马斯克点赞的 Attention Residuals:Kimi 如何重写 Transformer 的残差连接
在讲大语言模型时,大家最熟悉的 usually 是 attention(注意力机制)。它决定当前 token 该看前面哪些 token。但 Kimi 这篇《Attention Residuals》盯上的不是 token 与 token 之间的信息流,而是另一个更底层、却长期被默认接受的结构:层与层之间的信息到底怎么传。论文的判断很直接:今天的大模型在序列维度上已经学会了“选择性关注”,但在深度维度上,很多模型还在沿用一种相当机械的做法——前面所有层的输出一股脑往后累加。作者认为,这种做法在模型越来越深时,会带来信息稀释和状态膨胀的问题,于是他们提出了 Attention Residuals,也就是“注意力残差”。
层之间的注意力
要理解这篇论文,先得明白残差连接在 Transformer 里到底干了什么。我们平时会说残差连接是“梯度高速公路”,因为它让梯度可以绕过复杂变换,直接往前传,这对训练深网络非常重要。但论文指出,残差连接其实还有第二个作用:它定义了不同深度的信息如何聚合。标准 PreNorm 残差的展开结果,本质上就是把前面所有层的输出用固定权重相加。这意味着模型虽然在 token 选择上很灵活,但在“该多信第 3 层还是第 20 层”这件事上,却没有显式选择机制。
问题也就出在这里。按照论文的分析,PreNorm 下这种固定相加会让隐藏状态的幅度随着深度持续增长,量级上接近 O(L)。层数一深,单个层的贡献会越来越容易被淹没,早期层的信息会被埋进越来越厚的累积表示里。你可以把它想成写报告时不断把旧版本、批注版、修改版全部叠在一起,但每次都不做筛选。最后文档当然还保留了全部历史,可真正有用的信息反而更难被直接取出来。作者把这种现象概括为 PreNorm dilution,也就是 PreNorm 下的信息稀释。
Attention Residuals 的核心想法,就是把这种“固定相加”改成“先打分,再加权汇总”。具体来说,第 l层不再默认继承前面所有层的统一和,而是对前面各层输出做一次沿深度维度的 softmax 注意力,得到一组权重 αi→l(第 l 层给第 i 层分配的“参考权重”),再按这些权重做加权和:
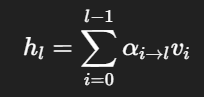
这里最关键的变化不在公式表面,而在含义上:第 l 层终于可以主动决定,自己现在更该参考哪些历史层。不是所有旧信息都同等重要,也不是所有深度都该平均继承。这个变化,相当于把注意力机制从“token 之间选重点”进一步推广到了“层之间选重点”。
很多人第一次看到这里会卡在“softmax 注意力”这几个字上。其实把它说成人话并不复杂:模型先给前面每一层一个分数,再把这些分数通过 softmax 变成一组全为正、总和为 1 的权重。分数高的层,最后占比更大;分数低的层,占比更小。于是原本“无条件全部继承”的残差路径,变成了“按当前内容动态选取”的残差路径。论文还特别强调,这些权重不是固定常数,而是 learned、input-dependent 的,也就是模型学出来、并且会随输入内容变化。
分块
当然,这个想法马上会遇到一个现实问题:如果每一层都去看前面所有层,开销怎么办?论文给出的工程答案是 Block AttnRes。它不要求每一层都直接访问全部历史层,而是先把网络分成若干 block。块内仍然用普通残差快速累积,块与块之间再做注意力聚合。这样一来,完整 AttnRes 需要的内存和通信规模可以从 O(Ld) 降到 O(Nd),其中 L 是总层数,N 是 block 数。GitHub README 里也用一张总览图把三种结构摆在一起:标准残差是统一相加,Full AttnRes 是每层回看所有历史层,Block AttnRes 则是在块级别做这个选择。
硬件方面的努力
在小规模训练里,Attention Residuals 的额外代价其实不大,因为反向传播本来就要保存激活值,跨层读取前面表示并不会额外引入太多成本。真正的问题出现在大模型训练阶段。为了省显存,训练通常会用 activation recomputation(激活重计算 / 检查点重算),也就是不把所有中间结果一直存下来,而是在反向传播时再算一遍;同时还会用 pipeline parallelism(流水线并行),把不同层切到不同设备或不同 stage(阶段)上顺序执行。在这种情况下,AttnRes 需要反复访问前面层或前面 block(块)的历史表示,这就不再只是“多做一点计算”,而会变成明显的内存读写和跨设备通信开销。论文也因此指出,Full AttnRes 在大规模训练时的主要挑战,不是公式本身,而是如何把这些跨层历史信息高效地保存、读取和传递。
为了解决这个问题,作者先用了 Block AttnRes,把原来“每层看所有历史层”改成“每个 block 只看前面 block 的摘要表示”,先把开销从按层增长压到按 block 数增长。然后又补了两套工程优化。第一套是 cache-based pipeline communication(基于缓存的流水线通信)。这里的 stage(阶段),指的不是模型里的某个抽象步骤,而是 pipeline parallelism(流水线并行)里切分到不同设备上的一段模型层;而 P 指的就是 physical stages(物理流水线阶段数),也就是这条流水线一共被切成了多少个真正分布在设备上的大段。在这种设置下,同一台设备往往会连续处理多个 virtual stage(虚拟阶段),所以前一个阶段已经收到过的 block 表示,没有必要下一阶段再完整传一次。作者的做法,就是把这些已接收的 block 缓存在本地,后续 stage 之间只传“新增的那部分 block”,而不是每次都把全部历史重新搬运一遍。这样一来,单次阶段切换时的通信峰值,就可以从原来和总执行块数 C 相关的 O(C),降到只和物理流水线阶段数 P 相关的 O(P),本质上就是减少不同流水线分段之间对同一批历史信息的重复传输。
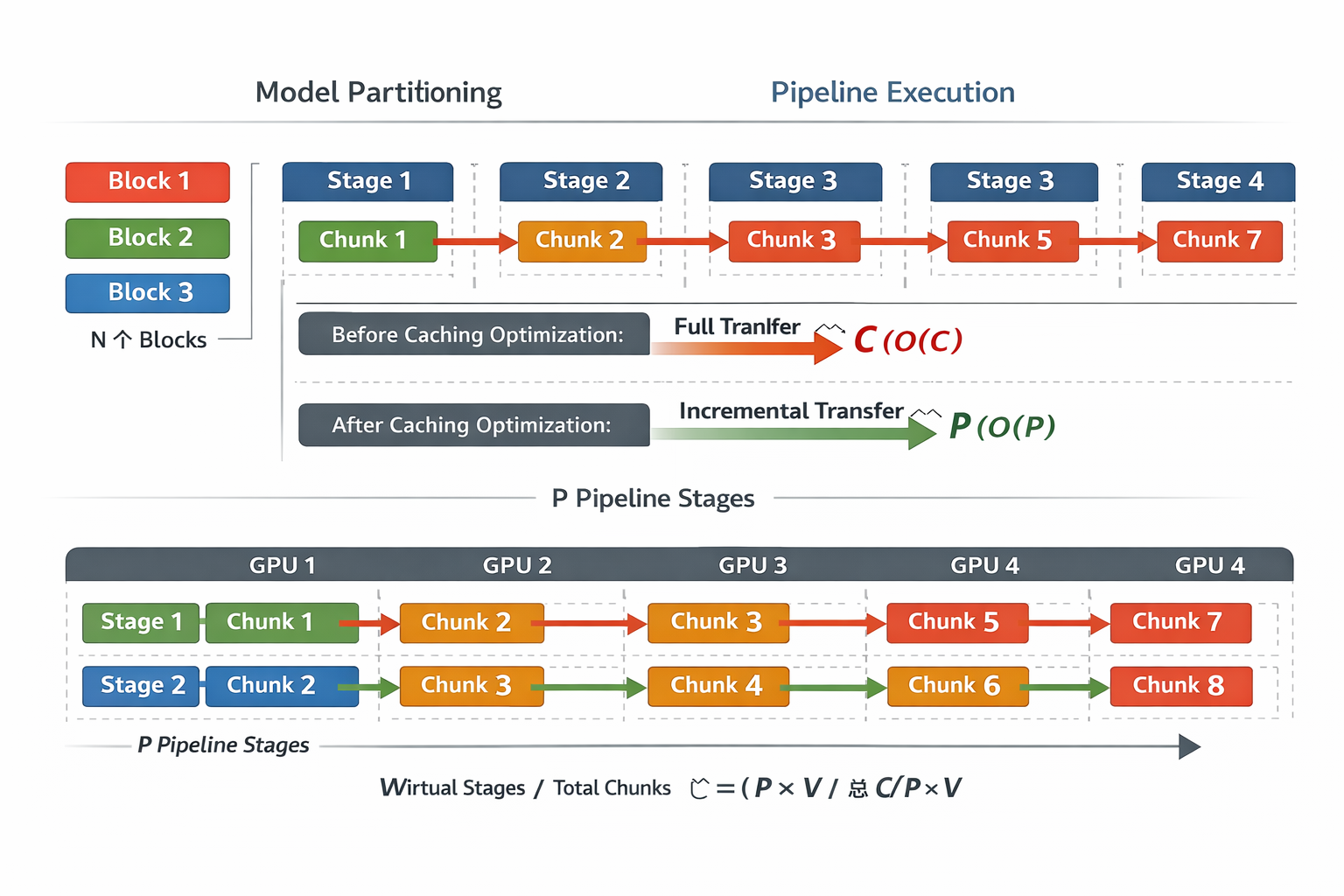
Chunk:交错流水线中,一个物理阶段在一个虚拟阶段上的执行单元
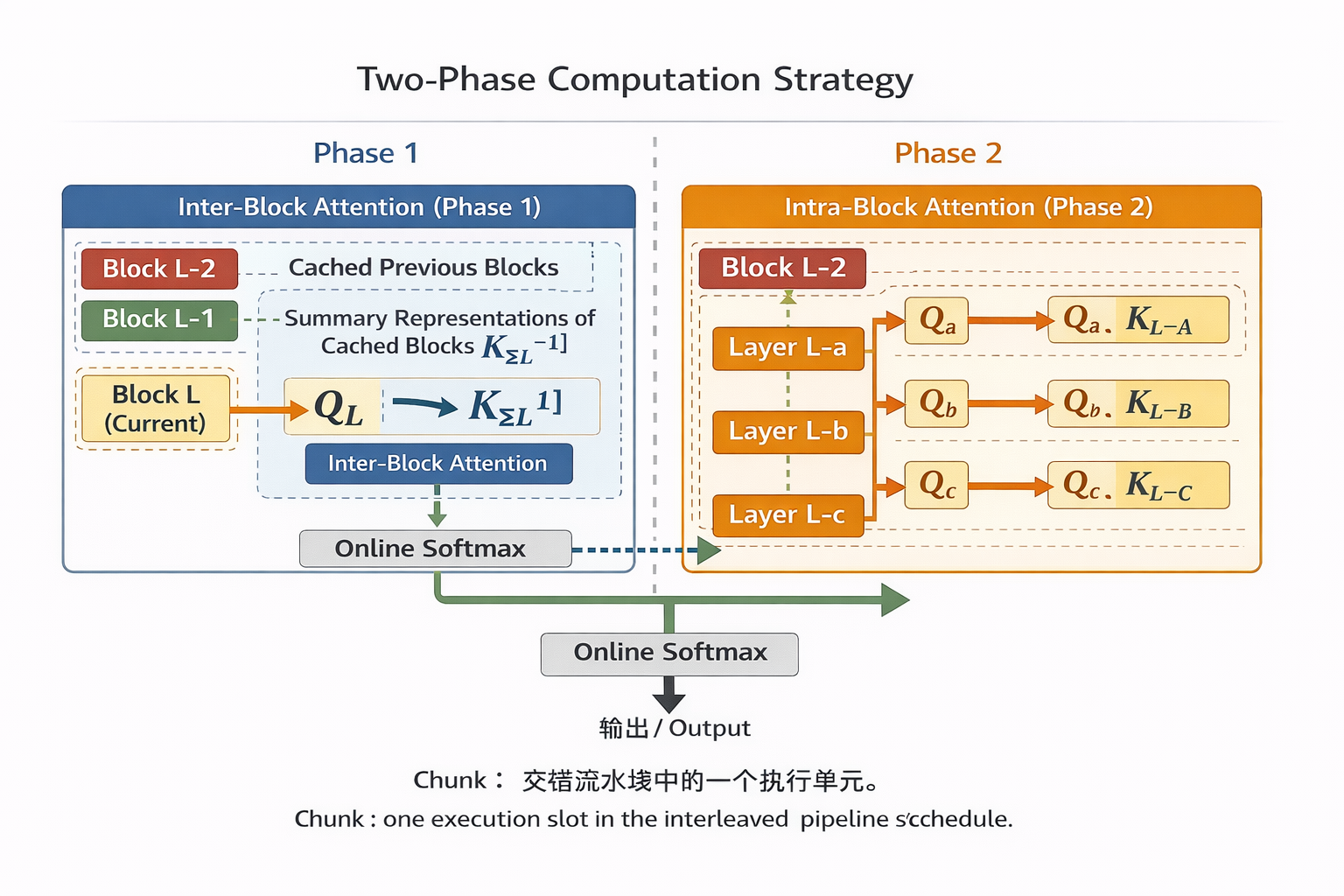
第二套是 two-phase computation strategy(两阶段计算策略),它主要解决推理时“反复读取历史 block 太慢”的问题。作者把一个 block 内的计算拆成两步。第一步先把这个 block 里所有层的 query 一起打包,对前面已经缓存好的 block 表示做一次并行的 inter-block attention(块间注意力);这样原本每层都要各读一遍历史,现在变成整个 block 只读一遍。第二步再在 block 内部按层顺序做 intra-block attention(块内注意力),也就是处理当前 block 里逐层累积出来的局部信息;最后再用 online softmax(在线 softmax)把“块间结果”和“块内结果”精确合并。这样设计的核心价值,就是把最贵的那部分历史读取做成批处理,把一次 block 内多层共享的部分摊薄掉。论文明确写到,Phase 1 把对历史 block 的读取从每层一次,降成每个 block 一次;Phase 2 的 I/O 规模则基本保持在和标准残差相近的水平。
实验结果
实验部分是这篇论文另一个值得注意的点。作者先做了 scaling law 实验,结论是 AttnRes 在不同计算预算下都稳定优于 baseline,而 Block AttnRes 达到了相当于 baseline 多用 1.25 倍算力训练才能接近的 loss 水平。这个结果很重要,因为它说明收益不是只在某个特定尺寸模型上偶然出现,而是具有跨规模的一致性。对于架构改动来说,这比单个 benchmark 上涨几分更有说服力。
作者随后把 AttnRes 集成进 Kimi Linear 架构,使用的是 48B 总参数、3B 激活参数、1.4T token 预训练 的设定。按论文给出的表格,AttnRes 版模型在所有已评估下游任务上都没有输给 baseline,并且在一些更依赖多步推理和组合式信息流的任务上提升尤其明显,比如 MMLU 从 73.5 提到 74.6,GPQA-Diamond 从 36.9 提到 44.4,HumanEval 从 59.1 提到 62.2,C-Eval 从 79.6 提到 82.5。作者据此推断,更好的深度信息流,对需要后层回收并重组前层表示的任务尤其有帮助。
训练动态分析也很能说明问题。论文展示的图里,baseline 随深度增加,输出幅度会明显抬高,而梯度又更偏向前部层;相比之下,Block AttnRes 的输出幅度更受控,梯度在不同层之间也更均匀。论文把这作为它缓解 PreNorm dilution 的直接证据之一。这个结果的直观含义是:模型不再需要靠越来越夸张的深层输出来“压过”前面积累的历史总和,也不再让梯度过度集中在少数层上。网络在深度维度上的“力学结构”因此更平衡。
从方法论上看,这篇论文最值得记住的并不是某个具体分数,而是一种新的思考方式。过去大家已经默认:序列维度要用 attention,因为信息不该平均看待;专家路由要动态分配,因为不同输入该走不同专家;但到了深度维度,很多模型仍然默认“所有前层都一视同仁”。AttnRes 提出的正是一个非常朴素、但后劲很强的问题:既然模型已经学会按内容选择 token,为什么不能按内容选择层? 从这个角度看,Attention Residuals 不只是一个残差变体,更像是在把“可学习路由”从序列、专家,再推进到网络深度本身。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)