网心技术 | Agent Harness:决定 AI Agent 真实上限的隐藏变量
过去两年,基础模型的能力飞速提升:上下文窗口更长,推理更稳定,代码能力更强。但一个更值得关注的现象是——同一个模型,在不同团队手中表现差异巨大...
一个正在被验证的判断
有的团队构建出能持续运行数小时的 Agent 系统,稳定完成跨文件重构、多步骤研究、自动化测试与部署;另一些团队用同样的模型,却频繁遭遇任务中断、上下文失序、token 成本失控、错误无法定位。他们能感受到模型"很聪明",但就是无法让这种聪明转化为可靠的产出。
差异不在模型,差异在模型之外。
我们把这个"模型之外"的东西叫做 Agent Harness——围绕模型运行的外部控制栈。它负责工具调用、状态管理、异常恢复、权限控制、上下文编排和任务调度。

Harness 这个词来自工程领域,原意是"承载器"或"支架",用来形容那些让核心部件得以安全、稳定运行的外部结构。
我们的核心判断是:基础模型能力决定 Agent 的理论上限,但 Harness 决定这个上限在现实中能被逼近到什么程度。
这并非理论推演。事实上,无论是工业界的实践,还是学界的研究都指向同一件事:Agent 的竞争已经从"谁的模型更强"进入"谁的系统工程更好"。
这篇文章将展开这个判断。我们会解释 Harness 解决什么问题、包含哪些能力层、行业头部玩家各自选择了什么路线,以及它对你的 Agent 实践意味着什么。
为什么模型强不等于 Agent 强
✅ 认知能力与执行能力的错位
大模型经过海量数据预训练与后训练之后,擅长语言理解、模式归纳、多步推理和任务分解。这些是强大的认知能力。但"能推理"和"能可靠地做事"之间隔着一整层工程问题。
现实任务要求模型持续与外部环境交互——读写文件、调用 API、执行命令、操作数据库——而交互本身包含大量边界条件:
-
工具调用的参数合不合法?返回值格式变了怎么办?
-
任务跑到一半网络断了,能从断点恢复吗?还是只能从头再来?
-
Agent 有写文件、执行 shell 的能力,谁来确保它不会误删生产数据?
-
对话越来越长,模型的注意力在衰减,token 成本在攀升,怎么控制?
-
多个子任务同时跑,上下文会不会互相污染?一个子任务的错误会不会级联扩散?
这些问题没有一个能靠"模型升级"自动解决。它们是运行治理问题,不是认知能力问题。你可以把模型从 Haiku 换成 Opus,推理变强了,但如果你的工具调用没有参数校验,上下文没有压缩策略,任务没有持久化机制,系统照样在多轮运行后崩溃失败。
✅ 学术共识正在形成
《Natural-Language Agent Harnesses》这篇论文把这一点说得很直接:现代 Agent 的成败越来越取决于 surrounding harness——围绕模型调用的控制栈。多步推理、工具使用、记忆、委派、停止条件,全部超出了单次模型调用的边界。论文进一步提出,应该把 Harness 本身作为一等研究对象,用可执行的自然语言来表示、比较和改进它。
Meta-Harness 团队的实验也从另一个角度证明了这一点:在固定同一个模型的条件下,仅仅通过优化 Harness(system prompts、tool definitions、completion policy、context management),就能把任务成功率提升数十个百分点。这意味着模型的"已有能力"中,有很大一部分在之前被低效的 Harness 浪费了。
没有 Harness,模型就只是一个生成器。有了 Harness,模型才成为一个系统。
✅ 缺乏 Harness 时的典型失败模式
在我们的实践中,以及在行业公开案例中,缺乏 Harness 工程能力时最常出现的失败模式有五类:
⚠︎ 状态丢失。任务运行到中途因服务波动或超时而完全中断,没有 checkpoint,只能从头开始。对于一个需要 30 分钟才能完成的多步骤任务,这意味着前面的工作全部白费——而且重跑时很可能在不同的步骤再次中断。
⚠︎ 工具失控。工具调用参数不合法或越权,但没有中间层拦截。Agent 尝试删除一个不该删的文件,或者向一个错误的 API 端点发送了请求,而系统没有任何防线阻止它。更隐蔽的情况是:工具调用在格式上合法,但在语义上错误——比如把测试环境的配置写入了生产环境。
⚠︎ 上下文膨胀。随着对话轮次增加,上下文持续膨胀但没有压缩机制。token 成本不断升高是表面问题;更深层的问题是模型的注意力被大量无关信息稀释,导致后续推理质量下降。这个现象被称为 Context Rot(上下文衰减)——上下文越长,模型的精度和召回率越低。该概念最早由社区讨论提出,Chroma 于 2025 年 7 月发布了实证研究,Anthropic 在其 Context Engineering 博文中做了系统阐述。
⚠︎ 不可诊断。日志缺失或结构混乱,使失败的根因无法被定位。你知道任务失败了,但不知道是模型的推理错误、工具的执行错误、还是上下文被污染了。没有诊断能力,就无法做有针对性的改进,只能反复试错。
⚠︎ 不可迁移。控制逻辑散落于 prompt 和脚本中,换任务或换模型时几乎无法复用。每做一个新项目都要从头搭一遍,之前积累的经验无法形成系统资产。
这五类失败都有一个共同特征:它们不会随模型升级自动消失。因为它们的本质是系统工程缺陷,不是模型能力不足。
Harness 的五层能力栈
从工程视角看,一个生产级 Harness 至少覆盖五层职责。理解这五层,是设计、评估和改进任何 Agent 系统的基础。
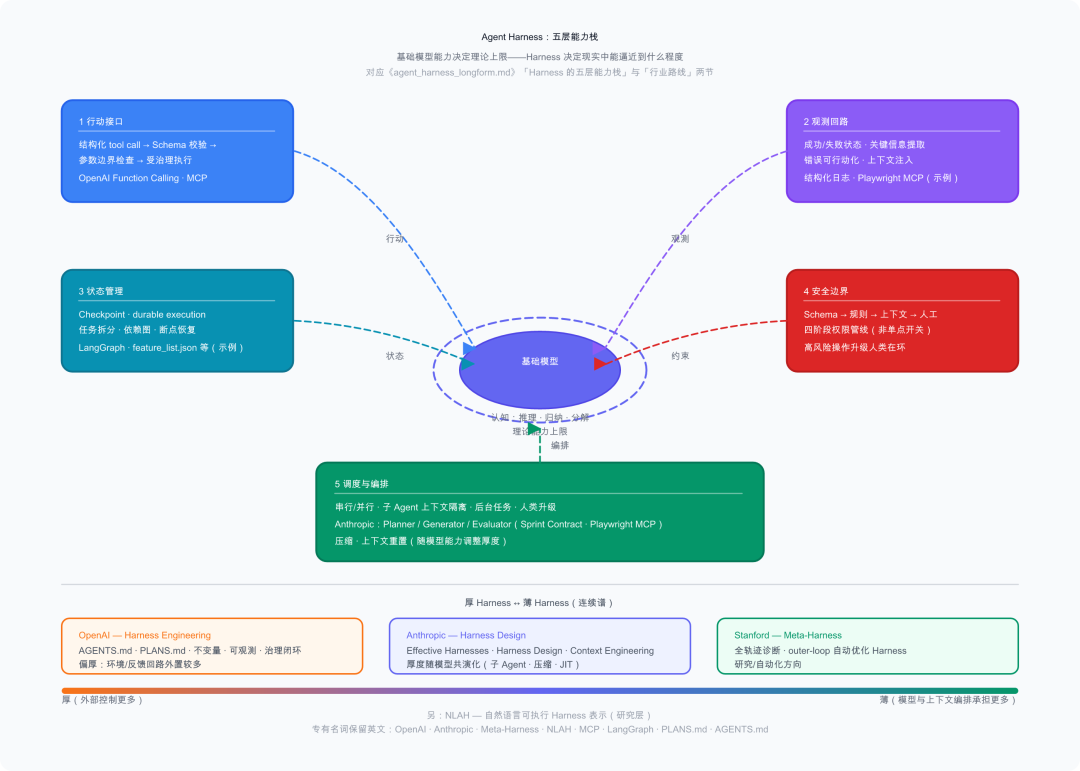
✅ 第一层:行动接口
把模型输出转化为结构化、可验证的操作。这是 Agent 接触外部世界的唯一通道。
工具调用的基本流程已经相对标准化:模型输出结构化的 tool call,系统执行工具,再将结果回写给模型(OpenAI 的 function calling 为此提供了接口级标准)。但生产级系统的真正难点不在"结构化调用"这一动作本身,而在其外围治理。
工具 schema 是否稳定?参数边界条件是否被检查?如果工具返回了异常格式的结果,系统是直接把它塞回上下文,还是先做清洗和压缩?如果同一类工具有多个版本,系统如何管理版本兼容性?
真正成熟的行动接口不是"模型自由调度的黑箱",而是在工具调用前后插入校验、记录与增强逻辑。工具调用前检查参数合法性,工具调用后检查返回值完整性,每一次调用都写入结构化日志。这样,工具系统才从一个"能用"的接口变成一个"受治理"的能力层。
✅ 第二层:观测回路
把工具执行结果、环境状态、错误信息结构化地回传给模型。
模型不是在真空里推理。它需要持续看到外部世界的反馈,才能做出有效的下一步决策。观测回路的质量直接决定了模型推理的质量——如果回传的信息太少,模型会做出错误假设;如果太多,模型的注意力会被稀释。
一个好的观测回路要做三件事:第一,把工具执行的成功/失败状态明确传达;第二,把关键结果信息提取出来,而不是把原始输出(可能有几千行)全部塞回上下文;第三,把错误信息转化为模型可以理解和行动的格式,而不是一段晦涩的 stack trace。
✅ 第三层:状态管理
为多轮、长时间运行维护上下文连续性。
短任务可以在一轮对话中完成,但生产级 Agent 经常面对需要数十步甚至数百步的任务。在这个尺度上,"对话"本身变得脆弱——网络超时、服务重启、模型 API 限流,任何一个波动都可能中断执行。
状态管理层的核心职责是:让系统能够在中断后恢复,而不是从头开始。LangGraph 的 durable execution 设计是这一层的典型代表。它通过 checkpoint 在每一步执行后保存状态,并允许系统在中断后从上次状态继续。这一设计体现了一个关键原则:系统可靠性不来自消灭错误,而来自把错误纳入可治理的生命周期。
除了断点恢复,状态管理还包括任务拆分与依赖图维护。当一个大任务被分解为多个子任务时,系统需要跟踪每个子任务的状态(待执行、执行中、已完成、已失败),维护它们之间的依赖关系,并在某个子任务失败时决定是重试、跳过还是回滚。这些逻辑不应该由模型在每一轮推理中重新推导——它们应该被外化为 Harness 的持久化结构。
✅ 第四层:安全边界
权限不是一个开关,而是一条多阶段管线。
Agent 一旦具备写文件、执行 shell、访问网络的能力,权限设计就从"辅助设置"变成系统生命线。问题不只是"禁止危险操作",而是如何让潜在危险的动作在到达执行层之前就被逐级过滤和缩减。
一种经过实践验证的设计是四阶段权限管线:
Schema 验证:工具调用的参数是否符合预定义的数据结构?
规则匹配:调用的命令模式是否命中已知的危险模式?(如 rm -rf、DROP TABLE、git push --force)
上下文评估:即使参数合法、模式不危险,在当前任务上下文中这个操作是否合理?
交互式确认:对于无法自动判定的高风险操作,升级到人类确认。
只有采用这种分阶段结构,系统才能在参数形状、命令模式、任务上下文与最终执行意图之间形成多层防线。单点开关式的权限设计——要么全开要么全关——在生产环境中是不可接受的。
✅ 第五层:调度与编排
组织串行、并行、子任务协作、后台执行和人工介入。
当任务足够复杂时,单个 Agent 循环不够。你需要子 Agent 来隔离上下文、并行工作、汇总结果。Anthropic 在构建其多 Agent 研究系统时发现,子 Agent 的价值不仅在于并行加速,更在于上下文经济学——每个子 Agent 在干净的上下文窗口中工作,不受其他子任务噪声的干扰,主 Agent 只需要接收压缩后的结果。
调度层还需要处理一些微妙的决策:什么时候应该串行执行(因为步骤之间有依赖);什么时候应该并行(因为子任务独立);什么时候应该把任务放到后台(因为它需要等待外部响应);什么时候应该中断自动执行并升级到人工审批(因为风险超过了自治阈值)。
这五层不是"附加功能"。它们是让 Agent 从"能回答问题"变成"能在环境中持续做事"的基础设施。缺少任何一层,系统都会在特定场景下暴露出脆弱性。
行业渐成共识,路线仍存分歧
过去几个月,行业头部玩家几乎同时发出了信号,说明 Harness 已经从"工程细节"上升为"战略议题"。但他们选择的表述方式和侧重点有明显差异,这些差异背后是对模型能力走向的不同判断。
✅ OpenAI:Harness Engineering——环境决定产出
OpenAI 2026 年 2 月发布的官方文章《Harness Engineering: Leveraging Codex in an Agent-First World》是行业第一篇系统阐述 Harness Engineering 概念的公司级文章。其核心主张非常明确:工程师的工作正在从"直接写代码"转向"设计环境、指定意图、构建反馈回路"。
文章的说服力来自他们自己的实践数据。OpenAI 内部的 Harness 团队用 Codex agent 在五个月内交付了一个内部产品——零行手写代码,约 100 万行 agent 生成代码,约 1500 个 PR,速度大约是传统开发的 10 倍。
但真正有价值的不是这些数字本身,而是他们在过程中踩过的坑和得到的教训。
教训一:早期进展比预期慢,问题不在模型而在环境。 他们最初以为模型能力足够强,结果却进展缓慢。当团队把精力从"让模型更聪明"转向"让环境更清晰"——投入到 AGENTS.md 文档、仓库知识库、架构约束、可观测系统和自动 review 上——之后,产出才真正起飞。这是 Harness 价值的最直接证明:同一个模型,换一套环境,表现完全不同。
教训二:给 agent 一张地图,而不是一本 1000 页的说明书。 他们发现,把所有信息塞进一个巨大的 AGENTS.md 文件是无效的。有效的做法是提供清晰的结构化指引——模块边界在哪里、数据流向是什么、核心不变量是什么——然后让 agent 自己在这个框架内探索细节。架构约束要执行不变量(invariants),而不是规定实现细节。
教训三:选择"无聊的技术"。 Agent 在使用稳定、文档充分、训练数据丰富的技术栈时表现最好。时髦但文档稀疏的新框架会导致 agent 频繁犯错。这对技术选型有直接影响:如果你的系统要大量依赖 agent 开发,技术栈的"agent 友好度"应该成为选型标准之一。
教训四:Harness 需要持续运行的治理机制。 Agent 生成的代码会累积"slop"——低质量模式、冗余抽象、不一致的命名。一开始靠人工清理,占每周 20% 时间。后来他们用后台 Codex 任务自动清理,把代码质量标准编码为可执行的规则。这说明 Harness 不只是启动时的一次性配置,而是一个需要持续运转的治理系统。
OpenAI 还在另一篇文章《A Practical Guide to Building Agents》中补充了更多落地建议:优先使用单 Agent 架构,只在确实需要时才引入多 Agent;用 guardrails 和 tool safeguards 构建安全层;把人类干预作为系统设计的一部分而非例外。
他们还通过 PLANS.md 机制展示了如何让 Agent 处理多小时级别的复杂问题——Agent 在执行前先生成结构化计划文档,在执行过程中持续更新计划状态,使得长任务变得可追踪、可恢复。
✅ Anthropic:Harness Design——Harness 必须随模型共演化
Anthropic 从 2024 年底到 2026 年初发布了大量跟 Agent 工程相关的博客,这里选取五篇文章(Building effective agents、多 Agent 研究系统、Context Engineering、Effective Harnesses、Harness Design)来分析其 Harness 实践方法论。其核心主张是:Harness 的每一个组件都编码了一个关于"模型做不到什么"的假设,这些假设必须随模型演进持续压力测试。
说服力同样来自他们自己的数据:
多 Agent 研究系统比单 Agent 性能提升 90.2%(Anthropic 内部评测),复杂查询研究时间缩短 90%,但 token 用量是 15 倍——Anthropic 自己说"这不是 bug,这是并行探索的成本"。Context Engineering 中,Memory Tool + Context Editing 使搜索任务性能提升 39%,100 轮场景 token 消耗降低 84%。Harness 对 2D 复古游戏制作器的测试中,单 Agent($9/20 分钟)核心功能损坏,三 Agent Harness($200/6 小时)全功能可用。
他们的 Harness 经历了三个阶段的演化,每一步都是对前一步失败模式的回应:
阶段一:两 Agent 架构解决跨窗口连续性。 即便是 Opus 4.5 跨多个上下文窗口运行,也会出现两个典型失败:一把梭(one-shotting,试图一次做完所有事)和提前收工(premature completion,看到进展后直接宣布完成)。解决方案受人类工程师启发:Initializer Agent 在首次运行时创建 feature_list.json(200+ 功能,全标记 "failing")、claude-progress.txt 和初始 git commit;Coding Agent 每次启动时先读 git log 和进度文件,选一个功能实现,做完提交并更新进度。核心洞察:让 Agent 能在全新上下文窗口中快速理解当前状态。
阶段二:Context Engineering 提供理论框架。 上下文衰减(Context Rot,概念最早由社区提出,Chroma 做了实证研究,Anthropic 系统阐述)说明上下文不是越多越好;即时检索(Just-in-Time Context)说明应该按需加载而非预加载;子 Agent 架构的核心价值是上下文隔离而非分工。这些原则为 Harness 中的压缩、裁剪和调度策略提供了理论基础。
阶段三:三 Agent 对抗架构突破质量天花板。 两 Agent 架构解决了连续性,但没解决质量——Agent 自我评估时倾向于自信地称赞平庸的工作。Anthropic Labs 的 Prithvi Rajasekaran 引入了 GAN 式设计:Planner 把一句话需求扩展为产品规格(~16 功能/10 sprint);Generator 按 sprint 实现,每个 sprint 前与 Evaluator 进行合约谈判(Sprint Contract)确定完成标准;Evaluator 用 Playwright MCP 像真实用户一样操作运行中的应用,基于结构化标准打分,不达标则打回修复,每个 sprint 迭代 5-15 轮。核心主张:把执行者和评判者分离,是提升产出质量最强的杠杆。
这三个阶段最有价值的不只是架构本身,而是 Anthropic 在其中发现的四条教训:
教训一:Harness 的最佳厚度是模型依赖的。 Sonnet 4.5 有严重的"上下文焦虑"(Context Anxiety)——感觉上下文变长时会赶工、偷工减料,必须做 context reset。Opus 4.5 消除了这个问题,可以去掉 reset。Opus 4.6 进一步允许去掉 sprint 分解,连续编码超 2 小时仍保持连贯。每换一代模型,Harness 都应该被重新审视——逐一移除组件,看哪些仍然承重,哪些已经多余。
教训二:Evaluator 的价值取决于任务是否超出模型的可靠独立完成范围。 模型能力越强,这条边界越远,Evaluator 的收益越集中在更难的任务上。在模型自身能做好的任务上,Evaluator 是多余开销。
教训三:对抗性压力能激发创造性。 在一个荷兰艺术博物馆网站项目中,第 10 轮迭代出现了创造性跳跃——Agent 放弃常规暗色落地页,重新想象为带棋盘地板的 3D 房间、CSS 透视渲染、门廊式导航。这种创意在单次生成中从未出现。
教训四,也是最重要的一条:
有趣的 Harness 组合空间不会随着模型改进而缩小——它会移动。
旧的脚手架被拆除,新的脚手架被搭建。Harness 工程不是一劳永逸的,而是需要随模型演进持续调整的活工程。AI 工程师的真正工作,是不断找到下一个有价值的 Harness 组合。
✅ Meta-Harness:让 Agent 自动优化 Harness
如果说 OpenAI 和 Anthropic 回答的是"如何手工做好 Harness",斯坦福与 KRAFTON 团队联合提出的 Meta-Harness 回答的是一个更根本的问题:Agent 能否自动优化 Harness 本身?
答案是能,而且效果显著。
在 Meta-Harness 之前,优化 Harness 基本靠两种方式:人工经验调优,或者基于文本的自动优化器(如 OPRO、TextGrad、AlphaEvolve 等)。前者依赖专家直觉,效率低且不可规模化;后者的问题则在于它们只给优化器看"压缩后的历史(如摘要、最终分数、短窗口内的候选)",严重限制了诊断能力。而 Meta-Harness 的关键洞察是:把优化器从"看摘要的建议者"升级为"看全量证据的调试工程师"。
具体做法是给一个 proposer agent(本身也是一个 coding agent,如 Claude Code)访问完整的历史文件系统(包含所有候选 Harness 的源代码、每次执行的完整轨迹、每个任务的评分),每轮可用上下文高达 1000 万 token,而此前最好的方法(AlphaEvolve)只有约 2.2 万 token,这是数量级的差距。
优化循环如下:
-
Proposer agent 读取文件系统中的历史候选代码、执行轨迹和评分
-
做反事实诊断——不是只看"哪个分高",而是深入分析"这个候选在任务 X 上失败了,根因是什么?如果换一种工具定义会怎样?"
-
基于诊断提出新的 Harness 候选
-
在保留任务集上评估新候选
-
把结果写回文件系统,进入下一轮
这个过程更像"工程调试"而不是"黑箱搜索"。Proposer 平均每轮会读取 82 个文件,参考超过 20 个历史候选——它真的在做深度分析,而不是随机变异。
三组实验设计,三个维度的验证
文本分类(高类别数场景)。 在 215 类法律文本分类任务(LawBench)等场景上,准确率从 40.9%(ACE 方法)提升到 48.6%(Meta-Harness),同时上下文开销降到 1/4。这个结果很反直觉——通常提升精度需要更多计算,但 Meta-Harness 发现的 Harness 不需要额外的 LLM 调用,提升完全来自更聪明的输入组织方式。对于标签空间大、类别相似度高的任务,Harness 优化的杠杆尤其大。
数学推理(跨模型迁移)。 在 200 道 IMO 级别数学题上,Meta-Harness 发现的检索策略在 5 个未参与搜索的模型上平均提升 4.7 分(34.1% → 38.8%)。这组实验最重要的发现不是分数本身,而是跨模型迁移性——同一个 Harness 在不同模型上都有效。这支持了一个关键主张:好的 Harness 优化的是"信息组织方式",而不是对特定模型的 prompt 技巧。对 RAG 系统有直接启示:很多团队只调 embedding 和向量库参数,但检索逻辑本身(何时检索、检索后如何组织结果)往往是更大的杠杆。
Agentic Coding(TerminalBench-2)。 这是最接近真实生产场景的评测。Claude Opus 4.6 达到 76.4%(排名第二),Claude Haiku 4.5 达到 37.6%(同赛道第一)。两个亮点:第一,优化对象是完整的 Harness 栈(system prompt + tools + completion check + context management),而不是单改 prompt,提升来自系统协同。第二,在弱模型上的提升尤其突出——Haiku 赛道的领先说明 Harness 优化能显著抬高小模型的上限。对于成本敏感场景,这意味着你可能不需要最贵的模型,只需要更好的 Harness。
关键启示
Meta-Harness 的价值不只在于实验数字。它证明了三件事:
第一,在固定模型条件下,Harness 仍然拥有巨大的优化空间。这意味着等待下一代模型不是唯一的提升路径。
第二,全量执行证据是高效优化的前提。给优化器摘要还是给它完整日志,效率差一个数量级——Meta-Harness 仅用 4 轮迭代就达到了其他方法最终收敛时的精度。
第三,Harness 优化可以被系统化、自动化。这指向了一个新的工程范式:当你的日志和评测集足够丰富时,可以让 agent 来优化 agent 的运行环境。
✅ Natural-Language Agent Harnesses:让Harness成为研究对象
NLAH 论文提出了另一个有价值的视角:把 Harness 从散落在代码和配置中的隐式存在,转化为可执行的自然语言表示。
这听起来像是学术抽象,但它解决了一个很实际的问题:目前大多数 Harness 是不可比较的。团队 A 的 Harness 写在 Python 脚本里,团队 B 的写在 YAML 配置里,团队 C 的写在 system prompt 里。你无法直接对照它们的异同,无法做控制变量实验,无法系统地评估"哪个设计决策贡献了多少性能"。
NLAH 的方案是:用结构化的自然语言来表示 Harness 的各个组件(控制流、工具定义、停止条件、记忆策略等),使它们可以被读取、比较、替换和组合。这为 Harness 的研究提供了标准化的表示层。
厚 Harness 与薄 Harness:一条连续谱
行业的分歧不在于"要不要 Harness"——这已经是共识。分歧在于 Harness 应该做多"厚"。
✅ 什么是厚 Harness
厚 Harness 把更多控制逻辑、架构约束、评测回路和守护机制外置到模型之外。系统层承担更多的决策和治理职责,模型更多地扮演"执行者"角色。
OpenAI 的路线是厚 Harness 的典型代表。他们强调:仓库知识库(repository as system of record)、结构化执行计划(PLANS.md)、机械化的架构约束(enforcing invariants)、全面的可观测系统、自动 code review。核心逻辑不是"模型弱所以要补系统",而是 "即使模型强,复杂软件系统仍然需要厚实的外部控制层"。
厚 Harness 的优势在于:可预测性强、可审计、对模型能力的依赖较低(弱模型也能用)、更容易满足合规要求。劣势在于:工程投入大、灵活性受限、可能过度约束模型的自主性。
✅ 什么是薄 Harness
薄 Harness 把更多策略空间交给更强的模型,外层重点放在高质量上下文组织、少而稳的工具集、必要的 guardrails 和运行时记忆管理上。
Anthropic 的演化路径本身就是薄化的活教材:Sonnet 4.5 时代需要 context reset + sprint 分解 + 严格交接工件(厚 Harness);Opus 4.5 消除了 context anxiety,可以去掉 context reset;Opus 4.6 进一步允许去掉 sprint 分解,Generator 连续编码超过 2 小时仍然保持连贯。模型每升级一代,Harness 就可以削薄一层——但不是去掉 Harness,而是把 Evaluator、Planner 等高价值组件保留,去掉那些不再"承重"的脚手架。
薄 Harness 不是"没有 Harness"——这一点很重要。它只是把 Harness 的重心从硬编码的流程控制转向上下文编排和运行时记忆管理。工具还是受治理的,权限还是分阶段的,安全边界还是存在的。区别在于:薄 Harness 倾向于把更多的"怎么做"留给模型自己判断。
薄 Harness 的优势在于:灵活性高、开发速度快、能充分利用强模型的推理能力、更容易适应新任务。劣势在于:对模型能力依赖高(弱模型用不了)、可预测性较低、审计难度较大。
✅ 不是二选一,而是一条连续谱
现实中,两条路线不是非此即彼。更可能的走向是:根据场景在厚薄之间动态调节。
-
企业软件工程、金融交易、医疗诊断、合规审计 → 更可能走厚 Harness。错误的代价极高,可审计性和可预测性比灵活性重要。
-
研究探索、内容生成、开放式知识工作 → 更可能走薄 Harness。任务多变,过度约束会限制创造性。
-
成本敏感 + 弱模型场景 → 厚 Harness 对提升上限更有价值。Meta-Harness 在 Haiku 上的表现已经证明这一点。
-
强模型 + 可探索环境 → 薄 Harness 更灵活,模型的自主判断质量足够高。
真正稳定的竞争力,不在于先验地站队某一端,而在于是否有一套能在厚薄之间动态调节的工程方法论——根据任务风险、模型能力、成本预算和合规要求来选择合适的厚度。
跨路线正在收敛的方法论
无论偏厚还是偏薄,我们观察到一组共通的工程方法正在沉淀。它们不依赖于特定框架或特定模型,因此比任何单一技术选型都更长寿。理解并掌握这些方法,是构建可持续演进的 Agent 系统的关键。
✅ 评测驱动开发
没有成功率、成本和恢复率的共同指标,所谓改进无法积累。你改了一个 prompt,任务成功率上去了,但 token 成本翻倍了——这是改进还是退步?没有多维度的评测框架,你无法回答这个问题。
Meta-Harness 的核心贡献之一就是把 Harness 优化变成了可评测、可迭代的闭环。评测不是事后的验收环节,而是优化循环的驱动力。每一轮迭代都基于明确的评测指标来决定方向。
对于实践者,最小可行的评测框架至少应该包括三个维度:任务成功率(能不能做完)、token/时延成本(值不值得)、恢复率(中断后能不能继续)。更成熟的团队还会加入跨模型迁移增益(换一个便宜的模型还能不能用)和错误可诊断性(出了问题能不能定位)。
✅ 全量轨迹归档
候选代码、执行日志、评分结构化保留。这不是"有了再说"的附加功能,而是后续所有优化的前提条件。
Meta-Harness 最有说服力的对比之一是:给 proposer 完整历史(1000 万 token)vs. 给它摘要(最多 3 万 token),优化效率差一个数量级。这个差距的根因是——摘要会丢失关键的诊断信息。你知道某个候选失败了,但你不知道它在第 23 步调用了一个错误参数的 API,而这个错误是因为 context 在第 17 步被一个无关的工具输出污染了。只有看到完整的执行轨迹,才能做这种级别的根因分析。
✅ 诊断驱动改动
每次修改先有根因假设,再有反事实验证,最后落到最小改动补丁。不是黑箱调参("改改 prompt 试试看"),而是工程调试("在这个失败案例中,如果把 tool definition 中的 X 改成 Y,模型应该不会再误调 Z 工具")。
这是 Meta-Harness 与此前优化方法的本质区别。此前的方法是"看分数做搜索"——分高的保留,分低的变异。Meta-Harness 是"看日志做调试"——先理解为什么失败,再做针对性修复。后者更像人类工程师的工作方式,效率也更高。
✅ 上下文预算管理
上下文不是越多越好。Anthropic 的 Context Rot 概念清晰地量化了这一点:更多的上下文 token 不仅增加成本,还会降低模型对关键信息的注意力。
因此,上下文压缩和即时检索不是"窗口快满了才启动"的补救机制,而是应该从第一步就纳入主流程的核心策略。每一个进入上下文的 token 都应该有理由——如果一段工具输出对后续决策没有价值,就不应该让它占用窗口空间。
✅ 子 Agent 隔离
子 Agent 不只是组织学工具(让不同的 Agent 做不同的事),更是上下文经济学工具。每个子 Agent 在独立的上下文窗口中工作,不受其他任务噪声的干扰。主 Agent 只接收压缩后的结果,上下文保持干净。
Anthropic 的多 Agent 研究系统验证了这一点:通过隔离,每个子 Agent 的工作质量更高(上下文更相关),主 Agent 的综合质量也更高(噪声更少)。代价是更多的 token 消耗——但如果 token 预算允许,隔离几乎总是值得的。
✅ 工具风险分级与权限管线
权限不是单点开关。Schema 验证 → 规则匹配 → 上下文评估 → 用户确认,多阶段收敛。每一阶段拦截一类风险,只有通过所有阶段的操作才会被执行。
这个设计的好处是:低风险操作(如读取文件)可以快速通过,不影响 Agent 的执行效率;高风险操作(如删除数据库表)会被层层过滤,确保安全。用户不会被大量低风险确认请求淹没,也不会在关键时刻失去控制。
✅ 知识库与计划文档作为系统事实来源
OpenAI 的 AGENTS.md / PLANS.md、Anthropic 的结构化笔记,本质上都是把上下文从"一次性输入"变成"持续维护的系统资产"。
PLANS.md 的设计尤其值得关注:Agent 在执行多小时任务之前,先生成一份结构化的执行计划;在执行过程中持续更新计划状态(哪些步骤完成了、哪些被修改了、遇到了什么意外)。这份文档既是 Agent 的工作记忆,也是人类审查和干预的接口。当任务中断并恢复时,Agent 可以从 PLANS.md 重建上下文,而不是重新推导所有步骤。
✅ 人类在环升级机制
不是"全自动"或"全手动"的二选一,而是根据风险等级动态决定何时交由人类确认。
一个好的升级机制应该是:对于 Agent 有信心且风险低的操作,自动执行;对于 Agent 不确定或风险高的操作,暂停并请求人类审批;对于人类也需要更多信息才能判断的操作,Agent 先提供分析和建议,再由人类做最终决策。这种分级机制既保持了自动化的效率,又保留了人类对关键决策的控制。
怎么看未来
基于以上分析,对未来 12-24 个月有四个判断。
✅ 第一,Harness 不会消失,只会重新分布
差别不在于有无 Harness,而在于控制逻辑、记忆机制、任务规划和安全约束是更多留在外层系统,还是更多交给模型与上下文编排。
随着模型变强,一些过去写死在外层的逻辑(比如详细的任务分解步骤、具体的错误处理策略)会被"上移"到上下文组织中——你不再需要硬编码"遇到 404 错误就重试三次",而是让模型自己判断如何处理。但同时,新的治理需求(合规审计、成本控制、数据安全、可解释性)会持续产生新的外层职责。Harness 的总量可能不会减少,但它的构成会持续变化。
✅ 第二,厚与薄会场景化分化
这一点在前文已经展开。核心判断是:不存在"最优厚度",只有"适合当前场景的厚度"。企业级 Agent 在可预见的未来会保持较厚的 Harness,因为合规、审计和安全要求不会因为模型变强而降低。消费级和研究级 Agent 则会继续向薄 Harness 演化,充分利用模型的自主判断能力。
✅ 第三,方法论会先于框架沉淀
Context engineering、harness engineering、eval-driven iteration、sub-agent isolation、memory compaction、tool risk grading——这些方法会比具体框架名更长寿。今天的 LangGraph、CrewAI、AutoGen 在两年后可能被新框架取代,但"评测驱动开发""上下文预算管理""诊断驱动改动"这些方法论会持续有效。
未来提升 Agent 能力的工作方式,不是等待"最终正确路线"出现,而是在这些方法论之间做组合、做实验、做评测。更现实的工程策略是:掌握一套跨框架可复用的方法论,然后在具体项目中根据需求选择或切换框架。
✅ 第四,自动化 Harness 优化会成为新常态
Meta-Harness 证明了这个方向的可行性和有效性。当日志和评测集足够丰富时,人工调优会自然过渡到 agent 驱动的自动提案与自动评测。
这不会取代人类工程师。相反,它会改变工程师的工作重心——从"手动调整 prompt 和配置"到"设计评测指标、审查自动提案、维护安全约束、做架构级决策"。这类似于 DevOps 和 CI/CD 对传统运维的改变:自动化不是消灭了运维工程师,而是把他们的工作从"手动操作"提升到了"设计系统和策略"。
同时,研究论文与工业实践会继续相互牵引但不完全重合。学术界会持续提出新的表示方式、新的优化目标和新的评测方法(如 Meta-Harness 和 NLAH);工业界则更关注"哪些做法能低成本稳定落地"。因此,未来的主线更可能是"研究提供新变量,工程筛选可复用方法",而不是某篇论文直接定义行业标准。
需要警惕的风险
对未来的判断如果只讨论机会而回避风险,就会失去可信度。我们认为至少有五个风险值得保持警觉:
评测过拟合。 Harness 优化如果只针对固定的评测集,可能会产生"在 benchmark 上很好看但在真实场景中失效"的结果。解决方案是使用多样化的保留集,并定期用新任务刷新评测。
错误归因。 当 Agent 表现变好时,很容易把功劳归给最近的一次修改,但真实原因可能是其他因素(比如 API 服务器负载变低了)。诊断驱动改动和反事实分析可以缓解这个问题,但无法完全消除。
数据泄露。 全量轨迹归档意味着大量执行细节被持久化存储。如果这些日志包含敏感信息(用户数据、API 密钥、内部代码),就需要严格的访问控制和脱敏处理。
权限蠕变。 系统在正常运行中逐渐积累越来越多的权限("上次加了这个权限,运行得更顺了,要不再加一个?"),直到安全边界变得形同虚设。定期的权限审计和最小权限原则是必要的防线。
合规边界模糊。 "可读""可迁移""可自动优化"的 Harness 并不自动意味着"可合规"。不同行业、不同地区的合规要求差异巨大,Harness 设计需要从一开始就把合规作为约束条件纳入,而不是事后补救。
给实践者的建议
1. 先建评测,再谈优化。 没有成功率、成本和恢复率的共同指标,所有改进都是盲飞。第一步不是调 prompt,而是建立一个能告诉你"系统现在表现如何"的评测框架。
2. 先建治理,再扩大自治。 权限、审计和回滚不到位时,Agent 自主性越强,系统风险越大。先把四阶段权限管线和人类在环机制搭好,再逐步放宽 Agent 的自治范围。
3. 把 Harness 当长期资产,不是项目脚本。 日志归档策略、权限规则、上下文管理策略、工具 schema、评测数据集——这些都是跨项目可复用的资产。只有当它们可以复用时,系统能力才真正可迁移。
4. 从最简单有效的方案开始。 Anthropic 的建议值得记住:do the simplest thing that works。过度工程化的 Harness 和没有 Harness 一样危险。先用单 Agent + 少量工具 + 基本权限跑通核心流程,再根据实际需求逐层加厚。
5. 关注弱模型上的表现。 如果你的 Harness 只在最强模型上有效,说明系统对模型能力的依赖过高。Meta-Harness 在 Haiku 4.5 上的突出表现说明:好的 Harness 能让便宜的模型做到贵模型的事。这不只是成本问题——当最强模型 API 限流或故障时,能退化到弱模型继续运行的系统,才是真正健壮的系统。
6. 把每一次失败变成诊断资产。 不要只记录"任务失败了",要记录完整的执行轨迹。今天看不出原因的失败日志,在积累了足够多的案例之后,可能会揭示系统级的模式。Meta-Harness 的核心竞争力就建立在这种"全量证据"之上。
7. 从一开始就设计可观测性。 不是出了问题再加日志,而是从架构阶段就把"这个系统的运行状态可以被外部理解"作为设计约束。每一次工具调用、每一次上下文压缩、每一次子 Agent 派发,都应该有结构化的记录。当你需要诊断一个两天前的失败时,你会感谢过去的自己。
结论
Agent 领域正在经历一次不那么显眼但意义深远的转变:从"模型能力竞争"到"模型 × 系统协同竞争"。
基础模型仍然定义理论能力边界——你不能用 Harness 让一个不会写代码的模型写出好代码。但 Harness 决定了这些能力中有多少能在现实环境中真正发挥出来。OpenAI 的 Harness Engineering 实践证明了环境设计的杠杆效应,Anthropic 从 Context Engineering 到三 Agent 对抗架构的演化提供了最完整的 Harness 设计方法论,Meta-Harness 展示了自动化优化的巨大空间。正如 Anthropic 所说:有趣的 Harness 组合空间不会随着模型改进而缩小——它会移动。
未来不会被某一篇论文或某一个框架定义。更可能发生的是:厚 Harness 与薄 Harness 两条路线并行推进,在 context engineering、eval-driven iteration、sub-agent isolation、memory management、tool governance 等方法论层面逐步收敛。
未来真正的竞争壁垒,不只是更强的模型,而是更成熟、更可进化、更可治理,同时又能根据场景动态调节厚薄程度的 Harness。
对于正在构建 Agent 系统的团队,我们的建议很简单:不要只追新模型。花同样的时间在你的 Harness 上——评测体系、权限管线、上下文策略、状态管理、可观测性——你会发现,回报率可能比等待下一个模型版本更高。
参考资料:
-
https://openai.com/zh-Hans-CN/index/harness-engineering/
-
https://openai.com/business/guides-and-resources/a-practical-guide-to-building-ai-agents/
-
https://developers.openai.com/cookbook/articles/codex_exec_plans
-
https://www.anthropic.com/research/building-effective-agents
-
https://www.anthropic.com/engineering/multi-agent-research-system
-
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
-
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
-
https://www.anthropic.com/engineering/building-agents-with-the-claude-agent-sdk
-
https://www.anthropic.com/engineering/harness-design-long-running-apps
-
https://yoonholee.com/meta-harness
-
https://arxiv.org/html/2603.28052v1
-
https://arxiv.org/pdf/2603.25723
-
https://docs.langchain.com/oss/python/langgraph/persistence
-
https://developers.openai.com/api/docs/guides/function-calling

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)