AI Agent全景解析:从语言根基到自主智能体的技术演进
维特根斯坦于 1921 年出版《逻辑哲学论》,正式提出“语言即世界”这一命题。语言是一种工具,可以实现对客观世界或主观世界进行理解和表达。要让机器理解世界,就需要语言作为桥梁,让机器具备“感知、思考、决策、执行”的能力。
在 1950 年,图灵就提出“如果一台机器能通过文本对话让人类无法分辨它是人还是机器,那它就具有了智能”。短短数年后,在1956年达特茅斯会议上,约翰·麦卡锡等科学家首次提出“人工智能(Artificial Intelligence 缩写为AI)”的专业术语,明确提出了“让机器模拟人类智能”的研究目标。在这一时期,“自然语言处理”则成为了AI早期发展最重要的相辅相成的模块。
“自然语言处理(NLP)”就是:让计算机能够理解、解释、操纵和生成人类自然语言,通俗点讲就是教计算机“听懂人话、说人话、看懂人写的字、写出人能看懂的内容”。
一、发展历程
AI 起源与发展(1950-1989): 早期以“自然语言处理(NLP)”为基础,机器基于符号逻辑和专家系统,在明确的规则和知识库下运行。例如:机器翻译通过词典、语法规则库、转换规则等来实现语言翻译。随着技术演进,在 1959 年“机器学习”的概念已经正式诞生,亚瑟·塞缪尔定义其为“在不被显式编程的情况下赋予计算机学习能力的研究领域”。1980 年之后,深度学习(特别是卷积神经网络和循环神经网络)的核心雏形和基础算法也在这个阶段被提出来了。由于其智能水平有限,应用场景狭窄,主要集中在工业控制、棋类游戏等封闭环境中。
机器学习:让机器从数据中自己学习规律,而不是仅仅依靠人类为它编写固定的指令 卷积神经网络:专为处理网格结构数据(如图像)设计的深度学习模型,通过卷积层提取局部特征、池化层压缩信息,并最终通过全连接层进行分类或回归等任务,广泛应用于图像识别、目标检测等领域。 循环神经网络:是一种能够处理和建模序列数据的神经网络,通过循环结构使网络能够记忆和利用先前输入的信息,广泛用于自然语言处理、时间序列分析等需要上下文关联的任务。
AI 复兴与突破(1990年代-2016年):随着计算机硬件技术的进步和数字化数据的快速发展,推动了深度学习和强化学习的成熟,AI 也具备从数据中学习的能力。同时,基于监督学习的对话机器人和推荐系统也开始广泛应用。但这一阶段的Agent通常是为特定任务训练的“专家模型”,泛化能力和自主性仍然受限。
AI 蓬勃发展(2017 年至今):Google的研究团队于 2017 年发表了一篇名为《Attention Is All You Need》的论文,正式提出了Transformer架构。进一步推动发展了大语言模型(Large Language Model,简称LLM),LLM强大的通用能力(语言理解、知识推理、代码生成)为构建通用自主Agent提供了可能。通过自然语言指令和上下文学习来理解和执行复杂任务。
Transformer: 是一种 基于注意力机制的神经网络架构,用于处理序列到序列(seq2seq)任务(如机器翻译)。它完全不使用循环(RNN)或卷积(CNN),而是靠 自注意力(Self-Attention) 和 前馈网络 来建模长距离依赖。核心是利用了词在上下文中具有位置、关联性、语义属性。
处理流程:文本输入并将词向量化 > 加上位置编码 > 编码处理(多头自注意力、前馈、残差和归一)> 生成富含上下文信息的向量序列> 解码输出文本
自注意力:“自注意力”是在句子中计算词和其他词的相关性。一个注意力机制可能只捕捉到一种关系(比如“谁做了什么”),但句子中的关系是复杂的。
多头注意力就是并行运行多个不同的自注意力机制 ,每个“头”可以学习到不同类型的关系。例如读书会分成几个小组,一个小组专门讨论“人物关系”,另一个小组讨论“时间顺序”,第三个小组讨论“情感色彩”,最后把各小组的结论汇总起来,就得到了对文本更丰富的理解。
位置编码:因为自注意力机制是‘一视同仁’地看所有词,打乱顺序计算结果也一样,所以必须人为地给它加上‘位置标签’。
前馈网络:对每个词的“理解”进行一次深加工。如果自注意力机制解决了‘关注上下文’(即‘看哪里’)的问题,那么前馈网络解决的就是‘独立思考与特征提取’(即‘怎么理解’)的问题。它像一个独立的处理器,对每个词进行深度的特征加工。
残差连接:允许信息绕过某些层直接传递,防止深层网络中的信息丢失或梯度消失(直接引用原始文本)
层归一化:对数据进行标准化,保持分布稳定,加速训练(主持人总结,防止跑题)
为了更直观地理解Transformer为何能取代前代技术,我们可以对比一下不同网络类型的特性:
|
网络类型 |
形象比喻 |
上下文记忆能力 |
擅长任务 |
主要缺点 |
|---|---|---|---|---|
|
FFN (前馈) |
流水线工人 |
❌ 完全不能 |
图像分类、简单预测 |
忽略顺序和关系 |
|
RNN (循环) |
读书人 |
✅ 短期记忆 |
语音识别、短文本生成 |
长句子会遗忘,训练慢 |
|
CNN (卷积) |
放大镜侦探 |
⚠️ 只看局部 |
图像识别、短语检测 |
难以建模远距离关系 |
二、模型演进
Transformer 最初是为处理文本(一维序列数据)设计的,但它的核心机制——自注意力(Self-Attention),其实是一种通用的数据处理能力。只要把图片、声音、视频都转化成计算机能看懂的“词汇”(Token),原本用来“接龙写文章”的 Transformer,就能用来“接龙画图”或“接龙生成视频”。AI 模型也从单模态发展到多模态,而多模态大模型(如GPT-4o)不仅仅是输入输出的多模态,更是内部表征的统一。
单模态:在输入和输出端分别专注于一种类型的信息处理。例如文生文、文生图、图生文、图生图等
多模态:输入或输出端能同时处理、理解和关联多种不同类型信息。例如视觉问答、生成带图片的问答等
模型就像是一个超级搏学的大脑,但仅有大脑是无法自主的行动。为了让 AI能够感知环境、进行决策,并自主采取行动以实现某种目标,从而发展出智能体(Agent)。虽然‘智能体’的概念早在20世纪就已萌芽,但直到LLM赋予了其强大的通用大脑,现代意义上的AI Agent才真正爆发。
三、AI Agent
1、核心能力
-
感知:通过多模态输入接口,感知和理解外部的复杂信息,包括文本、图像、声音、视频和传感器数据。关键技术包括自然语言处理(NLP)、计算机视觉(CV)、自动语音识别(ASR)、多模态融合
-
大脑:处理感知模块输入的信息,进行推理(逻辑分析、因果判断、意图推断)和规划(将宏大目标拆解为有序、可执行步骤,并能动态调整计划能力)。核心驱动是思维链,先生成推理过程再解决问题。主流决策框架包括
-
ReAct:思考(基于当前状态和目标进行推理并决定下一步采取什么行动)、行动(选择合适工具执行,以获取外部信息或改变环境状态)、观察(Agent接收行动执行后的结果并将其作为下一轮“思考”的输入)。
-
Plan-and-Execute:规划(分析用户目标并分解成详尽有序的步骤列表)、执行(调用工具按照规划逐个执行任务)。
-
Reflection & Self-Critique(反思与自我批判):核心思想是在 Agent 完成一次任务或一个重要步骤后,引入“反思”环节
-
行动:Agent 调用各种工具(API服务、数据库、软件应用等)来执行任务
-
记忆:Agent 拥有短期记忆和长期记忆机制,使其能够存储和检索在任务执行过程中的关键信息、经验和知识
2、多智能体系统
AI Agent 从“工具”向“组织”的演进,核心机制在于智能体之间高效的通信与协作。
2.1、MAS 核心架构模式:
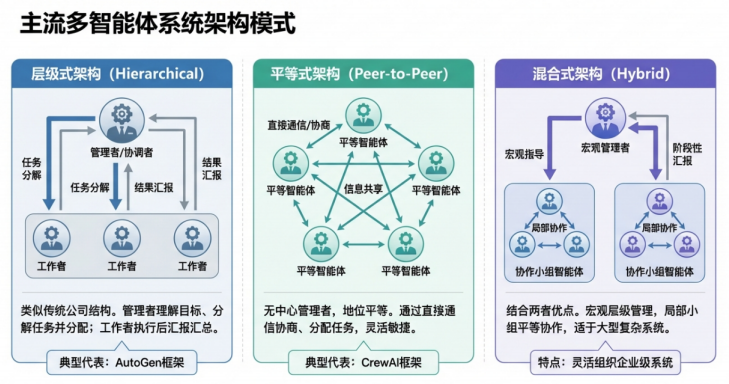
-
层级式架构:类似传统的公司管理结构。系统中存在一个“管理者”或“协调者”,负责理解最终目标、分解任务,并将子任务分配给下属的“工作者”。工作者完成各自任务后,将结果汇报给管理者,由管理者进行汇总和最终决策。
-
平等式架构:Agent 地位都是平等的,通过直接通信进行协商、分配任务和共享信息,共同推进任务的完成
-
混合式架构:结合以上两种模式的优点,在宏观上采用层级式进行任务分解和管理,在局部则采用平等式进行协作。
2.2、通信协议:
-
模型上下文协议(MCP):为 LLM与外部工具、数据和服务之间建立一套标准化的通信“语言”
-
智能体间协议(A2A):定义了 Agent 之间如何发现彼此、协商能力、交换信息和协调任务
2.3、协调机制:定义 Agent 如何分配任务、解决冲突和达成共识
-
黑板系统:所有 Agent共享一个公共的数据区域(黑板),它们可以从中读取任务、写入结果,通过这种间接方式进行通信和协调
-
合同网协议:基于市场机制的招标-投标模式。一个 Agent 可以发布任务“招标”,其他 Agent 根据自身能力进行“投标”,最终由发布者选择最合适的 Agent 来“中标”并执行任务
四、生态图谱
基础底座层:AI 芯片/算力、大语言模型、数据服务
智能体平台层:开发框架与工具链、LLMOps/AgentOps平台、连接器与插件市场
通用/行业智能体层:通用智能体、行业智能体
终端用户层:个人用户、企业用户
1、主流的开源框架
|
维度 |
LangChain |
LangGraph |
AutoGen |
CrewAI |
|---|---|---|---|---|
|
核心定位 |
事实上的行业标准 |
为复杂工作流而生 |
为多智能体协作而生 |
像管理团队一样管理 Agent |
|
核心理念 |
组合 |
状态图 |
可对话的 Actor |
角色和任务 |
|
最强优势 |
生态最完善 |
精确的流程控制 |
强大的对话管理 |
概念清晰,上手简单 |
|
主要劣势 |
学习曲线陡峭 |
更高的抽象层次 |
流程控制不精确 |
灵活性较低 |
|
适用场景 |
构建复杂的、需要深度定制的 AI 应用 |
任何需要精确控制、包含循环或需要多 Agent 协作的复杂任务 |
需要多个 AI 专家通过对话协作解决问题的场景 |
非常适合模拟和自动化具有明确分工和流程的业务场景 |
五、商业模式
模型即服务:底层大模型厂商API 调用次数或 Token 消耗量收费
平台即服务:智能体开发平台提供开发工具、运营环境和算力资源,通过订阅费的模式收费
软件即服务:将成熟的通用或行业智能体打包成标准化 SaaS 产品,按照用户数或功能模块收取订阅费
结果即服务:根据 Agent 为客户创造的实际业务价值(如节约的成本、带来的销售额)进行分成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)