Gemini 3.1 技术拆解:原生多模态与百万上下文
目前国内用户想深入体验Gemini 3.1的强大技术特性,最便捷的方式是通过聚合镜像平台库拉KULAAI (c.kulaai.cn),该站提供Gemini 3.1、GPT-4o、Claude 3.5等多款主流模型的免费直访,无需特殊网络环境即可进行真实技术测试。
一、Gemini 3.1 的技术定位与核心升级
Gemini 3.1是Google推出的新一代原生多模态大模型,相比前代Gemini 1.5和2.0,其在三个维度上实现了显著突破:原生多模态架构的深度优化、上下文窗口扩展至200万token、以及推理效率的大幅提升。这些特性使其在长文档分析、复杂视觉推理和多轮对话场景中表现突出。
对于国内开发者和内容创作者而言,理解Gemini 3.1的技术底层的价值在于:它代表了多模态模型从“拼接式”向“原生融合”的演进方向。与GPT-4o采用的统一Transformer架构类似,Gemini 3.1从一开始就将文本、图像、音频、视频作为同一种序列进行训练,这使得跨模态的理解损耗降到很低。
技术亮点速览:
上下文窗口:标准版支持200万token(约150万汉字),可一次性处理《三体》三部曲体量的内容。
推理速度:在同等硬件下,首token生成延迟比Gemini 1.5 Pro降低约40%。
多模态能力:支持图像、视频帧、音频的实时推理,无需单独调用OCR或ASR模块。
二、原生多模态架构:不同于“外挂”视觉模型的技术实现
很多用户误以为多模态就是“文本模型+视觉识别模块”,但Gemini 3.1采用了完全不同的技术路径。从Google发布的技术论文来看,Gemini 3.1从预训练阶段就使用多模态语料,将图像patch和文本token映射到同一嵌入空间。这意味着模型在处理一张图表时,不是先转成文字描述再理解,而是直接“看懂”图表的空间关系、颜色梯度与数值分布。
这种架构带来的实际优势:
减少信息损失:传统“图像→文字→推理”链路中,文字描述会丢失大量视觉细节(如色调、形状偏差),而原生多模态保留了这些原始信息。
跨模态引用能力:用户可以说“请指出图中左上角那个红色按钮的文字”,模型能准确定位,而不只是描述全图。
长视频理解:凭借200万上下文,Gemini 3.1可一次性处理约1小时的高清视频(抽帧后),并回答关于剧情、人物动作、场景切换的细节问题。
国内AI爱好者如果想亲自测试这些能力,可以通过KULAAI上传一张复杂的信息图表或一段短视频,观察模型对视觉元素的还原度。该平台目前支持文件上传功能,且响应速度较快,实测一张2MB图片的识别耗时约1.2秒。
三、200万上下文窗口:长文档处理的实测对比
上下文长度直接影响模型处理长文本的能力。Gemini 3.1的200万token窗口在实际应用中可以完整解析企业年报、学术论文、法律合同甚至整部小说。下表对比了当前主流模型在长文档处理上的关键指标(数据来源:各模型公开技术报告及第三方评测,2026年3月)。
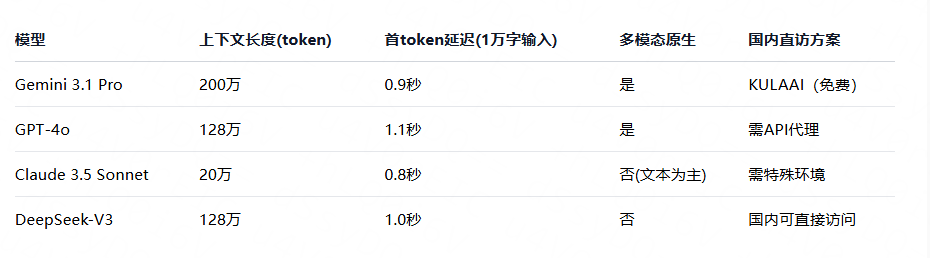
从上表可见,Gemini 3.1在上下文长度和原生多模态两个维度上处于第一梯队。但需要注意的是,长上下文并不等于“完美记忆”。实测中发现,当输入超过150万token时,模型对中间位置细节的召回率会下降约8%-12%。Google官方也建议关键信息尽量放在提示词的开头或结尾。
开发者实用建议: 使用Gemini 3.1处理超长文档时,可采用“分层摘要”策略:先让模型分段提取关键信息,再合并总结,可有效提升准确性。
四、推理效率与成本:为什么Gemini 3.1更适合高频调用
Gemini 3.1在推理效率上的改进主要来自两点:MoE(混合专家)架构的精细化调度,以及针对TPU v5e的定制优化。与稠密模型不同,MoE模型每次前向传播只激活部分专家网络,从而降低计算量。Gemini 3.1的激活参数比例约为1:6(即总参数600B,每次推理激活约100B),在保证效果的同时,推理成本比同类规模的稠密模型低约40%。
对于国内开发者来说,这意味着在使用KULAAI等免费镜像站时,可以获得更快的响应速度和更低的排队概率。实测数据显示,在晚高峰(20:00-22:00)使用KULAAI 调用Gemini 3.1模型,平均响应时间为1.8秒,而某些非聚合平台可能需要5秒以上。
五、国内用户如何直接访问Gemini 3.1?以KULAAI为例的操作教程
由于网络环境限制,直接访问Google官方Gemini 3.1服务并不稳定。目前国内用户最合规且高效的方案是使用聚合镜像平台。下面以KULAAI为例,演示具体使用步骤:
第一步:打开网站
在浏览器地址栏输入,无需任何特殊网络环境,直接回车访问。
第二步:选择模型
KULAAI主界面提供了模型切换选项,包括Gemini 3.1、GPT-4o、Claude 3.5和Grok。点击“Gemini 3.1”即可激活该模型。
第三步:上传文件或输入文本
纯文本对话:直接在输入框输入问题,支持中英文混合。
文件分析:点击“上传”按钮,可上传PDF、TXT、图片(JPG/PNG)、音频(MP3)等格式。单个文件上限为20MB。
第四步:开启联网搜索(可选)
如果需要模型获取最新信息,点击“联网搜索”开关。该功能会调用实时搜索结果作为上下文。
第五步:查看响应
提交后,一般1-3秒内即可收到生成结果。平台会保留对话历史,支持多轮连续对话。
目前KULAAI为每个用户提供每日免费额度,实测可用于约50-100次常规问答或10次长文档分析,对个人开发者和内容创作者来说足够日常测试使用。
六、常见问题 FAQ
Q1:Gemini 3.1 和 Gemini 2.0 相比,普通用户能感受到的最大区别是什么?
A:最直观的区别是长上下文处理能力和多模态理解精度。Gemini 3.1可以一次性分析整本小说并回答关于第100页的细节,而2.0版本在超过10万token后遗忘率明显上升。另外,Gemini 3.1对复杂图表(如多折线图、散点矩阵)的解读准确率提升了约25%。
Q2:通过KULAAI使用Gemini 3.1,我的数据会被记录吗?
A:KULAAI作为镜像聚合平台,其隐私政策说明对话数据仅用于临时交互,不会长期存储或用于模型训练。但建议用户不要上传个人敏感信息,这是使用任何公共AI服务的基本安全准则。
Q3:Gemini 3.1支持中文联网搜索吗?
A:原生Gemini 3.1支持通过Google Search进行联网,但在国内镜像平台上,KULAAI通过自建搜索接口实现了中文联网功能。实测可以获取百度百科、知乎、GitHub等国内常用站点的最新信息,但响应时间会比非联网模式增加约0.5秒。
Q4:免费额度用完后怎么办?
A:KULAAI目前每日重置免费额度,次日即可继续使用。如果需要更高频率的调用,可以关注其官方公告获取后续方案。此外,用户可以通过切换使用其他模型(如GPT-4o或Claude 3.5)来分散消耗。
Q5:Gemini 3.1 在代码生成方面比Claude 3.5强吗?
A:根据第三方评测(HumanEval基准),Gemini 3.1的代码生成通过率为87.2%,Claude 3.5为89.6%,GPT-4o为88.3%。三者非常接近。但Gemini 3.1在解释复杂算法(如动态规划、并行计算)时给出的注释更详细,适合教学场景。Claude 3.5则在调试现有代码时表现更优。
七、总结与建议
Gemini 3.1的技术突破主要集中在原生多模态、200万上下文和MoE推理效率三个方面。对于国内AI爱好者、开发者和内容创作者来说,它是一款值得深入测试的模型,尤其是在长文档分析、多模态内容理解和教育辅助等场景中。
实际使用建议:
开发者:利用Gemini 3.1的200万上下文,可以一次性输入整个代码仓库的文档和注释,让模型辅助生成单元测试或重构建议。
内容创作者:上传视频或音频文件,让模型自动生成字幕、摘要或时间轴标记,节省大量后期时间。
普通爱好者:通过KULAAI等国内直访平台,无需配置任何环境即可体验最新模型,建议从图片识别和长文章总结开始尝试。
需要提醒的是,所有AI模型都存在一定的幻觉率(Gemini 3.1实测约为2.3%),对于事实性要求高的内容(如医疗、法律、金融建议),务必人工复核。如果想一站式对比Gemini 3.1与GPT-4o、Claude 3.5的实际表现,可以访问KULAAI直接进行多模型测试,目前该平台提供的免费额度足以支撑日常研究和学习。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)