09 ComfyUI + SDXL 文生图工作流,一篇带你搞懂
别再乱调参数了!一篇带你搞懂 ComfyUI + SDXL 文生图工作流,效果直接拉满
这是一篇适合新手直接照着复现的 ComfyUI + SDXL 实战文章。
通过一个“超可爱水豚做早餐”的案例,带你搞懂最基础的文生图工作流、Prompt 写法和参数配置。
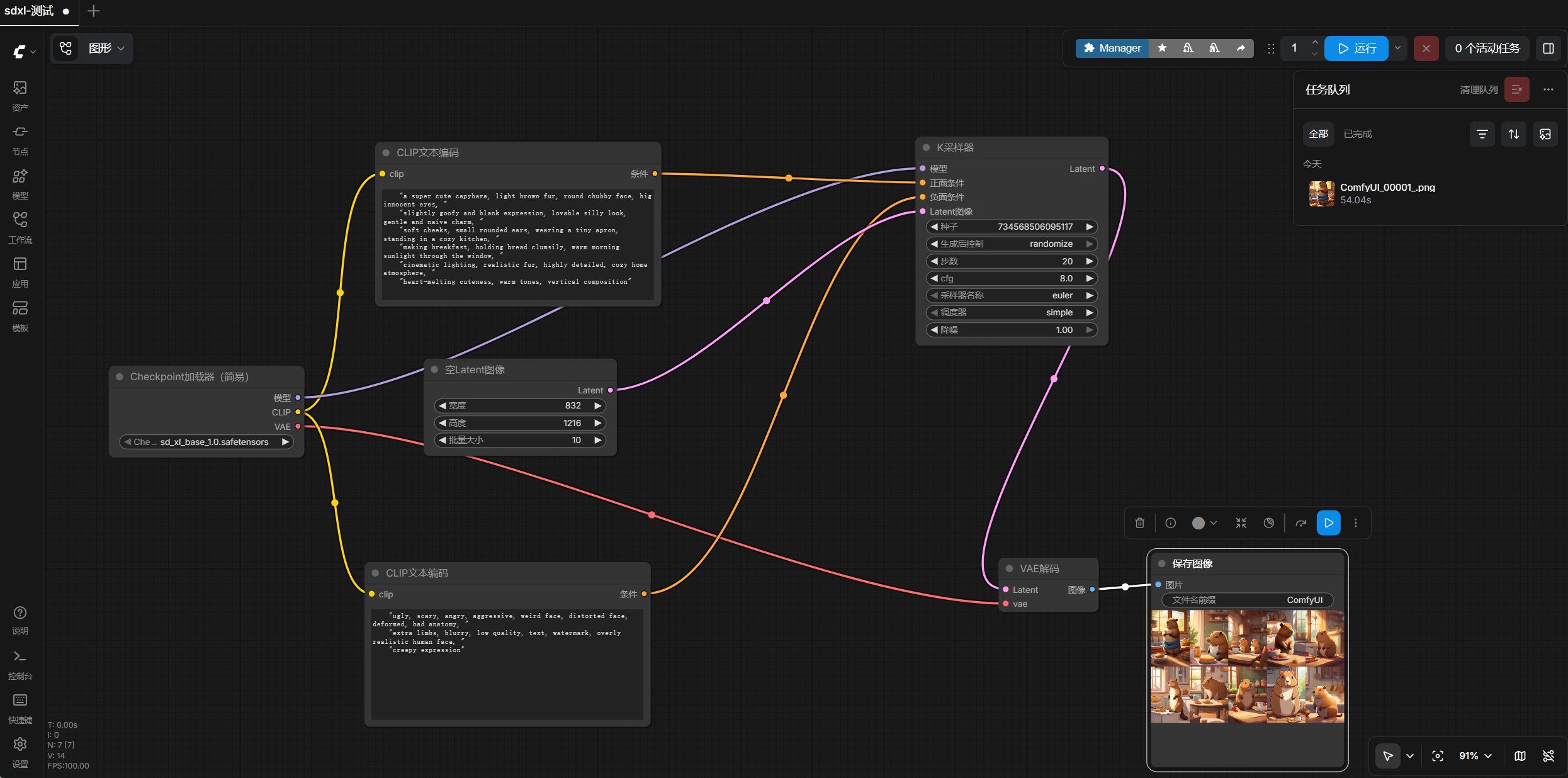
工作流

最终效果
前言:为什么你学了 ComfyUI,还是出不了满意的图?
很多人刚接触 ComfyUI 时,都会遇到几个很典型的问题:
- 节点看起来不复杂,但就是不会搭完整流程
- Prompt 抄了很多,生成效果却还是不稳定
- 参数认识归认识,一组合起来就容易翻车
- 明明是文生图,最终效果却总感觉差点意思
其实问题并不一定出在 ComfyUI 本身,而是因为你还没有一套真正能跑通、能复现、能理解的基础工作流。
所以这次我直接拿一个完整案例来拆解:
使用 sd_xl_base_1.0.safetensors 模型,在 ComfyUI 中搭建一套最基础、但非常实用的 SDXL 文生图流程,包括模型加载、正反向提示词编码、Latent 初始化、KSampler 采样、VAE 解码和图片保存 [1][2]。
为了让测试更有趣,我没有选择常见的人像案例,而是用了一个非常有画面感的主题:
一只穿着围裙、在温馨厨房里笨拙做早餐的超可爱水豚
实际跑下来,这套工作流不仅可以稳定出图,而且画面在暖色调、厨房氛围、毛发质感和可爱表达上都比较统一。
如果你也想快速理解 ComfyUI + SDXL 的基本工作方式,这篇文章可以直接照着复现。
一、先看本次案例的核心目标
本次生成的主题可以概括为:
- 主体:水豚
- 风格:可爱、治愈、温暖
- 场景:厨房、早餐、晨光
- 画面:高细节、电影感光照、竖构图
相比单纯生成一个角色,这种“主体 + 动作 + 场景 + 氛围”的写法,更容易让图片具备故事感。
二、这套 ComfyUI 工作流包含哪些节点?
本次使用的是最经典的一条 SDXL 基础文生图链路,主要节点如下:
CheckpointLoaderSimple:加载 SDXL 模型CLIPTextEncode:输入正向提示词CLIPTextEncode:输入反向提示词EmptyLatentImage:创建空白 Latent 图像KSampler:执行采样生成VAEDecode:将 latent 解码为图片SaveImage:保存结果图像 [1][2]
如果你是第一次用 ComfyUI,可以先记住一个最基础的公式:
模型 + Prompt + Negative Prompt + Latent + 采样器 = 最终图片
ComfyUI 的优势就在于:
它不是“黑盒出图”,而是把这条完整链路拆成可视化节点,方便你逐步理解每一步在做什么。
三、本次使用的模型
本次工作流使用的主模型是:
sd_xl_base_1.0.safetensors
它是通过 CheckpointLoaderSimple 节点加载的 [1]。
如果你当前拿到的是 diffusers 格式模型,也可以先转换成 ComfyUI 常用的 safetensors 格式。转换方式如下 [3]:
1)下载转换脚本
wget https://raw.githubusercontent.com/huggingface/diffusers/main/scripts/convert_diffusers_to_original_sdxl.py
2)执行模型转换
python convert_diffusers_to_original_sdxl.py \
--model_path /work/models/sdxl-base-diffusers \
--checkpoint_path /work/models/sd_xl_base_1.0.safetensors \
--use_safetensors
如果你已经有 sd_xl_base_1.0.safetensors,那这一步可以直接跳过。
四、先把可复现参数放出来,照着抄就能跑
很多教程喜欢先讲原理,但对新手来说,最重要的其实是:
先跑通,再理解。
下面是本次工作流里最关键的一组参数:
1)模型
sd_xl_base_1.0.safetensors
[1]
2)图像尺寸
- 宽度:
832 - 高度:
1216 - 批量大小:
10[1][2]
3)KSampler 参数
seed:734568506095117steps:20cfg:8sampler_name:eulerscheduler:simpledenoise:1[1][2]
4)图片保存前缀
ComfyUI[1]
这套参数的优点很明显:
- 容易复现
- 稳定性不错
- 出图速度和质量比较平衡
- 很适合新手理解基础采样配置
五、正向提示词(Prompt)怎么写?这次直接给完整版本
本次使用的正向提示词如下 [1][2]:
a super cute capybara, light brown fur, round chubby face, big innocent eyes,
slightly goofy and blank expression, lovable silly look, gentle and naive charm,
soft cheeks, small rounded ears, wearing a tiny apron, standing in a cozy kitchen,
making breakfast, holding bread clumsily, warm morning sunlight through the window,
cinematic lighting, realistic fur, highly detailed, cozy home atmosphere,
heart-melting cuteness, warm tones, vertical composition
这段 Prompt 写得比较完整,建议从 5 个层次来理解。
1)主体特征
- capybara
- light brown fur
- round chubby face
- big innocent eyes
也就是:
一只浅棕色毛发、圆脸、大眼睛的可爱水豚。
2)表情与气质
- slightly goofy and blank expression
- lovable silly look
- gentle and naive charm
也就是:
呆萌、憨憨的、很有亲和力。
3)动作设计
- wearing a tiny apron
- making breakfast
- holding bread clumsily
也就是:
穿着小围裙,在厨房里笨拙地做早餐。
4)场景描述
- standing in a cozy kitchen
- warm morning sunlight through the window
也就是:
温馨厨房、晨光照进来、家庭氛围感强。
5)风格与质感
- cinematic lighting
- realistic fur
- highly detailed
- cozy home atmosphere
- warm tones
- vertical composition
也就是:
电影感光照、真实毛发、高细节、暖色调、竖图构图。
六、为什么 Negative Prompt 一定要写?
很多新手容易忽略反向提示词,结果就是:
- 脸崩
- 结构畸形
- 多肢体
- 画面怪异
- 甚至出现莫名文字和水印
本次使用的反向提示词如下 [1][2]:
ugly, scary, angry, aggressive, weird face, distorted face, deformed, bad anatomy,
extra limbs, blurry, low quality, text, watermark, overly realistic human face,
creepy expression
它的作用可以简单理解为:
告诉模型“哪些内容不要出现”。
例如:
ugly:避免生成太丑scary/creepy expression:避免恐怖感weird face/distorted face:避免五官扭曲deformed/bad anatomy:避免结构畸形extra limbs:避免多肢体blurry/low quality:避免低清图text/watermark:避免画面出现文字和水印overly realistic human face:避免水豚脸被生成得太像“真人脸”
对于“动物拟人 + 可爱风”这种题材来说,Negative Prompt 非常重要。
七、这套参数为什么适合新手?核心原因其实就 4 点
1)尺寸适合做角色场景图
本次使用尺寸为 832 × 1216 [1][2],是比较典型的竖构图。
这个尺寸很适合:
- 主体居中
- 上下保留环境空间
- 同时表现角色和场景关系
如果你是做角色故事感图片,这种比例很实用。
2)Batch Size 直接开到 10,方便筛图
本次 batch_size = 10 [1][2]。
优点很直接:
一次生成 10 张图,更容易从中挑出表情、构图、氛围最满意的结果。
如果你的显存不够,也可以把它改成:
124
根据显卡情况来调整。
3)Steps=20,速度和质量平衡得比较好
本次采样步数设置为 20 [1][2]。
这个数值属于比较稳妥的入门区间:
- 不会太慢
- 也能保证基本细节
- 很适合第一轮测试
如果后续你想追求更高细节,可以尝试:
- 24
- 28
- 30
4)CFG=8,属于比较稳的默认值
本次 cfg = 8 [1][2]。
可以简单理解为:
这个参数控制模型对 Prompt 的“服从程度”。
- 太低:模型容易自由发挥
- 太高:画面容易变僵、变硬
8 基本是一个平衡型配置,特别适合新手起步。
八、工作流节点是怎么连接的?看懂这个你就算入门了
从整体结构上看,这条工作流的连接关系是这样的 [1][2]:
CheckpointLoaderSimple输出模型给KSamplerCheckpointLoaderSimple输出 CLIP 给两个CLIPTextEncode- 一个
CLIPTextEncode负责正向提示词 - 一个
CLIPTextEncode负责反向提示词 EmptyLatentImage输出 latent 给KSamplerKSampler输出 latent 给VAEDecodeVAEDecode输出图片给SaveImage
如果你想用一句话理解:
加载模型 -> 告诉模型想画什么 -> 告诉模型不要画什么 -> 创建空白潜空间 -> 采样生成 -> 解码成图片 -> 保存
ComfyUI 的学习重点,不是死记节点名字,而是理解这条生成链路。
九、为什么这个“水豚做早餐”的案例特别适合拿来练手?
我很推荐新手从这种案例开始,原因有几个。
1)主题足够具体
“水豚做早餐”比“生成一张好看的图”更明确,模型更容易理解,你也更容易判断结果对不对。
2)有动作,有场景,有风格
这个案例不是单纯生成一个角色,而是同时包含:
- 主体
- 动作
- 场景
- 氛围
- 光影
这对于练习 Prompt 结构特别有帮助。
3)问题很容易定位
如果结果不好,你能快速判断是:
- 主体不对
- 表情不对
- 动作不明显
- 厨房感太弱
- 还是脸崩了
4)后续很容易继续扩展
这套工作流后面完全可以继续叠加:
- LoRA
- Refiner
- 高清修复
- ControlNet
- 局部重绘
所以它不只是一个测试案例,也可以当成你后续的基础模板。
十、想继续优化?这几个方向最值得你试
虽然当前这套工作流已经能稳定出图,但如果你还想继续打磨,建议优先从下面几个方向优化。
1)调整尺寸
当前尺寸是:
832 × 1216
你也可以尝试:
- 横图:
1216 × 832 - 方图:
1024 × 1024
不同构图比例会直接影响画面叙事方式。
2)提高采样步数
当前:
steps = 20
可以尝试提高到:
242830
通常会增加一些细节,但同时也会更耗时。
3)微调 CFG
当前:
cfg = 8
建议测试区间:
6.5 ~ 7:更自然8:比较平衡9以上:更强调 Prompt,但有时会变得僵硬
4)强化动作词
如果你觉得“做早餐”的表现还不够明显,可以在 Prompt 中追加:
frying eggs, preparing breakfast, holding a spatula, standing near the kitchen table
这样动作会更明确。
5)切换风格方向
如果你想从“写实可爱”改为“插画可爱”,可以加入:
storybook style, soft illustration, pastel colors, cute children’s book vibe
这样整体风格会更偏绘本和插画感。
十一、给新手的复现步骤:建议按这个顺序来
如果你准备自己跑一遍,推荐按下面这个顺序操作。
第一步:准备模型
将 sd_xl_base_1.0.safetensors 放到 ComfyUI 模型目录中 [1]。
如果你当前拿到的是 diffusers 格式,先按前面的命令转换 [3]。
第二步:搭建基础节点
至少需要以下节点:
CheckpointLoaderSimpleCLIPTextEncode(正向)CLIPTextEncode(反向)EmptyLatentImageKSamplerVAEDecodeSaveImage[1][2]
第三步:填入参数
建议先不要乱改,直接使用本文参数:
宽度:832
高度:1216
batch_size:10
seed:734568506095117
steps:20
cfg:8
sampler:euler
scheduler:simple
[1][2]
第四步:复制 Prompt
把正向提示词和反向提示词原样填进去 [1][2]。
第五步:运行并筛图
一次出 10 张图后,从中挑出你最满意的结果,再围绕 seed、Prompt 和尺寸继续微调。
十二、这套工作流最大的价值是什么?
很多人学 ComfyUI,总想一步到位玩高级节点。
但实际上,最重要的不是堆功能,而是先搞懂最基础的生成逻辑。
通过这套工作流,你至少可以真正理解 3 件事:
1)Prompt 是如何参与生成的
正向和反向提示词并不是“随便填填”,而是经过 CLIPTextEncode 编码后送入采样器的 [1][2]。
2)KSampler 为什么是核心节点
步数、CFG、采样器类型、调度器,这些参数会直接影响最终画面的质量和风格 [1][2]。
3)latent 和图片不是同一个东西
采样器输出的是 latent,真正变成可见图片,还需要经过 VAEDecode 解码 [1][2]。
只要你把这几件事看懂,后面再学 LoRA、图生图、ControlNet、高级修复,理解速度会快很多。
十三、总结:别再乱抄参数了,先把这套基础流程跑顺
这篇文章其实只做了一件事:
用一个完整、可复现、效果直观的案例,带你跑通 ComfyUI + SDXL 的基础文生图工作流。
本次案例中,你已经拿到了:
- 可直接使用的模型信息 [1]
- 标准的节点结构 [1][2]
- 完整的正向 / 反向提示词 [1][2]
- 可复现的尺寸和采样参数 [1][2]
- diffusers 转 safetensors 的转换命令 [3]
如果你是新手,这套流程足够你把 ComfyUI 的核心逻辑走明白。
如果你已经会用 ComfyUI,这套工作流也很适合作为一个基础模板,继续往上扩展更多玩法。
一句话总结:
不要一上来就乱堆节点、乱调参数,先把最基础的 SDXL 文生图流程跑通,你后面学什么都会更快。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)