从零构建大语言模型分词器从零实现 — 从原始文本到 Token ID
本篇导读
在博客 #03 中,我们理解了为什么神经网络需要"把文字变成数字"——离散的文本必须先转为连续的向量。但向量化不是一步到位的,中间还要经过一个关键的桥梁:Token ID。
学完本篇你将能够:
- 用 Python 正则表达式从零实现一个分词器
- 理解词汇表(vocabulary)的本质和构建过程
- 编写一个完整的
SimpleTokenizerV1类,包含encode和decode方法 - 看清简单分词器的局限性——为什么它处理不了未知词
1.分词
分词在 LLM 数据流水线中的位置
分词(Tokenization 是把输入文本拆分成独立 token 的过程,这是为 LLM 创建嵌入的必要预处理步骤。这些 token 要么是单独的词,要么是特殊字符(包括标点符号)。
本节涵盖的文本处理步骤在 LLM 上下文中的视图。我们把输入文本拆分为独立的 token——它们要么是词、要么是标点等特殊字符。后续小节会把文本转换为 token ID 并创建 token 嵌入。
整个数据流水线是这样的:
原始文本 ──[分词]──▶ Token 列表 ──[查词汇表]──▶ Token ID 列表 ──[嵌入层]──▶ 向量
↑ ↑ ↑ ↑
本节起点 本节终点 下一节内容 第 2.7 节内容
训练文本:Edith Wharton 的短篇小说
我们将使用 Edith Wharton 的短篇小说《The Verdict》作为分词的练习文本。这篇小说已进入公有领域,可以合法用于 LLM 训练任务。原文可从 Wikisource 获取,作者已将其保存为 the-verdict.txt 文件。
📌 原书 Listing 2.1:将短篇小说读入 Python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
输出:
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fello
我们的目标是把这 20,479 个字符的短篇小说分词为独立的词和特殊字符,作为后续章节嵌入向量的输入。
💡 关于文本规模:实际 LLM 训练中通常处理数百万篇文章和数十万本书——数 GB 的文本。但出于教学目的,使用一本书这样的小样本就足以阐明文本处理的核心思想,并能在消费级硬件上合理时间内运行。
分词的三步演进
我们用 Python 的 re 正则表达式库逐步实现分词。注意:你不需要专门记忆任何正则语法——本章末尾会切换到现成的分词器(BPE)。
第一步:按空白字符拆分
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
输出:
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
问题:词和标点仍粘在一起('Hello,'、'world.')。
💡 为什么不把所有文本转为小写? 大小写帮助 LLM 区分专有名词和普通名词、理解句子结构、生成正确大小写的文本。所以我们保留原始大小写。
第二步:把标点拆开 + 过滤空白
result = re.split(r'([,.]|\s)', text)
result = [item for item in result if item.strip()]
print(result)
输出:
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
💡 要不要保留空白? 移除空白能减少内存和计算开销。但如果训练对文本结构敏感的模型(例如 Python 代码,对缩进敏感),保留空白就有用。这里我们为简洁起见移除。
第三步:处理所有特殊字符(包括双破折号 --)
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
输出:
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
完美——10 个独立 token。

图 1:分词的三步演进。从混杂着标点的原始文本,逐步过渡到干净的 Token 列表。
📌 我们目前实现的分词方案能把文本拆分为独立的词和标点字符。在此例中,示例文本被拆分为 10 个独立 token。
应用到全文
把这套规则用在《The Verdict》全文上:
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(len(preprocessed))
输出 4649 —— 全文拆分出 4,649 个 token(不含空白)。
打印前几个看看效果:
print(preprocessed[:10])
# ['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', ...]
每个词和特殊字符都被整齐地分开了。
2.Token → ID 转换
为什么还要再转一次?
上一节我们得到了 token 列表(Python 字符串)。但神经网络处理的是数字,不是字符串——所以还需要一步:把每个 token 映射成一个唯一的整数 ID。
这个映射关系存储在一个叫**词汇表(vocabulary)**的字典里。
词汇表构建过程
📌 原书 Figure 2.6 说明:我们通过对训练数据集的全部文本分词来构建词汇表。这些独立 token 按字母顺序排列、去除重复,然后聚合到一个词汇表中——它定义了从每个唯一 token 到唯一整数值的映射。
整个流程分三步:

图 2:词汇表的三步构建过程。完整训练文本经过分词、去重排序,最终每个唯一 token 获得一个整数 ID。
代码实现
第一步:得到所有唯一 token 并按字母排序
all_words = sorted(list(set(preprocessed)))
vocab_size = len(all_words)
print(vocab_size) # 1159
《The Verdict》的词汇表大小是 1,159 个唯一 token。
第二步:用字典推导式构建词汇表
📌创建词汇表
vocab = {token: integer for integer, token in enumerate(all_words)}
# 打印前 51 个条目看看
for i, item in enumerate(vocab.items()):
print(item)
if i > 50:
break
输出:
('!', 0)
('"', 1)
("'", 2)
...
('Has', 49)
('He', 50)
字典里每个 token 都关联着一个唯一的整数标签。下一步就是用这个词汇表把新文本转成 token ID。
📌 原书 Figure 2.7 说明:从一个新的文本样本开始,我们对它分词,再用词汇表把文本 token 转换为 token ID。词汇表从整个训练集构建,可以应用于训练集本身以及任何新的文本样本。
还需要反向映射
后面当我们想把 LLM 的输出(数字)转换回文本时,还需要一个反向词汇表——把 token ID 映射回对应的文本 token。
完整的 SimpleTokenizerV1 类
让我们实现一个完整的分词器类,包含:
encode方法:文本 → token ID 列表decode方法:token ID 列表 → 文本
📌 实现简单文本分词器
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab # 正向:token → ID
self.int_to_str = {i: s for s, i in vocab.items()} # 反向:ID → token
def encode(self, text): # 文本 → ID
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids): # ID → 文本
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) # 修复标点前的空格
return text
逐行解读:
__init__:接收一个词汇表字典,同时建立正向和反向映射。encode:复用第 2.2 节的分词逻辑,再查正向词汇表得到 ID 列表。decode:查反向词汇表得到 token,用空格拼接,最后用正则修复标点前的多余空格(例如把"Hello , world ."修复为"Hello, world.")。
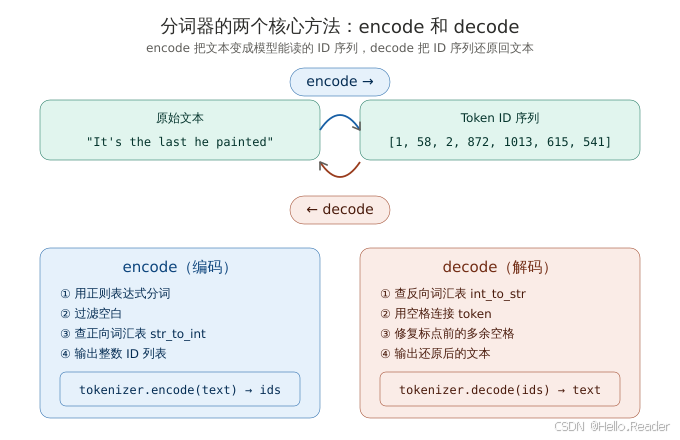
图 3:分词器的两个核心方法。encode 将文本转为 ID 序列,decode 反过来还原文本。两者依赖同一个词汇表的正向和反向映射。
分词器实现共享两个通用方法——encode 接收文本、拆分 token、通过词汇表转换为 ID;decode 接收 ID、转换回 token、再连接成自然文本。
实测分词器
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
输出 ID 序列:
[1, 58, 2, 872, 1013, 615, 541, 763, 5, 1155, 608, 5, 1, 69, 7, 39, 873, 1136, ...]
再用 decode 还原:
print(tokenizer.decode(ids))
# '" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable...'
完美还原——证明 encode 和 decode 是相互可逆的。
致命问题:未知词
到目前为止一切顺利。但试试一个不在训练集中的文本:
text = "Hello, do you like tea?"
tokenizer.encode(text)
执行结果:
KeyError: 'Hello'
问题在于:单词 “Hello” 没有在《The Verdict》中出现过,所以不在词汇表里。这恰恰说明了——LLM 训练需要大规模、多样化的训练集来扩展词汇表。
但即使训练集再大,永远会有从未见过的新词(人名、新造词、外语词等)。怎么彻底解决这个问题?这就是下一篇博客的主题。
3.本篇小结
| 概念 | 要点 |
|---|---|
| 分词(Tokenization) | 把连续文本拆分成独立的 token(词 + 标点) |
| 正则表达式分词 | 用 re.split 按空格、标点、双破折号拆分 |
| 词汇表(Vocabulary) | 训练数据中所有唯一 token → 整数 ID 的字典映射 |
encode 方法 |
文本 → 分词 → 查词汇表 → 整数 ID 列表 |
decode 方法 |
整数 ID 列表 → 反向查词汇表 → 拼接还原文本 |
| 致命局限 | 词汇表外的词(OOV)会导致 KeyError |
| 《The Verdict》数据 | 20,479 字符 → 4,649 token → 1,159 词汇表大小 |
4. 完整代码汇总
import re
# 1. 读入原始文本
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
# 2. 分词(第 2.2 节)
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(f"共 {len(preprocessed)} 个 token") # 4649
# 3. 构建词汇表(第 2.3 节)
all_words = sorted(list(set(preprocessed)))
vocab = {token: integer for integer, token in enumerate(all_words)}
print(f"词汇表大小: {len(vocab)}") # 1159
# 4. SimpleTokenizerV1 类
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i: s for s, i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
return [self.str_to_int[s] for s in preprocessed]
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
return re.sub(r'\s+([,.?!"()\'])', r'\1', text)
# 5. 测试
tokenizer = SimpleTokenizerV1(vocab)
sample = '"It\'s the last he painted, you know,"'
ids = tokenizer.encode(sample)
print(f"编码: {ids}")
print(f"解码: {tokenizer.decode(ids)}")
5.预习思考
- 为什么
decode方法需要re.sub(r'\s+([,.?!"()\'])', r'\1', text)这一步?如果去掉会怎样? - 如果训练文本里有"Hello",但有一个新词"Hi",词汇表无法处理。除了"扩大训练集",有没有更巧妙的方法?
- 为什么 GPT-2 的词汇表大小是 50,257,远大于我们这里的 1,159?这背后用到了什么不同的分词策略?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)