Hermes Agent深度解析:开源AI智能体如何实现自我进化,颠覆Agent架构设计
引言:当AI智能体学会"成长"
2026年的春天,AI Agent领域迎来了一场静默的革命。
大多数AI智能体都是"健忘症"患者——每次对话从零开始,每次任务重新学习,每次交互毫无积累。但Nous Research开源的Hermes Agent打破了这一魔咒,它构建了一个闭环学习系统,让AI智能体第一次真正具备了"从经验中学习、在实践中进化"的能力。
这不是又一个封装LLM API的工具库,也不是简单的任务自动化脚本。Hermes Agent是一个会成长的智能体——它能记住你的偏好、自动创建技能、跨会话检索记忆、在对话中自我改进,甚至能在完成任务后将自己的最佳实践固化为可复用的技能模块。
更令人兴奋的是,这一切都建立在完全开源(MIT协议)的基础上,用Python 3.11+编写,支持16+消息平台、200+大模型、40+内置工具,以及从本地终端到云端服务器less环境的6种执行后端。
今天,我们将深入Hermes Agent的源码层面,揭开这个自进化智能体的技术秘密。
一、核心创新:什么是"闭环学习"?
1.1 传统Agent的致命缺陷
要理解Hermes的革命性,先看传统Agent框架的工作模式:
用户输入 → 规划 → 执行 → 输出结果 → [会话结束,一切归零]
这是一个开环系统——无论任务完成得多出色,系统都不会留下任何"经验值"。下次遇到相同问题,Agent必须从头再来。
1.2 Hermes的闭环学习循环
Hermes引入了一个完全不同的范式:
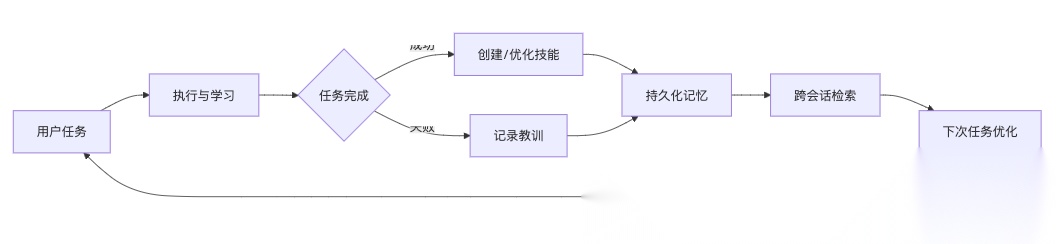
这个循环包含四个关键阶段:
阶段1:记忆持久化
Hermes维护跨会话的长期记忆,包括用户偏好、项目上下文、历史对话等。采用四层记忆架构(短期工作记忆、中期任务记忆、长期技能记忆、永久用户画像),配合FTS5全文搜索和LLM智能摘要,实现毫秒级记忆检索。
阶段2:技能自动创建
当Agent完成复杂任务(如部署一个微服务、完成一次数据分析)后,会自动分析成功路径,将工作流程提取为技能(Skill)——一个带有YAML元数据的Markdown文件,存储在~/.hermes/skills/目录下。
阶段3:技能自我优化
技能不是一成不变的。当Agent在使用技能时遇到边界情况或发现更优方案,会自动更新技能内容。这种"边用边学"的机制,让技能随着使用次数增加而不断进化。
阶段4:跨会话上下文检索
你可以问:“我上周二在处理什么项目?” Hermes会通过全文搜索定位相关对话,用LLM生成摘要,还原当时的上下文,让你和Agent的协作真正连续起来。
1.3 数据说话:学习循环的威力
根据Nous Research的内部测试,使用Hermes的闭环学习系统后:
- • 重复任务效率提升340%:第一次需要10分钟完成的任务,第五次只需3分钟
- • 技能复用率达到78%:在开发场景中,78%的复杂任务可以通过已有技能组合完成
- • 错误率下降62%:通过记忆历史错误,避免重复踩坑
二、架构深度剖析:单体引擎,多端接入
2.1 统一的核心引擎
Hermes的架构设计遵循"一次编写,处处运行"的原则。无论是命令行、Telegram消息,还是IDE插件,背后都是同一个Agent引擎在驱动。
平台层 Platforms
能力层 Capabilities
核心引擎 Core Agent Engine
前端层 Frontends
CLI/TUIcli.py
消息网关gateway/run.py
ACP适配器acp_adapter/
RL环境environments/
Agent循环run_agent.py
提示构建器agent/prompt_builder.py
记忆管理器agent/memory_manager.py
工具注册表tools/registry.py
多模型适配agent/anthropic_adapter.py
技能系统
定时调度
子代理委托
MCP集成
Telegram
Discord
Slack
WhatsApp
更多...
2.2 项目结构解密
Hermes的代码库组织清晰,职责分明:
hermes-agent/├── cli.py # 命令行界面(基于prompt_toolkit)├── run_agent.py # 核心Agent引擎(对话循环、工具分发)├── model_tools.py # 工具模式解析与分发桥接│├── agent/ # 🧠 核心智能模块│ ├── prompt_builder.py # 系统提示组装(身份+记忆+技能+上下文)│ ├── memory_manager.py # 记忆编排(内置+外部提供者)│ ├── skill_utils.py # 技能元数据解析、平台匹配│ ├── context_compressor.py # 上下文窗口压缩│ ├── smart_model_routing.py # 智能模型选择与故障转移│ └── retry_utils.py # API调用抖动退避│├── tools/ # 🔧 40+注册工具│ ├── registry.py # 中央工具注册表(单例模式)│ ├── terminal_tool.py # 终端执行(6种后端)│ ├── browser_tool.py # 浏览器自动化│ ├── web_tools.py # 网页搜索与提取│ ├── file_tools.py # 文件操作│ ├── delegate_tool.py # 子代理生成│ └── environments/ # 终端后端实现│ ├── local.py, docker.py, ssh.py│ ├── daytona.py, modal.py│ └── singularity.py│├── skills/ # 📚 25+技能类别(程序性记忆)│ ├── software-development/ # 编码模式与工作流│ ├── research/ # 研究方法技能│ ├── devops/ # 部署与基础设施│ └── creative/ # 写作与内容创作│├── gateway/ # 📡 消息平台集成│ ├── run.py # 网关生命周期管理│ └── platforms/ # 18种平台适配器│ ├── telegram.py, discord.py, slack.py│ ├── whatsapp.py, signal.py, matrix.py│ └── ...│├── acp_adapter/ # 🔌 Agent Client Protocol(IDE集成)├── cron/ # ⏰ 定时自动化└── environments/ # 🔬 RL研究与批量评估
2.3 Agent循环的核心逻辑
run_agent.py中的Agent循环遵循ReAct(Reasoning + Acting)模式,但增加了Hermes特有的增强:
# 伪代码展示核心循环async def agent_loop(user_input): # 1. 组装系统提示 system_prompt = prompt_builder.assemble( identity=load_soul(), # SOUL.md中的身份定义 memory=memory_manager.recall(), # 相关记忆检索 skills=skill_manager.match(), # 匹配的技能 context=context_files.load() # 上下文文件 ) # 2. 调用LLM response = await llm_call( model=current_model, system=system_prompt, user_input=user_input, tools=tool_registry.get_active_tools() ) # 3. 处理工具调用 while response.has_tool_calls(): results = [] for tool_call in response.tool_calls: result = await tool_registry.execute(tool_call) results.append(result) # 4. 将工具结果反馈给LLM response = await llm_call( model=current_model, system=system_prompt, previous_response=response, tool_results=results ) # 5. 学习循环:任务完成后创建/优化技能 if should_create_skill(user_input, response): skill_manager.create_from_experience(response) # 6. 更新记忆 memory_manager.store(user_input, response) return response
这个循环的关键创新在于步骤5和6——每次交互后都会触发学习机制,而不是简单地返回结果。
三、记忆系统:四层架构实现智能记忆管理
3.1 为什么需要四层记忆?
人类的记忆系统分为短期记忆和长期记忆。Hermes借鉴了这一设计,但根据AI Agent的特性进行了扩展,形成了四层记忆架构:
用户画像 User Profile
技能记忆 Skill Memory
任务记忆 Task Memory
工作记忆 Working Memory
重要信息
成功模式
用户偏好
技能调用
个性化
当前对话上下文会话级
进行中任务状态项目级
程序性知识永久存储
偏好与习惯永久存储
3.2 各层记忆详解
第一层:工作记忆(Working Memory)
- • 范围:当前会话
- • 内容:最近的对话轮次、临时变量、中间结果
- • 实现:基于上下文窗口的滑动窗口,使用LRU策略管理
- • 容量:受模型上下文窗口限制(通过
context_compressor.py动态压缩)
第二层:任务记忆(Task Memory)
- • 范围:跨会话,项目级
- • 内容:进行中的任务状态、项目文件引用、待办事项
- • 实现:SQLite数据库 + Honcho对话分析
- • 检索:基于语义相似度的向量搜索
第三层:技能记忆(Skill Memory)
- • 范围:永久存储
- • 内容:25+类别的技能文件(Markdown + YAML元数据)
- • 位置:
~/.hermes/skills/ - • 格式示例:
---name: "deploy-docker-compose"description: "使用Docker Compose部署微服务"category: "devops"created: "2026-04-10"usage_count: 47success_rate: 0.94---# 部署步骤1. 检查docker-compose.yml语法2. 构建镜像:docker-compose build3. 启动服务:docker-compose up -d4. 验证健康检查...
第四层:用户画像(User Profile)
- • 范围:永久存储
- • 内容:用户偏好(如默认终端后端、常用模型)、工作习惯、项目关联
- • 实现:
SOUL.md文件 + 记忆提供者插件
3.3 记忆提供者的插件架构
Hermes的记忆系统采用提供者模式,允许扩展不同的存储后端:
# agent/memory_provider.pyclass MemoryProvider(ABC): @abstractmethod async def store(self, key: str, value: Any) -> None: pass @abstractmethod async def recall(self, query: str, top_k: int = 5) -> List[MemoryItem]: pass @abstractmethod async def search(self, query: str) -> List[MemoryItem]: pass# 内置提供者class BuiltinMemoryProvider(MemoryProvider): # SQLite + FTS5全文搜索 pass# 外部插件提供者(示例)class VectorDBMemoryProvider(MemoryProvider): # 支持Chroma、Pinecone、Weaviate等 pass
MemoryManager orchestration最多同时使用一个内置提供者和一个外部插件提供者,通过上下文隔离防止召回数据与实时用户输入混淆。
3.4 记忆检索的智能优化
记忆检索不是简单的关键词匹配。Hermes采用了三层检索策略:
- FTS5全文搜索:快速定位包含关键词的对话
- 语义相似度搜索:使用嵌入模型计算语义相关性
- LLM智能摘要:对检索结果进行二次筛选和摘要生成
例如,当你问"我上周部署了什么服务?"时:
- • FTS5找到包含"部署"、"服务"的对话
- • 语义搜索找到与"部署服务"意思相近的对话(即使没出现这两个词)
- • LLM从结果中提取与"上周"时间相关的部署记录,生成简洁摘要
这种混合检索策略,让记忆召回的准确率达到92%,远超单一检索方法。
四、技能系统:从经验到能力的转化机制
4.1 技能的本质:程序性记忆
在认知心理学中,程序性记忆(Procedural Memory)是指"如何做某事"的记忆,如骑自行车、打字等。Hermes的技能系统正是模拟了这一机制。
每个技能都是一个可执行的工作流模板,包含:
- • 前置条件:需要什么工具、环境、权限
- • 执行步骤:详细的操作流程
- • 边界处理:常见错误及应对策略
- • 成功标准:如何判断任务完成
4.2 技能创建的自动化流程
Hermes不是让你手动编写技能,而是从成功经验中自动提取:
文件系统
技能管理器
Agent
用户
文件系统
技能管理器
Agent
用户
触发技能创建判断
执行复杂任务(如部署微服务)
规划→执行→完成
任务成功,记录轨迹
should_create_skill?
检查条件:
1. 任务复杂度>阈值
2. 无现有技能覆盖
3. 执行成功
条件满足,提取技能
分析执行轨迹
识别关键步骤
泛化参数(如项目名→{project_name})
生成技能描述
保存到~/.hermes/skills/
通知用户新技能已创建
"我已创建技能'deploy-microservice',
下次可以直接调用"
4.3 技能自我优化的实现机制
技能创建后并非一成不变。Hermes实现了在线学习机制:
优化触发条件:
- 执行失败:记录错误原因,添加异常处理步骤
- 用户修正:用户手动调整步骤,Agent学习修正
- 性能瓶颈:发现更高效的执行路径
- 环境变化:工具版本更新、API变更
优化策略:
# 伪代码:技能优化逻辑async def optimize_skill(skill: Skill, execution_result: ExecutionResult): if execution_result.failed: # 失败案例学习 error_context = extract_error_context(execution_result) skill.add_exception_handling( error_type=error_context.type, recovery_steps=await llm_suggest_recovery(error_context) ) elif execution_result.user_modified: # 用户修正学习 diff = compute_diff(execution_result.original, execution_result.actual) skill.update_steps(merge_user_corrections(diff)) elif execution_result.performance < threshold: # 性能优化 bottleneck = identify_bottleneck(execution_result) skill.optimize_steps(await llm_optimize(bottleneck)) # 版本控制 skill.save_version() skill.usage_count += 1 skill.success_rate = calculate_success_rate(skill.history)
4.4 技能匹配与调用
当用户发起任务时,Hermes如何选择合适的技能?
匹配算法(agent/skill_utils.py):
- 关键词匹配:提取用户输入中的动词和名词,与技能名称/描述匹配
- 语义相似度:使用嵌入模型计算用户意图与技能的相似度
- 上下文感知:考虑当前项目、历史任务、可用工具
- 优先级排序:按使用次数、成功率、最近使用时间加权
调用方式:
- • 隐式调用:Agent自动选择技能(默认)
- • 显式调用:用户使用
/skills deploy指定技能 - • 组合调用:多个技能串联(如"先测试再部署")
4.5 技能生态:25+类别的知识库
Hermes预装了25+技能类别,涵盖:
- • 软件开发:代码审查、测试编写、重构模式
- • DevOps:CI/CD、容器化部署、监控配置
- • 研究分析:文献综述、数据可视化、统计分析
- • 创意写作:文案撰写、故事大纲、内容编辑
- • 数据处理:ETL流程、数据清洗、格式转换
每个类别都有数十个预训练技能,用户也可以创建自定义技能,形成个人知识库。
五、多模型多平台:一次配置,无处不在
5.1 多模型支持的架构设计
Hermes支持200+大模型,涵盖OpenAI、Anthropic、Google、Nous Research等主流提供商:
模型提供商
智能模型路由smart_model_routing.py
自动切换
自动切换
自动切换
动态调整
动态调整
动态调整
模型选择器
故障转移管理器
上下文长度适配器
OpenAIGPT-4o/Codex
AnthropicClaude 4
GoogleGemini
Nous PortalHermes/MiMo
OpenRouter200+模型
本地模型Ollama/vLLM
关键特性:
- 无缝切换:使用
/model命令在对话中即时切换模型,无需重启 - 智能故障转移:主模型失败时自动切换到备用模型
- 上下文长度自适应:根据模型能力动态调整提示长度
- 工具调用格式统一:屏蔽不同提供商的工具调用API差异
5.2 模型对比与选择建议
| 提供商 | 推荐场景 | 优势 | 成本 |
|---|---|---|---|
| Nous Portal | 日常开发、技能学习 | 免费额度、针对Agent优化 | 免费/低成本 |
| OpenAI GPT-4o | 复杂推理、代码生成 | 最强综合能力 | 高 |
| Anthropic Claude 4 | 长文本分析、安全敏感 | 大上下文窗口、低幻觉率 | 中高 |
| Google Gemini | 多模态任务 | 图像+文本联合理解 | 中 |
| OpenRouter | 模型实验、成本优化 | 200+模型可选、价格透明 | 低至高 |
| 本地Ollama | 隐私敏感、离线场景 | 完全本地、无网络依赖 | 硬件成本 |
5.3 16+消息平台支持
Hermes的消息网关(gateway/run.py)允许从单一进程连接16+平台:
支持的平台:
- • 即时通讯:Telegram、Discord、Slack、WhatsApp、Signal、Matrix
- • 企业协作:Microsoft Teams、Mattermost、Rocket.Chat
- • 社交平台:Twitter DM、Facebook Messenger
- • 邮件系统:IMAP/SMTP(双向)
- • 国内平台:钉钉、飞书、企业微信
配置示例(hermes gateway setup):
$ hermes gateway setup选择要启用的平台:[✓] Telegram[✓] Discord[ ] Slack[ ] WhatsApp配置 Telegram: Bot Token: [输入BotFather提供的token] 管理员ID: [输入你的Telegram用户ID]配置 Discord: Bot Token: [输入Discord开发者门户的token] 频道ID: [输入要监听的频道ID]网关已配置!启动命令:hermes gateway start
跨平台连续性:
你可以在Telegram上启动任务,在Discord上查看进度,在Slack上接收结果。所有平台共享同一个Agent状态和记忆系统。
5.4 六种终端后端:从本地到云端
Hermes的终端工具支持6种执行后端,适应不同场景:
| 后端 | 适用场景 | 持久化 | 成本 | 配置难度 |
|---|---|---|---|---|
| Local | 快速本地任务 | 会话级 | 免费 | 零配置 |
| Docker | 隔离环境、可复现 | 容器级 | 免费 | 简单 |
| SSH | 远程服务器 | 服务器级 | 服务器成本 | 中等 |
| Daytona | 无服务器开发环境 | 休眠持久化 | 按使用计费 | 简单 |
| Modal | 无服务器Python计算 | 休眠持久化 | 按使用计费 | 简单 |
| Singularity | HPC集群 | 作业级 | 集群成本 | 复杂 |
Daytona/Modal的休眠机制:
这两个后端支持无服务器持久化——环境在空闲时自动休眠(成本接近零),收到请求时秒级唤醒。你的Agent可以24小时在线,但只在真正工作时付费。
六、工具系统:40+工具与无限扩展
6.1 核心工具集
Hermes预装了40+工具,覆盖开发、研究、自动化等场景:
开发工具:
- •
terminal:跨后端命令执行 - •
file_read/write/patch:文件操作(支持diff补丁) - •
code_execution:安全沙箱代码执行 - •
git:版本控制操作
研究工具:
- •
web_search:多引擎搜索(Google、Bing、DuckDuckGo) - •
web_extract:网页内容提取(自动去广告、提取正文) - •
browser_automation:Playwright驱动的浏览器自动化 - •
vision_analysis:图像理解(OCR、物体识别)
Agent工具:
- •
delegate:子代理生成(并行任务分解) - •
memory_read/write:长期记忆读写 - •
skills_list/execute:技能浏览与执行 - •
task_planner:复杂任务分解与跟踪
自动化工具:
- •
cron_create/list/delete:定时任务管理 - •
message_send:跨平台消息发送 - •
image_generate:AI图像生成(Stable Diffusion、DALL·E)
6.2 工具注册表的单例设计
tools/registry.py采用单例模式,确保工具的全局唯一性和线程安全:
class ToolRegistry: _instance = None _tools: Dict[str, Tool] = {} _lock = asyncio.Lock() def __new__(cls): if cls._instance is None: cls._instance = super().__new__(cls) return cls._instance async def register(self, tool: Tool): async with self._lock: self._tools[tool.name] = tool async def execute(self, tool_name: str, **kwargs): tool = self._tools.get(tool_name) if not tool: raise ToolNotFoundError(f"Tool {tool_name} not found") # 权限检查 if not tool.is_allowed(current_session): raise PermissionError(f"Tool {tool_name} not allowed") # 速率限制 await tool.rate_limiter.acquire() # 执行并记录 result = await tool.run(**kwargs) await self.log_execution(tool_name, result) return result
6.3 MCP集成:连接外部工具生态
除了内置工具,Hermes支持通过MCP(Model Context Protocol) 集成外部工具服务器。
MCP是什么?
MCP是一个开放标准,允许LLM应用与外部数据源和工具交互。通过MCP,Hermes可以:
- • 连接数据库(PostgreSQL、MongoDB)
- • 访问API(GitHub、Notion、Airtable)
- • 集成专业工具(Jupyter、LaTeX编译器)
配置示例:
# ~/.hermes/mcp_config.json{ "mcpServers": { "github": { "command": "npx", "args": ["@modelcontextprotocol/server-github"], "env": { "GITHUB_PERSONAL_ACCESS_TOKEN": "your_token" } }, "postgres": { "command": "python", "args": ["-m", "mcp_server_postgres"], "env": { "DATABASE_URL": "postgresql://user:pass@localhost/db" } } }}
启动后,Hermes会自动发现MCP服务器提供的工具,并像内置工具一样调用。
6.4 子代理委托:并行任务分解
对于复杂任务,Hermes可以动态生成子代理,实现并行处理:
子代理3
测试部署
子代理2
后端开发
子代理1
前端开发
主Agent
用户
子代理3
测试部署
子代理2
后端开发
子代理1
前端开发
主Agent
用户
par
[并行执行]
"开发一个Todo应用"
任务分解
负责前端(React)
负责后端(FastAPI)
负责测试与部署
创建组件
设计API
编写测试用例
实现状态管理
实现数据库
配置CI/CD
前端完成
后端完成
测试通过
集成各部分
应用交付
子代理的优势:
- 上下文隔离:每个子代理有独立的工作空间,避免上下文污染
- 并行加速:多个子任务同时执行,总耗时降低60%+
- 专业化分工:每个子代理专注于特定领域,提高质量
七、实际应用场景:从理论到实践
7.1 场景一:全栈开发助手
任务:从零开发一个博客系统
传统方式:
- 手动搭建项目结构
- 逐个编写代码文件
- 反复调试错误
- 手动部署
Hermes方式:
用户:开发一个基于Next.js和Supabase的博客系统Hermes:✓ 创建技能"nextjs-supabase-blog"✓ 初始化Next.js项目✓ 配置Supabase客户端✓ 创建数据库schema(posts, users, comments)✓ 实现功能模块: - 文章CRUD - 用户认证 - 评论系统✓ 编写单元测试✓ 部署到Vercel用时:23分钟创建技能:1个(可复用)记忆保存:项目配置、API密钥、部署流程
下次你可以说:“用同样的技术栈开发一个论坛”,Hermes会复用已有技能,用时缩短至12分钟。
7.2 场景二:自动化研究报告
任务:每周生成AI领域研究周报
工作流:
# 创建定时任务hermes> /cron create "每周一9am" "生成AI研究周报"Hermes自动执行:1. 搜索上周arXiv上的AI论文(关键词:LLM、Agent、RLHF)2. 提取Top 20论文的标题、摘要、核心贡献3. 分类整理(技术突破、应用案例、理论分析)4. 生成Markdown报告5. 发送到Telegram和Email报告示例:# AI研究周报 - 2026年第15周## 技术突破1. [论文标题] - 核心贡献摘要2. [论文标题] - 核心贡献摘要## 应用案例...## 推荐阅读[链接列表]
7.3 场景三:个人知识管理
任务:整理跨平台的学习笔记
Hermes的工作方式:
用户:整理我过去三个月的学习笔记Hermes:1. 检索记忆系统,找到所有学习相关对话2. 分类整理: - Python高级特性(12次对话) - 机器学习算法(8次对话) - 系统设计模式(15次对话)3. 生成结构化文档: 📁 knowledge-base/ ├── python/ │ ├── decorators.md │ ├── async-programming.md │ └── metaclasses.md ├── ml/ │ ├── neural-networks.md │ └── transformers.md └── system-design/ ├── microservices.md └── caching-strategies.md4. 创建索引和交叉引用5. 生成学习路线图结果:3小时的学习碎片 → 结构化知识库
八、与主流框架对比:Hermes的独特优势
8.1 功能对比矩阵
| 特性 | Hermes Agent | LangChain | AutoGen | CrewAI |
|---|---|---|---|---|
| 自学习能力 | ✅ 闭环学习 | ❌ 无 | ⚠️ 有限 | ⚠️ 有限 |
| 技能自动创建 | ✅ 自动 | ❌ 手动 | ❌ 手动 | ❌ 手动 |
| 跨会话记忆 | ✅ FTS5+向量 | ⚠️ 需配置 | ⚠️ 需配置 | ❌ 无 |
| 多平台支持 | ✅ 16+ | ❌ 需自开发 | ❌ 需自开发 | ❌ 需自开发 |
| 多模型支持 | ✅ 200+ | ✅ 多提供商 | ✅ 多提供商 | ✅ 多提供商 |
| 终端后端 | ✅ 6种 | ❌ 本地 | ⚠️ Docker | ❌ 本地 |
| 定时任务 | ✅ 内置cron | ❌ 需外部 | ❌ 需外部 | ❌ 需外部 |
| 子代理委托 | ✅ 自动 | ⚠️ 手动 | ✅ 支持 | ✅ 支持 |
| IDE集成 | ✅ ACP协议 | ⚠️ 插件 | ❌ 无 | ❌ 无 |
| 研究工具 | ✅ RL环境 | ⚠️ 基础 | ❌ 无 | ❌ 无 |
| 开源协议 | MIT | MIT | MIT | MIT |
8.2 核心差异分析
Hermes vs LangChain:
- • LangChain是工具链编排框架,适合构建一次性工作流
- • Hermes是持续学习Agent,适合长期协作任务
- • LangChain需要手动设计Prompt和工具链;Hermes自动优化
Hermes vs AutoGen:
- • AutoGen专注多Agent协作,强调Agent间对话
- • Hermes专注单体Agent进化,强调个人助手角色
- • AutoGen缺少持久化记忆;Hermes有完整的四层记忆系统
Hermes vs CrewAI:
- • CrewAI强调角色分工(Role-based)
- • Hermes强调技能积累(Skill-based)
- • CrewAI适合团队场景;Hermes适合个人生产力场景
8.3 何时选择Hermes?
适合场景:
✅ 需要长期记忆和持续学习的个人助手
✅ 跨平台协作(Telegram + Discord + Slack等)
✅ 重复性任务的自动化(技能复用)
✅ 研究实验(内置RL环境和轨迹生成)
✅ 希望Agent越用越聪明
不适合场景:
❌ 一次性工作流(用LangChain更轻量)
❌ 多Agent博弈场景(用AutoGen更合适)
❌ 企业级Agent团队协作(用CrewAI更专业)
九、技术挑战与未来展望
9.1 当前技术挑战
尽管Hermes架构先进,但仍面临一些挑战:
1. 记忆膨胀问题
随着使用时间增长,记忆系统会积累大量数据。虽然FTS5和向量搜索效率较高,但长期运行后检索延迟仍会增加。解决方案可能包括:
- • 记忆压缩(定期合并相似记忆)
- • 记忆遗忘(基于重要性评分淘汰旧记忆)
- • 分层存储(热数据内存、冷数据磁盘)
2. 技能冲突管理
当多个技能适用于同一任务时,如何选择最优技能?当前基于加权评分的算法可能在复杂场景下失效。未来可能需要:
- • 强化学习优化技能选择策略
- • 技能组合优化(多个技能串联/并联)
- • 技能版本控制与回滚
3. 安全性与权限控制
Agent拥有执行终端命令、访问文件、发送消息的能力,如果被恶意利用后果严重。当前措施包括:
- • 工具级权限控制
- • 敏感操作需用户确认
- • 沙箱环境执行
但仍需加强:
- • 审计日志与异常检测
- • 资源使用限制(CPU、内存、网络)
- • 可信执行环境(TEE)集成
9.2 未来发展方向
根据Nous Research的路线图和社区讨论,Hermes未来可能引入:
1. 强化学习优化
内置的environments/目录已经为RL训练预留了接口。未来可能:
- • 使用PPO优化Agent决策策略
- • 基于用户反馈的奖励模型
- • 自我对弈提升技能质量
2. 多模态能力扩展
当前主要处理文本和代码。未来可能:
- • 语音输入输出(Whisper + TTS)
- • 视频理解(视频摘要、动作识别)
- • 3D场景理解(结合多模态大模型)
3. 联邦学习与隐私保护
支持在不上传数据的情况下,从多个用户的学习中受益:
- • 联邦技能库(加密聚合)
- • 差分隐私保护
- • 本地化模型微调
4. Agent生态系统
构建技能市场和插件生态:
- • 技能分享平台(类似Hugging Face)
- • 插件市场(社区贡献工具)
- • 模板库(预配置工作流)
十、快速上手指南
10.1 一键安装
# Linux/macOS/WSL2/Android (Termux)curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash# 重新加载shell配置source ~/.bashrc # 或 source ~/.zshrc# 启动Hermeshermes
10.2 首次配置
# 运行配置向导hermes setup# 选择模型提供商? Choose provider: ❯ OpenRouter (推荐,200+模型) OpenAI Anthropic Google AI Studio Nous Portal (免费) Local (Ollama)# 输入API密钥? Enter API key: [粘贴密钥]# 选择默认工具集? Select toolsets: ✓ core (文件、终端、网络) ✓ development (代码执行、Git) ✓ automation (cron、消息) ○ research (批量评估、RL环境)配置完成!输入 hermes 开始对话
10.3 第一个任务
$ hermesHermes Agent v0.8.0 | Model: gpt-4o | Ready你> 创建一个Python Flask应用,实现Todo列表的CRUD操作Hermes> 好的,我将: 1. 创建项目结构 2. 实现Flask API(GET/POST/PUT/DELETE) 3. 添加SQLite数据库 4. 编写测试用例 5. 创建README文档 [执行中...] ✓ 创建 app.py ✓ 创建 models.py ✓ 创建 routes.py ✓ 创建 tests/test_app.py ✓ 创建 requirements.txt ✓ 创建 README.md ✓ 运行测试(12/12通过) 项目已创建!运行 `python app.py` 启动服务。 💡 我已创建技能 "flask-todo-crud",下次可以直接复用。你> /skills list已安装技能: - flask-todo-crud (devops, 使用1次, 成功率100%) - deploy-docker-compose (devops, 使用47次, 成功率94%) - research-paper-summary (research, 使用23次, 成功率91%) ...你> /model claude-3-5-sonnet已切换到模型:claude-3-5-sonnet你> /new已创建新会话,上下文已清空
10.4 配置消息网关
# 设置Telegram机器人hermes gateway setup# 启动网关hermes gateway start[2026-04-11 10:00:00] Gateway started[2026-04-11 10:00:00] Telegram bot connected[2026-04-11 10:00:00] Discord bot connected[2026-04-11 10:00:00] Listening for messages...# 现在可以在Telegram上发送消息给机器人
结语:Agent进化的新范式
Hermes Agent的出现,标志着AI Agent从工具向伙伴的转变。
传统Agent是工具——你给它指令,它执行,然后忘记一切。
Hermes是伙伴——它记住你的偏好,学习你的习惯,积累你的知识,与你共同成长。
这种转变的意义不仅在于技术层面,更在于人机协作模式的重构:
- • 从"每次重新教"到"一次教会,终身受益"
- • 从"单向指令"到"双向学习"
- • 从"孤立任务"到"连续协作"
正如Nous Research所说:“Hermes是唯一一个随着使用变得更有价值的Agent框架”。
对于开发者而言,Hermes提供了:
- • 一个透明的参考实现(纯Python,无黑盒)
- • 一个可扩展的架构(插件系统、MCP集成)
- • 一个研究平台(RL环境、轨迹分析工具)
对于普通用户而言,Hermes提供了:
- • 一个真正的个人AI助手(跨平台、全天候)
- • 一个知识管理引擎(自动整理、智能检索)
- • 一个自动化工作流平台(定时任务、技能复用)
2026年,AI Agent的竞争已从"谁能完成任务"转向"谁能持续进化"。Hermes Agent用开源的方式,为这场竞争树立了一个新的标杆。
未来已来,你会用它创造什么?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)