项目实训(三):安全分析引擎迭代——统一 Source 模型、SQL 形态识别与污点传播重构
一、写在前面
上一篇博客里,我主要完成的是安全分析引擎的 MVP:先把最小闭环跑通,也就是:
用户输入 → 动态拼 SQL →
execute()执行 → 输出一条 SQL 注入候选结果
那一版最重要的目标,是让检测链路先跑起来。
而这一轮迭代,我开始真正进入分析引擎内部结构的收敛阶段。
这一版我更关注的不再只是“能不能报出风险”,而是下面这些更底层的问题:
source这一层能不能统一建模- SQL 表达式能不能分得更清楚
sink规则能不能更稳地识别安全执行- 污点传播逻辑能不能收成统一入口
- visitor 内部状态能不能从平行
dict逐步收敛成更清晰的状态对象
如果把这一轮讲成一句话,那就是:
让后端分析引擎不只是“能工作”,而是开始具备更稳定的规则边界、更清楚的证据表达,以及更可扩展的内部结构。
二、这一轮迭代主要解决的问题
MVP 跑通之后,我发现,抓出一条 SQL 注入链其实还不够。
因为分析引擎内部还有几个比较明显的问题。
1. source 识别还不统一
最开始的 source 更像是几个零散判断:
- 这是不是
request.args.get(...) - 这是不是某种不可信输入
这种写法短期能跑,但不适合继续扩。
后面再加入:
request.form[...]request.json.get(...)input()sys.argv[...]os.getenv(...)
如果还停留在“一个个布尔函数”的阶段,source_rules.py 很快就会变成一堆零散 if else。
2. SQL 形态判断太粗
之前只要看到:
- f-string
- 字符串拼接
- .format()
基本就会把它往动态 SQL 的方向靠。
但这样会把很多普通字符串格式化也算进去,误报会变大。
3. execute() 的安全写法区分不够
例如下面这种其实是参数化查询:
sql = "SELECT * FROM users WHERE id = ?"
cursor.execute(sql, (user_id,))
如果分析引擎只看到 execute(sql),但识别不出 sql 本身是安全模板,就可能产生误报。
4. engine 内部缺少清晰的数据分层
MVP 阶段里,表达式分析、变量污点状态、危险 SQL 状态虽然已经能跑起来,但它们之间的层次还不够清楚。
例如:
- 当前表达式的污点结果
- 某个变量已经携带的污点状态
- 某个变量已经升级成危险 SQL 的证据状态
这些概念在代码里已经隐约存在,但还没有被明确拆成几层稳定的数据对象。
如果这一层不先理顺,后面继续扩规则时,engine 内部会越来越难维护。
5. visitor 内部状态还有明显过渡痕迹
最开始 visitor 里维护的状态大多是:
setdict- 多组平行结构
这在过渡期是合理的,但一旦赋值覆盖、变量复制、状态清理这些情况变多,平行状态同步就会越来越麻烦。
所以这一轮不只是补规则,也是在推动内部状态从“零散存储”向“对象化状态表”收敛。
三、这一版的核心目标
基于上面这些问题,这轮迭代我把目标收成了 5 件事:
- 统一
source模型 - 细化 SQL 形态识别
- 完善
sink的安全执行判断 - 明确 engine 内部三种核心数据类型
- 收敛 visitor 内部状态结构
这一轮不是单纯的补规则,而是在做:
source / pattern / sink / flow 这几层的边界收敛
四、Source 层从布尔判断升级为统一模型
首先,是 source_rules.py。
我希望 source 这一层回答的,不再只是:
这个 AST 节点是不是不可信输入?
而是:
如果它是 source,那么它属于哪类来源、具体写法是什么、有没有对应 selector?
所以这一版我引入了 SourceInfo:
@dataclass
class SourceInfo:
kind: str
label: str
selector: Optional[str] = None
这三个字段的分工我做了明确划分。
kind
用于内部逻辑和统计,强调语义类别,例如:
http.queryhttp.formcli.inputcli.argvenv.variable
label
用于展示和解释,强调具体写法,例如:
request.args.getrequest.form[]input()sys.argv[]os.getenvos.environ[]
selector
用于保留更细的选择信息,例如:
request.args.get("id")中的"id"os.getenv("TOKEN")中的"TOKEN"sys.argv[1]中的"1"
这样做之后,source 不再只是“是否成立”,而变成了一个可以被后续规则层正式消费的数据结构。
在规则形态上,这一版我把 source 分成了两类。
1. 调用型 source
例如:
request.args.get("id")
request.form.get("name")
request.values.get("q")
request.json.get("id")
input()
os.getenv("TOKEN")
os.environ.get("TOKEN")
2. 下标型 source
例如:
request.args["id"]
request.form["name"]
request.json["q"]
sys.argv[1]
os.environ["TOKEN"]
最终,source_rules.py 的主入口统一成了:
def match_source(node: ast.AST) -> Optional[SourceInfo]:
...
source 不再只是零散规则,而开始成为一个稳定模型。
五、SQL 形态不再只看“是不是字符串拼接”
MVP 阶段,我对 SQL 表达式的判断还比较粗:
只要看到 f-string、+ 拼接、% 格式化、.format(),基本就会往动态 SQL 的方向靠。
但这样有一个很明显的问题:
f"hello {name}"
"hello {}".format(name)
这些只是普通字符串构造,并不是 SQL。
如果不做额外限制,也可能被误判。
所以这一版里,我把 pattern_matcher.py 做了进一步细化,把 SQL 表达式至少分成三类。
1. 固定 SQL 字面量
例如:
"SELECT * FROM users"
这类字符串应该被识别为 SQL,但它本身不是动态构造。
2. 参数化 SQL 模板
例如:
"SELECT * FROM users WHERE id = ?"
"SELECT * FROM users WHERE id = %s"
这类字符串依然是 SQL,但它属于安全模板候选,不应该直接往危险 SQL 的方向走。
3. 动态构造 SQL
例如:
f"SELECT * FROM users WHERE id = {user_id}"
"SELECT * FROM users WHERE id = " + user_id
"SELECT * FROM users WHERE id = {}".format(user_id)
这类才是真正需要和污点传播结合起来判断的重点。
因此,这一版里我把 SQL 形态识别拆成了几个更明确的判断函数:
is_static_sql_literal(...)is_parameterized_sql_template(...)is_dynamic_sql_expr(...)
并在此基础上,增加了统一入口 classify_sql_shape(…),把 SQL 形态分类收成一个稳定接口,后续 engine 只需要调用这个主接口即可。
六、Sink 层开始区分“危险执行”和“安全执行”
在 sink_rules.py 里,我原先的目标比较直接:
先把 execute(...) 识别出来。
所以最早的 sink 判断主要只回答:
这个调用是不是数据库执行点?
这一版里,我把它往前推进了一步:
不只是识别
execute(...),还要尽量识别出它是不是安全参数化执行。
例如:
cursor.execute("SELECT * FROM users WHERE id = ?", (uid,))
这显然是安全写法。
而另一种常见情况是:
sql = "SELECT * FROM users WHERE id = ?"
cursor.execute(sql, (uid,))
这也是安全写法,但如果只看当前这一行,是识别不出来的。
所以这一轮我做了两个改动。
1. sink_rules.py 继续只负责“调用外形判断”
它主要识别:
- 是不是
execute - 有没有绑定参数
- 第一个 SQL 参数能不能取出来
- 整体看起来像不像参数化执行
2. taint_engine.py 额外维护安全 SQL 模板变量
sink_rules.py 不直接负责数据流状态, 但它允许 taint_engine.py 传入一个 safe_sql_template_variables 集合。
这样,当出现:
sql = "SELECT * FROM users WHERE id = ?"
cursor.execute(sql, (uid,))
sink 判断就不再只是“看这一行”,而是开始结合前面变量状态一起工作。
这样,就把三层边界拆清楚了:
pattern_matcher.py负责 SQL 形态sink_rules.py负责调用外形taint_engine.py负责把变量状态接进来
七、围绕三种 engine 内部数据类型组织污点传播
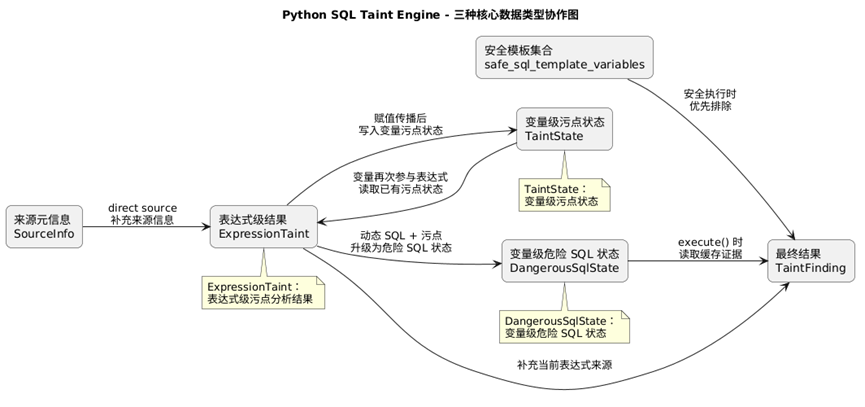
这一轮里,我对 taint_engine.py 最大的重构,不只是“把表达式分析收进一个函数”,而是开始围绕三种不同层次的数据类型来组织整个引擎内部逻辑。
如果从 engine 内部去看,这一版最核心的三类数据对象分别是:
ExpressionTaint:表达式级分析结果TaintState:变量级污点状态DangerousSqlState:变量级危险 SQL 状态
这三者分别对应三种不同粒度的问题。
1. ExpressionTaint:表达式级污点结果
这一类对象解决的是:
当前这个表达式,带不带污点?如果带,证据是什么?
大致结构是:
@dataclass
class ExpressionTaint:
source_line: Optional[int] = None
source_variable: Optional[str] = None
source_info: Optional[SourceInfo] = None
也就是说,不管当前分析的是:
request.args.get("id")
uid
f"SELECT ... {uid}"
"SELECT ..." + uid
"SELECT ... {}".format(uid)
最后都尽量先落成一份统一的表达式级结果。
2. TaintState:变量级污点状态
这一类对象解决的是:
某个变量当前是不是脏的?如果脏,它最早从哪里来?
大致结构是:
@dataclass
class TaintState:
origin_line: Optional[int] = None
source_info: Optional[SourceInfo] = None
它不再关心“这个表达式当前长什么样”,而是把传播之后的结果存成:
- 某个变量是否带污点
- 这个变量对应的来源行号
- 这个变量对应的结构化来源信息
也就是说,它已经进入了“变量状态层”。
3. DangerousSqlState:变量级危险 SQL 状态
这一类对象解决的是:
某个变量是不是已经被判成危险 SQL?如果是,它构造时的证据是什么?
大致结构是:
@dataclass
class DangerousSqlState:
build_line: int
source_line: Optional[int] = None
source_variable: Optional[str] = None
source_info: Optional[SourceInfo] = None
它保存的不再只是“这个变量脏了”,而是:
- 它在哪一行被构造成 SQL
- 它关联的 source 行在哪
- 它关联的 source 变量是什么
- 它关联的
SourceInfo是什么
也就是说,它已经从“污点变量”进一步升级成了“危险 SQL 变量”。
从这个角度看,这一轮不只是加了几个类,而是把 engine 里的数据流组织成了三层:
表达式级结果 → 变量级污点状态 → 变量级危险 SQL 状态
这比 MVP 阶段那种零散判断清楚得多。
八、这三种数据类型在 engine 里是如何衔接的
如果说上一节是在讲“有哪些类型”,那么这一节更关心的是:
这三种类型在 engine 内部到底是怎么流动起来的?
第一步:先把当前右值分析成 ExpressionTaint
无论是在赋值语句里,还是在 execute() 参数判断里,我现在都先从表达式开始:
(注:表达式就是“能算出一个值的那部分代码”。之所以先从表达式开始,是因为污点传播和 SQL 参数判定,本质上都是在分析“这个值是怎么来的”,而不是只分析变量名或整条语句)
- 看当前表达式里有没有 source
- 看当前表达式里有没有已有污点变量
- 看它是不是 f-string、拼接、
.format(...)这类复合结构
只要分析完,就都统一生成一个 ExpressionTaint。
第二步:如果表达式带污点,就把结果写入 TaintState
当右值分析出来是带污点的,例如:
uid = request.args.get("id")
name = uid
那么传播之后,name 不再只是一段表达式,而会被存成变量级状态,也就是:
self.taint_states[name] = TaintState(...)
某个变量以后再参与别的表达式时,不必重新从头找 source,而是可以直接从变量污点状态表里取。
第三步:如果表达式同时满足“动态 SQL + 污点”,就升级成 DangerousSqlState
例如:
sql = "SELECT * FROM users WHERE id = " + uid
这里如果右值同时满足:
SQL 形态为 dynamic_sqlExpressionTaint.has_taint == True
那它就不只是普通污点传播了,而是会进一步被记录为:
self.dangerous_sql_states[sql] = DangerousSqlState(...)
第四步:到了 execute(),优先读取 DangerousSqlState 作为证据
当后面出现:
cursor.execute(sql)
引擎就不只是看当前这一行,而是会优先去读取:
sql对应的DangerousSqlState- 当前 SQL 参数的
ExpressionTaint(execute调用的不是变量而是表达式时会用到) - 以及安全模板集合状态
也就是说,在 sink 处最终取证时,真正起核心作用的是:
- 当前表达式级污点结果
- 缓存过的危险 SQL 状态
- 安全模板排除条件
所以从数据流的角度看,这一轮 engine 内部真正形成的是这样一条主线:
SourceInfo先进入ExpressionTaintExpressionTaint再写入TaintState
当表达式构成危险 SQL 时,再升级成DangerousSqlState
最后在execute()处结合这些状态生成TaintFinding
而 safe_sql_template_variables 这条线则作为一个并行的安全分支存在,用来在 sink 判定时优先排除安全执行。
三种核心数据类型在 engine 中的协作关系如下图所示:
九、误报控制
这一轮不只是功能扩展,也是在做误报收缩。
到目前为止,我已经落地了几项比较关键的控制。
1. 普通字符串格式化不再轻易进入 SQL 分析
现在只有“像 SQL 的动态字符串构造”才会进入动态 SQL 判断。
这避免了把普通业务字符串格式化误判成 SQL 风险。
2. 参数化执行优先视为安全写法
例如:
cursor.execute("SELECT * FROM users WHERE id = ?", (uid,))
以及:
sql = "SELECT * FROM users WHERE id = ?"
cursor.execute(sql, (uid,))
这两类现在都会优先被放行。
3. 安全 SQL 模板变量可以继续传播
这意味着安全模板不只在“写死常量”的情况下有效,
而且在:
sql1 = "SELECT ... ?"
sql2 = sql1
这种变量传递下也能保留。
4. 变量被新值覆盖时,旧状态会被清理
例如:
username = request.args.get("username")
username = "fixed"
后一次赋值会清掉前一次的污点状态,避免旧状态残留导致误报。
十、函数参数与作用域:这一版仍然是过渡实现
这一轮我也进一步梳理了函数相关逻辑,但这部分我需要明确说明:
到目前为止,函数参数 / 作用域这一条线还没有被完全重写,它仍然是一个过渡方案。
当前策略是:
- 进入函数体分析前,把形参临时加入污点状态
- 遍历函数体
- 离开函数作用域后,再把这批临时状态清掉
也就是说,我现在还是先按一种比较保守的思路处理:
先把传入的函数形参视为可能有问题的输入
这样做的好处是:
- 能比较快覆盖教学场景里常见的函数拼 SQL 写法
- 先把最常见的风险捕捉下来
但它不是最终形态。
后面如果继续推进,这条线仍然需要进一步细化,例如:
- 更明确地区分函数局部作用域
- 更稳定地处理函数参数与返回值传播
- 减少“形参一律当污点”带来的粗糙性
十一、这一轮迭代的阶段性结果
到这一阶段,我已经把安全分析引擎从“能跑的 SQL 注入 MVP”往前推进了一步,主要体现在:
1. Source 层更统一了
不再只是布尔判断,而是有了稳定的 SourceInfo 模型。
2. SQL 形态判断更清楚了
能够区分:
- 固定 SQL
- 参数化 SQL 模板
- 动态 SQL
3. Sink 层更稳了
不只识别 execute(...),也开始区分安全参数化执行。
4. engine 内部三种核心数据类型已经明确
我现在已经可以把内部主线清楚地讲成:
ExpressionTaintTaintStateDangerousSqlState
它们分别承担表达式级、变量级污点、变量级危险 SQL 三层职责。
5. 内部状态开始收敛
visitor 内部从平行 dict 逐步转向对象化状态表,可维护性明显更好。
6. 误报控制已经开始落地
至少在 SQL 形态分类、安全模板识别、状态清理这几个方面,已经比 MVP 阶段更稳。
十二、这一轮迭代之后,我对引擎的理解
如果说上一篇博客更像是在回答:
安全分析引擎能不能先跑起来?
那么这一篇我更想回答的是:
安全分析引擎跑起来之后,内部结构能不能站得住?
真正困难的地方,不是“写出一个能检测的 if else”,
而是:
- source / sink / pattern / flow 的职责能不能拆清楚
- 内部状态会不会越来越乱
- 结果表达能不能稳定
- 后面还能不能继续扩
十三、下一步计划
接下来我准备继续沿着这条线往下做,重点会放在三件事上:
1. 继续补误报控制
例如:
- 更丰富的参数化占位符识别
- 更多
execute相关调用形态 - 更系统的测试样例补充
2. 继续细化 source 语义表达
包括:
- 更多输入来源扩展
- 更细的来源描述
- 更稳定的证据链表达
3. 重写函数参数 / 作用域这一条线
也就是把现在的“过渡实现”继续推进成更稳定的函数传播逻辑
结尾
这一轮迭代对我来说,一个很重要的感受是:
安全分析引擎真正难的地方,不是“先写出一条能报风险的规则”,而是让这条规则在结构上能长期站住。
从 MVP 往后走,真正开始拉开差距的,往往不是功能有没有继续堆,而是:
- 规则边界是否清楚
- 内部状态是否稳定
- 结果表达是否足够可解释
- 后续扩展时会不会越来越乱
而这一版我最想完成的,就是先把这些基础收紧一点。
后面不管是继续扩风险类型,还是往上下文补全、AI 解释那条线走,我都希望它建立在一套更稳的分析骨架之上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)