MCP突然爆火:大模型终于能像“插USB”一样调用工具了,开发者该怎么上手?
工程师最近频繁看到一个词:MCP(Model Context Protocol)。它爆火不是因为“又一个 AI 概念”,而是因为它解决了一个非常实际的工程问题:**如何让不同模型、不同客户端、不同工具之间,用统一方式对接**。
> 大家想学习更多AI知识,可以收藏下面两个网站:
过去做 AI Agent,接一个文件系统、接一个内部 API、接一个文档库,往往都要写一套私有适配层;现在 MCP 试图把这件事标准化,官方甚至直接用“像 USB-C 一样连接 AI 与工具/数据源”来描述它的定位[1]。这件事一旦成立,开发者的集成成本、迁移成本和维护成本都会明显下降。
## 摘要
> 摘要:MCP 的核心价值,不是“让模型会调工具”,而是“让工具接入方式标准化”。
本文从工程落地角度讲清楚 5 件事:
1. MCP 到底是什么,为什么会被类比为“AI 世界的 USB”;
2. 它解决了传统 Agent 工具接入中的哪些结构性问题;
3. 开发者有哪些上手路径:本地 reference server、远程托管 server、现成文档型 server;
4. 生产环境中要关注哪些规范更新:结构化工具输出、OAuth、安全头、用户补充询问;
5. 该如何从一个最小可用 PoC,逐步演进到可运维、可治理的 MCP 架构。
如果你是做 AI 应用、研发平台、内部 Copilot、IDE 插件、文档问答、自动化运维的工程师,MCP 值得你尽快看懂。
## MCP 到底是什么,为什么大家都在说“像插 USB 一样”
> 摘要:MCP 是连接模型与外部数据源/工具的开放协议,它标准化了“模型怎么发现、理解并调用外部能力”。
Anthropic 官方对 MCP 的定义非常直接:它是一个**开放协议**,用于把 AI 模型连接到外部数据源和工具[1]。官方用“像 USB-C 一样标准化连接”来类比它,这个比喻之所以传播很快,是因为工程师一看就懂:
- USB 解决的是“设备接口碎片化”;
- MCP 解决的是“模型工具接入碎片化”。
在没有 MCP 时,常见问题是:
- 每个模型供应商有自己的 tool calling 约定;
- 每个客户端有自己的插件协议;
- 每个公司内部系统又有自己的 API 封装方式;
- 一个工具接入到 A 能跑,不代表在 B、C 也能跑。
MCP 试图把这些“连接层”抽象出来。根据官方 server 仓库和文档,MCP 常见能力包括:
- **tools**:让模型发起动作,比如搜索、读文件、调用 API[2];
- **resources**:把外部内容作为可访问资源暴露给模型[2];
- **prompts**:把可复用的提示模板标准化暴露出来[2]。
你可以把它理解为:
**tools 是动作,resources 是上下文,prompts 是可复用交互入口。**
更重要的是,MCP 已经不是纸面协议。Anthropic 文档明确列出了其在 Claude Code、Claude Desktop、Claude.ai、Messages API 中的接入场景[1]。这意味着它已经进入实际产品链路,而不是停留在 demo 层。
## MCP 为什么会突然爆火:它解决的是工程集成问题
> 摘要:MCP 火的根本原因,不是模型能力跃迁,而是“接工具”终于有了统一工程接口。
很多人把 MCP 的走红理解为“Agent 时代来了”,但从工程角度看,更准确的说法是:**Agent 基础设施开始标准化了**。
过去做工具调用,通常有三种痛点:
### 1)工具定义重复建设
同一个文件系统访问能力,你可能要为 Claude、OpenAI、IDE 插件、自研 Agent 分别写适配层。
而 MCP 提供统一接口后,理论上一个 MCP server 可以被多个支持 MCP 的客户端复用[1][8]。
### 2)知识源与执行工具分裂
传统上“文档检索”和“API 调用”往往是两套接入方案。
MCP 把只读知识源和可执行工具都纳入统一协议范式。例如 OpenAI 提供的 Docs MCP server,本质就是把开发文档作为一个 MCP 能力源暴露出来,供编辑器或代理访问[5]。这说明 MCP 不只是“调函数”,也可以“接知识”。
### 3)模型上下文被工具描述吃掉
当一个平台有几百上千个 API endpoint 时,如果都转成独立工具描述,token 成本会非常高。Cloudflare 在其 MCP 实践中就明确指出,维护大量工具定义会挤占上下文窗口,因此提出 Code Mode:让模型更多基于类型化 SDK 写代码并执行,而不是为 2500+ endpoint 全量暴露工具[6]。
这说明 MCP 爆火后,生态已经从“能不能接”进入“怎么更便宜、更安全、更可维护地接”。
所以,MCP 之所以火,不只是因为它“让模型能调工具”,而是因为它让这件事**更像工程系统,而不是脚本拼装**。
## 开发者怎么上手:三条最短路径
> 摘要:上手 MCP 不必一开始自己写协议实现,最省时间的方法是先跑官方 server、再接现成远程 server、最后再做自定义。
对大多数开发者,我建议按下面顺序上手。
### 路径一:先跑官方 reference servers
MCP 官方维护了 `modelcontextprotocol/servers` 仓库,里面包含 filesystem、fetch、git、memory 等 reference servers[2]。
这是最好的学习入口,因为你可以直接观察:
- 一个 server 如何声明 tools/resources/prompts;
- 客户端如何发现可用能力;
- 工具输入输出如何组织;
- 扩展能力时应该遵循什么方式。
这一步的目标不是“做业务”,而是建立正确心智模型。
### 路径二:直接连接远程 MCP server
Anthropic 的 MCP connector 文档说明,Claude 的 Messages API 可以直接连接远程 MCP server,开发者不必自己额外实现独立 MCP client[4]。
这意味着如果你只是想验证业务价值,可以优先选择:
- 现成托管的 MCP server;
- 第三方提供的远程 MCP 能力;
- 自己用 HTTP 暴露一个轻量服务。
这条路径非常适合 PoC,因为它能减少客户端侧工作量。
### 路径三:接一个现成“文档型 MCP”
如果你想先感受 MCP 带来的用户体验,而不是自己造 server,可以直接使用现成案例。
OpenAI 提供了公开的开发文档 MCP server,地址是 `https://developers.openai.com/mcp`,文档里还给出了 Codex CLI 的接入示例[5]。
这种 server 的特点是:
- 只读;
- 风险小;
- 非常适合验证“模型通过 MCP 获取可靠知识源”的效果。
这也是企业内部知识库 MCP 化的一个非常直观的参考样板。
## 从规范演进看,MCP 为什么开始更适合生产环境
> 摘要:MCP 新版规范开始补足结构化输出、OAuth、安全约束和交互补问,这些都是生产可用性的关键指标。
很多协议“看起来很好”,但真正上生产卡在安全、可观测、可治理。MCP 在 2025 年几次规范迭代中,明显在往生产级靠拢。
根据 2025-06-18 changelog,几个值得工程师重点关注的变化有[3]:
### 1)Structured tool output
结构化工具输出意味着工具返回不再只是松散文本,而更适合被程序消费、校验、二次处理。
这对以下场景非常关键:
- 前端 UI 渲染;
- 多工具链路编排;
- 审计日志归档;
- 自动化后处理。
### 2)OAuth Resource Server 定位
规范进一步明确了 OAuth 相关角色定位[3]。
这说明 MCP 不再只服务于本地桌面小工具,而是要认真面对远程服务授权、企业身份体系和受控访问问题。
### 3)Resource Indicators 安全要求
这类要求本质上是为了减少令牌误用和资源越权访问风险[3]。
如果你打算把 MCP 接到内部系统、数据平台、运维后台,这一点必须重视。
### 4)Elicitation:服务端向用户补充询问
这是一个非常实用的能力。现实中很多工具调用都缺参数,比如“帮我发布这个服务”——到底哪个环境、哪个 region、哪个版本?
新版规范引入 elicitation,允许服务端在缺信息时发起补充询问[3]。这能显著降低“模型瞎猜参数”带来的事故概率。
### 5)HTTP 下 `MCP-Protocol-Version` 头要求
这类版本协商要求看起来细节,但恰恰是跨客户端、跨服务互操作稳定性的基础[3]。
工程上最怕“都支持 MCP,但连起来有微妙差异”。显式协议版本头有助于减少这种问题。
如果再结合官方周年回顾中提到的 **Tasks** 概念——支持多步任务状态跟踪,如 `working`、`input_required`、`completed`[7]——可以看出 MCP 正从“工具接口协议”演进为“Agent 工作流基础设施”。
## Key Comparison Table
> 摘要:不同接入方式的复杂度、控制力和适用场景差异很大,选型不要一上来就自研全栈。
| Dimension | 方案A:本地 reference server | 方案B:远程托管 MCP server | 方案C:只读文档型 MCP server | 方案D:自建生产级 MCP server |
|---|---|---|---|---|
| 上手速度 | 快,适合当天跑通 | 快,省去客户端实现细节 | 最快,几乎开箱即用 | 慢,需要完整设计 |
| 工程复杂度 | 低 | 中 | 低 | 高 |
| 控制力 | 中 | 低到中,受服务方限制 | 低 | 高 |
| 安全与权限设计 | 简单,多为本地权限 | 依赖远程认证与网络边界 | 相对简单,多为只读 | 复杂,需要 OAuth、审计、隔离 |
| 适用阶段 | 学习、Demo、原型 | PoC、轻量集成 | 文档问答、知识接入 | 企业内部平台、核心业务自动化 |
| 典型案例 | filesystem、fetch、git、memory[2] | Messages API 直连远程 server[4] | OpenAI Docs MCP[5] | 内部 API、数据平台、运维系统 |
| 主要风险 | 只会 demo,不懂生产约束 | 依赖第三方稳定性 | 只能读不能写 | 成本高、治理难度大 |
## 实战代码示例
> 摘要:先从“接一个现成 MCP server”开始,再逐步过渡到“实现自己的 MCP server”。
下面给两个非常实用的入门示例:一个是接现成文档型 MCP;另一个是自定义一个最小工具服务的伪代码结构。
### 示例 1:在 Codex CLI 中添加 OpenAI Docs MCP
```bash
# 作用:把 OpenAI 开发文档作为一个 MCP server 接入本地工具链
# 关键点:这是只读文档型 server,适合先体验 MCP 的接入与查询方式
codex mcp add openaiDeveloperDocs --url https://developers.openai.com/mcp
# 作用:查看已配置的 MCP server
# 关键点:确认 server 名称、连接状态是否正确
codex mcp list
```
上面这个例子来自 OpenAI 官方文档[5]。它的价值不在“功能多强”,而在于你可以立刻理解 MCP 的几个核心体验:
- 能力是以 server 形式接入的;
- 客户端对 server 做统一管理;
- 模型访问的不一定是“执行工具”,也可以是“知识源”。
### 示例 2:最小 MCP server 设计思路(伪代码)
```python
# 作用:演示一个最小 MCP server 的结构
# 关键点:声明工具、接收参数、返回结构化结果
class SimpleMCPServer:
def list_tools(self):
# 向客户端暴露可用工具元数据
return [
{
"name": "get_build_status",
"description": "查询指定构建任务状态",
"input_schema": {
"type": "object",
"properties": {
"build_id": {"type": "string"}
},
"required": ["build_id"]
}
}
]
def call_tool(self, tool_name, arguments):
# 基于工具名路由到实际业务逻辑
if tool_name == "get_build_status":
build_id = arguments["build_id"]
# 这里通常会调用内部 CI/CD API
result = query_build_system(build_id)
# 返回结构化输出,便于模型和上层程序处理
return {
"build_id": build_id,
"status": result.status,
"duration_seconds": result.duration_seconds,
"summary": f"构建 {build_id} 当前状态为 {result.status}"
}
raise ValueError("unknown tool")
```
这个伪代码对应的是最朴素的工程思路:
1. **先定义工具元数据**:让模型知道“有什么可用”;
2. **再做参数校验与路由**:不要把模型输出直接喂给内部系统;
3. **尽量返回结构化结果**:呼应 MCP 规范对 structured tool output 的强化[3]。
如果你做企业内部集成,建议第一个工具不要选“发布服务”“删资源”这种高风险动作,而是优先做:
- 查询工单状态;
- 查构建结果;
- 查文档;
- 查指标;
- 查配置。
先把“读”打通,再考虑“写”。
### 示例 3:远程接入时的 HTTP 头处理思路
```http
# 作用:演示 HTTP 接入时需要显式带协议版本
# 关键点:新版规范要求在 HTTP 下处理 MCP-Protocol-Version 头
POST /mcp HTTP/1.1
Host: mcp.example.com
Content-Type: application/json
MCP-Protocol-Version: 2025-06-18
{
"method": "tools/list",
"params": {}
}
```
这个细节来自官方 changelog[3]。很多团队做 PoC 时容易忽略版本协商,但一旦多客户端、多环境、多版本并存,这就是稳定性的关键。
## 代码块注释规范
> 摘要:技术博客里的代码不需要长篇注释,但必须让读者快速看懂“目的、关键步骤、风险点”。
建议遵守下面 4 条规则:
1. **每个代码块开头写清“作用”**
例如:这是演示配置 MCP server,还是演示工具调用,还是演示安全校验。读者先知道目标,理解成本会低很多。
2. **只注释关键步骤,不逐行翻译代码**
比如“声明工具元数据”“做参数校验”“返回结构化结果”。
不要把 `if` 注释成“这里是 if 判断”。
3. **对有坑的地方必须注释风险**
例如协议版本头、认证信息、只读/可写权限边界、生产环境不要硬编码 token。
4. **注释要与工程决策相关**
好注释回答的是“为什么这么做”,而不是“这行代码在做什么”。
比如“返回结构化结果,便于后续 UI 和审计消费”。
5. **示例代码尽量体现最小闭环**
包括输入、处理、输出三部分。读者能从代码看出 MCP 的完整交互思路,而不是只看到一段零散配置。
## 常见问题与排错
> 摘要:MCP 初学者常见问题集中在协议理解、连接方式、权限边界和工具描述设计上。
### 1)为什么工具已经注册了,但模型就是不用?
先检查工具描述是否过于模糊。
工具名、描述、输入 schema 必须让模型清楚知道“什么时候该用它”。官方 reference servers 很值得对照学习[2]。
### 2)本地能跑,换远程就不稳定?
优先排查:
- HTTP 传输和网络超时;
- 协议版本头是否正确;
- 认证链路是否完整。
新版规范对 `MCP-Protocol-Version` 有明确要求[3]。
### 3)MCP 是不是等于 function calling?
不是。
function calling 更像模型厂商自己的调用机制;MCP 是更通用的协议层,覆盖 tools、resources、prompts 等能力[1][2]。
### 4)是不是所有 API 都该暴露成独立工具?
不一定。
当 API 面太大时,工具描述本身会消耗大量上下文。Cloudflare 的实践就强调了这一点,并尝试通过类型化 SDK + Code Mode 来降低成本[6]。
### 5)一上来能不能做写操作工具?
不建议。
先做只读查询型工具,等你把权限、审计、回滚、用户确认链路都补齐,再逐步开放写操作。
## MCP 对架构的真实影响:它不只是协议,更像 Agent 基础设施
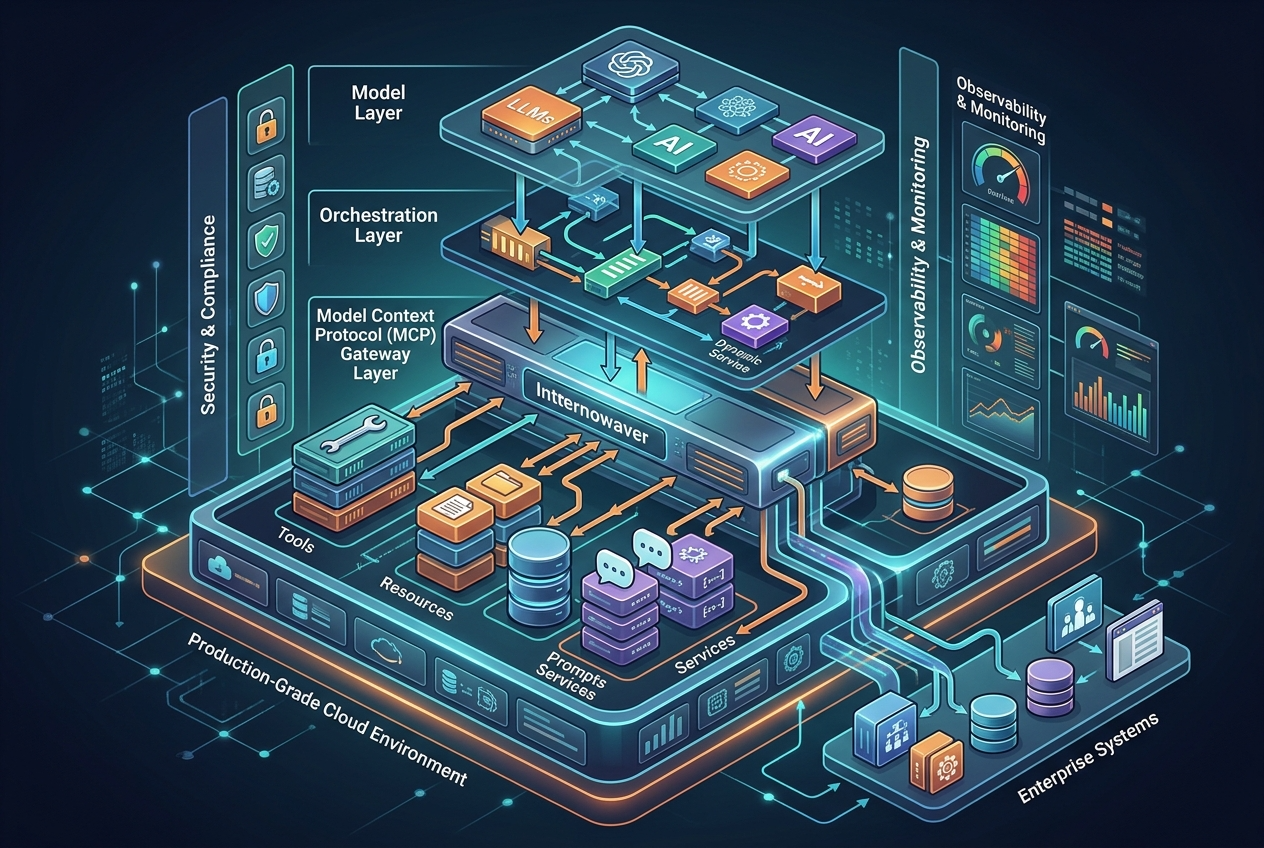
> 摘要:MCP 的长期价值不在单个工具调用,而在于把模型、工具、知识和任务状态放入统一基础设施。
如果只把 MCP 看成“换个方式调 API”,会低估它。
从已有公开资料看,MCP 正在朝几个方向扩展:
- **协议进入产品主链路**:Anthropic 已在多个产品接入[1];
- **跨厂商生态形成**:OpenAI 的 Apps SDK 明确基于 MCP 并做扩展[8];
- **复杂工作流支持增强**:Tasks 提供任务状态跟踪能力[7];
- **企业级问题被正面解决**:安全、OAuth、版本协商、交互补问持续完善[3][10]。
这意味着未来一套成熟的 AI 工程基础设施,很可能包括:
- MCP server:标准化暴露工具与资源;
- Agent runtime:负责编排、记忆、策略控制;
- 权限系统:做 OAuth、用户确认、资源隔离;
- 观测系统:记录任务状态、工具调用链路、失败原因;
- UI/IDE/Chat 客户端:作为统一入口。
从这个角度讲,MCP 很像早期 API 网关、插件系统、服务网格在各自时代扮演的角色:
**先统一接口,再积累生态,最后成为基础设施。**
## 结论:工程师下一步应该怎么做
> 摘要:别急着“全面拥抱 MCP”,先做一个低风险、可观测、可复用的最小闭环。
我的建议很明确:
1. **先跑官方 reference server**,建立 MCP 心智模型[2];
2. **再接一个现成远程或文档型 server**,感受标准化接入体验[4][5];
3. **选一个低风险内部读场景做 PoC**,比如查构建、查文档、查指标;
4. **从第一天就考虑结构化输出、认证、版本、审计**,不要把 PoC 写成未来技术债[3];
5. **不要盲目把所有 API 都工具化**,先评估上下文成本和维护成本[6]。
一句话总结:
**MCP 不是让模型“更聪明”,而是让 AI 系统“更像工程系统”。**
对开发者来说,它真正值得投入的原因,是标准化会带来复用、迁移、治理和生态红利。
## CSDN 发布建议(标签与专栏)
> 摘要:合理标签和专栏归类能显著提升文章曝光与搜索命中。
标签建议:MCP、Model Context Protocol、AI Agent、大模型、工具调用、Anthropic、OpenAI、协议设计、工程实践
专栏建议:AI 工程化实战、Agent 开发指南、大模型应用架构、开发者效率工具
## 参考资料
- [1] Model Context Protocol (MCP) - Anthropic
https://docs.anthropic.com/en/docs/mcp
- [2] GitHub - modelcontextprotocol/servers: Model Context Protocol Servers
https://github.com/modelcontextprotocol/servers
- [3] Key Changes - Model Context Protocol
https://modelcontextprotocol.io/specification/2025-06-18/changelog
- [4] MCP connector - Anthropic
https://docs.anthropic.com/en/docs/agents-and-tools/mcp-connector
- [5] Docs MCP | OpenAI API
https://platform.openai.com/docs/docs-mcp
- [6] Code Mode: fornisci agli agenti un'intera API in 1.000 token
https://blog.cloudflare.com/it-it/code-mode-mcp
- [7] One Year of MCP: November 2025 Spec Release | Model Context Protocol Blog
https://blog.modelcontextprotocol.io/posts/2025-11-25-first-mcp-anniversary/
- [8] Build with the Apps SDK | OpenAI Help Center
https://help.openai.com/en/articles/12515353-build-with-the-apps-sdk
- [9] New GraphQL Analytics API Explorer and MCP Server · Changelog
https://developers.cloudflare.com/changelog/2025-05-23-graphql-api-explorer/
- [10] The 2026 MCP Roadmap | Model Context Protocol Blog
https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)