Live Avatar 深度解析:首个 14B 参数实时流式无限时长数字人,10000 秒无漂移的技术秘密
本文是我逐行啃完 Live Avatar 论文 + 拆解所有核心疑问后的个人学习记录,全程结合 CausVid、Self-Forcing、Self-Forcing++ 等相关工作做横向对比,把我自己曾经踩过的坑、混淆过的概念、想不通的反直觉设计全部整理出来,目的是帮自己(也帮同样在啃这块的同学)彻底搞懂自回归视频扩散长时稳定的底层逻辑。
所有结论严格对应论文原文,没有主观臆断,所有对比都标注了来源,方便后续回溯。

一、先理清楚演进脉络:从 CausVid 到 Live Avatar,我们到底在解决什么问题?
在开始拆解疑问之前,先把整个自回归流式视频扩散的发展时间线理清楚,你会发现每一个新方法都是在解决上一个方法遗留的核心问题,Live Avatar 也不例外:
| 时间 | 方法 | 核心贡献 | 遗留的致命问题 |
|---|---|---|---|
| 2025.06 | CausVid (CVPR 2025) | 首次提出将双向扩散模型蒸馏为因果流式模型,实现分钟级视频生成 | 1. 双向→因果架构 gap 大,蒸馏收敛慢2. 干净 KV 缓存导致误差累积,长时生成快速漂移3. 1.3B 小模型,画质有限 |
| 2025.06 | Self-Forcing (CVPR 2025) | 提出自强制机制,用学生自己的生成结果做监督,缓解蒸馏 - 推理 gap | 1. 每块刷新干净 KV 缓存,计算开销大2. 还是存干净缓存,只能缓解漂移,不能解决3. 最长支持约 1 分钟生成 |
| 2025.10 | Self-Forcing++ | 降低 KV 缓存刷新频率,延长生成时长 | 1. 本质还是干净缓存,只是刷新更慢2. 最长支持约 4 分钟生成,还是会崩 |
| 2026.03 | Live Avatar | 算法 - 系统协同设计,实现 14B 大模型实时 + 10000 秒无漂移 | 1. 依赖静态场景先验2. 端到端延迟约 3 秒 |
核心演进主线:从 "能流式生成" → "能生成几分钟" → "能无限时长生成",所有的技术改进都围绕一个核心矛盾:如何在自回归生成中,既保证运动连续性,又避免误差的指数级累积。
二、我的核心疑问全解(结合对比)
下面是我在学习过程中遇到的所有疑问,每个疑问都结合相关论文做了对比和验证,这也是这篇笔记最有价值的部分。
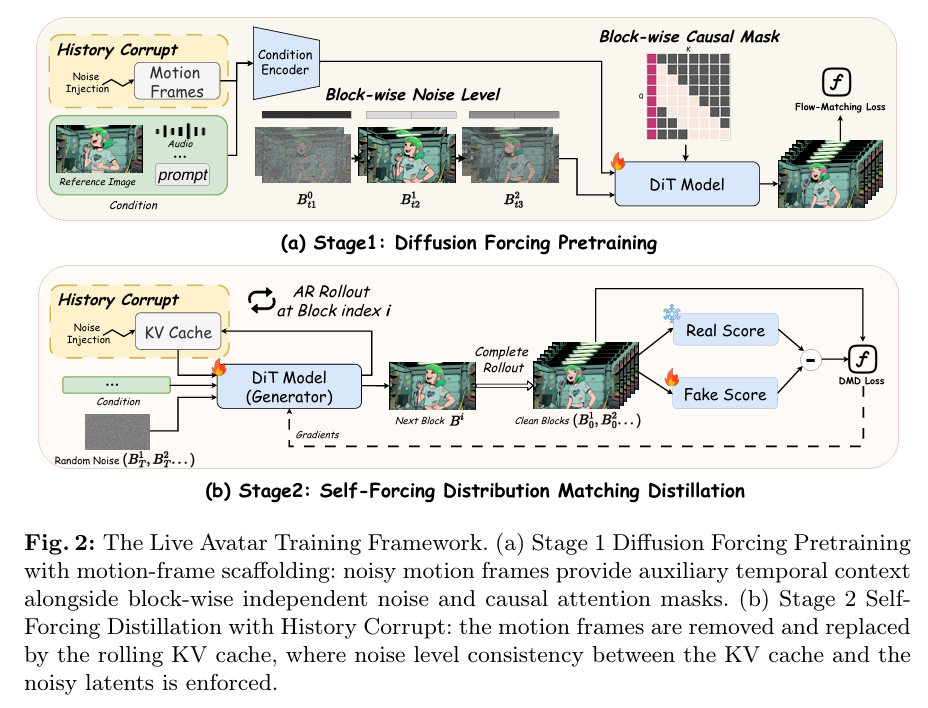
疑问 1:历史上下文到底是什么?和 Text Prompt 有本质区别吗?
这是我最开始混淆的第一个概念,很多教程都把历史上下文说成是 "另一种 prompt",这是完全错误的。
| 维度 | 历史上下文输入 | Text/Audio/Reference Image Prompt |
|---|---|---|
| 性质 | 时序动态条件,随生成过程不断更新 | 全局静态条件,整个生成过程固定不变 |
| 作用 | 保证运动连续性:控制口型、表情、手势的平滑过渡 | 保证身份和内容一致性:控制数字人是谁、说什么、什么风格 |
| 注意力范围 | 局部时序注意力,只关注最近的 N 帧(滚动窗口) | 全局注意力,所有帧都能看到 |
| 存储位置 | 滚动 KV 缓存 | 一次性编码后固定存储 |
大白话理解:
- Text Prompt:"一个绿头发的女孩在说话" → 整个视频都是这个女孩,不会变
- 历史上下文:第 1 帧女孩张嘴,第 2 帧必须从张嘴过渡到闭嘴,不能突然变成闭眼 → 保证动作不跳变
关键结论:历史上下文是流式生成的核心,没有它,模型只能生成独立的帧,无法生成连续的视频。所有自回归视频生成模型都必须依赖历史上下文。
疑问 2:为什么 Live Avatar 的蒸馏只需要 500 步,CausVid 需要 3000 步?
这里的 "步" 指的是参数更新次数(batch step),不是 epoch。Live Avatar 的蒸馏收敛速度是 CausVid 的 6 倍,核心原因有三个,按贡献度排序:
-
对称架构蒸馏(最大贡献)
- CausVid:教师是双向 DiT,学生是因果 DiT,架构本身存在巨大的不可消除的 gap,需要大量步数来对齐
- Live Avatar:教师是 Stage1 训练好的因果 DiT,学生也是因果 DiT,架构完全相同,只有推理步数不同,gap 被降到了最低
-
运动帧支架(5 倍加速,论文图 6)
- CausVid:Stage1 直接用干净的真实历史帧做上下文,Stage2 换成 KV 缓存时,模型需要重新学习 "从 KV 缓存提取运动信息" 的规则
- Live Avatar:Stage1 就对历史运动帧注入噪声,模拟推理时的噪声 KV 缓存,提前教会了模型 "身份 - 运动解耦" 的规则。Stage2 把运动帧换成 KV 缓存时,模型不需要重新学习,直接就能无缝切换
-
History Corrupt 提前引入
- CausVid:Stage1 用干净缓存,Stage2 还是用干净缓存,分布没有变化
- Live Avatar:Stage1 就引入了噪声历史,Stage2 的噪声 KV 缓存和 Stage1 的噪声运动帧分布完全一致,没有分布突变,因此收敛更快
疑问 3:为什么用模型自己生成的数据做蒸馏,效果反而比真实数据更好?
这是我最想不通的一个反直觉设计,直觉上真实数据的质量肯定比模型生成的数据高,但 Live Avatar 的实验证明恰恰相反。
两种 DMD 的本质区别
| 方法 | 输入 x_t 来源 | 训练分布 | 蒸馏 - 推理 gap | 长时稳定性 |
|---|---|---|---|---|
| CausVid DMD | 真实视频加噪 | 真实数据分布 | 大(训练用真实数据,推理用自己生成的数据) | 差(数分钟内漂移) |
| Live Avatar Self-Forcing DMD | 学生自回归生成的中间 latent | 推理时的自回归生成分布 | 零(训练和推理用完全相同的分布) | 好(>10000 秒无漂移) |
核心原因:长时生成的主要矛盾不是单帧质量,而是分布对齐
- CausVid 用真实数据训练,单个帧的质量确实更高,但训练时的输入分布和推理时的输入分布完全不同。长时生成时,模型会不断遇到训练时没见过的 "自己生成的有瑕疵的数据",不知道如何处理,误差会指数级累积
- Live Avatar 用自己生成的数据训练,虽然单个样本的质量略低,但训练分布和推理分布 100% 对齐。模型在训练时就已经学会了如何处理自己生成的有瑕疵的数据,如何纠正误差,因此长时稳定性大大提升
论文原文对应:"Self-Forcing 的核心价值是用分布对齐换单个帧质量,换取长时稳定性。"
疑问 4:KV 缓存到底存什么?为什么 Live Avatar 要存噪声?这是人为加的噪吗?
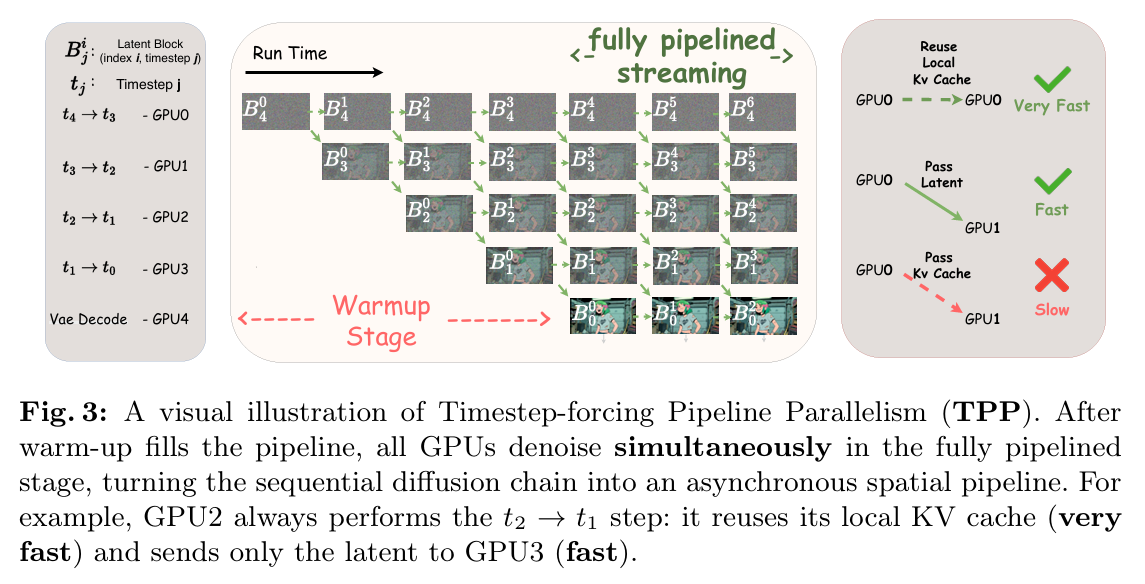
这是 Live Avatar 和所有之前方法的最核心区别,没有之一。我把三代方法的 KV 缓存机制完整对比:
| 方法 | KV 缓存存储内容 | 刷新机制 | 核心问题 |
|---|---|---|---|
| Self-Forcing | 干净的 latent(x₀) | 每生成一个块,做一次额外的前向传播,把 KV 缓存刷新为干净的 x₀的 KV | 干净缓存会传递误差,长时生成身份漂移严重 |
| Self-Forcing++ | 干净的 latent(x₀) | 每 N 个块刷新一次 | 还是存干净缓存,只是刷新更频繁,只能缓解漂移 |
| Live Avatar | 带噪声的中间 latent(x_t) | 完全去掉了刷新步骤,直接存去噪过程中第 t 步的 x_t 的 KV | 无(噪声抑制误差累积) |
关键澄清:噪声不是人为加的!
很多人误以为 Live Avatar 是在干净 latent 上人为加噪再存入 KV 缓存,这是完全错误的。
- KV 缓存里的噪声表征是模型去噪过程中自然输出的中间结果
- 比如 4 步去噪,第 2 步输出的 x₂就是带噪声的,直接把 x₂的 KV 存入缓存
- 强制KV 缓存的噪声水平和当前处理的 latent 的噪声水平完全一致(Timestep-forcing)
为什么存噪声更好?
高斯噪声是天然的低通滤波器:
- 抑制高频信息:人脸纹理、五官细节、小瑕疵等
- 保留低频信息:转头、张嘴、眨眼等运动轨迹
- 强制模型只能从 Reference Image 提取身份,从 KV 缓存提取运动,从根本上切断了误差累积的路径
疑问 5:身份锚点为什么只更新一次?持续更新为什么不行?
这是我问过的最反直觉的问题,也是 Live Avatar 最精妙的设计之一。
完整的身份锚点生命周期
- 初始阶段:用用户输入的原始 Reference Image 冷启动
- 唯一一次更新:第一个块生成完成后,用模型自己生成的第一个干净 latent 完全替换原始 Reference Image(AAS 机制)
- 永久固定阶段:之后永远不再更新锚点内容,仅通过 Rolling RoPE 调整其位置编码
为什么持续更新是绝对错误的?
任何用最新生成的帧更新身份锚点的尝试,都会导致误差的指数级累积:
- 最新生成的帧本身就带有微小的误差
- 用这个有误差的帧作为新的锚点,下一个帧的误差会在这个基础上继续放大
- 更严重的是:最新帧的姿态会被误认为是身份的一部分。比如人物转头了,用这个转头的帧作为锚点,模型会认为 "这个人的脸本来就是侧面的",再也转不回来了
为什么只用第一帧当锚点,人物转头不会有问题?
因为身份锚点提供的是抽象的身份原型,不是具体的姿态:
- 身份原型:五官比例、肤色、脸型、发型等不变的特征
- 姿态:转头、低头、张嘴等变化的特征,完全由 KV 缓存负责
- 模型在训练过程中已经见过了数百万张不同姿态的人脸,它完全知道如何把一个正面的身份原型,映射到任意姿态上
论文实验验证:图 7 展示了三个不同的人物,在 10s、100s、1000s、10000s 时的生成帧,所有人物都有明显的姿态变化,但身份完全一致。
疑问 6:TPP 并行和传统并行到底有什么区别?为什么能这么快?
TPP 是 Live Avatar 实现 14B 模型 45FPS 的核心系统创新,它彻底打破了扩散模型串行去噪的天生瓶颈。
| 并行方式 | 划分方式 | 加速比 | 通信开销 | 适配性 |
|---|---|---|---|---|
| 模型并行 | 按模型层划分 GPU | 低(4 卡约 2 倍) | 极高(需要传递巨大的激活值) | 通用 |
| 序列并行 | 按视频帧划分 GPU | 低(4 卡约 1.5 倍) | 高 | 适合批量生成 |
| TPP 并行 | 按去噪时间步划分 GPU | 高(4 卡约 4 倍,近线性) | 极低(只传递约 1KB 的 latent) | 仅适合因果流式扩散 |
TPP 的核心思想
每个 GPU 被分配一个固定的去噪时间步,而不是按层或按帧划分。比如 4 步去噪需要 4 个 GPU:
- GPU0 永远只做 t4→t3
- GPU1 永远只做 t3→t2
- GPU2 永远只做 t2→t1
- GPU3 永远只做 t1→t0
流水线填满后,所有 GPU 同时工作,吞吐量由单个 GPU 的单次去噪时间决定,而不是所有去噪步骤的总和。
TPP 和算法的深度协同
TPP 不是一个单纯的系统优化,它和 Live Avatar 的算法设计是深度耦合的:
- TPP 的时间步划分,天然适配了 Timestep-forcing 策略(每个 GPU 的 KV 缓存噪声水平和它处理的 latent 的噪声水平完全一致)
- 每个 GPU 只复用自己的本地 KV 缓存,不需要和其他 GPU 共享,通信开销几乎为零
疑问 7:Flow Matching 中的 Score 和 DDPM 中的 Score 有什么区别?
这是一个基础但容易混淆的概念,Score 的本质定义是统一的,但在不同框架下的表现形式不同。
Score 的通用本质
Score 是对数概率密度的梯度,表示 "在 x_t 这个位置,数据分布的最陡上升方向",也就是 "最可能出现真实数据的方向":s(xt,t)=∇xtlogp(xt)
不同框架下的模型预测目标
| 框架 | 模型预测目标 | 和 Score 的关系 |
|---|---|---|
| DDPM | 噪声 ε | s(xt,t)=−σtϵ |
| Flow Matching | 速度场 v | s(xt,t)=st2v−(xt−x0) |
关键结论:Flow Matching 直接预测速度场 v,训练更稳定、梯度更平滑、蒸馏效果更好,这也是当前所有大模型视频扩散(Wan、Sora、Live Avatar)都采用 Flow Matching 的原因。
三、我的学习心得与总结
1. Live Avatar 的核心贡献到底是什么?
不是 "做了一个更快的数字人",而是首次从理论上揭示了自回归视频扩散长时崩溃的三个根源,并提出了一套完整的、可复用的解决方案:
- 误差累积 → History Corrupt
- 分布漂移 → Adaptive Attention Sink
- 测试时条件漂移 → Rolling RoPE
这三个策略不仅适用于数字人生成,也为所有自回归视频生成模型的长时稳定问题提供了通用的解决思路。
2. 算法与系统协同设计的重要性
Live Avatar 的成功,是算法设计与系统架构深度协同的典范:
- 算法上的 Timestep-forcing 策略,为系统上的 TPP 并行提供了可能
- 系统上的 TPP 并行,又反过来验证了算法设计的有效性
- 两者缺一不可,任何单一的算法优化或系统优化,都无法实现 14B 大模型的实时无限时长生成
3. 反直觉设计往往是突破的关键
Live Avatar 中最反直觉的两个设计 ——"故意把历史记忆弄模糊" 和 "身份锚点只更新一次"—— 恰恰是它最核心的创新。这告诉我们,在做研究时,不要被固有的思维定式束缚,有时候反其道而行之,反而能找到解决问题的根本方法。
四、后续可以继续研究的方向
- 如何将 Live Avatar 的长时稳定策略扩展到动态场景和全身数字人?
- 如何进一步降低端到端延迟,满足视频通话等极致实时交互的需求?
- 如何在保持长时稳定的同时,支持数字人的身份和风格的动态变化?
- 如何将 TPP 并行推广到其他类型的扩散模型,如图像生成、3D 生成?
论文链接:
- Live Avatar: https://arxiv.org/abs/2512.04677
- CausVid: https://arxiv.org/abs/2504.04657
- Self-Forcing: https://arxiv.org/abs/2506.08009
- Self-Forcing++: https://arxiv.org/abs/2510.02283

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)