TPAMI 2026 | Mask-DiFuser:一种用于统一无监督图像融合的方法
01 论文信息
- 论文题目: Mask-DiFuser: A Masked Diffusion Model for
Unified Unsupervised Image Fusion - 论文作者: Linfeng Tang,Chunyu Li,Jiayi Ma
- 发表单位: 武汉大学电子信息学院
- 发表会议\期刊: TPAMI 2026
- 代码链接: https://github.com/ixilai/UMCFuse
02 论文主要贡献
1.提出一种基于掩码图像建模和扩散模型的统一图像融合自监督范式(Mask-DiFuser),通过掩码图像恢复学习互补信息聚合,缓解了图像融合中真实标签缺失的问题;
2.设计了一种嵌入退化因子的新型双掩码策略,模拟有价值的互补信息,同时有望提升融合模型对干扰的鲁棒性;
3.开发了一种融合局部内容和全局语义上下文的掩码扩散模型,通过自监督从自然图像中学习高质量先验,使生成的融合图像更符合人类视觉感知;
4.大量实验表明,该模型在红外 - 可见光、医学、多曝光和多聚焦图像融合任务中均表现优异,尤其在色彩保留、对比度增强和曝光适配方面效果突出。
03 论文创新点
1.融合掩码图像建模与扩散模型,将无监督图像融合转化为双掩码图像重建;
2.设计嵌入退化因子的双掩码策略,模拟真实互补信息,提升模型鲁棒性与生成能力;
3.构建局部内容 + 全局语义双分支扩散模型,双分支协同引导,让融合结果更贴合人类视觉感知;
4.实现单模型免微调适配多类图像融合任务,泛化性强,且能提升下游视觉任务性能。
04 方法
4.1 问题概述
图像融合的本质是将多幅源图像中的互补关键信息整合为单幅融合图像。但由于不存在真实的融合图像(即真实标签),难以明确定义有意义的互补信息。
为解决该问题,本文提出一种特殊的双掩码策略,模拟有效的互补上下文,将无监督图像融合转化为自监督掩码图像恢复任务(如图 2 所示);同时引入具备强大生成能力和泛化能力的扩散模型,使该方法能适用于各类图像融合任务。最终,通过自监督学习预训练的掩码扩散模型,可作为多融合任务的统一通用生成器,无需微调。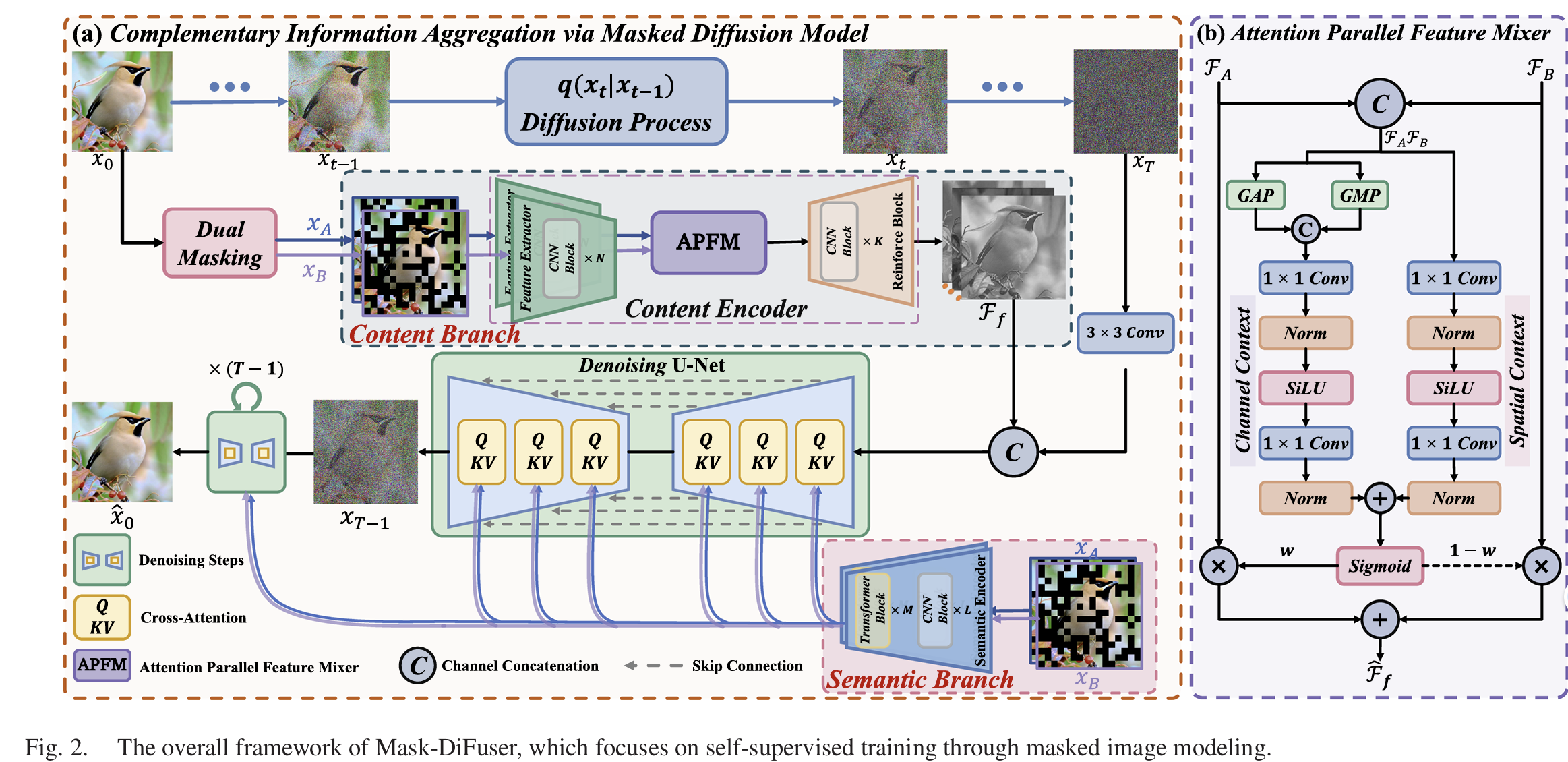
4.2 基于掩码扩散模型的图像融合
4.2.1 双掩码策略
给定一幅高质量源图像x0∈RH×W×3x_{0} \in \mathbb{R}^{H ×W ×3}x0∈RH×W×3,传统掩码策略通常通过施加从均匀分布中采样的固定掩码比例(如50%)的随机二值掩码MMM,构建两个互补的掩码图像(xAx_{A}xA和xBx_{B}xB)(如图 3 (b) 所示),其数学表达式为:
xA=M(x0)+M‾(xp);xB=M‾(x0)+M(xp)(1)x_{A}=\mathcal{M}\left(x_{0}\right)+\overline{\mathcal{M}}\left(x_{p}\right) ; x_{B}=\overline{\mathcal{M}}\left(x_{0}\right)+\mathcal{M}\left(x_{p}\right) \tag{1}xA=M(x0)+M(xp);xB=M(x0)+M(xp)(1)
其中,Mˉ\bar{M}Mˉ为掩码MMM的逻辑非,xp∈RH×W×3x_{p} \in \mathbb{R}^{H ×W ×3}xp∈RH×W×3为像素值随机分配的纯随机图像。这种简单的互补信息模拟方式,易导致后续融合模型出现模式崩溃,阻碍信息的有效整合,且忽略了实际成像过程中常见的光照退化、噪声、模糊等退化现象。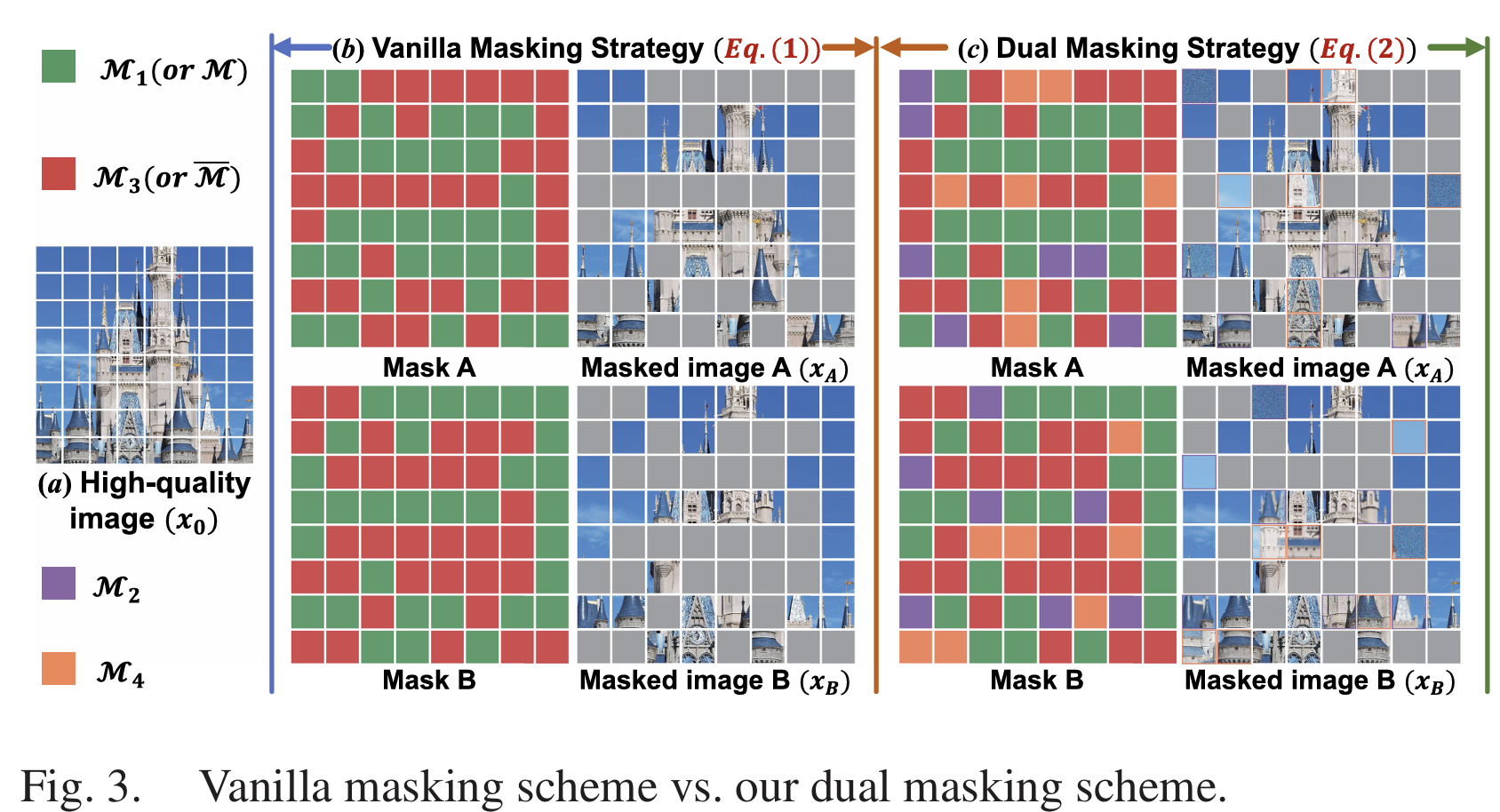
为解决上述局限性,本文提出一种新型双掩码策略(如图 3©所示),定义为:
xA=M1A(x0)+M2A(D(x0))+M3A(xp)+M4A(D(x0))x_{A}=\mathcal{M}_{1}^{A}\left(x_{0}\right)+\mathcal{M}_{2}^{A}\left(\mathcal{D}\left(x_{0}\right)\right)+\mathcal{M}_{3}^{A}\left(x_{p}\right)+\mathcal{M}_{4}^{A}\left(\mathcal{D}\left(x_{0}\right)\right)xA=M1A(x0)+M2A(D(x0))+M3A(xp)+M4A(D(x0))
xB=M1B(x0)+M2B(D(x0))+M3B(xp)+M4B(D(x0))x_{B}=\mathcal{M}_{1}^{B}\left(x_{0}\right)+\mathcal{M}_{2}^{B}\left(\mathcal{D}\left(x_{0}\right)\right)+\mathcal{M}_{3}^{B}\left(x_{p}\right)+\mathcal{M}_{4}^{B}\left(\mathcal{D}\left(x_{0}\right)\right)xB=M1B(x0)+M2B(D(x0))+M3B(xp)+M4B(D(x0))
s.t.{M1A∪M2A=M;M3A∪M4A=M‾M1B∪M2B=M‾;M3B∪M4B=M(2)s.t. \quad\left\{\begin{array}{l} \mathcal{M}_{1}^{A} \cup \mathcal{M}_{2}^{A}=\mathcal{M} ; \mathcal{M}_{3}^{A} \cup \mathcal{M}_{4}^{A}=\overline{\mathcal{M}} \\ \mathcal{M}_{1}^{B} \cup \mathcal{M}_{2}^{B}=\overline{\mathcal{M}} ; \mathcal{M}_{3}^{B} \cup \mathcal{M}_{4}^{B}=\mathcal{M} \end{array}\right. \tag{2}s.t.{M1A∪M2A=M;M3A∪M4A=MM1B∪M2B=M;M3B∪M4B=M(2)
其中,D(⋅)\mathcal{D}(\cdot)D(⋅)为随机退化操作集合,包括高斯模糊、高斯噪声、伽马校正和幅相变换。该设计具有双重作用:一方面,M2\mathcal{M}_{2}M2将非掩码区域的部分像素替换为退化图像块,迫使模型从退化输入中重建高质量内容,提升模型的生成能力;另一方面,M4\mathcal{M}_{4}M4将退化图像块引入掩码区域,促使模型选择性地提取和保留有价值的内容,提升模型的判别能力。最终,通过生成融合了真实退化的互补图像,该双掩码策略能有效模拟真实世界图像融合任务中的各类场景,显著提升通过自监督在合成数据上训练的融合模型的鲁棒性和泛化性。
4.2.2 掩码扩散模型
如图 2 (a) 所示,掩码扩散模型基于条件扩散模型构建,融合了双掩码策略,包含前向扩散过程和反向去噪过程。其核心是在通过马尔可夫链逼近高质量图像分布的同时,学习融合多源图像的互补信息。
前向扩散过程
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(3)q\left(x_{t} | x_{t-1}\right)=\mathcal{N}\left(x_{t} ; \sqrt{1-\beta_{t}} x_{t-1}, \beta_{t} I\right) \tag{3}q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(3)
其中,t∈[1,2,...,T]t \in[1,2, ..., T]t∈[1,2,...,T]为时间步,βt\beta_{t}βt为噪声的方差调度。利用高斯分布的性质和重参数化迭代推导,可将前向马尔可夫过程重新表示为:
q(xt∣x0)=N(xt;α‾tx0,(1−α‾t)I)(4)q\left(x_{t} | x_{0}\right)=\mathcal{N}\left(x_{t} ; \sqrt{\overline{\alpha}_{t}} x_{0},\left(1-\overline{\alpha}_{t}\right) I\right) \tag{4}q(xt∣x0)=N(xt;αtx0,(1−αt)I)(4)
其中,αˉt=∏i=1tαi\bar{\alpha}_{t}=\prod_{i=1}^{t} \alpha_{i}αˉt=∏i=1tαi,αt=1−βt\alpha_{t}=1-\beta_{t}αt=1−βt。因此,ttt步的样本xtx_{t}xt可直接由x0x_{0}x0推导得到:
xt=α‾tx0+1−α‾tϵt(5)x_{t}=\sqrt{\overline{\alpha}_{t}} x_{0}+\sqrt{1-\overline{\alpha}_{t}} \epsilon_{t} \tag{5}xt=αtx0+1−αtϵt(5)
其中,ϵt∼N(0,I)\epsilon_{t} \sim \mathcal{N}(0, I)ϵt∼N(0,I)。当扩散时间步TTT足够大时,αˉT\bar{\alpha}_{T}αˉT将渐近趋近于0,因此前向扩散过程结束时,xTx_{T}xT的分布逼近标准高斯分布N(0,I)\mathcal{N}(0, I)N(0,I)。
反向去噪过程
从纯高斯分布出发,以两个互补掩码图像xAx_{A}xA和xBx_{B}xB为条件,逐步去除噪声以恢复原始数据分布,该过程同样遵循马尔可夫链:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,xA,xB,t),σt2I)(6)p_{\theta}\left(x_{t-1} | x_{t}\right)=\mathcal{N}\left(x_{t-1} ; \mu_{\theta}\left(x_{t}, x_{A}, x_{B}, t\right), \sigma_{t}^{2} I\right) \tag{6}pθ(xt−1∣xt)=N(xt−1;μθ(xt,xA,xB,t),σt2I)(6)
借鉴现有研究,本文采用去噪网络ϵθ\epsilon_{\theta}ϵθ预测ttt步的噪声,以逼近均值μ\muμ,σt2\sigma_{t}^{2}σt2为与时间相关的常数。具体而言,分布参数可表示为:
μθ=1αt(xt−βt1−α‾tϵθ(xt,xA,xB,t))\mu _{\theta }=\frac {1}{\sqrt {\alpha _{t}}}\left( x_{t}-\frac {\beta _{t}}{\sqrt {1-\overline {\alpha }_{t}}}\epsilon _{\theta }(x_{t},x_{A},x_{B},t)\right)μθ=αt1(xt−1−αtβtϵθ(xt,xA,xB,t))
σt2=1−α‾t−11−α‾tβt(7)\sigma_{t}^{2}=\frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_{t}} \beta_{t} \tag{7}σt2=1−αt1−αt−1βt(7)
其中,ϵθ(xt,xA,xB,t)\epsilon_{\theta}(x_{t}, x_{A}, x_{B}, t)ϵθ(xt,xA,xB,t)为去噪网络ϵθ\epsilon_{\theta}ϵθ以xtx_{t}xt、xAx_{A}xA、xBx_{B}xB和ttt为条件预测的噪声。最终,利用重参数化技巧,可对xt−1x_{t-1}xt−1进行采样:
xt−1=1αt(xt−βt1−α‾tϵθ(xt,xA,xB,t))+σtz(8)x_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}} \epsilon_{\theta}\left(x_{t}, x_{A}, x_{B}, t\right)\right)+\sigma_{t} z \tag{8}xt−1=αt1(xt−1−αtβtϵθ(xt,xA,xB,t))+σtz(8)
其中,z∼N(0,I)z \sim \mathcal{N}(0, I)z∼N(0,I)为标准高斯噪声。
如图 2 (a) 所示,去噪网络ϵθ\epsilon_{\theta}ϵθ包含三个核心组件:内容编码器EcE_{c}Ec、语义编码器EsE_{s}Es和去噪U-NetNdN_{d}Nd,前两者用于捕捉局部和全局的条件上下文。
内容分支
引入内容编码器将互补图像转换为融合特征,提供完整的场景表征作为条件。内容分支由特征提取器、注意力并行特征混合器(APFM)和增强模块组成,以xAx_{A}xA和xBx_{B}xB为输入,生成局部内容条件Ff∈RH×W×64F_{f} \in \mathbb{R}^{H ×W ×64}Ff∈RH×W×64,表达式为:
Ff=Ec(xA,xB)(9)\mathcal{F}_{f}=\mathcal{E}_{c}\left(x_{A}, x_{B}\right) \tag{9}Ff=Ec(xA,xB)(9)
首先,特征提取器对xAx_{A}xA和xBx_{B}xB进行处理,得到特征图FA∈RH×W×64F_{A} \in \mathbb{R}^{H ×W ×64}FA∈RH×W×64和FB∈RH×W×64F_{B} \in \mathbb{R}^{H ×W ×64}FB∈RH×W×64;随后将其输入注意力并行特征混合器,通过融合通道和空间上下文评估特征重要性、生成融合权重,实现内容的粗融合(注意力并行特征混合器的详细工作流程如图 2 (b) 所示);融合后的内容特征经增强模块处理,降低通道维度并生成FfF_{f}Ff;最后,将FfF_{f}Ff与xtx_{t}xt的特征投影在通道维度上拼接,为去噪U-Net提供局部内容先验。
语义分支
融合卷积神经网络和Transformer,用于提供全局语义先验。具体而言,首先将xAx_{A}xA和xBx_{B}xB输入共享的语义编码器,得到语义表征SA∈RH/4×W/4×128S_{A} \in \mathbb{R}^{H / 4 ×W / 4 ×128}SA∈RH/4×W/4×128和SB∈RH/4×W/4×128S_{B} \in \mathbb{R}^{H / 4 ×W / 4 ×128}SB∈RH/4×W/4×128,表达式为:
SA=Es(xA),SB=Es(xB)(10)\mathcal{S}_{A}=\mathcal{E}_{s}\left(x_{A}\right), \mathcal{S}_{B}=\mathcal{E}_{s}\left(x_{B}\right) \tag{10}SA=Es(xA),SB=Es(xB)(10)
随后,通过交叉注意力机制将SAS_{A}SA和SBS_{B}SB融入去噪U-Net,为图像生成提供全局语义引导。交叉注意力机制的表达式为:
Attention(φi(xt),S)=softmax(QKTd)⋅V(11)Attention \left(\varphi_{i}\left(x_{t}\right), \mathcal{S}\right)=softmax\left(\frac{Q K^{T}}{\sqrt{d}}\right) \cdot V \tag{11}Attention(φi(xt),S)=softmax(dQKT)⋅V(11)
其中,Q=WQ(i)⋅φi(xt)Q=W_{Q}^{(i)} \cdot \varphi_{i}(x_{t})Q=WQ(i)⋅φi(xt),K=WK(i)⋅SK=W_{K}^{(i)} \cdot SK=WK(i)⋅S,V=WV(i)⋅SV=W_{V}^{(i)} \cdot SV=WV(i)⋅S;φi(xt)\varphi_{i}(x_{t})φi(xt)为去噪U-Net中第iii层的中间表征;WQ(i)W_{Q}^{(i)}WQ(i)、WK(i)W_{K}^{(i)}WK(i)、WV(i)W_{V}^{(i)}WV(i)为可学习的权重矩阵;ddd为缩放因子。为实现多源信息交互,将Attention(φi(xt),SA)Attention \left(\varphi_{i}\left(x_{t}\right), S_{A}\right)Attention(φi(xt),SA)和Attention(φi(xt),SB)Attention \left(\varphi_{i}\left(x_{t}\right), S_{B}\right)Attention(φi(xt),SB)在通道维度上拼接。
最终,融合局部内容和全局语义信息后,噪声估计过程ϵθ(xt,xA,xB,t)\epsilon_{\theta}(x_{t}, x_{A}, x_{B}, t)ϵθ(xt,xA,xB,t)可通过Nd(xt,Ff,SA,SB,t)N_{d}(x_{t}, F_{f}, S_{A}, S_{B}, t)Nd(xt,Ff,SA,SB,t)实现。
4.2.3 损失函数
借鉴现有研究,本文采用扩散损失Ldiff\mathcal{L}_{diff }Ldiff训练掩码扩散模型,定义为:
Ldiff=∥ϵt−ϵθ(α‾tx0+1−α‾tϵt,xA,xB,t)∥2(12)\mathcal{L}_{diff }=\left\| \epsilon_{t}-\epsilon_{\theta}\left(\sqrt{\overline{\alpha}_{t}} x_{0}+\sqrt{1-\overline{\alpha}_{t}} \epsilon_{t}, x_{A}, x_{B}, t\right)\right\| _{2} \tag{12}Ldiff=
ϵt−ϵθ(αtx0+1−αtϵt,xA,xB,t)
2(12)
其中,∥⋅∥2\|\cdot\|_{2}∥⋅∥2为l2l_2l2范数。尽管掩码扩散模型可通过自监督学习优化Ldiff\mathcal{L}_{diff }Ldiff,逼近分布p(x0∣xA,xB)p(x_{0} | x_{A}, x_{B})p(x0∣xA,xB),但实际实验中发现,模型生成的图像常存在明显的色彩失真。受相关研究启发,本文进一步引入图像级一致性损失,包括像素损失Lpix\mathcal{L}_{pix }Lpix、结构相似性(SSIM)损失Lssim\mathcal{L}_{ssim }Lssim、感知损失Lper\mathcal{L}_{per }Lper和色彩一致性损失Lcol\mathcal{L}_{col }Lcol。
根据公式(5),可基于去噪网络ϵθ\epsilon_{\theta}ϵθ预测的噪声近似估计x^0t\hat{x}_{0}^{t}x^0t,表达式为:
x^0t=1α‾t(xt−1−α‾tϵθ(xt,xA,xB,t))(13)\hat{x}_{0}^{t}=\frac{1}{\sqrt{\overline{\alpha}_{t}}}\left(x_{t}-\sqrt{1-\overline{\alpha}_{t}} \epsilon_{\theta}\left(x_{t}, x_{A}, x_{B}, t\right)\right) \tag{13}x^0t=αt1(xt−1−αtϵθ(xt,xA,xB,t))(13)
像素损失
定义为估计值x^0t\hat{x}_{0}^{t}x^0t与真实标签x0x_{0}x0之间的亮度差异:
Lpix=∥x^0t−x0∥2(14)\mathcal{L}_{pix }=\left\| \hat{x}_{0}^{t}-x_{0}\right\| _{2} \tag{14}Lpix=
x^0t−x0
2(14)
结构相似性损失
用于保持图像的结构相似性,定义为:
Lssim=(2μx^0tμx0+c1)(2σx^0tx0+c2)(μx^0t2+μx02+c1)(σx^0t2+σx02+c2)(15)\mathcal{L}_{ssim }=\frac{\left(2 \mu_{\hat{x}_{0}^{t}} \mu_{x_{0}}+c_{1}\right)\left(2 \sigma_{\hat{x}_{0}^{t} x_{0}}+c_{2}\right)}{\left(\mu_{\hat{x}_{0}^{t}}^{2}+\mu_{x_{0}}^{2}+c_{1}\right)\left(\sigma_{\hat{x}_{0}^{t}}^{2}+\sigma_{x_{0}}^{2}+c_{2}\right)} \tag{15}Lssim=(μx^0t2+μx02+c1)(σx^0t2+σx02+c2)(2μx^0tμx0+c1)(2σx^0tx0+c2)(15)
其中,μx^0t\mu_{\hat{x}_{0}^{t}}μx^0t和μx0\mu_{x_{0}}μx0为像素均值,σx^0t2\sigma_{\hat{x}_{0}^{t}}^{2}σx^0t2和σx02\sigma_{x_{0}}^{2}σx02为方差,σx^0tx0\sigma_{\hat{x}_{0}^{t} x_{0}}σx^0tx0为协方差,c1c_{1}c1、c2c_{2}c2为保证数值稳定性的常数。
感知损失
利用VGG网络提取x^0t\hat{x}_{0}^{t}x^0t和x0x_{0}x0的深层特征,通过特征差异施加约束,表达式为:
Lper=∑l∥ϕvggl(x^0t)−ϕvggl(x0)∥2(16)\mathcal{L}_{per }=\sum_{l}\left\| \phi_{v g g}^{l}\left(\hat{x}_{0}^{t}\right)-\phi_{v g g}^{l}\left(x_{0}\right)\right\| _{2} \tag{16}Lper=l∑
ϕvggl(x^0t)−ϕvggl(x0)
2(16)
其中,ϕvggl\phi_{v g g}^{l}ϕvggl表示VGG网络的第lll个卷积层。
色彩一致性损失
通过显式最小化x^0t\hat{x}_{0}^{t}x^0t和x0x_{0}x0色彩向量之间的夹角,防止色彩失真,定义为:
Lcol=1N∑i=1N∠(x^0t(i),x0(i))(17)\mathcal{L}_{col }=\frac{1}{N} \sum_{i=1}^{N} \angle\left(\hat{x}_{0}^{t}(i), x_{0}(i)\right) \tag{17}Lcol=N1i=1∑N∠(x^0t(i),x0(i))(17)
其中,x(i)x(i)x(i)为图像xxx的第iii个像素,∠(⋅,⋅)\angle(\cdot, \cdot)∠(⋅,⋅)用于计算RGB色彩空间中两个色彩向量的夹角。
最终,掩码扩散模型的总训练损失为上述各损失的加权和:
L=Ldiff+λ1Lpix+λ2Lssim+λ3Lper+λ4Lcol(18)\mathcal{L}=\mathcal{L}_{diff }+\lambda_{1} \mathcal{L}_{pix }+\lambda_{2} \mathcal{L}_{ssim }+\lambda_{3} \mathcal{L}_{per }+\lambda_{4} \mathcal{L}_{col } \tag{18}L=Ldiff+λ1Lpix+λ2Lssim+λ3Lper+λ4Lcol(18)
其中,λ1\lambda_{1}λ1、λ2\lambda_{2}λ2、λ3\lambda_{3}λ3、λ4\lambda_{4}λ4为控制各损失权重的超参数。
05 实验分析
5.1 红外与可见光融合



定性分析表明,Mask-DiFuser 生成的融合结果中行人目标最突出、整体对比度最高、曝光水平最优。具体而言,如图 4 所示,在 MSRS 数据集的夜间场景中,LRRNet、DDFM、U2Fusion 等方法无法有效保留行人的显著性,而 Mask-DiFuser 不仅增强了红外信息,还提升了草坪、道路、建筑等低光照区域的细节,使整个场景更明亮、更易识别;在白天场景中(图 5),Mask-DiFuser 的融合结果同样表现优异,人物目标的显著性和门的纹理细节尤为突出;在 RoadScene 数据集中(图 6),可见光图像的过曝光问题对 U2Fusion、DeFusion 等方法构成挑战,而 Mask-DiFuser 成功修正了源图像的过曝光伪影。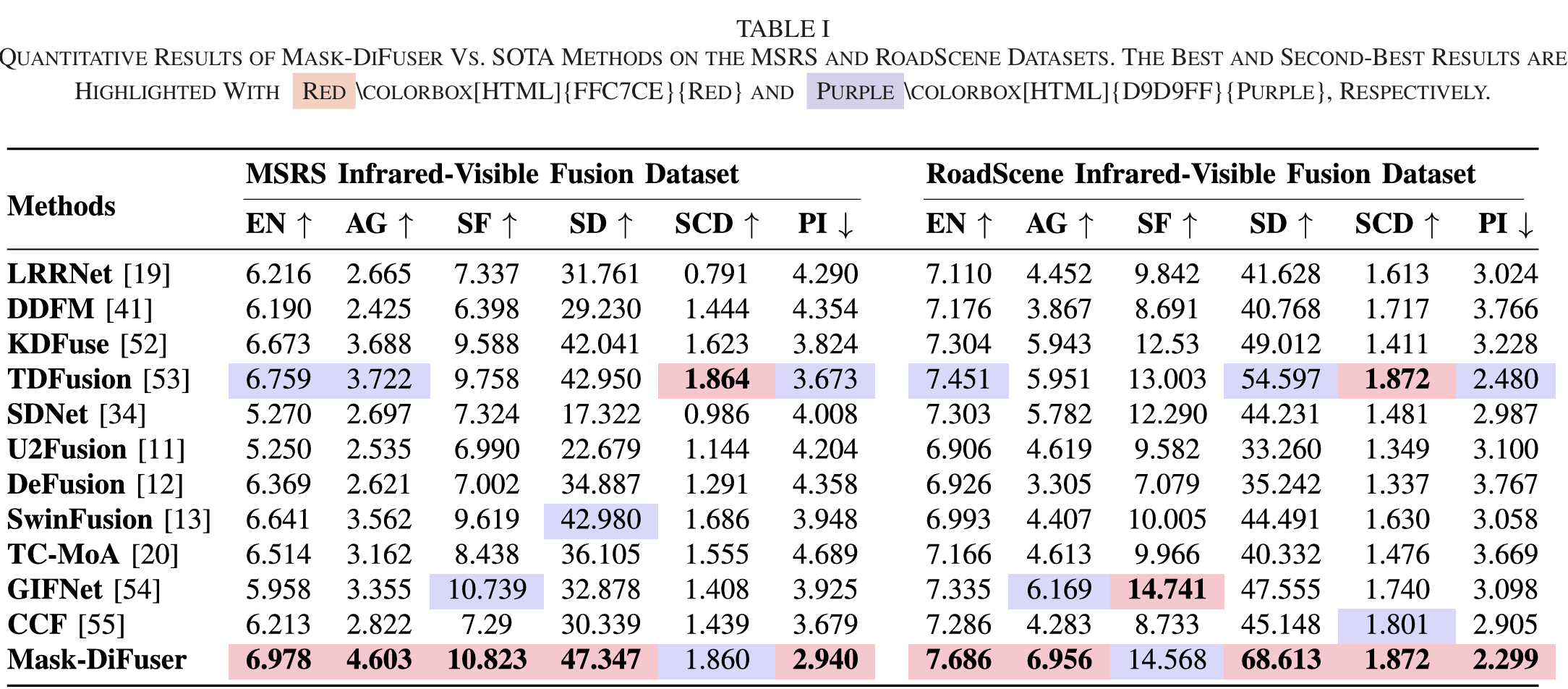
表 1 为 Mask-DiFuser 与其他算法的定量结果,可见该方法在所有评价指标上均保持最优性能:较高的 EN 和 AG 值,以及具有竞争力的 SF 值,表明融合图像有效保留了最丰富的纹理细节;最高的 SD 值证明融合图像的对比度最优;最佳的 PI 值体现了其优异的视觉质量。整体实验结果证实,Mask-DiFuser 能够学习到合适曝光、高清晰度、高对比度等高质量先验信息,进一步强化了其在处理复杂融合任务中的优势。
5.2 消融实验
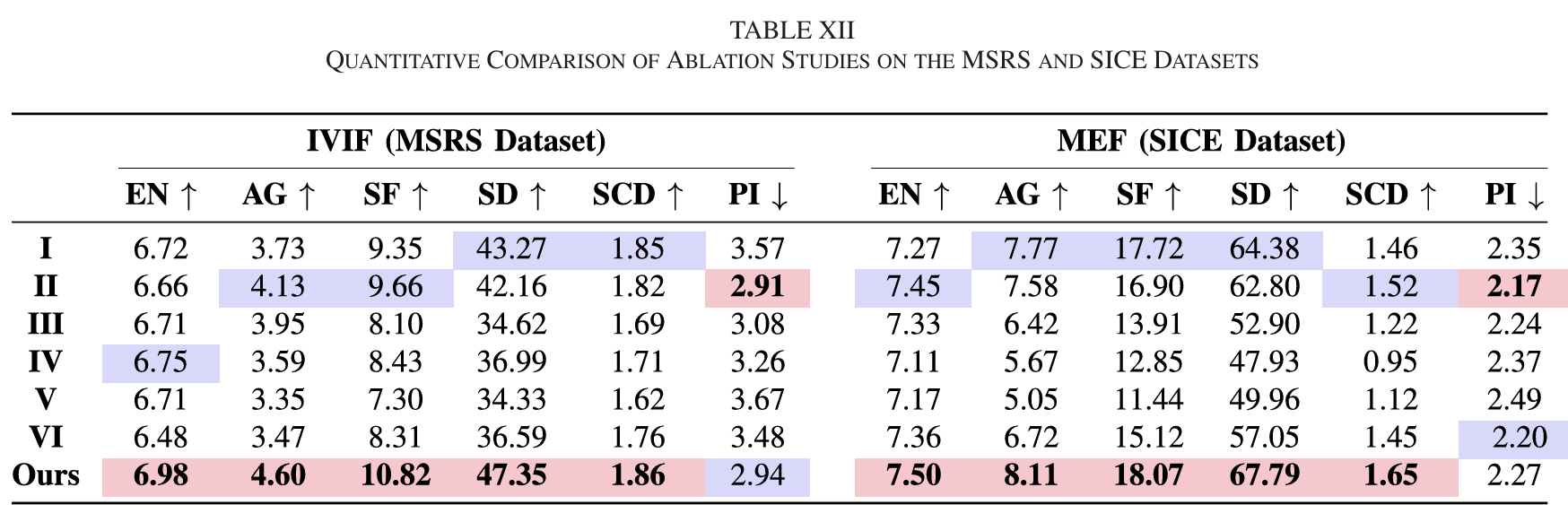
为验证 Mask-DiFuser 各特定设计的有效性,本文在红外 - 可见光图像融合(MSRS 数据集)和多曝光图像融合(SICE 数据集)任务上开展消融实验,设计六种模型配置:
I. 无内容分支:移除内容编码器;
II. 无语义分支:移除语义编码器;
III. 无注意力并行特征混合器:将注意力并行特征混合器替换为简单的平均加权融合策略进行粗融合;
IV. 卷积神经网络骨干:用卷积神经网络替代扩散模型作为骨干网络;
V. 仅扩散损失:仅使用扩散损失LdiffL_{diff}Ldiff训练模型,移除其他图像级一致性损失;
VI. 无退化因子:采用公式 (1) 的掩码策略,不引入退化操作。
如图 18 所示,移除任何核心组件都会导致模型性能明显退化:省略内容分支会使融合结果出现显著的块效应(蓝框标注);以卷积神经网络为骨干时,模型无法从自然图像中捕捉高质量先验,导致融合图像的视觉效果不够生动;仅使用扩散损失训练网络,会使融合结果出现明显的色彩失真;掩码策略中不引入退化因子,会限制掩码扩散模型的生成能力。表 12 的定量结果进一步证实了这些核心设计的重要性。
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)