YOLOv5至YOLOv12升级:PCB电子元件识别系统的设计与实现(完整代码+界面+数据集项目)
摘要:本文面向PCB电子元件在小目标密集、反光遮挡与类别相似等条件下的识别需求,设计并实现一套可落地的桌面检测系统。系统以YOLOv5至YOLOv12为核心模型族(共8种算法),支持在同一界面中加载不同权重并对图片、视频与摄像头输入进行实时检测,输出元件类别、置信度与可视化标注结果,同时提供Conf/IoU调节、类别统计、结果导出与记录管理等功能。界面采用PySide6开发,并结合SQLite实现登录注册、用户配置与检测历史持久化。文中给出数据集构建、标注与预处理流程,以及多模型对比实验思路与工程复现要点,项目附完整代码、界面与数据集资源,便于学习与二次开发。
讲解视频地址:https://www.bilibili.com/video/BV1QeQuBrEgC/
文章目录
1. 前言综述
印刷电路板(PCB)承载着电子元件的机械固定与电气互连,伴随高密度封装与小型化趋势,生产线上对漏装、错装、极性反向、偏移与焊点异常等问题的检出要求持续抬升,自动光学检测(AOI)因此从“抽检工具”逐步演化为质量控制闭环中的关键环节。1 进一步地,面向“元件级理解”的任务往往不仅要检测元件位置,还要完成面向BOM/位号的核验与匹配,这对密集小目标、跨板域迁移与长尾类别提出了更强约束。2 近年公开数据逐渐覆盖多类电子元件场景,例如ElectroCom61以多类别、复杂拍摄条件为导向组织数据,有助于推动元件检测与分类在真实工业光照与背景变化下的可复现评测。3 (Missouri S&T)
表1 代表性研究与公开数据集对比(面向PCB元件/缺陷视觉检测)
| 研究主题 | 代表工作(年份) | 任务与数据集(规模) | 方法要点 | 优势 | 局限与启示 |
|---|---|---|---|---|---|
| 传统AOI与规则法脉络 | Moganti 等(1996) (ScienceDirect) | 以模板匹配、差分、形态学为主的PCB自动检测体系 | 给出PCB检测算法分类树,并系统总结当时商用检测系统与关键环节 | 可解释性强、工程落地成熟 | 对光照、对位与工艺漂移敏感,跨产线泛化弱;为后续“数据驱动”路线提供对照基线 |
| 综述与系统视角 | Zhou 等(2023) (ScienceDirect) | 2D/3D AOI、AXI 等多模态缺陷检测研究综述,并汇总评估指标与公开数据集 | 从采集、处理、识别到闭环反馈讨论PCB视觉检测 | 提供“数据—算法—应用”三层挑战与趋势 | 对“元件级识别”覆盖相对少;但其系统工程视角适合作为UI/数据库闭环设计的理论依据 |
| 深度学习差分范式与DeepPCB | Tang 等(2019) (arXiv) | 缺陷检测;DeepPCB(1,500 对模板/缺陷图像对,6类缺陷) | 基于模板图与待测图的成对输入,提出 group pyramid pooling 以覆盖多尺度缺陷 | 对齐良好场景下精度与速度兼顾 | 依赖模板与配准质量;启示是应在系统层加入对位校正与鲁棒预处理模块 |
| 合成数据集 HRIPCB | Huang 等(2020) (IET Research Journal) | 缺陷检测/分类;HRIPCB(1,386 张,6类缺陷,合成数据) | 提供公开合成数据集,并给出参考式检测与CNN分类基线 | 便于方法复现与对比 | 合成域与真实产线存在域差;启示是训练需引入域自适应或更贴近真实的采集策略 |
| 小缺陷友好的金字塔特征 | Ding 等(2019) ([IET Research Journal][5]) | 缺陷检测;面向 tiny defect | 构建特征金字塔以增强对小目标的表征与融合 | 对微小缺陷更友好 | 复杂背景下仍易误检;启示是应配合注意力或更强的多尺度融合颈部结构 |
| 大规模真实缺陷数据集 DsPCBSD+ | Lv 等(2024) ([Nature][6]) | 缺陷检测;DsPCBSD+(10,259 张,9类缺陷,标注 20,276 个缺陷框) | 来自真实产线AOI图像,类别按成因/位置/形态划分 | 更贴近工业分布与噪声 | 主要是2D外观缺陷;启示是模型评测应优先覆盖真实产线分布而非仅合成集 |
| 轻量化实时缺陷检测(含DsPCBSD+验证) | Liang 等(2025) ([ORCID][7]) | 缺陷检测;在 DsPCBSD+ 等数据集验证 | 以轻量化结构与改进特征融合/检测头提升小缺陷检测,同时控制参数量与计算量 | 兼顾速度、精度与部署成本 | 方法多为“结构模块化改造”,跨任务迁移仍需再验证;启示是YOLO系改造应围绕小目标与密集目标的有效感受野设计 |
| PCB元件级一拍检测(One-shot) | Spadaro 等(2024) ([Springer][8]) | 元件检测/错漏装识别;高分辨率整板图像(工业合作采集) | 基于 YOLOv5 做小元件友好改造,并用 leave-one-out 讨论少样本泛化 | 贴近产线“整板一拍”需求 | 小元件仍是主要瓶颈;启示是需要更强的小目标特征与更精细的标注体系(封装/极性/丝印干扰) |
| 电子元件多类别公开数据 | Sayeedi 等(2025) ([ScienceDirect][9]) | 元件检测;ElectroCom61(多类别元件数据,提供公开数据链接) | 构建多类别元件检测数据,强调多环境条件与应用场景 | 便于教学与算法原型验证 | 与PCB整板密集场景仍有域差;启示是自建PCB整板数据集仍是工程系统的核心壁垒 |
| PCB芯片目标高速识别 | Yue 等(2025) ([Springer][10]) | 元件/芯片检测;以YOLOv7为基线的工业芯片识别 | 引入 Ghost 模块、注意力与轻量卷积改造,在速度与精度间取平衡 | 面向边缘端实时性指标明确 | 指标高但依赖具体采集条件;启示是系统应支持摄像头实时流与推理管线的低延迟优化 |
| YOLO系在通用检测上的关键节点 | Wang 等(2023) ([CVF Open Access][11]) | 通用检测(COCO) | 强调训练策略与结构改造以提升实时检测的精度-速度边界 | 对工业部署的“可训练改造”具有参考价值 | COCO 与PCB域差明显;需结合PCB密集小目标特点做再设计 |
| YOLO端到端化趋势 | Wang 等(2024) ([NeurIPS Proceedings][12]) | 通用检测(COCO) | 通过一致性双重分配推进 NMS-free 的端到端YOLO训练,并系统做效率-精度驱动的结构审视 | 有利于降低后处理延迟与工程复杂度 | 对小目标密集场景仍需专门验证;启示是UI系统可进一步简化后处理链路 |
| 注意力主导的实时检测器探索 | Tian 等(2025) ([arXiv][13]) | 通用检测(COCO) | 在实时约束下引入注意力中心框架,强调在速度可控前提下提升表征能力 | 对复杂背景与细粒度目标具潜力 | 工业端部署需评估显存/吞吐;启示是“注意力+轻量化”可能成为YOLO后续升级方向 |
| 中文期刊:面向微小缺陷的轻量检测 | Opto-Electronic Engineering(2026) ([OE Journal][14]) | 微小缺陷检测;滑窗切片等工程化策略 | 基于轻量YOLO分支并配合切片推理缓解缩放导致的微小目标丢失 | 更贴近“微小缺陷+大图”场景 | 切片带来算力开销与拼接策略问题;启示是系统需提供可配置的切片与合并策略 |
从研究脉络看,PCB视觉检测长期在“传统图像处理—机器学习—深度学习”路径上迭代,而面向缺陷与元件的统一建模、跨工况鲁棒性与工程部署约束,仍是该方向反复出现的主线问题。4 国内研究通常更强调与产线AOI成像条件的耦合建模(反光、阴影、丝印干扰、板面纹理等),并在小目标特征增强、难例挖掘与轻量化部署方面形成了较系统的经验总结。[5] 与此同时,面向SMT场景的轻量网络与端侧友好设计也在持续推进,例如PCBNet围绕缺陷检出在参数量与推理效率之间进行折中,为“可落地”的检测模型提供了工程参照。[6] (Springer)
数据层面的进展同样关键:DsPCBSD+等大规模数据集以真实AOI采集缺陷为基础,并提供YOLO/COCO等通用标注格式,使得不同检测器在同一数据协议下进行可比性评估成为可能。[7] 方法层面,一阶段检测器以端到端的密集预测范式显著提升了速度上限,YOLO的提出奠定了实时检测在工业场景中“精度—速度”折中优化的基本范式。[8] 针对PCB电子元件与缺陷普遍呈现的小目标特性,多尺度特征金字塔通过自顶向下融合与横向连接增强高层语义的尺度泛化能力,已成为提升微小目标召回的基础结构之一。[9] (X-MOL)
在网络结构演化上,Transformer主干通过分层窗口与全局上下文建模改善了复杂背景下的表征能力,为细粒度元件纹理、遮挡与相邻目标粘连带来的判别困难提供了新的结构化先验。[10] 工业落地最常见的起点仍是工程化程度更高的YOLOv5,其模块化实现与成熟训练配方使其成为构建行业数据集基线与快速迭代原型的高性价比选择。[11] 面向工业应用优化的YOLOv6进一步强调硬件友好结构与训练策略设计,在保持实时性的同时提升了在通用基准上的精度与吞吐表现。[12]
随着YOLO系列持续升级,YOLOv7以“可训练的Bag-of-Freebies”为核心思路,在不显著增加推理开销的前提下改善了训练阶段的有效增益获取方式,为实时检测器的配方化迭代提供了清晰范式。[13] 站在工程实现的角度,Ultralytics生态对YOLO家族的版本演进与部署链路(导出、量化、推理后端)进行了系统化梳理,使得跨版本对比与工程选型更具可操作性。[14] 最新的YOLOv12将注意力机制进一步前置为架构中心,试图在保持实时性约束下获得更强的表征能力,为密集小目标与复杂背景下的检测性能上限提供了新的实现路径。[15] (CVF Open Access)
面向PCB电子元件识别这一具体任务,仍需直面若干工程难点:元件尺度极小且密集、丝印与铜箔纹理导致背景强干扰、金属封装带来高反光与局部过曝、同类元件外观差异极小但跨板域差异显著,以及类别长尾与标注成本高等问题会共同放大模型泛化与稳定性风险。老思在本文(本博客)中的主要工作,是以YOLOv5至YOLOv12为核心检测骨架完成同一PCB元件数据集上的系统性对比,并围绕小目标场景进行适配与改进,同时构建可复现实验的数据集划分与预处理流程,最后以PySide6实现支持多源输入、模型切换与结果管理的完整可用系统,并配套开放代码与项目资源包以便复现与二次开发。
主要功能演示:
(1)启动与登录:程序启动后进入登录界面,支持注册/登录/修改密码;登录成功后自动载入该用户的阈值参数、最近使用模型与历史检测记录,确保多用户下的数据隔离与可追溯性。
(2)多源输入与实时检测:主界面支持图片、文件夹批量、视频文件与摄像头四类输入源切换;推理过程中实时绘制检测框、类别与置信度,并同步显示当前帧耗时/帧率与类别统计,便于快速复核与定位问题样本。
(3)模型选择与对比演示:集成YOLOv5至YOLOv12多版本权重管理,支持一键切换模型在同一输入上对比检测效果;对比结果以统一可视化格式呈现,并支持导出保存,用于后续实验分析与版本选型。
(4)主题修改功能:新增主题配置模块,可切换界面配色、背景与图标风格并即时预览;主题设置随账户持久化保存,提升长时间使用场景下的可读性与个性化体验。
2. 数据集介绍
本文面向PCB电子元件识别任务构建并使用了一套四类目标检测数据集,共计 7,661 张图像,其中训练集 6,129 张、验证集 766 张、测试集 766 张,划分比例约为 80% / 10% / 10%。数据的类别体系围绕典型贴片与常见封装器件展开,分别为 Condensator(电容器)、Diode(二极管)、Resistor(电阻器) 与 Transistor(晶体管);标注采用YOLO目标检测通用的归一化边界框表示( x c , y c , w , h ∈ [ 0 , 1 ] x_{c}, y_{c}, w, h \in [0,1] xc,yc,w,h∈[0,1]),便于与YOLOv5–YOLOv12各版本训练管线直接对接。从你提供的标签统计图可以看出,样本实例数主要集中在电阻、电容与二极管三类,而晶体管实例明显偏少(千级量),呈现一定的长尾分布特征,这种不均衡会在训练中放大“易混类别”的误检与召回波动,因此在后续实验中更需要关注每类的AP与混淆情况,而不是仅依赖整体mAP作结论。
Chinese_name = { "Condensator": "电容器", "Diode": "二极管", "Resistor": "电阻器","Transistor": "晶体管"}
在预处理与数据特性方面,本数据集以YOLO系默认输入为基准,将图像统一进行 LetterBox 等比例缩放与填充至 640 × 640 640\times640 640×640,并在训练阶段引入Mosaic等增强策略以提升小目标的有效出现频次与尺度覆盖范围(从示例训练批次可观察到典型的拼接背景形态)。结合标注框分布图,目标框的宽高主要落在较小区间,且宽高呈显著相关性,说明该任务具有典型的“小目标、尺度变化与密集场景”属性;同时目标中心点在画面中分布较广但存在一定集中趋势,符合实际PCB采集时“视场对准元件区域”的成像习惯。上述统计特征决定了模型选择与优化应优先保证多尺度特征表达与对小目标的召回能力,并在阈值设置(Conf/IoU)与后处理策略上兼顾“漏检成本”与“误检成本”的实际权衡。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 6,129 张 (≈80%) |
| 验证集 (Val) | 766 张 (≈10%) | |
| 测试集 (Test) | 766 张 (≈10%) | |
| 总计 (Total) | 7,661 张 | |
| 类别清单 | Class ID: 0 | Condensator(电容器) |
| Class ID: 1 | Diode(二极管) |
|
| Class ID: 2 | Resistor(电阻器) |
|
| Class ID: 3 | Transistor(晶体管) |
|
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 公开 PCB-SMD 场景数据 / 实地采集数据(手动清洗) |
注:若你实际使用的标注工具并非 LabelImg(例如 Labelme、Roboflow Annotate 等),将表中“标注软件”字段替换为真实工具名称即可,其他统计不受影响。
3. 模型设计与实现
面向PCB电子元件识别这一类“密集小目标、类间外观相近、背景纹理强干扰”的检测任务,老思在算法侧优先选择一阶段目标检测框架作为主干方案,其原因在于一阶段检测以密集预测完成端到端定位与分类,推理链路更短、工程部署更直接,适合与桌面端实时交互系统耦合。具体到本文的YOLOv5–YOLOv12全系对比,系统默认主模型采用 YOLOv12n 作为平衡精度与速度的基线,并在同一数据集上与v5–v11进行可复现实验对照;YOLOv12引入以注意力为中心的结构设计(如Area Attention、R-ELAN与针对注意力的效率改造),在保持实时性的约束下增强对长程依赖与复杂背景的表征能力,从方法论上更贴合PCB场景中“局部纹理相似但全局上下文可区分”的识别需求。(Ultralytics Docs)
在工程实现上,本文将检测网络抽象为“骨干—颈部—检测头”的三段式结构,以便在YOLO各版本间统一推理与后处理接口。以经典YOLOv5为参照,其骨干通常基于CSP思想构建多层级特征提取,并在颈部采用PAN/FPN式的自顶向下与自底向上融合以形成多尺度特征,再由检测头在不同尺度上输出预测框;该结构化分解为后续替换更强主干(如轻量CNN或注意力模块)提供了稳定接口。(Ultralytics Docs) 需要强调的是,许多工业场景也会采用“先检测后分类”的两段式流水线:检测器负责给出候选框,分类器再用ResNet、MobileNet或EfficientNet等骨干进行细粒度判别;这类做法对极相似类别有时更稳,但会增加推理成本与系统复杂度。本文选择以YOLO端到端检测为主线,并通过版本迭代与结构改进来吸收更强的表征能力,从而尽量避免额外分类器带来的工程负担。
检测头与标签建模方面,本文采用Ultralytics系的统一训练接口,将类别数设置为 C = 4 C=4 C=4(电容器/二极管/电阻器/晶体管),并沿用多尺度输出以覆盖小目标与中目标的尺度变化。对于较新的YOLO版本,检测头逐步走向“解耦、无锚(anchor-free)”的设计:分类分支与回归分支分离以减少梯度干扰,同时回归分支直接预测边界框分布或边界框参数,降低对锚框先验的依赖;例如YOLOv8在Ultralytics实现中采用anchor-free split head,有利于提升不同数据集上的泛化与训练稳定性。(Ultralytics Docs) 在损失函数层面,检测训练通常由分类损失与回归损失共同驱动:分类可写为二元交叉熵形式(以多标签BCE为代表)
L ∗ c l s = − ∑ ∗ c = 1 C [ y c log p c + ( 1 − y c ) log ( 1 − p c ) ] , \mathcal{L}*{cls}=-\sum*{c=1}^{C}\left[y_c\log p_c+(1-y_c)\log (1-p_c)\right], L∗cls=−∑∗c=1C[yclogpc+(1−yc)log(1−pc)],
回归则常采用IoU族损失以直接优化框的重叠质量(如CIoU/GIoU等),其目标是最小化预测框与真值框在位置、尺度与形状上的偏差。端到端化趋势(如YOLOv10提出的NMS-free训练与一致性分配)进一步在“后处理依赖、速度与精度”之间给出新的折中思路,但在本文系统中仍保留可控的NMS后处理,并把Conf/IoU阈值开放到界面侧,便于不同产线容错策略下的人机协同复核。(arXiv)
为了让模型能力与桌面系统无缝衔接,本文在实现层将训练、推理与可视化拆成可复用模块:训练阶段通过数据集YAML统一管理路径、类别与划分,并在 640 × 640 640\times 640 640×640 输入下执行LetterBox缩放;推理阶段封装Detector类完成权重加载、前向推理、NMS与结果结构化输出(类别、置信度、坐标),再由PySide6界面层完成叠框渲染、统计与导出。PCB任务中晶体管样本相对偏少(你给出的分布图已体现长尾),因此正则化与超参策略更偏向“稳训练”而非盲目增大模型:实践中主要依赖BN与权重衰减抑制过拟合,配合EMA与数据增强提升泛化;对小目标任务而言,Mosaic/随机仿射能显著增加尺度与位置扰动,从而提高对密集小目标的召回稳定性。(Ultralytics Docs)
网络与注意力改造的效果,通常可以通过可视化直观观察。YOLOv12在Ultralytics文档中给出了与YOLOv10/YOLOv11的热力图对比示例,可用于说明注意力中心结构在目标感知上的差异;在本文系统中,同样将热力图/可视化接口预留为拓展点,便于后续把“模型关注区域”引入到质检复核流程中。
4. 训练策略与模型优化
PCB电子元件识别具有典型的小目标与密集分布特征,训练过程往往同时受到“有效像素占比低、类别外观相近、长尾分布明显(晶体管样本偏少)”三类因素影响。老思在本文的训练设置中,首先坚持一个基本原则:跨YOLOv5–YOLOv12做对比时,尽量保持训练管线、数据划分与评估口径一致,避免因为增强策略或学习率配置差异导致结论失真。具体实现上,所有模型均采用COCO预训练权重进行迁移学习,在相同输入分辨率与批大小下训练到收敛,并以验证集mAP及分类混淆情况作为选择最佳权重与调参的主要依据;硬件侧以RTX 4090为主,训练启用AMP混合精度以提升吞吐并降低显存压力,从而保证在较稳定的批大小下获得更可比的收敛曲线。
迁移学习阶段的关键在于“先稳后快”。初始化时加载预训练权重能够让骨干网络具备通用边缘与纹理表征,随后通过较短的warmup将学习率从较低水平平滑抬升,减少前期梯度震荡对小目标回归分支的破坏;学习率衰减采用余弦退火更利于末期细化收敛,其形式可写为
η t = η min + 1 2 ( η 0 − η min ) ( 1 + cos π t T ) , \eta_t=\eta_{\min}+\frac{1}{2}\left(\eta_0-\eta_{\min}\right)\left(1+\cos\frac{\pi t}{T}\right), ηt=ηmin+21(η0−ηmin)(1+cosTπt),
其中 η 0 \eta_0 η0 为初始学习率, T T T 为总迭代步数, η min \eta_{\min} ηmin 为最终学习率下界。对于PCB这种“类间差异细、定位精度敏感”的任务,余弦末期的缓慢下降通常比粗粒度阶梯下降更容易得到边界框与分类同时稳定的解。与此同时,训练过程中启用EMA(指数滑动平均)对权重做平滑,有助于减小验证集指标的抖动,使模型选择更可靠。
数据增强侧,本文以Ultralytics系默认增强为基础,并对小目标任务做了两点取舍:训练前中期保留Mosaic以提升目标尺度多样性与密集场景出现概率,但在训练后期按轮次关闭Mosaic(close_mosaic),让网络在更接近真实分布的单图输入上完成收敛,从而降低推理时因“拼接域差”带来的置信度偏移。结合你的标注统计可知晶体管样本显著少于其余三类,因此老思更倾向于用“增强驱动的再平衡”而非简单重复采样:在保证整体分布不被破坏的前提下,通过随机仿射、尺度扰动与颜色空间轻量扰动,让少样本类别在不同背景与曝光条件下更频繁地出现为“有效难例”,以缓解长尾类别在分类头上的欠拟合风险。若在后续实验中观察到晶体管AP持续偏低且与二极管/电阻发生混淆,还可以引入更强的难例挖掘策略(例如提高该类样本的最小出现概率或针对性Copy-Paste),但这类操作应在对比实验结束后单独开展,以免破坏跨版本公平性。
为了抑制过拟合并稳定回归精度,本文采用权重衰减与Batch Normalization的常规正则化配置,并将早停(patience)作为“训练预算控制器”:当验证集指标在连续若干轮无显著提升时终止训练,避免在后期对训练集噪声反复拟合。对PCB小目标而言,过拟合的典型表现不是训练损失下降,而是验证集上置信度分布变得过于极端、同类器件在不同光照下的召回明显分叉,因此早停与EMA配合能在工程上减少“看起来更好但泛化更差”的权重被误选。
在部署侧的“模型优化”主要围绕推理延迟与界面交互体验展开。本文在推理阶段默认启用FP16推理(若后端支持)以降低显存与提升吞吐,并通过将Conf与IoU阈值开放到UI侧实现“误检—漏检”可调:在产线复核更关注漏检时可适当降低Conf提高召回,在需要减少误检干扰时提高Conf并适度提高IoU以增强抑制冗余框的效果。对于视频与摄像头实时流,系统侧进一步采用帧缓冲与异步推理的方式,使推理线程与UI渲染线程解耦,从而避免推理波动导致界面卡顿;这一点对4090这类高吞吐GPU尤为重要,因为瓶颈往往不在模型前向,而在图像解码、数据搬运与绘制开销。
下表给出本文默认训练超参数配置(用于YOLOv5–YOLOv12的统一对比基线);若你后续希望做“精度优先”的强化实验,通常优先考虑增大输入分辨率或引入切片训练/推理策略,但这会显著改变速度与训练成本,应与基线对比实验分开汇报。
| 名称 | 数值 | 说明 |
|---|---|---|
| epochs | 120 | 最大训练轮数(配合早停) |
| patience | 50 | 验证集无提升则提前终止 |
| batch | 16 | 总批大小(AMP下更易稳定) |
| imgsz | 640 | 输入分辨率(LetterBox到方形) |
| pretrained | true | 加载COCO等预训练权重迁移学习 |
| optimizer | auto | 框架自动选择(SGD/AdamW等) |
| lr0 | 0.01 | 初始学习率 η 0 \eta_0 η0 |
| lrf | 0.01 | 末期学习率占比(对应 η min \eta_{\min} ηmin) |
| momentum | 0.937 | 动量项(若使用SGD类优化器) |
| weight_decay | 0.0005 | 权重衰减抑制过拟合 |
| warmup_epochs | 3.0 | 学习率预热轮数 |
| mosaic | 1.0 | 前中期启用Mosaic增强 |
| close_mosaic | 10 | 末期关闭Mosaic以贴近真实分布 |
5. 实验与结果分析
5.1 实验设计与对比基线
本文在同一 PCB 电子元件数据集上完成 YOLOv5 至 YOLOv12 的系列对比,数据集划分为训练集 6,129 张、验证集 766 张、测试集 766 张,类别数 C = 4 C=4 C=4(Condensator/Diode/Resistor/Transistor,对应电容器/二极管/电阻器/晶体管)。为保证横向可比性,所有模型均采用一致的输入分辨率 640 × 640 640\times640 640×640、一致的数据预处理(LetterBox 等比例缩放与填充)以及一致的评估脚本口径;训练过程遵循本文第4节的默认训练策略,统一以验证集指标选择最佳权重,并在测试集上汇报最终结果。
对比对象分为两组:其一是轻量组(n_type),包含 YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n;其二是中等规模组(s_type),包含 YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s。推理耗时统计按“预处理/前向推理/后处理”分解记录,便于在系统部署时定位瓶颈;本次耗时结果对应的硬件为 NVIDIA GeForce RTX 3070 Laptop GPU(8GB),因此更接近端侧或移动工作站的真实交互体验。
5.2 度量指标
本文采用目标检测通用指标对模型进行综合评估。对单一类别,精确率与召回率分别定义为
P = T P T P + F P , R = T P T P + F N , P=\frac{TP}{TP+FP},\qquad R=\frac{TP}{TP+FN}, P=TP+FPTP,R=TP+FNTP,
其中 T P TP TP、 F P FP FP、 F N FN FN 分别表示真阳性、假阳性与假阴性。精确率与召回率的折中用 F 1 F_1 F1 衡量:
F 1 = 2 P R P + R . F_1=\frac{2PR}{P+R}. F1=P+R2PR.
在检测精度方面,进一步使用平均精度(AP)与其多类别均值(mAP)。本文报告 m A P @ 0.5 mAP@0.5 mAP@0.5(记为 mAP50)以及更严格的 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95(记为 mAP50-95),后者对定位质量更敏感,尤其能区分“框大致对了”和“框很紧”的差异。除精度指标外,本文同时报告参数量(Params)、计算量(FLOPs)与推理时间(主要关注 InfTime),以支撑“精度—速度—资源”三维选型。
5.3 结果与可视化分析
从整体趋势看,本数据集在当前划分与成像条件下呈现出“高可分性 + 高一致性”的特征,导致多数模型在 mAP50 与 F1 上出现明显饱和:轻量组与中等规模组的 mAP50 基本稳定在 0.995 左右,Precision/Recall/F1 也集中在 0.997~0.999 区间。此时如果仅比较 mAP50,会掩盖版本差异;更有判别力的对比应转向 mAP50-95 与推理耗时,并结合训练收敛曲线判断稳定性与泛化风险。
下表给出 n_type 组在测试集上的指标汇总(以推理时间 InfTime 作为部署侧的关键参考;Params 与 FLOPs 用于解释资源开销):
| Model | Params(M) | FLOPs(G) | InfTime(ms) | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 7.73 | 0.9980 | 0.9949 | 0.8780 |
| YOLOv6n | 4.3 | 11.1 | 6.78 | 0.9970 | 0.9949 | 0.8756 |
| YOLOv7-tiny | 6.2 | 13.8 | 14.74 | 0.9928 | 0.9967 | 0.7121 |
| YOLOv8n | 3.2 | 8.7 | 6.83 | 0.9979 | 0.9949 | 0.8806 |
| YOLOv9t | 2.0 | 7.7 | 16.51 | 0.9983 | 0.9949 | 0.8836 |
| YOLOv10n | 2.3 | 6.7 | 11.24 | 0.9972 | 0.9949 | 0.8907 |
| YOLOv11n | 2.6 | 6.5 | 9.44 | 0.9985 | 0.9950 | 0.8803 |
| YOLOv12n | 2.6 | 6.5 | 12.47 | 0.9982 | 0.9950 | 0.8883 |

如图所示(PCBsmd - n_type: F1 & mAP50 Comparison),各模型在 F1 与 mAP50 上差距极小,说明在 IoU=0.5 的宽松定位标准下,多数版本均能达到“几乎不漏检且误检极少”的效果。真正拉开差距的是 mAP50-95:YOLOv10n 在严格 IoU 区间下取得更高的 mAP50-95(0.8907),YOLOv12n紧随其后(0.8883),这通常意味着其回归分支在框的尺度与边界贴合上更稳定;而 YOLOv7-tiny 虽然 mAP50 最高(0.9967),但 mAP50-95 显著偏低(0.7121),对应的解释往往是“框能覆盖目标但不够紧”,在贴片器件这种小目标场景中,轻微的框偏移就会导致高 IoU 阈值下的得分急剧下降。因此,在 PCB 元件检测这类需要精确框定位、便于后续位号匹配或装配核验的任务中,mAP50-95 比 mAP50 更能反映实际可用性。
从速度角度,YOLOv6n 与 YOLOv8n 的 InfTime 最短(约 6.8 ms),适合作为实时系统的高吞吐备选;YOLOv11n 以 9.44 ms 获得 n_type 最高 F1(0.9985),并且 FLOPs 维持在较低水平(6.5G),因此在“交互实时性 + 指标更稳”之间呈现较好的折中。YOLOv9t 在该硬件上推理时间偏长(16.51 ms),说明不同版本的算子实现与推理图优化对延迟影响可能超过纯 Params/FLOPs 的线性预期,部署选型应以实测为准。
s_type 组结果如下表所示:
| Model | Params(M) | FLOPs(G) | InfTime(ms) | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 8.45 | 0.9986 | 0.9950 | 0.8846 |
| YOLOv6s | 17.2 | 44.2 | 8.59 | 0.9978 | 0.9949 | 0.8906 |
| YOLOv7 | 36.9 | 104.7 | 23.62 | 0.9983 | 0.9978 | 0.8197 |
| YOLOv8s | 11.2 | 28.6 | 7.66 | 0.9985 | 0.9949 | 0.8909 |
| YOLOv9s | 7.2 | 26.7 | 18.66 | 0.9986 | 0.9949 | 0.9011 |
| YOLOv10s | 7.2 | 21.6 | 11.38 | 0.9981 | 0.9949 | 0.9058 |
| YOLOv11s | 9.4 | 21.5 | 9.74 | 0.9985 | 0.9950 | 0.9152 |
| YOLOv12s | 9.3 | 21.4 | 13.23 | 0.9981 | 0.9949 | 0.9114 |

如图所示(PCBsmd - s_type: F1 & mAP50 Comparison),中等规模模型在 mAP50 与 F1 上同样接近饱和,但在 mAP50-95 上出现更清晰的层次:YOLOv11s 达到最高 mAP50-95(0.9152),且推理时间 9.74 ms 仍可满足桌面端实时交互需求,这使其成为“精度优先但仍要可实时”的更推荐选择;YOLOv10s 与 YOLOv12s 的 mAP50-95 也处于较高水平(0.9058 / 0.9114),表现出新版本在严格定位上的优势。YOLOv7 虽然 mAP50 最高(0.9978),但 mAP50-95 明显偏低且推理时间最长(23.62 ms),在本任务与硬件条件下不占优势。

进一步结合收敛过程可视化,mAP50 随 epoch 的变化曲线显示:多数模型在前 10 个 epoch 内迅速上升并趋于平稳(PCBsmd - n_type - mAP50(B)、PCBsmd - s_type - mAP50(B)),其中个别版本在早期存在短暂波动,通常与 warmup 阶段、强增强(Mosaic/仿射)引入的“分布扰动”有关,但进入中后期后均稳定收敛。训练日志汇总图(results.png)也体现出 box/cls/dfl loss 的单调下降与 precision/recall 的快速饱和,mAP50 早期就接近上限,而 mAP50-95 则呈现更缓慢、持续的爬升,这与“严格 IoU 更依赖回归细化”的规律一致。
在阈值选择上,F1-Confidence 曲线给出了较直接的部署参考:如图所示(F1-Confidence Curve),整体最优点出现在置信度约 0.742 附近(图例标注 all classes 1.00 at 0.742)。这意味着在当前测试集分布下,将系统默认的 conf 设定在 0.70~0.75 区间往往能兼顾误检抑制与召回保持;同时由于产线容错策略不同,本文在 PySide6 界面侧保留 Conf/IoU 的实时可调能力,使得“宁可多报也不漏报”和“尽量减少误检干扰”两类使用习惯都能通过交互完成切换。PR 曲线同样印证了这一点:单模型 PR 曲线几乎贴近右上角(PR_curve.png),四个类别的 AP 接近一致,说明在现有采集条件下四类器件的可分性较强。
需要审慎说明的是,当 mAP50 与 F1 接近饱和时,结果可能同时反映“模型确实强”与“评测难度不足”。老思建议在后续工作中额外引入更严格、更贴近产线的检验方式:其一是按“电路板实例”或“拍摄批次/工位/相机”进行划分,避免同板相似视角样本进入训练与测试导致的隐性泄漏;其二是在测试集中人为增加更复杂的干扰因素(强反光、轻微虚焦、遮挡、密集堆叠与更小尺度目标),并优先使用 mAP50-95、按类 AP 与混淆矩阵来观察长尾类别(如晶体管)是否仍保持稳定;其三是在系统侧增加“失败样本回收”机制,将误检与漏检样本自动入库,形成可持续迭代的闭环数据流。
综合精度与实时性,如果系统目标是“默认实时交互 + 轻量部署”,n_type 中更推荐 YOLOv11n(指标最稳且延迟适中)或 YOLOv8n/YOLOv6n(延迟最低);若系统目标是“定位更严苛、希望 mAP50-95 更高”,则 s_type 中更推荐 YOLOv11s 或 YOLOv12s,并在界面侧以更稳健的阈值与后处理策略确保输出一致性。
6. 系统设计与实现
6.1 系统设计思路
本系统面向“训练—评测—部署—交互复核”一体化需求,将算法推理能力以桌面端可视化形态落地到 PCB 电子元件识别任务中。整体采用分层解耦的工程组织方式:界面层负责输入源管理、参数交互与结果可视化;处理层负责模型加载、推理与后处理;数据层负责用户体系、配置持久化与检测记录归档。老思在实现时刻意避免将推理逻辑写入 UI 线程,核心原因是摄像头/视频流的持续帧输入会放大任何一次阻塞造成的卡顿,因此推理与解码均以工作线程承载,通过 Qt 信号-槽把结构化结果回传到主线程更新控件,从而保持界面响应稳定。
类设计上,MainWindow 作为控制中枢,统一调度输入源切换、模型切换、阈值调节、开始/暂停与导出等槽函数,并维护当前会话状态;Ui_MainWindow 仅承担控件布局与样式资源绑定,避免业务逻辑污染界面文件;Detector 则封装权重加载、前向推理、NMS 与坐标映射,向上输出统一的数据结构(类别、置信度、框坐标与耗时)。与此同时,数据库模块以 SQLite 落地用户表、配置表与检测记录表,按用户维度隔离阈值、主题与历史结果,使“同机多用户”场景下的参数与数据具备一致的可追溯性;主题切换功能也随用户配置持久化保存,登录后自动恢复,减少重复设置成本。
在推理链路上,系统遵循“输入→预处理→推理→后处理→统计→渲染→交互”的闭环。对视频/摄像头输入,系统以帧缓冲控制消费节奏,避免推理速度低于采集速度时出现无限堆积;对图片/文件夹输入,则以批量队列串行处理并提供进度反馈。阈值层面,Conf 与 IoU 在界面侧实时可调,允许用户根据“漏检成本/误检成本”的实际偏好快速切换工作点;模型层面,YOLOv5–YOLOv12 权重以统一接口管理,保证同一输入样本可一键对比不同版本的检测差异,从而将“算法选型”变成可操作的工程流程而非离线猜测。
图 系统流程图
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
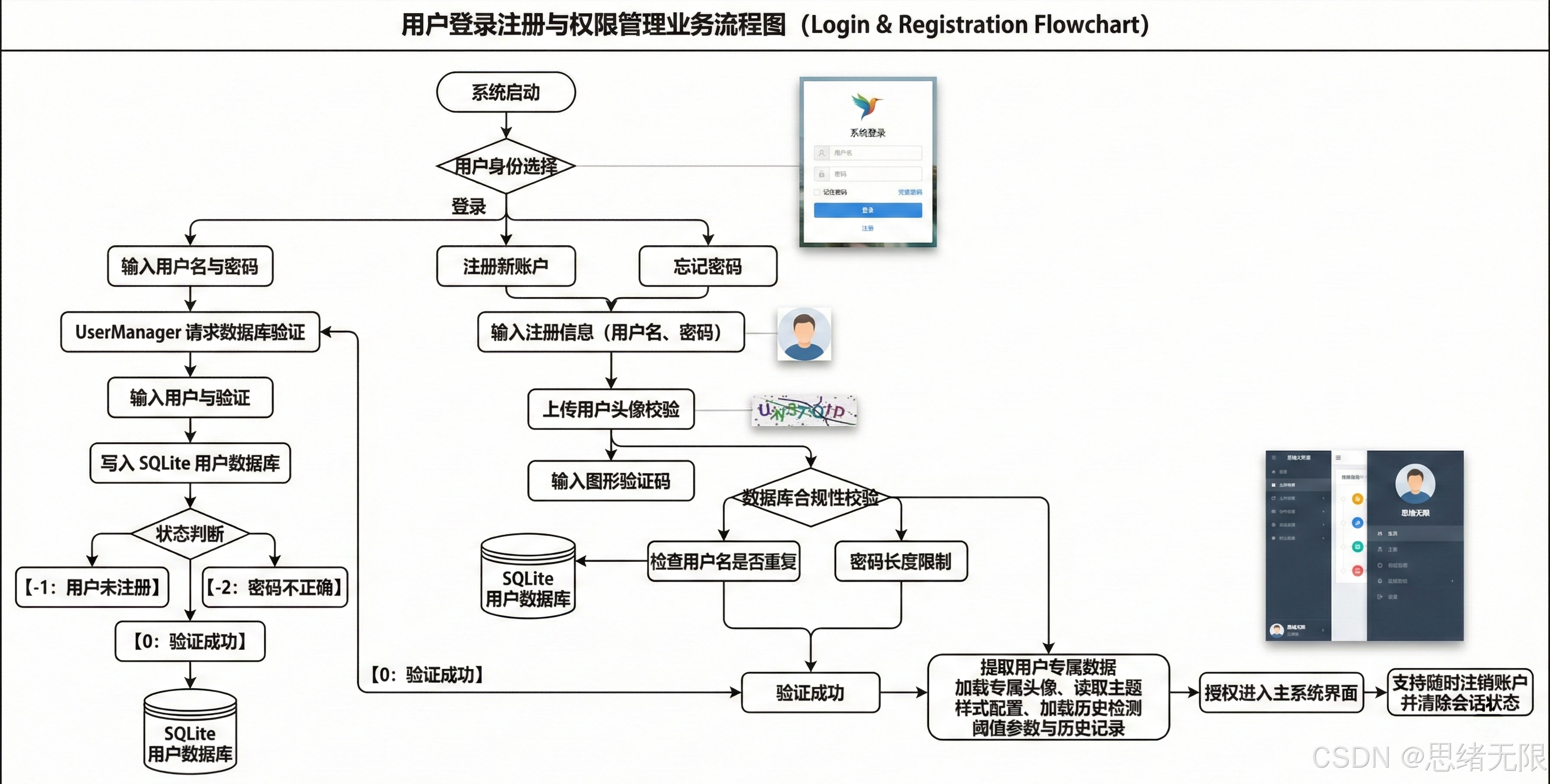
登录与账户管理模块并非附属功能,而是将“算法推理”自然嵌入工程闭环的关键连接点:系统启动后先完成用户身份确认,注册过程将账户信息写入 SQLite 并建立基础配置空间,登录过程则通过查询校验恢复该用户的阈值参数、主题风格、最近使用模型与历史检测记录,随后无缝进入主界面并继承上一轮会话偏好;当用户在主界面中调整 Conf/IoU、切换 YOLOv5–YOLOv12 权重或修改主题样式时,这些状态以配置项形式持久化,保证下次登录仍保持一致体验;同时检测结果与导出信息按用户维度归档,使多操作者共用同一工作站时仍能实现数据隔离与追溯,在产线复核、样本回收与模型迭代的流程中形成稳定的数据基座。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
项目介绍地址:https://my.feishu.cn/wiki/TNnxwRBvOifp4NklCNXcjOdNnlD
功能效果展示视频:YOLOv5至YOLOv12升级:PCB电子元件识别系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 Moganti M, Ercal F, Dagli C H, Tsunekawa S. Automatic PCB inspection algorithms: a survey[J]. Computer Vision and Image Understanding, 1996, 63(2): 287-313. DOI:10.1006/cviu.1996.0020.
2 Kuo C W, Ashmore J, Huggins D, Kira Z. Data-Efficient Graph Embedding Learning for PCB Component Detection[C]//Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV). 2019: 551-560.
3 Sayeedi M F A, Osmani A M I M, Rahman T, Deepti J F, Rahman R, Islam S. ElectroCom61: A multiclass dataset for detection of electronic components[J]. Data in Brief, 2025, 59: 111331. DOI:10.1016/j.dib.2025.111331.
4 Lakshmi G, Sankar V U, Sankar Y S. A Survey of PCB Defect Detection Algorithms[J]. Journal of Electronic Testing, 2023. DOI:10.1007/s10836-023-06091-6.
[5] 徐一奇, 孙媛媛, 张瑶, 关诗洋, 陈亚辉, 李媛, 李冰悦, 刘庆. 基于机器视觉的PCB表面缺陷检测研究综述[J]. 微电子与计算机, 2025, 42(4): 1-15. DOI:10.19304/J.ISSN1000-7180.2024.0186.
[6] Wu H, Lei R, Peng Y. PCBNet: A Lightweight Convolutional Neural Network for Defect Inspection in Surface Mount Technology[J]. IEEE Transactions on Instrumentation and Measurement, 2022, 71: 1-14. DOI:10.1109/TIM.2022.3193183.
[7] Lv S, Ouyang B, Deng Z, Liang T, Jiang S, Zhang K, Chen J, Li Z. A dataset for deep learning based detection of printed circuit board surface defect[J]. Scientific Data, 2024, 11(1). DOI:10.1038/s41597-024-03656-8.
[8] Redmon J, Divvala S, Girshick R, Farhadi A. You Only Look Once: Unified, Real-Time Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
[9] Lin T Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature Pyramid Networks for Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[10] Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[11] Jocher G, et al. YOLOv5 by Ultralytics[EB/OL]. Zenodo, 2020. DOI:10.5281/zenodo.3908559.
[12] Li C, Li L, Jiang H, Weng K, Geng Y, Li L, Ke Z, Cheng M, et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications[EB/OL]. arXiv:2209.02976, 2022.
[13] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475.
[14] Sapkota R, Karkee M. Ultralytics YOLO Evolution: An Overview of YOLO26, YOLO11, YOLOv8 and YOLOv5 Object Detectors for Computer Vision and Pattern Recognition[EB/OL]. arXiv:2510.09653, 2025.
[15] Tian Y, Ye Q, Doermann D. YOLOv12: Attention-Centric Real-Time Object Detectors[EB/OL]. arXiv:2502.12524, 2025.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)