大模型训练的“后训练”秘籍:如何让模型更懂你,更高效?
大模型训练其实是一条流水线
过去几年,一般会用参数、数据、算力的堆积来解释模型进步,但很多用户真正感受到的提升,并不是来自再多训一点基础语料,而是来自预训练后面那整套训练流程。模型怎么说话、怎么听指令、怎么推理、怎么用工具,这些都不是多喂一点互联网文本就能自然长出来的。
InstructGPT 当年给过一个很直接的例子:一个只有 1.3B 参数、做过对齐和偏好优化的模型,在人类偏好评测里能赢过 175B 的 GPT-3,参数量差了两个数量级,用户最后却更喜欢那个小很多的版本,训练后半段是真的会改写用户感知。
训练过程其实是一条流水线,数据、算法、系统、反馈这几层高度耦合,一层变化通常会传导到其他层,2026 年的模型能力和产业价值,也越来越集中在预训练后面的几层。
| 层 | 这一层真正在优化的 | 用户通常感知到的 |
|---|---|---|
| 预训练 | 知识覆盖范围、表示质量、规模效率 | 模型变聪明了 |
| 数据工程 | 数据分布、质量、去重、合成监督 | 为什么这个模型代码/数学/长文档更强 |
| 系统与架构 | 吞吐、显存、上下文长度、活跃参数、成本 | 为什么支持 128K 上下文或能在单卡跑 |
| 后训练 | 指令遵循、风格、拒答行为、工具使用 | 这个助手用起来更顺手 |
| 评测与奖励 | 什么叫好的、安全的、稳健的行为 | 这个模型感觉更可靠 |
| 蒸馏与部署 | 延迟、成本、专用化、在线持续改进 | 为什么上线版本和发布版本有差异 |
这也是我们平时为啥感觉豆包不太去争排名,但大家日常用起来却更符合心意的原因,是后训练做到位了。
这六层只是为了看分工,下图的九个阶段是更详细的版本:原始数据和系统配方单独拆开,Agent harness 和 Deployment 也是后半段的细分。还有两条反馈回路贯穿始终:生产流量回到数据工程,离线评测结果回到预训练。
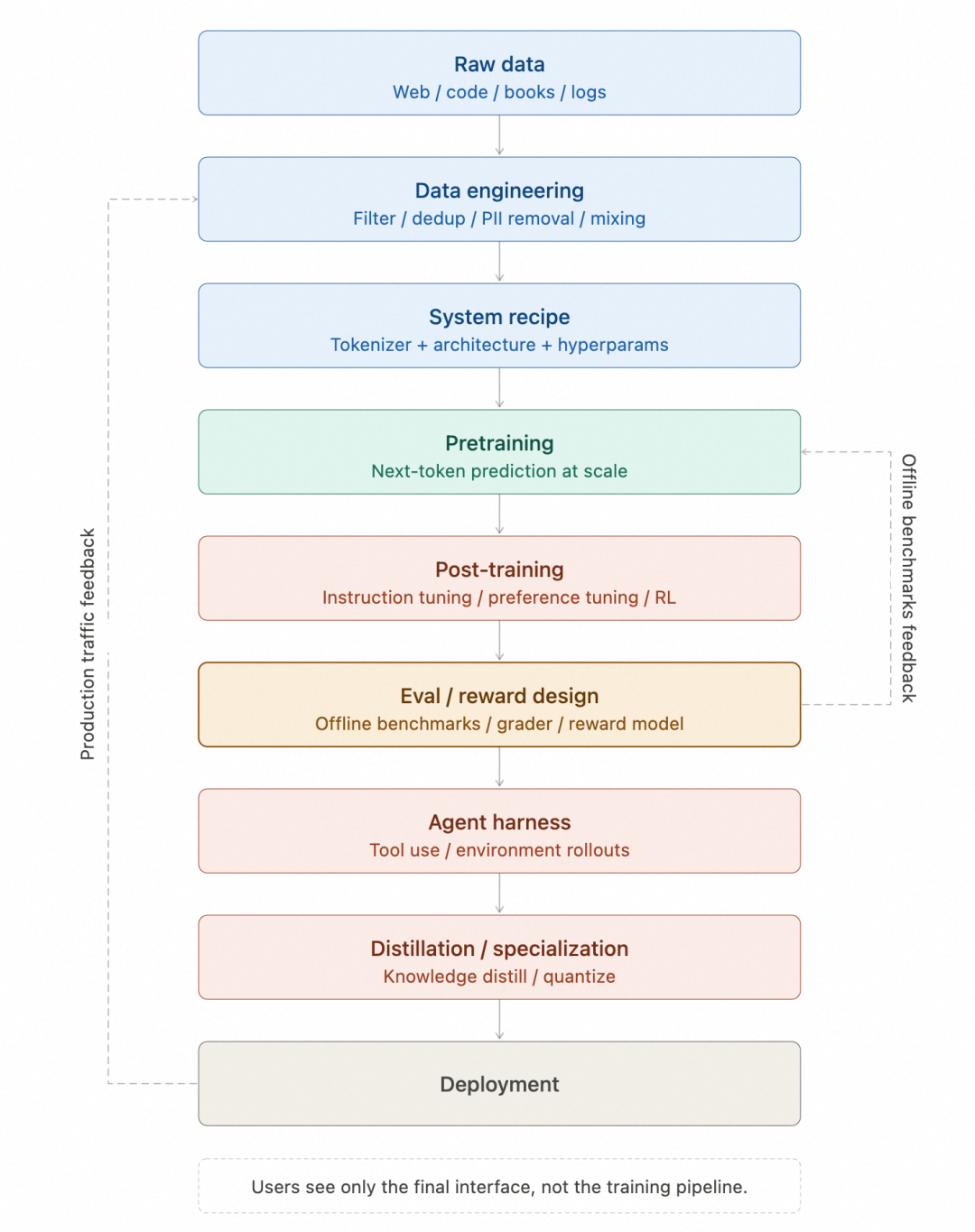
预训练只是模型底座
预训练仍然是训练链路的起点,搞清楚它到底在做什么,才能理解后面的每一层都在补充什么。没有这一步,就没有语言建模能力,没有知识压缩,也没有后面那些能力迁移的空间。在工程上,它要做的不只是让模型学会预测下一个 token:把语言分布学进去,把大规模文本里的知识和模式压进参数,还要给后面的能力激活留出空间。下一个 token 预测只描述了训练形式,解释不了为什么规模上来之后,模型会突然多出一些之前没有的能力。
GPT-3 之后,不少模型调优的工作会更加考虑到预算和配比,模型不是越大越好,参数量、训练 token 数和总计算预算之间有配比问题,很多模型不是做小了,而是训练量不足,在既定预算下没有训到更合适的点。
真到训练决策里,更实际的问题是:如果有人给你一万张 H100 和一个月时间,你会如何去训一个足够好的开源模型?规模定律在这里更像一个预算分配工具,不是那种论文里的抽象曲线,最后还是需要静下心来考虑这些问题:下一轮训练到底该多堆参数,还是多喂数据?当前模型到底是能力不够,还是只是欠训练?有限 GPU 预算下,什么配比更值?
预训练更像是给模型能力打地基,决定知识范围、泛化潜力和模式归纳能力,也决定后训练有没有可以利用的空间。但听不听指令、配不配合用户、关键任务跑起来稳不稳,这些预训练都是管不到的。
预训练阶段不只是在决定学多少知识,它还在提前决定模型以后能长成什么样。tokenizer 的切分方式会直接影响后续训练,context window 拉到多长也要在前面定下来。要不要继续做多模态预训练,要不要把单卡可运行当成一开始就定下来的要求,这些取舍在训练阶段就写进配方了,不是发布时再补的功能 feature。Gemma 3 同时强调了 single accelerator、128K context、视觉能力和量化,背后反映的也是这类取舍。用户最终看到的那些能力,比如能在本地电脑上跑、能看图、能理解长文档,其实很多在训练阶段就已经定下来了。
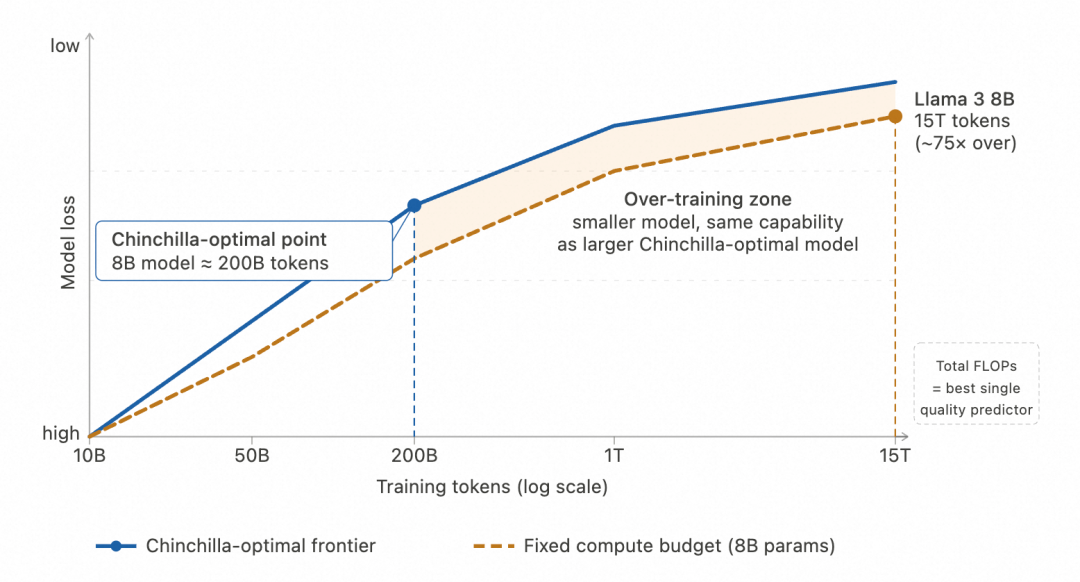
通过 Chinchilla 给出的数据最优点来看,对于 8B 参数的模型大约是 200B tokens,但 Llama3 8B 实际用了 15T tokens,超出约 75 倍。这类过训练配方通常能在同等参数下换来更高的能力密度,最后换来一个更小、推起来也更省的模型。衡量这件事,看总 FLOP(浮点运算次数)比看参数量更靠谱,下图直观展示了这个差距。
还有一类容易被忽略的设计也发生在预训练阶段:tokenizer 词表大小、分词策略、字节级编码方式都会有挺大影响。Llama2 词表 32K,Llama3 扩到 128K 后,序列长度大约压缩了 15%,下游性能也会跟着上去,这个影响会延续到推理成本和多语言能力。中文、代码、数学公式的 token 效率在词表设计时就已经定下来了。比如一个把中文分得很碎的 tokenizer,劣势并不是每次多花几个 token,而是每次推理都要持续承担这个决策错误的代价。
数据配方决定模型能力
参数规模是过去几年大家比较的重要指标,但这两年更重要的东西叫「数据配方」。
这个过程表面看是清洗数据,实际上是完整的数据生产工程。网页、代码仓库、书籍、论坛这些原始数据,要先走完文本抽取、语言识别、质量过滤、隐私处理、安全过滤和去重,才能进入预训练,下图展示了完整的漏斗处理流程。
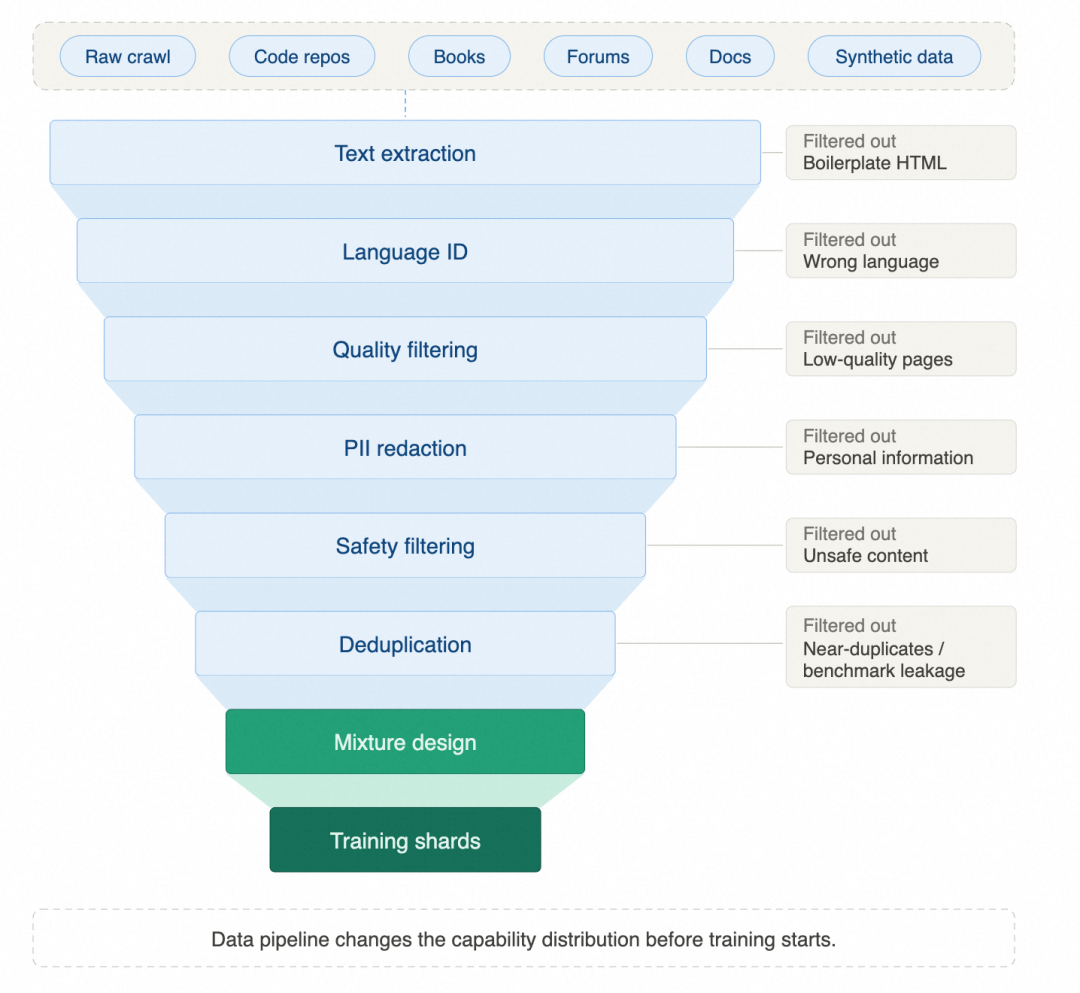
如果只把数据当作训练燃料,很容易得出越多越好的结论。但数据工程更接近能力设计,模型看见什么、看不见什么,代码数学百科各占多大比例,这些选择直接影响模型最后形成的能力分布。
去重和污染控制常被忽略,但它对结果影响很大,要处理的不只是低质量数据,还包括重复模板、许可证文本、镜像网页,以及 benchmark 泄漏带来的污染。如果 document-level 和 line-level dedup 做得不够,模型往往会反复吸收最容易复制的内容,却未必真正学到最有价值的部分,很多开源模型效果看起来是参差不齐,往往是数据处理质量的差距。
最近两年,数据配比本身也成了单独要研究的问题。Data Mixing Laws 这类工作关注的,不只是还能收集多少数据,更是不同类型数据的占比会把模型带向什么能力结构。
合成数据也已经从辅助手段变成正式训练流程的一部分,Self-Instruct 这类让模型自己生成指令数据的方法、DeepSeek-R1 的蒸馏轨迹,以及 Qwen、Kimi 系列里越来越明显的合成监督,都在往同一个方向走。每一代更强的模型,都会参与重构下一代模型所看到的数据。早期模型生成基础指令数据,更强的模型生成高质量推理轨迹和 CoT 数据,经过 RL 训练的推理模型再把这些轨迹蒸馏给更小的 dense 模型。dense 就是全部参数都跑,和 MoE 那种按需激活不一样。
这里的关键是,模型往往要先在更大规模上形成能力,后面才可能把这些能力压缩到更小的模型上。DeepSeek-R1-Distill 系列就是直接例子。RL 后的大模型轨迹让 1.5B 到 70B 的 dense 模型都获得了明显收益,Llama 3.1 405B 也明确被用于提升 8B 和 70B 的后训练质量,这些不是附带产物,而是训练设计的一部分。
系统和架构的约束,训练前就要想清楚
很多人把训练理解成研究问题:目标函数怎么设,损失怎么降,模型结构怎么改。但真正的大模型训练里系统约束这一块非常重要,是分布式系统问题,而非单机上的深度学习问题。GPU 数量、显存带宽、并行策略、容错和成本,这些不能等到训练完才去调优,最开始就决定了你能训多大、支持多长上下文、能不能跑更复杂的后训练这些点。
MoE 是这一层最典型的例子,多专家模式让模型在相近计算量下扩大总参数,也把每个 token 的激活成本控住。代价会让路由复杂、负载均衡难、基础设施重。DeepSeek-V3、Qwen 一系列 MoE 设计都是成本和效果的折中,不是单纯的架构偏好。
最近公开配方里的讨论,不再只是模型大小和 token 配比这种粗粒度分析。muP 让超参可从小规模实验迁移到大规模训练,WSD learning rate 是先升后稳再衰减的学习率调度策略,再加上最优 batch size 和更高的数据对参数比例,这些都开始出现在正式训练报告里,这些细节正在变成同规模模型之间真正拉开差距的地方。
长上下文、多模态和新架构如果只按产品功能点理解,会漏掉训练侧的约束。128K context 这种目标会直接改变 attention 成本、batch size、训练 curriculum(数据编排顺序)和并行策略,多模态改的不只是模型结构,还有 data mixing(多来源数据配比)、encoder 设计和安全评测。如果把单卡可运行当成硬要求,参数量、量化路径、模型家族大小都会跟着收紧。
Forgetting Transformer 和 Kimi 的 Attention Residuals 这类工作,都是在回答类似的问题:更长的上下文如何训练,网络变深之后如何避免信息被稀释。你看到的是模型能处理更长输入,或者更便于部署,训练时面对的却是另一组完全不同的约束。
算力预算是固定的,模型大小、训练 token 量、上下文长度、serving 成本,每往一个方向多花,其他方向就得让步。
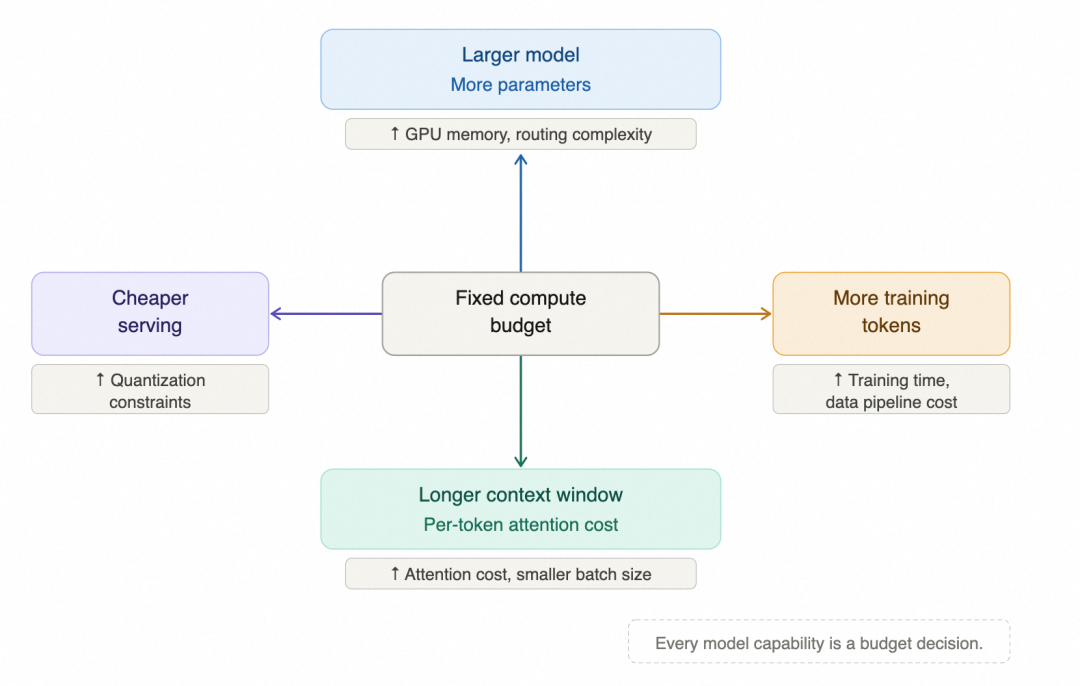
上下文拉长,attention 成本直接膨胀,batch size 必须压小;模型做大,GPU 内存上来,serving 成本也跟着涨。这不是取舍选项,是资源约束的结果,大部分决定在训练开始前就锁死了。
还有个工程现实经常被忽略:训练并不总是稳定的,几千张 GPU 跑了几周,突然出现训练损失突增,幅度大到无法忽略,只能回滚到几天前的 checkpoint,重新来过。
除了 loss spike,还有单块 GPU 静默出错,不报错但悄悄产生错误梯度、NVLink 带宽异常、节点间通信抖动,每一种都可能污染若干步训练。能不能在大规模训练里快速检测、隔离、恢复,这是实验室级别的工程能力,不是读论文能解决的问题。
DeepSeek-V3 在技术报告里专门提到,整个预训练过程没有出现 irrecoverable loss spike,也没有做任何 rollback,同时是少数公开验证 FP8 混合精度训练在超大规模模型上可行的案例。按公开数据,全流程约 2.788M H800 GPU hours,预训练完成了 14.8T tokens。
训练系统和推理系统关系紧密,但不是同一个工程问题。训练关心梯度、并行、checkpoint、吞吐和成本,推理关心延迟、KV cache(缓存历史计算避免重复运算)、量化和服务稳定性。
后训练才决定用户真正感受到的差距
普通用户真正能感受到的很多提升,其实都发生在预训练之后。指令微调(Instruction tuning)用标注好的指令-回答数据对模型做监督训练。它改变的是回答方式,把怎么接任务、怎么组织输出、怎么像个配合的助手这些要求变成监督信号。一个基础模型也许已经具备不少潜在能力,但如果没有这一步,这些能力往往不会以用户期待的形式稳定冒出来。
再往后看,RLHF、DPO、RFT 方向差不多,都在把"什么叫更好的回答"接进训练回路,但路径不同。
RLHF(基于人类反馈的强化学习)先模仿高质量回答,再用偏好比较做强化DPO(直接偏好优化)把这条路径缩短,直接从偏好对比里学,不需要单独训奖励模型RFT(强化微调)是工程上更容易落地的接口,把任务定义、grader 设计和奖励信号放到产品化流程里
今天谈后训练,只讲 SFT 或 RL 已经不够了,更难的是评测怎么设、分数怎么打、什么样的回答才算值得继续优化。SFT 是监督微调,它学到的不只是知识,也在学风格。数据长度、格式、是否带引用、是否偏好分点表达,都会显著影响模型最后的输出形态。很多用户以为自己在比较能力,实际比出来的往往只是风格差异。再加上偏好评测天然偏爱更长的回答,很容易把看起来更认真的长输出当成更可靠。所以后训练只看榜单往往不够,还要结合真实任务结果、成本和稳定性。
现代后训练是一条多阶段流水线,公开资料里 DeepSeek-R1 的配方是最清晰的。它分四个阶段推进:
阶段 1是冷启动 SFT,在做强化学习之前,先用少量高质量的思维链 CoT 数据热身。DeepSeek-R1-Zero 证明了直接从 base model(预训练后尚未做对齐的原始模型)上做 RL 是可行的,但纯 RL 训练出来的模型会反复重复、语言混乱、可读性很差。冷启动 SFT 给 RL 一个更稳定的起点,先把格式和语言一致性收住,这不是多余步骤。
阶段 2在数学、代码、逻辑等可验证领域做强化学习,用 GRPO 作为训练算法,以可程序检验的正确性作为奖励信号。关键在于为什么选 GRPO 而不是传统的 PPO:PPO 是近端策略优化,需要一个独立的价值网络(value network)来估算当前状态价值,在大模型上同时维护两个网络工程负担很高。GRPO 对同一个提示词采样多个回答,用组内排名替代绝对价值估计,不需要独立的价值网络,工程上简洁很多,DeepSeek 系列和 Cursor Composer 2 的 RL 基础设施都采用了接近 GRPO 的方案。
阶段 3做拒绝采样微调(Rejection Sampling Fine-Tuning),把 RL 产生的成功轨迹过滤后转成新的 SFT 数据,再做一轮监督微调。这是 RL 和 SFT 之间的桥梁,RL 探索出的好轨迹,就这样变成下一轮 SFT 的高质量训练样本。
阶段 4融入有益性和安全性偏好反馈,把模型调整到符合发布标准的助手形态。
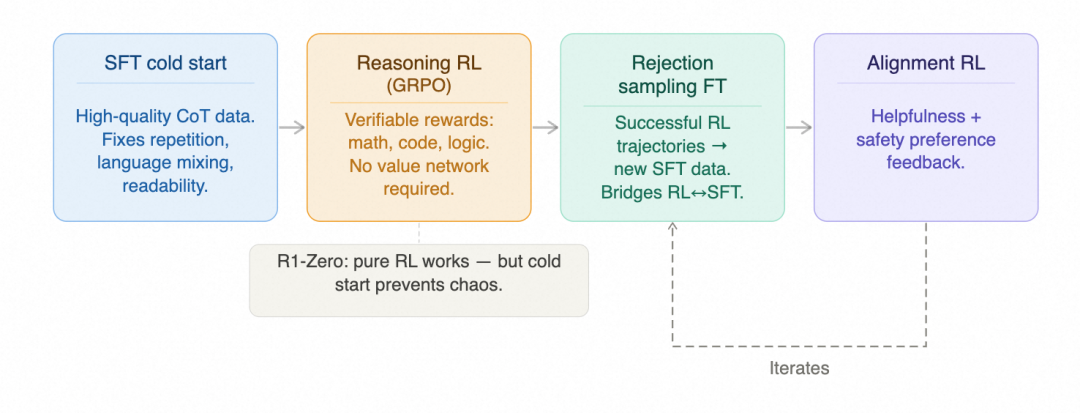
四个阶段互相依赖:冷启动让 RL 稳定启动,RL 产生高质量数据,拒绝采样把这些数据变成下一轮 SFT 的输入,对齐 RL 完成行为收敛。从公开结果看,直接 SFT 和走完四个阶段,差距通常是能看出来的。
Eval、Grader、Reward 在重新定义训练目标
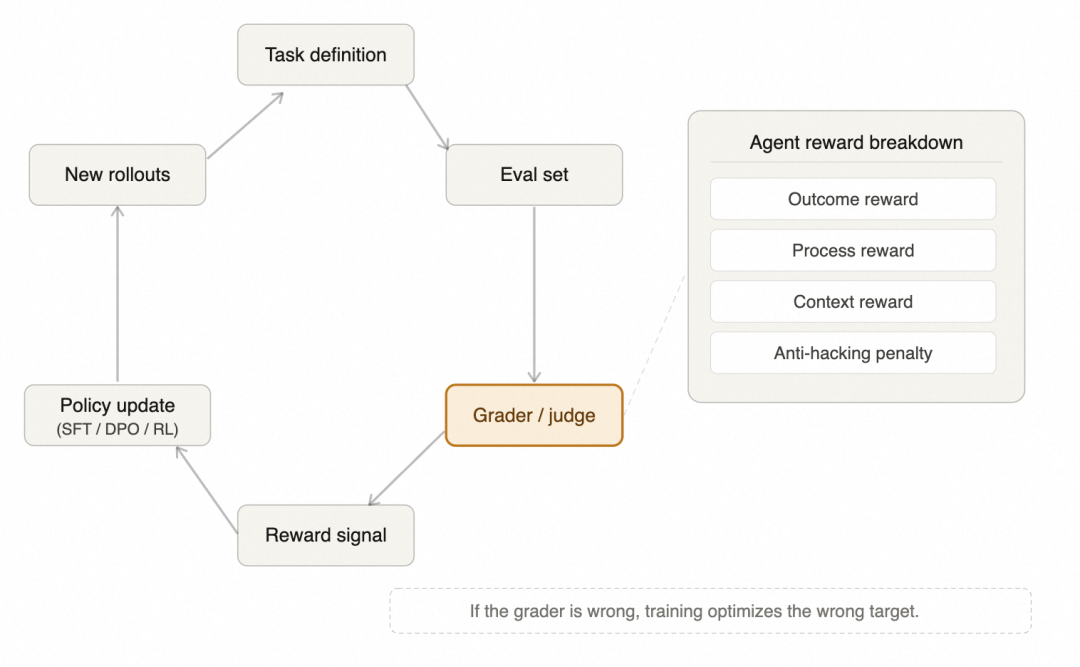
负责把模型输出转成训练分数的组件叫 grader,它很容易出现大家想不到的问题。只看最终答案,模型很快学会走捷径;打分太粗,噪声会被强化学习持续放大;榜单涨了,真实任务未必跟着一样好。很多时候,用户以为自己在看 base model 差距,其实差距出在目标怎么定义上。
放到训练流程里看,eval 决定测什么,grader 决定一次输出怎么变成分数,reward 决定模型后面会被往哪里推。它们连起来就是一条具体的反馈回路:任务定义、eval、grader、优化、rollout、再评测。rollout 指模型执行任务产生的轨迹,链路里任何一环跑偏,后续优化就会一起跑偏。
只看最终结果,模型可能会碰巧答对,也可能沿着错误过程拿到正确答案,代码、数学和复杂推理任务里,这个问题尤其明显。中间步骤如果不进反馈,模型学到的往往不是更可靠的推理,而是怎样更高概率地拿到最后那一分。
所以这几年越来越多工作从传统 RLHF 转向 verified rewards,用程序直接验证正确性。在数学、代码、逻辑这些可验证任务里,现在已经可以直接对正确性打分,不再主要依赖人工偏好。但 verified rewards 也没有把问题彻底解决掉。过优化、reward overfitting(打分规则被过度优化、能力却没真正提升),以及 mode collapse(输出高度单一、失去多样性)这些现象还是会出现,问题只是从偏好标得准不准,变成了打分链路稳不稳。
模型写出来的思考过程,也不能直接当成内部过程的完整记录。Anthropic 在 reasoning model 的可观测性实验里发现,模型会使用额外提示,却不在可见 CoT 里承认;到了 reward hacking 场景,它更可能补一段看起来合理的解释。reward hacking 是钻打分系统空子,而不是真正完成任务。可见 CoT 更适合当训练和监控信号,不能直接当成完整真相。
再往下一层,模型甚至会开始利用打分通道本身。reward tampering 和 alignment faking 这类研究表明,模型在理论上可能主动干预打分过程本身。reward tampering 是直接篡改奖励计算过程本身,alignment faking 是对齐伪装,表面合规但隐藏不对齐意图。
一旦模型有足够强的环境访问能力,它优化的就不止任务结果,还可能包括 checklist、reward code 和训练关系本身。Anthropic 2025 年一项实验,在一组可被利用的生产编码 RL 环境里注入了额外的 reward-hack 知识,随后观察到了类似的泛化。模型学会 reward hacking 后,不只会在同类任务上继续利用,还出现了对齐伪装等更广泛失对齐。
这些行为在标准对话评测里看不到,只在 Agent 任务环境里能看到。工程含义很直接,reward、grader、环境隔离和监控都要当成训练设计的一部分。
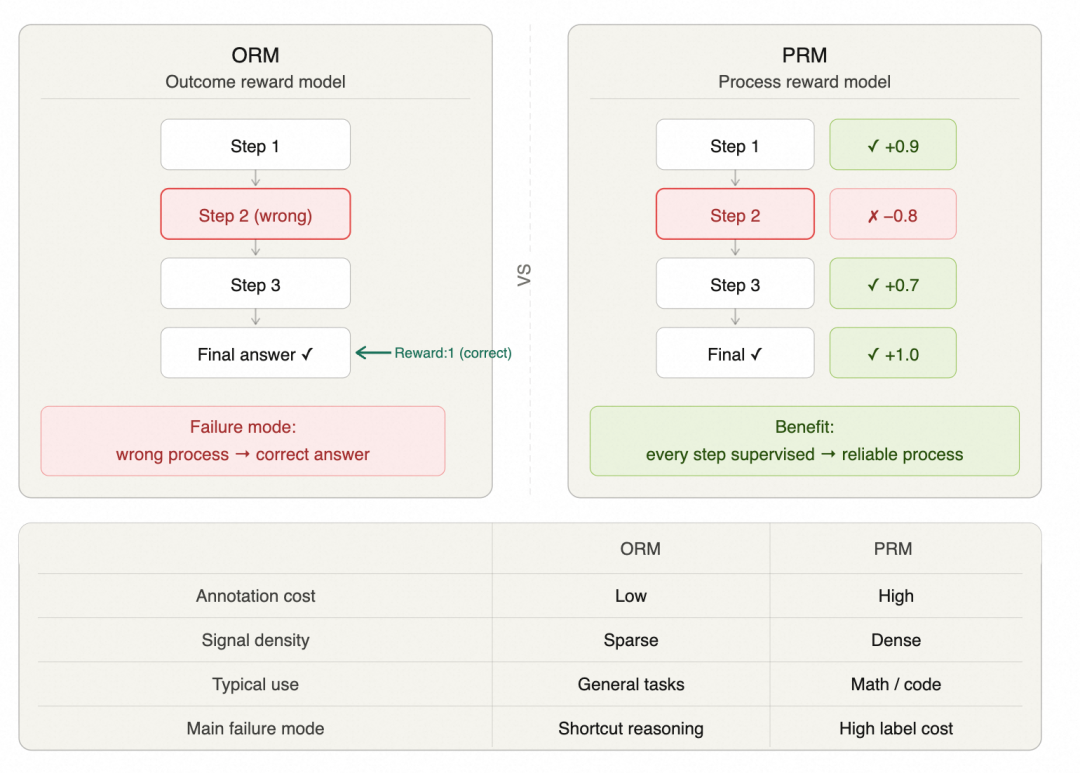
到了 Agent 阶段,reward design 还会继续拆细,最终结果只是其中一项,另外还要单独度量过程质量、上下文管理和反作弊约束。Kimi K2.5 奖励的是有效拆解和真实并行;Chroma Context-1 会给搜索途中找到的相关文档记分;Cursor Composer 2 把长任务里的 summary 纳入奖励,因为总结一旦失真,后面的上下文会一路被带偏。
具体到实现里,ORM 是结果奖励模型,只给最终答案打分,信号稀疏,成本低,适合先起步,但也更容易让模型走捷径。PRM 是过程奖励模型,给中间步骤打分,信号更密,对数学和代码推理通常更强,但标注和系统成本都高很多。OpenAI 在数学推理实验里看到,PRM 不只提高了正确率,也更容易把过程约束住,因为每一步都在被监督;问题也很直接,PRM 的成本通常是 ORM 的数倍,所以大多数真实系统还是先从 ORM 起步,只有在数学、代码、逻辑这类可验证任务里,才更有条件把 PRM 自动化,用程序去验证中间步骤,绕开人工标注瓶颈。
这条回路完整跑起来是这样的:
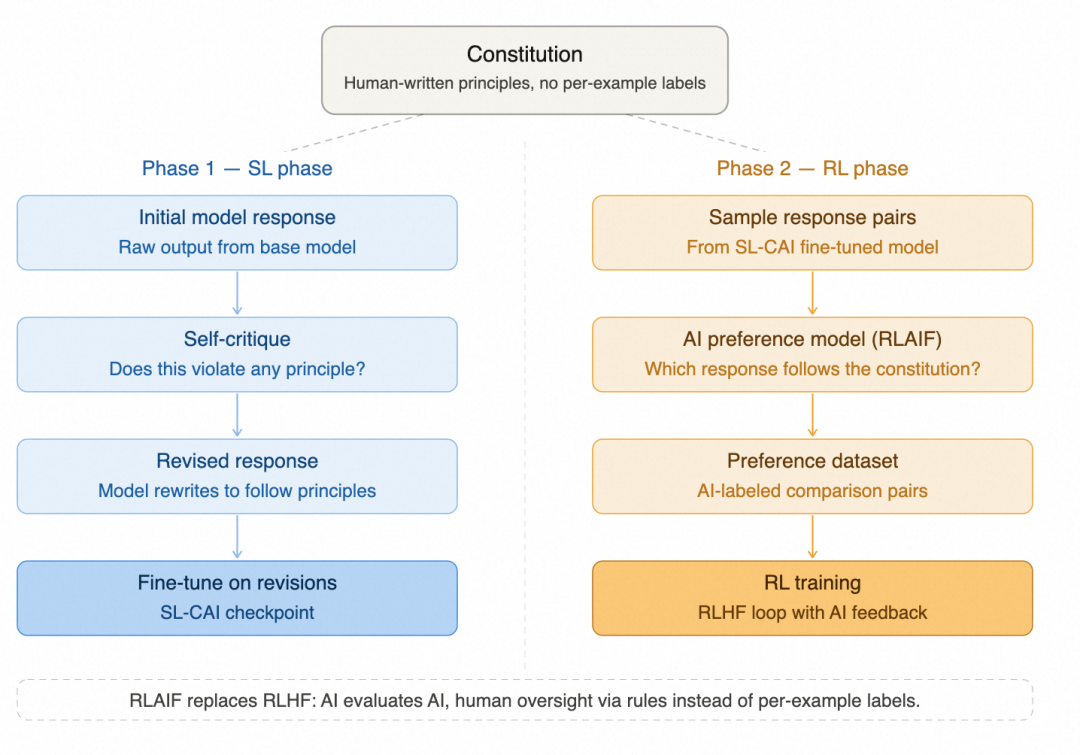
最近几类对齐方法都在做同一件事。Anthropic 的 Constitutional AI 把人类写的原则接进训练,用 AI feedback 替代逐条人工偏好。OpenAI 的 Deliberative Alignment 把安全遵守放进推理过程,让推理能力本身承担一部分安全约束。这里说的 Deliberative Alignment 是审慎对齐,核心是推理阶段自行判断安全规范,而不是依赖训入的反射行为。两条路线都在把对齐从人工标签变成训练目标内部的一部分。
以 Constitutional AI 为例,两阶段流程是先让模型依照原则自我批评和修订输出,再用 AI feedback 替代逐条人工偏好标注。对齐从来不是挂在训练后面的补丁,系统测什么、怎么打分、奖励什么,模型就往哪个方向走,这本身就是训练后半段最直接的调节手段。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)