独家揭秘:自动驾驶 3D Occupancy 真值自动标注系统架构与“踩坑”实录
在自动驾驶感知领域,从 2D 图像到 BEV,再到如今大热的 3D Occupancy Network(3D 占据网络),行业对三维空间理解的颗粒度要求正在呈现指数级增长。Occupancy 不仅能优雅地解决异形障碍物(General Obstacles)的识别问题,更是迈向端到端自动驾驶的重要基石。
但理想很丰满,现实很骨感。构建一个高精度、高效率的 Occupancy 真值(Ground Truth)生成系统,远比跑通几个开源模型复杂得多。今天,就结合前沿开源方案与实际工程落地经验,和大家深度拆解一下 Occupancy 真值系统的技术架构、核心挑战以及长尾场景(Corner Cases)的破局之道。
一、 巨人的肩膀:开源方案的演进与启示
在构建我们自己的系统之前,先来看看学术界和开源界目前进展到了哪一步。
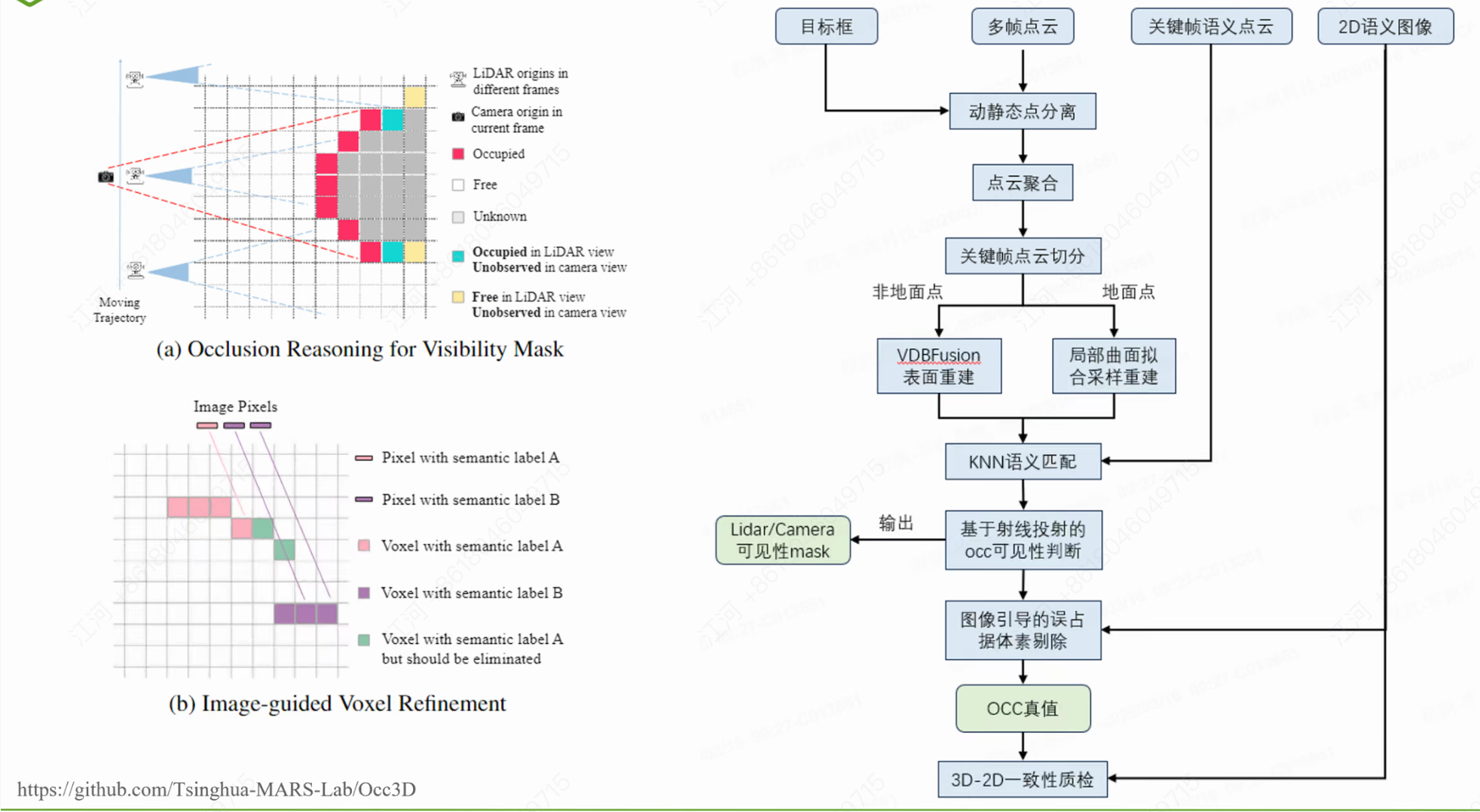
1. Occ3D (NeurIPS 2023):遮挡推理与体素细化
Occ3D 提供了一套非常经典的基于视觉和激光雷达(LiDAR)融合的标定框架。其核心亮点在于:
-
遮挡推理 (Occlusion Reasoning): 通过 LiDAR 视角的 Occupied/Free 状态与 Camera 视角的可见性进行交叉验证,生成准确的 Visibility Mask。
-
射线投射与图像引导: 利用 KNN 语义匹配和基于射线投射的可见性判断,辅以图像引导来剔除误识别的体素(Voxel),最终经过 3D-2D 一致性检查输出高质量真值。
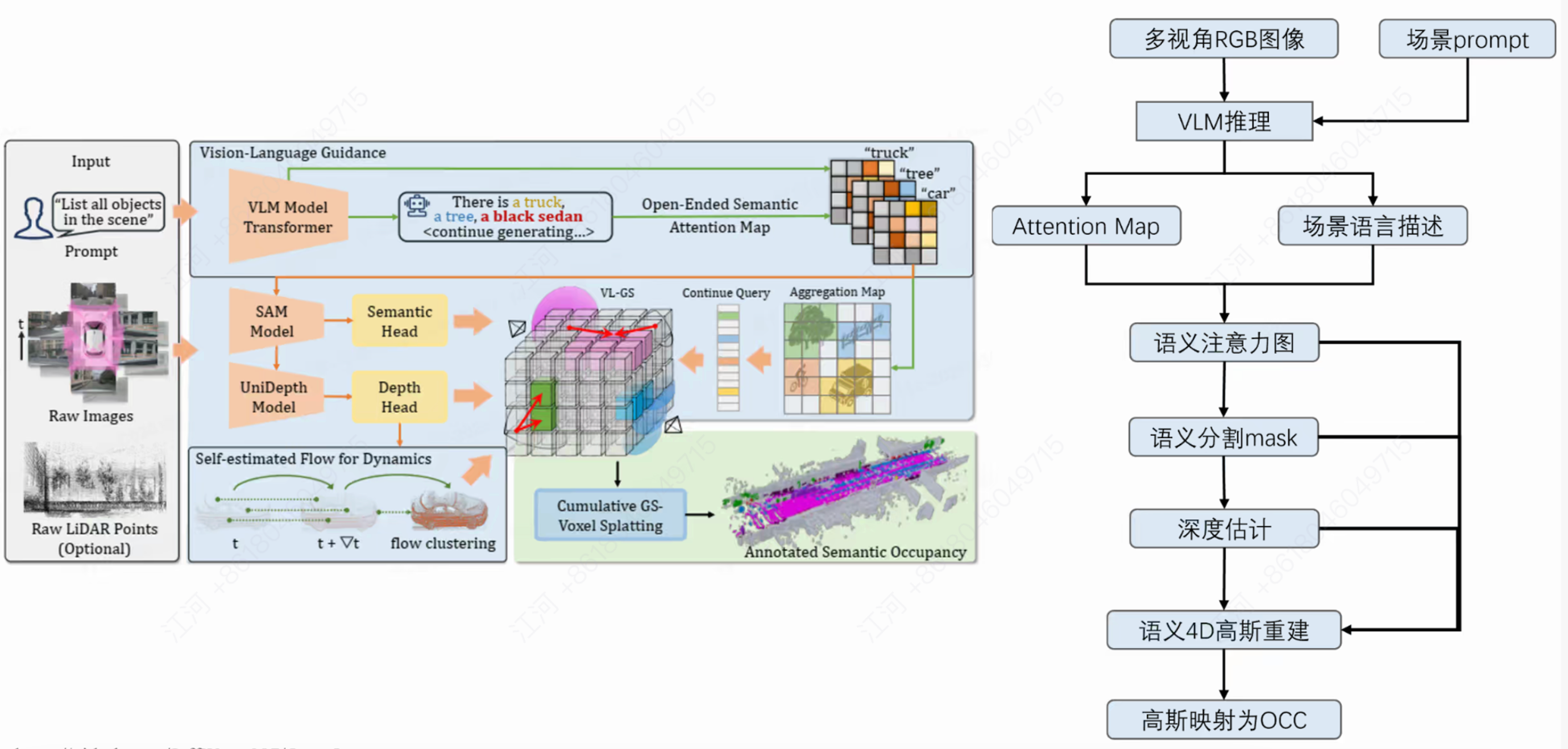
2. AutoOcc (ICCV Highlight):引入多模态大模型与 3D 溅射
AutoOcc 则代表了另一种更加前沿的探索——结合大语言视觉模型(VLM)。
-
利用 VLM(如基于 Transformer 的多模态大模型)和 SAM(Segment Anything)生成开放词汇的语义注意力图。
-
结合深度估计(UniDepth)和自监督的光流聚类来处理动态物体。
-
最惊艳的是引入了 3D Gaussian Splatting (3D GS) 进行体素特征的累加与渲染,直接降维打击传统的三维重建方法。
二、 落地挑战:为何我们必须自研 Pipeline?
开源方案虽然惊艳,但在实际车企的数据闭环中,往往会遇到以下“水土不服”的问题:
-
传感器依赖与深度缺失: 纯视觉方案受限于图像缺乏准确的深度和几何信息,极难直接标注出高精度的 3D 占据网格。因此,采用高精度 LiDAR 点云来构建真值是当前更稳妥且精准的路径。
-
稀疏性与噪点: 单帧 LiDAR 点云极其稀疏,且包含大量环境噪点(如雨雪、多径反射)。
-
特殊对象处理: 静态背景中的活动元素(如收费站抬杆)在多帧叠加时极易产生“拖影”或“残影”。
-
效率与精度的平衡: 动辄上亿规模的点云体素化,对算力和存储架构是极大的考验。
基于此,我们设计了一套**“静态叠帧 + 动态聚合 -> 点云稠密化 -> 体素化”**的真值生成总体框架。
三、 核心技术方案拆解 (Our Approach)
1. 预标注 (PreLabel) 与点云分割利器:SphereFormer
在输入端,我们依赖高精度的动态目标真值(Bounding Boxes)、基于三维重建的自车定位(Ego Pose)以及点云语义分割标签。
在点云分割模型上,我们采用了 SphereFormer (CVPR 2023)。传统算法在面临大范围占用时往往面临时间与显存成本的爆炸。SphereFormer 提出了径向窗口自注意力机制 (Radial Window Self-Attention),不仅大幅提升了远距离物体的识别能力,还极大地平衡了计算效率与精度。
2. 动静分离与多帧聚合 Pipeline
我们的数据流转过程如下:
-
分离去噪: 基于目标框将多帧语义点云分离为动态点和静态点,并进行几何与密度去噪。
-
多帧聚合补偿: 动态点基于 Box 坐标系进行多帧聚合;静态点基于 World 坐标系(结合 Ego Pose)进行运动补偿和聚合。
-
应对稀疏与噪点:
-
针对稀疏性:点素级采用全域帧点云叠加使其稠密化;体素级引入形态学膨胀 (Morphological Dilation)。
-
针对噪点:点素级基于几何特征去噪;体素级引入形态学腐蚀 (Morphological Erosion)。
-
-
体素化与后处理: 拼接后进行体素化,采用投票机制分配体素语义,最终输出语义 OCC 格式。
3. 工程化规格输出
为了适配不同的研发需求,我们在工程输出上做了精细的定义:
-
感知范围差异化: 区分行车与泊车场景。行车场景关注远距离(X轴达115.2m),体素尺寸适中(0.2x0.2x0.25m);泊车场景关注近场高精度,体素精细到(0.05x0.05x0.08m)。
-
语义状态: 包含 23 类状态(21类语义实体如 Road, Pedestrian, Car + 2类非占据状态 Free/Unvalid)。
-
存储格式: 为兼容现有大数据架构,时间戳前广对齐,使用
parquet格式落地,语义 Occ 存为 Uint8,速度栅格存为 FP32。
四、 进阶篇:让工程师掉头发的“长尾场景”后处理
标准 Pipeline 跑通只是及格,真正的核心竞争力体现在对长尾特殊对象(Corner Cases)的处理上。
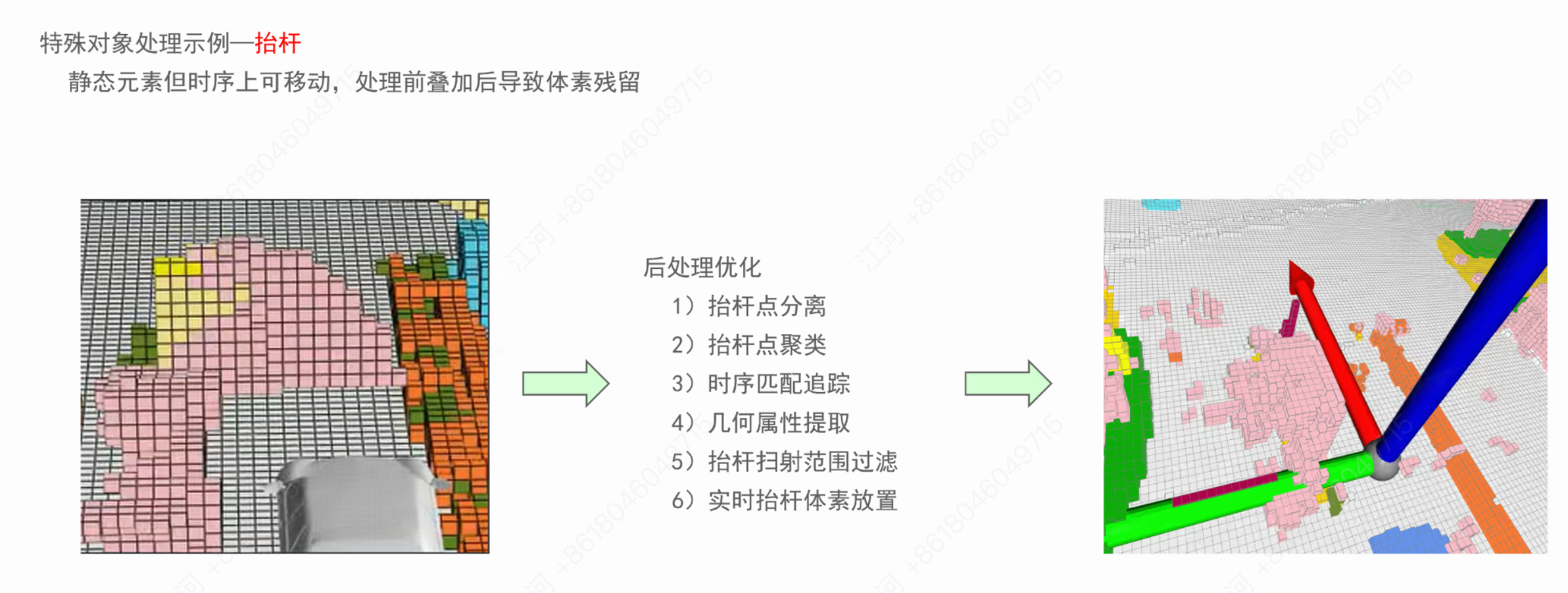
案例 1:收费站抬杆(Boom Barrier)的“残影”消除
痛点: 抬杆本质是静态元素,但在时序上可移动(抬起/放下)。如果简单粗暴地进行前向多帧叠加,体素中会残留严重的历史拖影。 后处理优化:
-
分离并聚类出抬杆点云。
-
进行时序匹配追踪,提取其几何属性。
-
核心步骤:过滤抬杆扫射范围内的无效点,并进行实时的抬杆体素精准放置,确保只呈现当前时刻的真实状态。
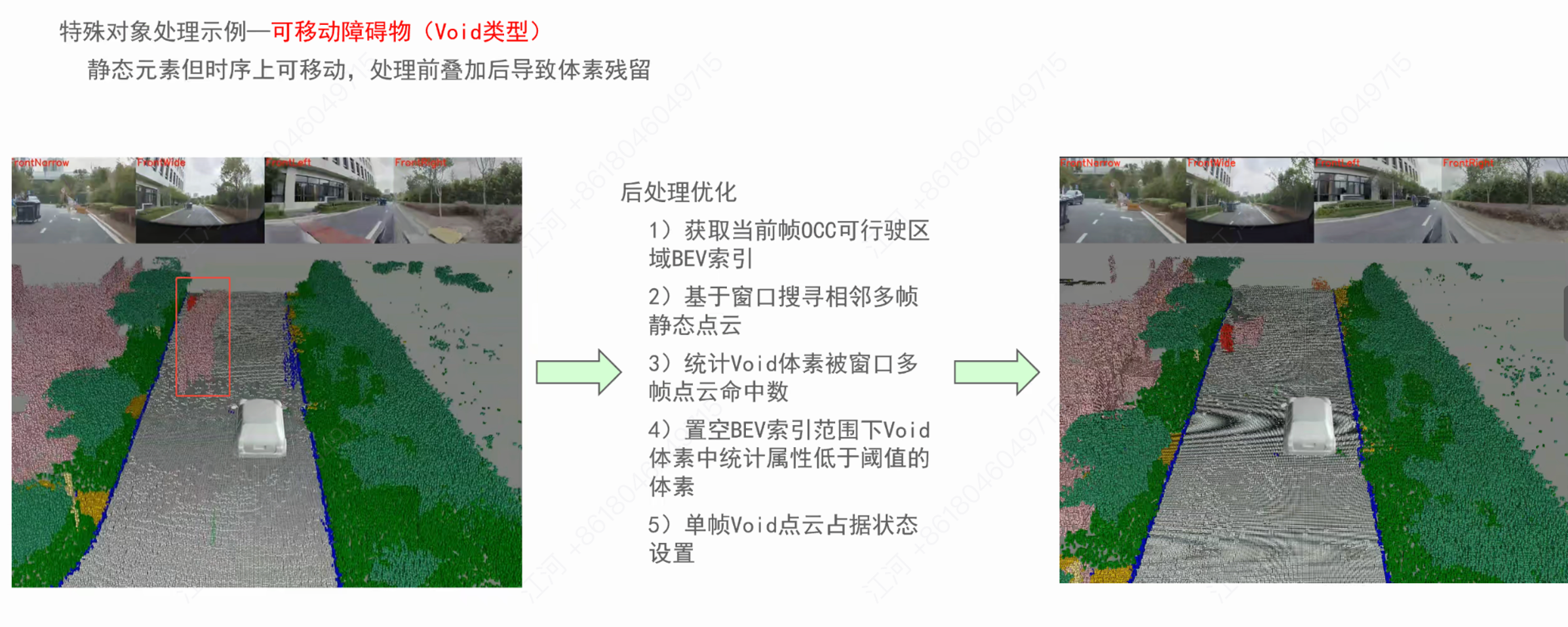
案例 2:可移动障碍物(Void 类型)的动态清理
痛点: 同样是静态变动态导致的时序叠加残影(例如被挪动的垃圾桶或路障)。 后处理优化:
-
获取当前帧 OCC 的可行驶区域 BEV 索引。
-
基于窗口搜寻相邻多帧的静态点云。
-
统计 Void 体素被窗口多帧点云命中的次数,若低于设定阈值,则直接置空 BEV 索引范围下的该体素。
-
重新设置单帧 Void 点云的占据状态,还原本真。
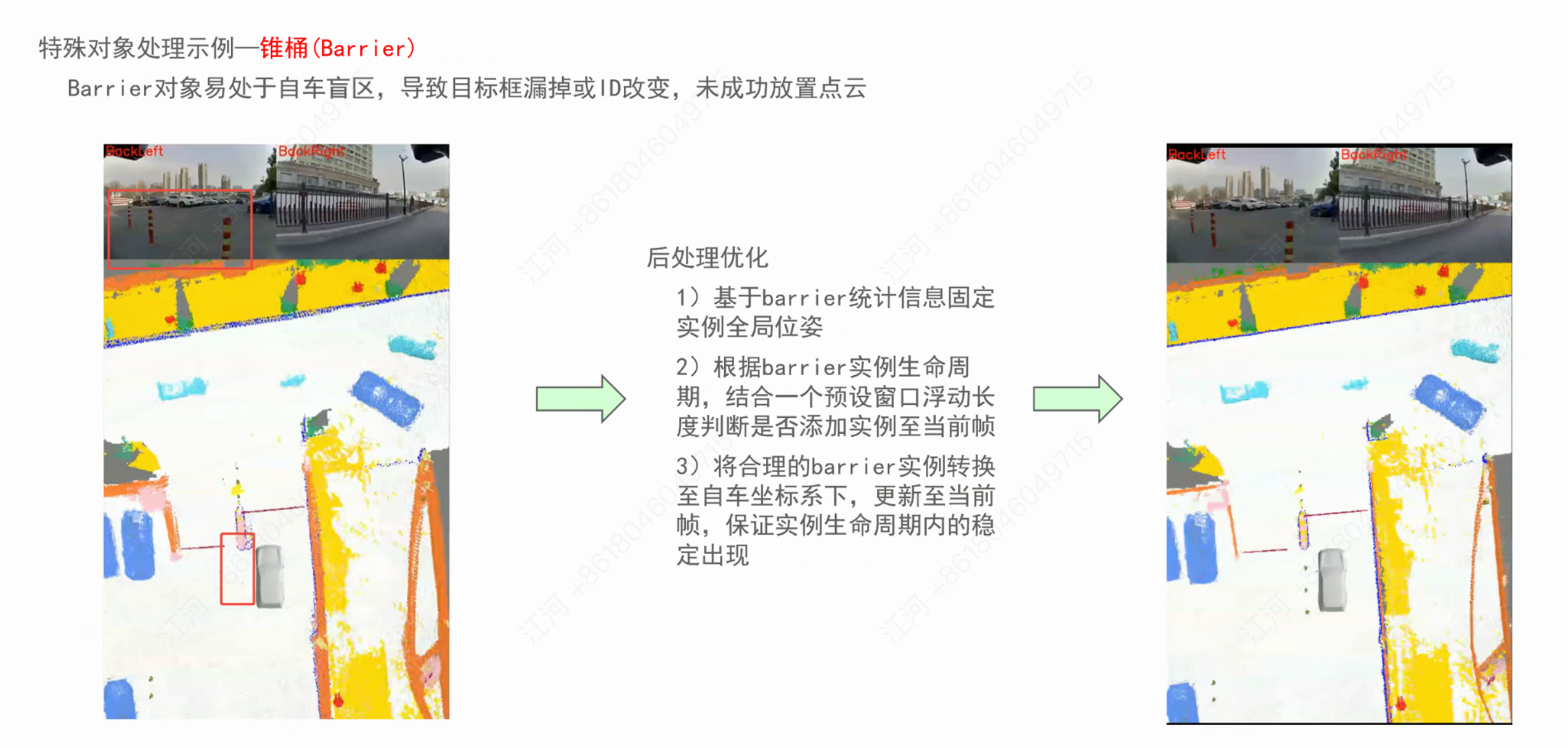
案例 3:频频“闪现”的锥桶(Barrier)
痛点: 锥桶体积小,极易陷入自车盲区,导致目标框漏掉或 ID 频繁跳变,最终无法成功放置点云。 后处理优化:
-
基于历史和全局的 Barrier 统计信息,固定其实例的全局位姿。
-
根据该实例的生命周期,结合预设的窗口浮动长度,智能判断是否需要将其“脑补”添加至当前帧。
-
将其转换至自车坐标系下,强制更新当前帧的占据状态,保证实例在整个生命周期内的稳定出现,彻底解决盲区闪烁问题。
五、 理想与现实的碰撞:量产规模化生产的“血泪教训”
当我们将这套精雕细琢的 Pipeline 推向真实的数据生产线时,作为系统架构的设计者,我们立刻迎来了现实的毒打。在海量数据的冲刷下,当前基于 LiDAR 的方案暴露出两大核心痛点:
1. 上游依赖综合征:误差级联与“空中楼阁”
OCC 真值的生成极度依赖上游预标注产物(如分割模型、目标检测框)。
-
分割与检测不匹配: 当分割模型预测错误,或者检测框未能完全包裹目标点云时,剥离出来的点云就会产生残留,导致 OCC 空间中出现莫名其妙的“空中杂点”。
-
动态目标畸变: 在高速运动场景下,动态目标本身的运动畸变叠加分割模型的预测偏差,会导致重建出的体素形状怪异,严重影响后续端到端模型的训练效果。
2. 算力与存储的黑洞:生产效率瓶颈
基于高精度 LiDAR 的全域帧叠加和极其密集的体素化操作,带来了极高的内存开销与时间成本。在追求降本增效的今天,这种重度依赖计算资源的生产模式,逼迫我们必须在算法层面进行深度的性能剖析和时空复杂度优化。

六、 降维打击?AUTO-OC 与前沿学术界的破局思路
面对传统方案的局限性,学术界给出了一条完全不同的性感路线:AUTO-OC。相比于我们在点云堆里苦苦挣扎,AUTO-OC 展现了基于大模型降维打击的潜力。
AUTO-OC 的核心杀手锏:
-
开放词汇(Open-Vocabulary)的无痛标注: 传统 OCC 方案最大的痛点是依赖“预定义类别”(比如设定好的 21 类)。而 AUTO-OC 引入了预训练的 VRM 大模型,通过多视角 RGB 图像,只需输入自然语言 prompt(如“列出场景中的所有物体”),就能动态生成场景描述和语义注意力图,彻底打破了类别的次元壁。
-
2D 到 3D 的完美一致性: 利用注意力图引导 SAM(Segment Anything)进行零样本的精准实例分割,并结合 UniDepth 估计深度。
-
引入 3D 高斯溅射(3D Gaussian Splatting): 将语义和深度信息作为监督信号,训练 3D 高斯模型,通过 Alpha 混合实现三维空间加权语义渲染。
既然 AUTO-OC 这么强,为什么我们目前的数据生产依然沿用 LiDAR 方案?
这本质上是一个**“算法前沿性”与“工程落地可行性”**的架构取舍。AUTO-OC 虽然实现了惊艳的语义一致性,但它的效果严重依赖 VRM 和深度估计模型的性能上限。在面对动态物体、快速变形的复杂物理场景时,其鲁棒性仍显不足。对于当前急需高精度、高稳定数据“喂养”量产模型的业务线来说,基于 LiDAR 的工程化方案虽然略显笨重,但结果更可控、底盘更稳。
七、 架构演进与未来展望:下一代 OCC 数据闭环走向何方?
站在架构设计的十字路口,结合当前的痛点与前沿趋势,下一代 OCC 真值自动标注系统必将迎来三大维度的演进:
1. 从“几何驱动”向“语义驱动”跨越
目前我们是以 LiDAR 的几何信息为主导,语义仅作为附加属性,且后处理逻辑异常复杂繁琐。未来,必将结合 VLM(视觉语言大模型)引导的开放词汇标注,利用强大的语义关系来反向指导和补全几何结构的缺失,让系统具备真正的“常识”。
2. 从“单模态依赖”向“多模态融合”演进
彻底告别仅依赖 LiDAR 的现状。参考 AutoOcc 的设计理念,探索以高画质视觉为核心、Camera 优先的量产真值方案,结合图像丰富的语义信息和开源大模型,对 LiDAR 生成的几何结构进行交叉校验和语义校正。
3. 终极形态:基于世界模型(World Model)的 OCC 预测
与其费尽心思地去“拼接”和“重建”物理世界,不如让模型直接“生成”它。结合 Generative AI(生成式模型),在给定条件(Condition,如 HDMap、三维 Box)下,直接预测和生成长尾场景下的 OCC 状态。这不仅能以极低的成本解决 Corner Case 数据稀缺的问题,更是实现数据生产效率跨越式提升的终极密码。
八、 写在最后:持续迭代的技术苦旅
自动驾驶的下半场,拼的是数据的质量、闭环的效率以及系统架构的弹性。
对于目前的 OCC 自动标注系统,我们仍有硬仗要打:一方面,需要彻底厘清动态目标在多帧数据中的生成与聚合机制,从根源上斩断“拖影”现象;另一方面,针对内存与时间的高昂开销,算法的工程化重构与性能榨取依然是近期的绝对优先级。
从 2D 到 3D,从预定义到开放词汇,从规则堆砌到世界模型,技术的进化从未停止。希望这篇踩坑实录与架构拆解,能为同在自动驾驶数据泥沼中前行的各位提供一些参考和启发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)