浅谈扩散模型如何编织创意图像的魔法
文生图模型——创意图像
我这里以拟人的例子来描述,想象一下,你请了一位画家朋友帮你画一幅画。
你说:“我想要一幅独一无二的杰作,要有创意,要让我眼前一亮!”
画家点点头,挥毫泼墨,画出了一幅抽象表现主义大作——色彩斑斓、构图大胆,但完全看不出你想要的是什么。
你看了画像后,马上改口说:“等等,我是想要一只戴着墨镜的柯基犬在沙滩上冲浪。”
画家跟你的描述,又画了一幅,这次确实是一只柯基,墨镜也对,沙滩也有,但是他画的是照片级写实风格,跟你上周在百度图片上看到的那张热门图片一模一样。
你崩溃了:“就不能既有创意,又听指挥吗?”
所以这位画家就是视觉生成模型。
它有"职业病"
生图模型有个天生的"职业病":它这辈子见过的图太多了(动辄数亿张),以至于它画每一笔时,脑子里都在疯狂"百度图片搜索"——“这张图我见过类似的吗?这样画安全吗?用户会喜欢吗?”
结果呢?
- 要多样性? 它容易放飞自我,画出来的东西你根本不认识。
- 要可控性? 它又变得像复读机,只会"缝合"见过的图,毫无新意。
创意和听话,仿佛天生水火不容:
这就像刚刚上面说的画家作画一样,你说"要一副独一无二的画",他就挥毫泼墨,画出了一幅抽象表现主义大作;你说"要一只戴着墨镜的柯基犬在沙滩上冲浪的画像",他画出来的画像跟百度图片上的一模一样。
算法工程师的"调解方案"
为了治好这位画家的"性格分裂",AI界的技术大佬们操碎了心,在不同模型架构里玩起了"平衡术":
| 技术方案 | 角色定位 | 调解思路 |
|---|---|---|
| 卷积神经网络 (CNN) | 老派素描师 | 擅长捕捉局部纹理细节,像用放大镜观察世界,稳但容易"套路化" |
| ResNet | 记忆增强师 | 加了"快捷通道",让信息传递不丢失,画得更深更准 |
| Transformer + 自注意力 | 全局构图师 | 能同时关注画面所有角落的关系,“这只手要和那只手协调”,但计算量爆炸 |
| CLIP | 翻译官 | 把"文字指令"翻译成"视觉语言",让模型终于能听懂人话了 |
但说到底,这些花里胡哨的架构,底层玩的都是同一套数学游戏:
向量空间里的特征信息 ——把图片、文字、风格、构图,统统压成高维空间里的一个个点,计算它们之间的距离、角度、相似度。创造力?不过是特征向量的"合理插值";可控性?不过是把指令向量"锚定"在生成路径上。
所以我们永远逃不开:数学空间、向量、特征!
文生图模型的"成长日记"——从模糊幻影到栩栩如生
婴儿期:AE(1986年)——“我是个会自我修炼的压缩天才”
1986年,这个孩子刚出生,名字叫自编码器(AutoEncoder)。别看它年纪小,它已经掌握了"自监督学习" 这门独门绝技——自己考自己,自己给自己打分。
它的"左右手"分工
AE有两个形影不离的兄弟:
- Encoder(编码器):左边的"侦探",火眼金睛找特征
- Decoder(解码器):右边的"画家",拿着特征还原图
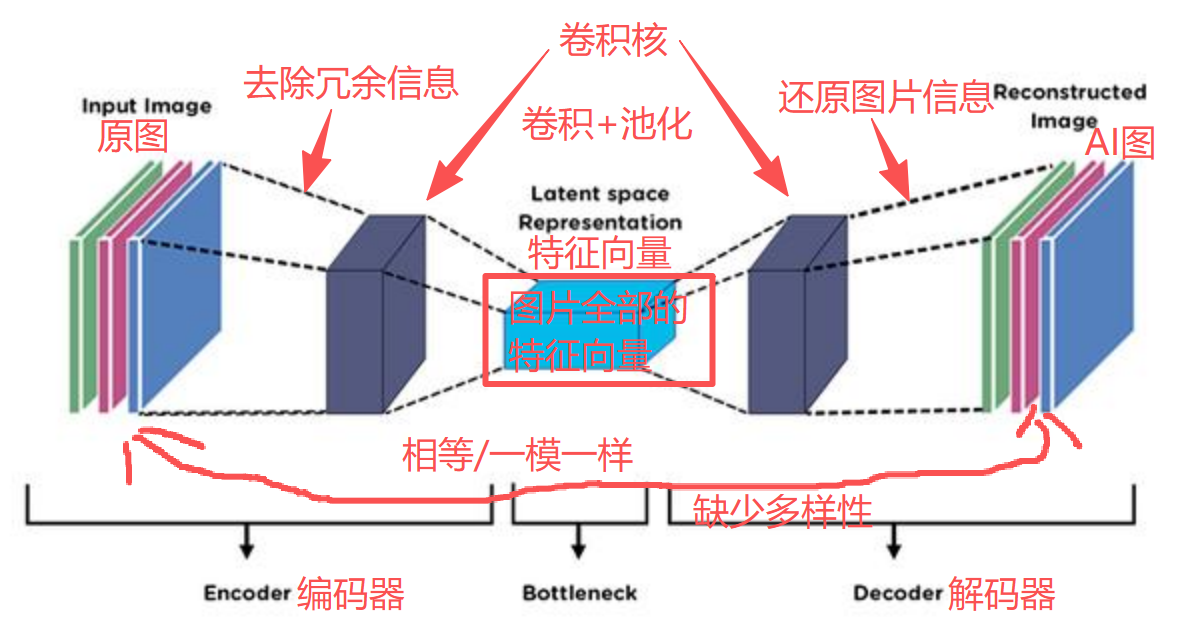
工作流程就像一场"传话游戏":
你扔给Encoder一张图(比如2000×3000像素的大图,白茫茫一片,中间写个小数字"2"),它开始疯狂做卷积——卷啊卷,卷啊卷,把图越卷越小,最后压缩成一小撮特征向量。
"几百万像素?太浪费了!"Encoder得意地说,“你看这张图,大片白色都是冗余信息,我只保留真正的精华——那个’2’的位置、形状、笔画特征,全藏在这堆向量里了!”
然后Decoder接过这堆向量,反向卷积,层层放大,试图把图还原出来。
一开始,这俩兄弟都很蠢——Encoder丢三落四,Decoder手残画歪,还原出来的图跟原图八竿子打不着。
但它们有个秘密武器:自监督。
输入图就是标准答案。Encoder和Decoder对着原图反复较劲——"这次差多少像素?损失函数算一算,反向传播调参数!"经过无数次迭代,它们终于修炼成精:Encoder能精准抓住核心信息,Decoder能用这点信息完美还原原图。
这证明了什么? 图片里真的有大量"水分"(冗余信息),不需要几百万维的数学空间,一小撮特征向量就够了!
"单飞"也能活
这对兄弟长大后可以单独出道:
- Decoder单飞:你给我特征向量,我能生成图(虽然只会复读见过的图)
- Encoder单飞:你给我图,我输出特征向量,可以拿去做分类任务(比如"这是猫还是狗?")
但说到底,AE就是个老实巴交的复读机——它只会把见过的图压缩再还原,从没见过的新东西?不会画,没创造力,多样性为零。
就像一个学生把课本背得滚瓜烂熟,但让他写篇新作文?当场傻眼。
幼儿期:VAE(2013年12月)——“我学会了’脑补’的魔法”
AE在"复读机"的岗位上干了27年,虽然压缩解压玩得溜,但创造力为零——让它画一只没见过的新狗?它只会摊手:“没背过,不会。”
2013年,它的进化版VAE(变分自编码器) 登场了。这次升级的核心就一句话:
“我不记死向量,我学的是’高斯分布规律’!”
从"记坐标"到"学地形"
AE的老做法:
输入10张狗图 → Encoder输出10个明确的特征向量(就像记10个精确地址)→ Decoder照着地址还原。
问题是: 这10个地址之间一片空白。你问它:"第11个地址在哪?"它一脸懵。
VAE的新玩法:
输入10张狗图 → Encoder不再记死地址,而是画一张"地图"——高斯分布曲线。
“这10只狗,不是10个孤立的点,而是同一个’狗分布’上的采样!”
算法公式:
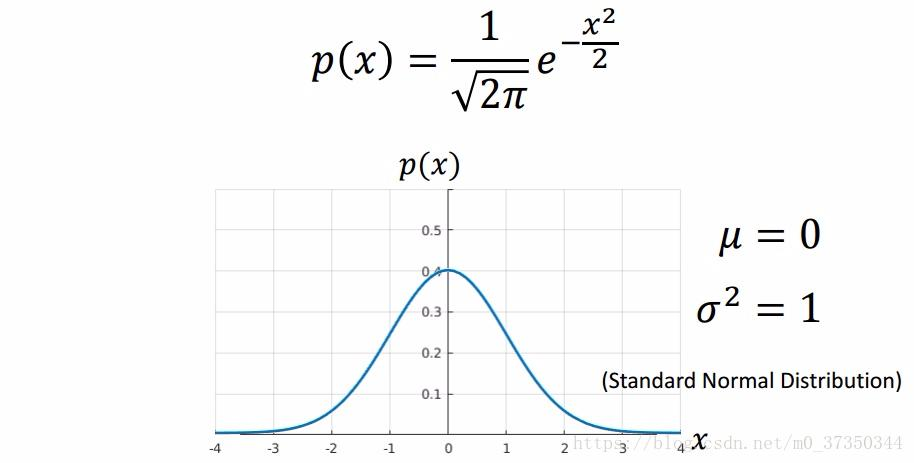
它输出两个关键参数:
- μ(均值):分布的中心在哪(x轴上的位置)
- σ(标准差):分布有多"胖"(σ越小头越尖,σ越大头越钝)
三维得高斯分布图:
"随机漫步"生成法
VAE的Encoder找到"狗分布"的μ和σ后,不直接解码——它玩了个花活:
- 在分布曲线上随机撒点(加个偏移量ε)
- 把这个新坐标扔给Decoder
- Decoder还原出一张图
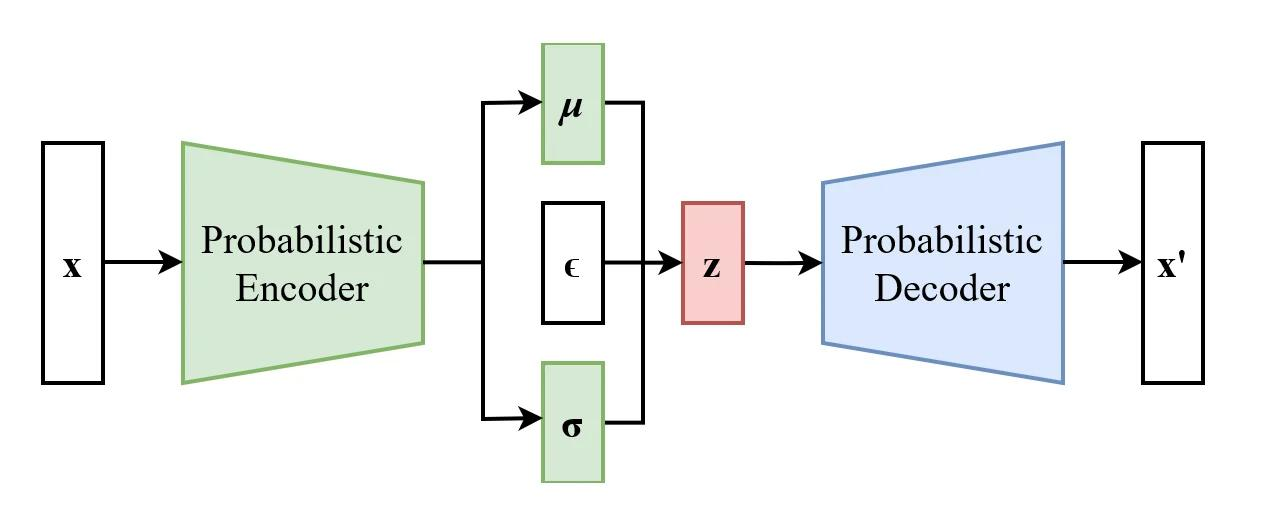
“看!这只狗世界上从没存在过,但看起来就是像狗!”
这就是多样性的诞生——同一个高斯分布里,无限采样,无限新图。
虽然这些"脑补狗"还是糊得像 Monet 的睡莲(高斯分布的模糊特性),但意义重大:
模型终于从"复读机"进化成了"印象派画家"——能创造, albeit 有点朦胧美。
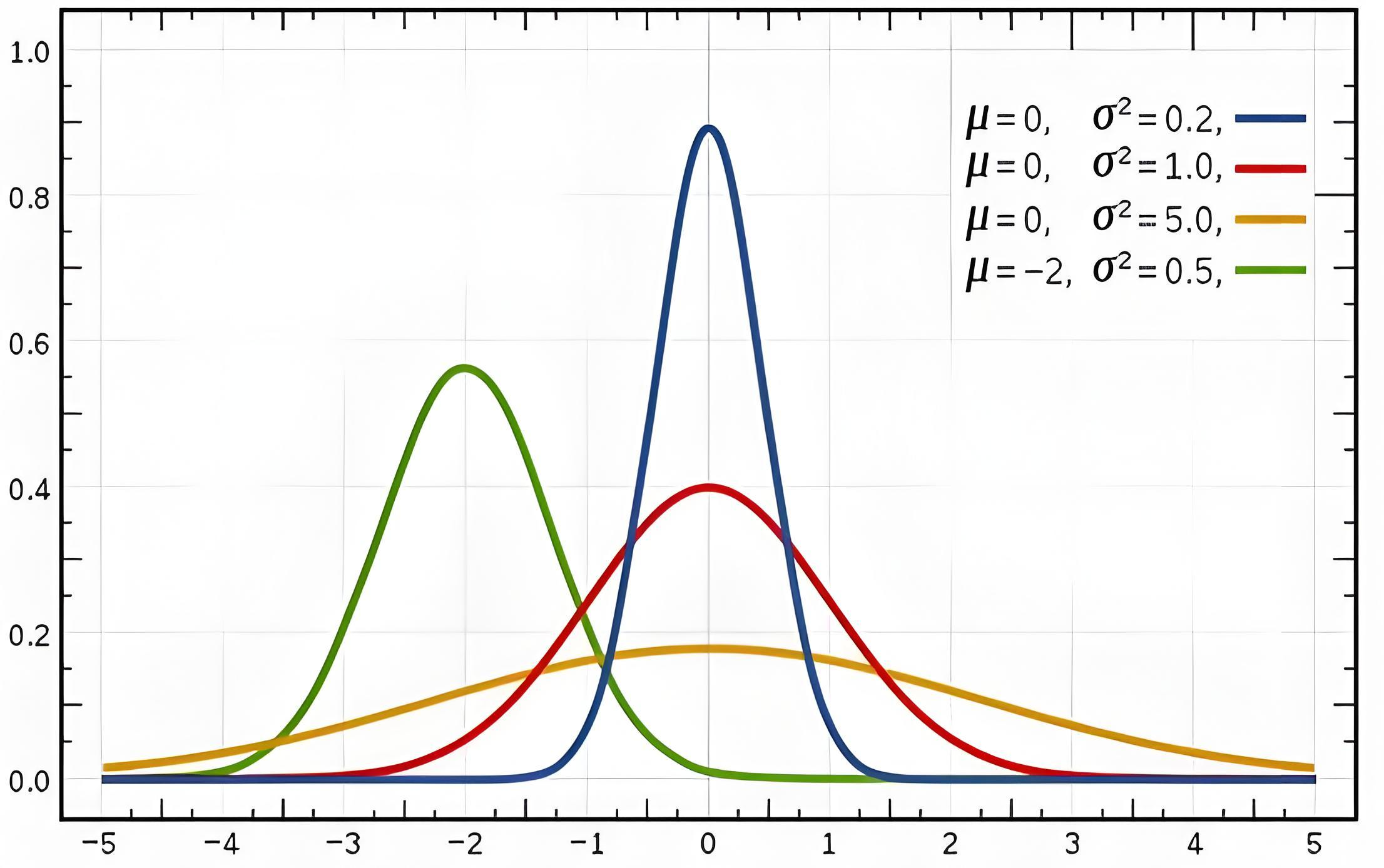
为什么高斯分布这么牛?
高斯分布(正态分布)是大自然的通用语言:
- 人的身高、考试成绩、测量误差…都服从这个"钟形曲线"
- 不管多少维,高斯分布都能描述复杂空间的概率规律
VAE的假设很朴素:真实世界的图片,也藏在某个高维高斯分布里。只要找到这个分布的参数,就能在数学空间里"漫步",生成合理的新样本。

历史地位
VAE是第一代文生图模型的祖师爷。
后来那些能根据文字生成图片的早期模型,骨子里都是VAE的逻辑:
“文字描述 → 找到对应的高斯分布 → 采样生成 → 解码成图”
创造力的大门,从此打开。
青春期:GAN(2014年6月)——“左右互搏的武痴”
VAE虽然学会了"脑补",但画出来的图总是雾蒙蒙的,像隔着毛玻璃看世界。2014年,一个疯狂的点子诞生了——让两个AI互相打架!
这就是GAN(生成对抗网络),江湖人称**“左右互搏之术”**。
师徒对决:一个造假,一个打假
GAN收了两个徒弟,天生冤家:
| 角色 | 人设 | 绝技 | 目标 |
|---|---|---|---|
| Generator(生成器) | 造假大师 | 把随机噪声变成"逼真"图片 | 骗过辨别器,“我这图是真的!” |
| Discriminator(辨别器) | 鉴宝专家 | 火眼金睛辨真假 | 识破造假,“这是AI画的,假的!” |
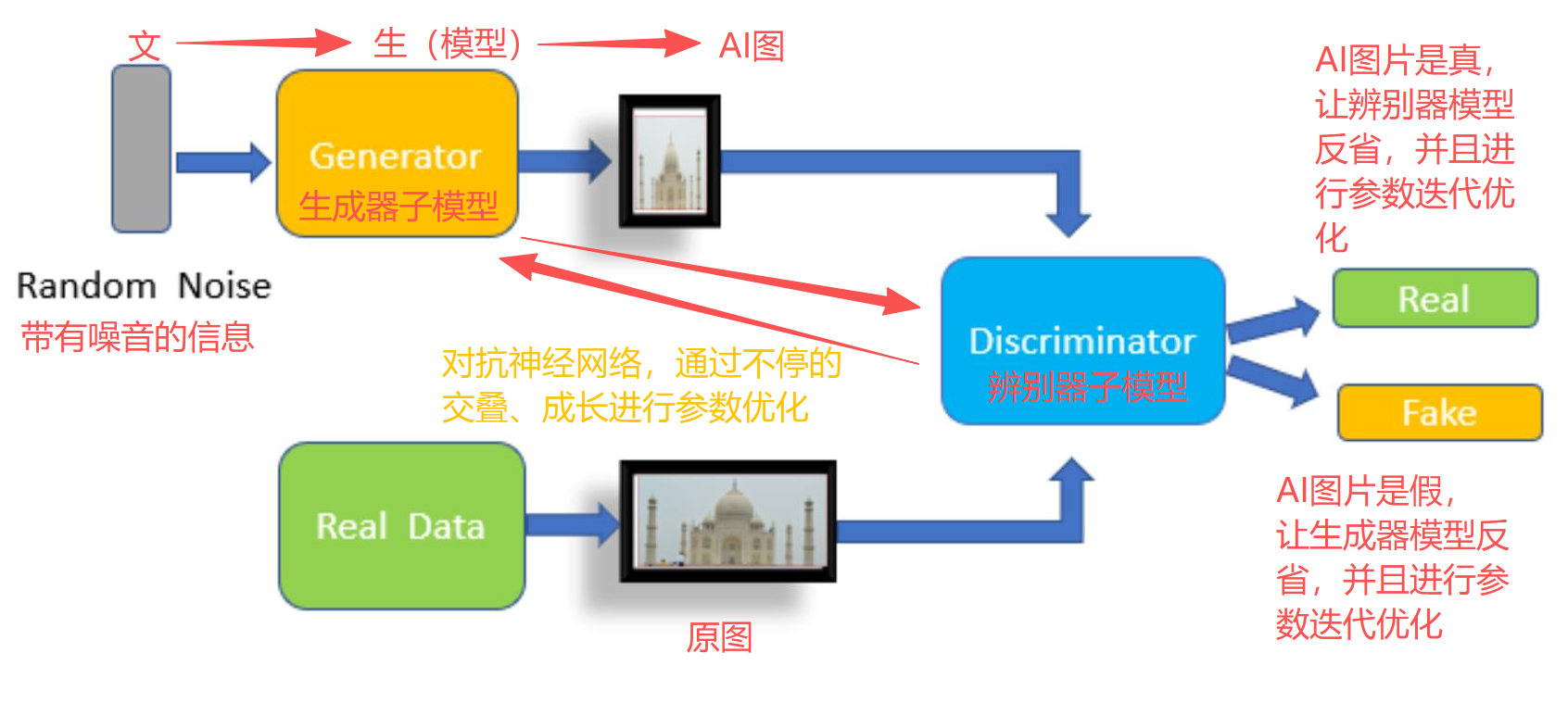
训练日常就像谍战片:
- 生成器拿到一团随机噪声(像电视雪花屏),"唰"地变出一张图:“师傅,看看我这幅《蒙娜丽莎》,刚从卢浮宫拍的!”
- 辨别器面前摆着两张图:一张是真图(Real Data),一张是生成器刚造的假图。它要判断:“左真右假?还是左假右真?”
- 第一轮对决:
- 辨别器说:“右边这幅,瞳孔反光不对,假的!”
- 反馈给生成器:“你参数太蠢,回去反省!优化!迭代!”
- 第二轮对决:
- 生成器升级后再来:“师傅,这次呢?”
- 辨别器眯眼细看:“…这皮肤纹理,这光影…好像是真的?”
- 反馈给辨别器:“你眼力不行,回去练!优化!迭代!”
- 无限循环…
这就是对抗训练(Adversarial Training)——在欺骗与识破的博弈中,双双进化。
造假大师的"职业病"
生成器为了赢,练就了一身以假乱真的绝技:
- 皮肤毛孔?清晰!
- 头发丝?根根分明!
- 眼神光?恰到好处!
但它得了严重的"抄袭综合征":
“只要画得像真图,就能骗过师傅!那我干嘛创新?直接复制粘贴网上见过的图不就行了?”
结果就是模式崩溃(Mode Collapse)——生成器发现某类脸最容易骗过辨别器,就疯狂复制这一种,其他风格?不学了,没必要。
你让它画"赛博朋克风格的猫",它给你一张普通橘猫高清写真——确实真,但跟你的要求八竿子打不着。
"聋子画家"的困境
更致命的是,GAN是个 “聋子” ——听不懂人话。
| 你喊的 | 它听到的 | 它画的 |
|---|---|---|
| “一只宇航员骑在马上” | “随便画张图” | 可能是风景、可能是人脸 |
| “油画风格” | “噪音输入” | 照片级写实 |
| “赛博朋克猫” | “随机种子123” | 普通橘猫 |
它没有指令遵循能力(Prompt Following)。输入文字?对它来说只是另一团噪音,触发一个随机的生成结果。
你想控制它?门儿没有。 它就像一位技艺高超但完全自我沉浸的画家,关在黑屋里疯狂作画,画出来什么算什么。
算法工程师的噩梦
GAN的训练现场,堪比修罗场:
- 生成器太强?辨别器被吊打,失去反馈意义,训练崩溃
- 辨别器太强?生成器永远骗不过,梯度消失,原地踏步
- 两者平衡?转瞬即逝的平衡点,稍微动下学习率就崩
算法工程师看着忽好忽坏、时稳时炸的训练曲线,头发大把大把掉…
GAN是视觉生成史上的"技术奇点"——它第一次证明了AI可以画出照片级真实的图。
但它也留下了两大遗产问题:
- 多样性 vs 真实性:为了骗过辨别器,它选择安全地抄袭,而非大胆地创新
- 可控性缺失:没有CLIP翻译官的年代,它就是个听不懂指令的哑巴天才
这些问题,要等到扩散模型+CLIP的时代,才能被真正解决…
闭关期:Diffusion Model(2015年)& DDPM(2020年6月)——“从噪声中顿悟”
Diffusion Model
GAN那对师徒打得天昏地暗,算法工程师念经脱发。2015年,一位"佛系"研究者看着窗外的落叶,突然悟道:
“与其让两个AI打架,不如…让图片自我毁灭,再教它重生?”
这就是扩散模型(Diffusion Model)——一部"向死而生" 的修炼手册。
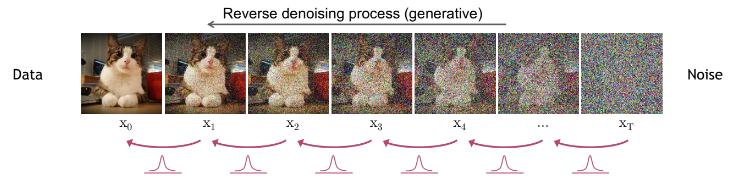
第一阶段:加噪——把杰作毁成雪花
想象你有一间干净的房间(一张清晰的狗图X₀),你拿着香水喷雾器(噪声生成器),开始疯狂喷洒:
物理直觉:
香水分子从香水的喷头,逐渐扩散到整个房间,最终均匀分布——这就是熵增,自然界最朴素的规律。
数学实现:
- 一张100×100的图 = 10,000个像素点,每个都是0-255的数值。
- 每一步,给每个像素加上服从高斯分布的噪声(像往清水里滴墨汁),a1像素向量 + b1噪声向量。
- 噪声与像素值相加,超过255就回绕(模运算),if a1像素向量 + b1噪声向量 > 255: a1像素向量 + b1噪声向量 - 255。
“加噪几百步、上千步后…”
清晰的狗 → 模糊的狗 → 狗的轮廓 → 色块 → 纯白噪声(雪花屏)

关键洞察: 这个毁灭过程是可预测的、有数学规律的——每一步加的噪声都服从已知的高斯分布,就像有编号的毁灭档案。
第二阶段:去噪——从雪花中召唤原图
现在,我们训练一位"还原大师"——UNet模型。
UNet的独门绝技:
| 能力 | 实现方式 | 作用 |
|---|---|---|
| 抓结构 | 卷积+池化(下采样) | 理解"这是狗的整体轮廓" |
| 抠细节 | 反卷积/上采样(跳连) | 还原"耳朵的毛发纹理" |
训练过程:
- 拿一张第t步的噪声图(比如"加了500次噪的狗")
- 告诉UNet:“这是第500步,原图是清晰的狗”
- UNet学习:怎么去掉这层噪声,还原成第499步的样子?
“不是一步登天,而是步步为营。”
经过成千上万次"去噪练习",UNet终于练就"从混沌中重建秩序" 的神通。
生成新图的魔法:无中生有
训练完成后,生成过程极其反直觉:
- 从纯随机噪声(雪花屏)开始
- 问UNet:“假设这是第1000步,往回走一步该是什么样?”
- UNet去掉一层噪声 → 得到第999步的"稍清晰一点的噪声"
- 重复1000次…
- "嘭!"一张从未存在过的狗图,从虚无中诞生!
不需要见过这张图,只要学会"去噪的规律",并且有指导员在,就能从噪声中"召唤"新图。
扩散模型 = 雪花图 + 指导员
DDPM的优化:从"画像素"到"猜噪声"
2020年,DDPM(去噪扩散概率模型) 带来了关键优化:
| 原版Diffusion | DDPM优化 |
|---|---|
| UNet直接输出10000个像素值(0-255) | UNet只输出10000个噪声值(符合高斯分布) |
| 算力爆炸,训练缓慢 | 计算量大减,效率飙升 |
| 像素空间硬算 | 噪声空间概率建模,数学上更优雅 |
核心思想转变:
“我不需要模型画出一整张图,我只需要它猜出这一步加的是什么噪声!”
因为噪声是高斯分布的,猜噪声比猜像素简单得多、快得多。
就像老师批改试卷:
- 原版:学生重写整张卷子
- DDPM:学生只写"这一步错在哪",老师把错的地方擦掉,分数自然修正
扩散模型的"性格特点"
| 优点 | 缺点 |
|---|---|
| 训练稳定(不用伺候GAN那对冤家) | 生成太慢(要迭代几百步) |
| 生成质量极高(细节清晰) | 像老太太绣花,急死人 |
| 数学优雅(概率论基础扎实) | 需要大量计算资源 |
| 多样性天然丰富(噪声空间无限采样) |
简而言之,
Diffusion Model是"慢工出细活"的匠人,DDPM是"聪明干活"的优化师。
它们解决了GAN的训练不稳定和模式崩溃,但留下了速度的短板。
爆发期:2021-2022 ——“我不仅画得好,还听得懂人话了!”
扩散模型虽然画质惊艳,但有个致命问题——它是个"自闭画家"。你让它画"猫",它可能画狗;你说"赛博朋克风格",它给你水墨山水。没有指挥棒,它全凭心情发挥。
2021-2022年,三位"技术救星"接连登场,终于让这位画家戴上了助听器,拿起了指挥棒。
2021年5月:Diffusion Models Beat GANs ——“分类器当教官”
核心创新:Classifier Guidance(分类器引导)
之前的扩散模型,UNet只会盲目去噪——“把雪花变成清晰的…某种东西”。
现在,给UNet配了一位"教官"——Classifier(分类器)**:
| 角色 | 职责 | 工作流程 |
|---|---|---|
| UNet | 去噪执行者 | “第t步的噪声图,去掉噪声变成第t-1步” |
| Classifier | 质量监督员 | “等等,这看起来像猫吗?不像?调整方向!” |
训练阶段:
- 预训练时,UNet通过去噪还原图片,算误差
- 或者:输入噪声图,UNet预测噪声,跟实际加的噪声对比算误差
生成阶段:
- 每一步去噪后,Classifier跳出来打分:“这图有80%像猫,20%像狗”
- Guidance信号反馈给UNet:“往’更像猫’的方向调整!”
效果:
- ✅ 有方向了:能按类别生成(猫/狗/人)
- ✅ 多样性仍在:因为初始化是随机噪声
- ❌ 但有点粗糙:Classifier只认类别,不懂复杂描述
这就像军训——教官只会喊"向左转/向右转",你问"能不能转45度角跳个舞?"教官一脸懵。
2022年4月:DALL·E 2 ——“CLIP当翻译官”
OpenAI扔出王炸!它把自家CLIP模型和扩散模型缝在了一起,解决了"文字→图片"的翻译难题。
CLIP的绝技:
“文字变向量,图片也变向量。如果描述匹配,两个向量就贴贴(相似度高);不匹配,就远离(相似度低)。”
DALL·E 2的"虚线上下"架构:
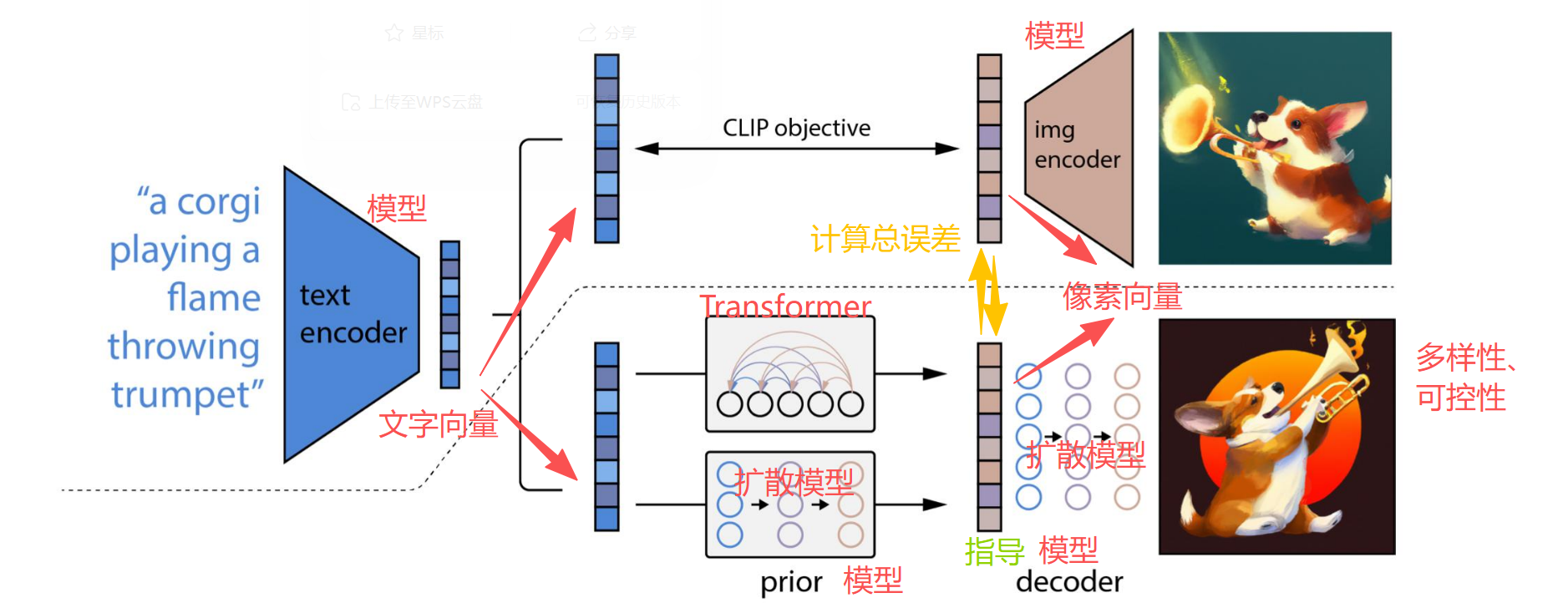
Prior模型的两种"性格":
| 架构 | 工作方式 | 特点 |
|---|---|---|
| 扩散模型版 | 文字向量加噪→去噪→生成图片向量 | 稳扎稳打,质量高 |
| Transformer自回归版 | 文字向量→生成新向量→拼接→再生成→循环 | 像接龙游戏,逐步构建 |
训练监督: 生成的图片向量,跟CLIP编码的真实图片向量对比。差得远?总误差反向传播,调整Prior参数!
Decoder的指挥棒: Img Encoder生成的图片向量,就是Decoder扩散模型的"指导员"——每一步去噪都要对照:“我生成的图,特征要跟这个向量匹配!”
历史意义:
- ✅ 真正的文生图:输入"宇航员骑在马上,油画风格",输出符合描述的图
- ✅ 语义对齐:文字和图片在同一个向量空间对话
- ❌ 但计算量还是大:在像素空间折腾,慢且贵
2022年7月:LDM(Latent Diffusion Model)——“在潜空间开外挂”
DALL·E 2虽然牛,但在像素空间做扩散就像用显微镜绣花——每一步都处理几百万像素,算力燃烧,钱包哭泣。
LDM的核心洞察:
“我干嘛在像素空间折腾?我去浅空间(Latent Space)玩啊!”
架构拆解:
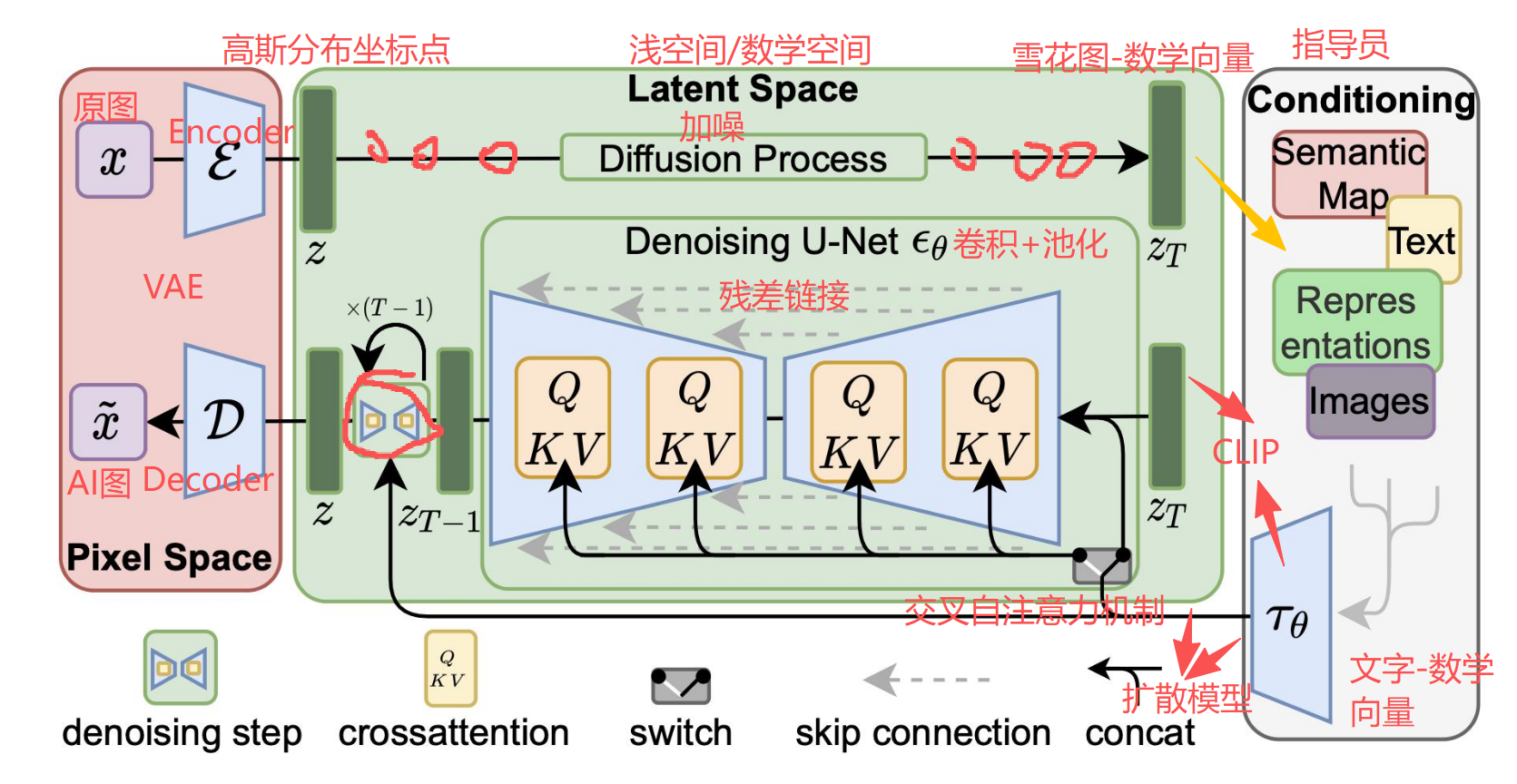
UNet的"强化外骨骼"——交叉注意力机制:

为什么浅空间是神来之笔?
| 像素空间 | 潜空间 |
|---|---|
| 文字 vs 图片 = 鸡同鸭讲(维度不同) | 文字向量 vs 图片向量 = 同场竞技(都是向量) |
| 每次输出都是图,文字看不懂 | 每次输出都是向量,文字能实时比对 |
| 计算量 = 几百万像素 | 计算量 = 几千维向量 |
| 慢、贵、难控制 | 快、省、精准控制 |
多指导员系统:
LDM不只有一个文字指挥棒,而是**“交响乐队指挥”**
- Semantic Map:“按这个布局画”
- Text:“内容是猫在弹琴”
- Representations:“风格像梵高”
- Images:“参考这张图的色调”
每个指导员都通过交叉注意力,在UNet的每一步去噪中"实时纠偏"。
爆发期总结:三重突破
| 时间 | 模型 | 突破点 | 解决的问题 |
|---|---|---|---|
| 2021.5 | Diffusion Beats GANs | Classifier Guidance | 有方向:从盲目生成到按类别生成 |
| 2022.4 | DALL·E 2 | CLIP对齐 + Prior模型 | 听得懂:文字能指挥图片生成 |
| 2022.7 | LDM | 浅空间扩散 + 多指导员 | 又快又准:计算量暴跌,控制精度暴涨 |
从"自闭天才"到"全能艺术家":
- 2015-2020:扩散模型学会"从毁灭中创造",但聋哑盲目
- 2021:Classifier给了模型方向感(虽然粗糙)
- 2022:CLIP给了模型听力,Prior给了模型翻译能力,浅空间给了模型速度
终于,我们可以对AI说:
“画一只戴着墨镜的柯基犬,在赛博朋克风格的东京街头骑摩托车,霓虹灯反射在墨镜上,油画质感,8K高清。”
而它,真的能听懂,并且画出来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)