【langchain】核心源码create_agent解析二
前言:接着【langchain】核心源码create_agent解析一之后,我们开始分析源码给出的一个栗子。
官方示例代码如下:
from langchain.agents import create_agent
def check_weather(location: str) -> str:
'''Return the weather forecast for the specified location.'''
return f"It's always sunny in {location}"
graph = create_agent(
model="anthropic:claude-sonnet-4-5-20250929",
tools=[check_weather],
system_prompt="You are a helpful assistant",
)
inputs = {"messages": [{"role": "user", "content": "what is the weather in sf"}]}
for chunk in graph.stream(inputs, stream_mode="updates"):
print(chunk)
通过阅读以上代码,你可能会有以下几点疑惑:
- 在调用
create_agent方法时,为什么LangChain能识别check_weather函数,因为check_weather函数并没有传递任何的参数?而实际上直接调用这个方法,需要传递location字符串? - 其次
inputs = {"messages": [{"role": "user", "content": "what is the weather in sf"}]},为什么要使用这样的格式定义inputs参数呢? - 最后为什么要使用
stream_mode="updates"模式呢?
第一个问题
在调用create_agent方法时,为什么LangChain能识别
check_weather函数,因为check_weather方法并没有传递任何的参数?而实际上直接调用这个函数,需要传递location字符串?
首先查看源码,官方定义的是 tools: A list of tools, dict, or Callable.,如果为 None 或空列表,Agent 将仅包含一个没有工具调用循环的模型节点。更多信息,请参阅 Tools工具。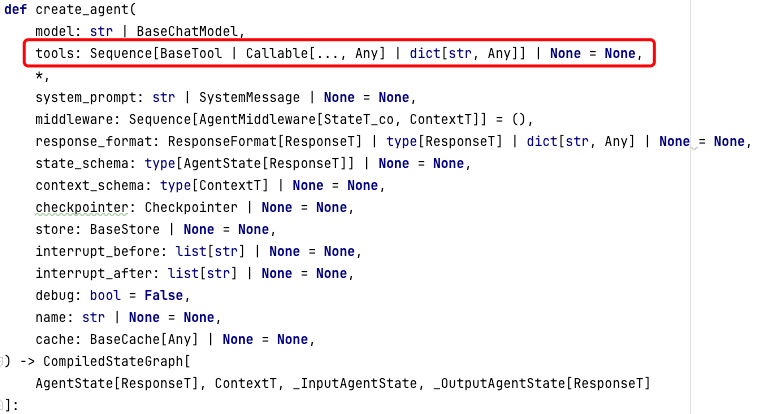
LangChain 能够准确识别 check_weather 方法的参数、名称和描述,主要依赖于 Python 的 自省(Introspection) 机制,具体是通过将普通函数转换为 LangChain 标准的 BaseTool 对象来实现的。
具体展开说说:
- 自动包装为
StructuredTool
当你将普通函数check_weather传入tools列表时,create_agent内部(通常在ToolNode或工具初始化阶段)会检测到它是一个可调用对象(Callable),而不是一个已经实例化的BaseTool。
此时,LangChain 会使用StructuredTool.from_function方法将该函数包装成一个工具对象。这个过程会自动提取函数元数据。
- 利用 Python 内省机制提取元数据
A. 提取参数 Schema (args_schema)
机制:使用 Python 标准库中的inspect模块。
过程:
读取函数的签名(Signature):
inspect.signature(check_weather)。
获取参数名:location。
获取参数类型注解:str。
生成 Pydantic 模型:根据这些信息,动态创建一个 Pydantic BaseModel 子类。例如:
class check_weatherArgs(BaseModel):
location: str = Field(..., description='...')
这个 Pydantic 模型就是 LLM 需要遵循的参数结构。LLM 在生成工具调用时,必须输出符合此 JSON Schema 的参数。
B. 提取工具名称 (name)
机制:读取函数的 name 属性。
结果:check_weather.__name__ 得到字符串 “check_weather”。这就是 LLM 在调用工具时需要使用的工具 ID。
C. 提取工具描述 (description)
机制:读取函数的文档字符串(Docstring),即 doc 属性。
结果:check_weather.__doc__ 得到字符串 “Return the weather forecast for the specified location.”。
作用:这段描述会被放入 System Prompt 或工具定义中,告诉 LLM 什么时候应该调用这个工具。
- 最终生成的工具定义
经过上述处理后,check_weather 在内部被转换成了类似以下的结构(伪代码):
{
"name": "check_weather",
"description": "Return the weather forecast for the specified location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": ""
}
},
"required": ["location"]
}
}
- LLM 如何调用
提示:LangChain 将上述 JSON Schema 发送给 Anthropic Claude 模型。
决策:Claude 分析用户问题 “what is the weather in sf”,发现需要天气信息,且有一个名为check_weather的工具可用。
生成:Claude 生成一个工具调用请求,参数为{"location": "sf"}。
执行:LangGraph 接收到这个请求,找到对应的check_weather函数,并将location="sf"作为关键字参数传入执行:check_weather(location=“sf”)。
最佳实践建议: 为了让 Agent 更聪明,务必写好 Docstring(描述清楚工具用途)和 Type Hints(确保参数类型正确),因为这两者是 LLM 理解如何正确使用工具的关键依据。
第二个问题
其次
inputs = {"messages": [{"role": "user", "content": "what is the weather in sf"}]},为什么要使用这样的格式定义inputs参数呢?
inputs 之所以设计为 {"messages": [...]}这种字典格式,主要基于 LangGraph(LangChain 底层的状态图引擎)的核心设计理念:基于状态(State-based)的工作流。
具体原因如下:
- 符合 AgentState 的结构定义
create_agent返回的是一个编译后的StateGraph。在 LangGraph 中,每个节点(Node)之间的数据传递是通过一个共享的 State(状态) 对象进行的。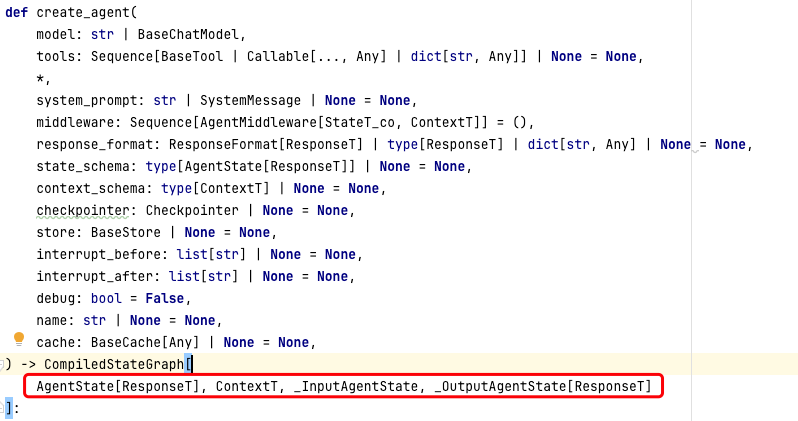
默认的 Agent 状态 schema 是 AgentState(或用户自定义的扩展)。AgentState 的核心字段通常包含 messages(消息列表)。
因此,启动图执行时,必须提供符合 State Schema 结构的初始数据。字典键 "messages" 直接对应 State 中的字段名。
-
支持状态的增量更新(Reducer 机制)
LangGraph 的状态管理不是简单的“覆盖”,而是“合并/追加”。messages字段在 State 定义中通常关联了一个 Reducer 函数(例如operator.add或自定义的追加逻辑)。
当你传入{"messages": [user_msg]}时,Graph 不会用这个列表替换掉状态中已有的所有消息,而是将其追加到现有的消息历史中。
这种设计使得 Agent 能够维护多轮对话的上下文记忆。 -
统一且灵活的输入接口
使用字典作为输入有以下优势:
解耦:调用者不需要知道内部具体的类实例(如HumanMessage对象),只需提供标准化的字典格式(Role-Content 结构),LangChain 内部会自动将其转换为相应的 Message 对象。
扩展性:如果用户通过state_schema扩展了状态(例如添加了user_id或metadata字段),只需在输入字典中增加对应的键值对即可,无需更改函数签名。
# 例如扩展了状态后,输入可以变成:
inputs = {
"messages": [{"role": "user", "content": "..."}],
"user_id": "12345",
"metadata": {"source": "web"}
}
第三个问题
最后为什么要使用
stream_mode="updates"模式呢?
与 stream_mode="updates" 配合,代码中使用了 graph.stream(inputs, stream_mode="updates"):inputs:是图的初始状态种子。updates:流式输出的是每个节点执行后对状态产生的增量更改(Delta)。
这种设计允许开发者清晰地看到 Agent 每一步(模型调用、工具执行)是如何一步步修改 messages 列表的,而不是每次都返回完整的庞大状态对象。inputs 这样设计是因为 LangGraph 是一个基于状态机的框架。{"messages": [...]} 是告诉状态机:“这是对话的起始消息,请将其放入状态管道的 messages 通道中开始运行。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)