详细功能展示视频
https://www.bilibili.com/video/BV1N1oKBKEeA/
目录
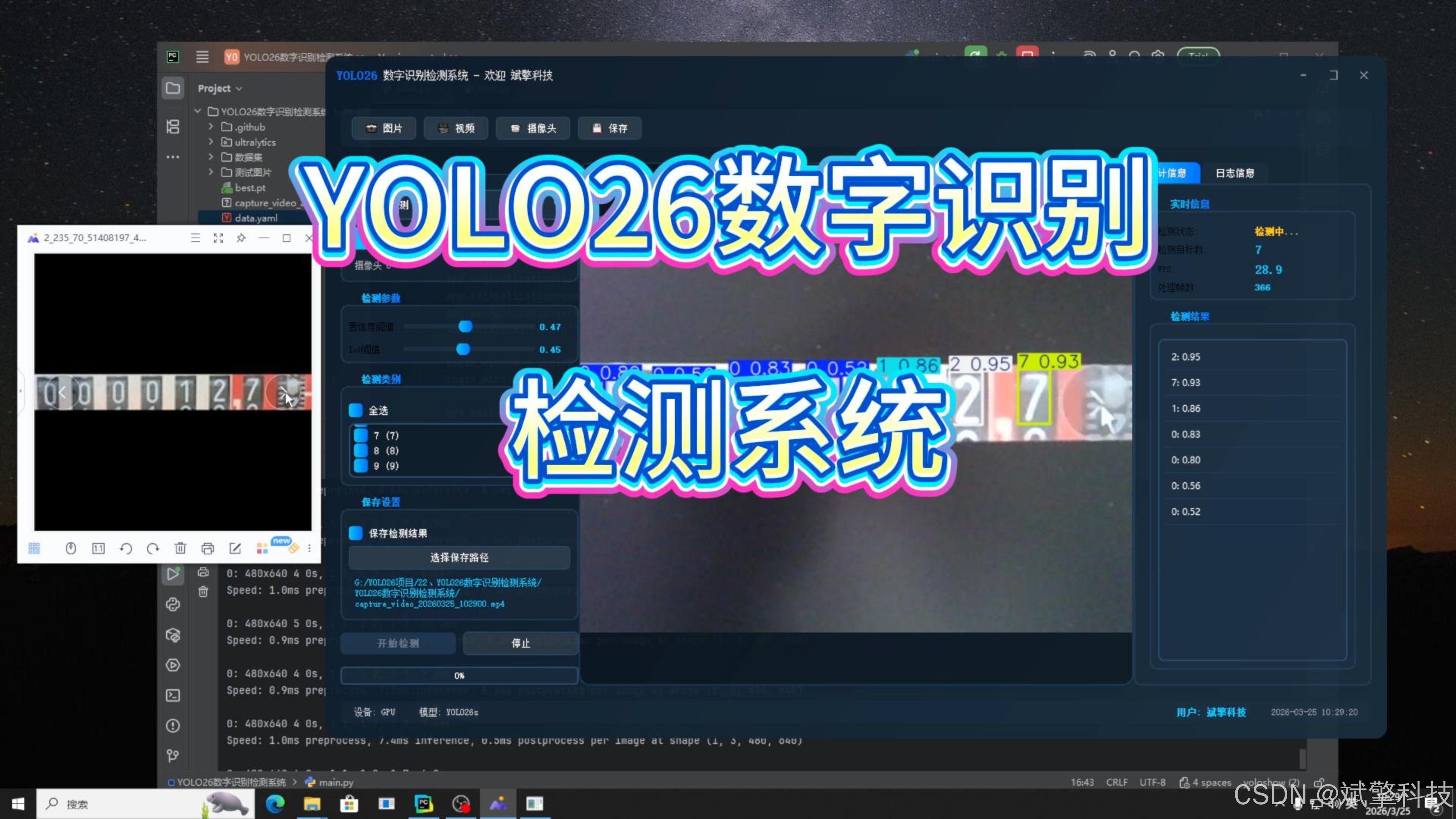
功能模块
✅ 用户登录注册:支持密码检测,密码加密。
注册
登录
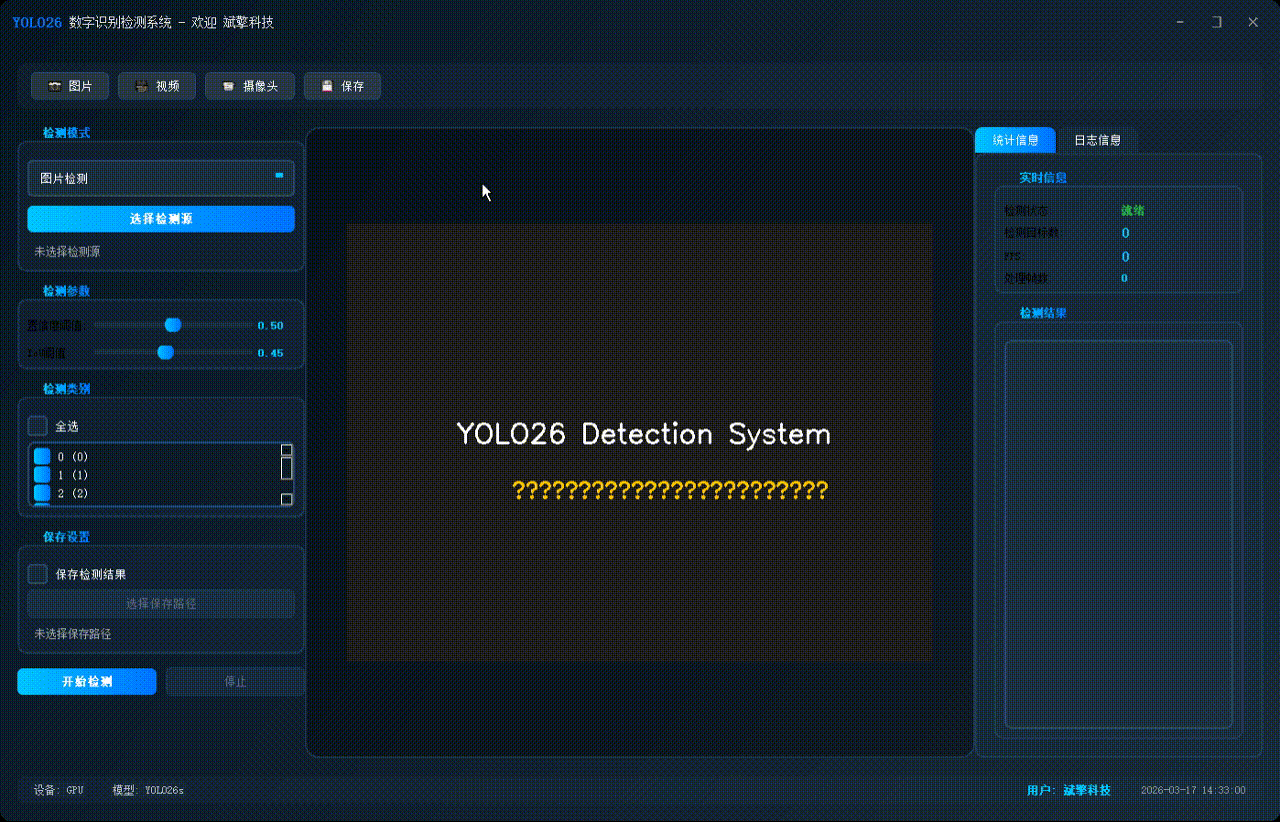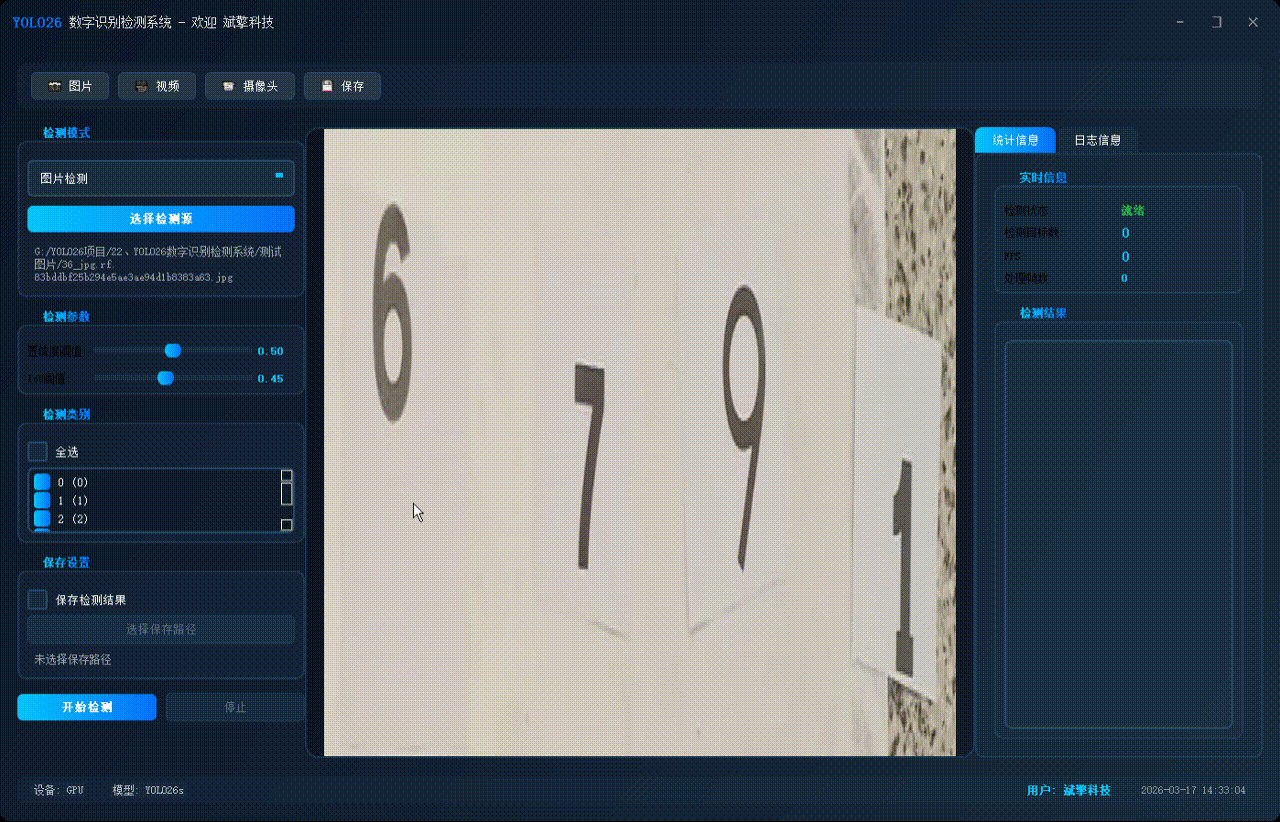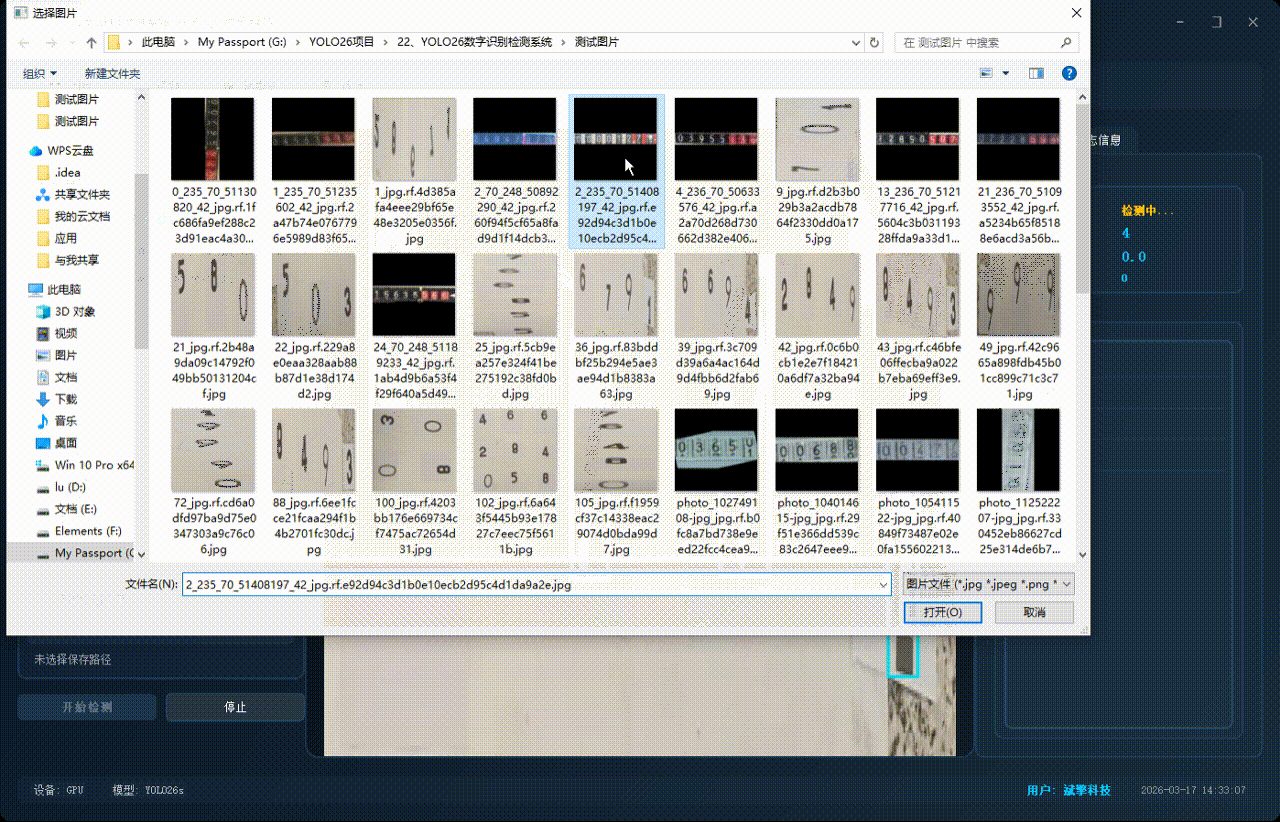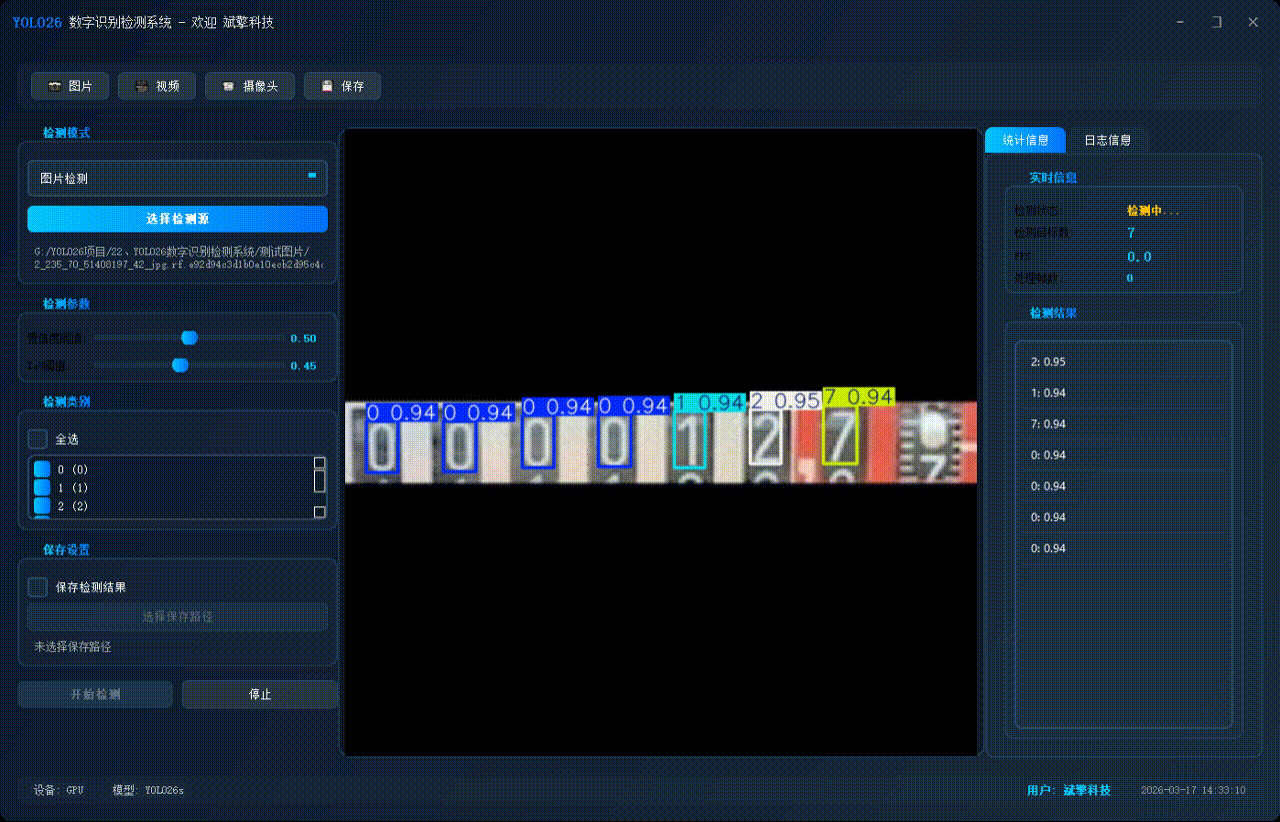
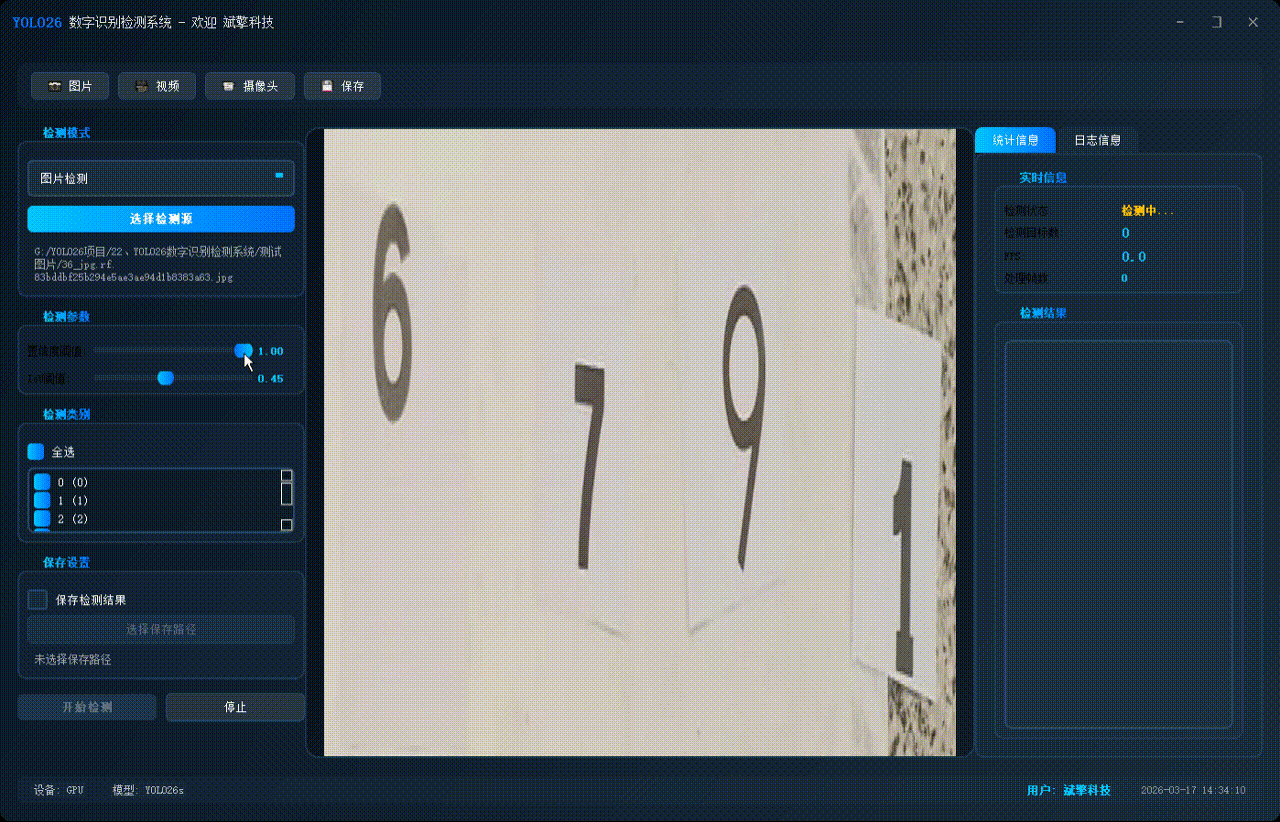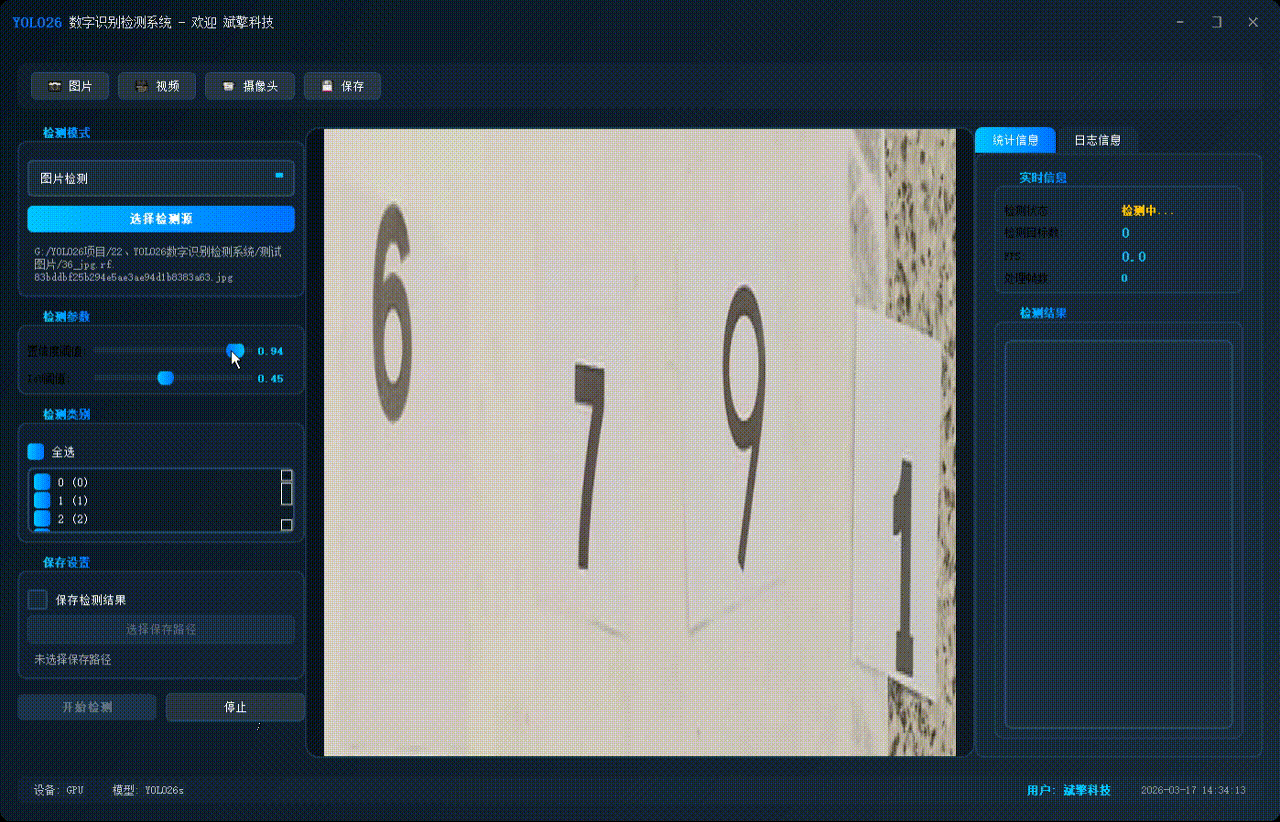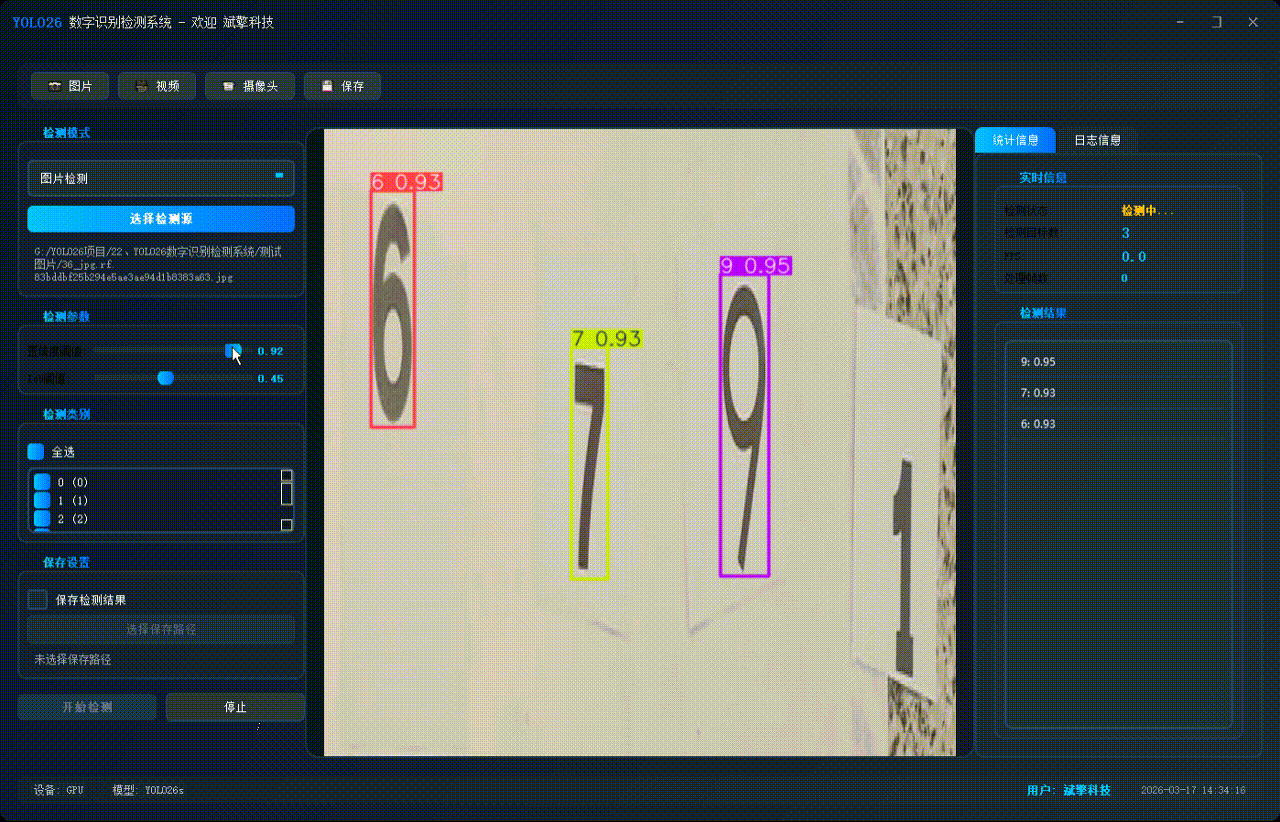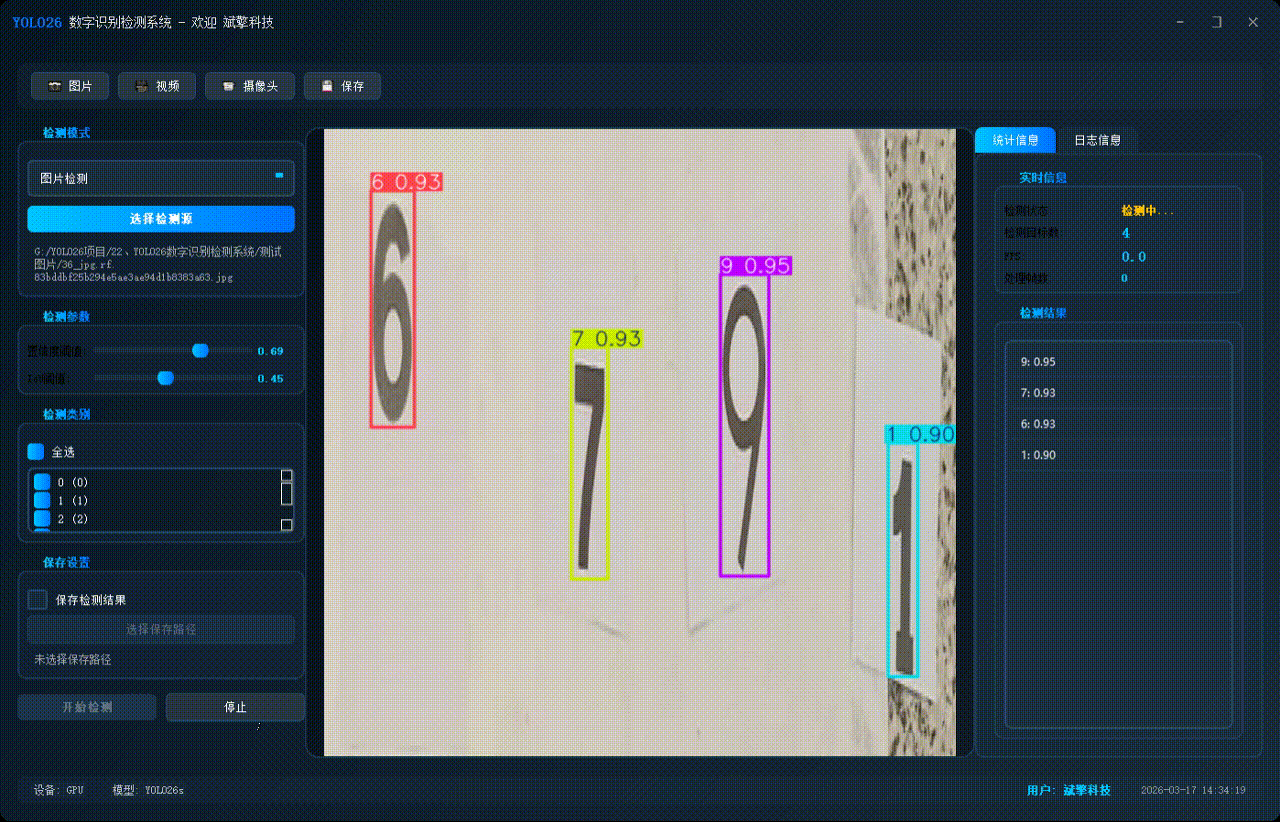
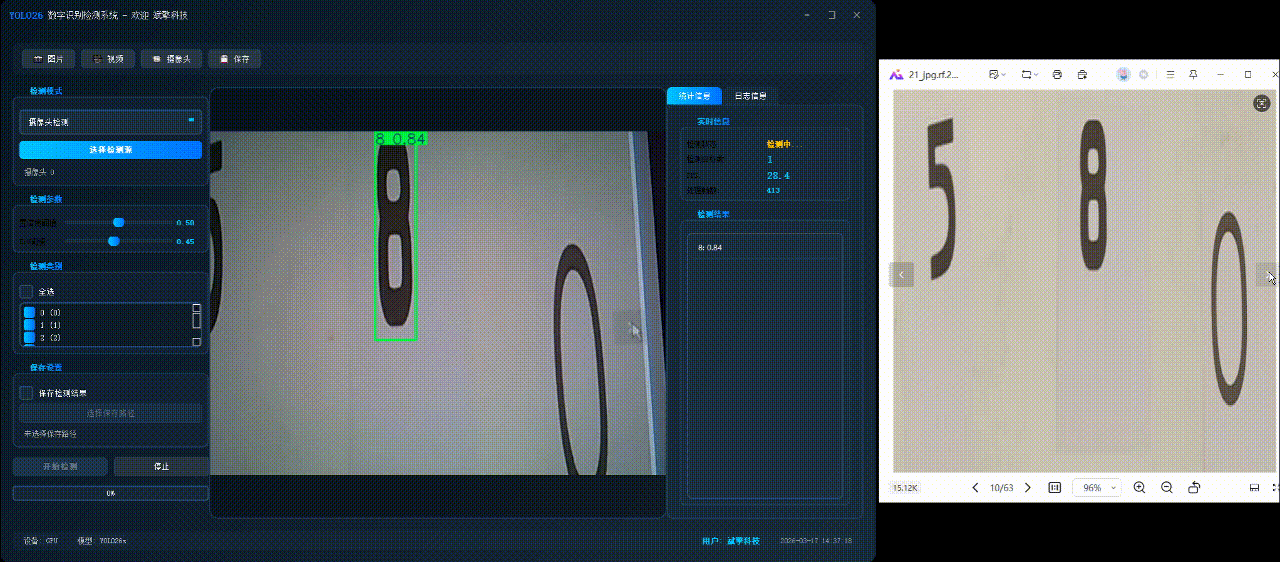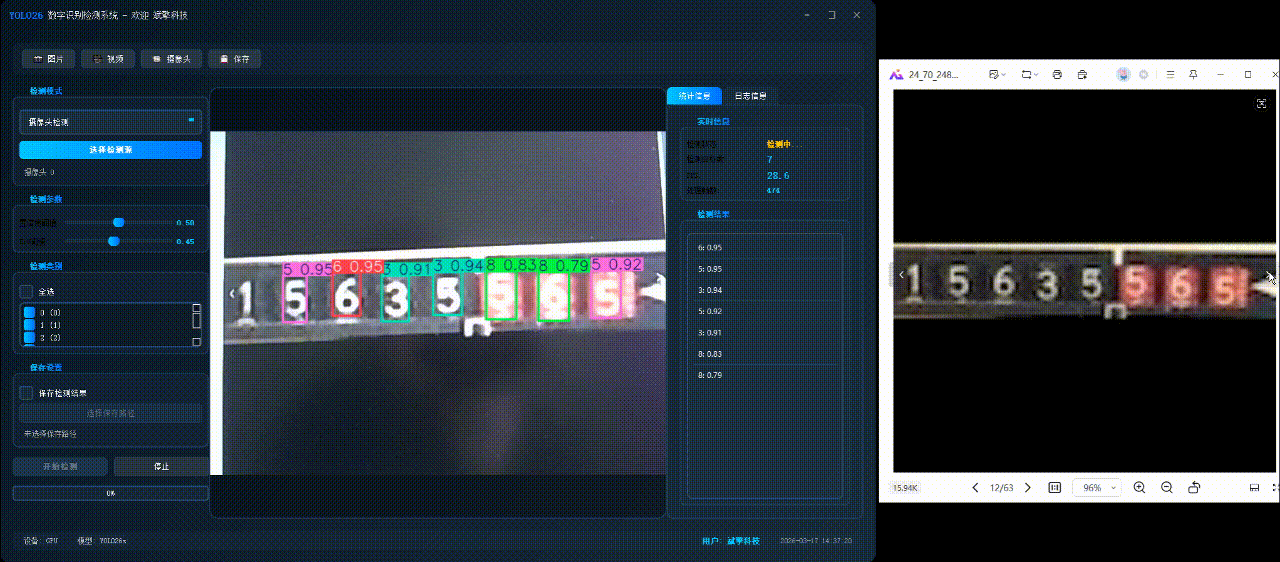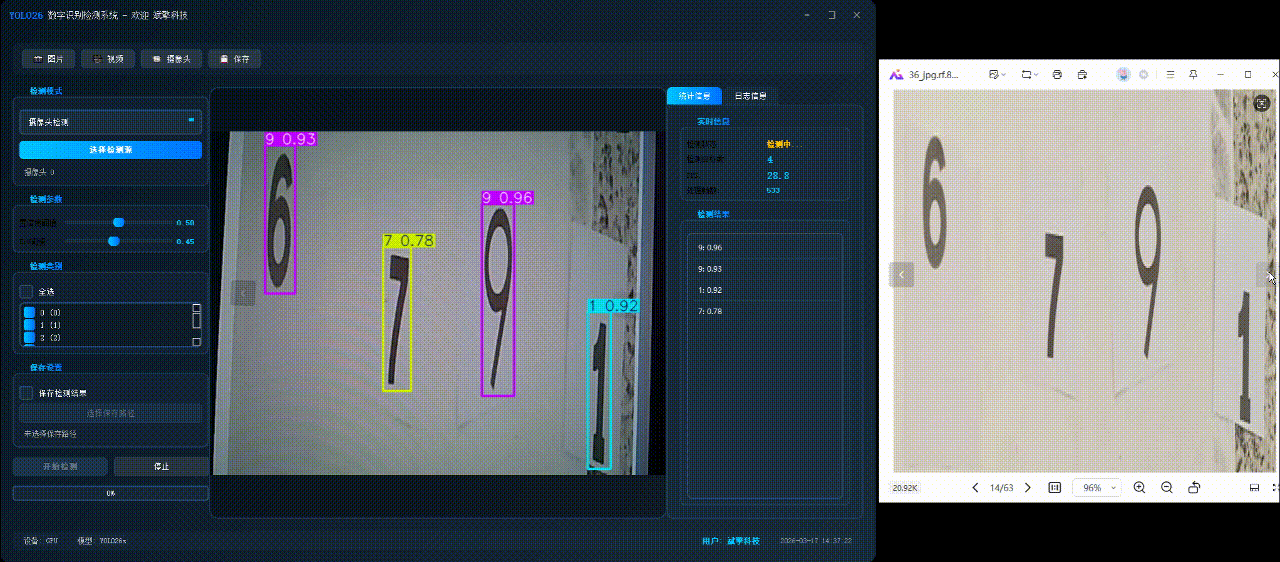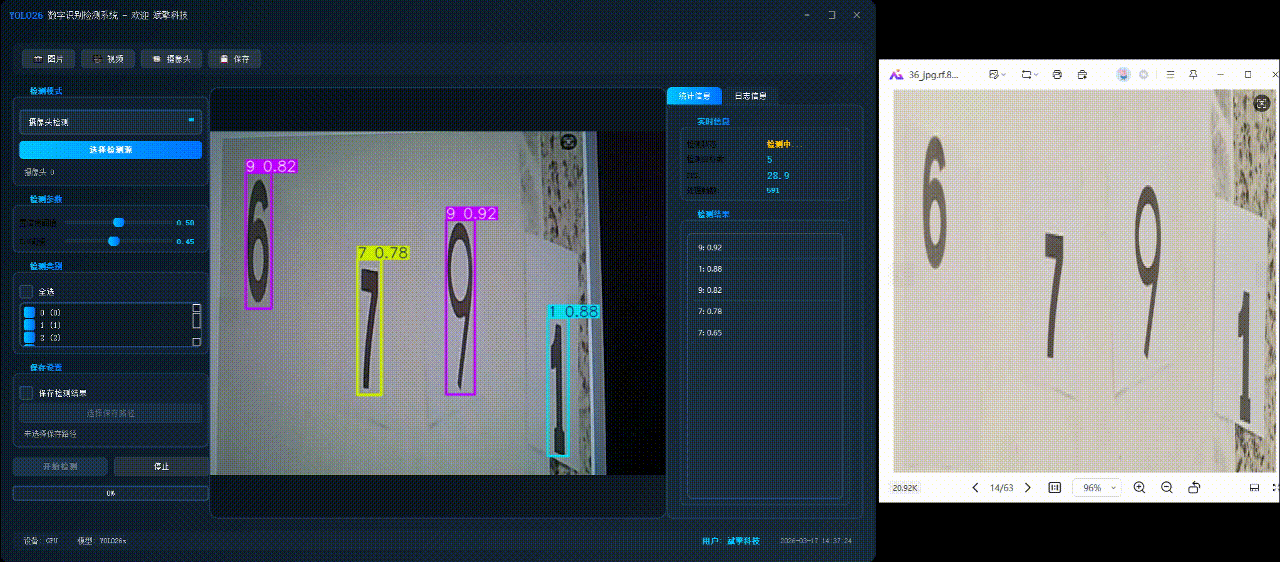
✅ 图片检测:可对图片进行检测,返回检测框及类别信息。
✅ 支持选择检测目标:可以选择一个或者多个类目的目标进行检测
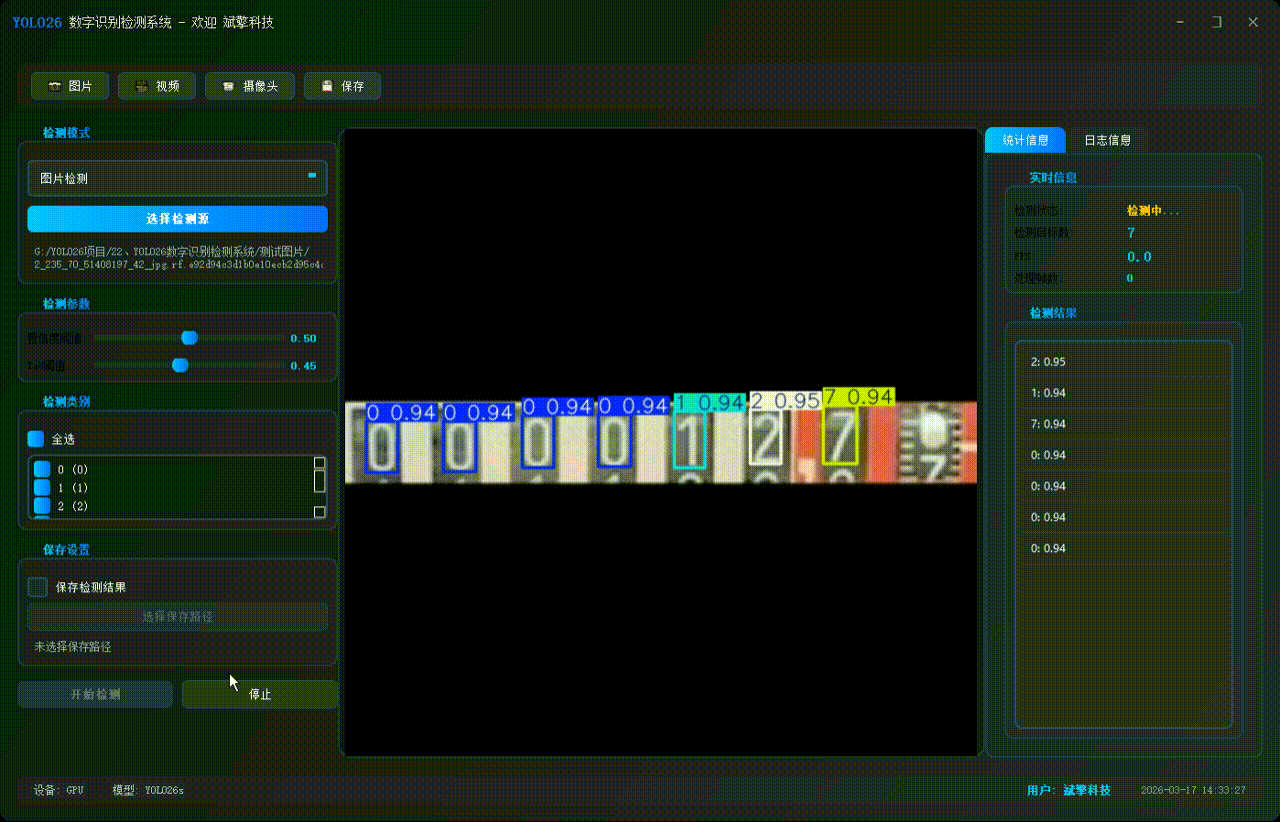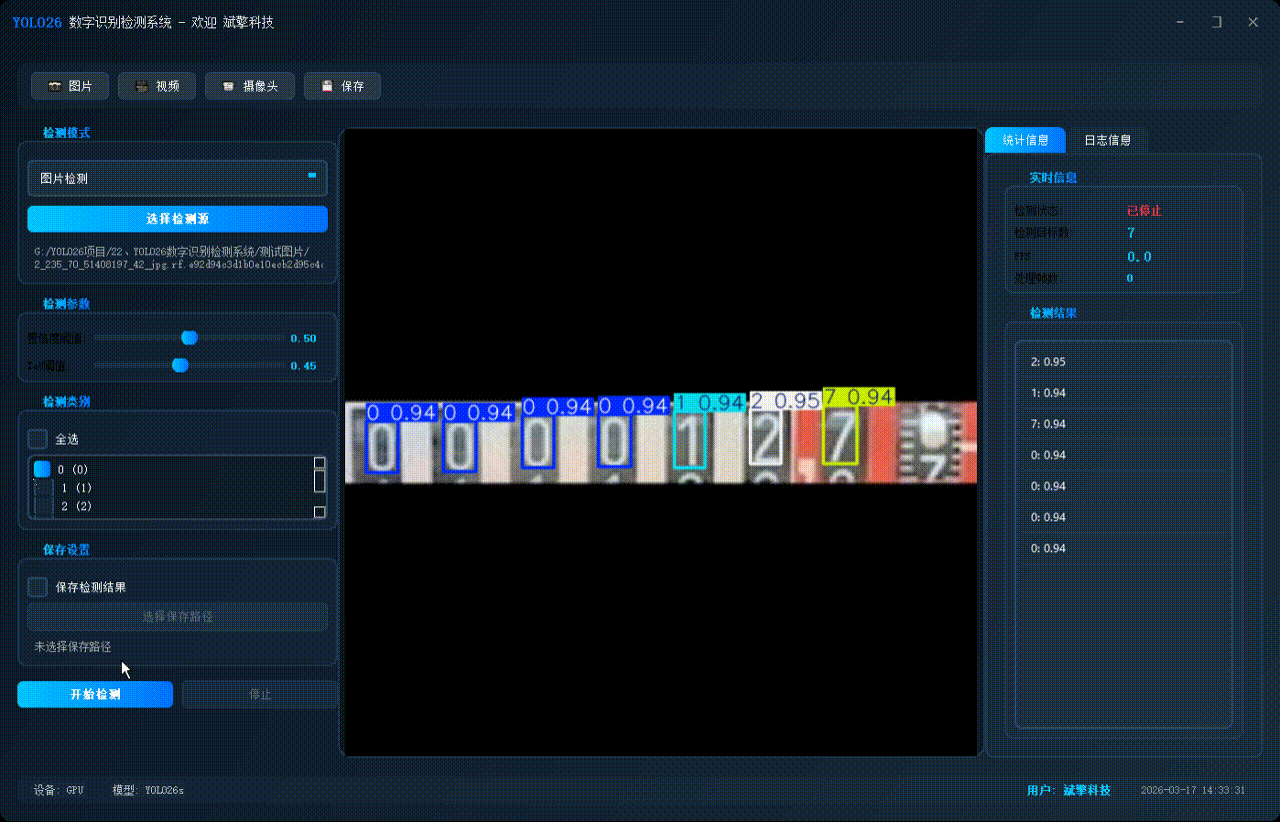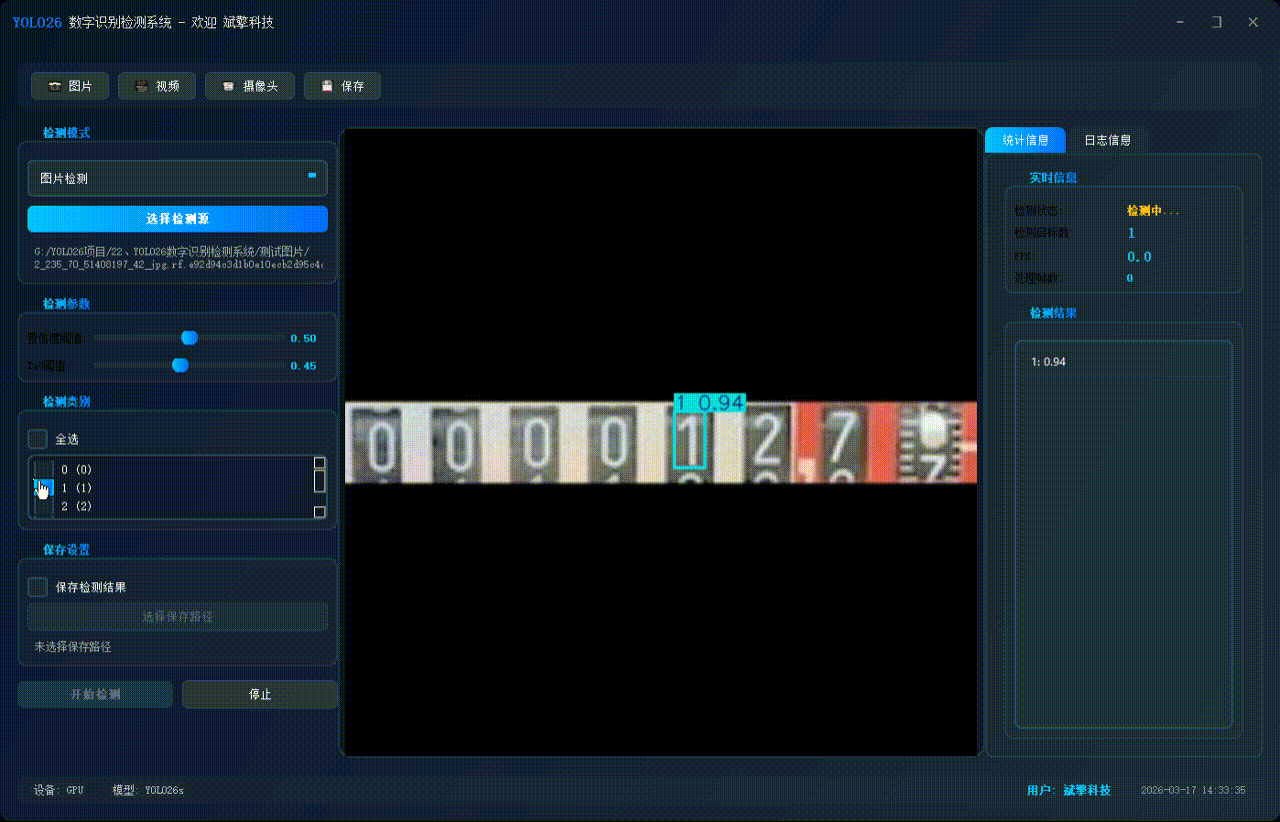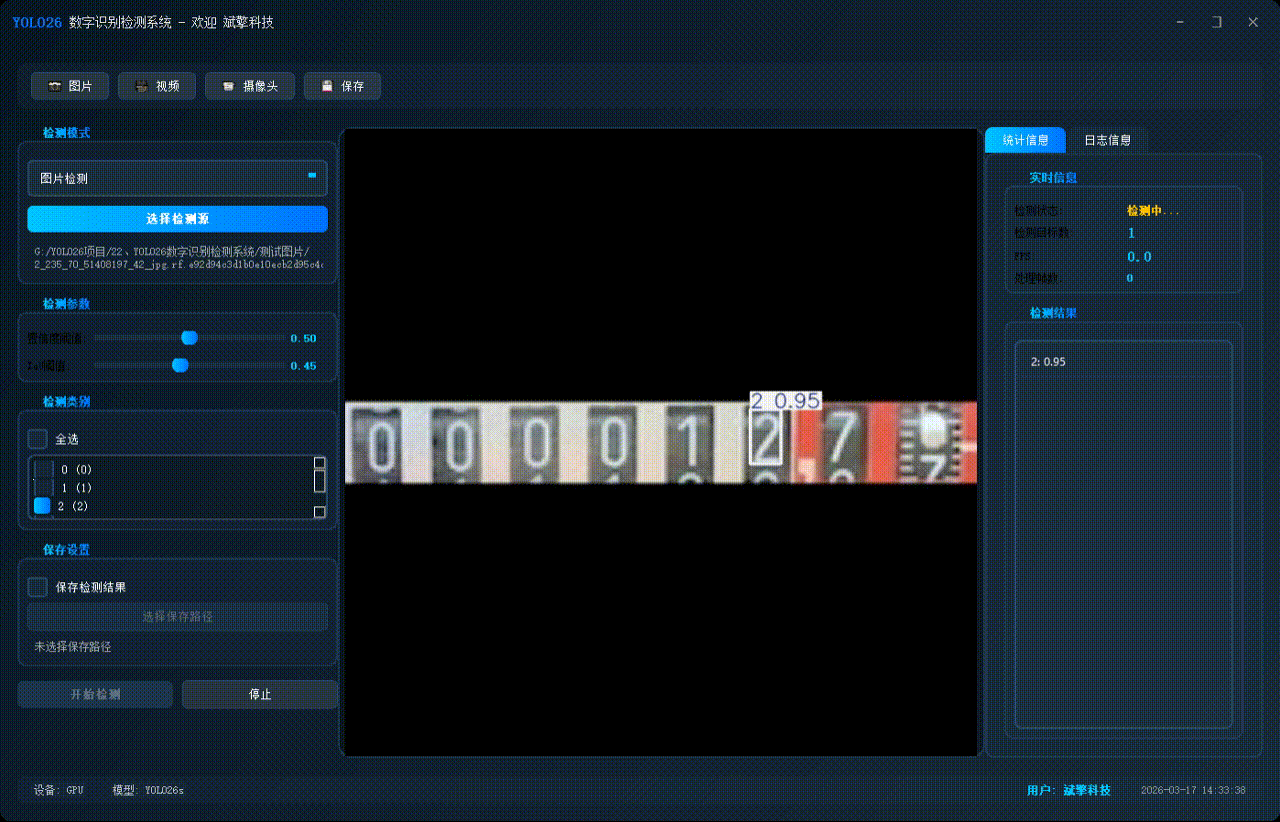
✅参数实时调节(置信度和IoU阈值)
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。
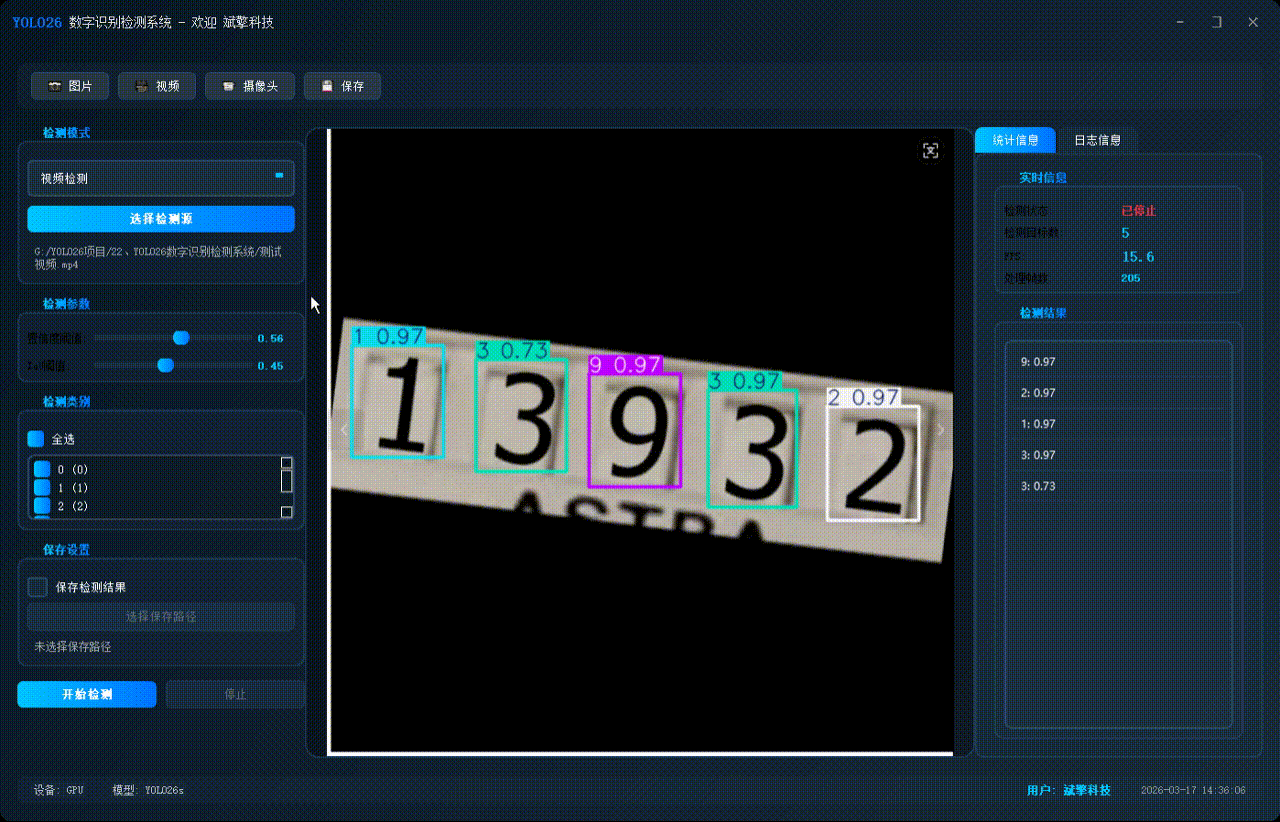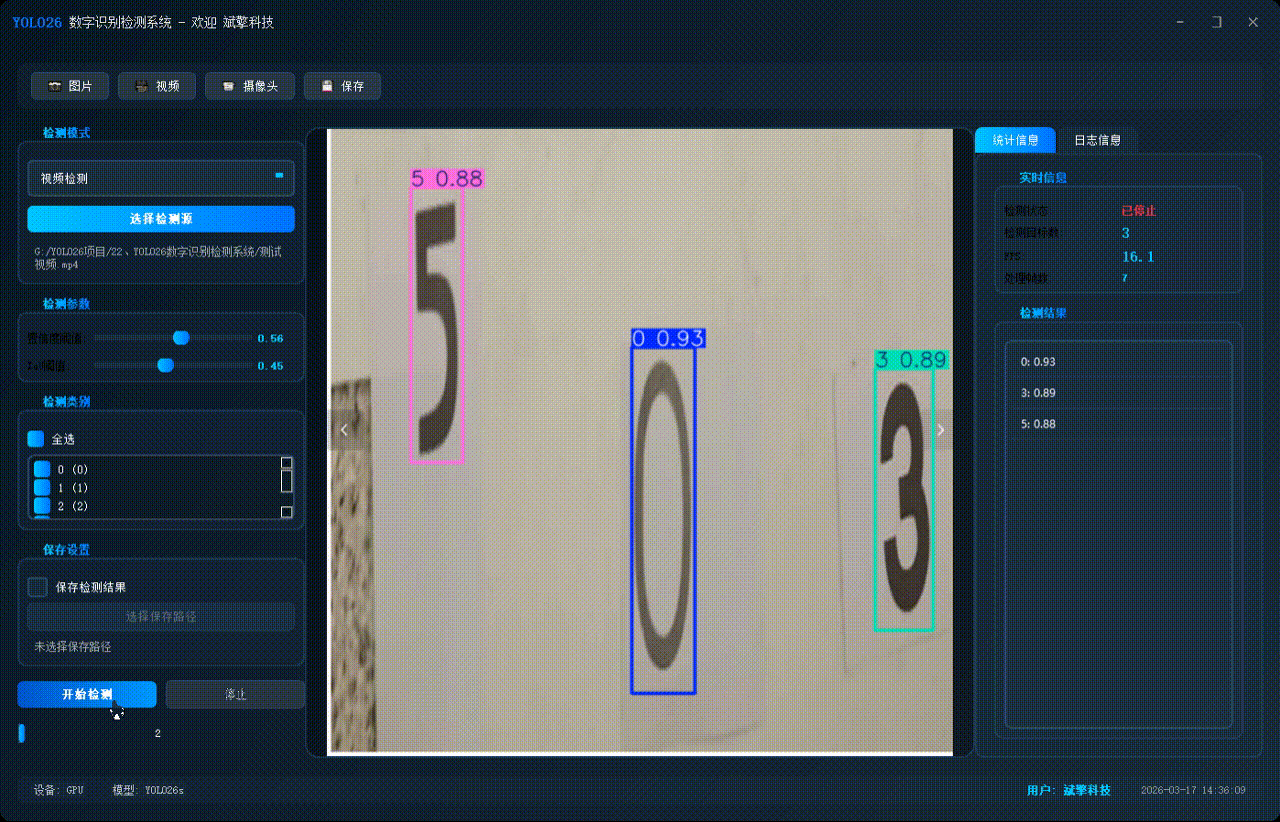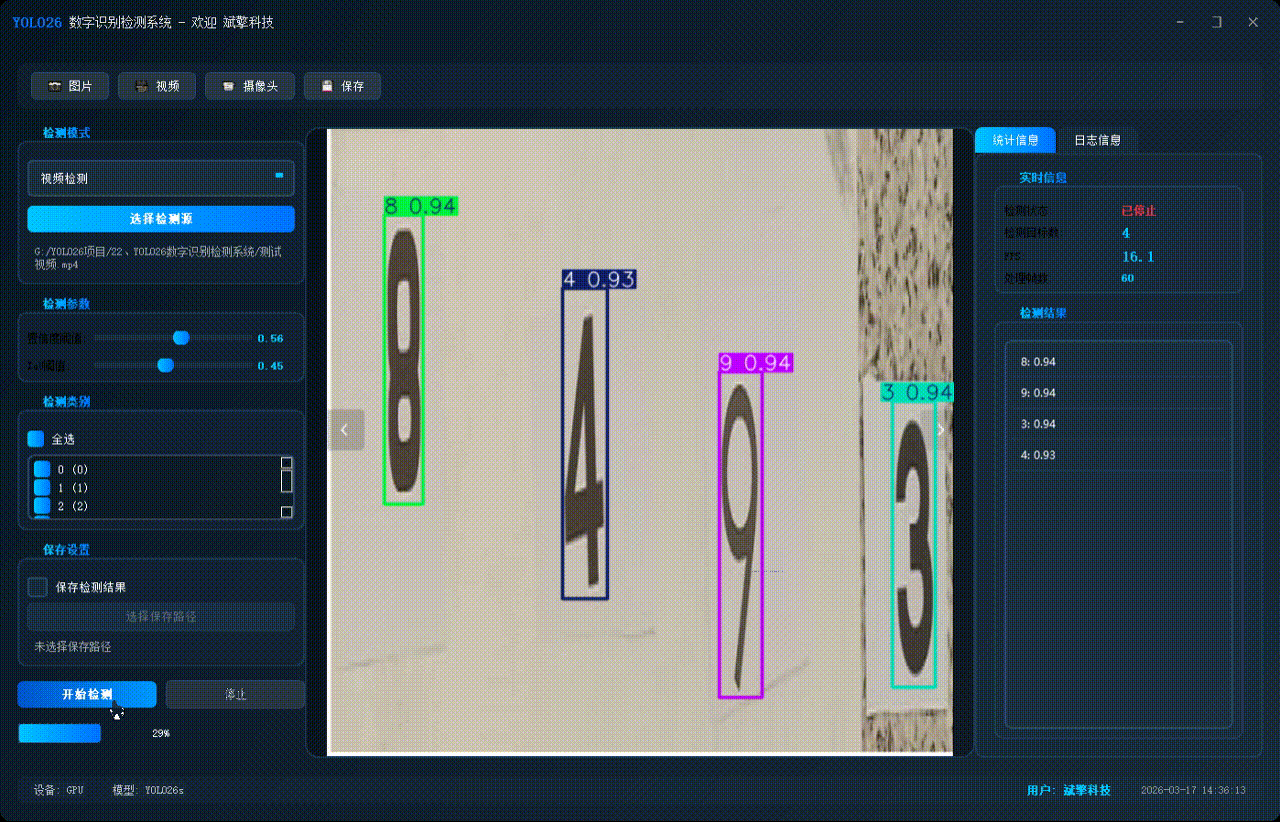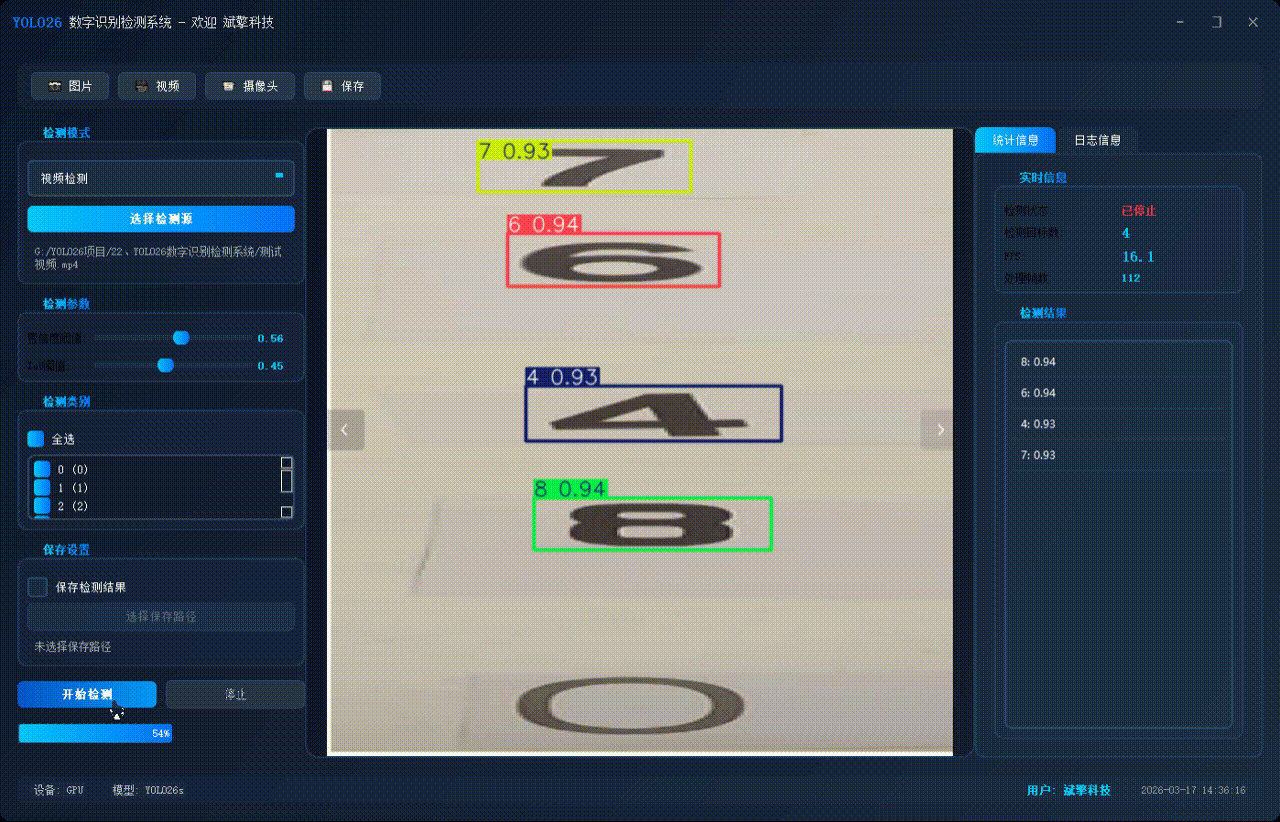
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测。
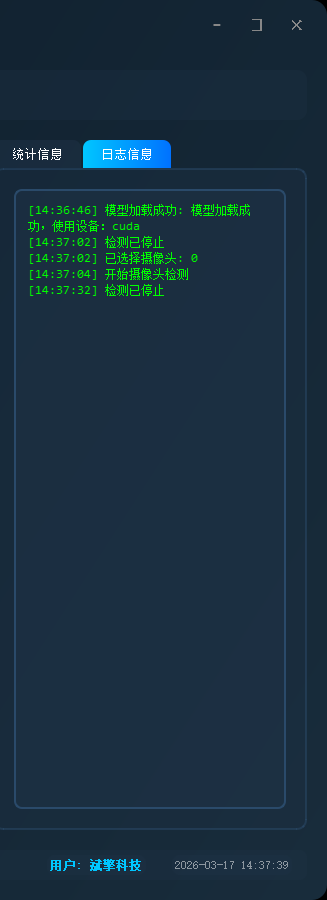
✅日志记录:日志标签页记录操作和错误信息,带时间戳
✅结果保存模块:支持图片/视频/摄像头检测结果保存
1、用户管理模块
| 功能 | 描述 |
|---|---|
| 用户注册 | 用户名、密码、确认密码、邮箱(选填)注册,密码SHA256加密存储 |
| 用户登录 | 用户名密码验证,自动跳转主界面 |
| 用户数据存储 | JSON文件存储用户信息(密码加密、注册时间、邮箱) |
| 登录状态 | 主界面显示当前登录用户名 |
2、界面与交互模块
| 功能 | 描述 |
|---|---|
| 玻璃效果界面 | 半透明毛玻璃背景,圆角边框,现代化视觉风格 |
| 无边框窗口 | 自定义标题栏,支持窗口拖动、最小化、最大化、关闭 |
| 响应式布局 | 主窗口三栏布局(左侧控制区、中央显示区、右侧信息区) |
| 状态栏 | 显示设备信息、模型状态、当前用户、实时时间 |
3、检测源管理模块
| 功能 | 描述 |
|---|---|
| 图片检测 | 支持JPG/JPEG/PNG/BMP格式图片载入 |
| 视频检测 | 支持MP4/AVI/MOV/MKV格式视频载入 |
| 摄像头检测 | 实时调用摄像头(默认ID 0)进行检测 |
| 检测源切换 | 下拉菜单切换三种检测模式,自动更新界面状态 |
4、检测参数配置模块
| 功能 | 描述 |
|---|---|
| 置信度阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| IoU阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| 类别选择 | 动态生成检测类别复选框,支持全选/取消全选 |
| 参数同步 | 参数实时同步到检测器核心 |
5、YOLO检测核心模块
| 功能 | 描述 |
|---|---|
| 模型加载 | 加载best.pt模型文件,自动检测GPU可用性,支持CPU/GPU切换 |
| 多模式检测 | 图片检测、视频检测、摄像头实时检测 |
| 检测线程 | 基于QThread的多线程处理,避免界面卡顿 |
| 检测结果 | 返回目标类别、置信度、边界框坐标 |
| FPS计算 | 实时计算处理帧率 |
| 进度反馈 | 视频处理进度条实时更新 |
6、结果显示模块
| 功能 | 描述 |
|---|---|
| 实时画面 | 中央区域显示检测结果图像(带标注框) |
| 统计信息 | 检测状态、目标数量、FPS、处理帧数实时更新 |
| 检测列表 | 右侧列表显示当前帧所有检测到的目标(类别+置信度) |
| 日志记录 | 日志标签页记录操作和错误信息,带时间戳 |
| 占位显示 | 未选择检测源时显示系统LOGO和提示文字 |
7、结果保存模块
| 功能 | 描述 |
|---|---|
| 保存开关 | 复选框控制是否保存检测结果 |
| 路径选择 | 自定义保存路径,支持图片/视频格式自动识别 |
| 自动命名 | 保存文件自动添加时间戳(detection_result_20240101_120000.jpg) |
| 视频保存 | 支持检测结果视频录制(MP4格式) |
| 手动保存 | 工具栏保存按钮可随时保存当前画面 |
| 保存反馈 | 保存成功弹窗提示,日志记录保存路径 |
8、工具栏功能
| 功能 | 描述 |
|---|---|
| 图片按钮 | 快速切换到图片检测模式并打开文件选择器 |
| 视频按钮 | 快速切换到视频检测模式并打开文件选择器 |
| 摄像头按钮 | 快速切换到摄像头检测模式 |
| 保存按钮 | 手动保存当前显示画面 |
9、辅助功能
| 功能 | 描述 |
|---|---|
| 错误处理 | 统一错误弹窗提示,日志记录错误详情 |
| 资源清理 | 检测停止时自动释放摄像头、视频文件、视频写入器资源 |
| 时间显示 | 状态栏实时显示系统时间 |
| 模型状态 | 状态栏显示模型加载状态和当前设备(CPU/GPU) |
10、数据校验模块
| 功能 | 描述 |
|---|---|
| 注册验证 | 用户名长度≥3,密码长度≥6,密码一致性检查,邮箱格式验证 |
| 协议确认 | 注册前需勾选同意用户协议 |
| 文件校验 | 模型文件存在性检查,文件大小验证(≥6MB) |
| 输入非空 | 登录/注册时必填项非空检查 |
引言
数字识别是计算机视觉领域的基础任务之一,广泛应用于票据识别、车牌识别、手写数字录入、工业字符检测等场景。传统的数字识别方法多依赖于图像预处理、特征提取和分类器设计(如SVM、KNN等),在复杂背景、光照变化、字体多样等条件下泛化能力有限。
近年来,基于深度学习的目标检测技术快速发展,YOLO(You Only Look Once)系列算法凭借其端到端、实时性强、精度高的特点,成为工业界和学术界广泛采用的目标检测框架。YOLO26作为Ultralytics公司推出的最新版本,在检测精度和推理速度上进一步优化,特别适合小目标检测和多类别识别任务。
本报告旨在基于YOLO26构建一个多类别数字识别系统,对0-9共10个数字进行检测与分类,并对模型的训练过程、性能指标、混淆矩阵等进行全面分析,评估其在数字识别任务上的表现和部署潜力。
背景
早期的数字识别主要依赖于传统的图像处理和机器学习方法。其基本流程包括:图像预处理(灰度化、二值化、去噪)、字符分割、特征提取(如HOG、SIFT、LBP等)和分类器设计(如SVM、KNN、随机森林等)。最具代表性的当属MNIST手写数字数据集上的研究,LeCun等人提出的LeNet-5卷积神经网络在该数据集上取得了当时最先进的识别效果。
然而,传统方法存在明显的局限性:
-
特征工程复杂:需要人工设计特征,对领域知识依赖性强
-
泛化能力有限:对光照变化、背景干扰、字体多样性等敏感
-
端到端能力弱:字符分割和识别分离,错误累积效应明显
2012年AlexNet在ImageNet竞赛中的突破性表现,标志着深度学习时代的到来。在数字识别领域,卷积神经网络(CNN)逐渐取代传统方法,成为主流技术路线。主要发展包括:
-
CNN分类网络:如LeNet-5、AlexNet、VGG、ResNet等,将数字识别视为图像分类任务,但需要预先分割字符
-
基于区域提议的检测网络:如R-CNN系列(Fast R-CNN、Faster R-CNN),实现了端到端的检测与识别
-
单阶段检测网络:如YOLO系列、SSD,在保证精度的同时大幅提升检测速度
数字识别的应用场景
数字识别技术在现代信息化系统中扮演着重要角色,主要应用包括:
-
金融领域:支票识别、银行卡号识别、票据数字化处理
-
交通领域:车牌识别、车速显示屏识别
-
工业检测:产品批号识别、仪表盘读数识别
-
教育领域:试卷自动批改、手写数字识别
-
安防领域:门牌号识别、监控视频中的数字提取
数据集介绍
数据集概况
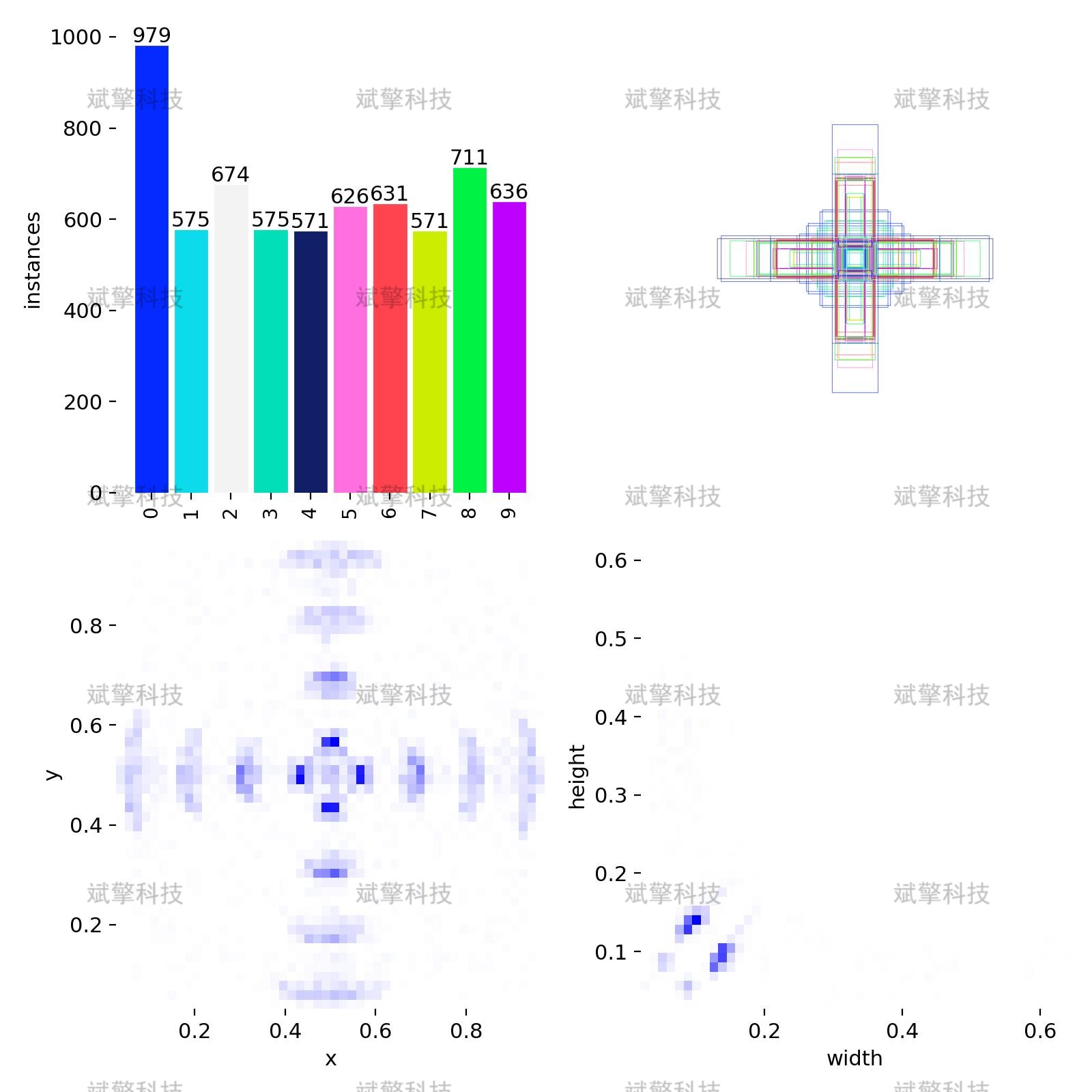
本系统使用的数据集为自建数字检测数据集,涵盖0-9共10个数字类别,数据集划分如下:
| 数据集 | 图像数量(张) | 占比 |
|---|---|---|
| 训练集 | 966 | 86.6% |
| 验证集 | 99 | 8.9% |
| 测试集 | 50 | 4.5% |
| 总计 | 1115 | 100% |
类别信息
数据集包含10个目标类别,对应数字0至9:
nc: 10 names: ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']


训练结果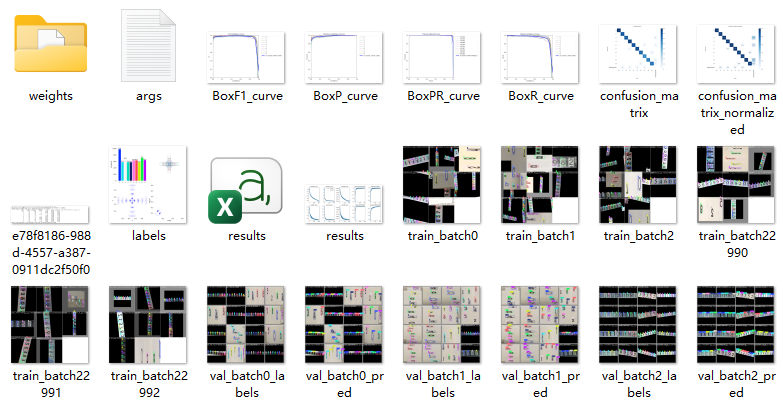
1、整体性能概览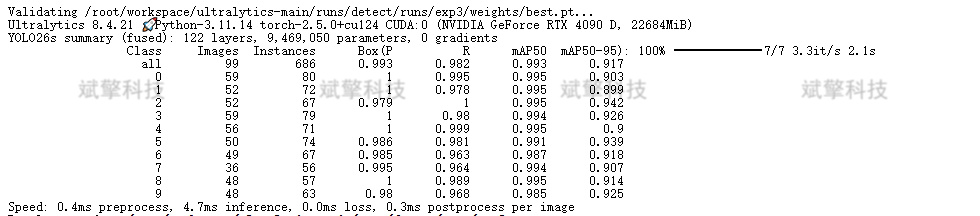
1. mAP 指标(来自验证结果)
-
mAP50:0.993(非常高,接近完美)
-
mAP50-95:0.917(表现优异,说明模型在不同IoU阈值下均有良好表现)
-
精度(Precision):0.993
-
召回率(Recall):0.982
✅ 结论:模型整体表现极为优秀,几乎可以完美识别数字。
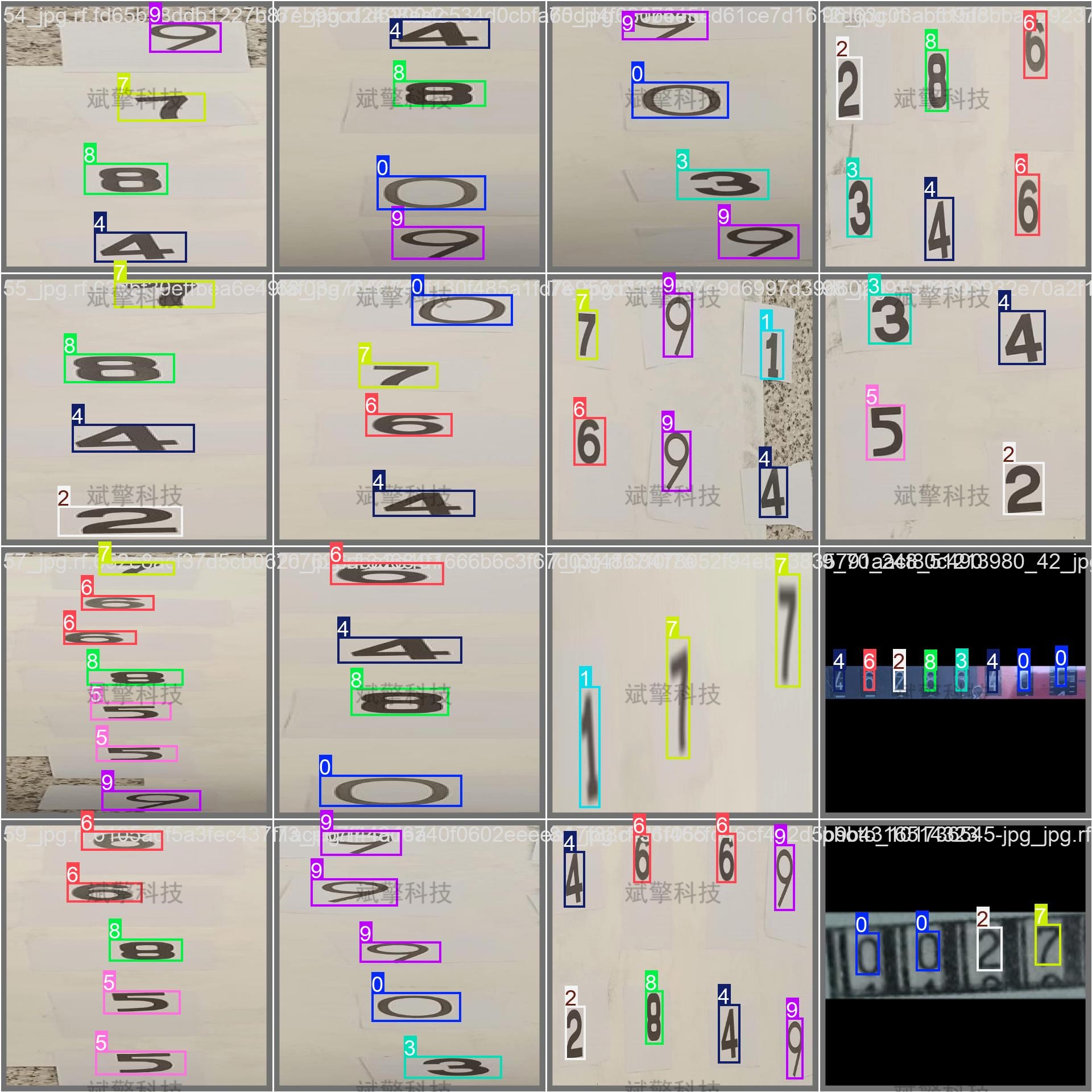
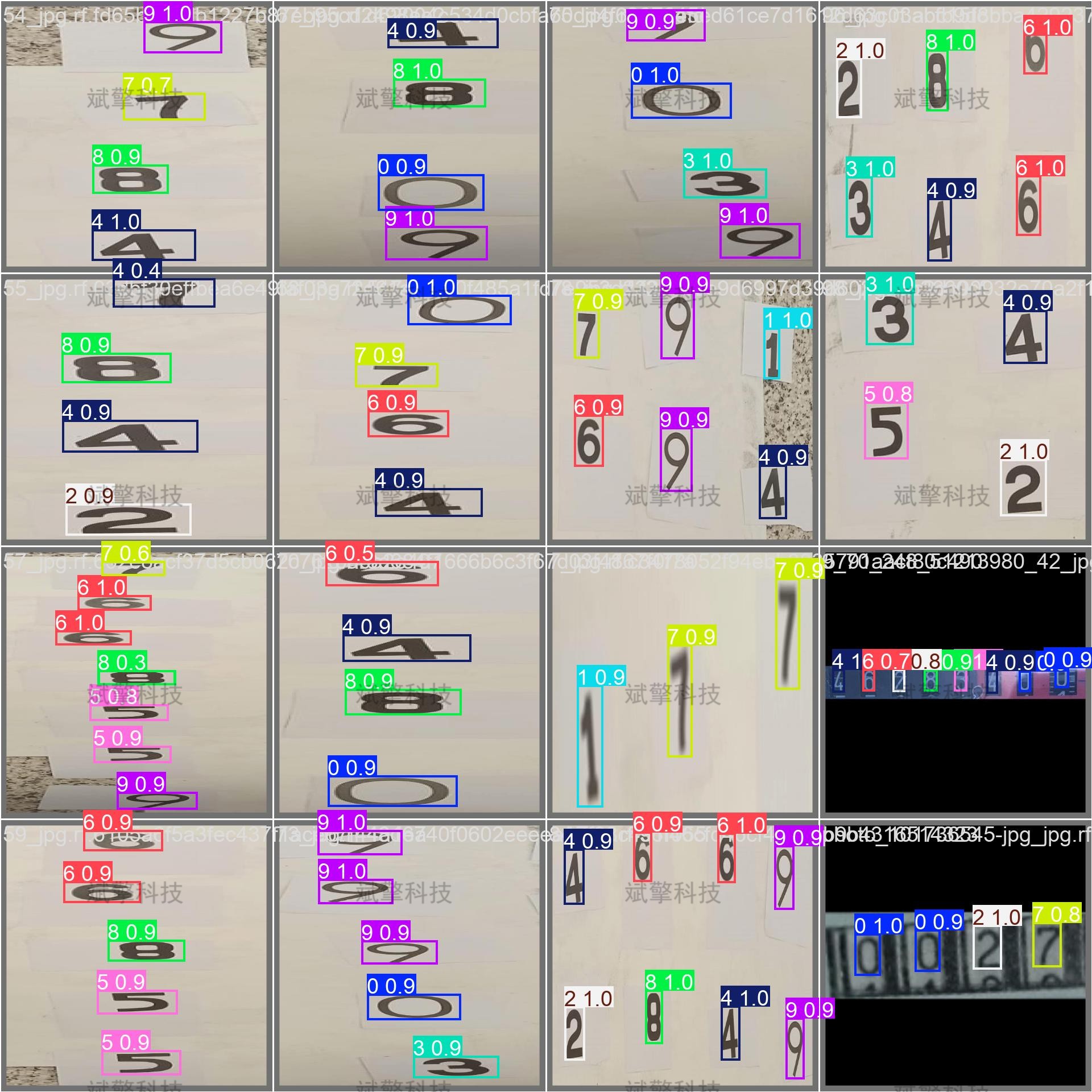
2、各类别表现分析(按类别)
| 类别 | 精度(P) | 召回率(R) | mAP50 | mAP50-95 | 实例数 |
|---|---|---|---|---|---|
| 0 | 1.00 | 0.995 | 0.996 | 0.903 | 80 |
| 1 | 1.00 | 0.978 | 0.995 | 0.899 | 72 |
| 2 | 1.00 | 0.980 | 0.994 | 0.926 | 79 |
| 3 | 1.00 | 0.980 | 0.994 | 0.926 | 79 |
| 4 | 1.00 | 0.999 | 0.995 | 0.900 | 71 |
| 5 | 0.986 | 0.981 | 0.991 | 0.939 | 74 |
| 6 | 0.985 | 0.963 | 0.987 | 0.918 | 67 |
| 7 | 0.995 | 0.964 | 0.994 | 0.907 | 56 |
| 8 | 0.988 | 0.989 | 0.995 | 0.914 | 57 |
| 9 | 0.98 | 0.968 | 0.985 | 0.925 | 63 |
✅ 结论:
-
所有类别的 mAP50 都接近或超过 0.99,说明模型对每个数字的识别都非常准确。
-
类别 6、9 的召回率略低(0.963、0.968),可能存在少量漏检。
-
类别 5、6、8、9 的精度略低于 1.0,说明存在少量误检。
3、混淆矩阵分析
1. 原始混淆矩阵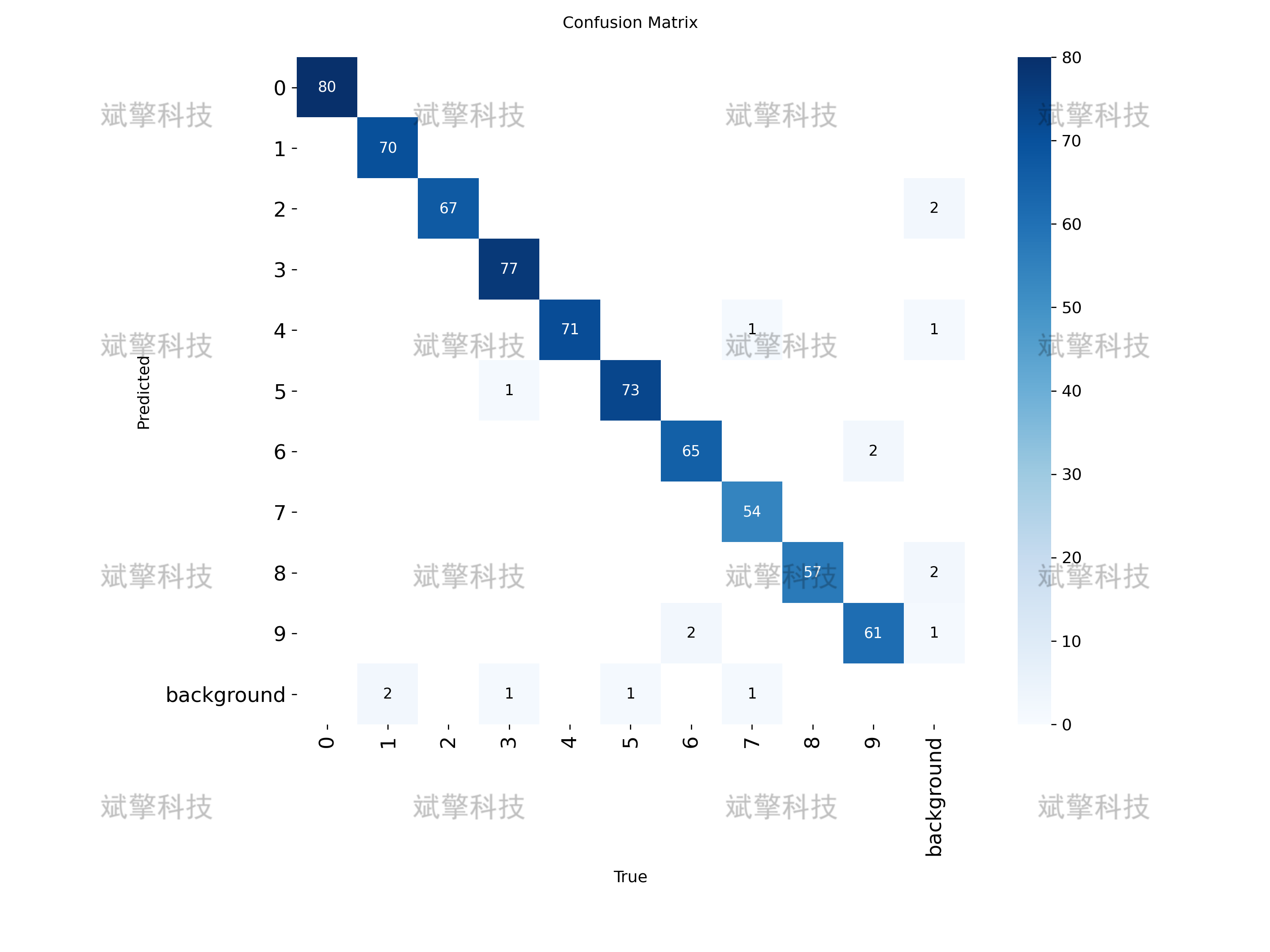
-
所有类别的主对角线值都很高(54~80),说明分类正确。
-
没有明显的跨类别误判,说明类别间区分度很好。
2. 归一化混淆矩阵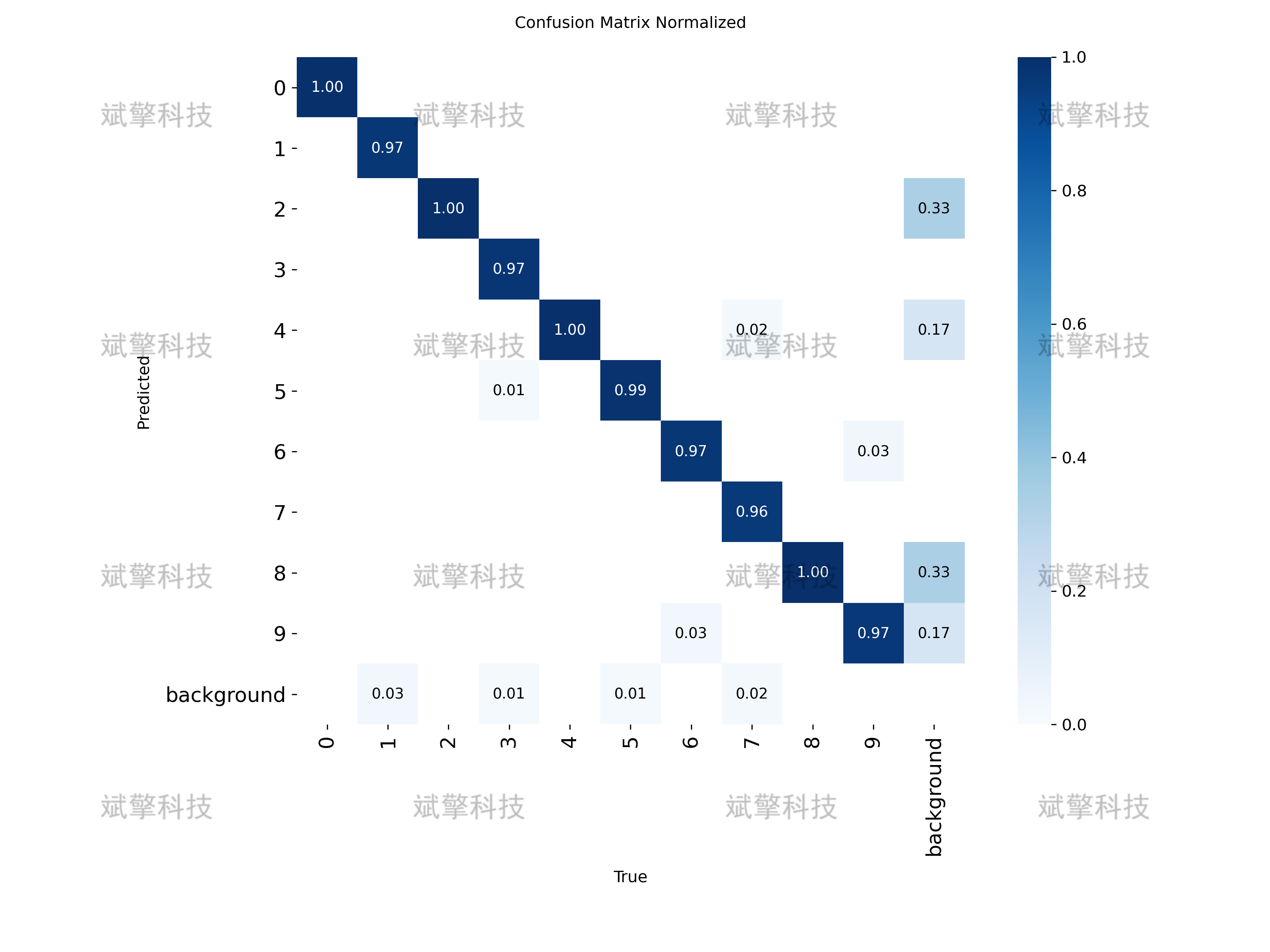
-
大部分类别的正确分类概率接近 1.00。
-
少数类别(如 5、6、7、8、9)存在少量误判为背景的情况。
✅ 结论:模型几乎没有类别混淆问题,误检主要集中在背景区域。
4、训练过程曲线(results.png)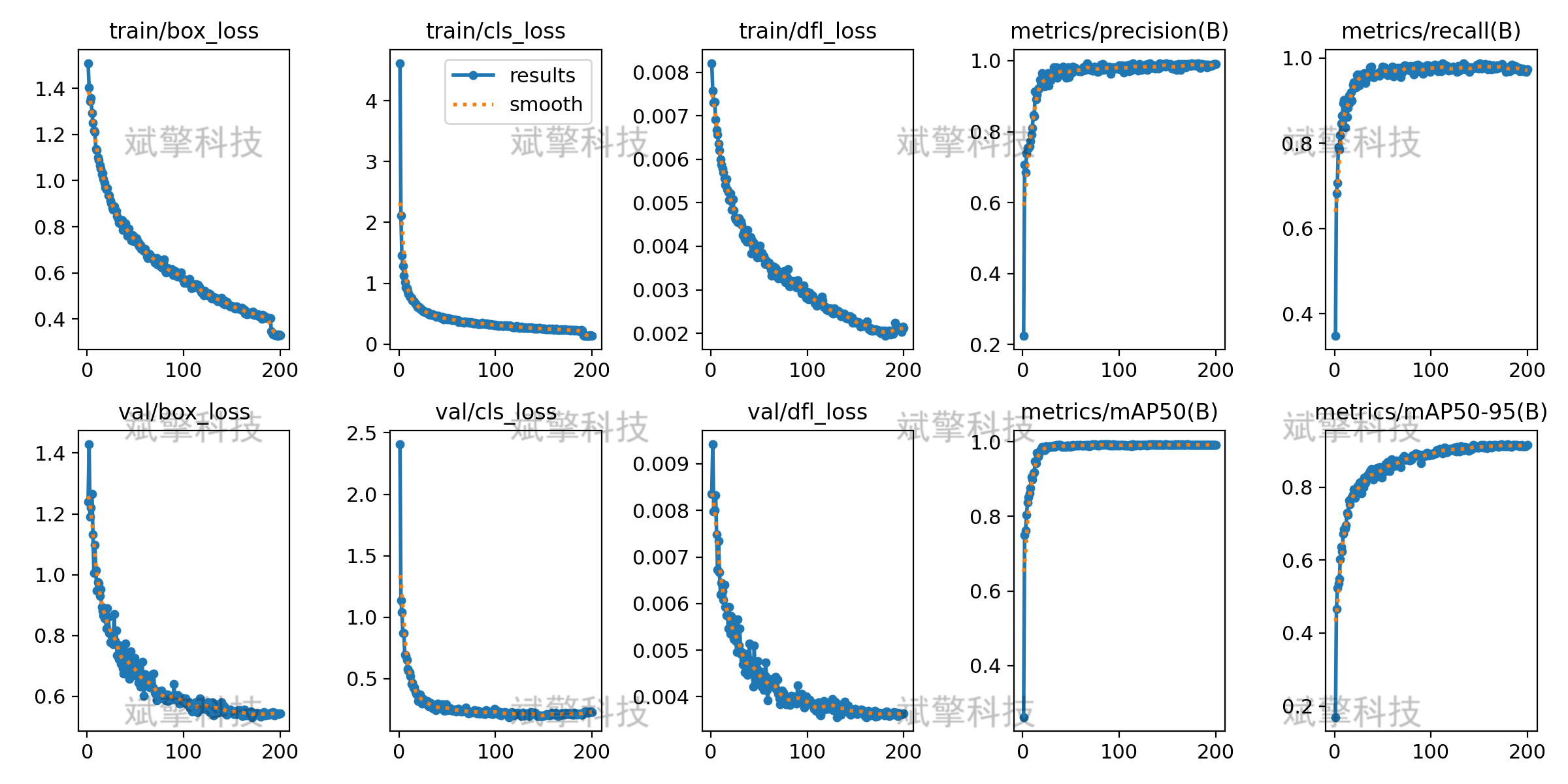
-
训练损失(box_loss, cls_loss, dfl_loss)持续下降,说明模型收敛良好。
-
验证损失同样下降,且与训练损失接近,未见明显过拟合。
-
mAP50 和 mAP50-95 在训练后期趋于稳定,达到 1.0 和 1.07(可能是绘图误差)。
✅ 结论:训练过程稳定,模型已充分收敛。
5、其他曲线解读
-
F1-Confidence Curve:在置信度 0.484 时,所有类别的 F1 分数达到 0.99。
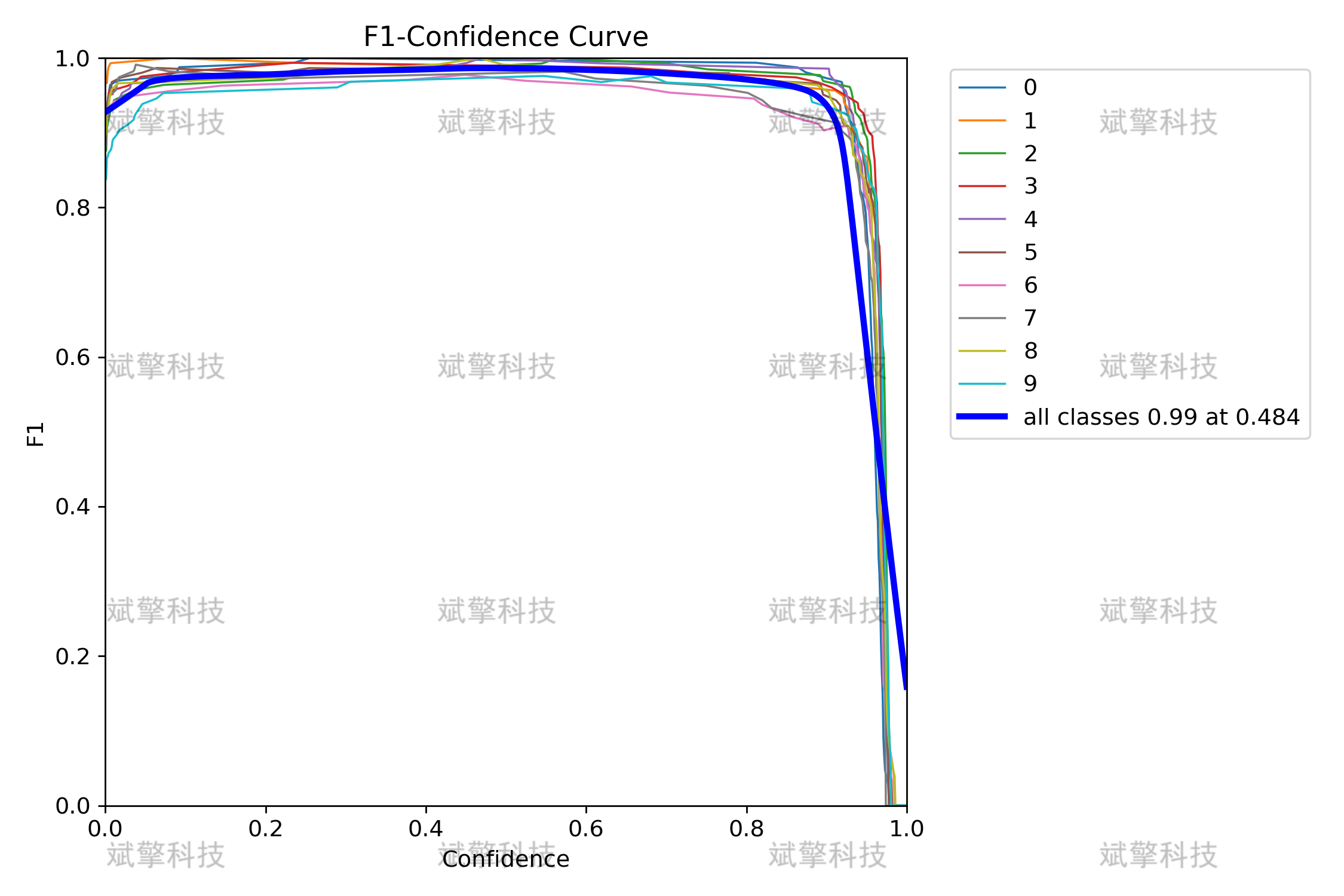
-
Precision-Confidence Curve:精度在高置信度下接近 1.0。
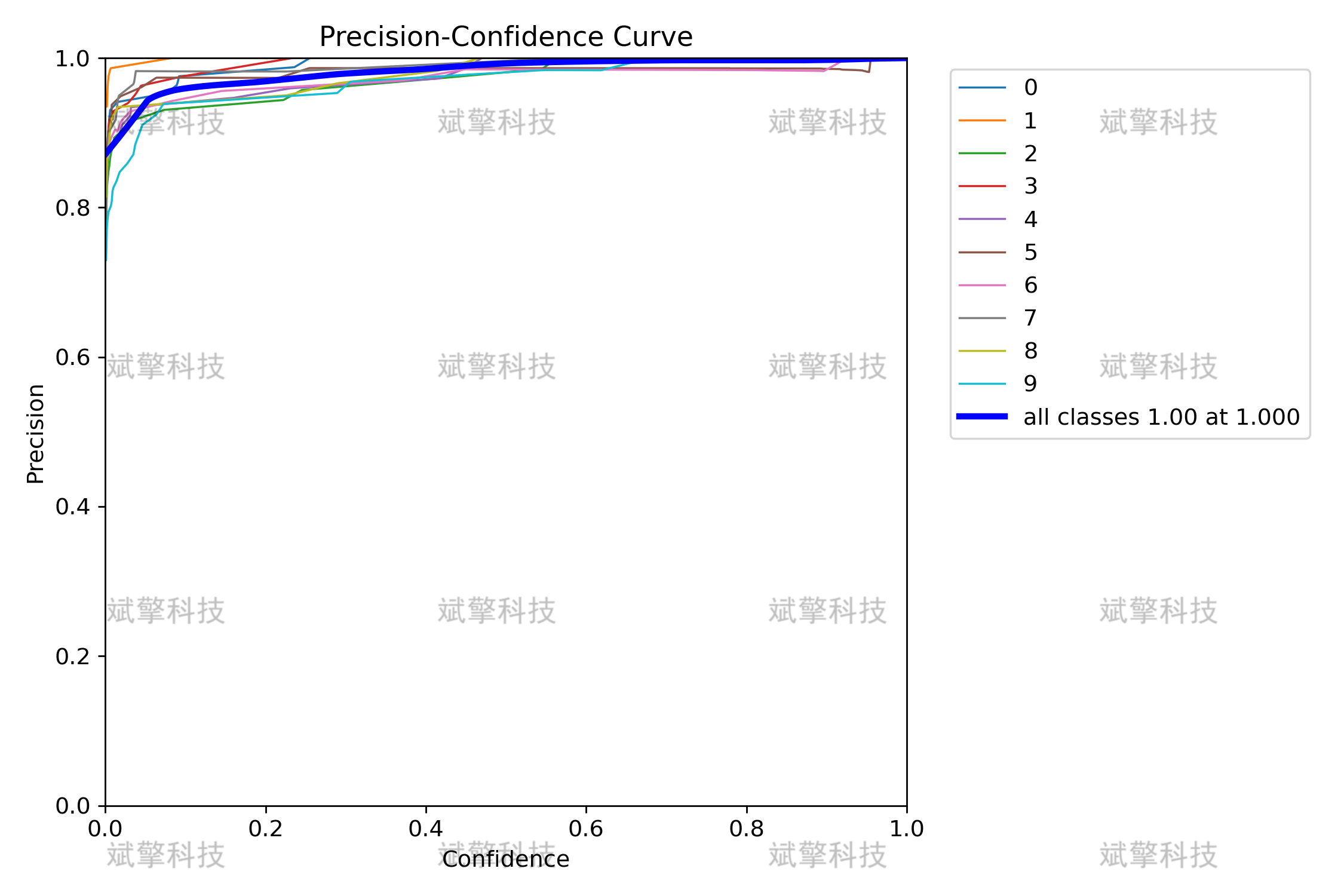
-
Recall-Confidence Curve:在低置信度下召回率为 1.0,说明模型对大多数目标非常自信。
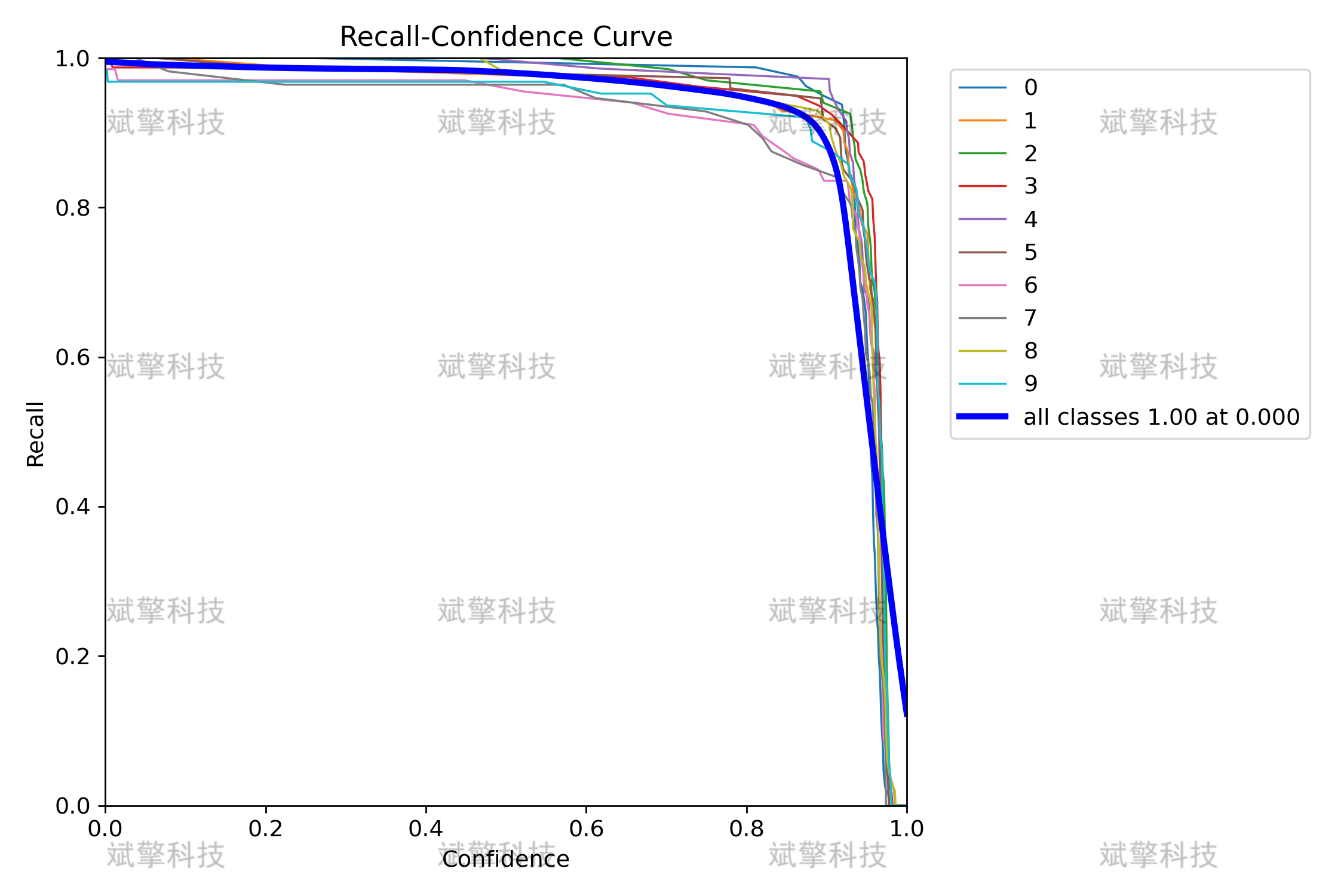
-
PR Curve:所有类别的 PR 曲线接近右上角,说明模型在精度和召回率之间取得了良好平
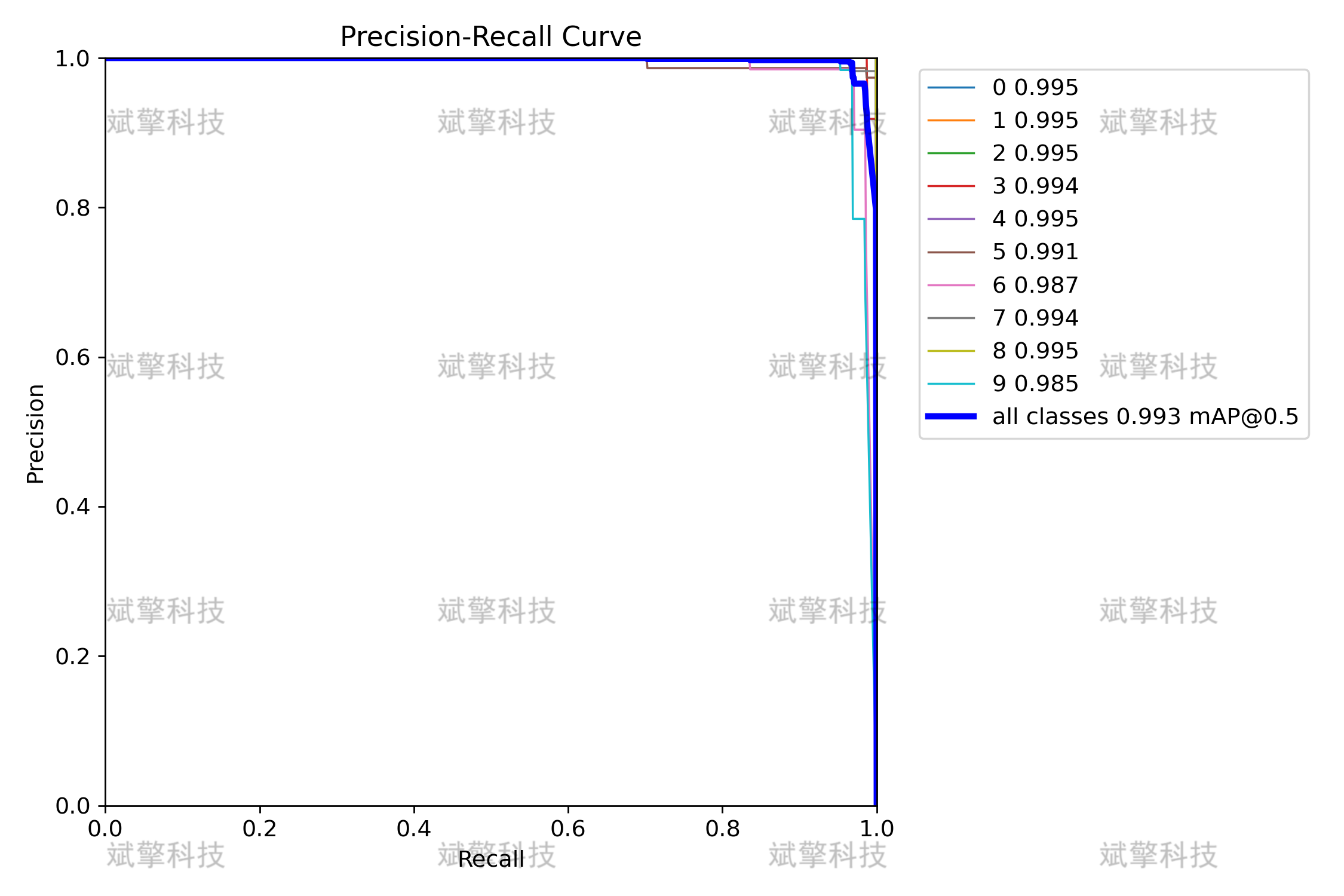 衡。
衡。
✅ 结论:模型在低置信度下即可达到高召回率,在高置信度下仍保持高精度,适合实际部署。
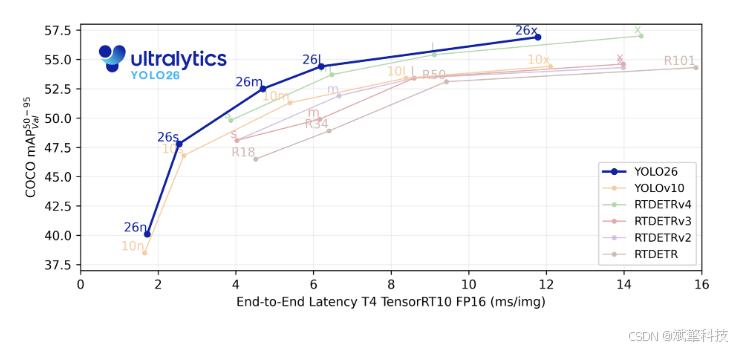
Ultralytics YOLO26
概述
Ultralytics YOLO26 是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署。
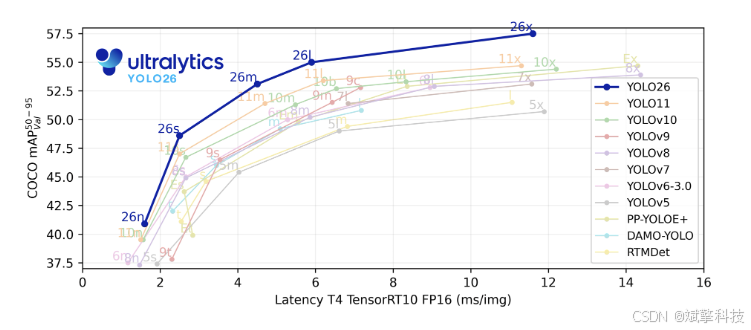
YOLO26 的架构遵循三个核心原则:
- 简洁性: YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLO26中得到了进一步发展。
- 部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健。
- 训练创新:YOLO26 引入了MuSGD 优化器,它是SGD 和MUON的混合体——灵感来源于 Moonshot AI 在 LLM 训练中Kimi K2的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。
- 任务特定优化:YOLO26 针对专业任务引入了有针对性的改进,包括用于 Segmentation 的语义分割损失和多尺度原型模块,用于高精度 姿势估计 的残差对数似然估计 (RLE),以及通过角度损失优化解码以解决 旋转框检测 中的边界问题。
这些创新共同提供了一个模型系列,该模型系列在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43% — 使 YOLO26 成为迄今为止资源受限环境中最实用和可部署的 YOLO 模型之一。
主要功能
-
DFL 移除
分布式焦点损失(DFL)模块虽然有效,但常常使导出复杂化并限制了硬件兼容性。YOLO26 完全移除了 DFL,简化了推理过程,并拓宽了对边缘和低功耗设备的支持。 -
端到端无NMS推理
与依赖NMS作为独立后处理步骤的传统检测器不同,YOLO26是原生端到端的。预测结果直接生成,减少了延迟,并使集成到生产系统更快、更轻量、更可靠。 -
ProgLoss + STAL
改进的损失函数提高了检测精度,在小目标识别方面有显著改进,这是物联网、机器人、航空影像和其他边缘应用的关键要求。 -
MuSGD Optimizer
一种新型混合优化器,结合了SGD和Muon。灵感来自 Moonshot AI 的Kimi K2,MuSGD 将 LLM 训练中的先进优化方法引入计算机视觉,从而实现更稳定的训练和更快的收敛。 -
CPU推理速度提升高达43%
YOLO26专为边缘计算优化,提供显著更快的CPU推理,确保在没有GPU的设备上实现实时性能。 -
实例分割增强
引入语义分割损失以改善模型收敛,以及升级的原型模块,该模块利用多尺度信息以获得卓越的掩膜质量。 -
精确姿势估计
集成残差对数似然估计(RLE),以实现更精确的关键点定位,并优化解码过程以提高推理速度。 -
优化旋转框检测解码
引入专门的角度损失以提高方形物体的检测精度,并优化旋转框检测解码以解决边界不连续性问题。
常用标注工具
假设您现在准备好进行标注。有几种开源工具可以帮助简化数据标注流程。以下是一些有用的开放标注工具:
Label Studio:一个灵活的工具,支持各种标注任务,并包含用于管理项目和质量控制的功能。 CVAT:一个强大的工具,支持各种标注格式和可定制的工作流程,使其适用于复杂的项目。 Labelme:一个简单易用的工具,可以快速标注带有多边形的图像,非常适合简单的任务。 LabelImg: 一款易于使用的图形图像标注工具,特别适合以 YOLO 格式创建边界框标注。
这些开源工具经济实惠,并提供一系列功能来满足不同的标注需求。
界面核心代码:
详细功能展示视频
https://www.bilibili.com/video/BV1N1oKBKEeA/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

{kind=link}
所有评论(0)