【LangChain】检索增强生成(RAG)和对应组件
目录
🐼什么是RAG
我们之前在说嵌入型模型将文本->向量,聊过RAG技术。
所以为啥要有RAG技术呢?看完一下场景就知道了:
对于【AI 大模型】来说,它最擅长的是语义理解和文本总结,最不擅长的就是获取实时的信息。因为大模型的训练数据是有截止日期的!
对于【搜索引擎】来说,它最擅长的就是获取实时的信息,缺点是信息分散,每次都需要人为进行
总结。
所以如果我们能把【AI 大模型】+ 【搜索引擎】,那么就是给 AI 配备了⼀个活字典,让 AI 可以随时进行实时查阅,之前用的Tavily那么工具就是例子。
他们俩配合的流程图:
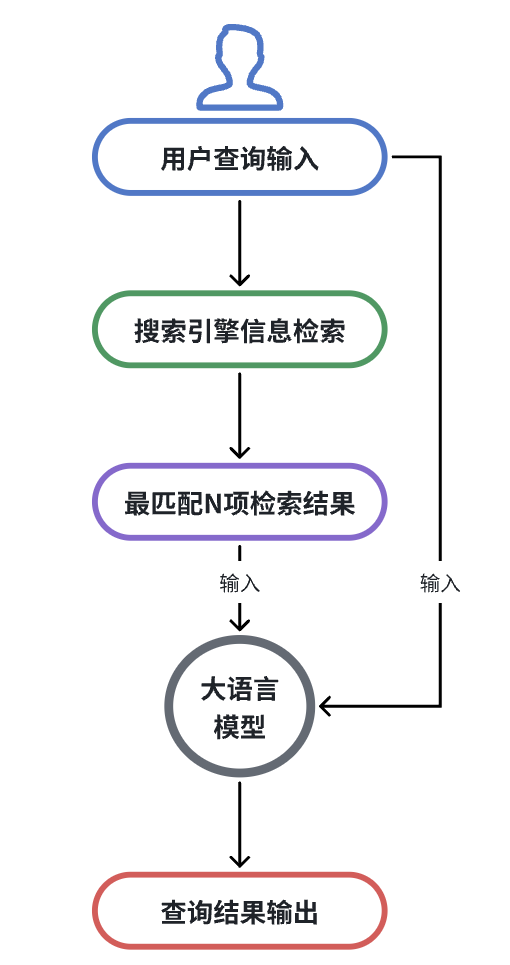
但是AI 大模型】+ 【搜索引擎】,这种方式的问题就是无法查询内部/本地的数据!
如何做呢?这也就是RAG的使用场景之一
答案是使用RAG(检索增强⽣成)技术!当用户向 LLM 提问时,系统首先在知识库(如公司内部⽂档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给 LLM 来生成答案。与 AI 搜索类似,本质是知识库改变了,从搜索引擎线上搜索改为了本地或私有知识库中搜索。
🐼RAG的流程
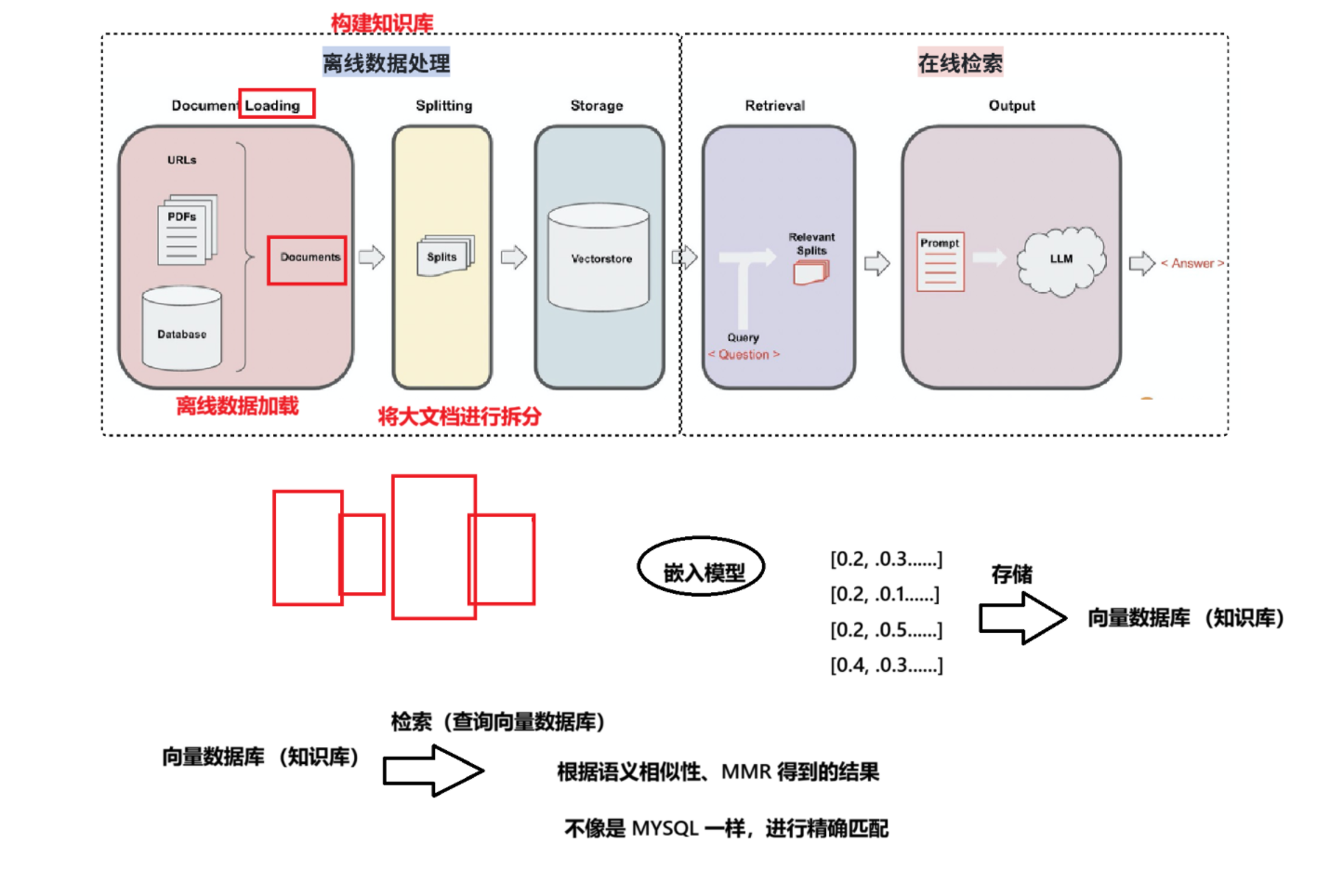
RAG 的流程分为【离线数据处理】和【在线检索】两个过程。
我们之前也提及过,我们需要把文本->向量,以便大模型可以根据语义相似,或者MMR来检索。
这个过程具体为:
下面我们将学习RAG技术所使用的一个个组件:
🐼Document 文档类(loader)
首先就需要从源中获取数据,即加载数据或文档。这是通过 LangChain 的文档加载器完成的。LangChain 文档加载器可以将各种数据源加载成⼀系列的文档对象 Document 。
我们可以直接定义LangChain 文档列表
这里我们定义了⼀个 documents ⽂档列表,其内包含了两个 Document ⽂档对象。通常,单个Document对象表⽰较⼤⽂档的⼀个块/页。每个 Document 对象,包含了以下参数:
• id :可选的文档标识符。理想情况下,这应该在整个文档集合中是唯⼀的,并格式化为
UUID,但不会强制执行。
• page_content :字符串文本
• metadata :与内容关联的任意元数据。类型为 dict [Optional]
下面我们学习一些Document加载器:
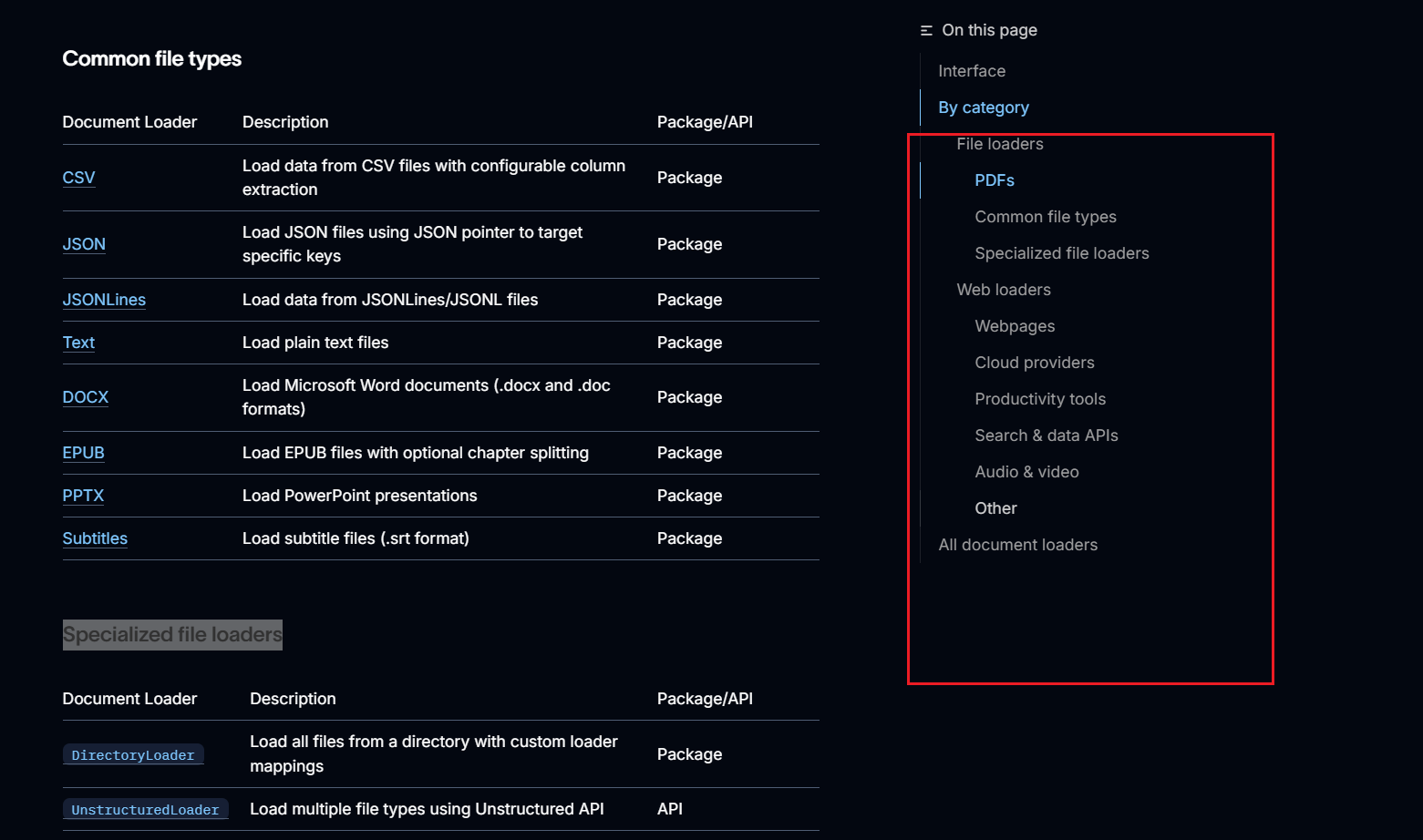
将本地的 PDF 文档加载到 LangChain 中,其实就是将 PDF 文档转换为⼀个个 Document 对象。这时就需要我们使用PyPDFLoader 文档加载器完成这⼀功能。
loader = PyPDFLoader("PDF/第十六届蓝桥杯大赛软件赛(编程类)知识点大纲.pdf")
documents = loader.load()
print(f"PDF页数\n{len(documents)}\n")
print(f"第一页前两百个字:\n{documents[0].page_content[:200]}")
print(f"第一页源数据:\n{documents[0].metadata}")
不过在某些应用程序中,例如对具有复杂布局、图表或扫描的 PDF 进行问答,可以跳过 PDF 解析,直接将 PDF页面转换为图像并将其直接传递给模型可能是更准确的。
加载 Markdown 文件
将本地的 Markdown ⽂档加载到 LangChain 中,需要我们使用UnstructuredMarkdownLoader 文档加载器完成这⼀功能。可以自行研究,当然,也支持各种文档加载,比如云服务厂商的...
🐼文本分割器(Text splitters)
我们已经将文本加载起来了,为啥要拆分呢?
对于pdf加载,它默认是按照页数来分割的,但是这就会导致本属于同一段话的内容如果在两页,那么就会是两个document。

markdown格式的也是如此,拆分的太细了。
所以文档拆分通常是将大文本分解为更小的、易于管理的块。这对于索引数据并将其传递到模型中都很有用。因为,大块更难搜索并且不适合模型的有限上下文窗口。拆分可以提高搜索结果的粒度,从而可以更精确地将查询与相关⽂档部分进行匹配。最终目的,也就是尽量保证一个document内的内容是相似的,能够称得上是一个document!
主要包括两种拆分:
1.根据⽂档长度与⽂档语义拆分
我们可以直接根据文档的长度拆分⽂档,是最简单且有效的方法。可确保每个块不超过指定的大小限制。对于长度拆分,其实也分为两种: 基于字符长度拆分 基于Token长度拆分
基于字符长度拆分
根据给定的字符序列进行拆分,拆分的块长度则按字符数来衡量。假设我们有一篇md文章都以'\n\n'分割,以长度分割的举个例子:
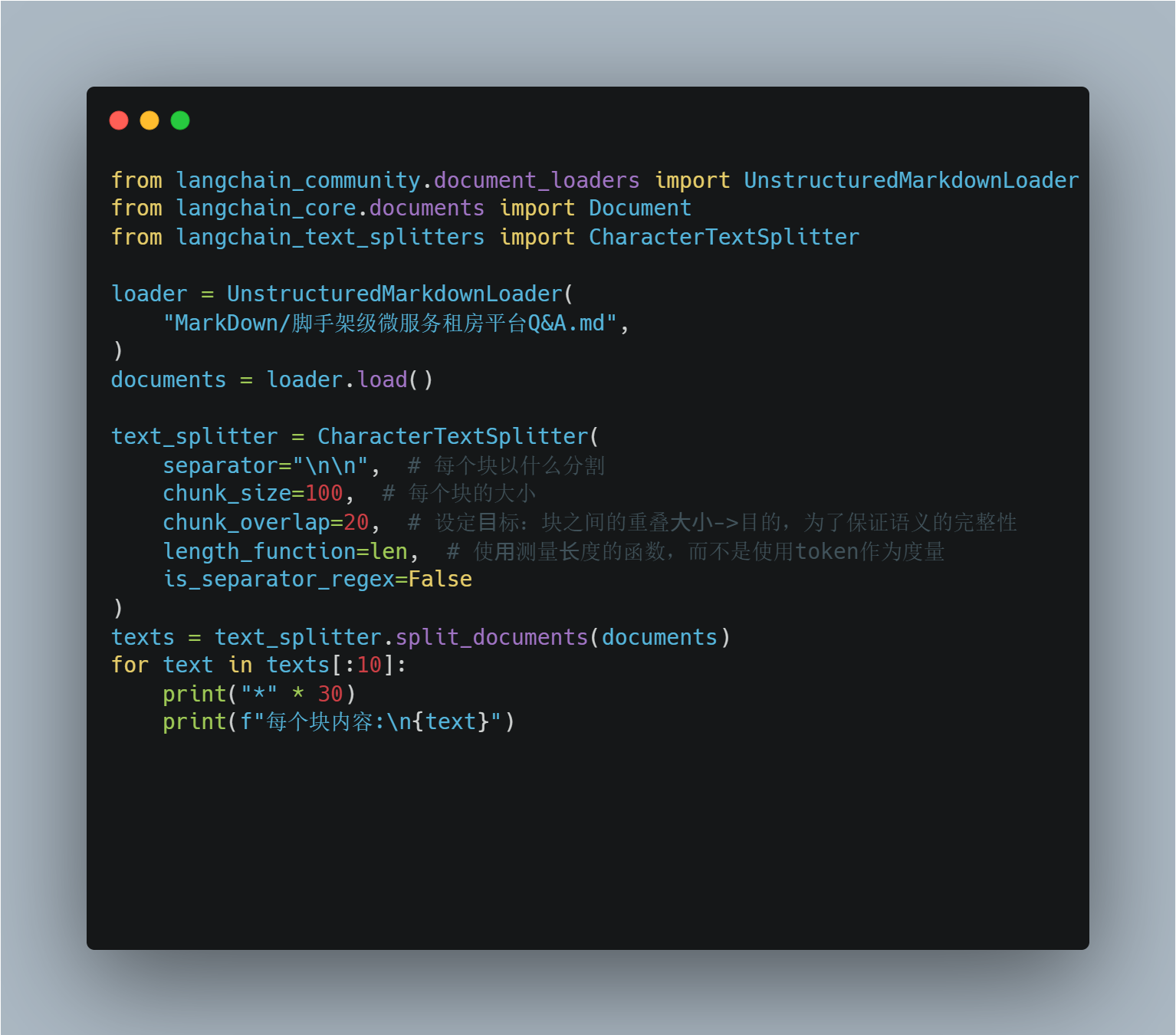
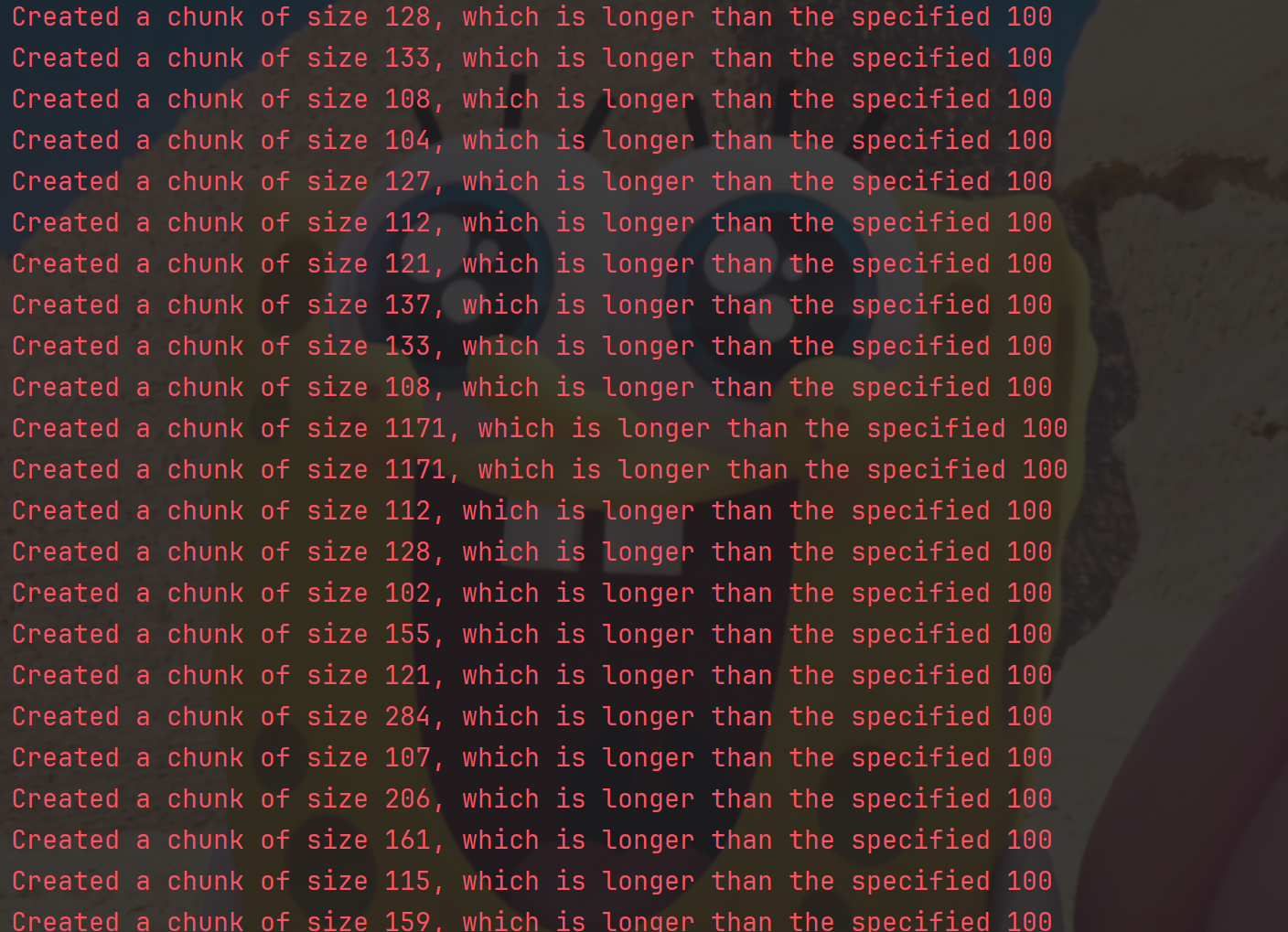
我们发现有很多块都超了,这表示分割时,超出了我们设定的 chunk_size=100 目标块大小。在这里要说明,这是⼀个在使用LangChain 的文本分割器时非常常见的问题。看到这个信息,不要担心,这不是错误,而是预期的行为。原因是为了保持语义的完整性!
说明我们设置的块的长度太小了,我们需要根据结果适当微调
适当调大:

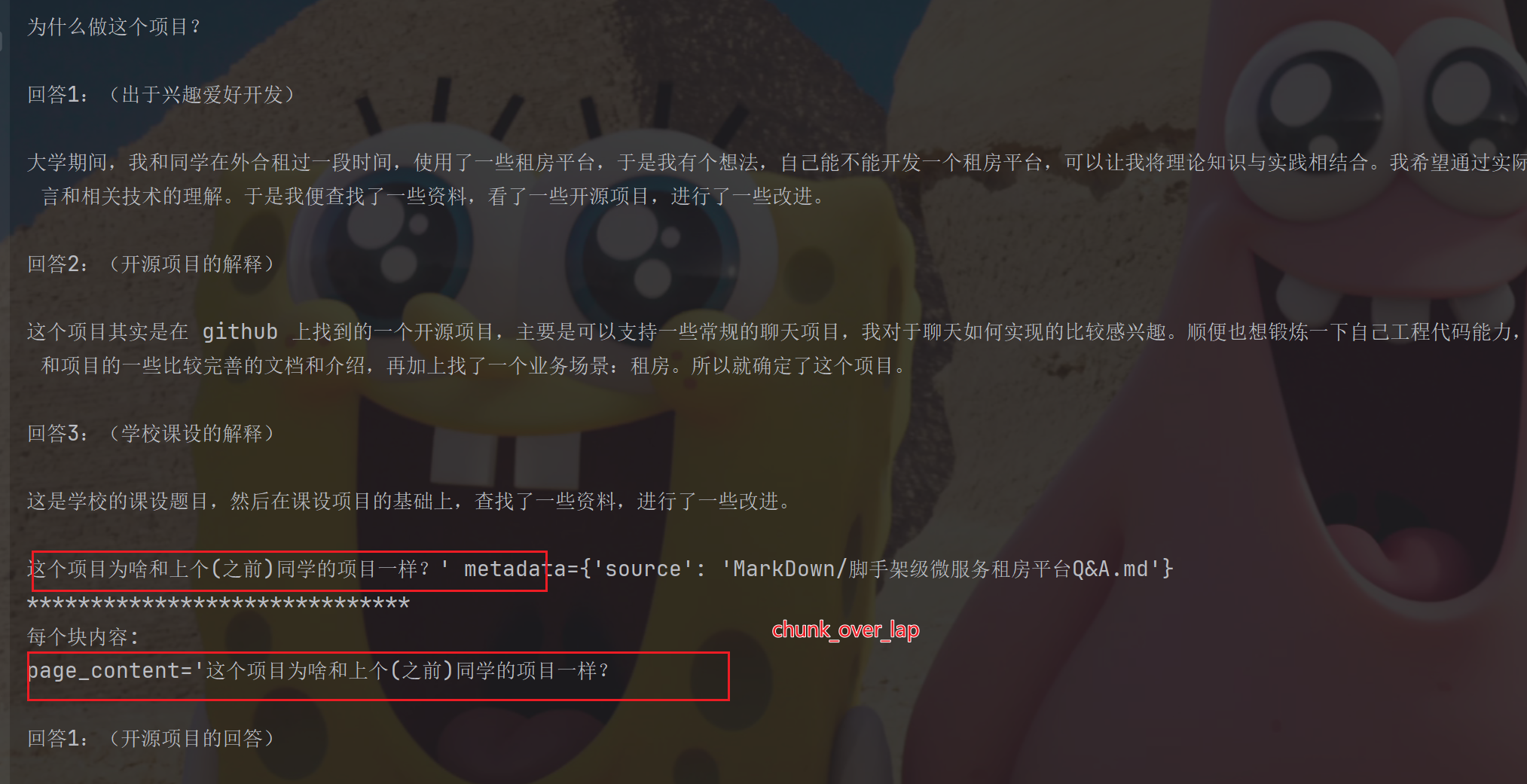
运行后,可以看到超出的分割已经很少了
基于 Token长度拆分
上面是基于长度分的,也支持token来分,可以借助 【 tiktoken 分词器】来进行token 的切分编码
给定⼀个文本字符串使用 tiktoken 分词器进行切分编码
如图:
import tiktoken
# 定于cl100k_base编码⽅式的分词器
enc = tiktoken.get_encoding("cl100k_base")
# 进⾏切分编码
enc_output = enc.encode("hello , how are you")
# 打印结果
print(f"编码后的token:{str(enc_output)}")
for token in enc_output:
print(f"将token: {str(token)} 变成⽂本:{str(enc.decode_single_token_bytes(token))}")
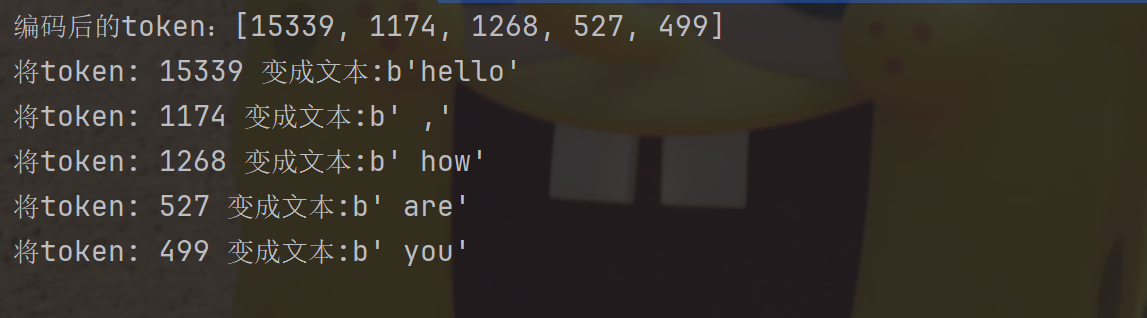
cl100k_base 是 tiktoken 分词器中的⼀种编码方式。 gpt-4 、 gpt-3.5-turbo 等都采用这种切分编码方式。
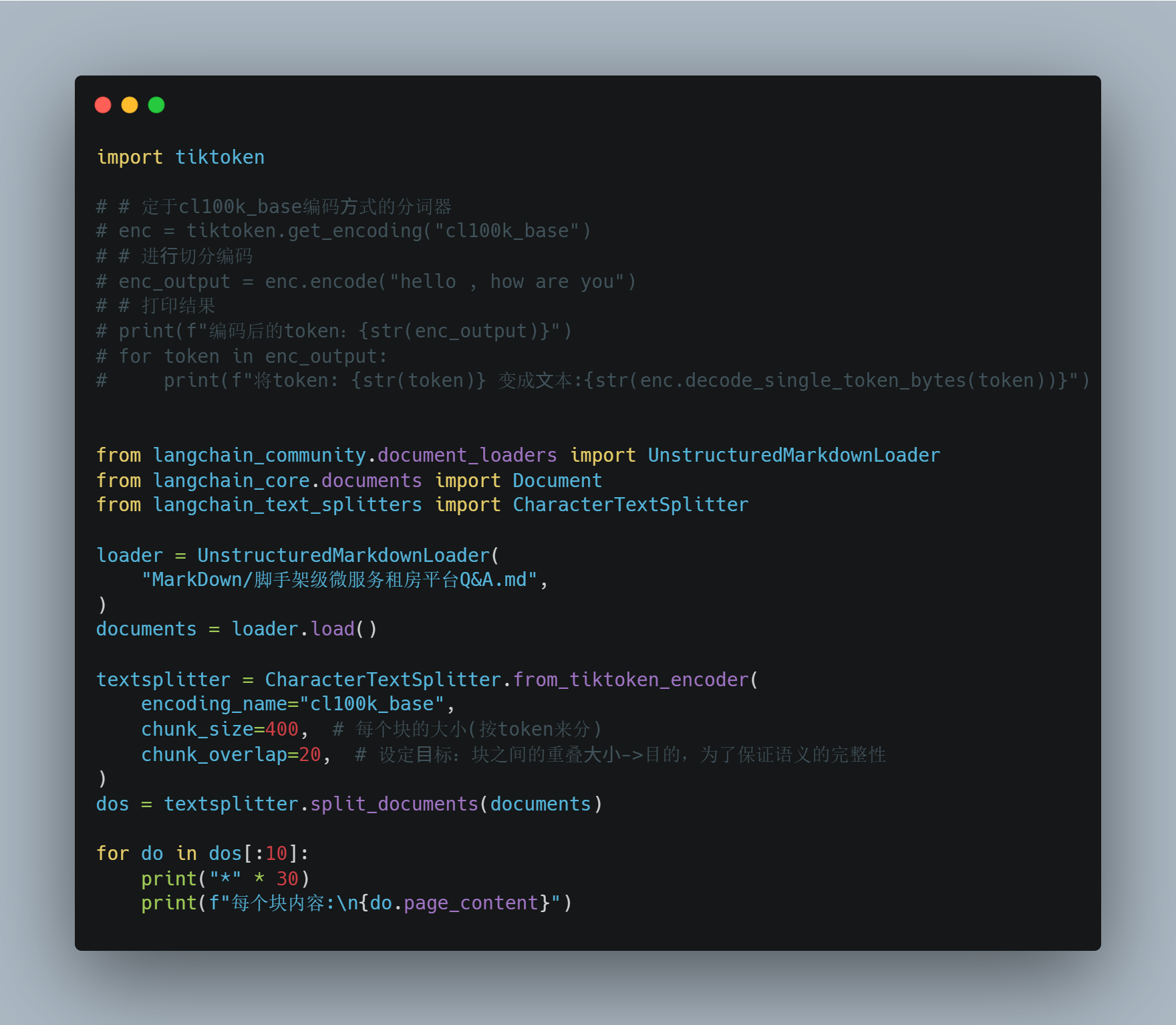
在LangChain中,我们可以使⽤ CharacterTextSplitter 分割器的 .from_tiktoken_encoder() 方法来定义根据 tiktoken 分词器拆分文本的分割器
硬性约束长度拆分
如果我们就想要求任何块都不能超过指定大小,可以使⽤ RecursiveCharacterTextSplitter类 或
RezursiveCharacterTextSplitter.from_tiktoken_encoder 方法,它会严格遵守对块大小的硬约束。
LangChain官方告诉我们,如果对于普通的文本分割,这种分割方式是推荐的
比如这里我们强制每个块大小就是100
textsplitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
".",
",",
], # 定义优先级的文本分割标识,从前往后,依次递归尝试分割
chunk_size=100, # 每个块的大小
chunk_overlap=0, # 设定⽬标:块之间的重叠⼤⼩->目的,为了保证语义的完整性
)
dos = textsplitter.split_documents(documents)
for do in dos[:10]:
print("*" * 30)
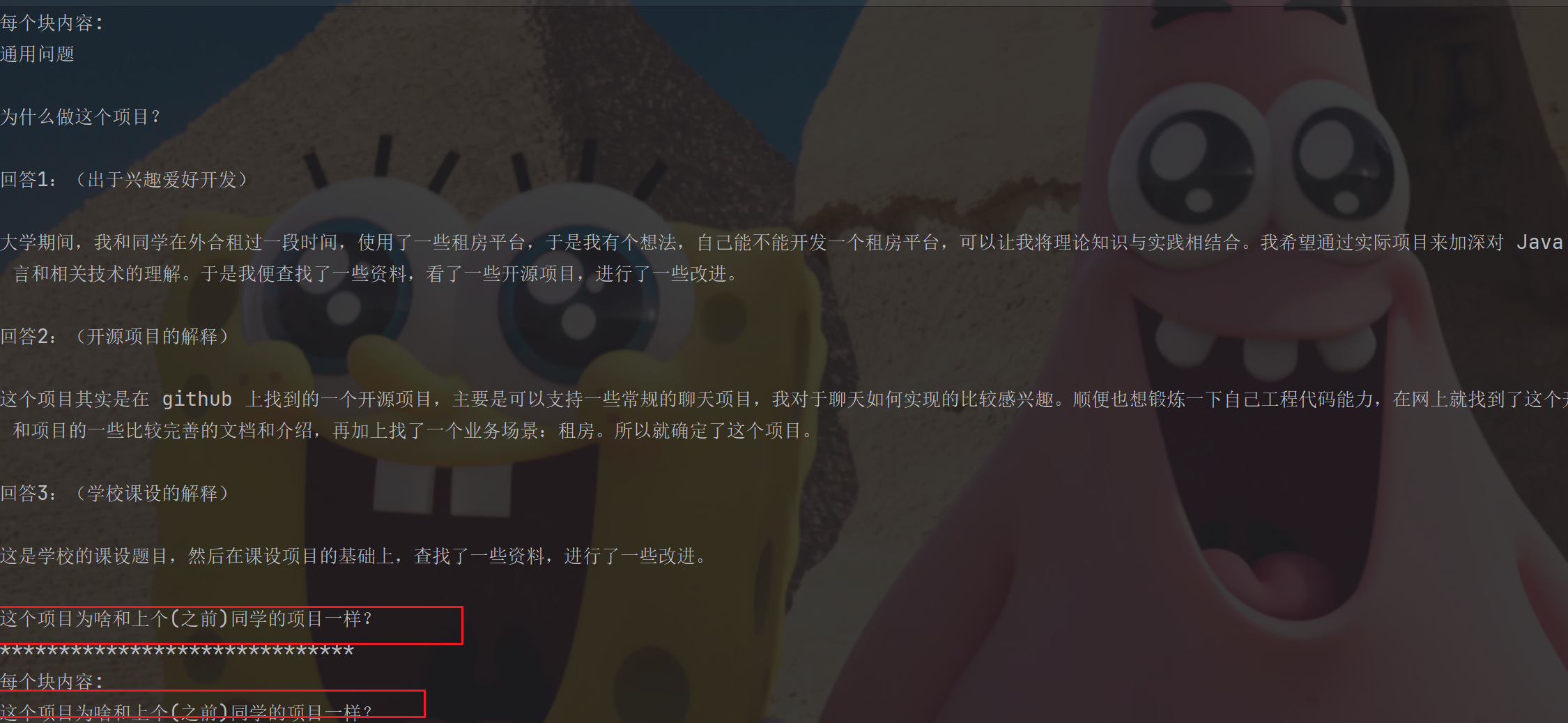
print(f"每个块内容:\n{do}")
我们发现中间确实一句话没说完就断了
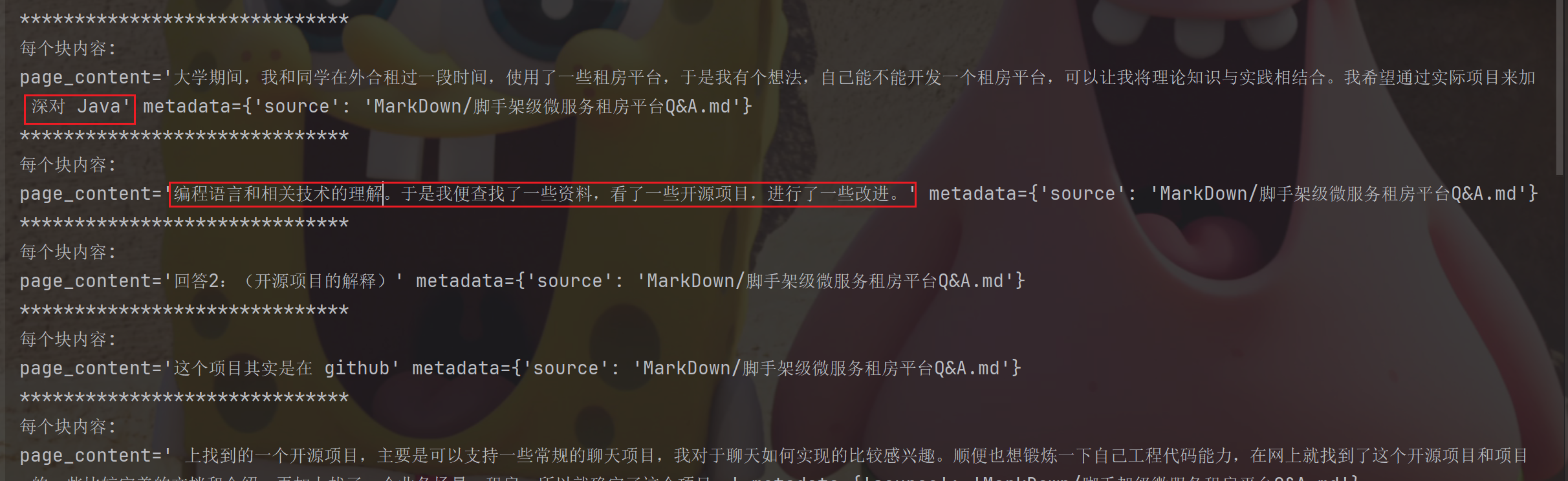
特殊文档结构拆分
若对于代码等特殊⽂本,可以尝试使用 Language 提供的不同的分割器(PythonCodeTextSplitter 、 HTMLHeaderTextSplitter 等)效果会更好,它会理解代码的语法结构。LangChain给我们提供了各种文本拆分器:
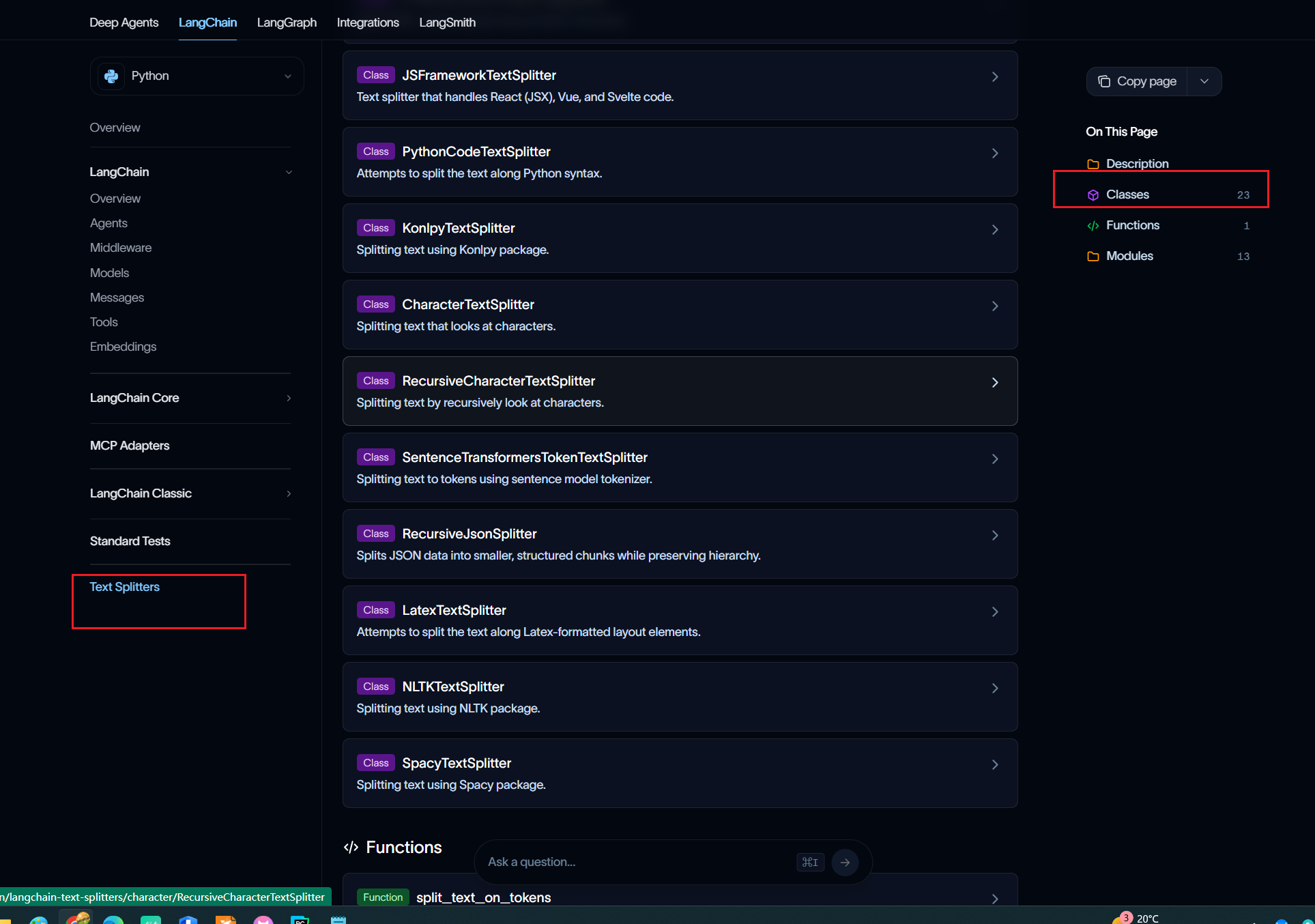
比如我们要拆分一个Json串,用一下RecursiveJsonSplitter这个文本分割器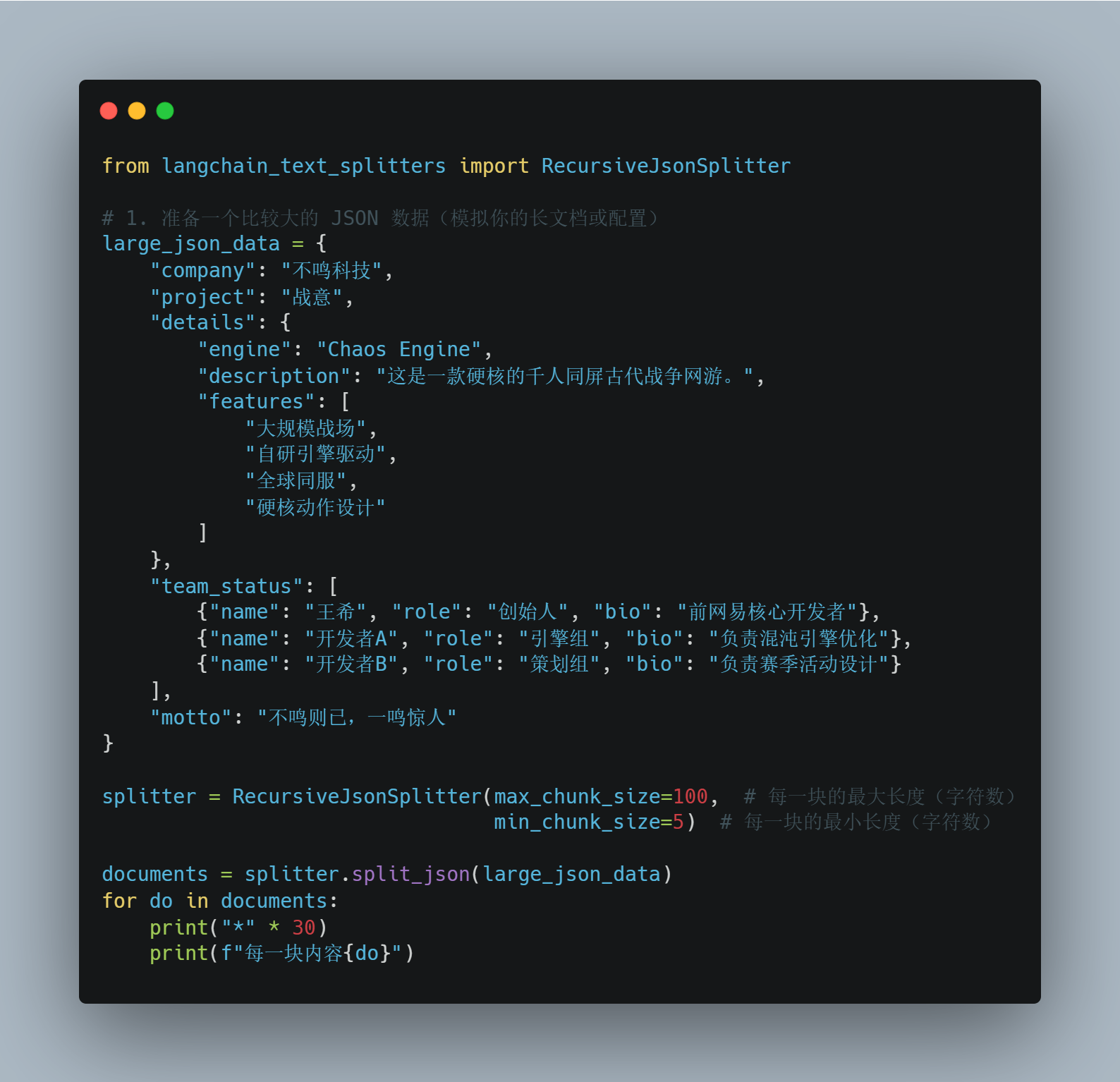

🐼嵌入式模型(Document->Vector)
下面我们就需要将一个个拆分好的splits,转换为向量,这个过程需要嵌入式模型。嵌入式模型时什么?请移步->这里
在 LangChain 中,有很多的嵌入模型提供方,使用不同的模型提供方,需要安装为其各自包
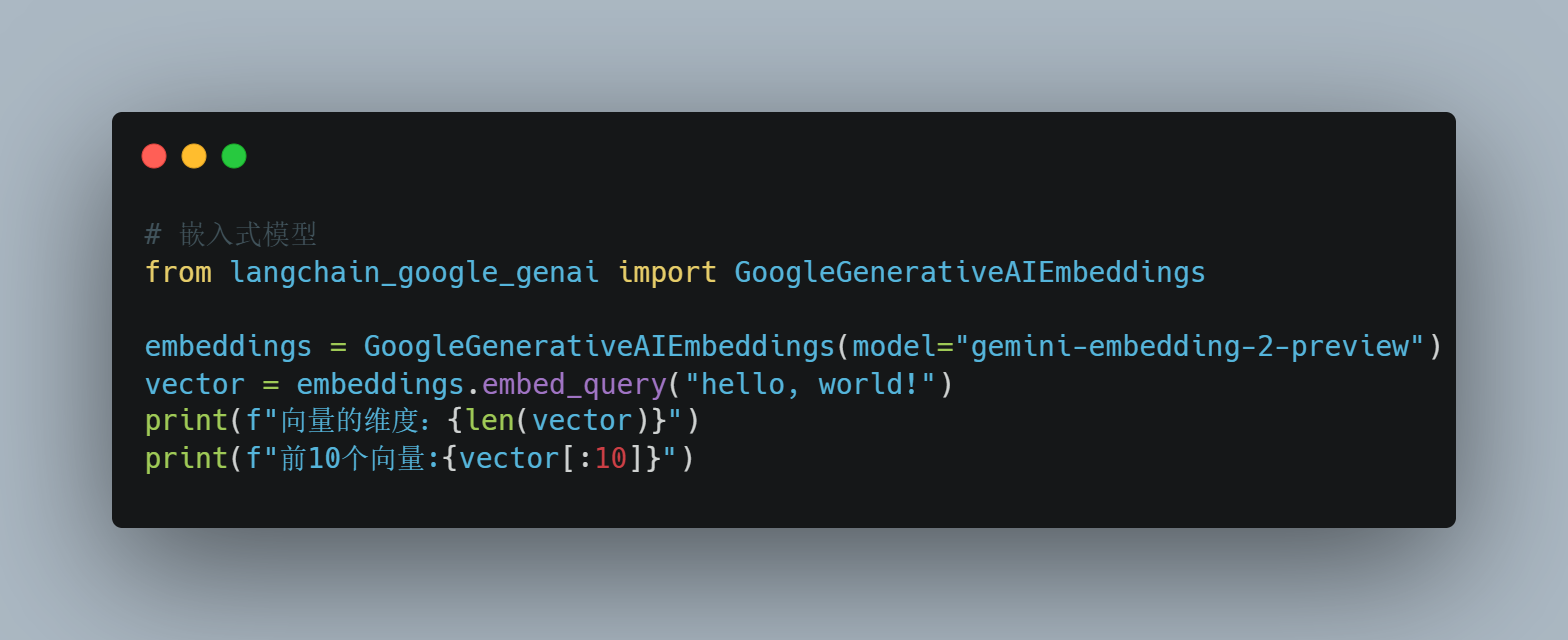
我们这里以google的嵌入式模型为例:
# 嵌入式模型
from langchain_google_genai import GoogleGenerativeAIEmbeddings
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-2-preview")在 LangChain 框架中基础 Embeddings 类( GoogleGenerativeAIEmbeddings继承了它)设计了两个核心方法来处理文本嵌⼊。
1. embed_documents() : 用于处理文档 Documents 。它的输⼊是多个⽂本。例如要将⼀个知识库里的所有段落都转换成向量后存⼊数据库,就会使用这个方法。
2.embed_query() :用于处理查询 Query 。它的输入是单个文本(⼀个字符串,str)。例如,当用户提出⼀个问题时,需要将这个问题转换成向量,以便在数据库中搜索相似的文档段落,就会使用这个方法。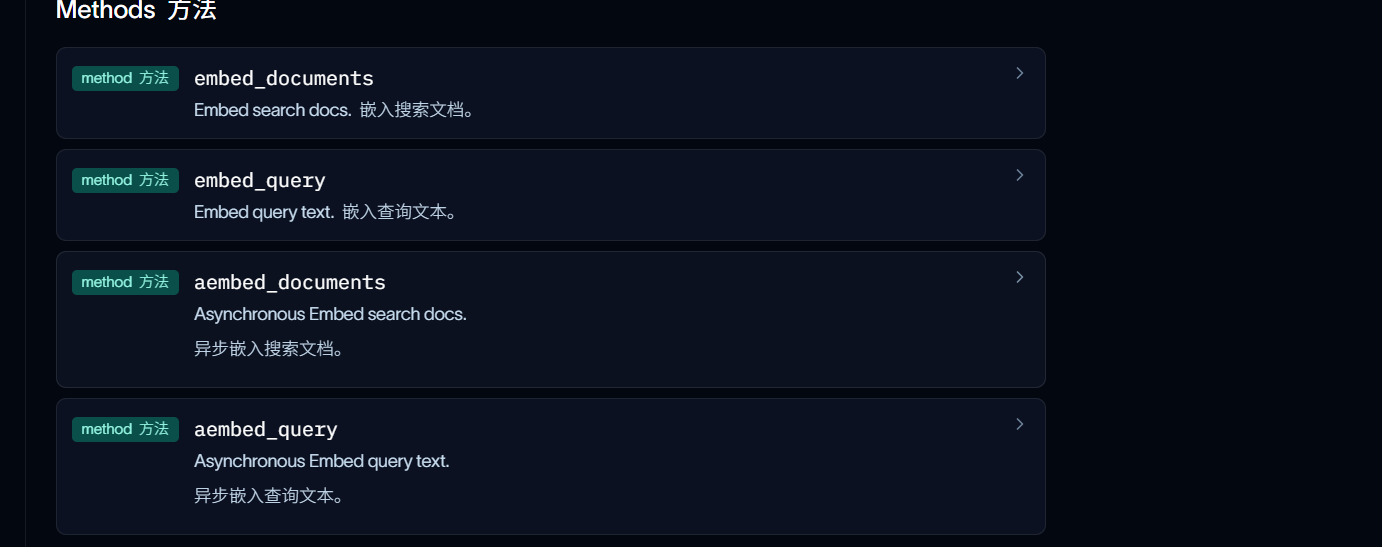
可是既然都是将文本->向量,为啥要设计两个方法?
之所以设计成两个方法,是因为某些嵌入模型提供商(如 OpenAI、Cohere 等)会针对 “被搜索的文档” 和 “搜索查询本身” 采用不同的优化策略和模型。即使底层是同⼀个模型,也可能对两者进行不同的预处理(例如添加不同的指令前缀),以获得更好的搜索效果。
所以我们既要将文档->向量,也要将查询的问题->向量,进行向量之间的数学运算,这样才能在向量库中查找到我们想要的文档
下面我们利用embed_query,将查询的问题->向量

利用embed_documents,将文档->向量
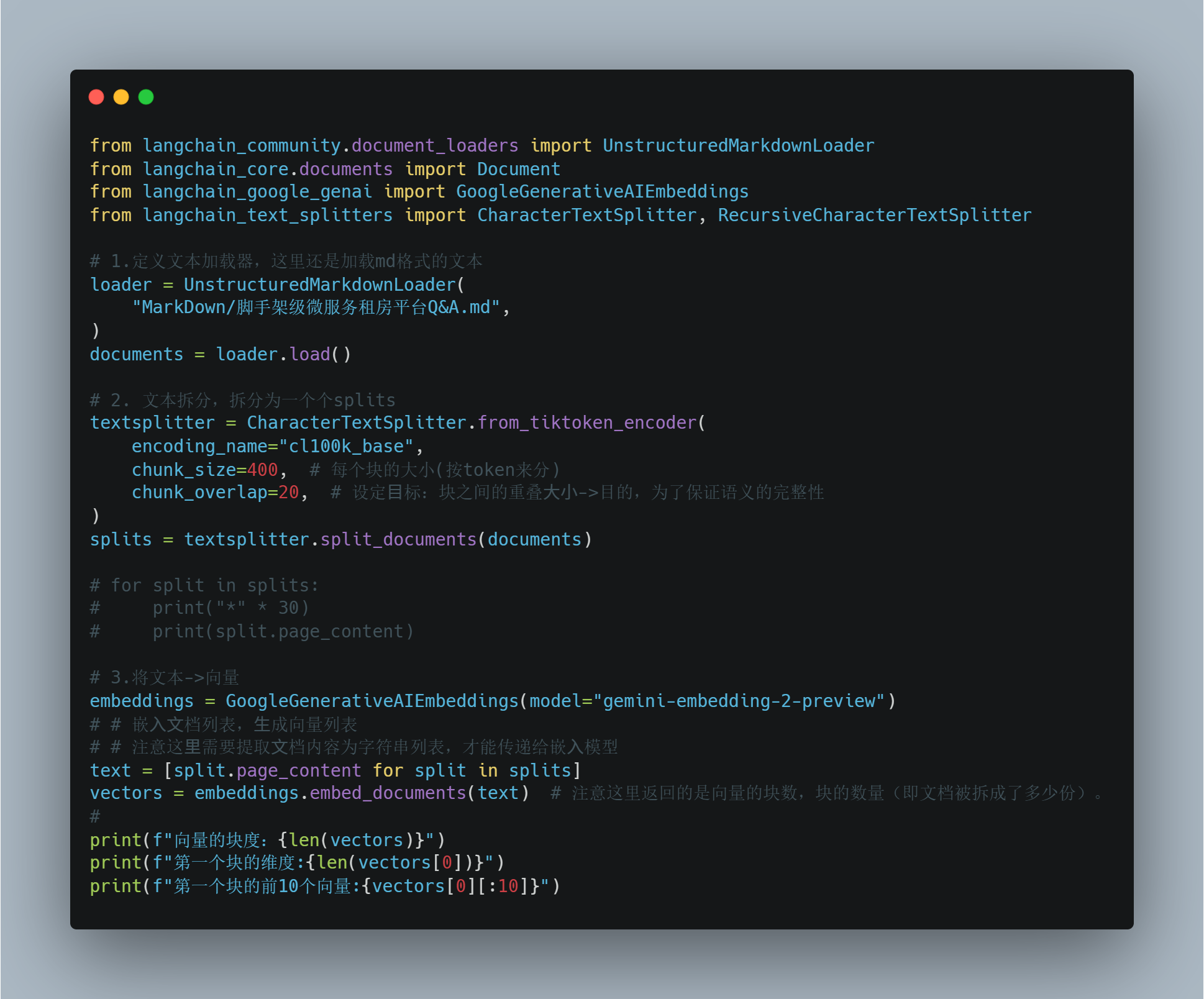
这里需要注意,向量的块数=切分后文档的块数
![]()

需要特别注意的是:
embed_query (单向量)
它处理的是一个字符串,返回的是一个列表(一维数组)。它是和每一个切分的文档匹配的
embed_documents (向量矩阵)
它处理的是一组字符串(即你拆分后的 splits),返回的是嵌套列表(二维数组/矩阵)。
🐼向量存储(Vector Stores)
在 LangChain 中,实际并不需要我们直接手动调用嵌入模型去生成向量,然后手动去比较向量。在我们之前提供的 RAG 知识地图中,存在⼀个 Vector Stores 向量存储。如果我们拆分文档->文档转向量->存储到向量数据库,多了一个修改的风险。
而拆分文档->向量数据库更安全。
所以,为什么要有向量数据库呢?为了提高管理和检索数据的能力。
不像MySQL了,还需要精确匹配等。向量存储的核心任务是解决⼀个传统数据库(如MySQL)不擅长的问题:基于内容的相似性搜索(Similarity Search),而不是基于精确匹配的查询。效率就是快!
想象⼀下,⼀篇文档若转换成⼀个有1536个浮点数的向量。⼀百万篇⽂档就是1536MB(约1.5GB)的纯向量数据。这只是⼀个起点,现实中的数据集可能轻松达到千万甚⾄亿级。如何高效地存储和管理这些向量?
向量数据库则提供了专门用于高效存储、管理和检索高位向量的能力。其核心就是 “高效地组织和检索这些数据”。
常见的向量数据库核心机制如下:
专门的索引
这是向量数据库的灵魂。它们不会使用暴力搜索,而是会预先为所有向量构建⼀种特殊的索引结构。这不索引不像MySQLB+树的索引,是一种精确查找的机制。它是近似的但不是精确的
常见的方法有近似最近邻(ANN)搜索:为了追求极致的速度,它愿意牺牲⼀点点精度。它不会保证找到绝对最相似的向量(即最近邻),但能以极高的概率找到非常相似的向量。通过聚类、分层、压缩等算法技术,将搜索范围从“整个数据库”缩小到“几个最可能的候选集”。
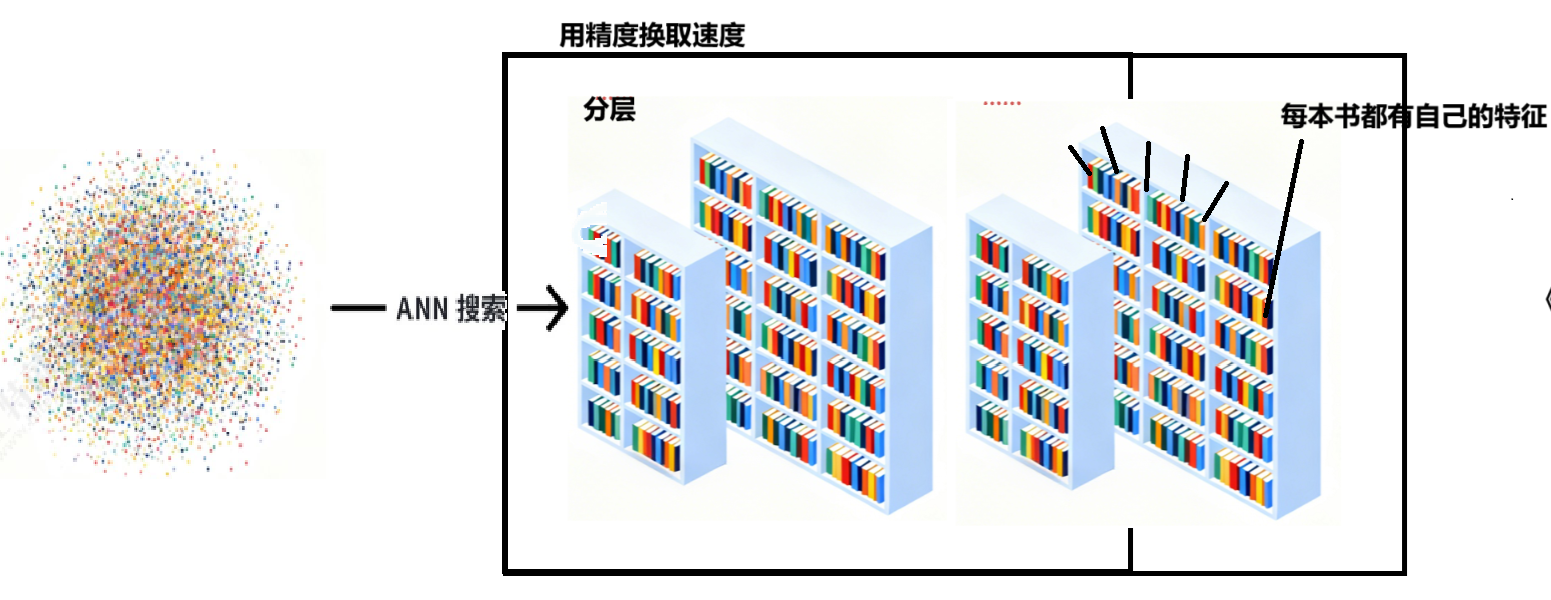
ANN如何工作的呢?就是将特征划分为几个空间域。使用近邻图的方式,主流索引方式就是HNSW(分层导航小世界),来通过一层层的入口节点,进入下一层空间域,因为已经提前划分好空间域了根据向量相似度, 所以查找不了几层就找到了。
同时,向量数据库底层使用高度优化的库来进行向量运算。如 FAISS 向量数据库,它是 Facebook AI 研究院开发的⼀种高效的相似性搜索和聚类的库。它能够快速处理⼤规模数据,并且支持在高维空间中进行相似性搜索。这些库充分利用了 CPU 的 SIMD 指令集和 GPU 的并行计算能力,让大规模的向量计算速度极快。简单来说,就是⼀个指令能够同时处理多个数据。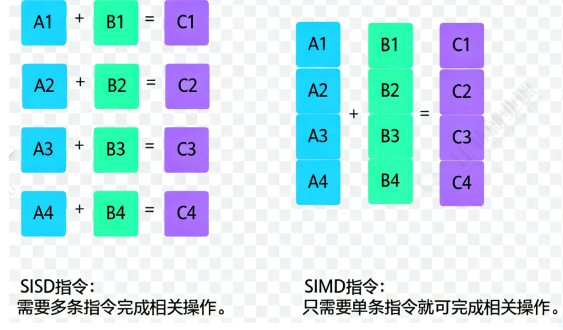
向量数据库不仅有专门的索引,还提供了完整的数据管理功能,CRUD 操作,元数据过滤,可扩展和分布式,集成方便。
LangChain 框架则通过与这些向量数据库集成,让开发者无需手动处理向量生成、存储和比价的复杂性,只需关注业务逻辑本身,极大地提高了开发效率和应用性能。
使用向量存储主要有两种方式,一是我们将使用 LangChain 的 InMemoryVectorStore 来实现向量的内存存储。二是通过三方的向量数据库来完成向量存储
🐸LangChain提供内存级别的向量存储
我们主要来根据这个类InMemoryVectorStore,来完成向量存储。
如何初始化一个向量数据库
# 向量数据库初始化
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-2-preview") # 定义嵌⼊模型
vector_store = InMemoryVectorStore(embeddings)
初始化完毕,我们需要向向量数据库添加文档
# 2.添加⽂档
# 要注意的是,该⽅法会为添加的⽂档编排索引,索引列表随着该⽅法返回。
# 2.1.定义文本加载器,这里还是加载md格式的文本
loader = UnstructuredMarkdownLoader(
"MarkDown/脚手架级微服务租房平台Q&A.md",
)
documents = loader.load()
# 2.2 文本拆分,拆分为一个个splits
textsplitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400, # 每个块的大小(按token来分)
chunk_overlap=20, # 设定⽬标:块之间的重叠⼤⼩->目的,为了保证语义的完整性
)
splits = textsplitter.split_documents(documents)
# 2.3 将切分好的splits添加->vectorstore
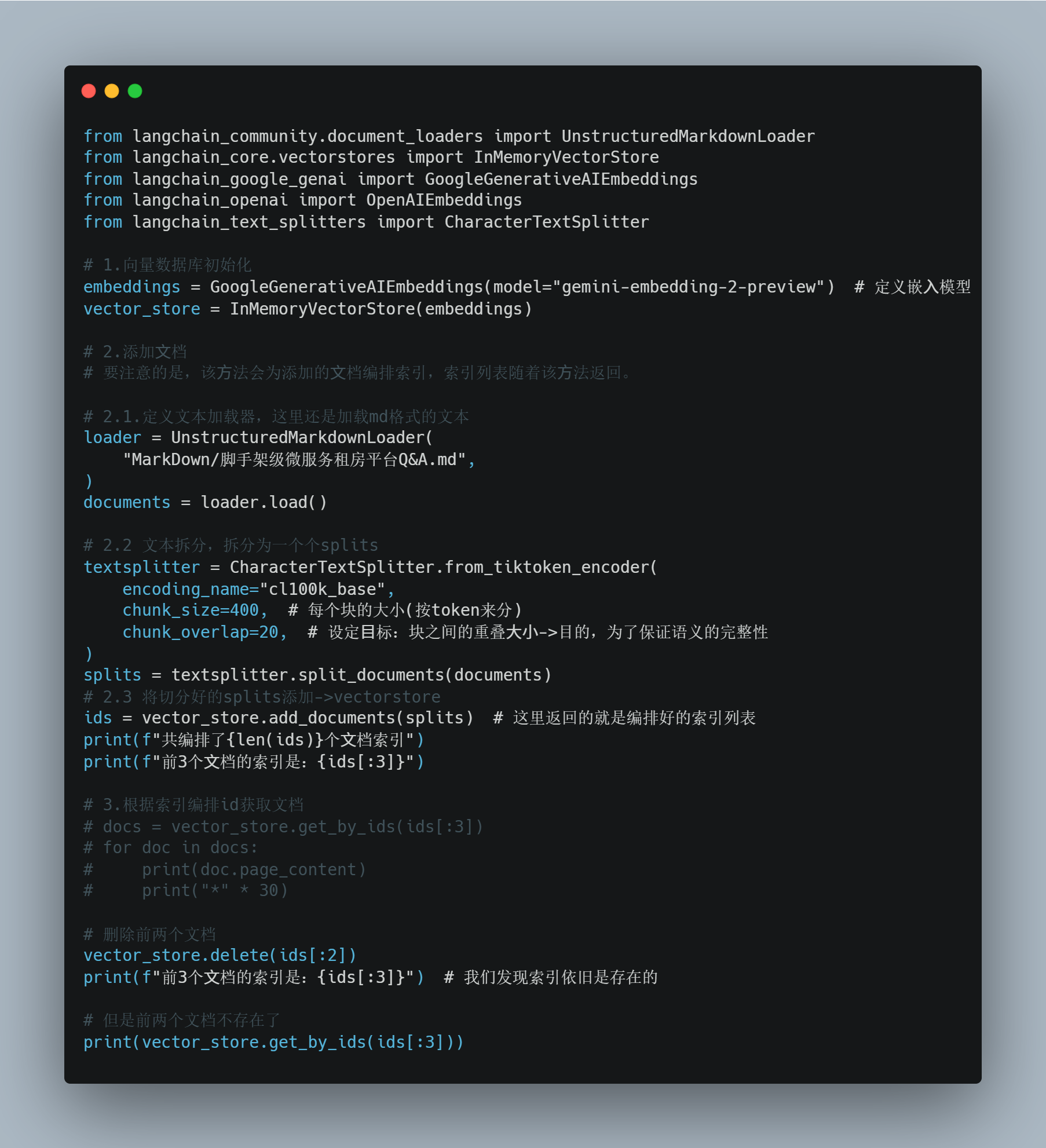
ids = vector_store.add_documents(splits) # 这里返回的就是编排好的索引列表
print(f"共编排了{len(ids)}个⽂档索引")
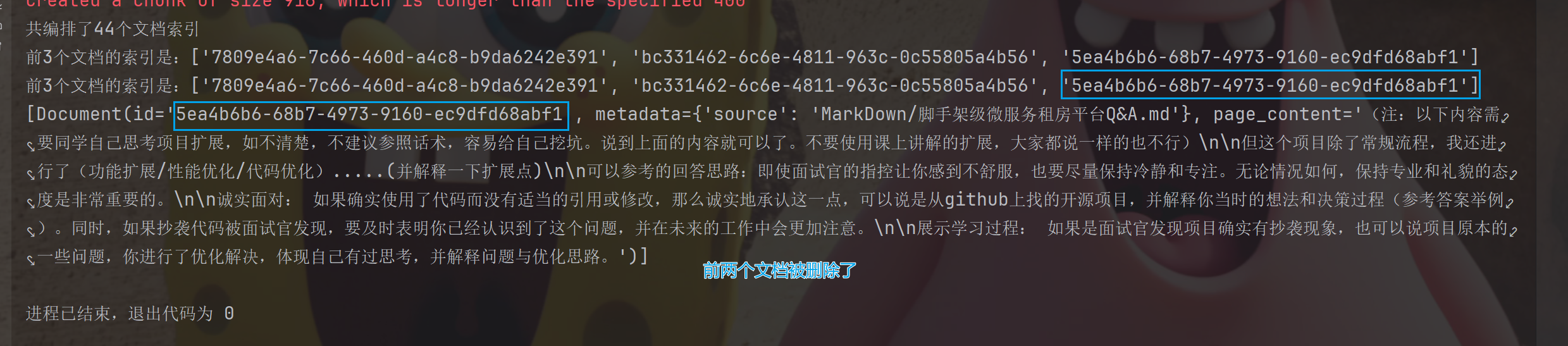
print(f"前3个⽂档的索引是:{ids[:3]}")
有了索引,获取文档使用 get_by_ids 方法,通过索引列表获取对应的文档列表。
# 3.根据索引编排id获取文档
docs = vector_store.get_by_ids(ids[:3])
for doc in docs:
print(doc.page_content)
print("*" * 30)同时我们已经可以删除文档。
完整
向量数据库的检索能力,如果我们传入⼀个查询,向量存储将嵌入该查询,在所有嵌入的文档中执行相似性搜索,并返回最相似的文档。如何根据相似性搜索的?欧氏距离/余弦相似度。
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的⽂档,并将它们作为⽂档列表返
回。这可以使用 similarity_search 方法来实现
ans_dos = vector_store.similarity_search(
query="你做的为啥和上个同学类似?", # 要查询的内容
k=2, # 查找到要返回的文档个数
)
for doc in ans_dos:
print(doc.page_content)
print("*" * 30)
这样,我们不就可以构建自已的知识库了吗??我们以后完全可以在内部构建一个向量数据库,方便AI快速查找,提高整个系统的并发能力
可以看见,搜索出来的内容,是较为符合我们的预取
此时我们可以将 “找到的最相关内容” 和我们 “提出的问题” ⼀起交给LLM 来生成答案,这便能极大地提高答案的准确性和时效性。以上流程,叫做检索增强生成 Retrieval-Augmented Generation, RAG,这是当前大语言模型应用的核心模式。
虽然向量数据库实现了搜索算法,来有效地搜索所有嵌入的文档以找到最相似的文档。但现实场景中,我们还希望通过先根据元数据进行过滤,来帮助缩小搜索范围。例如从特定来源或日期范围检索文档。
这次,我们以元数据的source来作为过滤,只有source匹配到"MarkDown/脚手架级微服务租房平台Q&A.md"才能成功匹配到
# 5.元数据过滤
def _filter_func(dos: Document) -> bool:
return dos.metadata.get("source") == "***"
ans_dos = vector_store.similarity_search(
query="你做的为啥和上个同学类似?", # 要查询的内容
k=2, # 查找到要返回的文档个数
filter=_filter_func
)
# 元数据过滤
for doc in ans_dos:
print(doc.page_content)
print("*" * 30)
我们将过滤条件改为:

我们也可以自定义过滤条件,来筛选最终过滤出来的文档,这个过程就叫做元数据过滤
🐸Redis 向量存储
RediSearch 是 Redis 官方提供的⼀款高性能【搜索】与【全文索引】引擎模块。它基于 Redis 构建,使用户能够直接在 Redis 数据库中执行复杂的【搜索】和【分词查询】,无需额外引入外部搜索引擎。RediSearch 特别适用于轻量级、响应速度要求较高的分词搜索场景。
RediSearch由几部分构成,分别为索引(Index), Index Fields(索引字段),metadata schema等Field字段。如图:
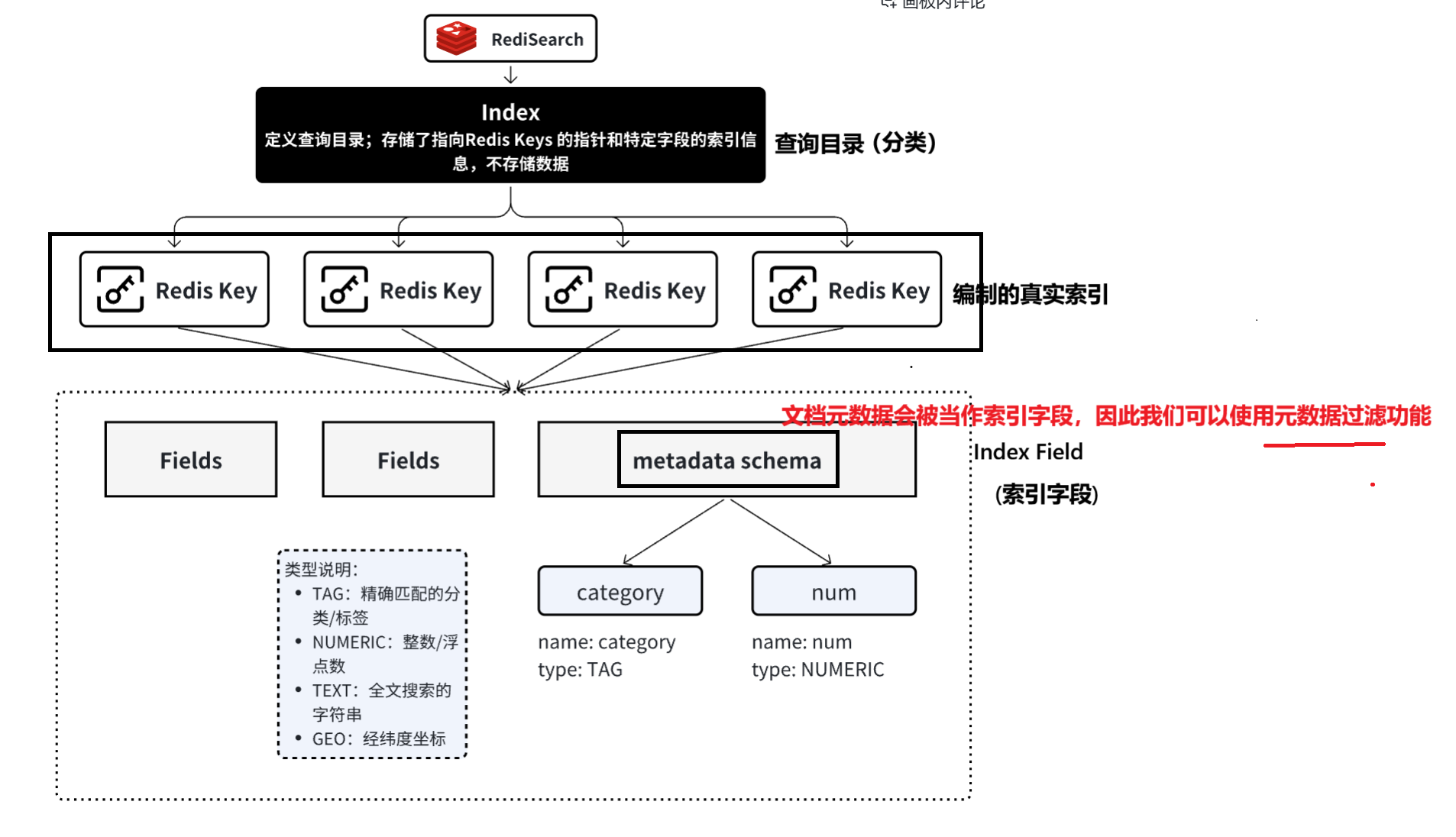
Index它本身不存储数据,而是存储了指向其他 Redis Keys 的指针,和这些 Keys 中特定字段的索引信息。相当于一个查询目录,它包含了每一个Redis key的位置,RedisKey中就存储的一个个真是的索引ids,
Index Fields(索引字段) 是创建索引时,明确指定的那些需要被索引的字段。它们定义了索引的“结构”或“蓝图”,可以把它想象成在⼀本书后面制作索引页(比如人名索引、主题索引)。我们不会把书中的每⼀个字都做到索引里,而是只选择那些重要的关键词(字段),并记录下它们出现的页码(文档ID)。这里的“关键词”就是 Index Fields。
在 RediSearch 中,索引字段是有特定的类型:就像蓝色框所示
metadata schema 则用来描述元数据的结构声明。这里的元数据是指我们将来要嵌入文档的元数据。因为对于文档元数据来说,它在存入Redis 后,就被定义成了索引字段。对于⽂档元数据来说,里面存放的就是⼀些文档属性值,如 source 表示文档来源。我们还可以⼿动加⼊其他元数据,这需要设置每个字段的声明: name 表示字段名, type 表示字段类型。这也就是为什么我们可以使用元数据来充当过滤条件的原因。
使用redis向量数据库之前,我们需要先启动redis服务器,并且保证我们Python中有redis客户端。
下面我们基于LangChain的RedisVectorStore这个类,来完成文档->向量的增删查改
需要注意,我们的redis服务器需要支持redis-8.0以上版本,所以这里直接用docker容器来镜像一个最新的redis版本出来。
使用RedisVectorStore初始化:
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_redis import RedisVectorStore, RedisConfig
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-2-preview")
config = RedisConfig(
index_name="qa",
redis_url="redis://192.168.174.128:6379",
# 添加两个索引字段
metadata_schema=[
{"name": "category", "type": "tag"}, # 索引字段
{"name": "num", "type": "numeric"}, # 索引字段
]
)
redis_vector_store = RedisVectorStore(
embeddings,
config=config,
)需要注意元数据字段的 schema。设置该字段对于将来的元数据过滤有帮助
我们可以根据 Index Name 查询其下的所有的 Index Fields
需要注意这个命令需要redis8.0以上
rvl index info -i qa --host #your redis ip --port 6379添加文档
我们可以使用 add_documents 方法,向向量库中去添加文档。这次我们可以给被分割的文档添加相关的元数据。
# 2.加载器
loader = UnstructuredMarkdownLoader(
"MarkDown/脚手架级微服务租房平台Q&A.md",
)
documents = loader.load()
# 3.文本拆分,拆分为一个个splits
textsplitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=400, # 每个块的大小(按token来分)
chunk_overlap=20, # 设定⽬标:块之间的重叠⼤⼩->目的,为了保证语义的完整性
)
splits = textsplitter.split_documents(documents)
# 4.为文档添加元数据
for i, doc in enumerate(splits, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = ""
# 看一第一个文档是否加进元数据
print(splits[0])
# 5.文档添加进向量数据库
ids = redis_vector_store.add_documents(splits)
print(f"共编排了{len(ids)}个文档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")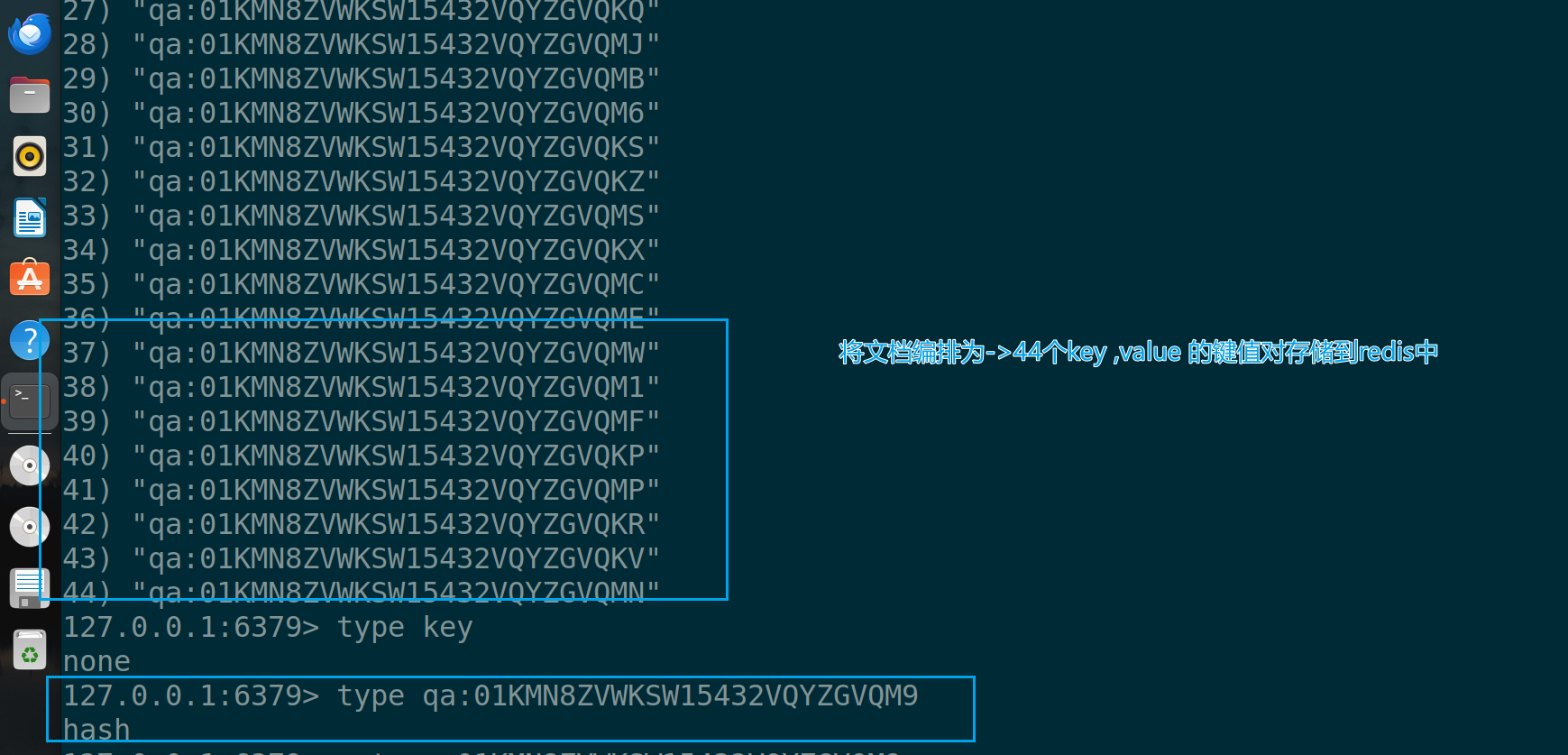

根据编排索引,查询文档
search_doc = redis_vector_store.get_by_ids(ids)
for doc in search_doc[:3]:
print("*" * 30)
print(doc.page_content)

使用 delete 方法,删除传入索引列表对应的文档列表。
# 7.删除向量数据库内容
# 删除指定的索引编排
redis_vector_store.delete(ids)
# 或者
# redis_vector_store.index.drop_keys(ids)
# 删除所有的索引编排
redis_vector_store.index.delete(drop=True)
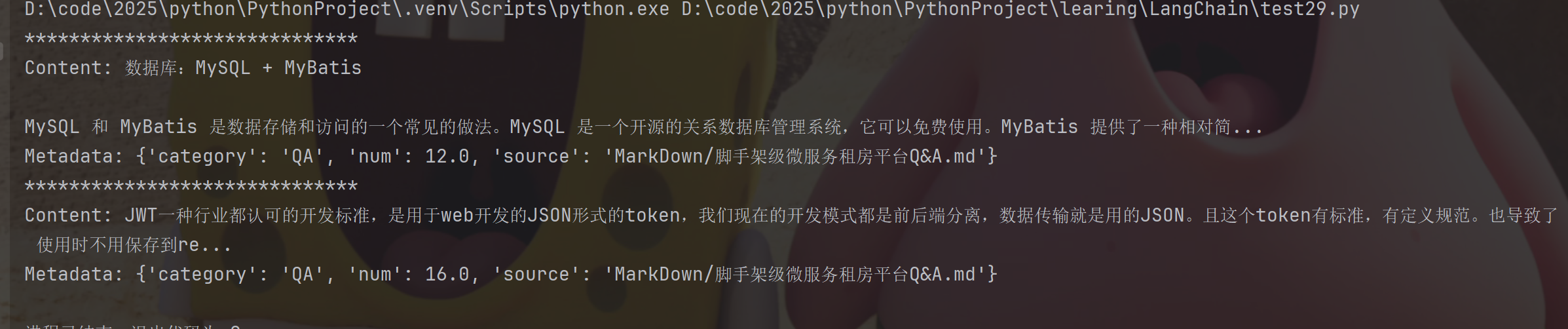
下面我们同样,在redis向量数据库中查找相似性搜索的结果
search_docs = redis_vector_store.similarity_search(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)
除了上面的 similarity_search 方法,其实还提供了向量搜索方法,比如根据查询语句搜索,并返回相似分值
search_docs = redis_vector_store.similarity_search_with_score(query="数据库表怎么设计的?", k=2)
for doc, score in search_docs:
print("*" * 30)
print(f"分数:{score}")
print(doc)
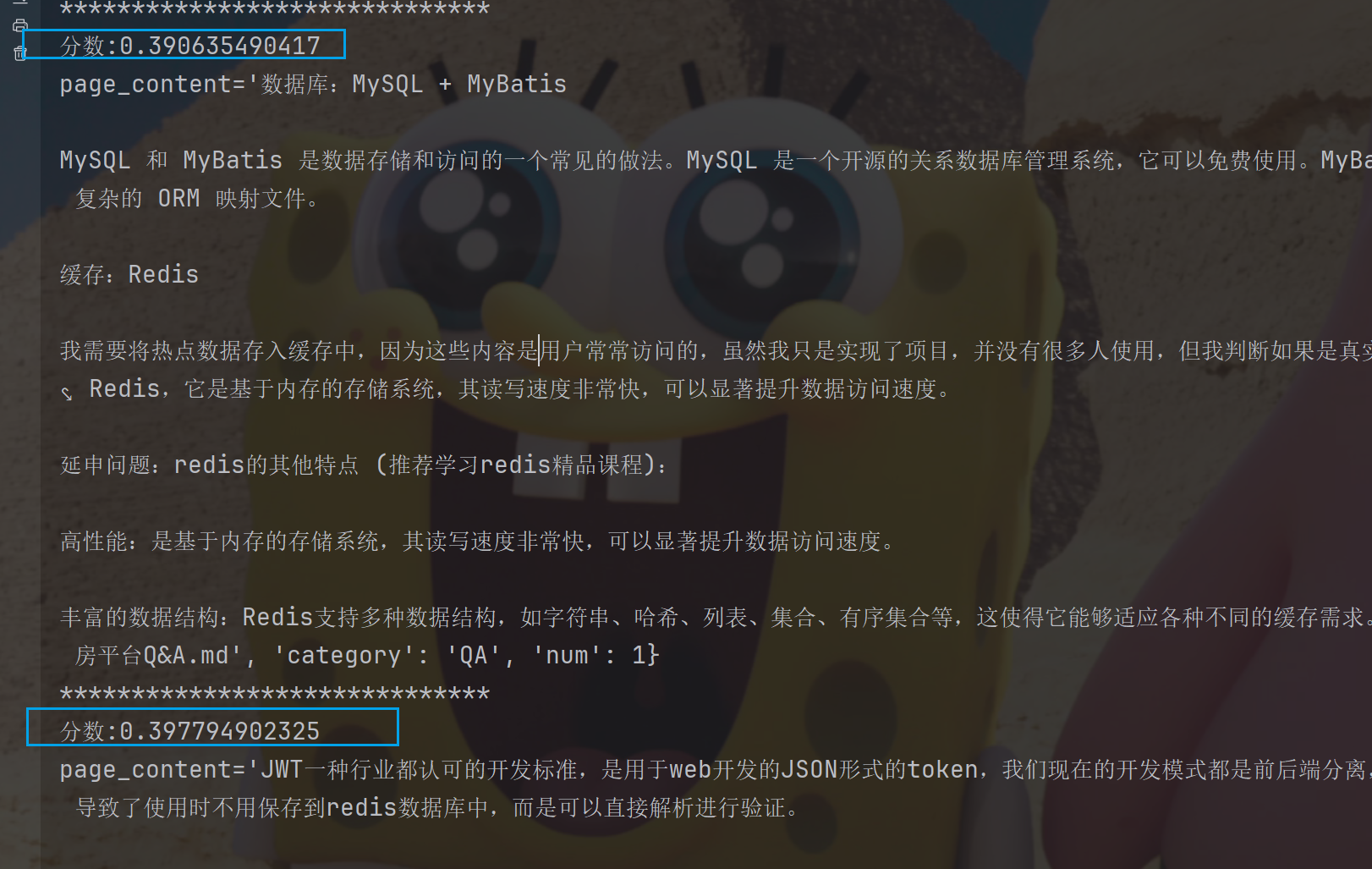
同时我们可以在搜索之前, 使用索引编排的字段进行先过滤,使用元数据过滤
filter_func = (Tag("category") == "QA") & (Num("num") > 13)
search_docs = redis_vector_store.similarity_search_with_score(query="数据库表怎么设计的?", k=2, filter=filter_func)
for doc, score in search_docs:
print("*" * 30)
print(f"分数:{score}")
print(doc)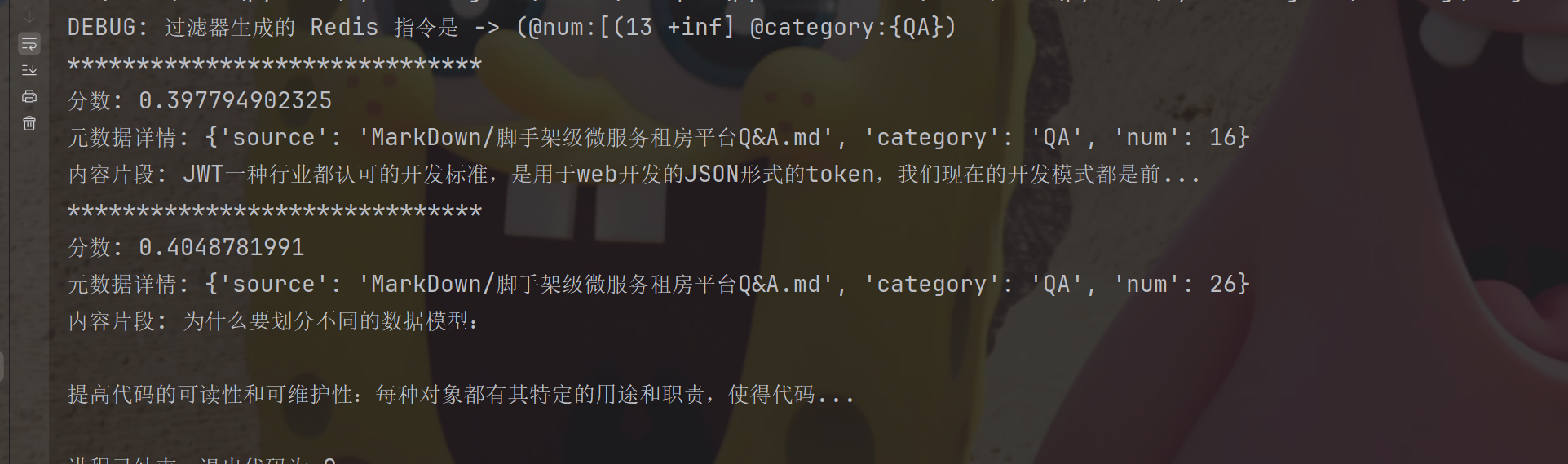 我们同时也可以使用MMR(最大边际相关性搜索)来搜索。
我们同时也可以使用MMR(最大边际相关性搜索)来搜索。
search_docs = redis_vector_store.max_marginal_relevance_search(query="数据库表怎么设计的?",
k=2,
fetch_k=10,
filter=filter_func)
for doc, score in search_docs:
print("*" * 30)
print(f"内容片段: {doc.page_content[:100]}...")
我们需要注意⼀个参数 fetch_k , fetch_k 是 MMR 算法第⼀步中,从向量库中初步获取的候选文档数量,然后,MMR 算法会在这个较小的候选池(⼤小为 fetch_k )中运行。它不再只考虑与查询的相似度,还会考虑候选文档之间的多样性。它会从这 fetch_k 个文档中,挑选出既与查询相关,彼此之间又不太相似的 k 个文档作为最终结果。

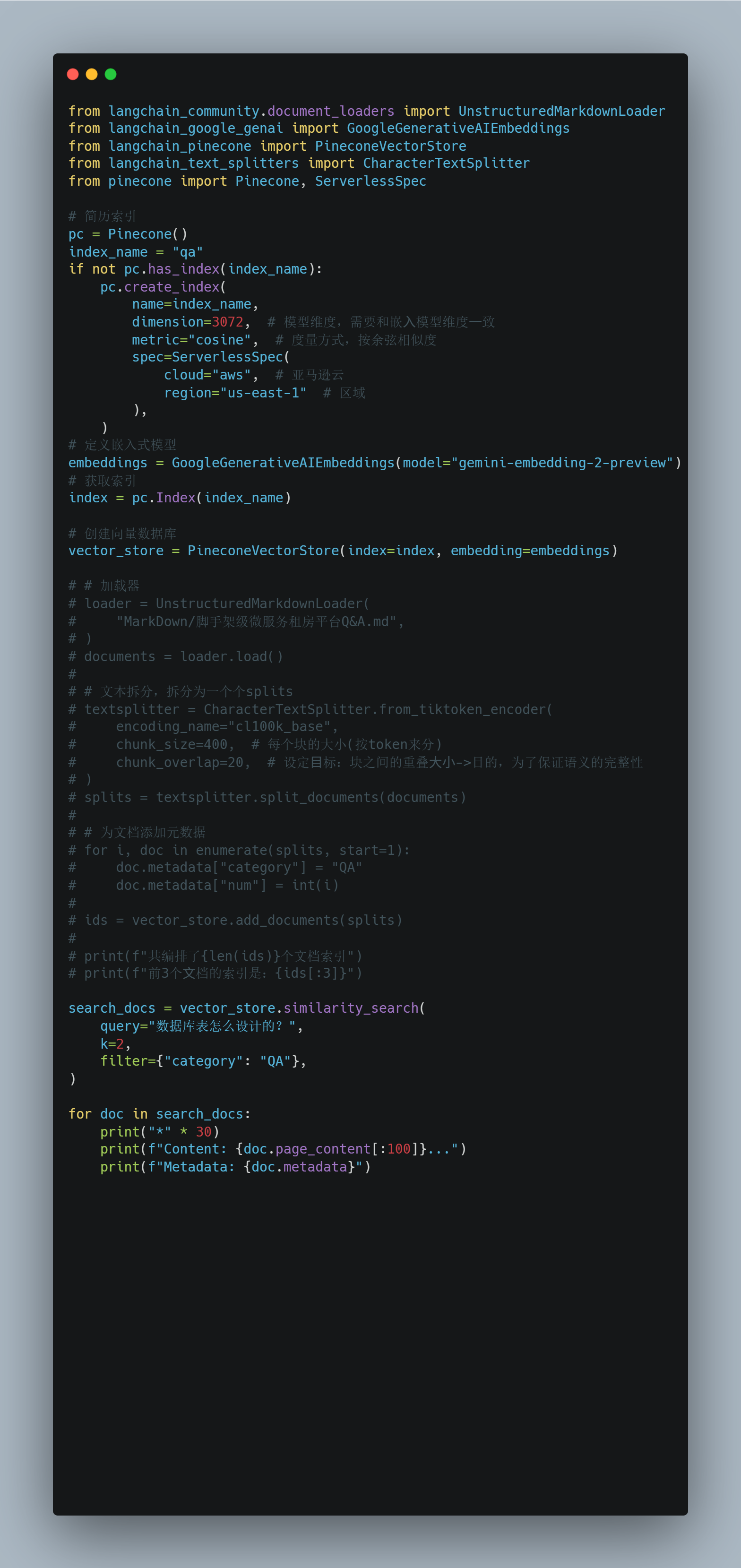
🐸Pinecone向量存储
同时,我们也可以使用Pinecone 向量存储,Pinecone 是为机器学习应用量身打造的生产级向量数据库服务,使用于高维向量数据的高效存储、索引与查询。
完整代码:
结果:
🐼检索器
其实,我们上面在使用LangChain为向量数据库的检索方法中,就可以完成检索了。不过检索器是一个单独的组件,是检索系统中的⼀个核心组件,它接收来自用户接口的查询(Query),检索出包含查询关键词的候选文档集合。
检索系统已成为人工智能应用(例如 RAG)的重要组成部分。且存在多种【不同类型】的检索系统,包括:关系数据库,词法搜索索引,向量数据库,,正是因为有这么多检索系统,LangChain 提供了⼀个统⼀的接口来与不同类型的检索系统进行交互。
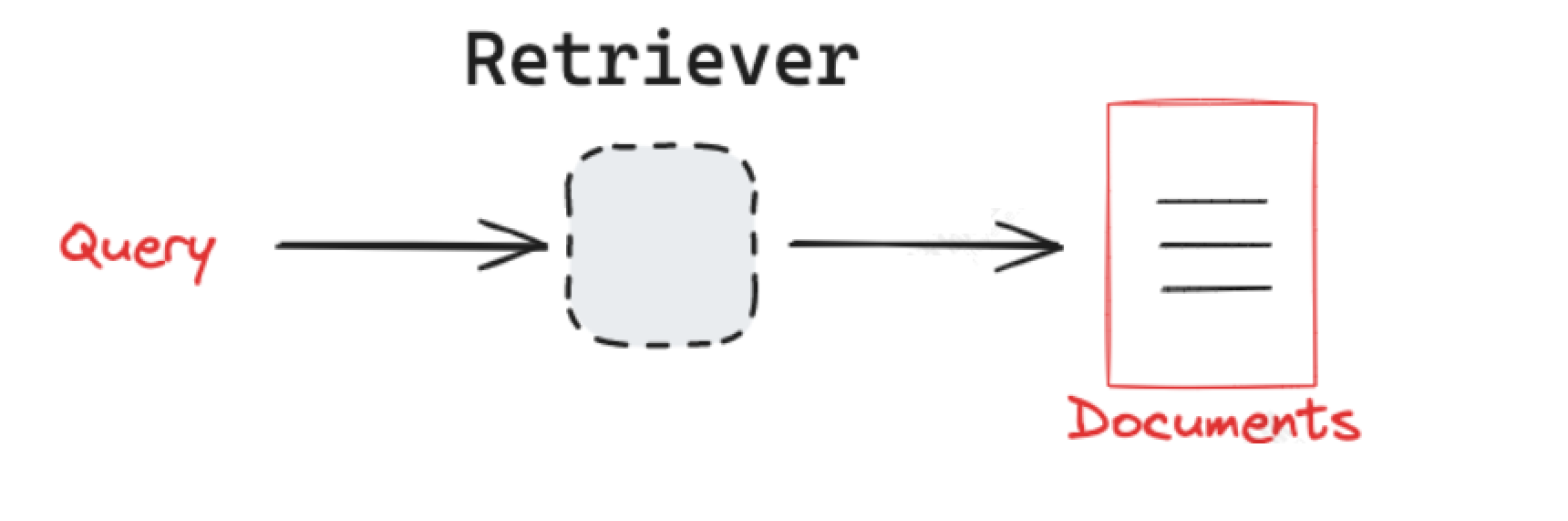
比如我们使用向量数据库作为检索器
LangChain 检索器是⼀个 Runnable 的对象 ,它是 LangChain 组件的标准接口。这意味着它有⼀些常用方法,包括 invoke ,用于与其交互。默认情况下,向量存储检索器使用相似性搜索。
RAG 是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌⼊模型在知识库中进行语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)