Google放大招,Gemma 4来了:2026年开源大模型还能不能打过闭源?
工程师真正关心的,从来不只是“谁家榜单第一”,而是**能不能部署、能不能调优、能不能接进现有系统、总拥有成本是否可控**。Google 在 2026-04-02 发布 Gemma 4,并明确把它定位为“最强开源模型”系列,且采用 Apache 2.0 许可,这件事的意义不在于又多了一个模型名字,而在于:**开源大模型在 2026 年是否重新拿回了工程主导权**。
> 大家想学习更多AI知识,可以收藏下面两个网站:
对一线研发团队来说,这直接影响三类决策:
1. 是继续全量依赖闭源 API,还是开始建设可控的本地/私有化推理能力;
2. 多模态、长上下文、函数调用、Agent 工作流这些能力,是否终于可以在开源栈里“开箱即用”;
3. 在手机端、边缘端、消费级 GPU、工作站、服务器之间,模型选型是否能形成一条完整链路。
---
## 摘要
> 摘要:Gemma 4 不是简单的参数升级,而是 Google 试图把“开源模型可用性”拉到接近前沿闭源产品的一次系统性推进。
根据 Google 官方博客与模型卡,Gemma 4 提供四个核心规格:**E2B、E4B、26B A4B MoE、31B Dense**,覆盖手机端到服务器侧部署场景,支持**文本与图像输入**,小模型还原生支持**音频输入**,输出为文本。[1][2][3] 其上下文窗口最高达到 **256K token**,支持 **140+ 语言**,并原生提供 **system role、函数调用、长上下文、混合注意力** 等工程特性。[2]
更重要的是,Google 没把 Gemma 4 只定义成聊天模型,而是明确对标**复杂推理、编码和 agentic workflows**。[1][2] 从 DeepMind 公布的基准看,31B/26B 相比 Gemma 3 27B 在 AIME 2026、LiveCodeBench v6、GPQA Diamond、τ2-bench 等任务上有明显提升。[3] 同时,31B 与 26B 在 2026-04-02 对应的 Arena AI 开源模型榜单中分数分别为 **1452** 和 **1441**,Google 官方称 31B 位列开源第 3、26B 位列开源第 6。[1][3]
但标题里的问题是:**开源还能不能打过闭源?**
答案应该更严谨一些:**Gemma 4 让开源阵营重新具备“在大量真实工程场景中与闭源正面竞争”的资格,但并不等于在所有前沿任务上全面超越闭源。** Arena 在 2026 年春季的整体格局仍显示闭源强者处于高位。[7] 所以,对工程团队来说,真正的结论不是“开源赢了”,而是:
- **在成本、可控性、私有化、边缘部署、多模态本地推理场景中,Gemma 4 非常能打;**
- **在追求全局最优通用能力时,闭源模型仍有领先优势;**
- **未来系统架构更可能是“开源本地 + 闭源云端”的混合路线。**
---
## Gemma 4 到底发布了什么?
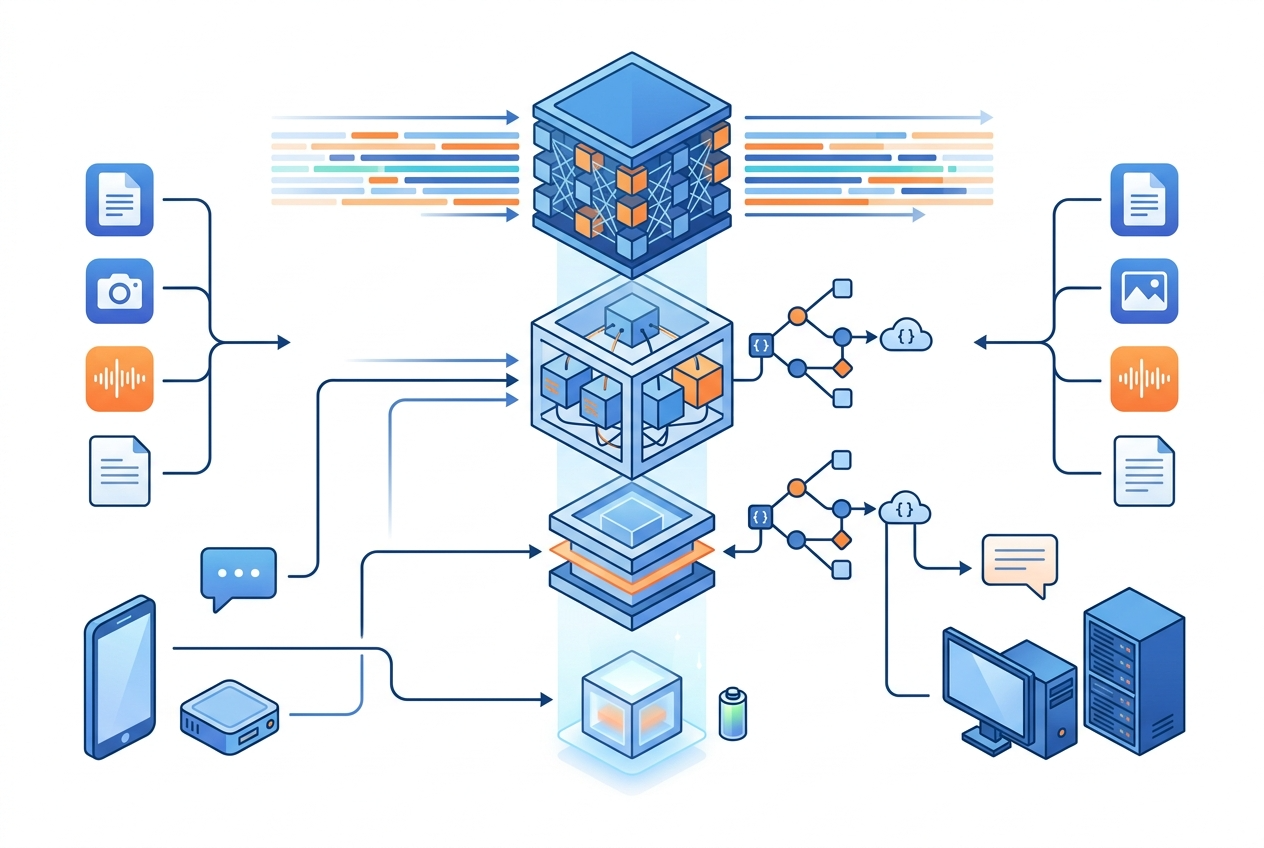
> 摘要:先把产品形态看清楚,才能讨论它的工程价值。
Gemma 4 的核心不是一个单点模型,而是一个**分层可部署的开源模型家族**。[1][2][3]
### 1)四档规格,覆盖不同部署层级
官方公开了四种规格:[1][2]
- **E2B**
- **E4B**
- **26B A4B MoE**
- **31B Dense**
其中,E2B/E4B 面向**移动设备与 IoT**,强调可离线运行,并支持视觉/音频输入;26B/31B 则面向**消费级 GPU、IDE、代码助手、Agent 工作流和工作站/服务器**。[3]
### 2)不是纯文本模型,而是多模态模型
Gemma 4 官方模型卡明确说明其为**多模态开源权重模型**,支持:
- 文本输入
- 图像输入
- 小模型原生支持音频输入
- 输出为文本
这意味着它不是“把文本聊天做到更强”这么简单,而是具备构建**视觉理解、语音入口、文档问答、多模态 Agent**的基础能力。[2]
### 3)长上下文与函数调用直接面向工程
Gemma 4 的上下文长度最高到 **256K token**,小模型为 **128K**。[2] 这对下面这些场景非常关键:
- 大型代码库分析
- 多轮任务规划
- 长文档 RAG
- 多工具调用的 Agent 状态保持
同时,模型卡强调其支持 **system role** 与 **函数调用**。[2] 这说明 Gemma 4 在协议层面已经考虑了生产系统集成,而不是只适合跑 benchmark。
---
## 为什么说 Gemma 4 是 Google 一次“工程化”放大招?
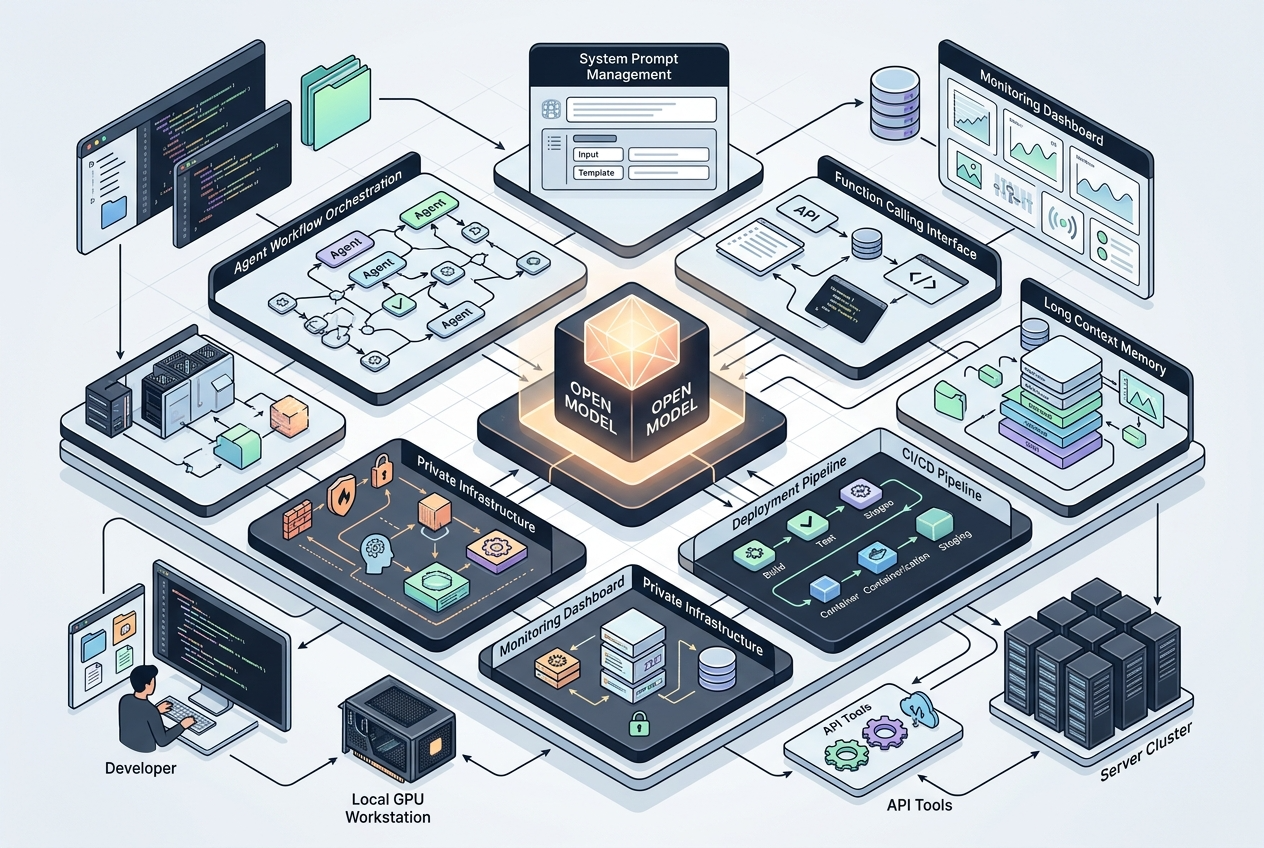
> 摘要:参数不是重点,重点是它在模型、协议、工具链、生态上同时补齐了短板。
过去很多开源模型的问题不是“不够聪明”,而是**很难落地**。Gemma 4 这次的信号很明确:Google 想做的不是一个只会刷榜的开源模型,而是一套**能进入主流开发工作流**的开源基础设施。
### 1)架构路线更实用:Dense + MoE 并存
Gemma 4 同时提供 **Dense** 与 **MoE** 版本。[2]
这背后的工程含义是:
- **Dense** 更适合稳定推理、部署简单、兼容性要求高的场景;
- **MoE** 更适合追求更高 intelligence-per-parameter 的性价比路线。
Google 官方反复强调 Gemma 4 的高 **intelligence-per-parameter**。[1] 这其实是在回应一个现实:开源阵营不一定拼得过闭源的超大训练规模,但可以通过**更高单位参数效率**争取部署优势。
### 2)工具链接入速度非常快
Gemma 4 在 2026-04-01 就进入了 **Hugging Face Transformers** 官方文档体系。[5] 这件事的意义很大,因为对开发者来说,“能不能马上用”比“论文上多强”更重要。
Transformers 文档还指出了 Gemma 4 的一些关键实现点,例如:
- 视觉处理器
- 固定 token budget 的图像编码
- **2D RoPE**
这意味着主流推理、微调、评测链路不需要从零开始适配。[5]
### 3)社区分发速度快,生态接受度高
Hugging Face 在 2026-04-08 发布欢迎 Gemma 4 的文章,多个官方仓库如 `gemma-4-31B-it`、`26B-A4B-it`、`E4B-it`、`E2B-it` 热度很高。[4]
这说明 Gemma 4 发布后迅速进入:
- 社区下载分发
- 推理框架支持
- 微调实验
- 第三方部署工具链
开源模型能不能打,除了能力,还要看**传播效率和生态摩擦成本**。这一点 Gemma 4 做得比很多“只在官宣当天热一下”的模型更扎实。
---
## 开源能不能打过闭源?先看事实,不喊口号
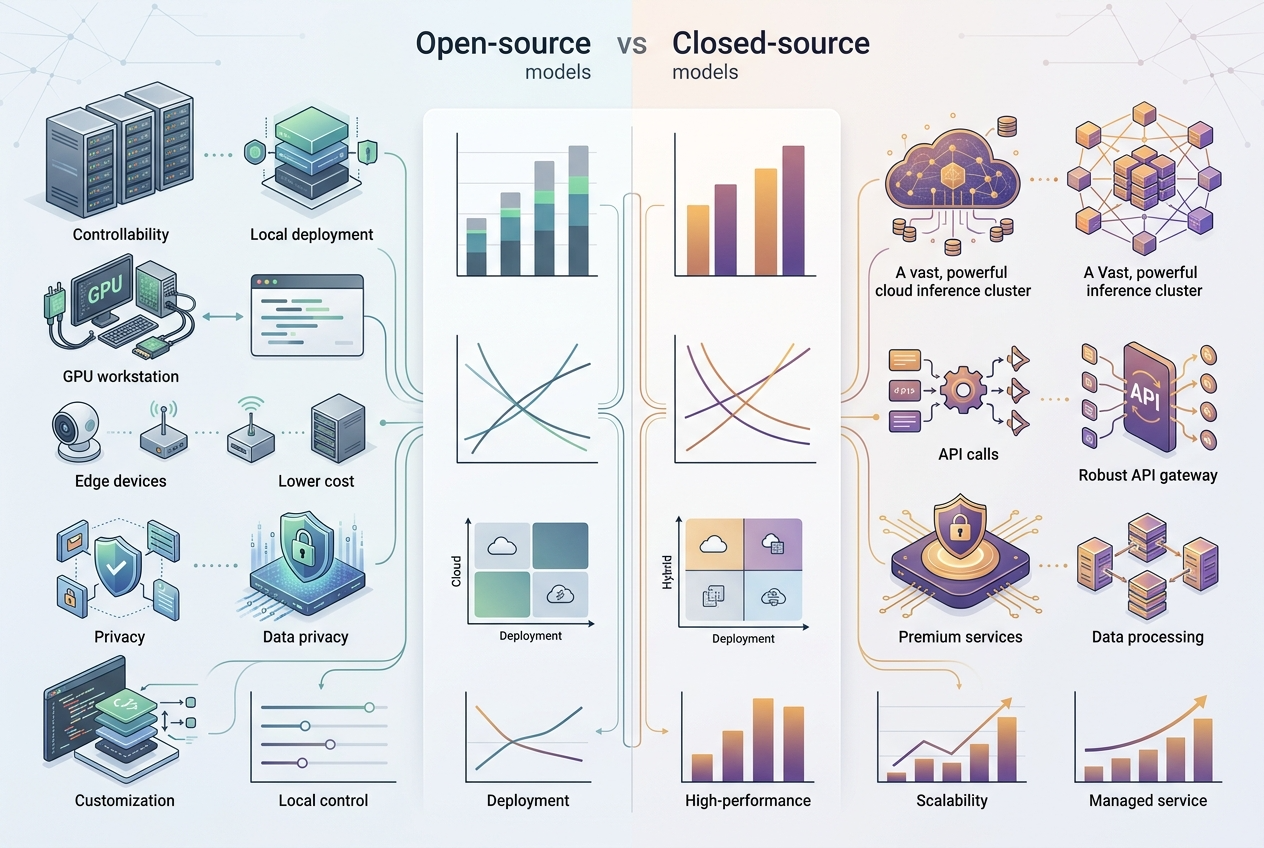
> 摘要:Gemma 4 让开源非常接近闭源,但“全面反超”这个结论目前还站不住。
这个问题不能只看单个 benchmark,也不能只看一个榜单截图。
### 1)Gemma 4 的确把开源能力往前推了一大截
根据 DeepMind 产品页,Gemma 4 31B/26B 在以下任务上显著强于 Gemma 3 27B:[3]
- AIME 2026
- LiveCodeBench v6
- GPQA Diamond
- τ2-bench
这意味着它在以下能力上都更接近“前沿可用”:
- 复杂推理
- 代码生成与理解
- 高难知识问答
- 工具/任务链式执行
### 2)Arena 开源排名很强,但不是整体第一
截至 2026-04-02,Gemma 4 的 Arena AI 文本分数为:[3]
- **31B:1452**
- **26B:1441**
Google 官方博客称,31B 在 2026-04-01 的 Arena AI 开源榜单中位列第 3,26B 位列第 6。[1]
这足以说明:**Gemma 4 已经站到了开源第一梯队。**
但同样要看到,Arena 2026 年 3 月更新也表明,**闭源模型在通用文本/代码榜单中依然占据前列**。[7] 所以更准确的表述是:
- **开源已经逼近闭源头部能力;**
- **部分场景可替代,部分场景仍有差距;**
- **工程价值不只来自能力,还来自许可、部署和成本。**
### 3)真正的竞争维度已经变了
2024 年大家常问“开源能否追平闭源智力”;
到了 2026 年,工程团队更应该问的是:
- 能否本地运行?
- 能否私有化?
- 能否接函数调用?
- 能否长上下文处理业务知识库?
- 能否在边缘设备跑多模态任务?
- 能否在合规前提下微调与审计?
在这些问题上,Gemma 4 的回答明显更偏向开源阵营有利。
---
## Key Comparison Table
> 摘要:做选型时,不要只看参数和榜单,要看部署层级、协议支持、生态成熟度和成本结构。
| Dimension | Gemma 4 E2B/E4B | Gemma 4 26B A4B MoE | Gemma 4 31B Dense | 典型闭源前沿模型 |
|---|---|---|---|---|
| 主要部署场景 | 手机端、IoT、离线边缘推理 | 消费级 GPU、IDE、代码助手、Agent | 工作站/服务器、高质量本地推理 | 云端 API 为主 |
| 输入模态 | 文本、图像,小模型支持音频 | 文本、图像 | 文本、图像 | 通常支持多模态,但依赖厂商 API |
| 上下文窗口 | 128K | 256K | 256K | 通常较强,但受 API 价格和配额约束 |
| 架构特点 | 小模型、面向端侧 | MoE,强调 intelligence-per-parameter | Dense,稳定性与通用性更强 | 厂商自定义,不透明 |
| 工程协议 | 支持 system role、函数调用 | 支持 system role、函数调用 | 支持 system role、函数调用 | 通常支持,但接口策略由厂商控制 |
| 可控性 | 高,可本地部署 | 高,可私有化部署 | 高,可私有化部署 | 低到中,依赖 API 服务条款 |
| 生态接入 | 已进入 Transformers,HF 分发快 | 已进入 Transformers,社区活跃 | 已进入 Transformers,社区活跃 | SDK 完整,但不可改权重 |
| 许可模式 | Apache 2.0 | Apache 2.0 | Apache 2.0 | 闭源商用协议 |
| 最适合的团队 | 端侧 AI、嵌入式、多模态入口 | 创业团队、业务 Agent、代码产品 | 有 GPU 资源的企业研发团队 | 追求最快上线、预算更宽松的团队 |
---
## 工程团队怎么选:不是“最强”,而是“最合适”
> 摘要:Gemma 4 的价值在于分层部署,你要按业务路径选型,不要按社交媒体热度选型。
### 场景一:移动端、离线端、隐私敏感
优先考虑 **E2B/E4B**。[1][3]
适用任务:
- 离线语音入口
- 端侧图像理解
- 设备内知识问答
- IoT 控制助手
原因很简单:闭源 API 在这类场景常见问题是**延迟、隐私、网络依赖、单次调用成本**。而 Gemma 4 小模型明确面向端侧,并且支持音频/视觉输入。[3]
### 场景二:中小团队做代码助手、RAG、Agent
优先考虑 **26B A4B MoE**。[2][3]
它更像一条“成本与能力平衡线”:
- 长上下文可做代码库级问答
- 函数调用适合 Agent 编排
- MoE 结构更利于参数效率
如果你的目标不是冲击绝对第一,而是想在有限 GPU 预算内做一个**稳定能跑、还能微调、可以私有化**的产品,26B 非常值得试。
### 场景三:企业内网、本地高质量推理
优先考虑 **31B Dense**。[1][3]
31B 的意义在于:
- 能力更稳
- 更适合复杂推理与代码任务
- 在开源榜单中处于非常靠前的位置
如果团队已有工作站或服务器资源,希望构建:
- 私有代码 Copilot
- 企业知识库问答
- 内网多工具 Agent
- 多模态运营/审核系统
31B 会是更扎实的基座。
### 场景四:必须追求全局最优效果
这时仍要考虑闭源模型。[7]
尤其是以下情况:
- 业务容错率极低
- 追求最高天花板
- GPU 资源有限但预算充足
- 上线窗口极短,不想做任何自托管运维
现实一点说,**Gemma 4 让开源可竞争,但没让闭源失去价值。**
---
## 实战代码示例
> 摘要:下面给出一个本地推理和一个函数调用编排示例,重点展示 Gemma 4 的工程接入方式。
### 示例 1:用 Transformers 加载 Gemma 4 做多轮对话
```python
# 目的:使用 Transformers 加载 Gemma 4 指令模型进行本地推理
# 关键点:设置 device_map、使用 processor/tokenizer、拼接 system/user 消息
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 选择已发布到 Hugging Face 的 Gemma 4 指令模型名称
model_id = "google/gemma-4-31b-it"
# 加载 tokenizer;实际部署中可配合量化版本减少显存占用
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载模型;device_map="auto" 让框架自动分配设备
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 构造 system + user 输入,契合 Gemma 4 原生支持的 system role
messages = [
{"role": "system", "content": "你是一个企业内网代码助手,回答要简洁、准确、工程化。"},
{"role": "user", "content": "请帮我设计一个支持256K上下文的RAG问答服务模块分层。"}
]
# 应用聊天模板,把结构化消息转成模型输入文本
input_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 编码输入并放到模型设备
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
# 生成回答;生产环境应根据延迟与质量设置 max_new_tokens、temperature 等参数
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True
)
# 解码输出;只展示新增部分可在工程中自行裁剪
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
```
### 示例 2:基于函数调用思想做 Agent 工具路由
```python
# 目的:演示如何把 Gemma 4 接入一个简单的工具调用流程
# 关键点:先让模型输出结构化调用意图,再由业务层执行真实函数
import json
# 假设这是模型返回的结构化内容;实际项目中可通过 prompt 约束输出 JSON
model_output = """
{
"tool_name": "search_docs",
"arguments": {
"query": "Gemma 4 256K context function calling best practices"
}
}
"""
# 业务侧定义工具函数;注意这里由服务端掌控,不让模型直接执行危险操作
def search_docs(query: str):
# 这里可以接企业知识库、向量库或搜索引擎
return {
"hits": [
{"title": "RAG长上下文设计规范", "score": 0.93},
{"title": "函数调用安全白名单策略", "score": 0.88}
],
"query": query
}
# 解析模型意图;工程上应加入 try/except 和 schema 校验
payload = json.loads(model_output)
tool_name = payload["tool_name"]
arguments = payload["arguments"]
# 路由到安全白名单中的工具;避免任意函数执行
tool_registry = {
"search_docs": search_docs
}
if tool_name not in tool_registry:
raise ValueError(f"Unsupported tool: {tool_name}")
# 执行工具并获取结果
tool_result = tool_registry[tool_name](**arguments)
# 结果可继续回填给模型,形成完整的 Agent 工作流
print(json.dumps(tool_result, ensure_ascii=False, indent=2))
```
这两个示例传达一个核心点:Gemma 4 的实用价值不只在“回答更聪明”,而在于它的协议和工具链已经足够让你快速构建:
- 本地聊天服务
- 企业 RAG
- IDE 代码助手
- 工具调用型 Agent
- 多模态入口服务
---
## 代码块注释规范
> 摘要:技术文章里的代码注释不是越多越好,而是要帮助读者快速理解关键决策点。
建议遵循下面 4 条规则:
1. **先写“目的注释”**
每个代码块开头先说明这段代码要解决什么问题,避免读者只看见 API 调用,不知道上下文。
2. **关键步骤必须注释,样板代码不用逐行解释**
比如模型加载、设备映射、消息模板、工具路由这些步骤要注释;`import`、简单变量赋值不用过度解释。
3. **注释聚焦工程取舍**
好的注释要回答“为什么这么写”,例如为什么选 `device_map="auto"`,为什么要做工具白名单,而不是只说“这里调用函数”。
4. **标出生产环境注意事项**
示例代码通常是最小可运行版本,应在注释中提醒读者补充异常处理、权限控制、schema 校验和监控埋点。
---
## 常见问题与排错
> 摘要:Gemma 4 上手不难,难的是把推理、显存、协议和工具调用真正跑稳。
1. **加载模型时报显存不足**
优先尝试更小规格模型,或使用量化版本;31B 更适合工作站/服务器资源,不一定适合单张中低端 GPU。[1][3]
2. **Transformers 无法识别模型配置**
先确认 `transformers` 版本是否足够新。Gemma 4 于 2026-04-01 才进入官方文档与支持范围,旧版本很可能缺少适配。[5]
3. **多模态输入格式不兼容**
按照官方模型卡与 Transformers 文档使用对应的 processor/视觉处理逻辑,不要把文本模型的输入方式直接套到图像任务上。[2][5]
4. **函数调用输出不稳定**
在提示词中强约束输出 JSON,并在服务端做 schema 校验;不要直接信任模型生成的任意函数名或参数。[2]
5. **长上下文效果不稳定**
256K 不代表“塞满就一定更准”。工程上仍要做分块、摘要、召回排序与上下文裁剪,长窗口是能力上限,不是替代 RAG 设计的借口。[2]
---
## 结论:2026 年开源大模型,已经从“能用”走向“值得主力投入”
> 摘要:Gemma 4 的真正意义,是让开源模型重新成为企业架构设计中的一等公民。
如果只问一句话结论,我的判断是:
**Gemma 4 让 2026 年的开源大模型不仅“还能打”,而且在很多工程场景里已经非常值得打。**
但这个“打”,不是指所有 benchmark 上全面超越闭源,而是指它在下面这些维度上形成了强竞争力:
- Apache 2.0 许可,利于商用与集成 [1]
- 从端侧到服务器的完整规格覆盖 [1][2][3]
- 多模态、长上下文、函数调用、system role 等工程能力齐全 [2]
- 已快速进入 Transformers 与 Hugging Face 生态 [4][5]
- 在开源榜单和核心基准上进入第一梯队 [1][3]
### 给团队的下一步建议
如果你是工程负责人,可以按这个顺序推进:
1. **先做 PoC 分层选型**:端侧试 E2B/E4B,服务侧试 26B 或 31B;
2. **优先验证三类任务**:代码助手、企业 RAG、函数调用型 Agent;
3. **建立混合架构**:常规任务走 Gemma 4,本地可控;极难任务再回退闭源 API;
4. **补齐可观测性**:延迟、显存、token 成本、工具调用成功率、幻觉率都要量化;
5. **尽早做数据闭环**:把真实业务反馈用于提示词优化和后续微调。
未来一年,开源和闭源不会是谁消灭谁,更可能是**谁更接近你的业务约束,谁就赢**。Gemma 4 的价值,就在于它让开源第一次在这么多工程维度上同时变得“可选、可用、可控”。
---
## CSDN 发布建议(标签与专栏)
> 摘要:标签要覆盖模型、框架、部署和架构四个维度,便于触达目标读者。
标签建议:大模型、Gemma4、Google、开源模型、Transformers、AI工程化、模型部署、Agent、多模态、RAG
专栏建议:大模型工程实战、开源模型选型指南、AI应用架构设计
---
## 参考资料
1. **Gemma 4: Our most capable open models to date**
https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
2. **Gemma 4 model card | Google AI for Developers**
https://ai.google.dev/gemma/docs/core/model_card_4
3. **Gemma 4 — Google DeepMind**
https://deepmind.google/models/gemma/gemma-4/
4. **Welcome Gemma 4: Frontier multimodal intelligence on device**
https://huggingface.co/blog/gemma4
5. **Gemma4 · Hugging Face Transformers Docs**
https://huggingface.co/docs/transformers/model_doc/gemma4
6. **Model cards — Google DeepMind**
https://deepmind.google/models/model-cards/
7. **March 2026: Arena Leaderboard Updates & Rankings**
https://arena.ai/blog/march-2026-arena-updates/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)