TPAMI 2024 | TIM Fusion :一种面向图像融合的任务引导、隐式搜索与元初始化深度模型

1 论文信息
论文题目: TIM Fusion :一种面向图像融合的任务引导、隐式搜索与元初始化深度模型
论文作者: Risheng Liu , Member, IEEE, Zhu Liu, Jinyuan Liu , Member, IEEE, Xin Fan , Senior Member, IEEE,
and Zhongxuan Luo
发表单位: 大连理工大学
发表会议\期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence
代码链接:https://github.com/LiuZhu-CV/TIMFusion
2 论文主要贡献
图像融合在各类基于多传感器的视觉系统中发挥关键作用,尤其对提升视觉质量和/或提取聚合特征以实现感知任务至关重要。然而,现有多数方法仅将图像融合视为独立任务,忽略了其与下游视觉任务的内在关联。此外,设计合适的融合网络架构往往需要大量工程工作,且当前融合方法缺乏提升灵活性和泛化能力的机制。为缓解上述问题,本文提出一种任务引导、隐式搜索与元初始化(TIM)深度模型,以应对实际场景中具有挑战性的图像融合问题。具体而言,首先提出一种约束策略,融入下游任务信息以指导图像融合的无监督学习过程;在此框架下,设计隐式搜索方案,高效自动挖掘适用于融合模型的紧凑架构;同时,引入前置任务元初始化技术,利用多样化的融合数据为不同类型的图像融合任务提供快速适配能力。在不同类别图像融合问题及相关下游任务(如视觉增强、语义理解)上的定性和定量实验结果,验证了TIM模型的灵活性和有效性。
3 论文创新点
图像融合模型,核心贡献可总结为:
- 针对将任务相关引导融入图像融合学习的问题,建立融合下游任务的约束策略建模图像融合,打破多数融合方法忽略视觉任务信息的瓶颈;
- 架构构建方面,提出隐式搜索策略,高效自动挖掘融合模型架构,避免主流设计方法的繁琐调优和大量架构工程工作;
- 参数训练方面,提出前置任务元初始化策略,学习不同融合数据间的内在特征提取规律,使融合模型仅需少量数据即可实现对多种场景的快速适配;
- 将该融合方法成功应用于各类下游视觉感知任务,在增强和语义理解任务上的客观与主观对比实验,充分验证了所提机制的优越性和有效性。
4 方法
主流基于深度学习的图像融合方法的核心是通过网络端到端训练,直接建立多模态输入与融合图像间的映射关系。本节首先定义图像融合网络,随后提出任务引导的图像融合、隐式架构搜索(IAS) 和前置任务元初始化(PMI) 三大核心模块,TIM模型的整体框架如图1所示。

4.1 符号定义
图像融合网络可形式化表示为:
I F = N F ( I A , I B ; θ F ) I_{F}=\mathcal{N}_{F}(I_{A}, I_{B} ; \theta_{F}) IF=NF(IA,IB;θF)
其中, I A I_A IA、 I B I_B IB为多模态输入图像, I F I_F IF为融合图像, θ F \theta_F θF为融合网络 N F \mathcal{N}_F NF的参数。引入损失函数 ℓ F \ell_F ℓF的约束,可通过 ℓ F ( N F ( I A , I B ; θ F ) ) \ell_{F}(\mathcal{N}_{F}(I_{A}, I_{B} ; \theta_{F})) ℓF(NF(IA,IB;θF))训练融合网络。
直接训练融合网络未考虑后续视觉任务,无法有效整合任务偏好信息,因此本文利用任务引导构建面向任务的图像融合,将视觉任务与图像融合过程关联。
4.2 任务引导的图像融合
从嵌套优化视角为图像融合引入任务特定目标,将整体框架解耦为**图像融合网络 N F \mathcal{N}_F NF和视觉任务网络 N T \mathcal{N}_T NT**两部分,因此整体网络和参数可表示为:
N = N T ∘ N F , θ = { θ T , θ F } \mathcal{N}=\mathcal{N}_{T} \circ \mathcal{N}_{F}, \quad \theta=\{\theta_{T}, \theta_{F}\} N=NT∘NF,θ={θT,θF}
其中, θ T \theta_T θT为视觉任务网络的参数。视觉任务的目标是基于融合图像 I F I_F IF生成任务导向输出 y y y,即 y = N T ( I F ; θ T ) y=\mathcal{N}_{T}(I_{F} ; \theta_{T}) y=NT(IF;θT),该框架可将单模态视觉任务的通用解决方案有效迁移至本模型,构建高效的 N T \mathcal{N}_T NT。
通过这种方式,将视觉任务与图像融合过程桥接,图像融合的优化受**信息丰富度损失 ℓ F \ell_F ℓF和任务特定保留比例损失 ℓ T \ell_T ℓT**的双重约束,以任务性能的有效反馈作为融合标准,实现面向任务的图像融合。
4.2.1 约束公式
任务引导的整体目标公式为:
min θ T ℓ T ( N T ( I F ; θ T ) ) (1) \min _{\theta_{T}} \ell_{T}\left(\mathcal{N}_{T}\left(I_{F} ; \theta_{T}\right)\right) \tag{1} θTminℓT(NT(IF;θT))(1)
约束条件为:
{ I F = N F ( I A , I B ; θ F ∗ ) θ F ∗ = arg min θ F ℓ F ( N F ( I A , I B ; θ F ) ) (2) \begin{cases} I_{F} = \mathcal{N}_{F}\left(I_{A}, I_{B} ; \theta_{F}^{*}\right) \\ \theta_{F}^{*} = \arg \min _{\theta_{F}} \ell_{F}\left(\mathcal{N}_{F}\left(I_{A}, I_{B} ; \theta_{F}\right)\right) \end{cases} \tag{2} {IF=NF(IA,IB;θF∗)θF∗=argminθFℓF(NF(IA,IB;θF))(2)
对于给定视觉任务,引入标准损失函数 ℓ T \ell_T ℓT基于单张融合图像 I F I_F IF训练 N T \mathcal{N}_T NT;同时,将图像融合过程视为约束条件,即基于融合网络的最优参数 θ F ∗ \theta_F^* θF∗得到融合图像 I F I_F IF。
4.2.2 分步优化策略
直接求解上述嵌套优化问题具有挑战性,因公式存在复杂的耦合关系。任务特定目标的梯度可表示为:
∂ ℓ T ∂ θ T = ∂ ℓ T ( θ T ; θ T ( θ F ∗ ) ) ∂ θ T + G ( θ T ( θ F ∗ ) ) \frac{\partial \ell_{T}}{\partial \theta_{T}}=\frac{\partial \ell_{T}(\theta_{T} ; \theta_{T}(\theta_{F}^{*}))}{\partial \theta_{T}}+G(\theta_{T}(\theta_{F}^{*})) ∂θT∂ℓT=∂θT∂ℓT(θT;θT(θF∗))+G(θT(θF∗))
其中, G ( θ T ( θ F ∗ ) ) G(\theta_{T}(\theta_{F}^{*})) G(θT(θF∗))表示基于图像融合最优参数 θ F ∗ \theta_F^* θF∗的间接梯度。本文旨在通过任务引导强化图像融合,而非为视觉任务提供更多融合反馈,因此未采用精确解法直接求解任务特定目标,而是设计渐进式分步优化过程聚合融合的任务偏好:
-
第一步:求解单图像融合约束
联合学习从无到有训练易因 I F I_F IF初始化不佳导致收敛困难,因此首先聚焦于求解公式(2)的单图像融合约束。核心难点是获得高效的特征提取架构,本文通过隐式架构搜索(IAS) 挖掘适配的架构构建 N F \mathcal{N}_F NF;同时,针对不同视觉任务的数据分布差异,通过前置任务元初始化(PMI) 学习可泛化的初始参数 θ F 0 \theta_F^0 θF0,获得与任务无关的融合能力。基于IAS和PMI,通过梯度下降 θ F k − ∇ θ F ℓ F ( N F ( I A , I B ; θ F k ) ) \theta_{F}^{k}-\nabla_{\theta_{F}} \ell_{F}(\mathcal{N}_{F}(I_{A}, I_{B} ; \theta_{F}^{k})) θFk−∇θFℓF(NF(IA,IB;θFk))得到基础融合图像。 -
第二步:融合与下游任务联合优化
将图像融合的约束融入视觉任务的优化过程,联合训练融合网络和下游任务网络,整体目标为:
min θ T , θ F ℓ T ( N T ( I F ; θ T ) ) + η ℓ F ( N F ( I A , I B ; θ F ) ) \min _{\theta_{T}, \theta_{F}} \ell_{T}(\mathcal{N}_{T}(I_{F} ; \theta_{T}))+\eta \ell_{F}(\mathcal{N}_{F}(I_{A}, I_{B} ; \theta_{F})) θT,θFminℓT(NT(IF;θT))+ηℓF(NF(IA,IB;θF))
其中, η \eta η为平衡权重。该公式表明, θ F \theta_F θF的梯度由 ℓ F \ell_F ℓF的信息丰富度度量和 ℓ T \ell_T ℓT的任务引导共同构成。这种学习策略对两个网络互利共赢:一方面,基于 I F I_F IF的图像融合嵌套优化可指导视觉任务的学习;另一方面,视觉任务输出 y y y的反向反馈可将任务相关信息融入图像融合,最终实现面向任务的学习。
4.3 隐式架构搜索(IAS)
如图1(a)所示,本文利用架构搜索为图像融合挖掘高效架构。当前融合架构的设计方法主要为手工设计和通用架构搜索,但存在明显缺陷:手工设计基于现有机制,依赖大量人力和设计经验;通用可微搜索策略[22,23]针对大规模数据集,因效率考虑采用一步近似,梯度估计不精确,在图像融合的小数据场景下易导致架构不稳定。
为此,本文提出隐式架构搜索(IAS),可有效求解公式(2),得到稳定的融合架构,整体过程如图1(b)所示。
4.3.1 梯度估计
借鉴可微松弛方法,引入 α F \alpha_F αF表示融合网络 N F \mathcal{N}_F NF的架构权重,引入搜索目标 ℓ α F \ell_{\alpha_F} ℓαF度量 α F \alpha_F αF的影响。隐式搜索的目标是避免 θ F \theta_F θF的学习不充分和大量计算,更适用于无监督融合任务。为简化表示,省略下标 F F F,搜索目标的梯度 G α G_\alpha Gα可形式化表示为:
G α = ∇ α ℓ α ( α ; θ ) + ∇ θ ℓ α ( α ; θ ) ∇ α θ ( α ) (3) G_{\alpha }=\nabla _{\alpha }\ell _{\alpha }(\alpha ;\theta )+\nabla _{\theta }\ell _{\alpha }(\alpha ;\theta )\nabla _{\alpha }\theta (\alpha ) \tag{3} Gα=∇αℓα(α;θ)+∇θℓα(α;θ)∇αθ(α)(3)
基于低层子问题存在单一最优解的假设,并结合隐函数理论,最优参数 θ \theta θ满足 ∇ θ ℓ ( θ ; α ) = 0 \nabla_{\theta} \ell(\theta ; \alpha)=0 ∇θℓ(θ;α)=0,且:
∇ α θ ( α ) = − ∇ α , θ 2 ℓ ( α ; θ ) ∇ θ , θ 2 ℓ ( α ; θ ) − 1 \nabla_{\alpha} \theta(\alpha)=-\nabla_{\alpha, \theta}^{2} \ell(\alpha ; \theta) \nabla_{\theta, \theta}^{2} \ell(\alpha ; \theta)^{-1} ∇αθ(α)=−∇α,θ2ℓ(α;θ)∇θ,θ2ℓ(α;θ)−1
该方式可获得比通用搜索策略更精确的梯度估计,避免一步更新的不足。借鉴高斯-牛顿(GN)方法,利用一阶梯度的外积近似二阶导数,基于最小二乘法,架构梯度的隐式近似公式为:
G α = ∇ α ℓ α ( α ; θ ) − ∇ θ ℓ ( α ; θ ) ⊤ ∇ θ ℓ α ( α ; θ ) ∇ θ ℓ ( α ; θ ) ⊤ ∇ θ ℓ ( α ; θ ) ∇ α ℓ ( α ; θ ) (4) G_{\alpha}=\nabla_{\alpha} \ell_{\alpha}(\alpha ; \theta)-\frac{\nabla_{\theta} \ell(\alpha ; \theta)^{\top} \nabla_{\theta} \ell_{\alpha}(\alpha ; \theta)}{\nabla_{\theta } \ell(\alpha ; \theta)^{\top } \nabla _{\theta } \ell(\alpha ; \theta )} \nabla _{\alpha } \ell(\alpha ; \theta) \tag{4} Gα=∇αℓα(α;θ)−∇θℓ(α;θ)⊤∇θℓ(α;θ)∇θℓ(α;θ)⊤∇θℓα(α;θ)∇αℓ(α;θ)(4)
一、符号先统一
- α \alpha α:架构参数(决定网络结构,比如算子选择、连接权重)
- θ \theta θ:网络权重(拟合数据的普通模型参数)
- ℓ α ( α ; θ ) \ell_\alpha(\alpha;\theta) ℓα(α;θ):验证集损失(用来更新架构参数 α \alpha α)
- ℓ ( θ ; α ) \ell(\theta;\alpha) ℓ(θ;α):训练集损失(用来更新网络权重 θ \theta θ)
- ∇ α \nabla_\alpha ∇α:对架构参数 α \alpha α 求梯度
- ∇ θ \nabla_\theta ∇θ:对网络权重 θ \theta θ 求梯度
- ∇ α , θ 2 \nabla^2_{\alpha,\theta} ∇α,θ2:混合二阶偏导(Hessian 矩阵)
二、公式 (3):隐式梯度的链式法则展开
G α = ∇ α ℓ α ( α ; θ ) + ∇ θ ℓ α ( α ; θ ) ∇ α θ ( α ) G_\alpha = \nabla_\alpha \ell_\alpha(\alpha;\theta) + \nabla_\theta \ell_\alpha(\alpha;\theta)\nabla_\alpha \theta(\alpha) Gα=∇αℓα(α;θ)+∇θℓα(α;θ)∇αθ(α)
- 公式含义
这是全导数链式法则:
- G α G_\alpha Gα:最终要计算的架构参数梯度(用来更新 α \alpha α)
- ∇ α ℓ α ( α ; θ ) \nabla_\alpha \ell_\alpha(\alpha;\theta) ∇αℓα(α;θ):直接梯度项
- 含义:固定网络权重 θ \theta θ,只看架构变化对验证损失的影响
- ∇ θ ℓ α ( α ; θ ) ∇ α θ ( α ) \nabla_\theta \ell_\alpha(\alpha;\theta)\nabla_\alpha \theta(\alpha) ∇θℓα(α;θ)∇αθ(α):隐式梯度项
- 含义:架构变化会先改变最优网络权重 θ ∗ ( α ) \theta^*(\alpha) θ∗(α),再间接影响验证损失
- 这是 DARTS 类隐式搜索的核心:考虑“架构 → 权重 → 损失”的完整链路
如果只算第一项,相当于假设网络权重已经收敛到最优,但实际训练中 θ \theta θ 还在更新,架构变化会改变 θ \theta θ 的最优解,所以必须加上第二项来修正梯度,否则架构搜索会有偏差。
三、公式: ∇ α θ ( α ) \nabla_\alpha \theta(\alpha) ∇αθ(α) 的隐函数定理推导
∇ α θ ( α ) = − ∇ α , θ 2 ℓ ( α ; θ ) ∇ θ , θ 2 ℓ ( α ; θ ) − 1 \nabla_\alpha \theta(\alpha) = -\nabla^2_{\alpha,\theta}\ell(\alpha;\theta)\nabla^2_{\theta,\theta}\ell(\alpha;\theta)^{-1} ∇αθ(α)=−∇α,θ2ℓ(α;θ)∇θ,θ2ℓ(α;θ)−1
- 前提假设
- 低层子问题(训练集)有唯一最优解 θ ∗ ( α ) \theta^*(\alpha) θ∗(α)
- 最优解满足一阶最优条件: ∇ θ ℓ ( θ ∗ ( α ) ; α ) = 0 \nabla_\theta \ell(\theta^*(\alpha);\alpha) = 0 ∇θℓ(θ∗(α);α)=0
-
推导逻辑(隐函数定理)
对 ∇ θ ℓ ( θ ∗ ( α ) ; α ) = 0 \nabla_\theta \ell(\theta^*(\alpha);\alpha) = 0 ∇θℓ(θ∗(α);α)=0 两边同时对 α \alpha α 求导:
∇ θ , θ 2 ℓ ⋅ ∇ α θ ( α ) + ∇ α , θ 2 ℓ = 0 \nabla^2_{\theta,\theta}\ell \cdot \nabla_\alpha \theta(\alpha) + \nabla^2_{\alpha,\theta}\ell = 0 ∇θ,θ2ℓ⋅∇αθ(α)+∇α,θ2ℓ=0
移项后就得到上面的公式:
∇ α θ ( α ) = − ( ∇ θ , θ 2 ℓ ) − 1 ∇ α , θ 2 ℓ \nabla_\alpha \theta(\alpha) = -\left(\nabla^2_{\theta,\theta}\ell\right)^{-1} \nabla^2_{\alpha,\theta}\ell ∇αθ(α)=−(∇θ,θ2ℓ)−1∇α,θ2ℓ -
含义
- ∇ θ , θ 2 ℓ \nabla^2_{\theta,\theta}\ell ∇θ,θ2ℓ:训练集损失对 θ \theta θ 的二阶 Hessian 矩阵
- ∇ α , θ 2 ℓ \nabla^2_{\alpha,\theta}\ell ∇α,θ2ℓ:训练集损失对 α \alpha α 和 θ \theta θ 的混合偏导
- 这一项本质是在算:架构变化如何引起最优网络权重的变化,是典型的二阶梯度计算
四、公式 (4):高斯-牛顿(GN)近似版梯度
G α = ∇ α ℓ α ( α ; θ ) − ∇ θ ℓ ( α ; θ ) ⊤ ∇ θ ℓ α ( α ; θ ) ∇ θ ℓ ( α ; θ ) ⊤ ∇ θ ℓ ( α ; θ ) ∇ α ℓ ( α ; θ ) G_\alpha = \nabla_\alpha \ell_\alpha(\alpha;\theta) - \frac{\nabla_\theta \ell(\alpha;\theta)^\top \nabla_\theta \ell_\alpha(\alpha;\theta)}{\nabla_\theta \ell(\alpha;\theta)^\top \nabla_\theta \ell(\alpha;\theta)} \nabla_\alpha \ell(\alpha;\theta) Gα=∇αℓα(α;θ)−∇θℓ(α;θ)⊤∇θℓ(α;θ)∇θℓ(α;θ)⊤∇θℓα(α;θ)∇αℓ(α;θ)
-
为什么要近似?
直接算 Hessian 逆矩阵 ( ∇ θ , θ 2 ℓ ) − 1 \left(\nabla^2_{\theta,\theta}\ell\right)^{-1} (∇θ,θ2ℓ)−1 计算量极大,不适合深度学习。
所以用高斯-牛顿法做近似:
∇ θ , θ 2 ℓ ≈ ( ∇ θ ℓ ) ⊤ ( ∇ θ ℓ ) \nabla^2_{\theta,\theta}\ell \approx \left(\nabla_\theta \ell\right)^\top \left(\nabla_\theta \ell\right) ∇θ,θ2ℓ≈(∇θℓ)⊤(∇θℓ)
∇ α , θ 2 ℓ ≈ ( ∇ α ℓ ) ⊤ ( ∇ θ ℓ ) \nabla^2_{\alpha,\theta}\ell \approx \left(\nabla_\alpha \ell\right)^\top \left(\nabla_\theta \ell\right) ∇α,θ2ℓ≈(∇αℓ)⊤(∇θℓ) -
公式拆解
- 第一项 ∇ α ℓ α ( α ; θ ) \nabla_\alpha \ell_\alpha(\alpha;\theta) ∇αℓα(α;θ):和公式 (3) 一样,是直接梯度
- 第二项:修正项(隐式梯度近似)
- 分子: ∇ θ ℓ ⊤ ∇ θ ℓ α \nabla_\theta \ell^\top \nabla_\theta \ell_\alpha ∇θℓ⊤∇θℓα → 训练集梯度与验证集梯度的点积
- 分母: ∇ θ ℓ ⊤ ∇ θ ℓ \nabla_\theta \ell^\top \nabla_\theta \ell ∇θℓ⊤∇θℓ → 训练集梯度的L2范数平方
- 系数: 点积 范数平方 \frac{\text{点积}}{\text{范数平方}} 范数平方点积 → 本质是投影系数,衡量验证梯度在训练梯度方向上的分量
- 乘以后面的 ∇ α ℓ ( α ; θ ) \nabla_\alpha \ell(\alpha;\theta) ∇αℓ(α;θ) → 用训练集梯度方向近似二阶导数
4.3.2 隐式搜索的优势
- 基于网络参数充分学习的需求设计,最优参数可提供精确的梯度估计;
- 与通用可微搜索相比,无需在每次迭代中更新一次架构,在架构搜索中具有稳定性;
- 针对无监督、小数据的图像融合任务,计算效率更高。
4.3.3 搜索目标设计
在搜索目标中引入操作敏感正则化 R e g Reg Reg,表征操作的基本属性(如计算成本、架构紧凑性)。例如, R e g Reg Reg可定义为所有操作的延迟加权和,用于约束参数量;也可通过跳连总数定义,控制架构紧凑性。因此,搜索目标公式为:
ℓ α F = ℓ F + λ ( R e g ( α F ) ) \ell_{\alpha_{F}}=\ell_{F}+\lambda(Reg(\alpha_{F})) ℓαF=ℓF+λ(Reg(αF))
其中, λ \lambda λ为平衡融合质量和操作敏感属性的权衡系数。
4.4 前置任务元初始化(PMI)
参数 θ F \theta_F θF在桥接图像融合的信息聚合和后续视觉任务中发挥关键作用:良好的初始化 θ F 0 \theta_F^0 θF0应揭示内在融合规律,作为快速适配的中介;同时,应融合风格化的域信息,提升对未见过的融合数据的泛化能力。
但现有图像融合方法极少挖掘内在融合规律,多为特定融合任务设计专属融合规则和模型;更重要的是,融合任务的差异大、强度分布不同,直接在混合融合数据集上预训练难以获得可泛化的 θ F 0 \theta_F^0 θF0,无法充分存储融合任务的元知识,也缺乏一致的特征表示。
为此,本文提出前置任务元初始化(PMI) 策略,学习快速适配能力,辅助框架快速适配特定融合任务,学习面向任务的 θ F ∗ \theta_F^* θF∗,并关联信息融合和下游视觉感知任务,整体过程如图1©所示。
4.4.1 约束公式
引入 ω \omega ω表示从不同融合场景的前置任务中学习的权重,在公式(1)和(2)中增加额外约束:
θ F 0 = ω ∗ , ω ∗ = arg min ω ∑ i = 1 M f ( ω ; θ F i ( ω ) ) (5) \theta_{F}^{0}=\omega^{*}, \quad \omega^{*}=\arg \min _{\omega} \sum_{i=1}^{M} f\left(\omega ; \theta_{F_{i}}(\omega)\right) \tag{5} θF0=ω∗,ω∗=argωmini=1∑Mf(ω;θFi(ω))(5)
其中, M M M为融合任务的数量, f f f为特征级的信息丰富度度量,用于衡量 ω \omega ω的泛化能力。该约束为基于图像融合的视觉优化构建了前置任务元初始化约束,本质是在图像融合约束(公式2)基础上的另一优化问题,存在一定的计算难度,但前置任务学习可捕捉图像融合的内在特征,从而提升其泛化能力和快速适配能力。
4.4.2 分层求解策略
采用分层求解过程求解上述问题,将其置于图像融合约束的解空间下,分为两步迭代执行,直至得到 ω ∗ \omega^* ω∗:
- 单场景优化:针对每个融合场景,通过数次梯度更新得到特定的 θ F i \theta_{F_i} θFi,公式为:
θ F i ← ω − ∇ ω ℓ F ( N F ( I A , I B ) ) \theta_{F_{i}} \leftarrow \omega-\nabla_{\omega} \ell_{F}(\mathcal{N}_{F}(I_{A}, I_{B})) θFi←ω−∇ωℓF(NF(IA,IB)) - 多场景元优化:度量各任务特定权重 θ F i \theta_{F_i} θFi的性能,学习不同图像融合任务的共同潜在分布和核心融合规律,公式为:
ω ← ω − ∇ ω ∑ i = 1 M f ( ω ; θ F i ( ω ) ) \omega \leftarrow \omega-\nabla_{\omega} \sum_{i=1}^{M} f(\omega ; \theta_{F_{i}}(\omega)) ω←ω−∇ωi=1∑Mf(ω;θFi(ω))
将 ω ∗ \omega^* ω∗赋值给 θ F 0 \theta_F^0 θF0,继续求解公式(1)的其他约束。基于该良好的初始化,仅需少量训练数据和迭代次数,即可取得比直接训练更优的结果。
4.5 算法流程
TIM模型的完整算法流程(面向任务的图像融合)如下:
算法1:面向任务的图像融合
输入:搜索空间 O O O,损失函数 ℓ F \ell_F ℓF、 ℓ T \ell_T ℓT,其他必要超参数
输出:最优架构和参数
- 图像融合的隐式架构搜索
while 未收敛 do
利用公式(2)通过 T T T步更新参数 θ F \theta_F θF;
利用隐式近似公式(4)更新架构权重 α F \alpha_F αF;
end while - 前置任务元初始化
while 未收敛 do
for 每个融合任务 i i i,执行 K K K步 do
θ F i ← ω − ∇ ω ℓ F ( N F ( I A , I B ) ) \theta_{F_i} \leftarrow \omega-\nabla_{\omega} \ell_F(\mathcal{N}_F(I_A,I_B)) θFi←ω−∇ωℓF(NF(IA,IB));
end for
ω ← ω − ∇ ω ∑ i = 1 M f ( ω ; θ F i ( ω ) ) \omega \leftarrow \omega-\nabla_{\omega} \sum_{i=1}^M f(\omega;\theta_{F_i}(\omega)) ω←ω−∇ω∑i=1Mf(ω;θFi(ω));
end while - 令 θ F 0 = ω ∗ \theta_F^0 = \omega^* θF0=ω∗;
- 整体网络的任务引导学习
联合优化 θ T ∗ \theta_T^* θT∗和 θ F ∗ \theta_F^* θF∗,目标为 min θ T , θ F ℓ T ( N T ( I F ; θ T ) ) + η ℓ F ( N F ( I A , I B ; θ F ) ) \min _{\theta_{T}, \theta_{F}} \ell_{T}(\mathcal{N}_{T}(I_{F} ; \theta_{T}))+\eta \ell_{F}(\mathcal{N}_{F}(I_{A}, I_{B} ; \theta_{F})) minθT,θFℓT(NT(IF;θT))+ηℓF(NF(IA,IB;θF)); - 返回 α F \alpha_F αF、 θ T ∗ \theta_T^* θT∗和 θ F ∗ \theta_F^* θF∗。
4.5.1 实现细节
主要介绍图像融合网络 N F \mathcal{N}_F NF的架构构建和参数训练细节。
4.5.1 搜索配置
- 搜索空间:借鉴[23]的图像融合专用搜索空间,包含多种融合导向的单元和操作。其中,单元包括连续单元 C S C C_{SC} CSC、分解单元 C D C C_{DC} CDC、多尺度融合单元 C M S C_{MS} CMS;操作包括通道注意力(CA)、空间注意力(SA)、膨胀卷积(DC)、残差块(RB)、密集块(DB)、分离卷积(SC),且卷积核尺寸包含3×3和5×5[23,24]。
- 正则化 R e g Reg Reg:定义为GPU延迟的加权和,以获得轻量高效的架构,计算式为 R e g ( α ) = ∑ l ∑ o ∈ O α l L A T ( o ) Reg(\alpha)=\sum_{l} \sum_{o \in O} \alpha_{l} LAT(o) Reg(α)=∑l∑o∈OαlLAT(o),其中 l l l为层索引, L A T ( o ) LAT(o) LAT(o)为操作 o o o的延迟。
- 训练设置:分别为单元权重和操作权重设置20和80个训练轮次;从IVIF和MIF任务中各采集200组训练数据,交替使用不同任务的数据集更新每个轮次;将数据集均分为网络参数更新和架构优化两部分;搜索阶段, N F \mathcal{N}_F NF由2个候选单元组成,每个单元包含2个块;采用SGD优化器,初始学习率 1 e − 3 1e^{-3} 1e−3, T = 20 T=20 T=20次迭代,余弦退火学习率策略,总搜索轮次100。
4.5.2 训练配置
- 前置任务元初始化:利用400组多任务数据优化初始参数 ω ∗ \omega^* ω∗,包含IVIF(TNO、RoadScene)和MIF(MRI、CT、PET、SPECT融合)四类融合任务;单任务更新(算法步骤9)和多任务更新(算法步骤11)的学习率分别设为 1 e − 3 1e^{-3} 1e−3和 1 e − 4 1e^{-4} 1e−4;单任务学习采用Adam优化器,执行4次梯度更新;裁剪64×64的图像块,生成对应的显著图;对RGB图像转换至YCbCr通道,仅对Y通道进行融合;采用翻转、旋转等数据增强策略。
- 实验硬件:所有搜索和训练实验基于NVIDIA GeForce GTX 1070 GPU和3.2 GHz Intel Core i7-8700 CPU完成。
4.6 面向视觉增强的图像融合
设计合适的图像融合方案以充分融合不同模态的特征是视觉增强的关键。如[23]所述,图像融合需保留完整且互补的信息,即红外图像的结构目标信息和可见光图像的丰富纹理细节。因此,将这两个目标构建为并行融合结构作为 N T \mathcal{N}_T NT,探究特征差异(目标提取、细节增强),并对整体框架进行隐式搜索。
4.6.1 架构设计
为约束计算量,采用2个连续单元(含2个候选操作)构建并行增强网络的外层结构,通过引入不同损失实现目标提取和细节增强的分目标优化;最后,引入空间注意力和3个3×3卷积得到最终融合图像,其中空间注意力用于生成特征图,融合分层特征。
4.6.2 损失函数设计
为简化训练过程,引入像素强度损失和SSIM损失,整体损失为二者的加权和:
- 像素强度损失:采用均方误差(MSE)度量像素强度差异, ℓ i n t = ∥ I 1 − I 2 ∥ 2 2 \ell_{int }=\left\|I_{1}-I_{2}\right\|_{2}^{2} ℓint=∥I1−I2∥22;
- SSIM损失:度量结构相似性, ℓ s s i m = 1 − SSIM ( I 1 , I 2 ) \ell_{ssim}=1-\text{SSIM}(I_{1}, I_{2}) ℓssim=1−SSIM(I1,I2);
- 基础融合损失: ℓ = ℓ i n t + μ ℓ s s i m \ell=\ell_{int }+\mu \ell_{ssim} ℓ=ℓint+μℓssim, μ \mu μ为权重系数。
引入两种权重度量方式实现信息保留:
- 融合网络 N F \mathcal{N}_F NF的特征信息保留:借鉴[14],通过VGG网络的浅层和深层特征估计权重图,记为 ℓ F \ell_F ℓF;
- 特定融合任务的视觉质量保留:通过空间显著图估计,基于像素分布加权信息比例。首先借鉴[24]的显著度引导融合规则,计算源图像的空间显著图;然后通过softmax函数将其归一化至[0,1],得到显著度引导权重 M A M_A MA、 M B M_B MB。基于此,加权损失为:
ℓ i n t v = ∥ M A ⊗ ( I F − I A ) ∥ 2 2 + ∥ M B ⊗ ( I F − I B ) ∥ 2 2 \ell_{int }^{v}=\left\|M_{A} \otimes(I_{F}-I_{A})\right\|_{2}^{2}+\left\|M_{B} \otimes(I_{F}-I_{B})\right\|_{2}^{2} ℓintv=∥MA⊗(IF−IA)∥22+∥MB⊗(IF−IB)∥22
ℓ s s i m v = 1 − SSIM ( M A ⊗ I A , M F ⊗ I A ) + 1 − SSIM ( M B ⊗ I F , M B ⊗ I B ) \ell_{ssim}^{v}=1-\text{SSIM}(M_{A} \otimes I_{A}, M_{F} \otimes I_{A})+1-\text{SSIM}(M_{B} \otimes I_{F}, M_{B} \otimes I_{B}) ℓssimv=1−SSIM(MA⊗IA,MF⊗IA)+1−SSIM(MB⊗IF,MB⊗IB)
任务损失记为 ℓ T = ℓ i n t v + μ ℓ s s i m v \ell_{T}=\ell_{int}^{v}+\mu \ell_{ssim}^{v} ℓT=ℓintv+μℓssimv,其中 μ = 0.75 \mu=0.75 μ=0.75。
对 N T \mathcal{N}_T NT的并行输出,分别利用 ℓ i n t \ell_{int} ℓint和 ℓ s s i m \ell_{ssim} ℓssim约束不同模态的相似性,实现目标提取和细节增强。
4.6.3 训练设置
- IVIF任务:利用TNO和RoadScene[14]的混合数据集,基于搜索得到的 N F \mathcal{N}_F NF搜索并行融合结构;
- MIF任务:从哈佛大学官网收集150组多模态医学数据,为MRI-CT、MRI-PET、MRI-SPECT三类融合任务分别搜索面向任务的网络;
- 优化策略:首先采用SGD优化器,学习率 1 e − 3 1e^{-3} 1e−3,余弦退火策略,训练100轮;然后加入后续的 N T \mathcal{N}_T NT,采用Adam优化器,学习率 1 e − 4 1e^{-4} 1e−4,对红外-可见光和医学图像融合任务各训练100轮。
4.7 面向语义理解的图像融合
基于 N F \mathcal{N}_F NF的融合结果,通过所提架构搜索增强面向多光谱目标检测和语义分割的语义理解任务网络 N T \mathcal{N}_T NT。需强调的是,本文目标并非重新设计整个语义感知网络,而是搜索核心特征表示模块,提升感知任务的性能。
4.7.1 特征融合架构设计
为获得高效的语义感知特征融合,改进有向无环图型单元,引入特征蒸馏机制,得到特征蒸馏单元 C F D C_{FD} CFD,实现灵活的特征表示。该单元包含多个节点,边表示操作的松弛;在最后一个节点,通过拼接其他节点的特征执行特征蒸馏[50]。
具体而言,采用级联的特征蒸馏单元构建模块化的特征融合部分(如目标检测的颈部模块、分割的特征解码模块),实现不同骨干网络的无缝替换。为实现高层感知任务的轻量高效特征表示,搜索空间包含多种单层卷积:
- 普通卷积: k × k k×k k×k, k ∈ { 1 , 3 , 5 , 7 } k\in\{1,3,5,7\} k∈{1,3,5,7};
- 膨胀卷积: k × k k×k k×k, k ∈ { 3 , 5 , 7 } k\in\{3,5,7\} k∈{3,5,7},膨胀率2;
- 残差卷积: k × k k×k k×k, k ∈ { 3 , 5 , 7 } k\in\{3,5,7\} k∈{3,5,7},含跳连。
4.7.2 目标检测任务
- 基线模型:采用RetinaNet作为基线,借鉴NAS-based检测方案,搜索颈部模块的融合结构;
- 特征融合:遵循自底向上原则,利用特征蒸馏单元逐步融合特征。对骨干网络输出的不同尺度特征,先下采样低分辨率特征,再在三个层级拼接输入至特征蒸馏单元(含4个节点);
- 损失函数:采用焦损失(Focal Loss)定义 ℓ T \ell_T ℓT,解决类别不平衡问题,平衡权重 η = 0.5 \eta=0.5 η=0.5;
公式:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t) = -\alpha_t (1-p_t)^\gamma \log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
意义:
- (p_t) 为模型对真实类别的预测概率
- ((1-p_t)^\gamma) 降低简单样本的损失,聚焦难分样本
- (\alpha_t) 平衡正负样本
- 用于解决类别不平衡、难易样本不平衡问题,多用于目标检测。
- 数据集:采用Takumi等人[6]提出的多光谱数据集,由RGB、远红外(FIR)、中红外(MIR)、近红外(NIR)相机采集,因分辨率低(256×256)、成像模糊,对数据集重新划分和过滤,最终选择2550组训练、250组测试,包含5类目标:彩色锥桶、停车标志、汽车、行人、自行车;
- 训练设置:以RetinaNet[55]为对比基线,核心改进为通过自动搜索和前置任务元初始化重新设计FPN;采用所提搜索策略从无到有逐步搜索整体架构,批次大小1,架构学习率 3 e − 4 3e^{-4} 3e−4,搜索轮次120;为快速收敛,先训练融合模块40轮以获得良好初始化;整体训练160000步,初始学习率 2 e − 3 2e^{-3} 2e−3,余弦退火至 1 e − 8 1e^{-8} 1e−8。
4.7.3 语义分割任务
- 骨干网络:采用ResNet18作为编码器提取特征,与现有RGB-T分割方案[56]的双骨干网络相比,本文基于嵌套公式的图像融合方案更轻量;
- 解码器设计:采用类似的融合策略整合高低层特征图:首先通过残差上采样将低分辨率特征调整为与高层特征相同的尺寸和通道数,再拼接作为输入;单元输出引入残差连接;利用三层特征,通过两个特征蒸馏单元(各含2个节点)融合,最终从1/8尺度的特征图生成分割结果;
- 数据集:采用MFNet数据集,1083组训练、361组测试,包含多种场景(低光、眩光、白天),图像尺寸640×480,9类目标:背景、路障、彩色锥桶、护栏、弯道、自行车、行人、汽车;
- 损失函数:在1/8和1/16尺度计算交叉熵损失,作为搜索和训练的 ℓ T \ell_T ℓT,平衡权重 η = 0.5 \eta=0.5 η=0.5;
- 训练设置:基于预搜索的 N F \mathcal{N}_F NF,专门搜索分割网络的解码器部分;批次大小2,初始学习率 1 e − 2 1e^{-2} 1e−2,采用随机裁剪、旋转等数据增强;搜索解码器100轮;采用SGD优化器,学习率从 1 e − 2 1e^{-2} 1e−2衰减至 1 e − 8 1e^{-8} 1e−8,整体训练240轮。
5 实验分析
本节首先将任务引导的图像融合应用于视觉增强和语义理解两类任务,通过定性和定量实验验证方法的优越性;随后进行消融实验,验证隐式架构搜索(IAS)和前置任务元初始化(PMI)两大核心机制的有效性。
5.1 面向视觉增强的图像融合
在红外-可见光图像融合(IVIF) 上进行全面的客观和主观评估,验证方法的优越性;同时将方法扩展至医学图像融合(MIF),验证灵活性。
5.1.1 红外-可见光图像融合
对比方法:12种当前最优的基于学习的融合方法,包括DDcGAN[17]、RFN[57]、DenseFuse[9]、FGAN[16]、DID[11]、MFEIF[25]、SMOA[24]、TARDAL[1]、SDNet[13]、U2Fusion[14]、IRFS[38]、LRRNet[35]。
最终搜索架构:融合部分的外层结构为 C M S C_{MS} CMS和 C S C C_{SC} CSC,增强部分为 C S C C_{SC} CSC和 C S C C_{SC} CSC;内层操作依次为3-RB、3-DC、3-DB、3-DC、SA、3-DC、CA、SA。
为兼顾视觉质量和快速部署,提供两种版本的融合方案: T I M w / o L TIM_{w/o L} TIMw/oL(无延迟约束)、 T I M w / L TIM_{w/L} TIMw/L(含延迟约束,“L”表示latency),其中 T I M w / L TIM_{w/L} TIMw/L由两个含3-RB和CA操作的 C S C C_{SC} CSC构成。
评价指标:4种代表性的有参考数值指标:
- 互信息(MI):源于信息论,度量源图像到融合图像的信息传递,表征不同分布间的相互依赖程度;
- 基于图像梯度的特征互信息(FMI):FMI越高,表明融合图像从源图像中融合的特征信息(如边缘)越多;
- 视觉信息保真度(VIF):结合四个尺度计算保真度损失,表征人类视觉感知的信息保真度;
- 基于边缘的相似性度量( Q A B / F Q^{AB/F} QAB/F):通过统计方法度量纹理细节,计算从源图像传递到融合图像的边缘信息总量。
定量结果:

如表1所示,TIM模型在IVIF任务上取得最优性能, M I MI MI和 Q A B / F Q^{AB/F} QAB/F相较于最新的融合方法(TARDAL、SDNet)有显著提升,表明TIM融合图像具有视觉友好、特征互补、纹理丰富的特点;同时, T I M w / L TIM_{w/L} TIMw/L在两个数据集上也取得了可比拟的性能。
计算效率对比:

如表2所示,在TNO数据集上对比参数量、浮点运算量(FLOPs)、推理时间(10组448×620图像),结果表明:
- DenseFuse等基于融合规则的方法参数量和FLOPs少,但推理时间受限于 ℓ 1 \ell_1 ℓ1范数等融合规则,慢于端到端网络;
- T I M w / L TIM_{w/L} TIMw/L在两个数据集上实现了最快的推理时间和最低的FLOPs,相较于最新的TARDAL,参数量减少57.23%,FLOPs减少57.03%,更易在硬件上部署以实现实时推理。
视觉质量-计算效率综合分析:如图4所示,直观展示了融合质量(MI)、计算效率(平均推理时间)、参数量的综合性能,TIM模型实现了三者的平衡。
5.1.2 含配准的图像融合
实际场景中,因成像流程不同和复杂环境(如温度变化、机械应力),难以获得高精度对齐的多光谱图像,源图像的未对齐易导致融合结果出现伪影和重影[63]。本文方法基于灵活的公式设计,可有效解决未对齐图像的融合问题。
在图像融合约束(公式2)的基础上,增加源图像配准约束,实现配准与融合的联合优化:
I B = N R ( I A , I B ′ ; θ R ) I_{B}=\mathcal{N}_{R}(I_{A}, I_{B}' ; \theta_{R}) IB=NR(IA,IB′;θR)
其中, I B ′ I_B' IB′为未对齐图像, N R \mathcal{N}_R NR为配准模块,采用预训练的MRRN方案[64]作为 N R \mathcal{N}_R NR,构建更通用的图像融合框架。
实验设置:首先通过仿射和弹性变换利用随机变形场合成受损红外图像,再通过跨模态风格迁移将其映射至可见光图像的分布;然后利用初始化参数,以监督方式联合学习更鲁棒的融合方案。
实验结果:定量和定性结果分别如表3、图5所示,其他融合方法基于VoxelMorph[65]配准的图像对进行实验。由于红外图像的畸变损坏无法精确恢复,AUIF、SDNet等当前最优算法的结果中仍存在明显的重影(第一行),而本文方法在未对齐的多光谱图像下,仍能有效保留可见光细节和充足的红外热信息。
5.1.3 扩展至医学图像融合
基于灵活的公式设计,将TIM模型扩展至具有挑战性的医学图像融合任务。MRI、CT、PET、SPECT四种典型医学图像为生理系统提供了不同的结构和功能感知信息,利用哈佛大学数据集,采用上述搜索方案和配置,为MRI-CT、MRI-PET、MRI-SPECT三类任务分别挖掘适配架构。
各任务最优架构:
- MRI-CT融合: N T N_T NT的分层结构由5-RB、5-RB、5-RB、SA操作构成;
- MRI-PET融合:操作包括3-SC、3-RB、3-RB、5-RB;
- MRI-SPECT融合:由5-RB、3-DB、3-RB、SA构成。
对比方法:6种主流医学图像融合方法,包括U2Fusion[14]、SDNet[13]、IFCNN[59]、DTCWT[60]、NSCT[61]、PAPCNN[62]。
(1)定性对比
MRI-PET/SPECT融合的定性结果如图7所示(不同脑半球轴位切片)。受成像设备限制,PET/SPECT图像分辨率低、存在马赛克失真,而MRI提供了丰富的结构细节,医学图像融合的目标是保留结构细节并恢复功能颜色表达。本文方法通过去除PET/SPECT的马赛克失真提升视觉质量(图7最后一行),而其他对比方法的融合结果仍存在马赛克和噪声;此外,SDNet、U2Fusion等方法无法有效保留MRI的显著结构,也无法恢复颜色表达。相较于对比方法,本文方法抑制了噪声伪影的生成,突出了软组织的有效结构(如边缘),且无颜色失真,高对比度的视觉效果体现了融合的全面性。
(2)定量对比
采用4种评价指标进行客观评估:MI、熵(EN)、VIF、差异相关和(SCD)[66]。其中:
- EN:度量融合图像中保留的信息总量,适用于存在马赛克等成像质量差异的医学模态;
- SCD:度量不同图像间的相关性,因医学图像的边缘细节不如可见光图像密集,故采用SCD替代FMI、 Q A B / F Q^{AB/F} QAB/F等边缘感知指标。
定量结果以箱线图形式展示于图6,本文方法在三类医学图像融合任务的四个指标上均取得了一致的最优均值,验证了方法的优越性。
5.2 面向语义理解的图像融合
基于嵌套优化的优势,将TIM模型应用于目标检测和语义分割两类语义理解任务,提升任务性能。
对比方法:3种代表性的感知导向融合方法,LRRNet[35]、PSFusion[67]、DetFuse[31]。
5.2.1 目标检测任务
(1)定量对比

在多光谱数据集上的目标检测定量结果如表4所示,对比了基于单模态输入、简单平均融合、各融合方法的RetinaNet检测结果,本文框架相较于融合方法和单模态图像取得了显著提升:
- 现有检测方案基于可见光图像数据集训练和测试,能有效检测可见光显著目标,但红外成像的热信息对汽车发动机、人体等目标检测有益,对自行车、彩色锥桶等低热目标不敏感;
- 本文方法充分融合了多模态的互补优势,在行人、汽车、停车标志等目标上取得了最优的检测精度,mAP指标显著优于对比方法。
5.2.2 语义分割任务
(1)定量对比
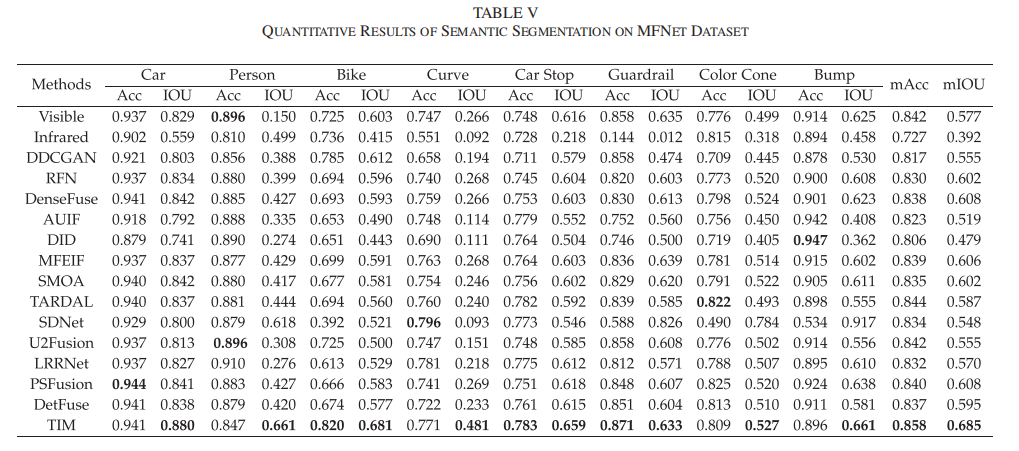
在MFNET数据集上,测试10种融合方法的语义分割性能,采用平均交并比(mIoU)和平均准确率(mACC)作为评价指标,结果如表5所示。本文方法基于通用公式设计,在所有8类目标上均取得了最高的数值性能;而仅关注视觉质量或统计度量的预训练融合方法,无法在分割性能上保持一致的优异表现;相较于感知导向的融合方法,本文策略仍有显著提升,验证了方法既保证互补信息融合,又辅助提升语义分割性能的目标。
5.3 消融实验
为评估**隐式架构搜索(IAS)和前置任务元初始化(PMI)**两大核心机制的有效性,以红外-可见光图像融合为基础任务进行消融实验:首先对比所提搜索策略与主流搜索策略(DARTS)的融合性能,然后验证前置任务元初始化的重要性。
5.3.1 隐式架构搜索(IAS)的有效性
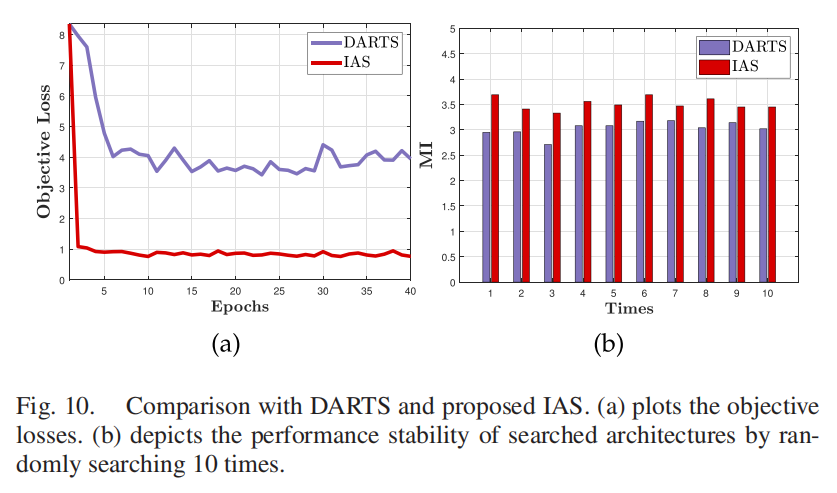
在TNO数据集上,从目标损失和数值结果两方面对比IAS与主流可微搜索策略DARTS[22],结果如图10所示:
- 损失收敛性(图10(a)):基于精确的梯度估计,IAS的目标损失收敛更快,能为架构松弛权重找到更优解;
- 架构稳定性(图10(b)):随机搜索10次,得到10个基于DARTS和IAS的架构,DARTS基架构的性能波动大,无法实现稳定表现,而IAS基架构不仅数值结果更高,且性能稳定。
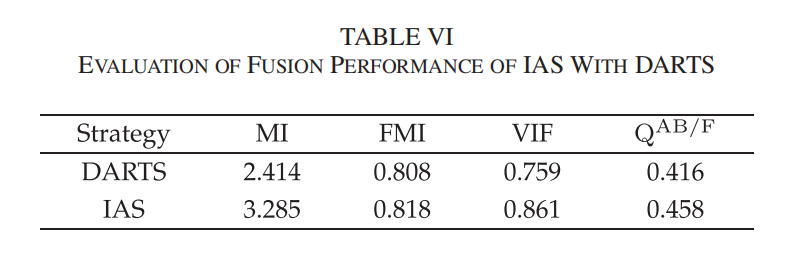
最终性能对比:定性和定量结果分别如图11、表6所示,IAS搜索的网络在各指标上均优于DARTS,验证了IAS的高性能、高效率、高稳定性。
单操作架构对比:为公平对比单操作构成的架构,仅利用 N F \mathcal{N}_F NF模块,基于 ℓ T \ell_T ℓT训练,采用主流内层操作设计启发式结构(固定外层结构为 C M S C_{MS} CMS和 C S C C_{SC} CSC),结果如表7所示:3-DB在MI指标上取得最高数值,但推理时间第二慢;在硬件延迟约束和 λ = 0.5 \lambda=0.5 λ=0.5的权衡下,本文方法实现了推理时间和性能的平衡。
权衡系数 λ \lambda λ的有效性:为验证硬件正则化的权衡系数 λ \lambda λ的影响,提供三种不同延迟约束的版本,结果如表8所示:推理时间和参数量对 λ \lambda λ的调整敏感, λ \lambda λ增大时,推理时间减少,但数值性能略有下降,可通过调整 λ \lambda λ实现性能和效率的灵活权衡。
5.3.2 前置任务元初始化(PMI)的有效性
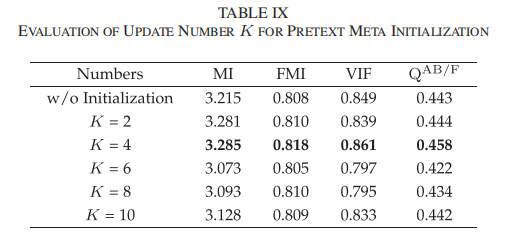
PMI策略旨在学习可泛化的参数,实现图像融合的快速适配。通过实验验证该训练策略的影响,并探究初始化的最优内层更新次数 K K K,结果如表9所示。其中,“w/o Initialization”表示基于特定数据直接端到端训练的版本。
实验结论:
- 合适的 K K K能显著提升最终数值性能,当 K = 4 K=4 K=4时,取得综合最优的数值结果,因该设置能从多任务、多数据分布中学习内在的融合特征;
- 内层更新次数并非越多越好, K > 4 K>4 K>4时性能下降,表明过度更新会导致过拟合;
- 前置任务元初始化能有效学习图像融合的内在规律,显著提升融合性能。
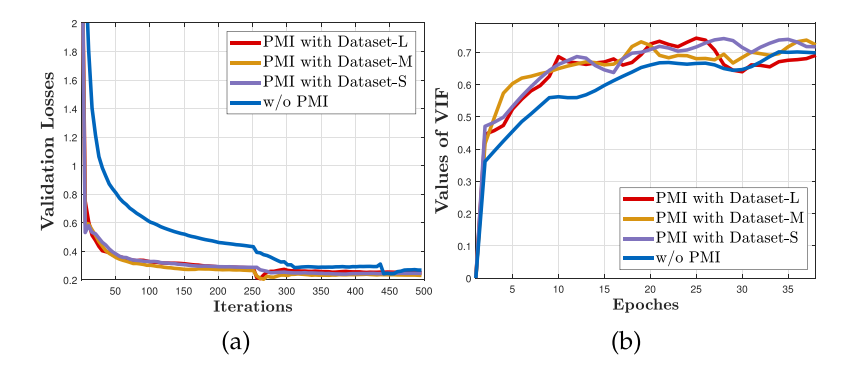
收敛性分析:绘制验证集的损失曲线和VIF指标曲线(视觉质量),结果如图12所示:
4. 含PMI的版本验证损失更低,且更快收敛至稳定阶段,相较于无PMI的版本具有明显优势;
5. 含PMI的版本能快速达到最优VIF指标,体现了鲁棒的视觉质量;
6. 仅用特定任务的少量训练数据,含PMI的版本仍能取得显著的数值结果。
训练数据规模的影响:如图12所示,探究不同训练数据规模对PMI的影响,将IVIF的训练图像块分为Dataset-L(6195组)、Dataset-M(3097组)、Dataset-S(1548组):
7. PMI基于大规模数据集训练时收敛更慢,基于小规模数据集训练时无法保持稳定,易出现振荡;
8. 综合训练效率和质量,选择3097组图像块作为PMI的训练数据。
任务引导融合的有效性:对比直接融合(仅用 ℓ F \ell_F ℓF的原始训练策略生成融合图像)和任务引导融合(TIM)在四类代表性视觉任务上的性能,结果如表10所示。任务引导融合能有效提升不同任务的性能,验证了PMI对视觉效果和语义理解的任务引导融合均具有积极作用。
6 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)